improving mapreduce performance through data placement in heterogeneous hadoop clusters jiong xie...
Post on 20-Dec-2015
222 views
TRANSCRIPT

Improving MapReduce Performance through Data Placement in
Heterogeneous Hadoop Clusters
Jiong XiePh.D. Student
April 2010

Presentation Outline
• Background
• Motivation
• Related Work
• Design and Implementation
• Experimental Result
• Conclusion/Future Work
22
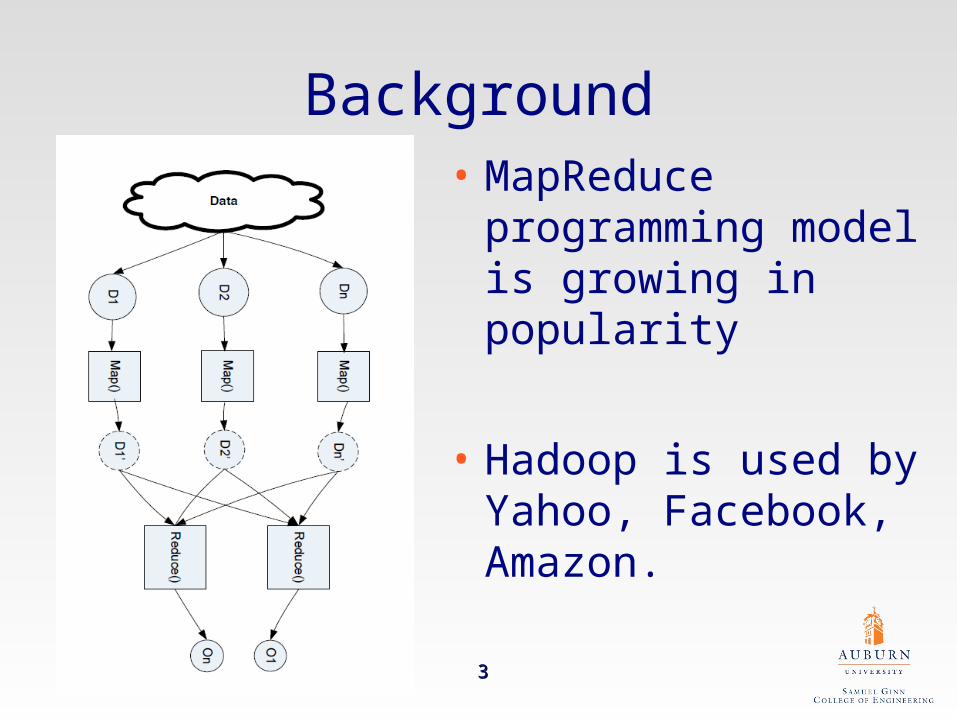
Background• MapReduce
programming model is growing in popularity
• Hadoop is used by Yahoo, Facebook, Amazon.
33

Data Intensive Applications
44
Bioinformatics Weather forecast
AstronauticsMedicine science
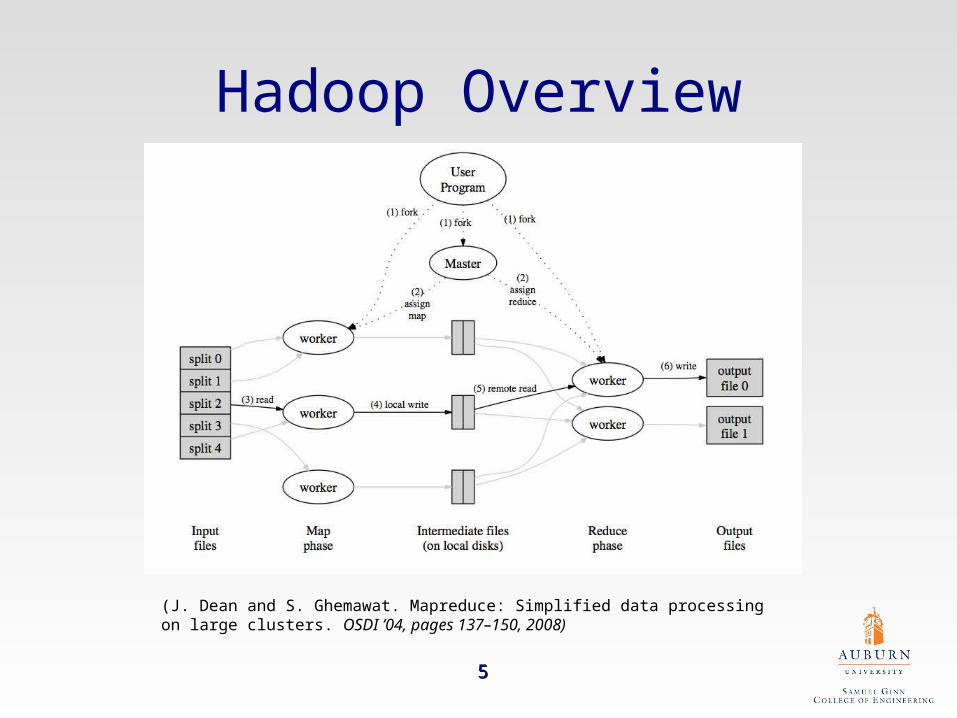
Hadoop Overview
55
(J. Dean and S. Ghemawat. Mapreduce: Simplified data processing on large clusters. OSDI ’04, pages 137–150, 2008)
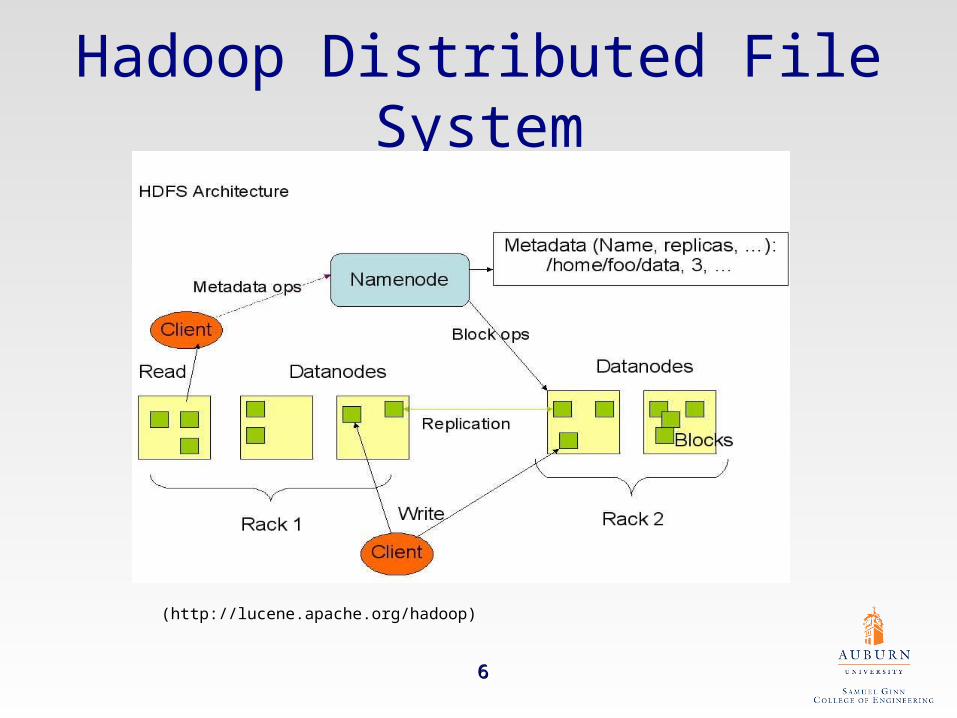
Hadoop Distributed File System
66
(http://lucene.apache.org/hadoop)

Motivational Example
Time (min)
Node A(fast)
Node B(slow)
Node C(slowest)
2x slower
3x slower
1 task/min
77

The Native Strategy
Node A
Node B
Node C
3 tasks
2 tasks
6 tasks
Loading Transferring Processing 88
Time (min)
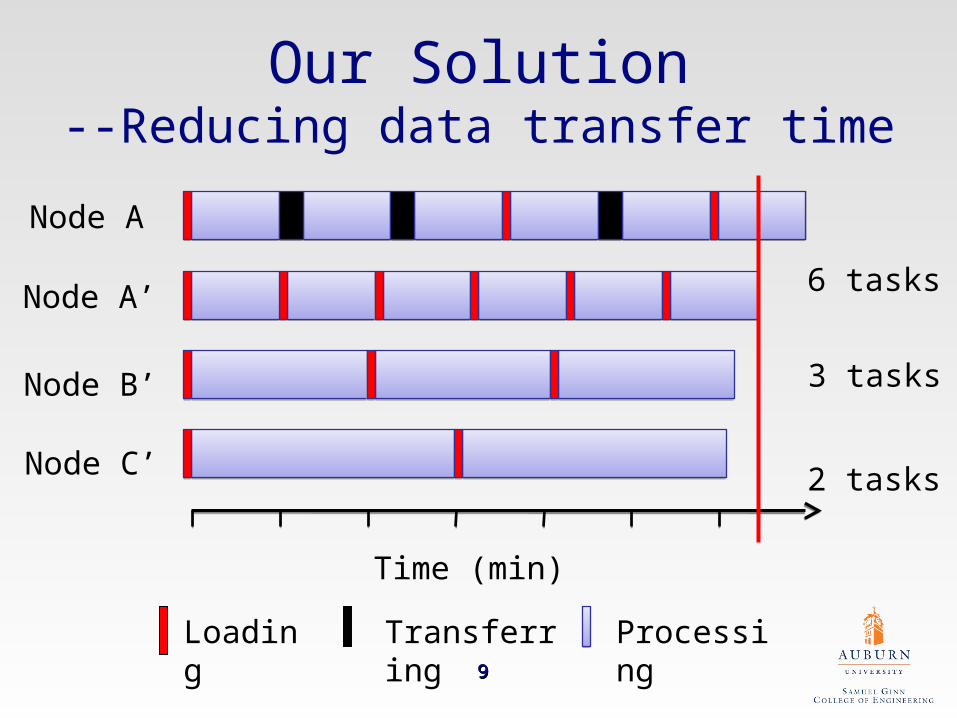
Our Solution--Reducing data transfer time
99
Node A’
Node B’
Node C’
3 tasks
2 tasks
6 tasks
Loading Transferring Processing 99
Time (min)
Node A
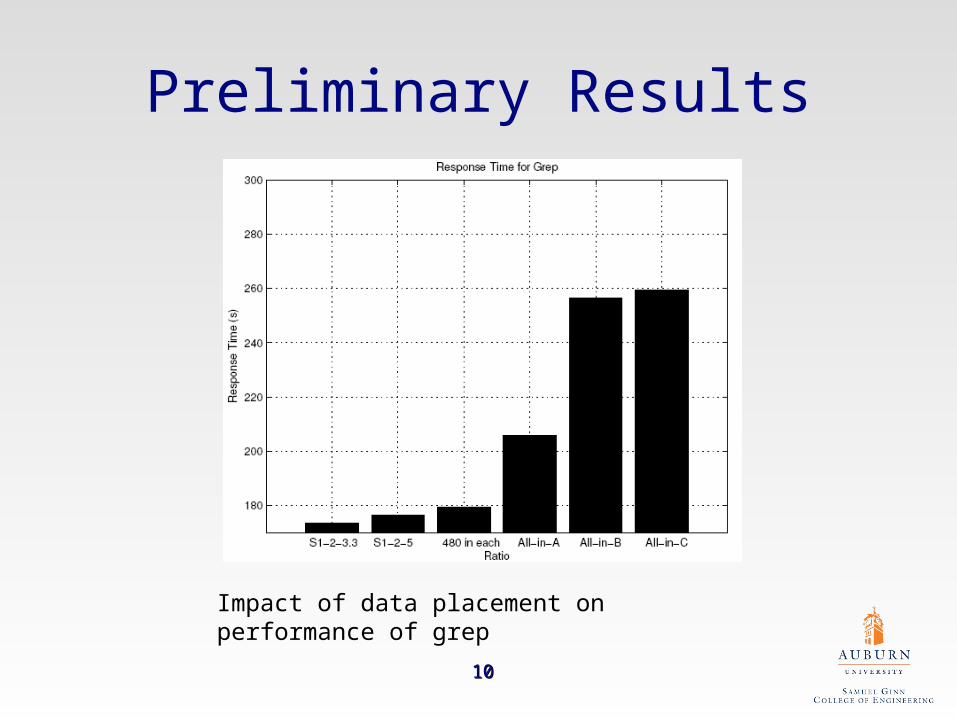
Preliminary Results
1010
Impact of data placement on performance of grep

Challenges
• Does computing ratio depend on the application?
• Initial data distribution
• Data skew problem– New data arrival– Data deletion – New joining node– Data updating
1111

Measure Computing Ratios• Computing ratio
• Fast machines process large data sets
1212
Time
Node A
Node B
Node C
2x slower
3x slower
1 task/min

Steps to MeasureComputing Ratios
1313
Node Response time(s)
Ratio # of File Fragments
Speed
Node A 10 1 6 Fastest
Node B 20 2 3 Average
Node C 30 3 2 Slowest
1. Run the application on each node with the same size data, individually collect the response time
2. Set the ratio of the shortest response as 1, accordingly set the ratio of other nodes
3.Caculate the least common multiple of these ratios
4. Count the portion of each node
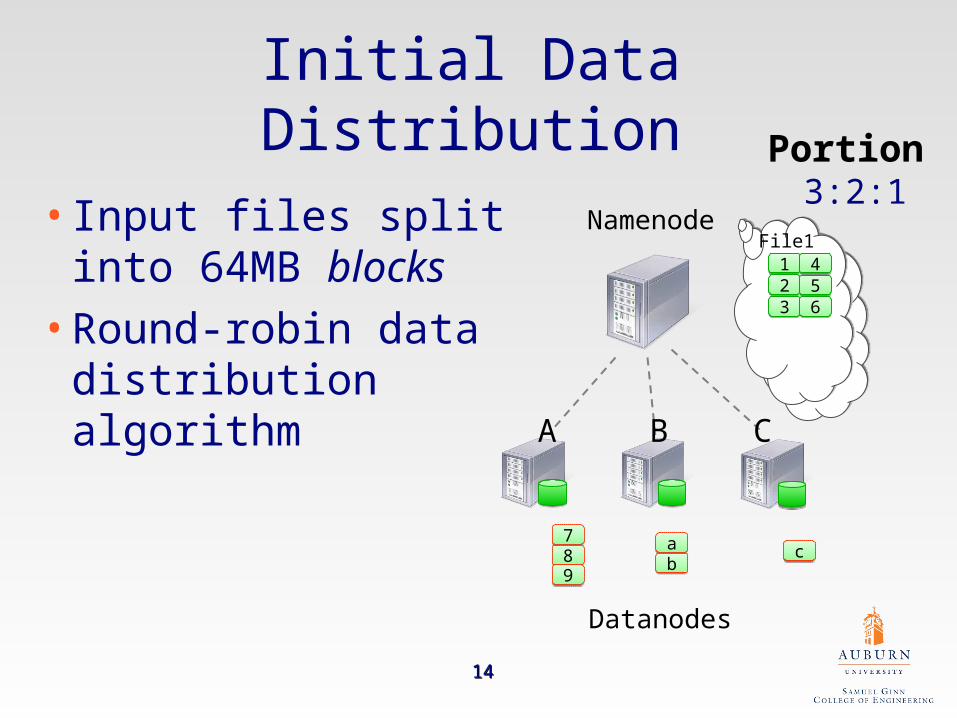
Initial Data Distribution
Namenode
Datanodes
112233
File1445566
778899
aabb
cc
• Input files split into 64MB blocks
• Round-robin data distribution algorithm
CBA
1414
Portion 3:2:1
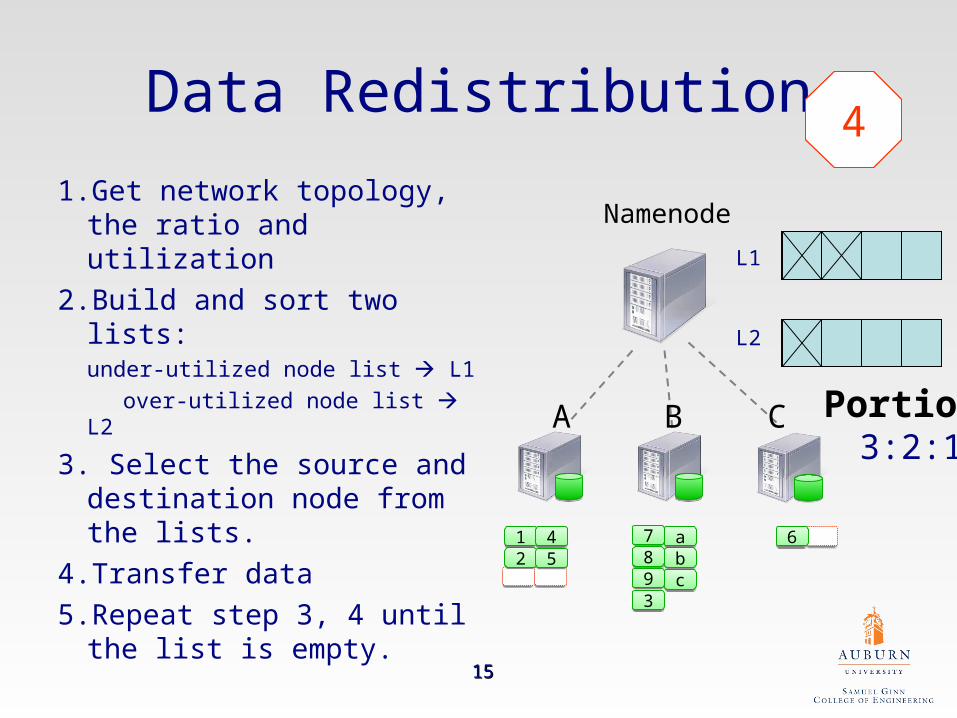
1Data Redistribution
1.Get network topology, the ratio and utilization
2.Build and sort two lists:under-utilized node list L1
over-utilized node list L2
3. Select the source and destination node from the lists.
4.Transfer data
5.Repeat step 3, 4 until the list is empty.
Namenode
1122
33
4455
66778899
aabbcc
CA
CBA
B
234
L1
L2
1515
Portion 3:2:1

Sharing Files among Multiple Applications
• The computing ratio depends on data-intensive applications.– Redistribution– Redundancy
1616

Experimental Environment
Five nodes in a hadoop heterogeneous cluster
1717
Node CPU Model CPU(Hz) L1 Cache(KB)
Node A Intel core 2 Duo 2*1G=2G 204
Node B Intel Celeron 2.8G 256
Node C Intel Pentium 3 1.2G 256
Node D Intel Pentium 3 1.2G 256
Node E Intel Pentium 3 1.2G 256

Grep and WordCount
• Grep is a tool searching for a regular expression in a text file
• WordCount is a program used to count words in a text file
1818

Computing ratio for two applications
1919
Computing ratio of the five nodes with respective of Grep and Wordcount applications
Computing Node Ratios for Grep Ratios for Wordcount
Node A 1 1
Node B 2 2
Node C 3.3 5
Node D 3.3 5
Node E 3.3 5
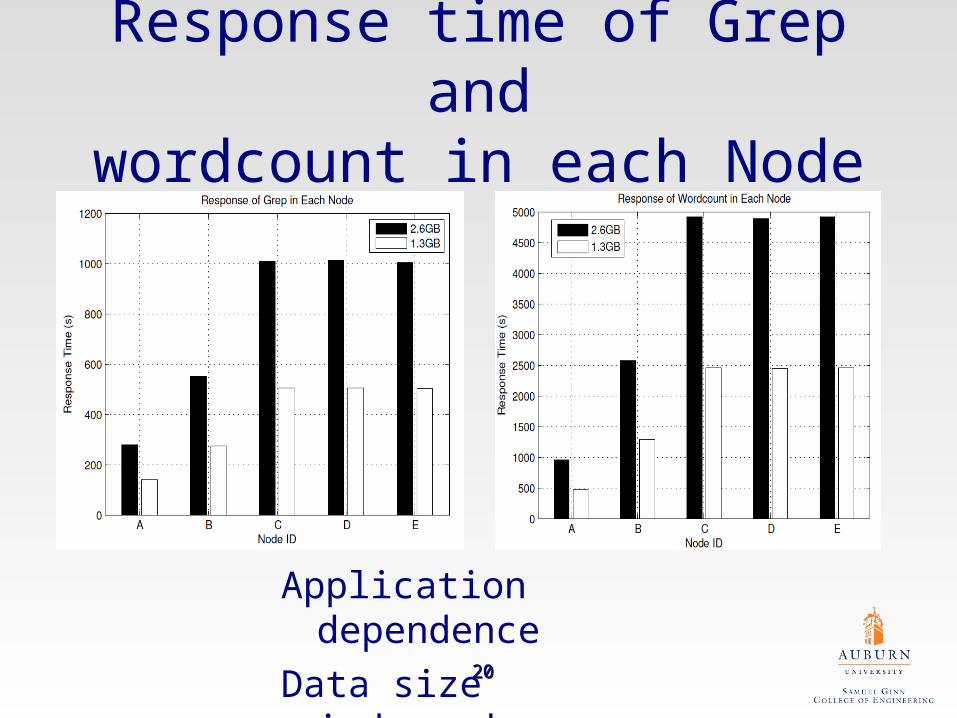
Response time of Grep andwordcount in each Node
2020
Application dependence
Data size independence

Six Data Placement Decisions
2121
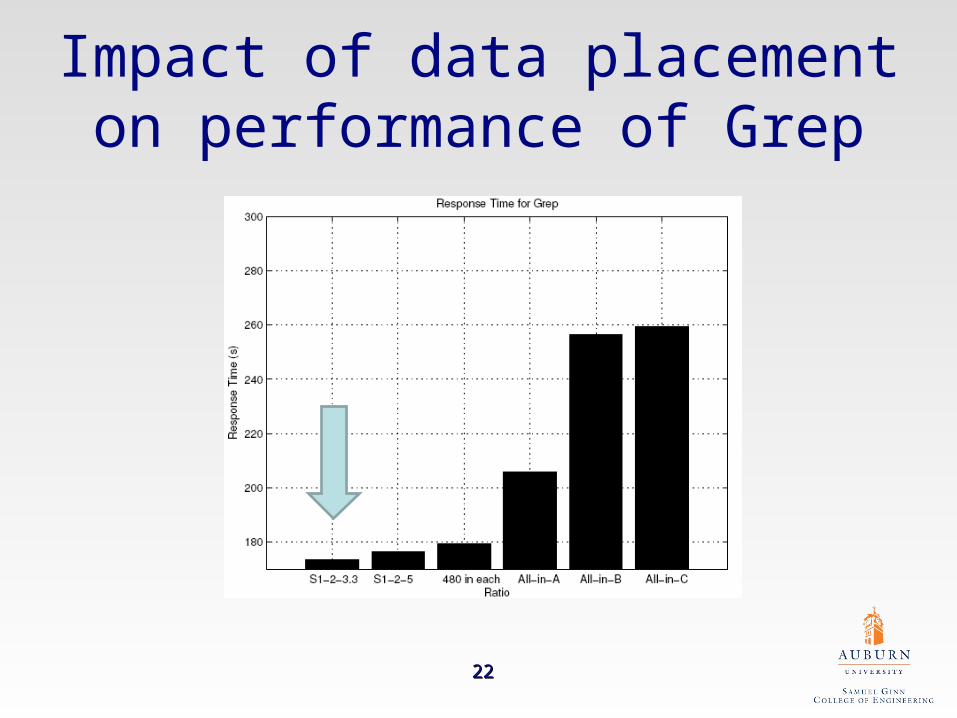
Impact of data placement on performance of Grep
2222
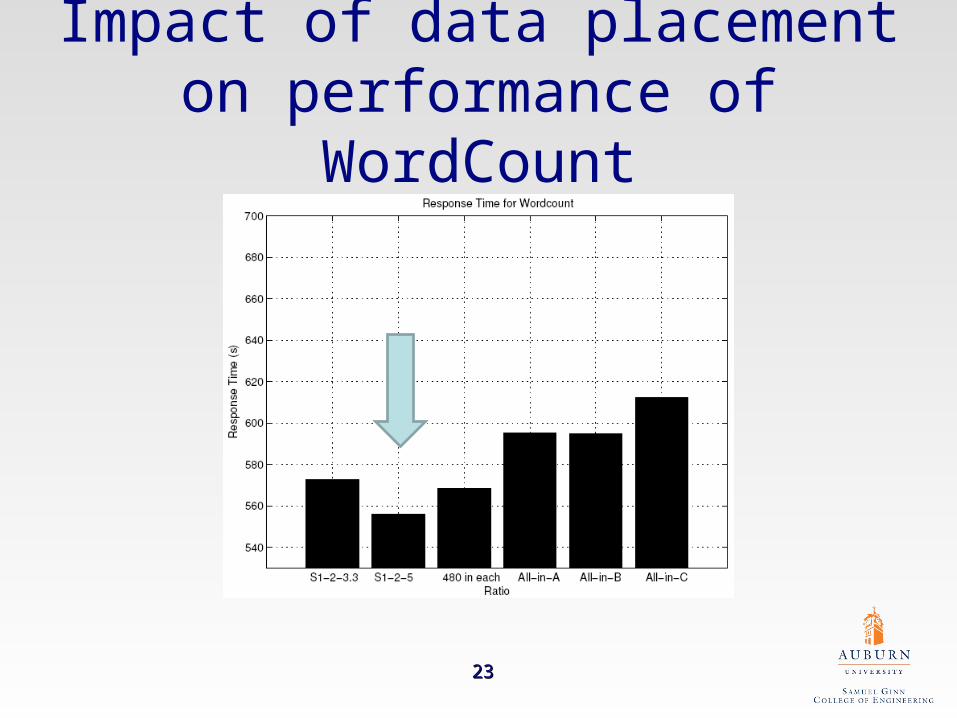
Impact of data placement on performance of WordCount
2323

Conclusion
• Identify the performance degradation caused by heterogeneity.
• Designed and implemented a data placement mechanism in HDFS.
2424

Future Work
• Data redundancy issue
• Dynamic data distribution mechanism
• Prefetching
2525

Thanks
2626

Question
?
2727