improving hdfs availability with hadoop rpc quality of service
TRANSCRIPT

Improving HDFS Availability with !Hadoop RPC Quality of Service
Hadoop Summit 2015

• Hadoop performance at scale
Ming Ma
• Hadoop reliability and scalability
Twitter Hadoop TeamChris Li
Data Platform
Who We Are

@twitterhadoop
Agenda
‣Diagnosis of Namenode Congestion
• How does QoS help?
• How to use QoS in your clusters

@twitterhadoop
Hadoop Workloads @ Twitter, ebay• Large scale
• Thousands of machines • Tens of thousands of jobs / day
• Diverse • Production vs ad-hoc • Batch vs interactive vs iterative
• Require performance isolation

@twitterhadoop
Solutions for Performance Isolation• YARN: flexible cluster resource management
• Cross Data Center Traffic QoS • Set QoS policy via DSCP bits in IP header
• HDFS Federation
• Cluster Separation: run high SLA jobs in another cluster

@twitterhadoop
Unsolved Extreme Cluster Slowdown
• hadoop fs -ls takes 5+ seconds
• Worst case: cluster outage • Namenode lost some datanode heartbeats → replication storm

@twitterhadoop
Audit Logs to the Rescue
• Username, operation type, date record logged for each operation
• We automatically backup into HDFS

@twitterhadoop
(Hadoop Learning about Itself)

@twitterhadoop
Cause: Resource Monopolization
Each color is a different user Area is number of calls

@twitterhadoop
What’s wrong with this code?
while (true) { fileSystem.exists("/foo");}
Don’t do this at home
Unless QoS is on ;)

@twitterhadoop
Bad Code + MapReduce= DDoS on Namenode!
Namenode
Bad User
Good Users
Other Users

@twitterhadoop
Bad Code + MapReduce= DDoS on Namenode!
Namenode
Bad User
Good Users
Other Users

@twitterhadoop
Bad Code + MapReduce= DDoS on Namenode!
Namenode
Bad User
Good Users
Other Users

@twitterhadoop
Bad Code + MapReduce= DDoS on Namenode!
Namenode
Bad User
Good Users
Other Users

@twitterhadoop
Bad Code + MapReduce= DDoS on Namenode!
Namenode
Bad User
Good Users
Other Users

@twitterhadoop
Bad Code + MapReduce= DDoS on Namenode!
Namenode
Bad User
Good Users
Other Users

@twitterhadoop
Client Process Namenode Process
RPC ServerRPC Client
DFS Client Namenode Service
Responders
NN Lock
Hadoop RPC Overview
FIFO Call Queue HandlersReaders
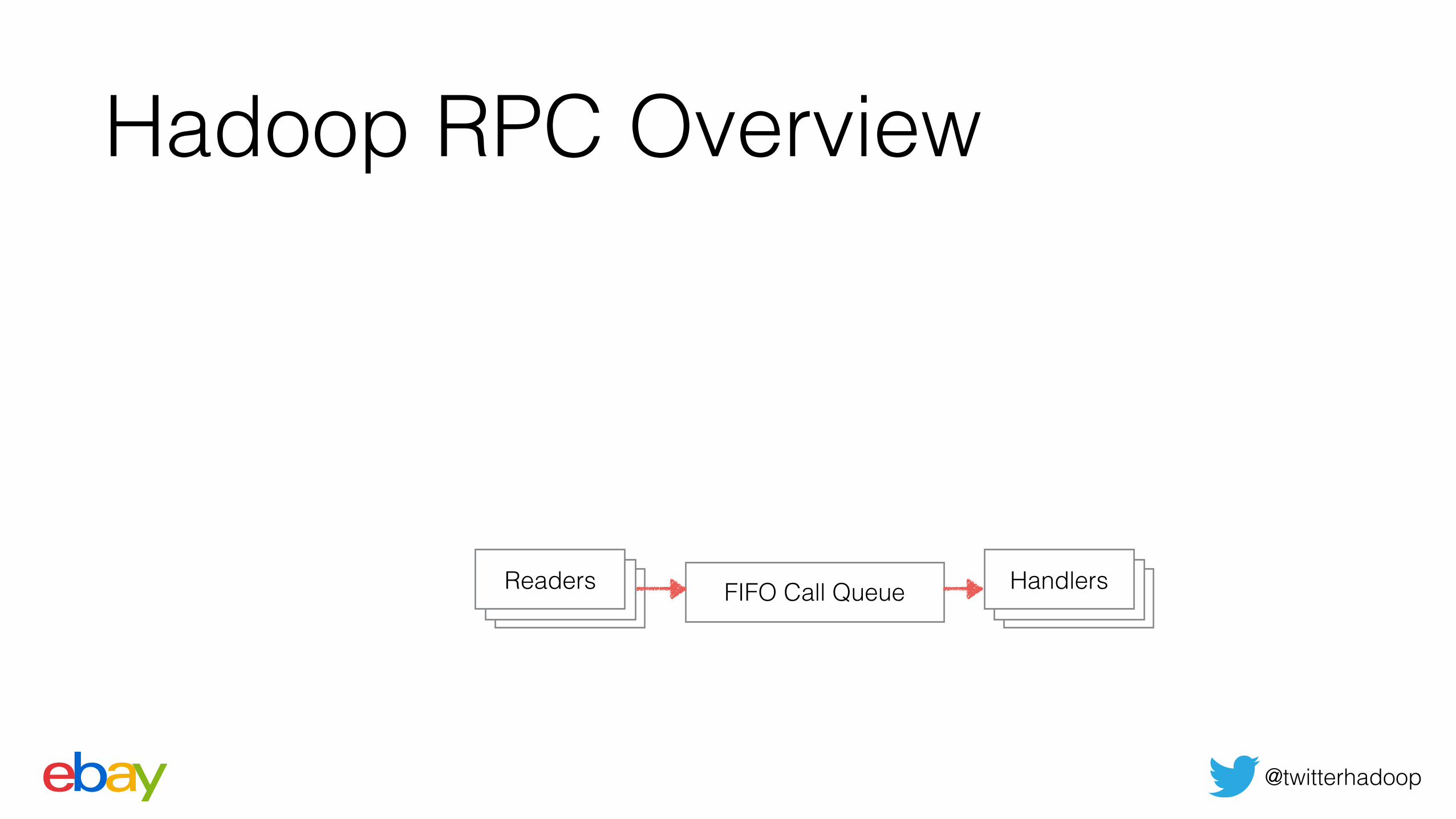
@twitterhadoop
Hadoop RPC Overview
FIFO Call Queue HandlersReaders

@twitterhadoop
Diagnosing CongestionGood User
Bad User
FIFO Call QueueHandlersReaders

@twitterhadoop
Diagnosing Congestion
HandlersReaders
Good User
Bad User

@twitterhadoop
Diagnosing Congestion
HandlersReaders
Good User
Bad User
••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••

@twitterhadoop
Solutions we’ve considered
• HDFS Federation
• Use separate RPC server for datanode requests (service RPC)
• Namenode global lock

@twitterhadoop
Agenda
✓Diagnosis of Namenode Congestion
‣How does QoS help?
• How to use QoS in your clusters

@twitterhadoop
Goals
• Achieve Fairness and QoS
• No performance degradation • High throughput • Low overhead

@twitterhadoop
Model it as a scheduling problem
• Available resource is the RPC handler thread
• Users should be given a fair share of resources

@twitterhadoop
Design Considerations
• Pluggable, configurable
• Simplifying assumptions: • All users are equal • All RPC calls have the same cost
• Leverage existing scheduling algorithms

@twitterhadoop
Solving Congestion with FairCallQueue
Call Queue
HandlersReaders
Good User
Bad User
Queue 0
Queue 1
Queue 2
Queue 3Sc
hedu
ler
Mul
tiple
xer

@twitterhadoop
Fair SchedulingCall Queue
HandlersReaders
Good User
Bad User

@twitterhadoop
Fair Scheduling: Good UserCall Queue
HandlersReaders
Good User
Bad User
11%

@twitterhadoop
Fair Scheduling: Good UserCall Queue
HandlersReaders
Good User
Bad User
Queue 0: < 12%

@twitterhadoop
Fair Scheduling: Good UserCall Queue
HandlersReaders
Good User
Bad User

@twitterhadoop
Fair Scheduling: Bad UserCall Queue
HandlersReaders
Good User
Bad User

@twitterhadoop
Fair Scheduling: Bad UserCall Queue
HandlersReaders
Good User
Bad User
80%

@twitterhadoop
Fair Scheduling: Bad UserCall Queue
HandlersReaders
Good User
Bad User
Queue 3: > 50%

@twitterhadoop
Fair Scheduling: Bad UserCall Queue
HandlersReaders
Good User
Bad User
@twitterhadoop
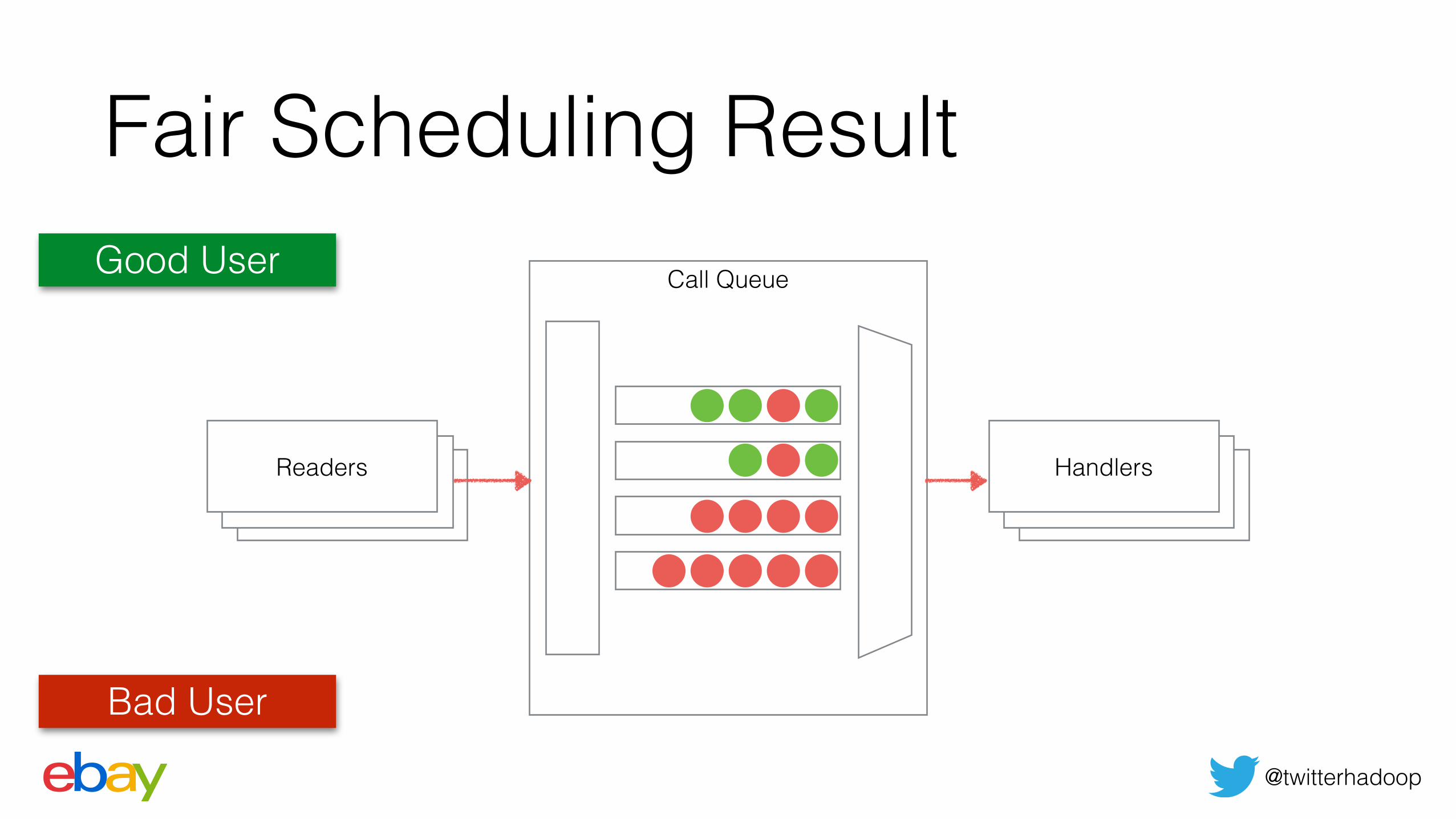
Fair Scheduling ResultCall Queue
HandlersReaders
Good User
Bad User

@twitterhadoop
Weighted Round-Robin MultiplexingCall Queue
HandlersReaders
Good User
Bad User

@twitterhadoop
Weighted Round-Robin MultiplexingCall Queue
HandlersReaders
Good User
Bad User
Take 3

@twitterhadoop
Weighted Round-Robin MultiplexingCall Queue
HandlersReaders
Good User
Bad User
Take 2

@twitterhadoop
Weighted Round-Robin MultiplexingCall Queue
HandlersReaders
Good User
Bad User

@twitterhadoop
Weighted Round-Robin MultiplexingCall Queue
HandlersReaders
Good User
Bad User

@twitterhadoop
Weighted Round-Robin MultiplexingCall Queue
HandlersReaders
Good User
Bad User
Repeat

@twitterhadoop
FairCallQueue preventing high latency
FIFO CallQueue
FairCallQueue

@twitterhadoop
RPC Backoff
• Prevents RPC queue from completely filling up
• Clients are told to wait and retry with exponential backoff

RPC BackoffGood User
Bad User
Call Queue
HandlersReaders
Good User
RetriableException

@twitterhadoop
RPC Backoff EffectsConnectTimeoutException
ConnectTimeoutException
Goo
d Ap
p La
tenc
y (m
s)
0
2250
4500
6750
9000
Abusive App - number of clients - number of connections100 x 100 1k x 1k 10k x 100 10k x 500 10k x 10k 50k x 50k
Normal FairCallQueue FairCallQueue + RPC Backoff

@twitterhadoop
Current Status• Enabled on all Twitter and ebay production
clusters for 6+ months
• Open source availability: HADOOP-9640 • Swappable call queue in 2.4 • FairCallQueue in 2.6 • RPC Backoff in 2.8

@twitterhadoop
Agenda
✓Diagnosis of Namenode Congestion
✓How does QoS help?
‣How to use QoS in your clusters

@twitterhadoop
QoS is Easy to Enablehdfs-site.xml: !
<property> <name>ipc.8020.callqueue.impl</name> <value>org.apache.hadoop.ipc.FairCallQueue</value> </property> <property> <name>ipc.8020.backoff.enable</name> <value>true</value> </property>
Port you want QoS on

@twitterhadoop
Future Possibilities• RPC scheduling improvements
• Weighted share per user • Prioritize datanode RPCs over client RPC
• Overall HDFS QoS • Namenode fine-grained locking • Fairness for data transfers • HTTP based payloads such as webHDFS

@twitterhadoop
Conclusion
• Try it out!
• No more namenode congestion since it’s been enabled at both Twitter and ebay
• Providing QoS at the RPC level is an important step towards HDFS fine-grained QoS

@twitterhadoop
Special thanks to our reviewers:• Arpit Agarwal (Hortonworks)
• Daryn Sharp (Yahoo)
• Andrew Wang (Cloudera)
• Benoy Antony (ebay)
• Jing Zhao (Hortonworks)
• Hiroshi Ideka (vic.co.jp)
• Eddy Xu (Cloudera)
• Steve Loughran (Hortonworks)
• Suresh Srinivas (Hortonworks)
• Kihwal Lee (Yahoo)
• Joep Rottinghuis (Twitter)
• Lohit VijayaRenu (Twitter)

@twitterhadoop
Questions and Answers
• For help setting up QoS, feature ideas, questions:
Ming Ma Chris Li
@twitterhadoop@mingmasplace

@twitterhadoop
Appendix

@twitterhadoop
FairCallQueue Data• 37 node cluster
• 10 users runs a job which has: • 20 Mappers, each mapper:
• Runs 100 threads. Each thread: • Continuously calls hdfs.exists() in a tight loop
• Spikes are caused by garbage collection, a separate issue

@twitterhadoop
Client Backoff Data
• See https://issues.apache.org/jira/secure/attachment/12670619/MoreRPCClientBackoffEvaluation.pdf

@twitterhadoop
Related JIRAs• FairCallQueue + Backoff: HADOOP-9640
• Cross Data Center Traffic QoS: HDFS-5175
• nntop: HDFS-6982
• Datanode Congestion Control: HDFS-7270
• Namenode fine-grained locking: HDFS-5453

@twitterhadoop
Thoughts on Tuning
• Worth considering if you run a larger cluster or have many users
• Make your life easier while tuning by refreshing the queue with hadoop dfsadmin -refreshCallQueue

@twitterhadoop
Anatomy of a QoS conf key
• core-site.xml
• ipc.8020.faircallqueue.priority-levels
RPC server’s port, customize if using non-default port / service rpc port

key: default:
@twitterhadoop
Number of Sub-queues
• More subqueues = more unique classes of service
• Recommend 10 for larger clusters
ipc.8020.faircallqueue.priority-levels 4

key: default:
@twitterhadoop
Scheduler: Decay Factor
• Controls by how much accumulated counts are decayed by on each sweep. Larger values decay slower.
• Ex: 1024 calls with decay factor of 0.5 will take 10 sweeps to decay assuming the user makes no additional calls.
ipc.8020.faircallqueue.decay-scheduler.decay-factor 0.5

key: default:
@twitterhadoop
Scheduler: Sweep Period
• How many ms between each decay sweep. Smaller is more responsive, but sweeps have overhead.
• Ex: if it takes 10 sweeps to decay and we sweep every 5 seconds, a user’s activity will remain for 50s.
ipc.8020.faircallqueue.decay-scheduler.period-ms 5000

key: default:
@twitterhadoop
Scheduler: Thresholds
• List of floats, determines boundaries between each service class. If you have 4 queues, you’ll have 3 bounds.
• Each number represents a percentage of total calls.
• First number is threshold for going into queue 0 (highest priority). Second number decides queue 1 vs rest. etc.
• Recommend trying even splits (10, 20, 30, … 90) or exponential (default)
ipc.8020.faircallqueue.decay-scheduler.thresholds 12%, 25%, 50%

key: default:
@twitterhadoop
Multiplexer: Weights
• Weights are how many times the mux will try to read from a sub-queue it represents before moving on to the next sub-queue.
• Ex: 4,3,1 is used for 3 queues, meaning: Read up to 4 times from queue 0, Read up to 3 times from queue 1, Read once from queue 2, Repeat
• The mux controls the penalty of being in a low-priority queue. Recommend not setting anything to 0, as starvation is possible in that case.
ipc.8020.faircallqueue.multiplexer.weights 8,4,2,1

key: default:
@twitterhadoop
Backoff Max Attempts
• The default is equivalent to 90 seconds of retrying
• To achieve equivalent of 10 minutes of retrying, set it to 44.
dfs.client.retry.max.attempts 10