improved bounds for policy iteration in markov decision
TRANSCRIPT

1/9
Improved Bounds for Policy Iteration in Markov Decision Problems
Shivaram Kalyanakrishnan
Department of Computer Science and EngineeringIndian Institute of Technology Bombay
November 2017
Collaborators: Neeldhara Misra, Aditya Gopalan, Utkarsh Mall, Ritish Goyal, Anchit Gupta
Shivaram Kalyanakrishnan (2017) Analysis of Policy Iteration in MDPs 1 / 9

1/9
Improved Bounds for Policy Iteration in Markov Decision Problems
Shivaram Kalyanakrishnan
Department of Computer Science and EngineeringIndian Institute of Technology Bombay
November 2017
Collaborators: Neeldhara Misra, Aditya Gopalan, Utkarsh Mall, Ritish Goyal, Anchit Gupta
Shivaram Kalyanakrishnan (2017) Analysis of Policy Iteration in MDPs 1 / 9

1/9
Improved Bounds for Policy Iteration in Markov Decision Problems
Shivaram Kalyanakrishnan
Department of Computer Science and EngineeringIndian Institute of Technology Bombay
November 2017
Collaborators: Neeldhara Misra, Aditya Gopalan, Utkarsh Mall, Ritish Goyal, Anchit Gupta
Shivaram Kalyanakrishnan (2017) Analysis of Policy Iteration in MDPs 1 / 9

1/9
Improved Bounds for Policy Iteration in Markov Decision Problems
Shivaram Kalyanakrishnan
Department of Computer Science and EngineeringIndian Institute of Technology Bombay
November 2017
Collaborators: Neeldhara Misra, Aditya Gopalan, Utkarsh Mall, Ritish Goyal, Anchit Gupta
Shivaram Kalyanakrishnan (2017) Analysis of Policy Iteration in MDPs 1 / 9

2/9
Sequential Decision Making
Shivaram Kalyanakrishnan (2017) Analysis of Policy Iteration in MDPs 2 / 9

2/9
Sequential Decision Making
ActSense
AGENT
ENVIRONMENT
Think
actionrewardstate
Shivaram Kalyanakrishnan (2017) Analysis of Policy Iteration in MDPs 2 / 9

2/9
Sequential Decision Making
ActSense
AGENT
ENVIRONMENT
Think
actionrewardstate
https://img.tradeindia.com/fp/1/524/panoramic-elevators-564.jpg
Shivaram Kalyanakrishnan (2017) Analysis of Policy Iteration in MDPs 2 / 9

2/9
Sequential Decision Making
ActSense
AGENT
ENVIRONMENT
Think
actionrewardstate
https://img.tradeindia.com/fp/1/524/panoramic-elevators-564.jpg
http://www.nature.com/polopoly_fs/7.33483.1453824868!/image/WEB_Go—1.jpg_gen/derivatives/landscape_630/WEB_Go—1.jpg
Shivaram Kalyanakrishnan (2017) Analysis of Policy Iteration in MDPs 2 / 9

3/9
Markov Decision Problems (MDPs)
s s1 2
s3
0.5, 0
1, 1
0.5, 3
0.25, −1
1, 10.5, −1
1, 2
0.5, 30.75, −2
Shivaram Kalyanakrishnan (2017) Analysis of Policy Iteration in MDPs 3 / 9

3/9
Markov Decision Problems (MDPs)
s s1 2
s3
0.5, 0
1, 1
0.5, 3
0.25, −1
1, 10.5, −1
1, 2
0.5, 30.75, −2
Elements of an MDP
States (S)
Actions (A)
Transition probabilities (T )
Rewards (R)
Shivaram Kalyanakrishnan (2017) Analysis of Policy Iteration in MDPs 3 / 9

3/9
Markov Decision Problems (MDPs)
s s1 2
s3
0.5, 0
1, 1
0.5, 3
0.25, −1
1, 10.5, −1
1, 2
0.5, 30.75, −2
Elements of an MDP
States (S)
Actions (A)
Transition probabilities (T )
Rewards (R)
Behaviour is encoded as a Policy π, which maps states to actions.
Shivaram Kalyanakrishnan (2017) Analysis of Policy Iteration in MDPs 3 / 9

3/9
Markov Decision Problems (MDPs)
s s1 2
s3
0.5, 0
1, 1
0.5, 3
0.25, −1
1, 10.5, −1
1, 2
0.5, 3
RED
BLUE
RED 0.75, −2
Elements of an MDP
States (S)
Actions (A)
Transition probabilities (T )
Rewards (R)
Behaviour is encoded as a Policy π, which maps states to actions.
Shivaram Kalyanakrishnan (2017) Analysis of Policy Iteration in MDPs 3 / 9

3/9
Markov Decision Problems (MDPs)
s s1 2
s3
0.5, 0
1, 1
0.5, 3
0.25, −1
1, 10.5, −1
1, 2
0.5, 3
RED
BLUE
RED 0.75, −2
Elements of an MDP
States (S)
Actions (A)
Transition probabilities (T )
Rewards (R)
Behaviour is encoded as a Policy π, which maps states to actions.
What is a “good” policy?
Shivaram Kalyanakrishnan (2017) Analysis of Policy Iteration in MDPs 3 / 9
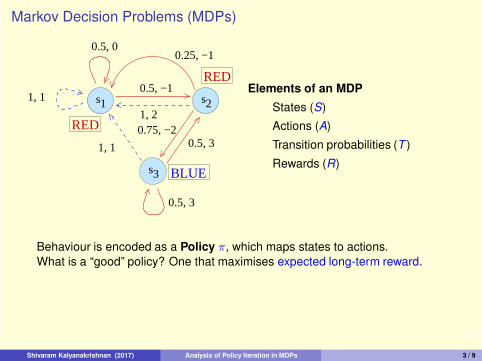
3/9
Markov Decision Problems (MDPs)
s s1 2
s3
0.5, 0
1, 1
0.5, 3
0.25, −1
1, 10.5, −1
1, 2
0.5, 3
RED
BLUE
RED 0.75, −2
Elements of an MDP
States (S)
Actions (A)
Transition probabilities (T )
Rewards (R)
Behaviour is encoded as a Policy π, which maps states to actions.
What is a “good” policy? One that maximises expected long-term reward.
Shivaram Kalyanakrishnan (2017) Analysis of Policy Iteration in MDPs 3 / 9
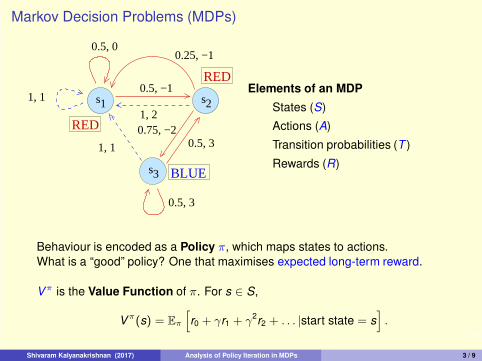
3/9
Markov Decision Problems (MDPs)
s s1 2
s3
0.5, 0
1, 1
0.5, 3
0.25, −1
1, 10.5, −1
1, 2
0.5, 3
RED
BLUE
RED 0.75, −2
Elements of an MDP
States (S)
Actions (A)
Transition probabilities (T )
Rewards (R)
Behaviour is encoded as a Policy π, which maps states to actions.
What is a “good” policy? One that maximises expected long-term reward.
Vπ is the Value Function of π. For s ∈ S,
Vπ(s) = Eπ
[
r0 + γr1 + γ2r2 + . . . |start state = s
]
.
Shivaram Kalyanakrishnan (2017) Analysis of Policy Iteration in MDPs 3 / 9

3/9
Markov Decision Problems (MDPs)
s s1 2
s3
0.5, 0
1, 1
0.5, 3
0.25, −1
1, 10.5, −1
1, 2
0.5, 3
RED
BLUE
RED 0.75, −2
γ = 0.9
Elements of an MDP
States (S)
Actions (A)
Transition probabilities (T )
Rewards (R)
Discount factor (γ)
Behaviour is encoded as a Policy π, which maps states to actions.
What is a “good” policy? One that maximises expected long-term reward.
Vπ is the Value Function of π. For s ∈ S,
Vπ(s) = Eπ
[
r0 + γr1 + γ2r2 + . . . |start state = s
]
.
Shivaram Kalyanakrishnan (2017) Analysis of Policy Iteration in MDPs 3 / 9

4/9
Optimal Policies
Vπ satisfies a recursive equation: V
π = Rπ + γTπVπ, which gives
Vπ = (I − γTπ)
−1Rπ.
Shivaram Kalyanakrishnan (2017) Analysis of Policy Iteration in MDPs 4 / 9
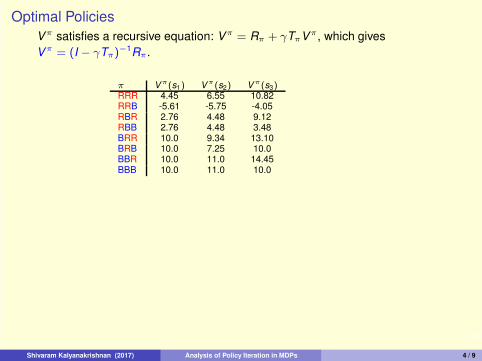
4/9
Optimal Policies
Vπ satisfies a recursive equation: V
π = Rπ + γTπVπ, which gives
Vπ = (I − γTπ)
−1Rπ.
π Vπ(s1) V
π(s2) Vπ(s3)
RRR 4.45 6.55 10.82RRB -5.61 -5.75 -4.05RBR 2.76 4.48 9.12RBB 2.76 4.48 3.48BRR 10.0 9.34 13.10BRB 10.0 7.25 10.0BBR 10.0 11.0 14.45BBB 10.0 11.0 10.0
Shivaram Kalyanakrishnan (2017) Analysis of Policy Iteration in MDPs 4 / 9
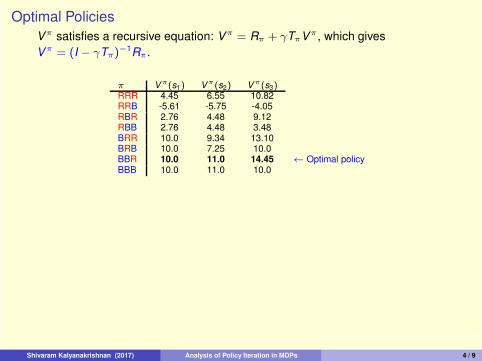
4/9
Optimal Policies
Vπ satisfies a recursive equation: V
π = Rπ + γTπVπ, which gives
Vπ = (I − γTπ)
−1Rπ.
π Vπ(s1) V
π(s2) Vπ(s3)
RRR 4.45 6.55 10.82RRB -5.61 -5.75 -4.05RBR 2.76 4.48 9.12RBB 2.76 4.48 3.48BRR 10.0 9.34 13.10BRB 10.0 7.25 10.0BBR 10.0 11.0 14.45 ← Optimal policyBBB 10.0 11.0 10.0
Shivaram Kalyanakrishnan (2017) Analysis of Policy Iteration in MDPs 4 / 9

4/9
Optimal Policies
Vπ satisfies a recursive equation: V
π = Rπ + γTπVπ, which gives
Vπ = (I − γTπ)
−1Rπ.
π Vπ(s1) V
π(s2) Vπ(s3)
RRR 4.45 6.55 10.82RRB -5.61 -5.75 -4.05RBR 2.76 4.48 9.12RBB 2.76 4.48 3.48BRR 10.0 9.34 13.10BRB 10.0 7.25 10.0BBR 10.0 11.0 14.45 ← Optimal policyBBB 10.0 11.0 10.0
Every MDP is guaranteed to have an optimal policy π⋆, such that
∀π ∈ Π,∀s ∈ S : Vπ⋆
(s) ≥ Vπ(s).
Shivaram Kalyanakrishnan (2017) Analysis of Policy Iteration in MDPs 4 / 9

4/9
Optimal Policies
Vπ satisfies a recursive equation: V
π = Rπ + γTπVπ, which gives
Vπ = (I − γTπ)
−1Rπ.
π Vπ(s1) V
π(s2) Vπ(s3)
RRR 4.45 6.55 10.82RRB -5.61 -5.75 -4.05RBR 2.76 4.48 9.12RBB 2.76 4.48 3.48BRR 10.0 9.34 13.10BRB 10.0 7.25 10.0BBR 10.0 11.0 14.45 ← Optimal policyBBB 10.0 11.0 10.0
Every MDP is guaranteed to have an optimal policy π⋆, such that
∀π ∈ Π,∀s ∈ S : Vπ⋆
(s) ≥ Vπ(s).
What is the complexity of computing an optimal policy?
Shivaram Kalyanakrishnan (2017) Analysis of Policy Iteration in MDPs 4 / 9

4/9
Optimal Policies
Vπ satisfies a recursive equation: V
π = Rπ + γTπVπ, which gives
Vπ = (I − γTπ)
−1Rπ.
π Vπ(s1) V
π(s2) Vπ(s3)
RRR 4.45 6.55 10.82RRB -5.61 -5.75 -4.05RBR 2.76 4.48 9.12RBB 2.76 4.48 3.48BRR 10.0 9.34 13.10BRB 10.0 7.25 10.0BBR 10.0 11.0 14.45 ← Optimal policyBBB 10.0 11.0 10.0
Every MDP is guaranteed to have an optimal policy π⋆, such that
∀π ∈ Π,∀s ∈ S : Vπ⋆
(s) ≥ Vπ(s).
What is the complexity of computing an optimal policy?
Note: an MDP with |S| = n states and |A| = k actions has a total of kn policies.
Shivaram Kalyanakrishnan (2017) Analysis of Policy Iteration in MDPs 4 / 9

4/9
Optimal Policies
Vπ satisfies a recursive equation: V
π = Rπ + γTπVπ, which gives
Vπ = (I − γTπ)
−1Rπ.
π Vπ(s1) V
π(s2) Vπ(s3)
RRR 4.45 6.55 10.82RRB -5.61 -5.75 -4.05RBR 2.76 4.48 9.12RBB 2.76 4.48 3.48BRR 10.0 9.34 13.10BRB 10.0 7.25 10.0BBR 10.0 11.0 14.45 ← Optimal policyBBB 10.0 11.0 10.0
Every MDP is guaranteed to have an optimal policy π⋆, such that
∀π ∈ Π,∀s ∈ S : Vπ⋆
(s) ≥ Vπ(s).
What is the complexity of computing an optimal policy?
Note: an MDP with |S| = n states and |A| = k actions has a total of kn policies.
One extra definition needed: Action Value Function Qπ
a for a ∈ A.
Qπ
a = Ra + γTaVπ.
Given π, a polynomial computation yields Vπ and Q
π
a for a ∈ A.
Shivaram Kalyanakrishnan (2017) Analysis of Policy Iteration in MDPs 4 / 9

5/9
Policy Improvement
s s s s s s ss1 2 3 4 5 6 7 8
π
Shivaram Kalyanakrishnan (2017) Analysis of Policy Iteration in MDPs 5 / 9

5/9
Policy Improvement
s s s s s s ss1 2 3 4 5 6 7 8
π
Shivaram Kalyanakrishnan (2017) Analysis of Policy Iteration in MDPs 5 / 9

5/9
Policy Improvement
s s s s s s ss1 2 3 4 5 6 7 8
π
3Q (s ) ππQ (s ) 3
7Q (s ) ππQ (s ) 7
Shivaram Kalyanakrishnan (2017) Analysis of Policy Iteration in MDPs 5 / 9

5/9
Policy Improvement
s s s s s s ss1 2 3 4 5 6 7 8
π
Improvable states
Shivaram Kalyanakrishnan (2017) Analysis of Policy Iteration in MDPs 5 / 9

5/9
Policy Improvement
s s s s s s ss1 2 3 4 5 6 7 8
π
Improvable states
Improving actions
Shivaram Kalyanakrishnan (2017) Analysis of Policy Iteration in MDPs 5 / 9

5/9
Policy Improvement
Given π,
Pick one or more improvable states, and in them,
Switch to an arbitrary improving action.
Let the resulting policy be π′.
s s s s s s ss1 2 3 4 5 6 7 8
π
Improvable states
Improving actions
Shivaram Kalyanakrishnan (2017) Analysis of Policy Iteration in MDPs 5 / 9

5/9
Policy Improvement
Given π,
Pick one or more improvable states, and in them,
Switch to an arbitrary improving action.
Let the resulting policy be π′.
s s s s s s ss1 2 3 4 5 6 7 8
π
s s s s s s ss1 2 3 4 5 6 7 8
π
Policy Improvement
Shivaram Kalyanakrishnan (2017) Analysis of Policy Iteration in MDPs 5 / 9

5/9
Policy Improvement
Given π,
Pick one or more improvable states, and in them,
Switch to an arbitrary improving action.
Let the resulting policy be π′.
s s s s s s ss1 2 3 4 5 6 7 8
π
s s s s s s ss1 2 3 4 5 6 7 8
π
Policy Improvement
Policy Improvement Theorem (H60, B12):
(1) If π has no improvable states, then it is optimal, else
(2) if π′ is obtained as above, then
∀s ∈ S : Vπ′
(s) ≥ Vπ(s) and ∃s ∈ S : V
π′
(s) > Vπ(s).
Shivaram Kalyanakrishnan (2017) Analysis of Policy Iteration in MDPs 5 / 9

5/9
Policy Improvement
Given π,
Pick one or more improvable states, and in them,
Switch to an arbitrary improving action.
Let the resulting policy be π′.
s s s s s s ss1 2 3 4 5 6 7 8
π
s s s s s s ss1 2 3 4 5 6 7 8
π
Policy Improvement
Policy Improvement Theorem (H60, B12):
(1) If π has no improvable states, then it is optimal, else
(2) if π′ is obtained as above, then
∀s ∈ S : Vπ′
(s) ≥ Vπ(s) and ∃s ∈ S : V
π′
(s) > Vπ(s).
Shivaram Kalyanakrishnan (2017) Analysis of Policy Iteration in MDPs 5 / 9

5/9
Policy Improvement
Given π,
Pick one or more improvable states, and in them,
Switch to an arbitrary improving action.
Let the resulting policy be π′.
s s s s s s ss1 2 3 4 5 6 7 8
π
s s s s s s ss1 2 3 4 5 6 7 8
π
Policy Improvement
Policy Improvement Theorem (H60, B12):
(1) If π has no improvable states, then it is optimal, else
(2) if π′ is obtained as above, then
∀s ∈ S : Vπ′
(s) ≥ Vπ(s) and ∃s ∈ S : V
π′
(s) > Vπ(s).
Shivaram Kalyanakrishnan (2017) Analysis of Policy Iteration in MDPs 5 / 9

6/9
Policy Iteration (PI)
π ← Arbitrary policy.
While π has improvable states:
π ← PolicyImprovement(π).
Shivaram Kalyanakrishnan (2017) Analysis of Policy Iteration in MDPs 6 / 9

6/9
Policy Iteration (PI)
π ← Arbitrary policy.
While π has improvable states:
π ← PolicyImprovement(π).
Shivaram Kalyanakrishnan (2017) Analysis of Policy Iteration in MDPs 6 / 9

6/9
Policy Iteration (PI)
π ← Arbitrary policy.
While π has improvable states:
π ← PolicyImprovement(π).
Shivaram Kalyanakrishnan (2017) Analysis of Policy Iteration in MDPs 6 / 9

6/9
Policy Iteration (PI)
π ← Arbitrary policy.
While π has improvable states:
π ← PolicyImprovement(π).
Shivaram Kalyanakrishnan (2017) Analysis of Policy Iteration in MDPs 6 / 9

6/9
Policy Iteration (PI)
π ← Arbitrary policy.
While π has improvable states:
π ← PolicyImprovement(π).
Shivaram Kalyanakrishnan (2017) Analysis of Policy Iteration in MDPs 6 / 9

6/9
Policy Iteration (PI)
π ← Arbitrary policy.
While π has improvable states:
π ← PolicyImprovement(π).
Shivaram Kalyanakrishnan (2017) Analysis of Policy Iteration in MDPs 6 / 9

6/9
Policy Iteration (PI)
π ← Arbitrary policy.
While π has improvable states:
π ← PolicyImprovement(π).
Shivaram Kalyanakrishnan (2017) Analysis of Policy Iteration in MDPs 6 / 9

6/9
Policy Iteration (PI)
π ← Arbitrary policy.
While π has improvable states:
π ← PolicyImprovement(π).
Different switching strategies lead to different routes to the top.
Shivaram Kalyanakrishnan (2017) Analysis of Policy Iteration in MDPs 6 / 9

6/9
Policy Iteration (PI)
π ← Arbitrary policy.
While π has improvable states:
π ← PolicyImprovement(π).
Different switching strategies lead to different routes to the top.
How long are the routes?!
Shivaram Kalyanakrishnan (2017) Analysis of Policy Iteration in MDPs 6 / 9

7/9
Switching Strategies and Bounds
Upper bounds on number of iterations
PI Variant Type k = 2 General k
Howard’s PIDeterministic O
(
2n
n
)
O
(
kn
n
)
[H60, MS99]
Mansour and Singh’sRandomised 1.7172n ≈ O
(
k
2
)n
Randomised PI [MS99]
Shivaram Kalyanakrishnan (2017) Analysis of Policy Iteration in MDPs 7 / 9

7/9
Switching Strategies and Bounds
Upper bounds on number of iterations
PI Variant Type k = 2 General k
Howard’s PIDeterministic O
(
2n
n
)
O
(
kn
n
)
[H60, MS99]
Mansour and Singh’sRandomised 1.7172n ≈ O
(
k
2
)n
Randomised PI [MS99]
Lower bounds on number of iterations
Ω(n) Howard’s PI on n-state, 2-action MDPs [HZ10].
Shivaram Kalyanakrishnan (2017) Analysis of Policy Iteration in MDPs 7 / 9

7/9
Switching Strategies and Bounds
Upper bounds on number of iterations
PI Variant Type k = 2 General k
Howard’s PIDeterministic O
(
2n
n
)
O
(
kn
n
)
[H60, MS99]
Mansour and Singh’sRandomised 1.7172n ≈ O
(
k
2
)n
Randomised PI [MS99]
Lower bounds on number of iterations
Ω(n) Howard’s PI on n-state, 2-action MDPs [HZ10].
Ω(1.4142n) Simple PI on n-state, 2-action MDPs [MC94].
Shivaram Kalyanakrishnan (2017) Analysis of Policy Iteration in MDPs 7 / 9

7/9
Switching Strategies and Bounds
Upper bounds on number of iterations
PI Variant Type k = 2 General k
Howard’s PIDeterministic O
(
2n
n
)
O
(
kn
n
)
[H60, MS99]
Mansour and Singh’sRandomised 1.7172n ≈ O
(
k
2
)n
Randomised PI [MS99]
Batch-switching PIDeterministic 1.6479n
k0.7207n
[KMG16a, GK17]
Recursive Simple PIRandomised – (2 + ln(k − 1))n
[KMG16b]
Lower bounds on number of iterations
Ω(n) Howard’s PI on n-state, 2-action MDPs [HZ10].
Ω(1.4142n) Simple PI on n-state, 2-action MDPs [MC94].
Shivaram Kalyanakrishnan (2017) Analysis of Policy Iteration in MDPs 7 / 9

8/9
Recursive Simple Policy Iteration
s s s s s s ss1 2 3 4 5 6 7 8
π
Shivaram Kalyanakrishnan (2017) Analysis of Policy Iteration in MDPs 8 / 9

8/9
Recursive Simple Policy Iteration
Given π,
Pick the improvable state with the highest index, and,
Switch to an improving action picked uniformly at random.
Let the resulting policy be π′.
s s s s s s ss1 2 3 4 5 6 7 8
π
Shivaram Kalyanakrishnan (2017) Analysis of Policy Iteration in MDPs 8 / 9

8/9
Recursive Simple Policy Iteration
Given π,
Pick the improvable state with the highest index, and,
Switch to an improving action picked uniformly at random.
Let the resulting policy be π′.
s s s s s s ss1 2 3 4 5 6 7 8
π
Shivaram Kalyanakrishnan (2017) Analysis of Policy Iteration in MDPs 8 / 9

8/9
Recursive Simple Policy Iteration
Given π,
Pick the improvable state with the highest index, and,
Switch to an improving action picked uniformly at random.
Let the resulting policy be π′.
s s s s s s ss1 2 3 4 5 6 7 8
π
s s s s s s ss1 2 3 4 5 6 7 8
π
Policy Improvement
Shivaram Kalyanakrishnan (2017) Analysis of Policy Iteration in MDPs 8 / 9

8/9
Recursive Simple Policy Iteration
Given π,
Pick the improvable state with the highest index, and,
Switch to an improving action picked uniformly at random.
Let the resulting policy be π′.
s s s s s s ss1 2 3 4 5 6 7 8
π
s s s s s s ss1 2 3 4 5 6 7 8
π
Policy Improvement
Expected number of iterations: (1+Hk−1)n ≤ (2+ ln(k−1))n.
Shivaram Kalyanakrishnan (2017) Analysis of Policy Iteration in MDPs 8 / 9

8/9
Recursive Simple Policy Iteration
Given π,
Pick the improvable state with the highest index, and,
Switch to an improving action picked uniformly at random.
Let the resulting policy be π′.
s s s s s s ss1 2 3 4 5 6 7 8
π
Expected number of iterations: (1+Hk−1)n ≤ (2+ ln(k−1))n.
Shivaram Kalyanakrishnan (2017) Analysis of Policy Iteration in MDPs 8 / 9

9/9
Conclusion
Policy Iteration: widely used algorithm, more than half a century old.
Substantial gap exists between upper and lower bounds.
We furnish several exponential improvements to upper bounds.
Shivaram Kalyanakrishnan (2017) Analysis of Policy Iteration in MDPs 9 / 9

9/9
Conclusion
Policy Iteration: widely used algorithm, more than half a century old.
Substantial gap exists between upper and lower bounds.
We furnish several exponential improvements to upper bounds.
Bears similarity to Simplex algorithm for Linear Programming.
Howard’s PI works much better in practice than the variants for which we have
shown improved upper bounds!
Open problem: Is the number of iterations taken by Howard’s PI on n-state,
2-action MDPs upper-bounded by the (n + 2)-nd Fibonacci number?
Shivaram Kalyanakrishnan (2017) Analysis of Policy Iteration in MDPs 9 / 9

9/9
Conclusion
Policy Iteration: widely used algorithm, more than half a century old.
Substantial gap exists between upper and lower bounds.
We furnish several exponential improvements to upper bounds.
Bears similarity to Simplex algorithm for Linear Programming.
Howard’s PI works much better in practice than the variants for which we have
shown improved upper bounds!
Open problem: Is the number of iterations taken by Howard’s PI on n-state,
2-action MDPs upper-bounded by the (n + 2)-nd Fibonacci number?
For references see tutorial.
Theoretical Analysis of Policy IterationTutorial at IJCAI 2017https://www.cse.iitb.ac.in/ shivaram/resources/ijcai-2017-tutorial-policyiteration/index.html.
Shivaram Kalyanakrishnan (2017) Analysis of Policy Iteration in MDPs 9 / 9

9/9
Conclusion
Policy Iteration: widely used algorithm, more than half a century old.
Substantial gap exists between upper and lower bounds.
We furnish several exponential improvements to upper bounds.
Bears similarity to Simplex algorithm for Linear Programming.
Howard’s PI works much better in practice than the variants for which we have
shown improved upper bounds!
Open problem: Is the number of iterations taken by Howard’s PI on n-state,
2-action MDPs upper-bounded by the (n + 2)-nd Fibonacci number?
For references see tutorial.
Theoretical Analysis of Policy IterationTutorial at IJCAI 2017https://www.cse.iitb.ac.in/ shivaram/resources/ijcai-2017-tutorial-policyiteration/index.html.
Thank you!
Shivaram Kalyanakrishnan (2017) Analysis of Policy Iteration in MDPs 9 / 9