implementation of string match algorithm bmh on gpu using cuda
DESCRIPTION
Implementation of String Match Algorithm BMH on GPU Using CUDA. Author : Junrui Zhou, Hong An, Xiaomei Li, Min Xu , and Wei Zhou Publisher : ESEP 2011 Presenter: Yu Hao , Tseng Date : 2013/7/31. Outline. Introduction Related Work Implementation on GPU using CUDA - PowerPoint PPT PresentationTRANSCRIPT

Implementation of String Match Algorithm BMH on GPUUsing CUDAAuthor: Junrui Zhou, Hong An, Xiaomei Li, Min Xu, and Wei Zhou Publisher: ESEP 2011Presenter: Yu Hao, TsengDate: 2013/7/31
1

Outline
• Introduction• Related Work• Implementation on GPU using CUDA• Experiment and Result• Conclusion
2

Introduction• The Boyer-Moore-Horspool algorithm was chosen since it
involves sequential accesses to the global memory, which can cut down the overhead of memory access as well as this algorithm is more effective than some other string match algorithm.
• To exploit the performance of applications implemented on GPU, how to use the memory on GPU and transform the structure of the algorithm should be firstly taken into account.
3

Related Work• BMH serial algorithm• Example :
• Pattern : gcagagag• Shift Table :
4
a c g *1 6 2 8

Implementation on GPU using CUDA
• Store Strategy• Text
• The pattern and skip arrays are transferred to constant Memory inside GPU to reduce the access latency.
5

Implementation on GPU using CUDA (Cont.)
• Kernel of BMH algorithm on GPU• SM_size = N / B_num + (M - 1)• T_size = SM_size / B_size + (M – 1)
6

Implementation on GPU using CUDA (Cont.)
• Bank-conflict free solution
7

Implementation on GPU using CUDA (Cont.)
• Global memory access optimization
8
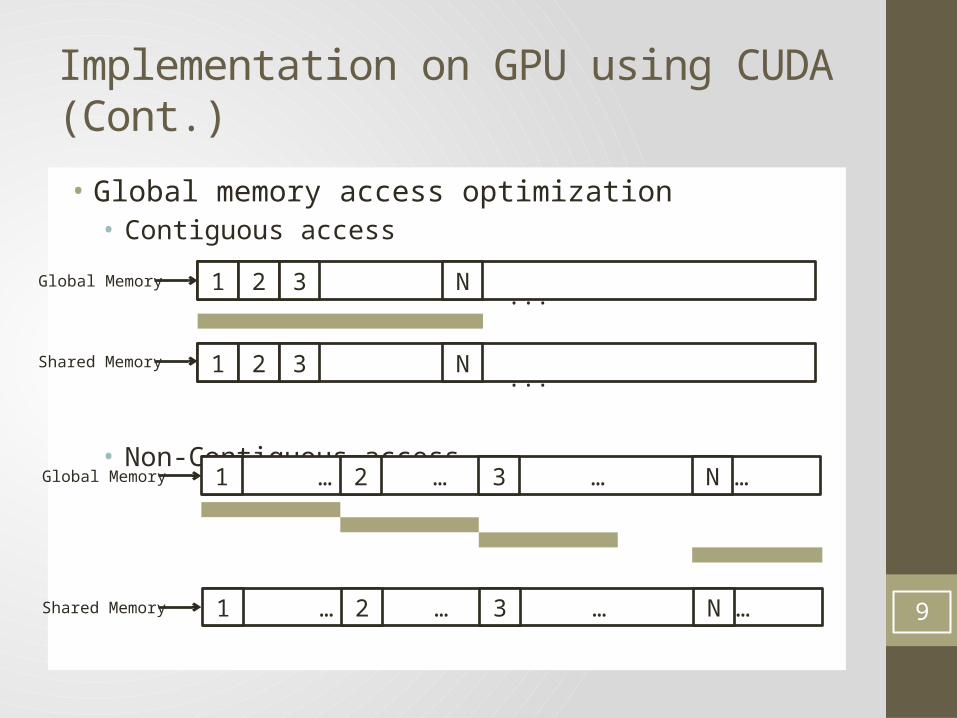
Implementation on GPU using CUDA (Cont.)
• Global memory access optimization• Contiguous access
• Non-Contiguous access
9
...............................................1 2 3 N
...............................................1 2 3 N
Global Memory
Shared Memory
………………………………………………………………………………………1 2 3 NGlobal Memory
Shared Memory…………………………………………………………………
……………………1 2 3 N

Implementation on GPU using CUDA (Cont.)
• Elimination of if-branch in kernel• As we know, the mechanism of GPU processing if-branch is to
execute each thread of one half-warp one by one serially. No doubt that manner cripples the concurrency of the kernel.
10

Experiment and Result
11

Experiment and Result (Cont.)
12

Experiment and Result (Cont.)
13

Experiment and Result (Cont.)
14

Conclusion• The parallel implementation of the algorithms is at least 40
times faster than the serial implementation.• The hardware must be as fully utilized as possible.
15