implementation of different pattern recognition algorithm
TRANSCRIPT

PROJECT ON IMPLEMENTATION OF DIFFERENT PATTERN RECOGNITION ALGORITHM IN
REAL TIME DATA SET
Presented By:Sudipta Pan (M.Tech -CSE ,3 rd semester)
Roll No.:10911213014NETAJI SUBHASH ENGINEERING COLLEGE
2014

WHAT IS PATTERN RECOGNISITION
Given a text string T[0..n-1] and a pattern P[0..m-1], find all occurrences of the pattern within the text.
Example: T = 000010001010001 and P = 0001, the occurrences are:
first occurrence starts at T[1]second occurrence starts at T[5] third occurrence starts at T[11]

WHY I CHOOSE PATTERN RECOGNISITION
APPLICATION :• Image preprocessing· Computer vision· Artificial intelligence· Radar signal classification/analysis· Speech recognition/understanding· Fingerprint identification· Character (letter or number) recognition· Handwriting analysis· Electro-cardiographic signal analysis/understanding· Medical diagnosis· Data mining/reduction

PATTERN RECOGNISITION APPROACH
Statistical Pattern Recognition Syntactic Pattern Recognition Neural Pattern Recognition

Statistical pattern recognition approach
Statistical pattern recognition attempts to classify patterns based on a set of extracted features and an underling statistical model for the generation of these patterns. It assumes a statistical basis for classification of algorithms.For e.g:Speech Recognition

Syntactic pattern recognition approach
The principle behind this approach is that many times the interrelationships or interconnections of features yield important structural information, which facilitates structural description or classification. Therefore, in these approaches we must be able to quantify and extract structural information and to assess structural similarity of patterns.For e.g. Recognizing areas such as highways,rivers,and bridges in satellite pictures.

Neural pattern recognition approach
This approach makes use of the knowledge of how biological neural systems store and manipulate information. They are particularly well suited for pattern association applications. Artificial neural networks (ANNs) provide an emerging paradigm for pattern recognition implementation that involves large interconnected networks of relatively simple and typically nonlinear units so called neural-nets. For e.g. Back propagation ,high-order nets,time –delay neural networks and recurrent nets.

ALGORITHM DESCRIPTION The Knuth-Morris-Pratt (KMP) algorithm:
It was published by Donald E. Knuth, James H.Morris and Vaughan R. Pratt, 1977 in: “Fast Pattern Matching in Strings.“To illustrate the ideas of the algorithm, consider the following example:T = xyxxyxyxyyxyxyxyyxyxyxxy And P = xyxyyxyxyxxit considers shifts in order from 1 to n-m, and determines if the pattern matches at that shift. The difference is that the KMP algorithm uses information gleaned from partial matches of the pattern and text to skip over shifts that are guaranteed not to result in a match.

KMP Algorithm cont…..
The text and pattern are included in Figure 1, with numbering, to make it easier to follow.1.Consider the situation when P[1……3] is successfully matched with T[1……..3]. We then find a mismatch: P[4] = T[4]. Based on our knowledge that P[1…… 3] =T[1…… 3], and ignoring symbols of the pattern and text after position 3, what can we deduce about where a potential match might be? In this case, the algorithm slides the pattern 2 positions to the right so that P[1] is lined up with T[3]. The next comparison is between P[2] and T[4].

P: x y x y y x y x y x xq: 1 2 3 4 5 6 7 8 9 10 11_(q): 0 0 1 2 0 3 Table 1: Table of values for pattern P.Time Complexity :
The call to compute prefix is O(m)using q as the value of the potential function, we argue in the same manner as above to show the loop is O(n)Therefore the overall complexity is O(m + n)

Boyer-Moore algorithm: It was developed by Bob Boyer and J Strother Moore in 1977. The algorithm preprocesses the pattern string that is being searched in text string.

Stringpattern matching - Boyer-Moore
This algorithm uses fail-functions to shift the pattern efficiently. Boyer-Moore starts however at the end of the pattern, which can result in larger shifts.Two heuristics are used:1: if we encounter a mismatch at character c in Q, we can shift to the first occurrence of c in P from the right:Q a b c a b c d g a b c e a b c d a c e d
P a b c e b c d a b c e b c d
(restart here)

Time Complexity:
•performs the comparisons from right to left;•preprocessing phase in O(m+ ) time and space complexity;•searching phase in O(mn) time complexity; •O(n / m) best performance

Rabin-Karp ALGORITHM
The Rabin –Karp algorithm searches for a pattern in a text by hashing. So we preprocess p by computing its hashcode, then compare that hash code to the hash code of each substring in t. If we find a match in the hash codes, we go ahead and check to make sure the strings actually match (in case of collisions).

Concept of Rabin Karp Algorithm
The Rabin-Karp string searching algorithm calculates a hash value for the pattern, and for each M-character subsequence of text to be compared.If the hash values are unequal, the algorithm will calculate the hash value for next M-character sequence. If the hash values are equal, the algorithm will compare the pattern and the M-character sequence.In this way, there is only one comparison per text subsequence, and character matching is only needed when hash values match.
Time Complexity:Running time for Rabin Karp algorithm is O(mn)in theworst case, since the Rabin Karp algorithm explicitly verifies everyvalid shift.

The NAÏVE STRING MATCHING ALGORITHM
The naive algorithm finds all valid shifts using a loop that checks the condition P[1……m]=T[s+1….s+m] for each of the n-m+1 possible values of s.NAÏVE-STRING-matCher(T,P) 1.n=T.length2.m=P.length3.for s=0 to n-m4. if P[1……m]==T[s+1….s+m]5. print “Pattern occurs with shift” s

NAÏVE STRING MATCHING ALGORITHM CONT…..Below figure portrays the naive string-matching procedure as “template” containing the pattern over the text,noting for which shifts all of the characters on the template equal the corresponding characters in the text. The for loop of lines 3-5 considers each possible shift explicitly.The text in line 4 determines whether the current shift is valid; this test implicitly loops to check corresponding character positions until all positions match successfully or a mismatch is found.Line 5 prints out each valid shift s.
Time Complexity: 1. The overall complexity is O(mn)

Brute-Force String Matching A brute force algorithm for string matching problem has
two inputs to be considered: pattern (a string of m characters to search for), and text (a long string of n characters to search in). Algorithm starts with aligning a pattern at the beginning of text. Then each character of a pattern is compared to the corresponding character, moving from left to right, until all characters are found to match, or a mismatch is detected. While the pattern is not found and the text is not yet exhausted, a pattern is realigned to one position to the right and again compared to the corresponding character, moving from left to right.
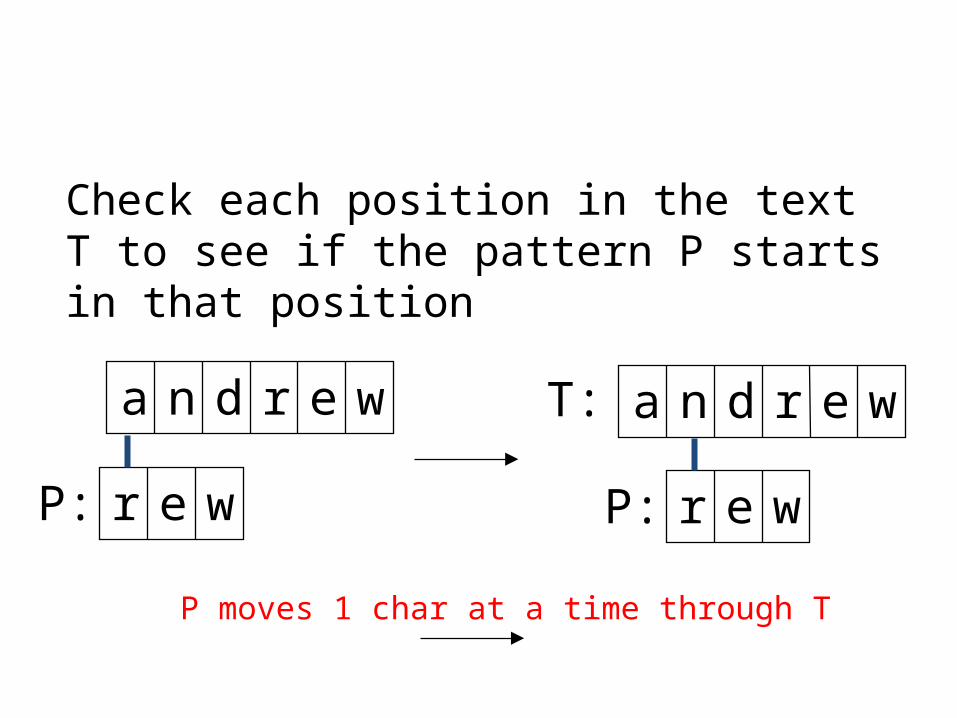
Check each position in the text T to see if the pattern P starts in that position
a n d r e w
r e wP:
a n d r e wT:
r e wP:
P moves 1 char at a time through T

Brute Force Pseudo-Code:doif(text letter==pattern letter)compare next letter of pattern to next letter of textelsemove pattern down text by one letterwhile(entire pattern found or end of text)
AnalysisBrute force pattern matching runs in time O(mn) in the worst case.But most searches of ordinary text take O(m+n), which is very quick.
SCREEN SHOTS:

FUTURE SCOPEI have try to improve the complexity of different algorithms.From above five algorithms are consider and I will try to develop a new algorithm.I want to research in biometrics identification using a fingerprint or face image or a recorded voice and others. Using this features can be identify a person, first a feature set are extracted from the image or the audio, then are compare with an stored feature set, some algorithms and process are well known to made this task

REFERENCES 1 .Fu, K. S. (King Sun), 1930- “Syntactic pattern recognitionand applications”
Englewood Cliffs, N.J. : Prentice-Hall,c19822.Schalkoff, Robert J, “Pattern recognition : statistical,structural, and neural approaches” New York : J. Wiley,c1992 Journals:Journal of Pattern Recognition Society.IEEE transactions on Neural Networks.Pattern Recognition and Machine Learning.Books:Duda, Heart: Pattern Classification and Scene Analysis. J. Wiley & Sons, New York, 1982. (2nd edition 2000).3.H. F. Ebel, C. Bliefert, and W. E. Russey, The Art of Scientific Writing: From Student Reports to Professional Publications in Chemistry and Related Fields. Weinheim: Wiley-VCH Verlag GmbH &Co. KGaA, 2004.
4.F. M. Lastname. (2006, January). Formatting papers for Journal of Pattern Recognition Research.Journal of Pattern Recognition Research [Online]. 1(1). pp. 1-3. Available: http://www.jprr.org

THANK YOU