ibm power systems platform: advancements in the state … · ibm power systems platform:...
TRANSCRIPT

IBM Power Systemsplatform: Advancementsin the state of the art inIT availability
&
G. T. McLaughlin
L. Y. Liu
D. J. DeGroff
K. W. Fleck
This paper surveys the current state of information technology (IT) availability on the
IBM System p5t server platform, then describes how selected hardware and software
features of the next-generation IBM Powere Systems platform (by which we
specifically mean IBM POWER6e processor-based systems running the IBM AIXt 6
operating system) will enable client IT organizations to more closely approach true
continuous availability. Also presented is information on several IT management
disciplines that are critical to achieving high levels of availability. The objective is to
enable accelerated adoption and success with the new Power Systems platform by
explaining how the technologies can be used to improve IT availability. We define the
underlying dependencies required to implement the new live partition mobility and
the live application mobility features and show how the environment can be best
designed for planned maintenance. Until now, the concept of server virtualization in
the UNIXt environment has been limited to a single server, but the Power Systems
platform extends the virtualization realm. A brief discussion is given comparing
software clustering with the new mobility features and illustrating how they are
complementary.
INTRODUCTION
Many IBM clients have come to rely on the IBM
System p5* platform (servers based on IBM
POWER5* or POWER5þ* processor technology) to
run their key business functions. Its performance,
reliability, and leadership in virtualization make it a
compelling choice. In addition, there is a rich library
of commercially available software from which to
choose. Properly designed infrastructures based on
the System p5 platform are generally capable of
meeting stated availability requirements. However,
clients often struggle with meeting maintenance
demands given constrained IT budgets and changing
availability requirements; as availability needs
�Copyright 2008 by International Business Machines Corporation. Copying inprinted form for private use is permitted without payment of royalty providedthat (1) each reproduction is done without alteration and (2) the Journalreference and IBM copyright notice are included on the first page. The titleand abstract, but no other portions, of this paper may be copied or distributedroyalty free without further permission by computer-based and otherinformation-service systems. Permission to republish any other portion of thepaper must be obtained from the Editor. 0018-8670/08/$5.00 � 2008 IBM
IBM SYSTEMS JOURNAL, VOL 47, NO 4, 2008 MCLAUGHLIN ET AL. 519

increase, so does the importance of properly
maintaining all infrastructure components. While
the current System p5 platform provides capabilities
to mitigate the impact of planned outages on
information technology (IT) availability, it is evident
that these measures are still too disruptive in cases
where availability requirements are very stringent.
The next-generation IBM System p* platform is built
on IBM POWER6* processor hardware and the IBM
AIX* 6 operating system (referred to herein as the
IBM Power* Systems platform) and addresses the
need for nondisruptive maintenance capabilities.
The Power Systems platform provides new work-
load mobility features and numerous hardware and
operating system (OS) resiliency improvements,
allowing planned and emergency maintenance
actions to be completed at any time rather than
having to be scheduled at times of low use, such as
nights and weekends. These new features comple-
ment existing high-availability (HA) technologies to
advance the state of the art in IT availability.
SETTING THE STAGE
It is useful to briefly describe some key concepts as a
prelude to examining the availability characteristics
of the System p5 and Power Systems platforms.
Assessments done by the IBM High Availability
Center of Competency (HACoC) show that base
hardware, OS technologies, and environmental
factors—areas that are traditionally the focus of
availability solutions—account for only about 20
percent of the total unplanned downtime; operations
(process) and applications are responsible for the
remaining 80 percent. In addition, when considering
strategies to maximize availability, we have found
that planned downtime is often overlooked.
As a rule, it is better to design in availability from
the start than to try to retrofit it. Consider the end-to-
end logical view of a typical infrastructure (Figure 1).
For a business to achieve its availability goals, it is
critical to view the system not only with the
traditional component-focused view, but from an
end user’s perspective, by asking, ‘‘What are the
business objectives that drive availability require-
ments?’’ To answer this question, it is necessary to
quantify the costs of an outage and to understand
the capabilities and limitations of current technolo-
gy. If the availability goal is near-continuous
availability, then it must be possible to remove any
infrastructure component without affecting service
delivery; in short, all single points of failure must be
eliminated.
The IT Infrastructure Library*** (ITIL****) v3
Services Design volume defines the term Single
Point of Failure (SPoF) as follows: Any Configura-
tion Item that can cause an Incident when it fails,
and for which a Countermeasure has not been
implemented. A SPoF may be a person, or a step in a
Process or Activity, as well as a Component of the IT
Infrastructure. To that, the IBM HACoC team has
added an informal definition of the term ‘‘counter-
measure’’: An action or solution that will mitigate
the impact of the failure of a Configuration Item to
meet the stated availability goals.
Some of the key terms used throughout this paper
are defined as follows:
� High availability (HA): The attribute of a system to
provide service during defined periods at accept-
able or agreed-upon levels and to mask unplanned
outages from end users� Continuous operations (CO): The attribute of a
system to continuously operate and mask planned
outages from end users� Continuous availability (CA): The attribute of a
system to deliver nondisruptive service to the end
user seven days a week, 24 hours a day (no
planned or unplanned outages)
The relationship of these three terms can be stated
informally as: CA ¼ CO þ HA.
In general, reducing data loss costs more, so an
appropriate trade-off must be made to achieve the
availability goals of the business within budgetary
constraints. Similarly, shorter recovery times are
more costly. Recovery time considerations include
fault detection, network and data recovery, and the
bringing online of servers, middleware, and appli-
cations. The desired point in time by which data
must be restored in order to resume transaction
processing is called the recovery point objective
(RPO). The desired length of time required to restore
IT services following a disruptive event is called the
recovery time objective (RTO).
AVAILABILITY LANDSCAPE
In this section, we review some key features of
System p5 servers, server clustering technologies,
and data mirroring technologies. While applications
MCLAUGHLIN ET AL. IBM SYSTEMS JOURNAL, VOL 47, NO 4, 2008520

and networking are also important contributing
factors to achieving business availability goals, our
focus is on the base infrastructure. We then briefly
cover two load-balancing options and conclude with
a summary of HA configurations.
Virtualization and clustering
Through virtualization and capacity management
features, System p5 servers provide benefits that
help clients efficiently achieve their availability
targets. Detailed information on such features as
logical partitioning, dynamic logical partitioning,
cluster systems management, network installation
management, hardware management console, vir-
tual Ethernet, virtual I/O server, and integrated
virtualization manager is given in References 1 and 2.
The System p5 platform also offers capacity on
demand (CoD) capabilities.3
CoD can be included in
cluster takeover design and capacity, and it helps
address the old complaint that IT availability is
achieved by buying two of everything, with no easy
way to utilize the excess capacity.
One of the characteristics of the System p5 platform
is that there are generally several options to address
any need, including HA clustering. In this section,
we briefly describe IBM PowerHA Cluster Manager
(HACMP*) software,4
IBM Tivoli* System Automa-
tion for Multiplatforms5
(SA MP), and Symantec
Veritas** Cluster Server (VCS) products. These
technologies reduce the duration of an outage with
automated, fast recovery.
HACMP software first shipped in 1991, and it is
recognized as a robust, mature HA clustering
solution. It is also a powerful tool for testing,
maintenance, and monitoring hardware, networks,
and applications. Reference 6 describes best prac-
tices for HA cluster design and also testing,
Managedcontent
Web servicesdirectory
ClientsPresentation services
Application servicesResource managers
Loadbalancer
Gatewayservices
Pervasivedevice
Transcoder
Internet
Browser
Third-partysystems orservices
Public or private networks
Reverseproxyserver
Web server
Contentdelivery
Webapplicationservices
Applicationlogic
Contentmanagement
Directory and security services
Applicationdatabaseservices
Applicationdata
Integrationhub
Packagedsolutions
Customerrelationshipmanagement
Legacyapplications
Enterprisedatabases
Universal layer
Enterprise system management
Enterprise security management
Devicegateway
Userprofiles
Staticcontent
Figure 1Example of a typical IT infrastructure
IBM SYSTEMS JOURNAL, VOL 47, NO 4, 2008 MCLAUGHLIN ET AL. 521

maintenance, and monitoring in a virtualized world.
Reference 7 covers various clustering options, HA
design considerations for application availability,
and best practices for testing and maintenance.
HACMP software is particularly recommended in
environments that are standardized on AIX.
In the most recent release, which was generally
available in June 2008, the end-to-end component
was separated to become its own product, the
System Automation Application Manager (SA AM).
The base component was renamed System Auto-
mation for Multiplatforms (SA MP). SA MP provides
the capability to manage the availability of applica-
tions running on Microsoft Windows**, AIX, and
Linux** on IBM and non-IBM platforms. SA AM
manages different clustering technologies and pro-
vides a single point of control and management for
heterogeneous mixes of various clustering technol-
ogies, such as HACMP, SA MP base, VCS, SA z/OS*,
and Microsoft Cluster Server (MCS). More details
are available in Reference 8.
VCS is an original equipment manufacturer HA
cluster software product that supports the following
platforms: Sun Microsystems Solaris**, AIX, HP-UX,
Linux (Red Hat or Novell SUSE Linux Enterprise),
and Windows. Details of the Veritas Foundation
Suite for AIX are available in Reference 9.
Data availability
Ensuring data availability is a significant component
of an overall availability strategy. This section
briefly describes several options that are used in IT
infrastructures based on System p servers. Please
consult the references for further details for data and
database mirroring.
The geographic logical volume manager (GLVM) is a
component of AIX that provides real-time geo-
graphic data mirroring over standard TCP/IP
(Transmission Control Protocol/Internet Protocol)
networks. It is built upon the AIX logical volume
manager (LVM) and allows the creation of a mirror
copy of critical data at a geographically distant
location.10
The HACMP extended distance (XD)
feature provides integration of GLVM into an
HACMP cluster environment. If the server cluster
nodes are within approximately 2 to 4 km, then LVM
is a viable solution; otherwise, GLVM should be
considered.
The business continuity (BC) solutions in the IBM
portfolio of system storage resiliency technologies
have been segmented to meet client RPO and RTO
objectives for System p environments with HACMP/
XD. Information on the seven tiers of BC (a mapping
of recovery costs compared with recovery time
objectives) and more details on Metro Mirror (MM)
and Global Mirror (GM) solutions (and Metro Global
Mirror, a combination of the two) can be found in
References 11 and 12. Additional comprehensive
storage solutions can be found in Reference 13. The
MM solution is synchronous and is the preferred
solution when data centers are within approxi-
mately 100 km of one another. MM can be used for
both HA and disaster recovery (DR) purposes. The
GM solution is asynchronous and can be used
between data centers that are separated by long
distances, making it the preferred DR solution.
As its name implies, IBM DB2* HADR can be used
for both HA and DR (when configured in an HA
cluster environment) and provides three data
mirroring modes: synchronous, near synchronous,
or asynchronous. It is an effective solution to mirror
critical DB2 databases. More detailed information,
advantages, and limitations are available in Refer-
ences 12 and 14.
The use of Oracle database products is popular on
the System p platform. The Oracle Real Application
Clusters (RAC) product is a good solution for
clustering database servers with data-sharing capa-
bility. Recommendations and samples of how to
implement an Oracle 9i RAC database with IBM
General Parallel File System* (GPFS*) are available
in Reference 15. Reference 16 provides an overview
of the Oracle Maximum Availability Architecture.
Figure 2 shows how cluster configurations can be
altered to address data availability requirements
over various distances. It is also possible to mix
configurations to create a multisite solution, for
instance, combining MM with GM. Because of the
parallel resources, a multisite solution increases
availability beyond the combined availability of a
one-site infrastructure.
LVM and GLVM are less expensive solutions, but
they use some server CPU cycles because they are
OS-level functions. With its different synchroniza-
tion modes, DB2 HADR could be used for database
mirroring in all cluster configurations.
MCLAUGHLIN ET AL. IBM SYSTEMS JOURNAL, VOL 47, NO 4, 2008522

Load balancing and cluster configuration optionsHA clustering does not completely eliminate outag-
es, but instead reduces the impact of an outage. If
the goal is near-continuous availability, consider
load-balancing options if the costs of an outage
justify the additional investment.
The IBM brand image hinges heavily on the
performance and availability of its complex Web
site. It is a three-site global server load-balancing
implementation that eliminates traditional mainte-
nance windows. All three sites are identical, active
sites with POWER processor-based servers. This
solution is ideal for Web applications with minimal
back-end data synchronization or stateless applica-
tions that do not require any back-end data
synchronization.
Figure 3 shows another load-balancing solution
implemented using the container architecture, in
which a container is an implementation of a
particular function. The interfaces to container 1 and
container 2 are identical, as are the functions for the
two containers, but the implementation of each
container could be in different physical configura-
tions. The front end requires a hardware or software
workload dispatcher, while data synchronization is
accomplished through IBM MQSeries* middleware.
Because the client sessions are not sticky state
(stateless), container load balancing is possible for
both inbound and outbound traffic. This solution
could be implemented in the same server, within the
same data center, or among multiple data centers
(two or more sites) at various distances. The
benefits of this solution include increased availabil-
ity with additional redundancy, easier introduction
of new technologies and applications, less-risky
platform migrations, easy performance testing, and
DR capability.
Having briefly surveyed various server clustering
products, data mirroring options, and load-balanc-
ing solutions, we turn to considering some sample
cluster implementations drawn from real-life client
case studies. Any option that is chosen must take
into consideration the availability goals of the
business, the IT budget, and the applications.
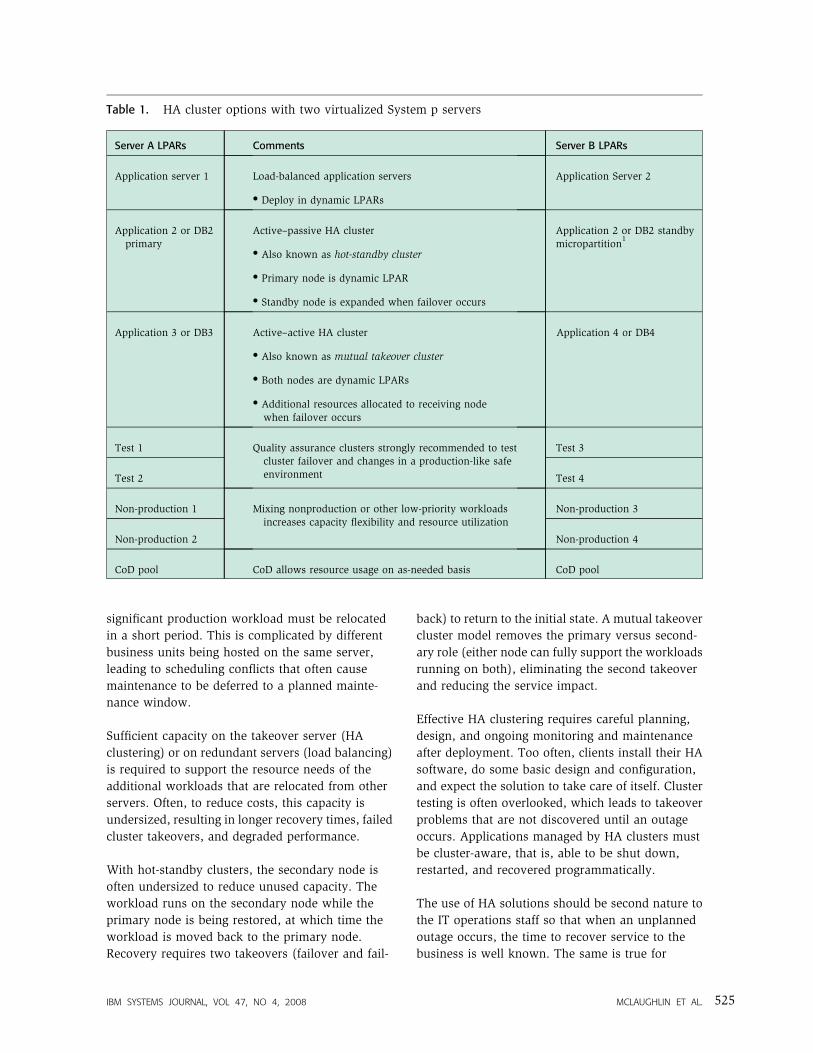
Table 1 illustrates several HA cluster configuration
2 km
Site A Site BCampus clusterLocal cluster
Remote cluster
100 km
Site A Site B Global cluster
1000 km
Site A Site B
Asynchronousreplication
Synchronousreplication
O/S mirroring
Figure 2Clustering and data replication scenarios
IBM SYSTEMS JOURNAL, VOL 47, NO 4, 2008 MCLAUGHLIN ET AL. 523

options that can be used effectively in servers with
logical partitions (LPARs). Indeed, the recommend-
ed practice is to deploy different cluster types based
on specific processing needs. The integration of HA
clustering with virtualization (particularly dynamic
resource management) allows the achievement of
HA while efficiently utilizing server resources.
WHY IS IMPROVING IT AVAILABILITY DIFFICULT?
Protecting the business from unplanned outages is
only part of the CA equation. Even if hardware and
software never failed, the changes in an IT
environment would still need to be managed.
Change is driven by many causes, including
business growth, evolving requirements, and soft-
ware and hardware life cycles. The infrastructure
must be able to tolerate changes without disruption
to the users.
A proactive maintenance strategy is an obvious way
to manage planned change and reduce the risk of
outages due to defects for which fixes are already
available. Change is constant, and clients who
achieve very high levels of IT availability have
designed infrastructures, supported by effective
management practices, that can tolerate change.
Options exist today to manage service availability
during planned maintenance actions, including
concurrent maintenance features, rolling upgrades
enabled by clustering, and application load balanc-
ing. Yet many clients are still unable to consistently
make changes nondisruptively, so they hesitate to
make changes, even when they are urgently needed.
In order to save money, many clients consolidate
workloads onto a few large servers. If a planned or
unplanned outage occurs on a consolidated server,
Applicationgateways
Applicationgateways
Shared applicationservices
Shared data services
Internet banking environment
Container 1 Container 2
Data center network equipment
Internet
Gen
eral
man
agem
ent s
ervi
ces
R ele
ase
man
agem
ent e
nviro
nmen
t
Inte
rnet
ban
king
man
agem
ent s
ervi
ces
IBM WebSphere*
External applications
Token servers Registrations Filenet Mainframe
Internet banking application servers
Web servers
Internet banking application servers
Web servers
Shared security authorization services
Figure 3Logical design of a container load-balancing solution
MCLAUGHLIN ET AL. IBM SYSTEMS JOURNAL, VOL 47, NO 4, 2008524
significant production workload must be relocated
in a short period. This is complicated by different
business units being hosted on the same server,
leading to scheduling conflicts that often cause
maintenance to be deferred to a planned mainte-
nance window.
Sufficient capacity on the takeover server (HA
clustering) or on redundant servers (load balancing)
is required to support the resource needs of the
additional workloads that are relocated from other
servers. Often, to reduce costs, this capacity is
undersized, resulting in longer recovery times, failed
cluster takeovers, and degraded performance.
With hot-standby clusters, the secondary node is
often undersized to reduce unused capacity. The
workload runs on the secondary node while the
primary node is being restored, at which time the
workload is moved back to the primary node.
Recovery requires two takeovers (failover and fail-
back) to return to the initial state. A mutual takeover
cluster model removes the primary versus second-
ary role (either node can fully support the workloads
running on both), eliminating the second takeover
and reducing the service impact.
Effective HA clustering requires careful planning,
design, and ongoing monitoring and maintenance
after deployment. Too often, clients install their HA
software, do some basic design and configuration,
and expect the solution to take care of itself. Cluster
testing is often overlooked, which leads to takeover
problems that are not discovered until an outage
occurs. Applications managed by HA clusters must
be cluster-aware, that is, able to be shut down,
restarted, and recovered programmatically.
The use of HA solutions should be second nature to
the IT operations staff so that when an unplanned
outage occurs, the time to recover service to the
business is well known. The same is true for
Table 1. HA cluster options with two virtualized System p servers
Server A LPARs Comments Server B LPARs
Application server 1 Load-balanced application servers Application Server 2
� Deploy in dynamic LPARs
Application 2 or DB2primary
Active–passive HA cluster Application 2 or DB2 standbymicropartition
1
� Also known as hot-standby cluster
� Primary node is dynamic LPAR
� Standby node is expanded when failover occurs
Application 3 or DB3 Active–active HA cluster Application 4 or DB4
� Also known as mutual takeover cluster
� Both nodes are dynamic LPARs
� Additional resources allocated to receiving nodewhen failover occurs
Test 1 Quality assurance clusters strongly recommended to testcluster failover and changes in a production-like safeenvironment
Test 3
Test 2 Test 4
Non-production 1 Mixing nonproduction or other low-priority workloadsincreases capacity flexibility and resource utilization
Non-production 3
Non-production 2 Non-production 4
CoD pool CoD allows resource usage on as-needed basis CoD pool
IBM SYSTEMS JOURNAL, VOL 47, NO 4, 2008 MCLAUGHLIN ET AL. 525

planned outages; migrating workload to another
system should be a documented, tested procedure so
that the decision to act can be made confidently and
based on business needs.
POWER SYSTEMS PLATFORM RESHAPES THEAVAILABILITY LANDSCAPE
Any HA solution that mitigates the impact of
unplanned outages by shutting down resources on
the failing node and restarting them on the backup
node typically demonstrates an observable service
interruption. Still, this approach is typically faster
than manually recovering the failed component.
Many clients have also adopted HA clustering as a
planned maintenance tool, yet they find that the
small service interruptions caused by the takeover
process are still too disruptive. These clients would
undoubtedly welcome a solution that would allow
them to perform maintenance actions nondisrup-
tively.
The new features described below advance the
capability of the Power Systems platform to help
eliminate outages for planned maintenance or
administrative changes. The philosophy behind
these features represents a fundamental shift in
thinking toward availability. When an operation can
be performed dynamically, with no service inter-
ruption, it becomes possible to take proactive
actions to avoid problems as soon as the need is
identified.
Live partition mobility
Live partition mobility (LPM) is the ability to
logically move an active partition between Power
Systems servers. This technology builds upon the
virtualization capability of the IBM POWER Hyper-
visor*17
and allows movement of both AIX- and
Linux-based workloads. Mobile partitions provide
additional capability for workload capacity and
energy management in the IT infrastructure.
Virtual partition memory, the processor compati-
bility register, and processor time-base adjustment
facilities are the key POWER6 processor enhance-
ments that make LPM possible.18
These technolo-
gies are necessary to ensure that the OS and
applications are able to function seamlessly after a
live migration to a different managed system.
When migrating the processor and memory states of
active partitions between different physical systems,
two key challenges are ensuring that there is
adequate capacity (so that the partition definition
can run on the target system) and limiting the time
required to move processing from the source to the
target system (so that no outage is perceived by the
user).19
LPM works by virtualizing all storage and network
resources through a virtual I/O (VIO) server so that
they are accessible on the source and target Power
Systems servers. When a migration is requested, the
hardware management console (HMC) validates
that the target system is capable and the LPAR is in a
proper state for migration. It then creates an
identical partition definition on the target system
and copies the current memory state to the target
partition. As copied memory pages are again
changed on the source, they are tracked to be resent,
and once the memory state is copied and the system
has determined it is ready to perform the switch,
processing is stopped and the processing state
copied and started on the target system. Remaining
dirty memory pages are resent and destination faults
on empty pages are given copy priority. Once the
remaining memory pages are sent to the target, the
migration is complete.20
The only potential inter-
ruption is during the processing steps of the
migration: stop, copy state, and start. This interval
should be short enough to be observable, at most, as
a slight pause during runtime. This slight pause does
not impact the running partition.
There are several planning requirements to enabling
LPM:20
� Systems must be managed by the same HMC� Adequate resources must exist on the target
managed system� All storage is virtualized on an external storage
area network (SAN)� No physical adapters can be used by the mobile
partition� All network and disk access must be virtualized
through VIO servers� Each Shared Ethernet Adapter (SEA) on both VIO
servers is configured to bridge to the same
Ethernet network
Given the virtualized storage requirement, it is not
surprising that the mobile partition cannot own any
physical adapters, as they would not be available on
the target system. Tape and optical drives may also
MCLAUGHLIN ET AL. IBM SYSTEMS JOURNAL, VOL 47, NO 4, 2008526

be virtualized through VIO servers; however, if
physical tape or optical drives are required for
backup operations, the I/O controllers may be added
to the partition and removed prior to migration
using dynamic LPARs. Inactive migrations (or non-
live partition migrations) may be performed on
partitions that own physical I/O. The hardware must
then be verified or removed from the partition
profile prior to partition activation on the target
managed system.20
The VIO server virtualizes both disk and network
resources for use by LPARs and allows an identical
configuration to be created on the target managed
system during a partition migration. In addition to
the general storage virtualization requirements, the
root file system (rootvg) must also be accessed
through the VIO server storage that resides on the
SAN.
The new integrated virtual Ethernet adapter (i.e., the
host Ethernet adapter) is a physical Ethernet port on
the managed system that can be virtualized up to 32
partitions. These ports, while virtualized, are
considered to be physical I/O and cannot be
assigned to mobile partitions.
Partition mobility depends on the storage subsystem
being accessible from both the source and target
systems. These considerations are outside the scope
of this paper; however, it is extremely important
that care and planning must be applied to the design
of the storage infrastructure to protect against
service outages.
Reference 21 provides additional details on deploy-
ing a resilient VIO server configuration that utilizes
SEA takeover, link aggregation, mutipathing I/O,
and dual VIO servers.
Live application mobility
Workload partitions (WPARs) allow the logical
separation of workloads into virtualized partitions
within the AIX OS. The application runtime envi-
ronment is virtualized and is moveable between
other AIX partitions. This enhances the ability to
handle dynamic workloads, capacity management,
and other planned outages. WPARs are a function of
AIX 6 and can be created on any server supported by
this OS. In most cases, applications can run
unmodified in WPARs. LPARs supporting WPARs
may use shared or dedicated processors that will
then be virtualized to the supported WPARs. Live
application mobility (LAM) is the term used to
describe the movement of applications running in
WPARs between managed systems.
Like LPM, LAM does not protect the application
from unplanned outages. Instead, it facilitates
nondisruptive, planned workload relocations. Un-
like LPM, there is no requirement for the systems to
be managed by the same HMC or for the resources
to be virtualized through a VIO server.
The global environment is similar to the main
operating environment of earlier versions of AIX. It
is the part of AIX that owns all resources and does
not belong to the WPAR and it is where WPARs are
managed (WPARs cannot be managed from within a
WPAR). The global environment shares its allotted
system resources, such as processors, memory, and
file systems, with the defined WPARs. Capacity caps
on processor and memory utilization can be defined.
Because each WPAR runs in the global environ-
ment, they share the same OS environment. This
simplifies OS and application software maintenance,
but care is needed to ensure that all applications
deployed and running in separate WPARs under a
single AIX global environment are capable of
running at the same AIX level.
The capacity of all resources assigned to the global
environment, either dedicated or virtualized, needs
to be carefully planned and managed in order to
accommodate active WPARs and the potential
relocation of workload through LAM. For example, a
single Ethernet interface on the global environment
can be virtualized to WPARs, each with its own
unique IP address through IP aliases, but the
networking configuration can be changed only from
the global environment. Since a single adapter can
be shared by many WPARs, there may be a need to
balance WPARs across multiple adapters. The
WPARs can access storage only through file systems
defined in the global environment. WPARs cannot
access or be assigned physical or virtual disks.
There are two types of WPARs, each having
different operating characteristics that are important
to understand. A system workload partition (SWP)
is a near fully capable AIX operating environment
with its own /, /usr, /opt, /var, /tmp, and /home
file systems as well as init and all attendant
services (/usr and /opt can optionally be shared
IBM SYSTEMS JOURNAL, VOL 47, NO 4, 2008 MCLAUGHLIN ET AL. 527

from the global environment). It is a near clone of
the global environment. When an SWP is started, an
init process is created and subsequent services are
spawned. The SWP can have its own network
environment including inetd service. An applica-
tion workload partition (AWP) is more lightweight
and transient; it is started as soon as the application
is started and is removed when the application
stops. An AWP is started by running the wparexec
command and passing the application start com-
mand as an argument. Once the application task
passed to wparexec completes, the AWP is termi-
nated as well.
The new AIX 6 Workload Partitions Manager*
(WPM) provides a central point of management for
creating, changing, and controlling WPARs across
any number of servers and global environments.22
It
is the point of control for initiating manual WPAR
mobility operations and for setting up automated
WPAR mobility. Based on predefined policies, a
WPAR group can be defined that will relocate
WPARs across multiple servers to meet peak
demands and then return to the original configura-
tion when the peak subsides. This is useful for
managing daily workload peaks or end-of-month
processing needs.
LAM works by checkpointing the application and
restarting it on another LPAR running AIX. This is
coordinated by the WPM or by running commands
directly on the source and target global environment
AIX instances. Since the WPM has a cross-system
view, it can provide performance details on all
active WPARs. Checkpoint and restart are the key
operations for LPM and can be used to balance
workload by initiating a checkpoint and kill opera-
tion followed by a restart operation at a later time.
Complementary technologies for workload
relocation
Clients will often shut down a workload during a
maintenance window rather than use a workload
relocation mechanism because they lack automation
or because of application characteristics. As avail-
ability requirements continue to rise, this practice is
becoming inadequate. Without the ability to relocate
workloads during a planned outage, clients often
choose to delay or even skip software maintenance.
This practice exposes them to unplanned outages
due to missing service updates. LPM and LAM both
provide dynamic workload relocation capability to
help alleviate this problem.
In a typical HA cluster solution, workload relocation
requires that resources, such as the application, IP
service address, storage, and file systems, be shut
down on one cluster node and then reactivated on
an alternate node. The steps to accomplish this are
automated through the clustering framework once a
resource group takeover is initiated. The end-to-end
process can take several minutes or longer, de-
pending on the amount of disk storage, the number
of file systems involved, and the length of time it
takes for the applications to be stopped and started.
User impact during the cluster takeover may be
significant. A switchover of less than two minutes is
not realistic in most production environments.
In Figure 4, the lower portion of the bar represent-
ing the HA cluster takeover illustrates that it actually
provides fast recovery. The application must be
stopped, file systems unmounted, volume groups
varied off (taken offline), and finally the service IP
address (used for cluster communications) is taken
down. The takeover is then performed, and these
steps must be taken in reverse to return the
application to a usable state. Until the application
has completely started and is accepting connections,
the end user is without service. Start-to-finish
takeover times vary widely based on application
stop and restart characteristics and are typically
measured in minutes.
Both LPM and LAM have a much smaller impact on
the end user; depending on the workload, the
interruption may be imperceptible. In the LPM bar,
the only time the application is not running is
between the stop and start processing states when
the partition is being moved to the target managed
system. Similarly, the pause in runtime shown in the
LAM bar is only during the state migration of the
WPAR. In contrast to HA cluster takeover times,
LPM or LAM pauses typically take only a few
seconds.
For LPM, the stop and start processing time is very
short as the partition is migrated between managed
systems, but the complete time to migrate the
partition will depend on the workload and how long
it takes to copy the memory to the target system.
System and network capacity will affect these times.
MCLAUGHLIN ET AL. IBM SYSTEMS JOURNAL, VOL 47, NO 4, 2008528

Unlike traditional HA clustering, it is not necessary
to keep cluster nodes synchronized for planned
maintenance tasks when LPM or LAM is used, but
the consideration applies for unplanned outages. If
the VIO server on the source is modified, similar
modifications must be made on the target server.
LPM and LAM are highly beneficial for planned
maintenance and workload balancing, but they will
not protect against unplanned outages. Both mobil-
ity features require the source and destination
systems to be operational. A situation in which the
source fails unexpectedly (e.g., an application
termination or an LPAR or system crash) requires
the quick failure detection and automated resource
relocation provided by HA clustering software, such
as HACMP.
HACMP 5.4 leverages WPAR features in order to
realize the benefits that WPARs provide for appli-
cation isolation. HACMP runs in the global envi-
ronment and manages the application execution in a
defined and active WPAR, but it does not manage
the WPAR itself. HACMP has created a new resource
group attribute, a WPAR-enabled resource group
that is configured to run in a specific WPAR, one
Application stop Unmount/vary off Mount/vary on Application start
System A System B
Normal runtimeInterruptionPause
IP takendown
IP re-enabled
HMC verification
Partition creation
Copy memory state over Ethernet Complete memory copy
Stop processing Start processing
HA clustering
HACMP takeover complete
Initiatemigration
Migrationcomplete
CheckpointVerify
Restart on target
Delete source WPAR
LAM
LPM
System A System B
System A System B
Relocationcomplete
Initiaterelocation
Verify
Figure 4Comparison of HA clustering, LPM, and LAM (No time reference is implied, and time lines are not to scale)
IBM SYSTEMS JOURNAL, VOL 47, NO 4, 2008 MCLAUGHLIN ET AL. 529

that supports only the IP service address, file
system, and application-type resources.
The key value of LPM and LAM is to increase
uptime. The capability to move workloads dynam-
ically around the data center makes it possible to
perform firmware maintenance, environmental
maintenance (power or cooling), and other tasks
nondisruptively. Many clients have processes and
plans in place to deal with component failures and
DR, but are still using planned outages to perform
tasks that can now be handled dynamically.
Deciding between LPM and LAM
LPM and LAM are similar because both can move
workloads from one managed system to another
quickly enough that the movement is transparent to
the user. However, they have different require-
ments, and it is important to understand which
technology will best meet business needs. As with
many virtualization technologies, performance im-
plications should be considered.
File system performance is one such consideration.
LPM-enabled partitions must use virtualized storage
on a VIO server which, depending on the VIO server
configuration, could reduce system performance for
I/O-intensive applications. WPARs must use Net-
work File System (NFS) to access application data
and perform checkpoints, which will be limited to
the performance of the NFS server and TCP/IP
network.
While WPARs may offer better CPU and memory
utilization (because they allow management of
multiple workloads to meet the capacity of the
LPAR), this also means a possibility of resource
contention. Mobile LPARs are normal partitions;
they have dedicated resources and are not suscep-
tible to resource contention. By using dynamic
LPARs to adjust CPU and memory capacity to match
the workload, high utilization can also be achieved.
Because all WPARs share the global environment,
they must all share the same fixes, and an OS fault
would cause all WPARs to fail. Because of the
limited isolation of a WPAR, it is possible that one
WPAR may impact another. LPARs offer greater
fault isolation than WPARs.
WPARs would be suitable for tier 1 (Web server) of
a multitier architecture. Where data may be ac-
cessed in a read-only fashion and application
scalability is an important factor in responding to
dynamic workloads, WPARs would also be a good
fit. Mobile LPARs may be the better choice when
dedicated capacity is required for an application,
such as a database.
LPM is a POWER6 processor feature, while LAM is
an AIX 6 feature. If the application to be moved runs
on Linux but not AIX, then LPM would be used.
Additional enhanced availability features
While this paper focuses on new workload reloca-
tion capabilities, the AIX 6 OS and POWER6
processor-based servers include numerous addi-
tional features and enhancements that can improve
IT service availability.
Concurrent firmware maintenance
Concurrent firmware maintenance (CFM) was in-
troduced in firmware level 2.3.0 for the System p5
platform and is also available for the release of the
new POWER6 processor-based Power Systems
platform. CFM requires that the platform be
managed by an HMC. CFM generally eliminates the
need for a system reboot when applying an update
within a release level. In many cases, all of the fixes
provided in a service pack can be activated
concurrently, allowing the client to apply the fixes
without disrupting the managed system. There are a
small number of fixes that cannot be activated
concurrently. The client usually still has the option
to apply the concurrent portions of these fix packs
and delay the remainder until a system reboot can
be scheduled.
When upgrading the firmware on the managed
system to a new release level, a system reboot is still
required. Because of this, some clients choose to
remain on a release of firmware past the end-of-
support date to avoid a reboot. Beginning with
POWER6 processor-based systems, firmware re-
leases will be supported for two years to help ensure
that most clients are able to run for at least one year
on a supported firmware release. It is strongly
recommended to maintain currency and upgrade
firmware levels once a year as available.
Service processor takeover
Service processor takeover helps reduce outages due
to a failure of the service processor hardware or
other hardware failures that could cause a system
MCLAUGHLIN ET AL. IBM SYSTEMS JOURNAL, VOL 47, NO 4, 2008530

outage. A common misconception is that the
redundant service processor provides the mecha-
nism to eliminate outages due to firmware mainte-
nance. In fact, the redundant service processor
provides the ability to handle certain error condi-
tions and keep them from impacting the managed
system by failing over to the other service processor.
On the Power Systems platform, the dual service
processor capability is being installed by default on
all Model 570 8- , 12- , and 16-way systems. This
feature was previously available only on Model 590/
595 and select 570 models.
AIX concurrent kernel updates
AIX 6 includes the capability to apply some kernel
updates without requiring a reboot.23
This helps
reduce the number of planned outages required to
maintain currency of the AIX system. It also helps
reduce the number of unplanned outages by
allowing the more efficient application of available
fixes.
POWER6 processor instruction retry
This feature can shield a running application from a
transient processor fault by retrying the instruction
on the same processor. A solid processor fault
causes the alternate processor recovery capability to
be invoked in order to deallocate the failing
processor and locate the instruction stream on a new
processor core. The new processor can be acquired
through CoD or, if available, an unused spare
processor. If neither of these options is available,
then the new partition availability priority capability
will be used to attempt to terminate lower-priority
partitions in order to acquire a spare processor. The
priority is set by the system administrator so that
lower-tier applications or development workloads
can be impacted in order to protect higher-priority
applications.24
RAS features
The reliability, availability, serviceability (RAS)
capabilities of the POWER platform are extensive
and have been greatly improved for the POWER6
processor release. These capabilities have been
thoroughly documented elsewhere; the following
list provides a few highlights.
� The HMC version 7 offers the capability of remote
management through a Web browser, enhancing
the serviceability and manageability.25
� Additional enhancements to the HMC and service
processor will enable greater reliability and
serviceability.26
� Concurrent maintenance has been further ex-
tended to include additional devices such as GX
Adapters.26
CONCLUSION
Today’s System p5 servers can deliver very high IT
availability when properly configured, deployed,
and maintained. However, client IT organizations
increasingly struggle to meet their users’ growing
availability requirements while dealing with IT
budget constraints, constantly evolving infrastruc-
tures, and decreasing time available for critical
maintenance activities.
The new Power Systems platform addresses this
situation because it provides the following:
� New workload mobility features—LPM and
WPAR-based LAM—that enable administrators to
nondisruptively move workloads between man-
aged systems, creating new opportunities to
maximize IT availability while facilitating the
dynamic management of maintenance and other
changes� Significant enhancements in hardware and soft-
ware RAS� Greater performance with equivalent energy con-
sumption compared with the previous-generation
System p platform
As with any new or improved technology, clients
must analyze the benefits, understand the costs, and
learn how to use the new capabilities effectively.
Once this is done, clients should realize increased
availability and greater flexibility to perform main-
tenance tasks whenever necessary.
When POWER6 and AIX 6 workload mobility
features and RAS enhancements are combined with
existing availability technologies—including HA
clustering software, middleware availability capa-
bilities, and host- and storage-based data mirroring
and replication—extremely high levels of IT service
availability can be efficiently achieved.
ACKNOWLEDGMENTSThe authors thank the following people for their
contributions to this paper: Randall Wilson, Alfredo
Fernandez, Creighton M. Hicks, Cam-Thuy T. Do,
IBM SYSTEMS JOURNAL, VOL 47, NO 4, 2008 MCLAUGHLIN ET AL. 531

James Wang, Stephan D. Linam, Brent W. Jacobs,
Michael L. Trantow, Terrence T. Nixa, Brian O’Leary,
and Christine O’Sullivan.
*Trademark, service mark, or registered trademark ofInternational Business Machines Corporation in the UnitedStates, other countries, or both.
**Trademark, service mark, or registered trademark ofSymantec Corporation, Microsoft Corporation, Linus Tor-valds, Sun Microsystems, Inc., or Hewlett-Packard Develop-ment Company, L.P., in the United States, other countries, orboth.
***A registered trademark of the Central Computer andTelecommunications Agency, which is now part of the Officeof Government Commerce.
****A registered trademark, and a registered communitytrademark of the Office of Government Commerce, and isregistered in the U.S. Patent and Trademark Office.
CITED REFERENCES AND NOTES1. C. Hales, C. Milsted, O. Stadler, and M. Vagmo, PowerVM
Virtualization on IBM System p: Introduction andConfiguration Fourth Edition, IBM Redbook SG24-7940-03, IBM Corporation (May 2008), http://www.redbooks.ibm.com/redbooks/pdfs/sg247940.pdf.
2. D. Quintero, L. Rosca, M. Vanous, R. Wale, J. Yoshino,and O. Lascu, Virtualization and Clustering Best PracticesUsing IBM System p Servers, IBM Redbook SG24-7349-00,IBM Corporation (May 2007), http://www.redbooks.ibm.com/redbooks/pdfs/sg247349.pdf.
3. Capacity on Demand, IBM Corporation, http://www-03.ibm.com/systems/p/advantages/cod/index.html.
4. IBM PowerHA Cluster Manager (HACMP), IBM Corpora-tion, http://www-03.ibm.com/systems/p/advantages/ha/index.html.
5. Tivoli System Automation for Multiplatforms, IBM Cor-poration, http://www-306.ibm.com/software/tivoli/products/sys-auto-multi/.
6. A. Abderrazag, High Availability Cluster Multiprocessing(HACMP) Best Practices, White Paper, IBM Corporation(January 2008), http://www-03.ibm.com/systems/p/software/whitepapers/hacmp_bestpractices.html.
7. G. McLaughlin, Considerations and Sample Architecturesfor High Availability on IBM eServer pSeries and Systemp5 Servers, White Paper, IBM Corporation (March 2006),http://www14.software.ibm.com/webapp/set2/sas/f/best/arch_ha_Systemp5.pdf.
8. Tivoli System Automation for Multiplatforms, IBM Cor-poration, http://www-306.ibm.com/software/tivoli/products/sys-auto-multi/.
9. A. Govindjee, F. Sherman, J. Littin, S. Robertson, and K.Jeong, Introducing VERITAS Foundation Suite for AIX,IBM Redbook SG24-6619-00, IBM Corporation (December2006), http://www.redbooks.ibm.com/redbooks/pdfs/sg246619.pdf.
10. S. Tovcimak, Using the Geographic LVM in AIX 5L, WhitePaper, IBM Corporation (September 2005), http://www-03.ibm.com/systems/p/os/aix/whitepapers/pdf/aix_glvm.pdf.
11. C. Brooks, C. Leung, A. Mirza, C. Neal, Y. L. Qiu, J. Sing,F. T. H. Wong, and I. R. Wright, IBM System StorageBusiness Continuity Solutions Overview, IBM RedbookSG24-6684-01, IBM Corporation (February 2007), http://www.redbooks.ibm.com/redbooks/pdfs/sg246684.pdf.
12. D. Clitherow, M. Brookbanks, N. Clayton, and G. Spear,‘‘Combining High Availability and Disaster RecoverySolutions for Critical IT Environments,’’ IBM SystemsJournal 47, No. 4, 563–575 (2008, this issue).
13. C. Brooks, F. Byrne, L. Higuera, C. Krax, and J. Kuo, IBMSystem Storage Solutions Handbook, IBM Redbook SG24-5250-06, IBM Corporation (October 2006), http://www.redbooks.ibm.com/redbooks/pdfs/sg245250.pdf.
14. W.-J. Chen, C. Chandrasekaran, D. Gneiting, G. Castro, P.Descovich, and T. Iwahashi, High Availability andScalability Guide for DB2 on Linux, UNIX, and Windows,IBM Redbook SG24-7363-00, IBM Corporation (Septem-ber 2007), http://www.redbooks.ibm.com/redbooks/pdfs/sg247363.pdf.
15. O. Lascu, V. Carastanef, L. Li, M. Passet, N. Pistoor, andJ. Wang, Deploying ORACLE 9i RAC on IBM eserverCluster 1600 with GPFS, IBM Redbook SG24-6954-00, IBMCorporation (October 2003), http://www.redbooks.ibm.com/redbooks/pdfs/sg246954.pdf.
16. S. Djordjevi�c, Oracle’s Maximum Availability Architec-ture, Oracle Corporation, http://www.oracle.com/global/yu/dogadjaji/db11gl_bg/max_avail.pdf.
17. W. J. Armstrong, R. L. Arndt, D. C. Boutcher, R. G.Kovacs, D. Larson, K. A. Lucke, N. Nayar, and R. W.Swanberg, ‘‘Advanced Virtualization Capabilities ofPOWER5 Systems,’’ IBM Journal of Research & Develop-ment 49, No. 4/5, 523–532 (2005).
18. W. J. Armstrong, R. L. Arndt, T. R. Marchini, N. Nayar,and W. M. Sauer, ‘‘IBM POWER6 Partition Mobility:Moving Virtual Servers Seamlessly Between PhysicalSystems,’’ IBM Journal of Research & Development 51,No. 6, 757–762 (2007). http://researchweb.watson.ibm.com/journal/rd/516/armstrong.html.
19. R. L. Arndt, ‘‘Power6 for Partition Mobility,’’ Proceedingsof the Power Architecture Developer Conference, Austin,TX (2007), http://www.power.org/devcon/07/Session_Downloads/PADC07_Arndt_Partition_Mobility.pdf.
20. S. Vetter, M. Harding, N. Itoh, P. Nutt, G. Somers, F.Vagnini, and J. Wain, PowerVM Live Partition Mobility onIBM System p, IBM Redbook SG24-7460-00, IBM Corpo-ration (December 2007), http://www.redbooks.ibm.com/abstracts/sg247460.html.
21. S. Vetter, J. Abbott, R. Bassemir, C. Hales, O. Plachy, andM. Yeom, Advanced POWER Virtualization on IBMSystem p Virtual I/O Server Deployment Examples, IBMRedpaper REDP-4224-00, IBM Corporation (February2007), http://www.redbooks.ibm.com/abstracts/redp4224.html.
22. C. Almond, B. Blanchard, P. Coelho, M. Hazuka, J. Petru,and T. Thitayanun, Introduction to Workload PartitionManagement in IBM AIX Version 6.1, IBM Redbook SG24-7431-00, IBM Corporation (November 2007), http://www.redbooks.ibm.com/abstracts/sg247431.html.
23. S. Vetter, R. Aleksic, I. N. Castillo, R. Fernandez, A. Roll,and N. Watanabe, IBM AIX Version 6.1 Differences Guide,IBM Redbook SG24-7559-00, IBM Corporation (December2007), http://www.redbooks.ibm.com/abstracts/sg247559.html.
24. D. Henderson, B. Warner, and J. Mitchell, IBM POWER6Processor-based Systems: Designed for Availability, White
MCLAUGHLIN ET AL. IBM SYSTEMS JOURNAL, VOL 47, NO 4, 2008532

Paper, IBM Corporation (June 2007), http://www-03.ibm.com/systems/p/hardware/whitepapers/power6_availability.html.
25. S. Hochstetler, J. Min, M. Robbins, N. Milliner, N. Chand,and S. Hidayat, Hardware Management Console V7Handbook, IBM Redbook SG247491-00 18, IBM Corpo-ration (October 2007), http://www.redbooks.ibm.com/abstracts/sg247491.html.
26. J. Mitchell, G. Ahrens, J. Villarreal, and B. Warner, IBMPOWER6 Processor-based Systems: Designing and Imple-menting Serviceability, White Paper, IBM Corporation(June 2007), http://www-03.ibm.com/systems/p/hardware/whitepapers/power6_serviceability.html.
Accepted for publication May 30, 2008.
Grant T. McLaughlinIBM Systems and Technology Group, 2455 South Road,Poughkeepsie, NY 12601 ([email protected]).Mr. McLaughlin recently became the Business ResilienceOfferings manager for Enterprise Systems. He was previouslythe client engagement program manager and a PowerSystemse specialist at the IBM HACoc. He received a B.S.degree in computer science from Syracuse University. He isalso Project Management Institute and ITILe certified. Hisresponsibilities have spanned mainframe software technicalsupport, multiplatform UNIXt software development andsupport, AIXe software development, and softwaredevelopment project and program management.
Leo Y. LiuIBM Systems and Technology Group, 113 Buckden Place, Cary,NC 27518 ([email protected]). Dr. Liu is a certifiedengagement leader and System p platform specialist at theIBM HACoC. He received a B.S. degree in electronicengineering and an M.S. degree in management science, bothfrom the National Chiao-Tung University, Taiwan, and aPh.D. degree in computer science from Pennsylvania StateUniversity. He is PMI and ITILe certified.
Daniel J. DeGroffIBM Systems and Technology Group, 3605 Highway 52 N,Rochester, MN 55901 ([email protected]). Mr. DeGroff is amember of the IBM PowerHA for i development team and hasworked as a technical specialist for the IBM HACoC. Hereceived a B.S. degree in electrical engineering and technologyfrom South Dakota State University. He also received the ITILfoundation certification.
Kenneth W. FleckIBM Systems and Technology Group, 2455 South Road,Poughkeepsie, NY 12601 ([email protected]). Mr. Fleck is anavailability specialist and subject-matter expert with the IBMHACoC and has worked on availability assessments aroundthe world where he specializes in availability on the IBMSystem xe and System pe platforms and the implementationof HA and infrastructure resiliency best practices. &
IBM SYSTEMS JOURNAL, VOL 47, NO 4, 2008 MCLAUGHLIN ET AL. 533
Published online October 27, 2008.