hybridizing principles of the electre method with case-based reasoning for data mining:...
TRANSCRIPT

European Journal of Operational Research 197 (2009) 214–224
Contents lists available at ScienceDirect
European Journal of Operational Research
journal homepage: www.elsevier .com/locate /e jor
Decision Support
Hybridizing principles of the Electre method with case-based reasoningfor data mining: Electre-CBR-I and Electre-CBR-II
Hui Li *, Jie SunSchool of Business Administration, Zhejiang Normal University, 91 Subbox in P.O. Box 62 at YingBinDaDao 688, Jinhua City 321004, Zhejiang Province, PR China
a r t i c l e i n f o a b s t r a c t
Article history:Received 18 May 2007Accepted 30 May 2008Available online 10 June 2008
Keywords:Data miningElectreCase-based reasoning30-times hold-out methodFinancial distress prediction
0377-2217/$ - see front matter � 2008 Elsevier B.V. Adoi:10.1016/j.ejor.2008.05.024
* Corresponding author. Tel.: +86 158 8899 3616.E-mail addresses: [email protected] (H. Li), sunji
Electre is an important outranking method developed in the area of decision-aiding. Data mining is a vitaldeveloping technique that receives contributions from lots of disciplines such as databases, machinelearning, information retrieval, statistics, and so on. Techniques in outranking approaches, e.g. Electre,could also contribute to the development of data mining. In this research, we address the followingtwo issues: a) why and how to combine Electre with case-based reasoning (CBR) to generate correspond-ing hybrid models by extending the fundamental principles of Electre into CBR; b) the effect on predictiveperformance by employing evidence vetoing the assertion on the base of evidence supporting the asser-tion. The similarity measure of CBR is implemented by revising and fulfilling three basic ideas of Electre,i.e. assertion that two cases are indifferent, evidence supporting the assertion, and evidence vetoing theassertion. Two corresponding CBR models are constructed by combining principles of the Electre deci-sion-aiding method with CBR. The first one, named Electre-CBR-I, derives from evidence supportingthe assertion. The other one, named Electre-CBR-II, derives from both evidence supporting and evidencevetoing the assertion. Leave-one-out cross-validation and hold-out method are integrated to form 30-times hold-out method. In financial distress mining, data was collected from Shanghai and ShenzhenStock Exchanges, ANOVA was employed to select features that are significantly different between com-panies in distress and health, 30-times hold-out method was used to assess predictive performance,and grid-search technique was utilized to search optimal parameters. Original data distributions werekept in the experiment. Empirical results of long-term financial distress prediction with 30 initial finan-cial ratios and 135 initial pairs of samples indicate that Electre-CBR-I outperforms Electre-CBR-II andother comparative CBR models, and Electre-CBR-II outperforms the other comparative CBR models.
� 2008 Elsevier B.V. All rights reserved.
1. Introduction
Data mining is a new popular tool to mine knowledge fromdata, under the contributions from lots of disciplines such as dat-abases, machine learning, information retrieval, statistics, datavisualization, parallel and distributed computing, and so forth.(Han and Kamber, 2001; Zhou, 2003). There are systematic ap-proaches in data mining to carry out classification and predictiontasks, with some mature theories of data preprocessing, perfor-mance assessment, and so on. They assist the process of modelingeffectively. Electre is a chief outranking approach that has beendeveloped by Roy (1971, 1991, 1996), Roy and Vincke (1984),Roy and Słowinski (2008). In the development of Electre, it ismainly applied into the area of decision-aiding. Till now, seldomcontributions have been made from decision-aiding methods tothe area of data mining.
ll rights reserved.
[email protected] (J. Sun).
CBR is a body of concepts and techniques which touches onknowledge representation, reasoning, and learning from experi-ence (Schank and Abelson, 1977; Schank, 1982; Pal and Shiu,2004; Shiu and Pal, 2004). It is also a methodology in data mining(Han and Kamber, 2001). CBR is a comprehensible manner for pre-diction, because it is similar to human reasoning process. As we allknow, human beings always search their memories to find similarexperiences when they are encountered with a new problem. Itcould learn over time, reason in domains with incomplete dataand concepts that have not been fully defined or modeled, and pro-vide a means of explanation.
Financial distress prediction, which could be regarded as a datamining task, has become an important research area since 1966. Inthe beginning, statistical techniques such as multivariate discrim-inant analysis (MDA) (Altman, 1968) and Logistic regression (Logit)(Martin, 1977) were employed in financial distress prediction.Then, with the development of machine learning, neural networks(NN) (Odom and Sharda, 1990), case-based reasoning (CBR) (Jo andHan, 1996), and support vector machine (SVM) (Shin et al., 2005;Hui and Sun, 2006) were applied and they often outperformed

H. Li, J. Sun / European Journal of Operational Research 197 (2009) 214–224 215
statistical ones. Data mining, which refers to mining knowledgefrom large amounts of data, has made great strides during the lasttwo decades. It revives the interest for researches of financial dis-tress prediction. Lin and McClean (2001), Sun and Li (2008a),respectively, used systematic data mining approaches with hybridmodels to find hidden patterns, trends and relationships in finan-cial data. Clustering analysis, a technique of data mining, was alsoused to predict financial distress (Smet and Guzman, 2004). Mean-while, group decision making began to be employed to build anearly warning system of financial distress (Sun and Li, 2007). Inthe period of 1968–2005, more than 67% of published papers onfinancial distress prediction collected samples containing less thanone thousand records, and there were no researches involvingmore than ten thousands records in the review by Kumar and Ravi(2007). In financial distress prediction of Chinese listed companies,there are no more than 2000 listed companies in Shanghai andShenzhen Stock Exchanges. As a result, the number of the samplesthat could be used is limited. Thus, it is a suitable area for the appli-cation of CBR with the algorithm of k-nearest-neighbor (KNN) as itsheart.
Electre and CBR are both developed on the basis of distancemeasure between two objects. They are derived from humanbehaviors or developed to assist human behaviors in daily life.Thus, it is reasonable to combine Electre with CBR to fulfill similar-ity measure. In fact, Slowinski and Stefanowski (1994, 1996), werethe first authors who applied outranking relations to define differ-ent similarity functions for the data features. Li et al. (2007) alsoinvestigated the possibility of defining a similarity function byusing outranking relations. Li and Sun (2008) attempted to useranking-order information in defining a similarity measure inCBR. However, there is a lack of research on how and why to com-bine outranking approaches with CBR, and there are no discussionson effects of evidence supporting and vetoing the assertion thattwo objects are similar. In this research, we address why andhow to combine the Electre decision-aiding method with CBR toform a data mining method and attempt to investigate whetherpredictive performance could be improved by employing evidencevetoing the assertion on the base of evidence supporting the asser-tion. The following five contents are mainly presented, i.e., datamining by CBR, fundamental principles of Electre, similarity mea-sures by employing principles of Electre in two different means,reduction on computation complexity of Electre when hybridizing,and detailed methodology. Two hybrid CBR models are con-structed, both of which are fulfilled by extending the basic ideasof Electre and using them in CBR. The assertion of the Electre deci-sion-aiding method is revised as ‘case a and case b are indifferent’in order to be consistent with the idea of similarity in CBR. In thehybridization process, we generate two corresponding models.The first one, named Electre-CBR-I, derives from evidence support-ing the assertion. The other one, named Electre-CBR-II, derivesfrom both evidence supporting and evidence vetoing the assertion.Meanwhile, the application area is financial distress prediction.The performance of the two hybrid models are compared by 30-times hold-out method, which is combined by leave-one-outcross-validation and hold-out method. The classical CBR modelsbased on Euclidean distance and Manhadun distance and the onebased on grey correlation degree are also employed to make acomparison.
This paper is organized as follows. Section 2 makes a brief re-view on data mining processes, commonly used feature selectionmethods, and CBR-based financial distress prediction. The contri-bution of this paper and why this kind of combination isselected are presented in Section 3. Section 4 addresses how tocombine the basic principles of Electre with CBR to generatetwo hybrid models for data mining purpose. Section 5 designsthe experiment of financial distress prediction, with empirical
results and analysis presented in Section 6. Section 7 draws someconclusions.
2. Literature review
2.1. Data mining processes
Data mining is composed of several systematic processes. Theyaim to obtain more suitable data and models for prediction orclassification problems. Chief processes of data mining includedata collection, data cleaning, data integration, data reductionby feature selection or/and construction, data verification, model-ing, assessment and prediction (Han and Kamber, 2001; Handet al., 2001; Witten and Frank, 2000; Lin and McClean, 2001).Data cleaning is to clean the data for specific application. Dataintegration merges data for specific applications into a data cube.Such data in financial distress prediction includes publicly re-vealed symptoms of listed companies, class labels describingwhether the company runs into financial distress or not, and re-lated operating strategies that help the company in distress getout of it. Data reduction leads to a reduced representation ofthe data set which is much smaller in volume, yet produces thesame even better predictive accuracy. Whether or not the pro-cessed data set is suitable for financial distress prediction shouldbe verified in the process of data verification. There are two maintechniques for data verification, i.e. multi-collinearity test amongfeatures and significance test on difference between samples indistress and health. In the modeling process, specific models aredeveloped and applied for data mining tasks. Predictive perfor-mance is usually assessed through hold-out method or cross-validation.
2.2. CBR-based financial distress mining
CBR was born in 1980 or so (Schank and Abelson, 1977; Schank,1982) and began to be used in financial distress prediction in 1996.Under the guidance of showing that CBR systems could be effec-tively developed for a variety of accounting tasks (Brown and Gup-ta, 1994), there are indeed some researches that have studiedfinancial distress prediction using CBR. Jo and Han (1996) firstlyintroduced CBR into financial distress prediction to form a case-based forecasting system. Jo et al. (1997) gave the comparisonamong case-based forecasting, MDA, and NN. Average accuracyof MDA, NN and CBR was 82.22%, 83.79% and 81.52%, respectively.By employing the CBR shell of ReMind, Bryant (1997) also tried tofind out whether or not CBR could be used successfully to predictcorporate bankruptcy. Experimental results indicated that Logithad superior predictive accuracy than CBR.
Feature weighting is an important problem in feature-weightedsimilarity measure, e.g. Euclidean distance metric. Park and Han(2002) proposed the AHP-weighted KNN algorithm for bankruptcyprediction by introducing analytic hierarchy process (AHP), a com-monly used weighting mechanism, into CBR. Experimental resultsindicated that it outperformed all the other comparative CBR mod-els. In the following two years, Yip and Deng (2003), Yip (2004)used CBR with KNN algorithm to predict business failure of Austra-lian firms. Experimental results indicated that CBR with weightedKNN outperformed MDA, and MDA outperformed CBR with pureKNN. Lately, Sun and Hui (2006) proposed a financial distress pre-diction model based on grey correlation metric and weighted KNN.It was concluded that the new CBR model had a good predictiveability for those companies that would probably run into financialdistress in less than two years. Lin et al. (2007) integrated rough settheory with grey relational analysis and CBR to implement finan-cial distress prediction, with the conclusion that the proposed

216 H. Li, J. Sun / European Journal of Operational Research 197 (2009) 214–224
model was the most accurate and effective model in predictivemodels based on rough set theory.
Researches of CBR-based financial distress prediction could besummarized as follows: (a) studies of CBR-based financial distressprediction mainly distribute in Korea, USA, Australia, China’s main-land, and Taiwan; (b) current researches of CBR-based financialdistress prediction do provide some evidence on its effectivenessand un-effectiveness; (c) the majority of forgoing researches useequal weight on each feature; (d) the majority of forgoing re-searches employ Euclidean metric as the foundation of similaritymeasure; (e) in the majority of forgoing researches, the principleof KNN, rather than nearest neighbor, is utilized and (f) MDA step-wise method and two-tailed t-test have been used to select fea-tures in CBR-based financial distress prediction.
2.3. Commonly used methods of feature selection in financial distressmining
Financial distress prediction could be regarded as a specificform of classification problem. For such problems, two families offeature selection methods have been developed so far (Guyonand Elisseeff, 2003). One family of feature selection is the filtersand the other one is the wrappers. Both families are data oriented.The grouping principle for feature selection methods is whether ornot a classifier or predictor is taken into consideration when carry-ing out the process of feature selection.
Filters select optimal feature subsets as a pre-processing step.This step is independent of the classifier. Till now, there are sev-eral specific filter approaches commonly used in financial distressprediction. For example, Chen and Hsiao (2008), Min et al.(2006), Lin and McClean (2001), Jo et al. (1997), Jo and Han(1996), Back et al. (1996), respectively, employed stepwise meth-ods of MDA, Logit, and ANOVA in their applications of financialdistress prediction. Wrappers take interest of a classifier intoconsideration and use it as a black box to select feature subsetsaccording to their predictive power. When wrappers are includedin the training process, they are often called as embedded meth-ods. A commonly used wrapper in financial distress prediction isgenetic algorithm (GA), which is employed to search optimal fea-ture subsets under the assessment of the classifier’s predictiveaccuracy. For example, Min et al. (2006) and Kim (2004), respec-tively, used GA to select optimal feature subsets for the classifiersthey employed.
One of the main advantages of filters is that they could be usedas preprocessing step to reduce space dimensionality and over-come over-fitting. Thus, it is reasonable to use a filter or wrapperwith a linear predictor in the process of feature selection, and thentrain a more complex non-linear predictor on the resulting features(Guyon and Elisseeff, 2003). In fact, Bi et al. (2003) have alreadycarried out this type of research recently. They used a linear SVMin the process of feature selection, but a non-linear SVM for predic-tion using the resulting features. Chen and Hsiao (2008) also triedto use a wrapper with a linear predictor, i.e. MDA stepwise method,to select optimal features for a non-linear SVM.
In the area of financial distress prediction, there is another fam-ily of feature selection method. When Beaver (1966) and Altman(1968) started the area of financial distress prediction by applyingstatistical models, experience-based feature selection was used.Lin and McClean (2001) compared predictive accuracy using twotypes of feature subsets, respectively, generated by human judg-ment and ANOVA. Their conclusion is that the filter approach out-performed feature selection method based on human beings’experience. The so called experience of expert is hard to be at handand it does not take into consideration the characteristic of a spe-cific application problem. Nowadays, a relatively complete initialfeature subset built by experts’ experience needs to be employed
firstly. Then, data oriented feature selection methods are supposedto be used.
3. Contribution of this work
In this research, we would like to call attention of researchers indecision-aiding area, e.g. outranking approach, on the applicationarea of data mining. The contribution of this paper is twofold. Onthe one hand, we try to describe why and how to apply somekey techniques of Electre into data mining. This is done by analyz-ing the fundamental ideas of Electre. When fulfilling this motiva-tion, we find the media of CBR, which is a classification methodin data mining. The reason why we choose CBR is not only becauseof its merits mentioned in Section 1, but also because both CBR andElectre are developed on the basis of distance measure betweenpairs of objects on each feature. In CBR with KNN as its heart,Euclidean distance is traditionally used. In Electre, the determina-tion of an outranking relation also roots on a distance measure oneach feature. At the same time, CBR is believed to be a methodol-ogy not a technology (Kolodner, 1993; Watson, 1999; Pal and Shiu,2004). Hence, any technique or approach could be absorbed intoCBR. Thus, it sounds reasonable to combine principles of the Elec-tre decision-aiding method with CBR and form a hybrid model, i.e.Electre-CBR. We generate two Electre-CBR models. The first one,named Electre-CBR-I, is developed on the basis of evidence sup-porting the assertion that two objects are indifferent. The otherone, named Electre-CBR-II, is developed on the basis of both evi-dence supporting and vetoing the assertion that two objects areindifferent. The effect on predictive performance by employing evi-dence vetoing the assertion on the base of evidence supporting theassertion is attempted to be investigated.
On the other hand, we try to investigate the performance of thetwo Electre-CBR models in long-term financial distress prediction.Predictive performance of the two derived models is planed to becompared. Classical CBR models are planned to be employed asbaseline models. Initial data used is collected from Shanghai andShenzhen Stock Exchanges in China. In the empirical research,we employ ANOVA to find significantly different features betweensamples in health and distress, as Lin and McClean (2001), Minet al. (2006) did. In the assessment of predictive performance, weemploy 30-times hold-out strategy by combining hold-out methodand leave-one-out cross-validation (LOO-CV). Correspondingparameters are optimized by grid-search technique in LOO-CV.Predictive performance is evaluated by predictive results producedon hold-out data. Statistical analysis is employed to find whetheror not there are significant differences among comparative modelson the basis of 30 predictive results.
4. Hybridizing fundamental principles of Electre into CBR
4.1. Data mining by CBR
Case library is very critical in CBR. When employing CBR intofinancial distress prediction, the data set of useful samples is usedas case library, and each sample is taken as a case. Judgment on acurrent sample’s financial state is generated by integrating finan-cial labels of similar cases in case library. These cases have similarsymptoms with the current one. Internal structure of CBR-basedfinancial distress prediction system could be divided into two ma-jor parts, i.e. company retriever and company label classifier. It isshown as Fig. 1. The task of company retriever is to find appropri-ate companies in case library. The task of company label classifieris to use similar companies to label the current one. When dis-tance-based data mining methods are utilized, company retriever
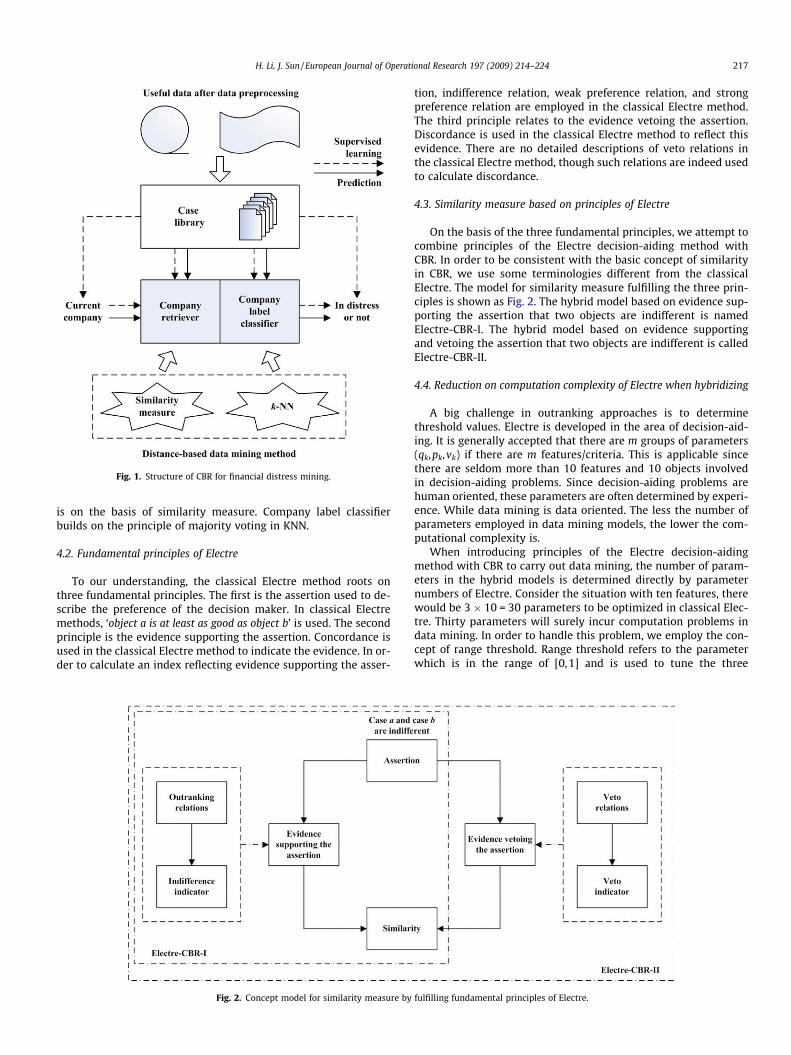
Fig. 1. Structure of CBR for financial distress mining.
H. Li, J. Sun / European Journal of Operational Research 197 (2009) 214–224 217
is on the basis of similarity measure. Company label classifierbuilds on the principle of majority voting in KNN.
4.2. Fundamental principles of Electre
To our understanding, the classical Electre method roots onthree fundamental principles. The first is the assertion used to de-scribe the preference of the decision maker. In classical Electremethods, ‘object a is at least as good as object b’ is used. The secondprinciple is the evidence supporting the assertion. Concordance isused in the classical Electre method to indicate the evidence. In or-der to calculate an index reflecting evidence supporting the asser-
Fig. 2. Concept model for similarity measure by
tion, indifference relation, weak preference relation, and strongpreference relation are employed in the classical Electre method.The third principle relates to the evidence vetoing the assertion.Discordance is used in the classical Electre method to reflect thisevidence. There are no detailed descriptions of veto relations inthe classical Electre method, though such relations are indeed usedto calculate discordance.
4.3. Similarity measure based on principles of Electre
On the basis of the three fundamental principles, we attempt tocombine principles of the Electre decision-aiding method withCBR. In order to be consistent with the basic concept of similarityin CBR, we use some terminologies different from the classicalElectre. The model for similarity measure fulfilling the three prin-ciples is shown as Fig. 2. The hybrid model based on evidence sup-porting the assertion that two objects are indifferent is namedElectre-CBR-I. The hybrid model based on evidence supportingand vetoing the assertion that two objects are indifferent is calledElectre-CBR-II.
4.4. Reduction on computation complexity of Electre when hybridizing
A big challenge in outranking approaches is to determinethreshold values. Electre is developed in the area of decision-aid-ing. It is generally accepted that there are m groups of parameters(qk,pk,vk) if there are m features/criteria. This is applicable sincethere are seldom more than 10 features and 10 objects involvedin decision-aiding problems. Since decision-aiding problems arehuman oriented, these parameters are often determined by experi-ence. While data mining is data oriented. The less the number ofparameters employed in data mining models, the lower the com-putational complexity is.
When introducing principles of the Electre decision-aidingmethod with CBR to carry out data mining, the number of param-eters in the hybrid models is determined directly by parameternumbers of Electre. Consider the situation with ten features, therewould be 3 � 10 = 30 parameters to be optimized in classical Elec-tre. Thirty parameters will surely incur computation problems indata mining. In order to handle this problem, we employ the con-cept of range threshold. Range threshold refers to the parameterwhich is in the range of [0,1] and is used to tune the three
fulfilling fundamental principles of Electre.

218 H. Li, J. Sun / European Journal of Operational Research 197 (2009) 214–224
thresholds, i.e. indifference threshold, difference threshold andveto threshold. The three relations will be described in next sec-tion. The three corresponding range thresholds, i.e. q, p, v,(q < p < v) are defined in the following way:
qk ¼ q� rangeðkÞ; ð1Þpk ¼ p� rangeðkÞ; ð2Þvk ¼ v� rangeðkÞ; ð3Þ
where range(k) represents the range of the kth feature, and q, p, vcould be, respectively, called as range threshold of indifferencethreshold, difference threshold and veto threshold.
4.5. Model specification
4.5.1. Frame modelThe frame model of Electre-CBR for data mining is shown as
Fig. 3. We could find from Fig. 3 that key problems for combining
Fig. 3. Structure of the hybrid data mining
principles of the Electre decision-aiding method with CBR areassertion definition, outranking relation, indifference indicator,veto relation, veto indicator, and parameter number reduction. Atthe same time, the key problem of employing CBR in data miningis similarity measure. Key problems for building up case library in-clude data collection and preprocessing. One of the key problemsin data preprocessing is feature selection.
The initial aim of developing outranking approaches, e.g. Elec-tre, is to help human beings to make a decision by ranking alterna-tives. Thus, the research objective in Electre is to find which objectis more preferred than the other. When trying to combine somekey techniques of Electre into CBR, some changes on initial defini-tions of Electre have to be made. As we all know, CBR is developedto help human beings to make a decision by providing similarexperiences to the encountered problem. Thus, the research objectin CBR is to find which object is more similar (or indifferent) to thetarget object. This is completely different from the initial researchobject of Electre. Hence, we have to revise original definitions of
model by combining Electre into CBR.

H. Li, J. Sun / European Journal of Operational Research 197 (2009) 214–224 219
Electre to be consistent with the research object of CBR, when com-bining principles of the Electre decision-aiding method with CBR tocarry out data mining tasks.
4.5.2. Revised assertionConcepts of outranking relations derive from researches of
European school of multi-criteria decision aiding (Roy, 1971,1991, 1996; Brans and Vincke, 1985; Vincke, 1986; Bouyssou andPirlot, 2005; Roy and Słowinski, 2008). Specific definitions of out-ranking relations in Electre are assertion oriented. In classical deci-sion-aiding domain, the objective of developing Electre is to find apreferred sequence of objects. Thus, the assertion ‘object a outranksobject b’, meaning ‘object a is at least as good as object b’, is em-ployed in classical decision-aiding domain. For example, in thesummary of basic theory on Electre in Takeda (2001), it is theassertion ‘object a outranks object b’ or ‘object b is outranked by ob-ject a’ that is used, on the assumption that object a is at least aspreferred if object a outranks object b. Thus, there are three typesof relations generated between the two objects, i.e. strict prefer-ence, weak preference, and indifference.
When employing the principles of Electre into CBR to carryout data mining, it is a different situation. CBR has been devel-oped on the assumption that similar experience could guide fur-ther problem solving (Schank, 1982; Pal and Shiu, 2004). It is theconcept of indifference, rather than preference, which is em-ployed in CBR. In the hybridization of Electre and CBR, it is notapplicable to directly use the classical definitions of Electre tosolve data mining problems. In this view, we employ the asser-tion ‘object a and object b are indifferent’ when developing a hy-brid model for CBR-based financial distress prediction. As aresult, there are corresponding three types of relations generatedbetween the two objects, i.e. indifference, weak difference, andstrong difference.
4.5.3. Revised definitions of outranking relationLet the distance between case a and case b be denoted by dab.
Let xak and xbk be values of the kth feature of case a and case brespectively. Let wk express the weight of the feature. The distancemeasure between two cases in financial distress prediction on thekth feature could be denoted as follows:
dabk ¼ jxak � xbkj: ð4Þ
Indifference relation, weak difference relation, and strong differencerelation on each feature are defined as follows, respectively.
Definition 1. Case a and case b are considered as indifferent whenthe kth feature is taken into account, which could be denoted asIk(a,b), if the condition, dabk 6 qk, is met. qk is indifferencethreshold.
Definition 2. Case a and case b are considered as strongly differentwhen the kth feature is taken into account, which could be denotedas SDk(a,b), if the condition, dabk > pk, is met. pk is differencethreshold.
Definition 3. Case a and case b are considered as weakly differentwhen the kth feature is taken into account, which could be denotedas WDk(a,b), if the condition, qk<dabk 6 pk, is met.
Strong difference will only be concluded if there exists enoughevidence that one case is clearly dominating or dominated by thecase it is compared with. Weak difference represents a certain lackof conviction. Indifference means that the two cases are almost thesame. They compose the space of outranking relation between twocases, which could be expressed as Or.
4.5.4. Revised definitions of veto relation
Definition 4. There is a non-veto relation on the assertion thatcase a and case b are considered as indifferent when the kth featureis taken into account, which could be denoted as NVk(a,b), if thecondition, dabk 6 pk, is met.
Definition 5. There is a strong veto relation on the assertion thatcase a and case b are considered as indifferent when the kth featureis taken into account, which could be denoted as SVk(a,b), if thecondition, dabk > vk, is met. Here, vk is veto threshold.
Definition 6. There is a weak veto relation on the assertion thatcase a and case b are considered as indifferent when the kth featureis taken into account, which could be denoted as WVk(a,b), if thecondition, pk < dabk 6 vk, is met.
It is to partition the space of strong difference more particularly.Strong veto relation will only be concluded if a case is too stronglydominating or dominated by the case it is compared with on somefeature. Thus, the assertion that case a and case b is indifferent isforbidden. While weak veto relation represents a certain lack ofconviction. Non-veto relation means that relation between twocases could be measured by indifference indicator effectively. Thethree veto relations compose the space of strongly different rela-tions between two cases, which could be expressed as Vr.
4.5.5. Electre-CBR-I: using revised similarity measure based onevidence supporting the assertion
The similarity measure of CBR based on evidence supporting theassertion that two cases are indifferent is defined as follows:
SIM0ab ¼
Xm
k¼1
wkc0kða; bÞPmk¼1wk
; ð5Þ
where c0kða; bÞ is called the concordance index in classical Electre. Inorder to represent basic ideas of similarity in CBR, we rename con-cordance index as indifference indicator between case a and case bon the kth feature. The indifference indicator expresses the evi-dence which supports the assertion that case a and case b are indif-ferent. c0kða; bÞ is determined by
c0kða; bÞ ¼ f ðOrÞ ¼0 if SDkða; bÞ;pk�dabkðpk�qkÞ
if WDkða; bÞ;1 if Ikða; bÞ:
8><>: ð6Þ
4.5.6. Electre-CBR-II: using revised similarity measure based onevidence supporting and vetoing the assertion
Similarity between two cases based on evidence supporting andvetoing the assertion could be computed by
SIMab ¼
SIM0ab
if d0kða; bÞ 6 SIM0ab for every feature;
SIM0ab
Qk2fk:dk
^ k2fk:dk^ða;bÞ>SIMab
^g
1�d0kða;bÞ1�SIM0ab
if d0kða; bÞ > SIM0ab for at least one feature;
8>>>>>><>>>>>>:
ð7Þ
where d0kða; bÞ is called as the discordance index in the classicalElectre. In order to represent basic ideas of similarity in CBR, we re-name discordance index as veto indicator between case a and case bon the kth feature. Veto indicator expresses the evidence which ve-toes the assertion that case a and case b are indifferent. d0kða; bÞcould be computed in the following way:
d0kða; bÞ ¼ gðVrÞ ¼0 if NVkða; bÞ;vk�dabkðvk�pkÞ
if WVkða; bÞ;1 if SVkða; bÞ:
8><>: ð8Þ

220 H. Li, J. Sun / European Journal of Operational Research 197 (2009) 214–224
Note that Formula (7) is directly inspired by a similar formula usedto define the concordance–discordance index of the classical Electremethod, an index that is usually called degree of credibility of outran-king (Roy, 1971, 1991, 1996; Roy and Słowinski, 2008).
5. Financial distress mining
The objective of the application is to investigate predictive per-formance of the two Electre-CBR models. For comparison, the otherthree CBR models developed earlier are also considered. Two ofthem are on the basis of Euclidean distance metric and Manhadundistance metric, and the other one is on the basis of grey coefficientmetric. Predictive performance of the above five CBR models iscompared in this research. The general design of financial distressmining is shown as Fig. 4.
5.1. Initial data and variables
Listed companies that have had negative net profits in two con-secutive years will be specially treated (ST) by China SecuritiesSupervision and Management Committee (CSSMC). They are con-sidered as companies in financial distress. Companies that havenever been specially treated are regarded as healthy ones. The pair-ing strategy is employed to collect initial data in order to provideinformation of two distinct classes for learning machines. We col-lected 135 companies in distress from Shenzhen Stock Exchangeand Shanghai Stock Exchange with the period range of 2000–2005. Generally, a machine could learn from data effectively ifthere are comparable numbers of each class. Hence, we pairedthe distress companies by collecting corresponding healthy com-panies in principle of the same branch of industry and asset scale.If there is no corresponding healthy company to a specific com-pany in distress, we try to use a healthy company that is similarto the company in distress from the point of view of the type ofindustry and asset scale.
Suppose the year when a company runs into financial distressas the benchmark year t-0, then t-1, t-2, t-3, respectively, repre-sents one year, two years, and three years before distress. If thereare negative net profits in two consecutive years for a listed com-pany, this company will surely be regarded as a company in finan-
Fig. 4. Experime
cial distress. If there is a negative net profit in one year for a listedcompany, this phenomenon will surely call attention of corre-sponding people of the company. In order to generate an earlywarning of financial distress for listed companies using data beforethere are some signals from net profit, it is necessary to employfinancial data in the period of t-3.
The initial financial feature set is composed of 35 financial ra-tios, which cover activity ratios, long-term debt ratios, short-termdebt ratios, profitability ratios, growth ratios and structural ratios.Five of them could be easily calculated through the integration ofthe others, which were deleted. The remaining 30 initial ratiosare listed in Table 1, which covers mostly employed features infinancial distress prediction in China (Liang and Wu, 2005; Huaet al., 2007; Ding et al., 2008; Sun and Li, 2008b).
5.2. Data preprocessing
Initial data collected for financial distress prediction tends to beincomplete, noisy, and inconsistent. In the process of outlier elim-ination, sample companies with at least one financial ratio valuemissing were dropped. Companies with financial ratios deviatingfrom the mean value as much as three times of the standard devi-ation were also excluded. Meanwhile, obvious outliers were alsoeliminated by expertise. Final sample companies consist of 81healthy companies and 81 companies in distress at year t-3.
The strategy of dimension reduction by removing irrelevant,weakly relevant or redundant features through ANOVA stepwisemethod was used. Each feature selected was considered to be ofequal importance since feature selection is a specific form of fea-ture weighting. There are several reasons for employing ANOVAstepwise method for feature selection in this research.
(a) Though there are some researches using feature subsetspicked out by domain experts, yet it is a time-consumingtask. Besides, it is also difficult to carry out effectivelybecause the behavior of the data for financial distress predic-tion is not well-known.
(b) Those researches in financial distress prediction that haveemployed ANOVA stepwise method for feature selection,e.g. Lin and McClean (2001); Min et al. (2006), guide thisresearch.
ntal design.

Table 1Initial feature set
Category Variable Features
Profitability X1 Gross income to salesX2 Net income to salesX3 Earning before interest and tax to total assetX4 Net profit to total assetsX5 Net profit to current assetsX6 Net profit to fixed assetsX7 Profit marginX8 Net profit to equity
Activity X9 Account receivable turnoverX10 Inventory turnoverX11 Account payable turnoverX12 Total assets turnoverX13 Current assets turnoverX14 Fixed assets turnover
Short-time liability X15 Current ratioX16 The ratio of cash to current liability
Long-time liability X17 Asset-liability ratiosX18 Equity to debt ratioX19 Ratio of liability to tangible net assetX20 Ratio of liability to market value of equityX21 Interest coverage ratio
Growth X22 Growth rate of primary businessX23 Growth rate of total assets
Structural ratios X24 The proportion of current assets (over totalassets)
X25 The proportion of fixed assets (over totalassets)
X26 The ratio of equity to fixed assetsX27 The proportion of current liability (over total
liability)
Per share items andyields
X28 Earning per shareX29 Net assets per shareX30 Cash flow per share
H. Li, J. Sun / European Journal of Operational Research 197 (2009) 214–224 221
(c) Lin and McClean (2001) have provided some evidence thatdata-oriented filter approach of feature selection, e.g.ANOVA stepwise method, outperforms feature selectionbased on human beings’ judgments.Features that are consid-ered as significantly different between samples in distressand health by ANOVA stepwise method are shown in Table2. From the table we could find that optimal feature subsetis composed of X3, X4, X5, X8, X9, X10, X11, X12, X13,X16, X17, X18, X19, X20, X21, X22, X24, X25, X27, X28,X29, and X30.In order to eliminate impacts on predictiveperformance from different normalization processes, no nor-malization process was employed. It means that the experi-ment in this research was carried out on the basis of originaldata distribution.
5.3. Assessing predictive accuracy
Using all data to get a classifier and then to estimate the accu-racy of the classifier could result in overly optimistic estimate. Inholdout method, the useful data set is divided into a training setand a testing set randomly. The former is utilized to derive a clas-sifier, whose predictive accuracy is estimated with the latter. In V-fold cross validation, useful data are partitioned randomly into Vexclusive subsets with approximately equal size. By holding outone class of the partition as testing set and the remaining as train-ing set each time, V values of the predictive accuracy could be ob-tained. The average of those values is taken as the final predictiveaccuracy. LOO-CV is a special kind of V-fold cross validation in caseV is taken as the number of cases.
One would always like to get information from the performanceof a classifier when it is used for generalization purposes, using
data that do not intervened in the learning dataset. Meanwhile, itis believed that holdout method is biased in assessing predictiveaccuracy. Considering this, we used a hybrid assessing strategyby combining hold-out method and LOO-CV to estimate predictiveaccuracy of various models. We split the whole data into two partsrandomly. One part, which occupies 30%, is used as testing datathat never intervenes in the learning and validating processes.The other one, which occupies 70%, is used as training and validat-ing data. LOO-CV is carried out in training and validating processesto get optimal parameters. This kind of split was carried out for 30times to generate 30 predictive results. On its basis, paired-sam-ples t-test was employed to find whether or not there exists signif-icant difference among various models. As the majority ofresearches in financial distress prediction did, we did not distin-guish Type I error and Type II error. The total predictive accuracywas utilized as optimization objective in training and validating.Total predictive accuracies of hold-out data were used to assesspredictive models.
5.4. Comparative CBR models employed
5.4.1. Euclidean CBR and Manhadun CBRIn Euclidean CBR (ECBR), similarity measure is computed by the
following formula:
SIMab ¼1
1þ
ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiPmk¼1
wkdabkPm
k¼1wk
!2vuut
: ð9Þ
In Manhadun CBR (MCBR), similarity measure is computed in thefollowing way:
SIMab ¼1
1þPm
k¼1wkdabkPm
k¼1wk
: ð10Þ
5.4.2. Grey CBRLet the grey correlation degree between case a and case b be de-
noted as yabk. Let xak and xbk express values of the kth feature ofcase a and b, respectively. Let h(a) express case library without casea, and b, c 2 h(a). The measure of the grey correlation degree be-tween two cases could be computed as follows:
yabk ¼infkjxak � xckj þ 0:5� supkjxak � xckj
dabk þ 0:5� supkjxak � xckj; ð11Þ
where infkjxak � xckj and supkjxak � xckj represent the minimum andmaximum distance of case a and case b ("b 2 h(a)) on the kth fea-ture, respectively. dabk represents the distance between case a andcase b on the kth feature.
Once the grey correlation degree between two cases has beenmeasured, similarity between the two cases could be computed.The grey correlation degree could be transformed into similarityby the following way:
SIMab ¼
ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiXm
k¼1
wkyabkPmk¼1wk
� �2vuut : ð12Þ
5.5. Model implementation and parameters searching
The predictive models were implemented using Matlab. Thedimension reduction process of ANOVA was realized using SPSS.All features employed were put on equal importance since featureselection is a specific form of feature weighting. To search optimalparameters of the corresponding models in the process of LOO-CV,the standard technique of grid-search was employed. For the

Table 2ANOVA output
Category Variable Mean (health) SD (health) Mean (distress) SD (distress) F Sig.
Profitability X1 0.2516 0.1373 0.2559 0.1516 0.036 0.849X2 0.0791 0.1054 0.0564 0.7611 0.071 0.791X3 0.0577 0.0487 0.0395 0.0468 5.893 0.016**
X4 0.0357 0.0410 0.0188 0.0450 6.238 0.014**
X5 0.0765 0.0971 0.0345 0.0684 10.10 0.002***
X6 0.2204 0.4054 0.1158 0.4993 2.140 0.145X7 0.8158 0.1342 0.7868 0.8155 0.099 0.753X8 0.0644 0.0775 0.0361 0.1023 3.939 0.049**
Activity X9 15.602 47.324 5.5249 10.184 3.510 0.063*
X10 4.6350 4.3574 2.7678 2.5661 11.04 0.001***
X11 11.2399 10.6976 6.1088 5.5320 14.70 0.000***
X12 0.5465 0.4129 0.3496 0.2304 14.04 0.000***
X13 1.0715 0.6644 0.6039 0.4170 28.78 0.000***
X14 3.5699 6.3878 2.4497 3.7608 1.850 0.176
Short-time liability X15 1.6576 0.6513 1.5533 0.7460 0.899 0.345X16 0.2140 0.3057 0.0147 0.1730 26.08 0.000***
Long-time liability X17 0.3934 0.1358 0.4820 0.1442 16.17 0.000***
X18 1.8476 1.2786 1.3369 1.2103 6.815 0.10*
X19 0.8635 0.5927 1.3371 0.8666 16.48 0.000***
X20 183.47 144.56 243.88 170.51 5.915 0.016**
X21 8.5323 12.662 3.5785 4.2432 11.15 0.001***
Growth X22 0.3354 1.4424 0.0055 0.6732 3.481 0.064*
X23 0.1383 0.4194 0.1909 0.3389 0.771 0.381
Structural ratios X24 0.5320 0.1926 0.6129 0.1516 8.844 0.003***
X25 0.3468 0.1877 0.2613 0.1354 11.06 0.001***
X26 3.5026 6.1163 3.1899 4.6148 0.135 0.714X27 0.8825 0.1515 0.9217 0.1101 3.558 0.061*
Per share items and yields X28 0.1631 0.1860 0.0810 0.1873 7.821 0.006***
X29 2.6917 0.9426 2.4290 0.9930 2.982 0.086*
X30 0.2481 0.3479 0.0341 0.4135 12.70 0.000***
* Significant at the level of 10%.** Significant at the level of 5%.*** Significant at the level of 1%.
Table 4t-Values of pairwise comparative models by total accuracy
ECBR MCBR GCBR Electre-CBR-I
MCBR �1.642a 1 – –GCBR �2.076** �1.511 1 –ELECTRE-CBR-I �4.785*** �4.090*** �2.957*** 1ELECTRE-CBR-II �3.662*** �2.814*** �1.775* 2.811***
a A t-value.* Significant at the level of 10%.** Significant at the level of 5%.*** Significant at the level of 1%.
222 H. Li, J. Sun / European Journal of Operational Research 197 (2009) 214–224
hybrid model of Electre-CBR, parameters of qk, pk, vk were, respec-tively, determined by the three range thresholds, i.e. q, p, v. Thiscould be found from the definition of range threshold. Thus, grid-search technique was employed to search optimal values of thethree parameters. q was searched in the range of [0,0.1] by stepsof 0.02. p was searched in the range of [0.3,1] by steps of 0.1.And v was searched in the range of [p,1] by steps of 0.1 sincev > p in the definition. When determining the number of the near-est neighbors, we followed Pan et al.’s (2007) approach. For all theCBRs, we tried 1-NN, 3-NN, 5-NN, 7-NN, 9-NN, 11-NN, 13-NN, and15-NN to find the optimal KNN for financial distress prediction.
6. Empirical results and analysis
In this section, predictive abilities of the five CBR models arecompared. Table 3 lists total predictive accuracies on each model.Paired-samples t-test was utilized to examine whether there isany significant difference on predictive performance of each mod-el. Table 4 shows the results of significance test for pairwise com-parisons of predictive performance between models by totalaccuracy.
Table 3Means of total accuracy obtained with comparative models on 30 data sets
Models ECBR MCBR GCBR Electre-CBR-I Electre-CBR-II
Minimum 58.33 60.42 56.25 58.33 56.25Maximum 72.92 75.00 81.25 83.33 83.33Mean 66.60 67.30 69.24 71.81 70.63
From Table 3 we could find that Electre-CBR-I produces highertotal predictive accuracy than Electre-CBR-II, GCBR, MCBR, andECBR by 1.18%, 2.57%, 4.51%, and 5.21%, respectively. The highestpredictive accuracies of the two Electre-CBR models are both83.33%. As Table 4 shows, predictive accuracy of Electre-CBR-I isstatistically better than those of Electre-CBR-II, GCBR, MCBR, andECBR at the significant level of 1%. Predictive accuracy of Electre-CBR-II is significantly better than that of GCBR at the level of10%, and significantly better than those of MCBR and ECBR at thelevel of 1%. There are no significant differences between predictiveaccuracies of ECBR-MCBR, and MCBR-GCBR.
Both Electre-CBR-I and Electre-CBR-II produce higher predictiveperformance than the other three CBR models in the experiment. Ittestifies the effectiveness of the hybrid models and their applicabil-ity in financial distress prediction. In predictive performance com-parison between Electre-CBR-I and Electre-CBR-II, the formeroutperforms the latter on predictive accuracy. The main differencebetween Electre-CBR-I and Electre-CBR-II is that veto relations are

H. Li, J. Sun / European Journal of Operational Research 197 (2009) 214–224 223
introduced in the latter to partition the space of strong differencein detail. Maybe this process reduces total predictive accuracy byover-fitting the training data and validating data. In order to verifythis assumption, we employ all data and used the assessment ofLOO-CV to find whether or not Electre-CBR-II outperforms Elec-tre-CBR-I by over-fitting training data and validating data. Theoptimal KNN for Electre-CBR-I is 9-NN, and the corresponding pre-dictive accuracy is 72.84%. Predictive accuracy of Electre-CBR-II,which introduces evidence vetoing the assertion that two objectsare indifferent, is 73.46%. The improved predictive accuracy maypossibly result from over-fitting the training and validating data.
7. Conclusion and remarks
The conclusion of this study is that the two hybrid data miningmodels for financial distress prediction, i.e. Electre-CBR-I and Elec-tre-CBR-II, could produce acceptable predictive performance. Pre-dictive performance of the CBR system in long-term financialdistress prediction has been improved significantly, under theassessment of 30-times’ hold-out data. It testifies the possibilityof applying some techniques of the decision-aiding approach ofElectre into the area of data mining. Fundamental principles ofElectre and how to extend them into CBR are presented in detail.We generate two hybrid models of Electre-CBR. The first one,named Electre-CBR-I, is developed on the basis of evidence sup-porting the assertion that two objects are indifferent. The otherone, named Electre-CBR-II, is developed on the basis of evidencesupporting and vetoing the assertion that two objects areindifferent.
In this research, we use outranking relations for CBR in threeways. We first adopt an indifference indicator deriving from indif-ference relations, weak difference relations, and strong differencerelations as similarity measure mechanism. Second, we use a vetoindicator deriving from non-veto relations, weak veto relations,and strong veto relations to enhance the mechanism of similaritymeasure between two cases. Third, we utilize the principle of k-nearest neighbor to generate a prediction for financial distressbased on outranking indicators. 30-times hold-out method is em-ployed to assess predictive performance of various CBR models.This assessment is combined by hold-out method and LOO-CV.Dataset is divided into training dataset, validating dataset, andtesting dataset. Training data and validating data are employedin LOO-CV to obtain optimal parameters of models. Testing datasetis used to assess predictive performance of the correspondingmodels. From the results of the experiment, it could be found thatthe two hybrid CBRs, i.e. Electre-CBR-I and Electre-CBR-II, offer aviable approach for financial distress prediction. Empirical resultsshow that they offer significantly better predictive performancethan the three CBR models respectively derived from Euclideanmetric, Manhadun metric, and grey coefficient metric.
Note that we carried out the experiment on the basis of initialdata distributions, with optimal feature subset produced by the fil-ter approach of one way ANOVA, and with data of year t-3. All con-clusions drawn out should be considered under the circumstanceof experiment design. At the same time, data we collected is toidentify long-term financial distress not bankruptcy, namely threeyears ahead of distress. Thus, there may be less volume of signalsthat could be used to distinguish companies in distress from com-panies in health than to distinguish bankrupt companies fromhealthy companies. It maybe the main reason that the average va-lue of predictive accuracies of each CBR model is around 70%. Thisresearch also has some limitations. There are some other factorsthat could enhance the predictive ability of a CBR system. Predic-tive performance of CBR may be improved if some optimizationalgorithms are employed for feature weighting, though it is not al-ways the case. Of course, the generalization of the enhanced model
of CBR by outranking relations should be tested further more byapplying it into other problem domains or using data for financialdistress or bankruptcy prediction from other counties.
Acknowledgements
This research is partially supported by the National Natural Sci-ence Foundation of China (#70801055) and the Zhejiang ProvincialNatural Science Foundation of China (No. Y607011). The authorsgratefully thank anonymous referees for their useful comments.Meanwhile, we thank Ms. Zhe Li and Ms. Ying Li for their help inchecking the manuscript for us.
References
Altman, E., 1968. Financial ratios discriminant analysis and the prediction ofcorporate bankruptcy. Journal of Finance 23, 589–609.
Back, B., Laitinen, T., Sere, K., 1996. Neural network and genetic algorithm forbankruptcy prediction. Expert Systems with Applications 11, 407–413.
Beaver, W., 1966. Financial ratios as predictors of failure. Journal of AccountingResearch 4, 71–111.
Bi, J., Bennett, K., Embrechts, M., et al., 2003. Dimensionality reduction viasparse support vector machines. Journal of Machine Learning Research 3,1229–1243.
Bouyssou, D., Pirlot, M., 2005. A characterization of concordance relations. EuropeanJournal of Operational Research 167, 427–443.
Brans, J.P., Vincke, Ph., 1985. A preference ranking organization method: ThePromethee method for multiple criteria decision making. Management Science31, 647–656.
Brown, C.E., Gupta, U., 1994. Applying case-based reasoning to the accountingdomain. Intelligent Systems in Accounting, Finance and Management 3, 205–221.
Bryant, S.M., 1997. A case-based reasoning approach to bankruptcy predictionmodeling. Intelligent Systems in Accounting, Finance and Management 6, 195–214.
Chen, L.-H., Hsiao, H.-D., 2008. Feature selection to diagnose a business crisis byusing a real GA-based support vector machine: An empirical study. ExpertSystems with Applications 35 (3), 1145–1155.
Ding, Y.-S., Song, X.-P., Zen, Y.-M., 2008. Forecasting financial condition of Chineselisted companies based on support vector machine. Expert Systems withApplications 34, 3081–3089.
Guyon, I., Elisseeff, A., 2003. An introduction to variable and feature selection.Journal of Machine Learning Research 3, 1157–1182.
Han, J.-W., Kamber, M., 2001. Data Mining Concepts and Techniques. MorganKaufman, San Mateo.
Hand, D., Mannila, H., Smyth, P., 2001. Principles of Data Mining. MIT Press,Cambridge.
Hua, Z.-S., Wang, Y., Xu, X.-Y., et al., 2007. Predicting corporate financial distressbased on integration of support vector machine and logistic regression. ExpertSystems with Applications 33, 434–440.
Hui, X., Sun, J., 2006. An application of support vector machine to companies’financial distress prediction. In: Torra, V., Narukawa, Y., Valls, A., et al. (Eds.),Modeling Decisions for Artificial Intelligence. Springer-Verlag, Berlin, pp. 274–282.
Jo, H., Han, I., 1996. Integration of case-based forecasting, neural network, anddiscriminant analysis for bankruptcy prediction. Expert Systems withApplications 11, 415–422.
Jo, H., Han, I., Lee, H., 1997. Bankruptcy prediction using case-based reasoning,neural network and discriminant analysis for bankruptcy prediction. ExpertSystems with Applications 13, 97–108.
Kim, K.-J., 2004. Toward global optimization of case-based reasoning systems forfinancial forecasting. Applied Intelligence 21, 239–249.
Kolodner, J.L., 1993. Case-Based Reasoning. Morgan Kaufman, San Francisco.Kumar, P.R., Ravi, V., 2007. Bankruptcy prediction in banks and firms via statistical
and intelligent techniques – A review. European Journal of Operational Research180, 1–28.
Li, H., Sun, J., 2008. Ranking-order case-based reasoning for financial distressprediction. Knowledge-Based Systems. doi:10.1016/j.knosys.2008.03.047.
Liang, L., Wu, D., 2005. An application of pattern recognition on scoring Chinesecorporations financial conditions based on back propagation neural network.Computers & Operations Research 32, 1115–1129.
Li, H., Sun, J., Sun, B., 2007. Financial distress prediction based on OR-CBR in theprinciple of k-nearest neighbors. Expert Systems with Applications.doi:10.1016/j.eswa.2007.09.038.
Lin, F.-Y., McClean, S., 2001. A data mining approach to the prediction of corporatefailure. Knowledge-Based Systems 14, 189–195.
Lin, R.-H., Wang, Y.-T., Wu, C.-H., et al., 2007. Developing a business failureprediction model via RST, GRA and CBR. Expert Systems with Applications.doi:10.1016/j.eswa.2007.11.068.
Martin, D., 1977. Early warning of bank failure: A Logit regression approach. Journalof Banking and Finance 1, 249–276.

224 H. Li, J. Sun / European Journal of Operational Research 197 (2009) 214–224
Min, S.-H., Lee, J.-M., Han, I., 2006. Hybrid genetic algorithms and support vectormachines for bankruptcy prediction. Expert Systems with Applications 31, 652–660.
Odom, M., Sharda, R., 1990. A neural networks model for bankruptcy prediction. In:Proceedings of International Joint Conference on Neural Networks, San Diego,CA, pp. 163–168.
Pal, S.K., Shiu, S., 2004. Foundations of Soft Case-Based Reasoning. Wiley, NewJersey.
Pan, R., Yang, Q., Pan, J., 2007. Mining competent case bases for case-basedreasoning. Artificial Intelligence 171, 1039–1068.
Park, C.-S., Han, I., 2002. A case-based reasoning with the feature weights derived byanalytic hierarchy process for bankruptcy prediction. Expert Systems withApplications 23, 255–264.
Roy, B., 1971. Problems and methods with multiple objective functions.Mathematical Programming 1, 239–266.
Roy, B., 1991. The outranking approach and the foundations of ELECTRE methods.Theory and Decision 31, 49–73.
Roy, B., 1996. Multicriteria Methodology for Decision Aiding. Kluwer AcademicPublishers, Dordrecht.
Roy, B., Słowinski, R., 2008. Handling effects of reinforced preference and counter-veto in credibility of outranking. European Journal of Operational Research 188,185–190.
Roy, B., Vincke, P., 1984. Relational systems of preference with one or morepseudo-criteria: Some new concepts and results. Management Science 30,1323–1335.
Schank, R., 1982. Dynamic Memory. Cambridge University Press, New York.Schank, R., Abelson, R., 1977. Scripts, Plans, Goals and Understanding. Erlbaum
Hillsdale, New Jersey.Shin, K.-S., Lee, T.-S., Kim, H.-J., 2005. An application of support vector machines in
bankruptcy prediction model. Expert Systems with Applications 28, 127–135.Shiu, S.C.K., Pal, S.K., 2004. Case-based reasoning: Concepts, features and soft
computing. Applied Intelligence 21, 233–238.Slowinski, R., Stefanowski, J., 1994. Rough classification with valued closeness
relation. In: Diday, E., Lechevallier, Y., Schrader, M., et al. (Eds.), New
Approaches in Classification and Data Analysis. Springer-Verlag, Berlin, pp.482–489.
Slowinski, R., Stefanowski, J., 1996. Rough set reasoning about uncertain data.Fundamenta Informaticae 27, 229–243.
Smet, Y.D., Guzman, L.M., 2004. Towards multicriteria clustering: An extension ofthe k-means algorithm. European Journal of Operational Research 158, 390–398.
Sun, J., Hui, X.-F., 2006. Financial distress prediction based on similarity weightedvoting CBR. In: Li, X., Zaiane, R., Li, Z. (Eds.), Advanced Data Mining andApplications. Springer-Verlag, Berlin, pp. 947–958.
Sun, J., Li, H., 2007. Financial distress early warning based on group decisionmaking. Computers & Operations Research. doi:10.1016/j.cor.2007.11.005.
Sun, J., Li, H., 2008a. Data mining method for listed companies’ financial distressprediction. Knowledge-Based Systems 21, 1–5.
Sun, J., Li, H., 2008b. Listed companies’ financial distress prediction based onweighted majority voting combination of multiple classifiers. Expert Systemswith Applications 35 (3), 818–827.
Takeda, E., 2001. A method for multiple pseudo-criteria decision problems.Computers & Operations Research 28, 1427–1439.
Vincke, Ph., 1986. Analysis of MCDA in Europe. European Journal of OperationalResearch 25, 160–168.
Watson, I., 1999. Case-based reasoning is methodology, not a technology.Knowledge-Based Systems 12, 303–308.
Witten, I.H., Frank, E., 2000. Data Mining: Practical Machine Learning Tools andTechniques with Java Implementations. Morgan Kaufman, San Francisco, CA.
Yip, A., Deng, H., 2003. A case-based reasoning approach to business failureprediction. In: Palade, V., Howlett, R.J., Jain, L.C. (Eds.), Knowledge-BasedIntelligent Information and Engineering Systems. Springer-Verlag, Berlin, pp.1075–1080.
Yip, A., 2004. Predicting business failure with a case-based reasoning approach. In:Negoita, M., Howlett, R., Jain, L., et al. (Eds.), Knowledge-Based IntelligentInformation and Engineering Systems. Springer-Verlag, Berlin, pp. 665–671.
Zhou, Z.-H., 2003. Three perspectives of data mining. Artificial Intelligence 143,139–146.