html and xml - york university · html and xml xml stands for extensible markup language ... one or...
TRANSCRIPT

HTML and XML
XML stands for eXtensible Markup Language HTML is used to mark up text so it can be displayed to users
XML is used to mark up data so it can be processed by computers
HTML describes both structure (e.g. <p>, <h2>, <em>) and appearance (e.g. <br>, <font>, <i>)
XML describes only content, or “meaning”
HTML uses a fixed, unchangeable set of tags
In XML, you make up your own tags

XML.. XML is a meta-language With HTML, existing markup is static: <HEAD> and <BODY>
for example, are tightly integrated into the HTML standard and cannot be changed or extremely difficult extended.

XML.. XML is a meta-language With HTML, existing markup is static: <HEAD> and <BODY>
for example, are tightly integrated into the HTML standard and cannot be changed or extremely difficult extended.
XML, on the other hand, allows ou to create your own markup tags and configure each to your liking: for example <WebEngHeading> <WebEngSummary>
<WebEngReallyWildFont>
Each of these elements can be defined through user defined document type definitions (DTD) and stylesheets are applied to one or more XML documents.
There are no ‘correct’ tags for an XML document, except those defined by the author

Some Code Schema Entity
Passport Details SubEntities
Last Name First Name Address
Entity
Address SubEntities
Street City Town State Province ……..

<!ELEMENT passport_details (last_name,first_name+,address)> <!ELEMENT last_name (#PCDATA)> <!ELEMENT first_name (#PCDATA)> <!ELEMENT address
(street,(city|town),(state|province),(ZIP|postal_code),country,contact_no?,email*)> <!ELEMENT street (#PCDATA)> <!ELEMENT city (#PCDATA)> <!ELEMENT town (#PCDATA)> <!ELEMENT state (#PCDATA)> <!ELEMENT province (#PCDATA)> <!ELEMENT ZIP (#PCDATA)> <!ELEMENT postal_code (#PCDATA)> <!ELEMENT country (#PCDATA)> <!ELEMENT phone_home (#PCDATA)> <!ELEMENT email (#PCDATA)>
DTD

Internal DTD and Instance <?xml version='1.0'?> <!DOCTYPE passport_details [ <!ELEMENT passport_details
(last_name,first_name+,address)> <!ELEMENT last_name (#PCDATA)> <!ELEMENT first_name (#PCDATA)> <!ELEMENT address
(street,(city|town),(state|province) ,(ZIP|postal_code),country,contact_no?,email*)> <!ELEMENT street (#PCDATA)> <!ELEMENT city (#PCDATA)> <!ELEMENT town (#PCDATA)> <!ELEMENT state (#PCDATA)> <!ELEMENT province (#PCDATA)> <!ELEMENT ZIP (#PCDATA)> <!ELEMENT postal_code (#PCDATA)> <!ELEMENT country (#PCDATA)> <!ELEMENT phone_home (#PCDATA)> <!ELEMENT email (#PCDATA)> ]>
<passport_details> <last_name>Smith</last_name> <first_name>Jo</first_name> <first_name>Stephen</first_name> <address> <street>1 Great Street</street> <city>GreatCity</city> <state>GreatState</state> <postal_code>1234</postal_code> <country>GreatLand</country> <email>[email protected]</email> </address> </passport_details>

Shared DTD XML Document specifies the DTD <?xml version='1.0'?> <!DOCTYPE passport_details SYSTEM "PassportExt.dtd"> <passport_details> <last_name>Smith</last_name> <first_name>Jo</first_name> <first_name>Stephen</first_name> <address> <street>1 Great Street</street> <city>GreatCity</city> <state>GreatState</state> <postal_code>1234</postal_code> <country>GreatLand</country> <email>[email protected]</email> </address> </passport_details>

XML Examples
XML Source File http://www.yorku.ca/jhuang/xml/04.adhoc.topics.xml
XML Style language
http://www.yorku.ca/jhuang/xml/04.adhoc.topics.xsl
Parsing and rendering XML with IE5+
http://www.yorku.ca/jhuang/xml/04.adhoc.topics_xsl.xml

XML Applications XML permits document authors to create markup for
virtually any type of information.
Authors can create entirely new markup languages for describing specific types of data, including mathematical formulas, chemical molecular structures, music, recipes etc.
- XHTML - VoiceXML (for speech) - MathML (for mathematics) - SMIL (the Synchronous Multimedia Integration Language, for
multimedia presentations) - CML (Chemical Markup Language, for chemistry) - XBRL (Extensible Business Reporting Language, for financial
data exchange)

XML Parsers Processing an XML document requires a software program
called an XML parser (or processer). These are available at no charge in many languages (Java, Python, C++ etc.).
http://www.xml.com/programming/ Parsers check an XML documents syntax and enable software
programs to process marked-up data. XML parsers can support the Document Object Model (DOM) or the Simple API for XML (SAX).
DOM: Build a tree structure containing the XML document’s data
SAX: Process the document and generate events

In Brief .. XML is for Data Exchange • Very frequently companies need to exchange data among dissimilar systems, locations, software, hardware, data formats etc.
• Data stored in different formats - Data that is not stored in databases (unstructured data) is difficult to exchange and often require custom software
• Data can be interchanged in various ways - agree on a totally custom format - agree on a proprietary system - using standard data format • XML provides a standardised format for data and techniques for generating, validating, formatting, transforming and extracting it

When Do You Use It?
• XML is good for exchanging data between dissimilar systems
• If data exchange only occurs between similar systems,
XML may not be the right choice!

B2B • XML is frequently used in B2B applications - B2B means that two companies are exchanging data - also one company exchanging data between different locations - agreement on the format (through DTD, XML Schema) of messages
B2C • Business-to-Consumer involves sending XML directly to the client • Data sent directly to the client needs a style (XSL) applied • Applying style is best accomplished on the server side

• Three distinct parts - Prolog <?xml version=“1.0” encoding=“UTF-8”?> - Root Element - Miscellaneous Section • Prolog contains instructions that apply to the entire document (such as XML declaration, DTD) • Root element is a single element that encloses all of the data • Miscellaneous is not recommended but still included in the standard
Document Structure
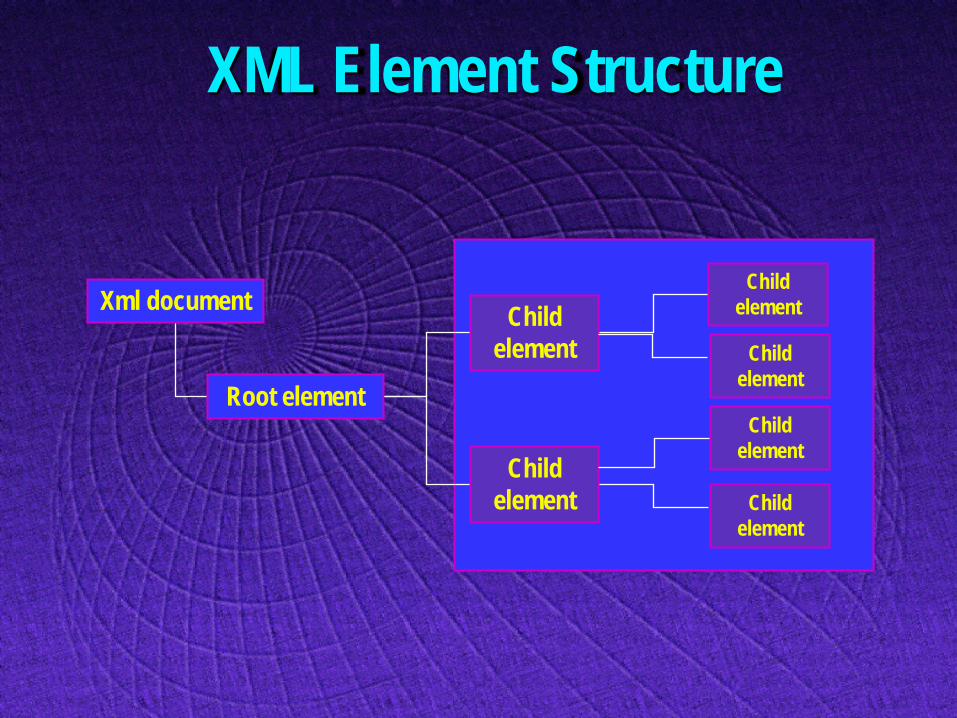
Xml document
Root element
Child element
Child element
Child element
Child element
Child element
Child element
XML Element Structure

- have the same overall structure - can contain sub-elements
XML Elements
<Student Sex = “Male” > Some Data </Student> START TAG ELEMENT
END TAG CONTENTS
ATTRIBUTE
NAME
PCDATA (Parsed Character Data)

Element vs. Attribute based XML <student id = “9906789”> <name>Adam</name> <email>[email protected]</email> </student>
<student id = “9906789” name=“Adam email=“[email protected]”> </student>
<student> <id> 9906789 </id> <name>Adam</name> <email>[email protected]</email> </student>
1 2
3
Which is better? NO RIGHT ANSWER! Some issues to consider
- elements can have substructures; but not attributes
- ID attributes can be easily located and processed

<?xml version = "1.0"?> <!-- article.xml --> <books> <author> <title> Introduction to Computer Graphics </title> <date>1995</date> <fname>James</fname> <lname>Foley</lname> </author> <author> <title> Principles of Database Systems </title> <date month="February” >2000</date> <fname>Greg</fname> <lname>Riccardi</lname> </author> </books> <!- - This is a list of students - ->
XML Document (another sample .xml file)
root element
attribute
• The document structures data with ‘books’ element as the root node. • Root node contains elements (e.g. author)
• Each element further contains child nodes that describe data
• <books>,<author>,<title> etc. are customised tags describing data.
prolog
Miscellaneous

XML Syntax • XML elements must be enclosed within start and end tags <title> Introduction to Computer Graphics </title> If there is no data inside the element, tag can end with ‘/>’ <title/> which is same as <title> </title> • Element attributes must be enclosed within double quotes: <date month="February” >2000</date> • Element tags are case sensitive <author> Adam </Author> is incorrect
• XML tags must be nested in correct order: <books> <author> … </books> </author> Bad <books> <author> … </author> </books> Good XML is therefore very rigid in enforcing syntax compared to HTML (which is very forgiving) • A “well formed” documents follows all these rules

DTD: Document Type Definition • The XML sample document shown earlier follows syntax rules only. It is therefore called a well-formed document
• It can also be made to follow strict grammar rules for enforcing the structure
• DTD specifies grammar rules for an XML document
- several XML documents prepared from various sources can be validated using a single set of grammar rules
• An XML document that adheres to a DTD is called valid. A valid document has stronger structure than a well-formed document
• DTD specifies rules for elements (child nodes) and how it can be expanded into sub elements (child nodes)
• DTD consists - Element declarations, Attribute list, Data types etc.
• DTDs are based on SGML; difficult to create!

DTD Nested Elements <!ELEMENT author (date, title, fname, lname)> • The author grammar indicates that it is made up of four elements defined as below:
<!ELEMENT date (#PCDATA)> <!ELEMENT title (#PCDATA)> <!ELEMENT fname (#PCDATA)> <!ELEMENT lname (#PCDATA)>
• Each element may have attributes that contains information about its content
e.g. <date month="February” >2000</date>
• An element’s attribute list can be defined using ATTLIKST tag: syntax: <!ATTLIST element_name attribute_name type default_value> <!ATTLIST date month CDATA #IMPLIED>
Specifies the month attribute of the element date. CDATA means that it is a character string. #IMPLIED means - the attribute is optional. If it is not specified the system provides a value. Other options: #REQUIRED: the XML author must provide the attribute value #FIXED: the attribute value is fixed and can not be modified by the user
Define the list
CDATA in non-parsed

External DTD in XML document • Any external DTD specification can be used by several XML documents Example: <!DOCTYPE books SYSTEM "author.dtd">
books is the root element of the document. SYSTEM specifies the DTD file.
<!-- DTD for books: author.dtd --> <!ELEMENT books (author+)> <!ELEMENT author (date, title, fname, lname)> <!ELEMENT date (#PCDATA)> <!ATTLIST date month CDATA #IMPLIED> <!ELEMENT title (#PCDATA)> <!ELEMENT fname (#PCDATA)> <!ELEMENT lname (#PCDATA)> <!DOCTYPE books SYSTEM "author.dtd">
<books> <author> <date>1995</date> <title> Introduction to Computer Graphics </title> <fname>James</fname> <lname>Foley</lname> </author> ….. </books>
author.dtd
authorDtd.xml using a DTD
External subset (specified in XML using SYSTEM or PUBLIC keywords)
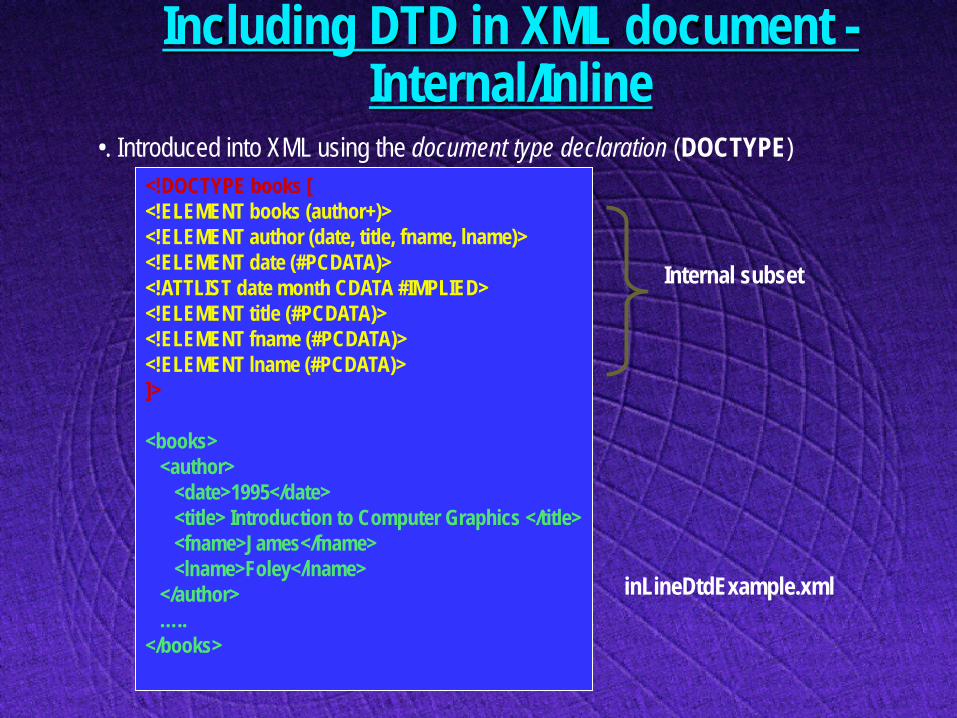
Including DTD in XML document - Internal/Inline
•. Introduced into XML using the document type declaration (DOCTYPE) <!DOCTYPE books [ <!ELEMENT books (author+)> <!ELEMENT author (date, title, fname, lname)> <!ELEMENT date (#PCDATA)> <!ATTLIST date month CDATA #IMPLIED> <!ELEMENT title (#PCDATA)> <!ELEMENT fname (#PCDATA)> <!ELEMENT lname (#PCDATA)> ]> <books> <author> <date>1995</date> <title> Introduction to Computer Graphics </title> <fname>James</fname> <lname>Foley</lname> </author> ….. </books>
inLineDtdExample.xml
Internal subset

DTDs - Disadvantages • Notoriously hard to read • Difficult to create (written in non-XML syntax; uses EBNF - Extended Backus-Naur Form - grammar) • No support for namespaces etc. • Limited data types (PCDATA, CDATA)
Alternative to DTDs - XML Schemas • also referred as XSchema
• Easy to create and read (Well-formed XML syntax) • can be edited using XML tools • Support for namespaces • More data types (byte, float, long; time, date; binary ..) • User-defined data types (Facets are properties used to specify a data type, setting limits and boundaries on data values)
If time permits – covered towards the end
Also study ANY, EMPTY, Mixed Content
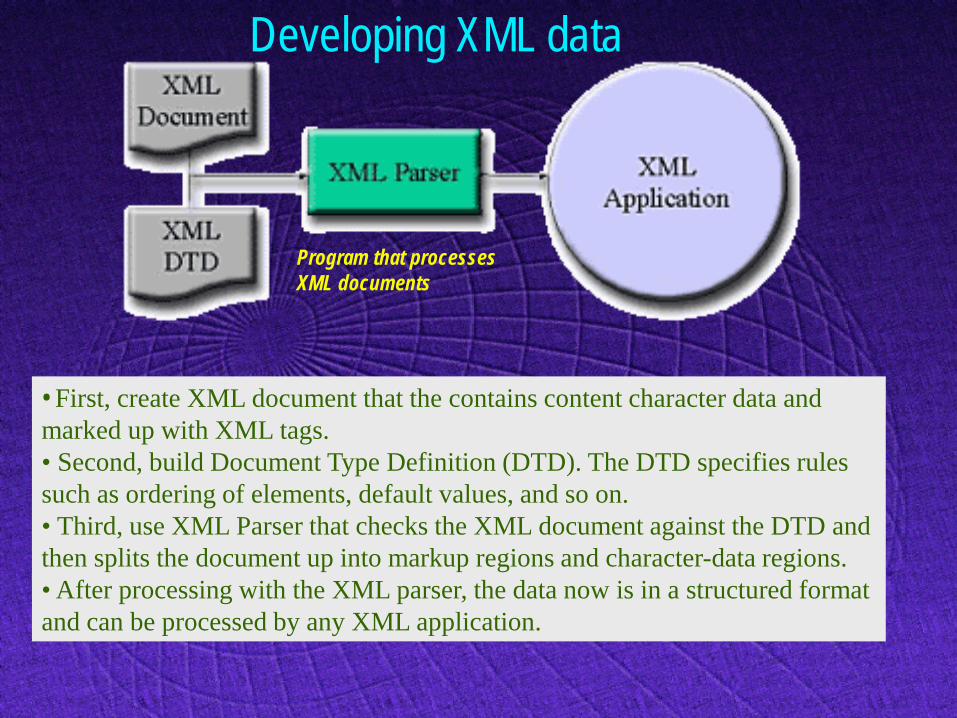
Developing XML data
• First, create XML document that the contains content character data and marked up with XML tags. • Second, build Document Type Definition (DTD). The DTD specifies rules such as ordering of elements, default values, and so on. • Third, use XML Parser that checks the XML document against the DTD and then splits the document up into markup regions and character-data regions. • After processing with the XML parser, the data now is in a structured format and can be processed by any XML application.
Program that processes XML documents
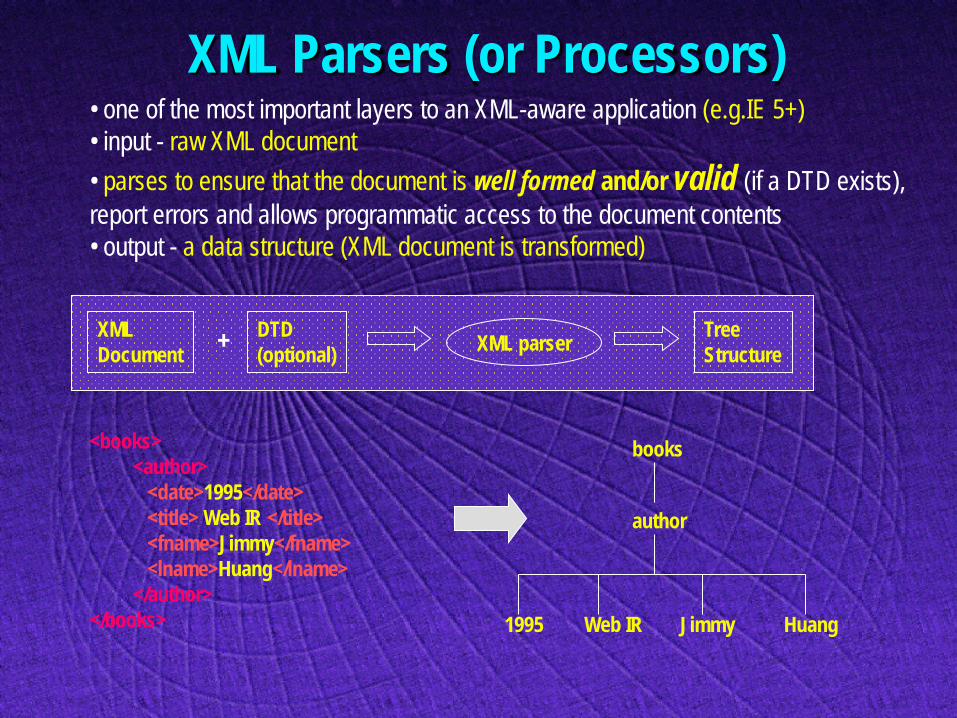
XML Parsers (or Processors) • one of the most important layers to an XML-aware application (e.g.IE 5+) • input - raw XML document • parses to ensure that the document is well formed and/or valid (if a DTD exists), report errors and allows programmatic access to the document contents • output - a data structure (XML document is transformed)
XML Document
DTD (optional) + XML parser Tree
Structure
<books> <author> <date>1995</date> <title> Web IR </title> <fname>Jimmy</fname> <lname>Huang</lname> </author> </books>
books
author
1995 Web IR Jimmy Huang

Parsing XML Documents
• Parsers can support the Document Object Model (DOM) and Simple API for XML (SAX) for accessing document’s content programmatically using languages such as Java, C, C++, Python etc.
• A DOM based parser builds a tree structure containing the XML document’s data in memory.
(used to create and modify XML documents)
• A SAX based parser processes the document and generates events (I.e. notifications to the application) when tags, comments etc. are encountered. These events return data from the XML document. (used to read XML documents only; SAX is attractive for handling large documents because it is not required to load the entire document)

DOM (Document Object Model) • A DOM-based parser exposes a programmatic library called the DOM API that allows data in an XML document to be accessed and modified by manipulating the nodes in a DOM tree. DOM API is available in many languages e.g. JavaScript. • Data can be accessed quickly as all the document’s data is in memory. • The DOM interfaces for creating and manipulating XML documents are platform and language dependant. DOM parsers exist for Java, C, C++, Python and Perl.
• JDOM provides a higher-level API than the W3C DOM for working with XML documents in Java. See www.jdom.org
- provides full tree representation of the XML document
- allows random access to any node
- provides a variety of output formats
- less memory intensive than DOM API
• In order to use DOM API, programming experience is required.

SAX (Simple API for XML) • Developed by the members of the XML-DEV mailing list • Released in May 1998 • SAX and DOM are totally different APIs for accessing information in XML documents. • SAX based parsers invoke methods when markup (e.g. a start tag, end tag etc.) is encountered. With this event based model, no tree structure is created to store data. Instead, data is passed to the application from the XML document as it is found. => greater performance and less memory overhead than with DOM • Many DOM parsers use a SAX parser to retrieve data for building the DOM tree. • SAX parsers are typically used for reading documents that will not be modified.

Parsing (msxml) and rendering XML with IE
• XML document contains data, NOT formatting information. • When XML document is loaded into IE5+, the document is parsed by msxml. • If the document is well-formed, the parser makes the document’s data available to the application (I.e. IE5). • The application can format and render the data and also perform other processing. • IE5 renders data by applying a stylesheet that formats and colours the markup identically to the original document. • Notice the - sign. It indicates that child elements are visible. When clicked, it becomes + hiding the children. • This behaviour is similar to viewing disk directory structure using a program such as Windows Explorer.

Using XML: How does browser read XML ?
XML parser: A tool for reading XML documents.
To manipulate an XML document, you need an XML parser. The parser loads the document into your computer's memory. Once the document is loaded, its data can be manipulated using the DOM. The DOM treats the XML document as a tree.
Once you have installed Internet Explorer 5.0, the Microsoft XML parser is available.
http://www.w3schools.com/xml/xml_parser.asp
Netscape will support XML metadata in Communicator/Navigator 5.0.

Using XML: Presenting Data
Need to convert XML tags into appropriate HTML tags for use in a browser!!
<lastname>Smith</lastname>
<b>Smith</b> Smith

Extensible Stylesheet Language (XSL)
• XML is just data - no presentation information
• To present the data on the screen or paper or any media - apply appropriate style
• Style sheets contain rules that instruct the processor how to present elements
• Two style languages: CSS (Cascading Style Sheets) and XSL
• XSL is powerful than CSS and an excellent solution to control the presentation of data - resource intensive: memory and processing power
- complex to write
• transforms and translates XML data from one format into another same document needed to be displayed in HTML, PDF and postscript form

CSS and XSL
CSS - Cascading Style Sheets can predefined HTML display (font etc) these are shared and reused
XSL - XML Style language
predefine display characteristics for XML entities
transform into CSS for browsers to use

Cascading Style Sheets
CSS last_name { font-family: verdana, arial; font-size: 15pt; font-weight:bold; display: block; margin-bottom: 5pt; } first_name { font-family: verdana, arial; font-size: 15pt; font-weight:bold; display: block; margin-bottom: 5pt; }
street, city, town, state, province, ZIP, postal_code {
font-family: verdana, arial; font-size: 12pt; font-weight:bold; color:green; display:block; margin-bottom: 20pt; margin-top: 40pt; } email { font-family: verdana, arial; font-size: 12pt; font-weight:bold; color:blue; display:block; margin-top: 5pt; }

Extensible Stylesheet Language (XSL)
• XSL provides a complete separation of data or content and presentation, and provides a method to translate data into a PDF or HTML document.
• XSL is a combination of two languages: * XSLT(Extensible Stylesheet Language Transformation): defines rules for transforming an XML document into another format * XSLFO (XSL Formatting Objects): specific XSL instructions that describe how content should be rendered; sophisticated version of CSS; formatting of <h1>,<table> tags can be set
• http://www.w3.org/Style/XSL

XSLT • XSLT is a declarative language for transforming XML documents into other
• once an XML document is parsed, it is transformed through XSLT that is, XSL textual stylesheet and a textual XML document are merged together to produce data formatted according to the stylesheet.
XML document
XML stylesheet (XSLT)
XSLT processor XML document (another text-based format)
• XSLT Processors - selection criteria: speed of transformation and conformity to the XSL and XSLT specifications
• some widely used parsers: * Apache Xalan, Oracle XSL Processor, Lotus XSL Processor, James Clark’s XT, Keith Visco’s XSL:P, Michael Kay’s SAXON, Microsoft XSL processor (built into IE 5)

<?xml version='1.0'?> <xsl:stylesheet xmlns:xsl="http://www.w3.org/TR/WD-xsl" xmlns="http://www.w3.org/TR/REC-html40" result-ns=""> <xsl:template><xsl:apply-templates/></xsl:template> <xsl:template match="/"> <html> <head> <title><xsl:value-of select="/passport/last_name"/></title> </head> <body> <H1><xsl:value-of select="/pastport/last_name, first_name"/></H1> <H2>Address</H2> <BLOCKQUOTE> <xsl:apply-templates select="/passport/address"/> </BLOCKQUOTE> </body> </html>
XSL (Style Language)

<xsl:template match=”EmployeeRecord/Name"> <Bold> <xsl:apply-templates/> </Bold> </xsl:template>
XSL: Examples
<xsl:template match=”EmployeeRecord/Name"> <Bold> <xsl:apply-templates select=“FirstName”/> </Bold> </xsl:template>
All the children of the “Name” element contained in “EmployeeRecord” are processed with template.
The templates is applied only to the `FirstName’ element of the `Name’ element contained in `EmployeeRecord’.

Options for Displaying XML
XML Document
CSS Stylesheet
XSL Stylesheet
XML enabled Web Broswer
XML Display Engine
XSL Transformation
spec
HTML Document Web Browser
XSL Transformation
example1 example2

An Example
Boeing
Boeing places a DTD on its site
part purchasers use this DTD
Boeing can use multiple XSL stylesheets

Boeing (cont’d)
customer creates an order document, they can verify the validity of that document against the DTD.
this ensures they are transmitting only type-valid orders.
in turn, Boeing can ensure they are receiving only type-valid documents.
Example

XML - Advantages Platform and system independent User-defined tags Doesn’t require explicit DTD Display format and content are separate XML - Disadvantages Requires a processing application “More difficult” than HTML Must be converted to HTML to view in
browser
Summary

Coordinating Heterogenous Databases
Separation of Structure / Content / Display
Document Validity Checking
Potential Use in Standards
Importance of XML

<html><body> <h2>Student List</h2> <ul> <li> 9906789 </li> <li>Adam</li> <li>[email protected]</li> <li>yes - final </li> </ul> <ul> <li> 9806791 </li> <li>Adrian</li> <li>[email protected]</li> <li>no</li> </ul> </body></html>
HTML Document (good for formatting)
What is “yes”?
What is “no”?
Data and presentation
logic mixed

<?xml version = "1.0"?> <student_list> <student> <id> 9906789 </id> <name>Adam</name> <email>[email protected]</email> <bsc level=“final”>yes</bsc> </student> <student> <id> 9806791 </id> <name>Adrian</name> <email>[email protected]</email> <bsc>no</bsc> </student> </student_list>
XML Document (good for describing data)
• Data is self-describing
• custom tags describe content (define your own tags)
• easy to locate data (e.g. all BSC students)
Only data
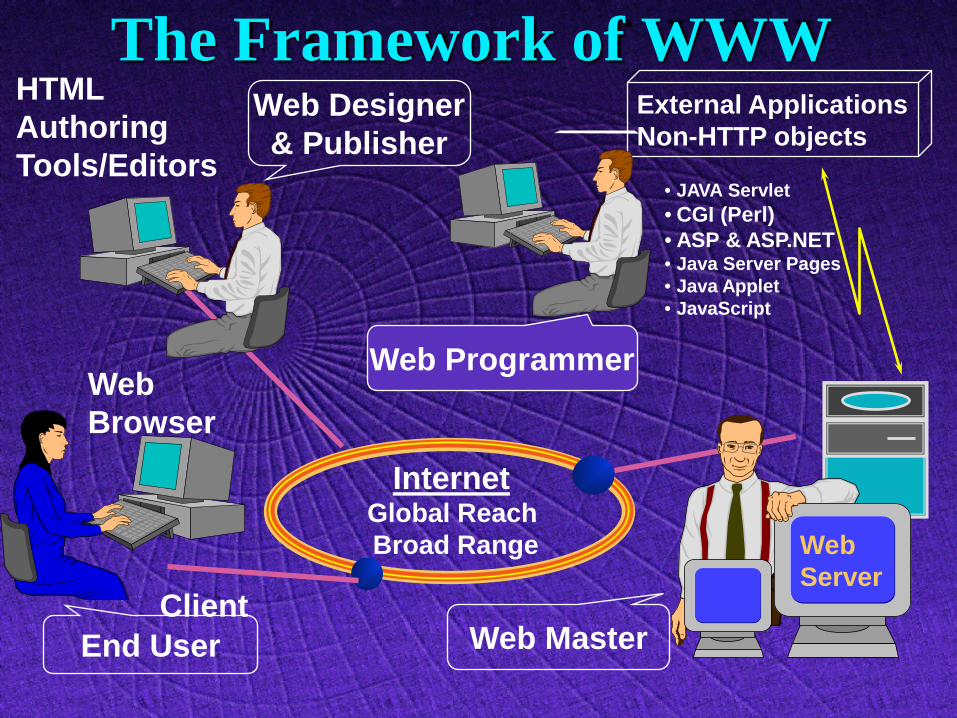
The Framework of WWW
Web Browser
Client End User Web Master
HTML Authoring Tools/Editors
Web Designer & Publisher
Internet Global Reach Broad Range
External Applications Non-HTTP objects
• JAVA Servlet • CGI (Perl) • ASP & ASP.NET • Java Server Pages • Java Applet • JavaScript
Web Programmer
Web Server

Why Build Pages Dynamically?
The Web page is based on data submitted by the user E.g., results page from search engines and order-
confirmation pages at on-line stores
The Web page is derived from data that changes frequently
E.g., a weather report or news headlines page
The Web page uses information from databases or other server-side sources E.g., an e-commerce site could use a servlet to build a
Web page that lists the current price and availability of each item that is for sale