how do constraint families interact? a study of...
TRANSCRIPT

Bruce Hayes 9th Workshop on Altaic Formal Linguistics UCLA August 23, 2013
How do constraint families interact? A study of variation in Tagalog and Hungarian1
I. BACKGROUND: VARIATION IN PHONOLOGY
1. Theme
The world’s languages show a great deal of variation in their phonology. Token variation: same thing can be said in two ways (vanity [ˈvænɪti, ˈvænɪɾi]) Type variation: different words or stems follow different patterns:
serene [iː] ~ serenity [ɛ] but obese [iː] ~ obesity [iː] Modern phonology can embrace (rather than abstract away from) this variation and
analyze it precisely.
2. Variation in constraint-based phonology
We can often attribute it to “ambivalence” with conflicting constraints. obesity violates a usually-valid phonological constraint of English: don’t have
long vowels in antepenultimate syllables serenity has a mismatch of vowel length with its base form serene Neither one is perfect, and different words prioritize differently.
3. Experiments on variation
The last few years of phonological research have achieved a beautiful new empirical result on variation — the Law of Frequency Matching.
I’ll illustrate it with an example.
4. Example: Nasal Substitution in Tagalog (Zuraw 2000, 2010)
The basic pattern, stated as a rule: Input: ŋ, plus an obstruent consonant Output: a single nasal consonant, same place of articulation as the obstruent
Example: mag-bigáj ‘give’, but /maŋ-bigáj/ mamigáj ‘distribute’
1 This talk reports work done in collaboration with Kie Zuraw of UCLA.

Bruce Hayes How do constraint families interact? p. 2
5. The full set of cases for Nasal Substitution
ŋ + p, ŋ + b m
ŋ + t, ŋ + s, ŋ + d n
ŋ + k, ŋ + g ŋ
6. The problem-set version of Nasal Substition
Problem given in Kenstowicz and Kisseberth’s classic (1979) text and others: data are preselected so that it looks like the process always applies. This makes the student who solves the problem happy and motivates him/her to
study more phonology. Perhaps such problem sets also account for something I’ve widely observed:
phonologists who don’t believe there’s much variation.
7. Real-life Tagalog (Take 1)
The process appears to not apply almost as often as it does apply. Where it doesn’t apply, what you get is simple assimilation of the place of the nasal. /maŋ-bigkas/ [mambigkas] ‘to recite’
Here are the full set of outputs:
Input Output if Nasal Substitution
Output if no Nasal Substitution
ŋ+p m mp
ŋ+t n nt
ŋ+k ŋ ŋk
ŋ+b m mb
ŋ+d n nd
ŋ+g ŋ ŋg
Bruce Hayes How do constraint families interact? p. 3
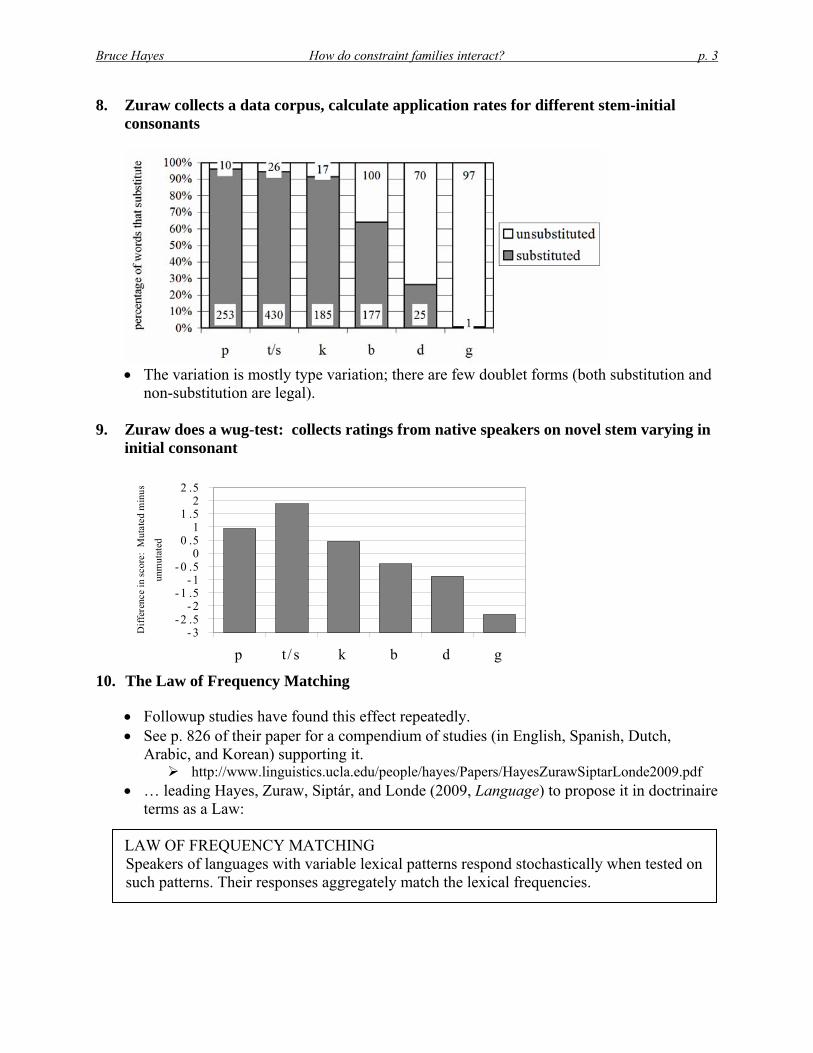
8. Zuraw collects a data corpus, calculate application rates for different stem-initial consonants
The variation is mostly type variation; there are few doublet forms (both substitution and
non-substitution are legal).
9. Zuraw does a wug-test: collects ratings from native speakers on novel stem varying in initial consonant
- 3- 2 .5
- 2- 1 .5
- 1- 0 .5
00 .5
11 .5
22 .5
p t / s k b d g
Dif
fere
nce
in s
core
: M
utat
ed m
inus
unm
utat
ed
10. The Law of Frequency Matching
Followup studies have found this effect repeatedly. See p. 826 of their paper for a compendium of studies (in English, Spanish, Dutch,
Arabic, and Korean) supporting it. http://www.linguistics.ucla.edu/people/hayes/Papers/HayesZurawSiptarLonde2009.pdf
… leading Hayes, Zuraw, Siptár, and Londe (2009, Language) to propose it in doctrinaire terms as a Law:
LAW OF FREQUENCY MATCHING Speakers of languages with variable lexical patterns respond stochastically when tested on such patterns. Their responses aggregately match the lexical frequencies.

Bruce Hayes How do constraint families interact? p. 4
11. The “Law” has exceptions…
These are worth studying, for other reasons In the paper just cited, the wug-test results diverge somewhat from the corpus data —
suggesting Hungarians exposed to the data favor grammars that value: formally simple constraints phonetically natural constraints
A long-term prospect (not addressed here): use the divergences from the Law of Frequency Matching as a probe into the language faculty.
II. TOOLS FOR STUDYING VARIATION: STOCHASTIC GRAMMAR FRAMEWORKS
12. What we want
A system that permits us to construct constraint-based grammars Grammar does not generate just one output (as in Classical Optimality Theory; Prince
and Smolensky 1993/2004) Instead: output is a frequency distribution over candidates Constraints are not ranked, but have strengths of some kind — expressed as real
numbers, usually called weights. Analysis succeeds when our frequency distributions match those output by real speakers.
13. Different frameworks for stochastic grammar behave differently
They share the same basic goals … … the math can be quite different. Choosing among them is a core (mathematically-formulable) question of linguistic
theory.
14. Some contending current frameworks I’ll discuss
Maxent grammars (Goldwater & Johnson 2003, Wilson 2006) Noisy Harmonic Grammar (Boersma & Pater 2008, Pater 2009) Stochastic OT (Boersma 1998, Boersma & Hayes 2001)
15. An affiliated question: how to learn?
Given a stochastic grammar framework, is there some algorithm that can learn grammars in this framework?
One way to pose the question: I give you: A corpus of data — with frequencies A suitable set of constraints
You give me: A weight for each constraint, such that the grammar with these weights correctly
matches the observed frequencies The frameworks above all come with one or more affiliated learning algorithms.

Bruce Hayes How do constraint families interact? p. 5
16. Why learning algorithms are a sensible idea
Often a machine-implemented algorithm can find a more accurate solution than a person. In the long run, we hope to model the actual process of language acquisition in children.
17. Finding the best framework
At first blush, they seem all to work pretty well in matching frequency data. To get insight into what theory we should prefer, we’ll have to look at data in particularly
challenging areas. We think one such area is intersecting constraint families.
III. INTERSECTING CONSTRAINT FAMILIES
18. A simple case
Hungarian vowel harmony (Hayes and Londe 2006, Hayes et al. 2009, much earlier work)
There are basically two choices: you can use either the front or the back vowel version of a suffix (e.g. dative [-nɛk] ~ [-nɔk]).
Vowels of Hungarian are: Back (u, uː, o, oː, ɔ, aː) Neutral (i, iː, eː, ɛ)
Front (y, yː, ø, øː) Most word types take exclusively back suffixes (e.g. B) or front suffix (F) But there are Tagalog-like zones of variation where each individual stem has its own
behavior. As in Tagalog, there are general patterns governing the zones taken as an aggregate. E.g., in words ending BN:
Favor front suffixes to the extent that the neutral vowel is lower; back suffixes otherwise = the Height effect
[ɛ], the lowest, takes front suffixes most often, followed by [eː], followed by [i, iː] What about BNN? Typically it shows back suffixes less often than BN. This is the
Count Effect.

Bruce Hayes How do constraint families interact? p. 6
19. Interaction of the Height Effect and the Count Effect
They combine smoothly: there is a Height effect for both BN and BNN. 1 > 2 > 3, 4 > 5 > 6 At each height, there is a Count Effect. 1 > 4, 2 > 5, 3 > 6
BI Beː Bɛ BNI BNeː BNɛ 1 2 3 4 5 6
20. Moving toward an analysis
If we set up families of constraints by which the height of the final N vowel, or the number of NN’s, influence the backness proportion, these would be (very small) intersecting constraint families.
This is what the references just cited do, getting the Height and Count effects, as well as their intersection.

Bruce Hayes How do constraint families interact? p. 7
21. There could be more categories than just 2 x 3
Perhaps there are multiple constraints in each intersecting family. Each constraint determines some aspect of the quantitative behavior of the outcomes, and
the families intersect.
ConstrA
ConstrB
ConstrC
ConstrD
Constraint1
Constraint2
Constraint3
Constraint4
22. Using this as a test for theories
Different theories will intersect the constraints differently, producing different frequency patterns.
If we have enough data, we could distinguish the theories. In our current work, we’re doing cases from Tagalog, French, and Hungarian.
I’ll skip the French here for lack of time.
IV. TAGALOG NASAL SUBSTITUTION
23. Reviewing the basic data pattern, with an improved corpus
Data: from Zuraw’s server, fishing for Tagalog-language web pages.
Stem-initial obstruent
Be
ha
vio
r a
cc
ord
ing
to
dic
tio
na
ry
p
sub
stu
nsu
bst t/s k b d g
1040 17
100
70
97253 430 185
177
25
1
Width of the bars: these show the number of data that underlie the proportion observed.

Bruce Hayes How do constraint families interact? p. 8
24. Refining our description of Tagalog further: break it down by prefix
Here are the six most frequent ŋ-final prefixes in the language:2
paŋ-RED- mainly gerunds maŋ-RED- professional or habitual nouns maŋ- “adversive” verbs (harm the patient) maŋ- other verbs paŋ- various nominalizations paŋ- “reservational” adjectives (‘for use in X’)
Each prefix actually has its own frequency curve. These curves are roughly similar and form a hierarchy when graphed.
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
p t/s k b d g
Ob
serv
ed n
as.
sub
. ra
te
maN- other
paN-RED-
maN-RED
maN- adversative
paN- noun
paN- reservative
25. Understanding this pattern: a suggested motto Saturation at the peripheries, maximal differences medially. Examples:
Rate for /g/ is so low that there are only minor differences between prefixes — saturation at zero (you can’t go any lower).
/p/ is so high that four prefixes are upwardly saturated at one; only the lowest two differ.
/b/ is medial, and distinguishes all six values.
2 RED means, roughly, “reduplicate the following syllable”.

Bruce Hayes How do constraint families interact? p. 9
Mentally flip the axes for more cases: maŋ- other and maŋ- adversative are so high on the left side of the chart that they
saturate at 1, wiping out differences between [p, t, k] (which do differ for other prefixes)
paŋ-reservative is so low on the right that the d-g distinction is gone (saturation at zero).
V. A THEORY THAT NATURALLY DISPLAYS THIS PATTERN:
HARMONIC GRAMMAR
26. Harmonic grammar
Developed by Paul Smolensky in the 1980’s and 1990’s as a way of doing “analytically aware” connectionism.
Some subsequent references: Legendre et al. (1990), Smolensky, Paul, and Geraldine Legendre. 2006. Pater, (2009), Potts et al. (2009)
Now being considered as a plausible rival to the long-dominant evaluation method of Optimality Theory (Prince and Smolensky 1993).
27. Key to harmonic grammar
No ranking (as OT does) Instead, every constraint has a weight (real number, usually constrained to be
nonnegative) To compute frequency distributions:
For each candidate you compute the dot product of violations and weights Meaning: for each candidate/constraint, multiply violations times weights, then
sum over constraints — an intuitive “penalty score”. Example: the dot product below would be 2.2 + 2 + 8.3 = 12.5 1.1 2 8.3 weights 2 1 1 violations Following (some but not all) earlier authors, we’ll call this dot product the harmony.
28. Simple harmonic grammar
Not a stochastic theory; derives one output only. Candidate with the lowest harmony is the unique winner.3 We’ll see stochastic versions shortly.
3 I know this sounds backwards, but it’s not my fault.

Bruce Hayes How do constraint families interact? p. 10
29. Harmonic grammar’s most salient prediction
Constraint ganging Violations of two weaker constraints can outweigh a strong constraint. Two violations of a weak constraint can count as stronger than one of a strong
constraint. A nice real-life case of ganging from Lango is given in Potts et al. 2010.
30. Maxent harmonic grammar
This is a way to make a harmonic grammar stochastic and thus analyze variation. References: Goldwater and Johnson (2006), Wilson (2006) A formula takes the harmony values of all the candidates and converts them to
probabilities. For a simple two-candidate system, the formula is:
p(Cand1) = exp(−H(Cand1))
exp(−H(Cand1)) + exp(−H(Cand2))
where p(x) = the probability of candidate x exp(y) = ey, where e is the base of natural logarithms, about 2.718 H(x) = the harmony of x, as given in (Error! Reference source not found.)
31. Maxent predicts “Saturation at the peripheries, maximal differences medially”
Imagine a bunch of inputs, each with two viable candidates, call them I and II. Some constraints penalize I; some penalize II.
A computational gimmick: it works ok to say that the constraints penalizing II have negative weights.
So, the higher the total harmony, the more likely II will win. Two constraint families: A and B. Effect of A is somewhat bigger. Key idea: let’s sum up the harmonies for families A and B separately. Getting saturation at the peripheries, maximal differences medially.
Harmony for family A is very low: total harmony will be pretty low for candidate I, no matter what family B says. Candidate I is little-penalized, and always wins.4
Harmony for family A is very high: total harmony will be pretty high for candidate I, no matter what family B says. Candidate I is much-penalized, and Candidate II always wins.
Harmony for family A is medium: now family B matters.
4 By “always” I mean something like .9999; maxent never actually goes all the way to 1.

Bruce Hayes How do constraint families interact? p. 11
32. Cashing out this intuitive result quantitatively
Three curves, representing total harmony from family B of −5, −7.5, and −10.
Fixing the amount of harmony from family B at −5, −7.5, −10, we see three sigmoid curves, obtained by varying the amount of harmony from A.
You can see: saturation at 1 for low A-harmony saturation at 0 with high A-harmony harmony from family B matters only in the middle (e.g., look at 7).
33. A bit of nomenclature
For intersecting constraint families, maxent grammar creates a wug-shaped curve family.5
5 Thanks to Dustin Bowers for this apt simile.

Bruce Hayes How do constraint families interact? p. 12
VI. BACK TO TAGALOG WITH MAXENT HARMONIC GRAMMAR
34. Some phonological constraints
Markedness:
*N+C No nasal + obstruent sequence (where + is morpheme boundary)
*NC̥ See Hayes & Stivers 1996 for phonetic motivation, Pater 1999 and Pater 2001 for role in nasal substitution.
Here: responsible for higher rates of nasal substitution in p/t/s/k. *[root m/n/ŋ *[root n/ŋ *[root ŋ
Express a general tendency for Tagalog roots not to begin with nasals—stronger for backer consonants.
General motivation: avoid domain-initial sonorants. Stated as stringency hierarchy (Prince 1997, de Lacy 2002) See Flack 2007 on the badness of domain-initial [ŋ] All penalize nasal substitution
Faithfulness:
We adopt one Faithfulness constraint — basically, “don’t commit substitution”— for each prefix construction.
FAITH-paŋ-Adj. A segment from input adjectival paŋ- and a distinct input segment must not correspond to the same output segment
FAITH-paŋ+red (similar) FAITH-maŋ-other (similar) FAITH-paŋ-N (similar) FAITH-maŋ-adv (similar) FAITH-maŋ+RED (similar)
35. Finding the right constraint weights
Maxent is a wonderful framework from the viewpoint of learnability. The algorithm for finding the best weights (Berger et al 2006) always converges, and is
guaranteed to find the most accurate weights. It’s easy to run this algorithm using the Maxent Grammar Tool (Wilson & George 2009),
available at http://www.linguistics.ucla.edu/people/hayes/MaxentGrammarTool/ We found the weights that best fit the counts in Zuraw’s Tagalog data.

Bruce Hayes How do constraint families interact? p. 13
0
1
2
3
4
5
6
7
NasSub *NC *[m/n/ng *[n/ng *[ng Faith-maN-other
Faith-paN-RED
Faith-maN-RED
Faith-maN-advers
Faith-paN-noun
Faith-paN-
reserv
Max
En
t w
eig
ht
Comments:
Maxent often turns one of your constraints into a zero-weighted default — this happened here with *[m/n/ŋ.
[ŋ] really is the worst initial nasal — it gets the effect of both *[n/ŋ and *[ŋ, a case of ganging.

Bruce Hayes How do constraint families interact? p. 14
36. Maxent grammar’s predictions
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
p t/s k b d g
Max
En
t p
red
icte
d n
as.
sub
. ra
te
maN- other
paN-RED-
maN-RED
maN- adversative
paN- noun
paN- reservative
It’s easy to see this as a truncated wug-shaped curve family. Also, to a fair extent, the saturation and medial differences of the original data (repeated
here) are captured.
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
p t/s k b d g
Ob
serv
ed n
as.
sub
. ra
te
maN- other
paN-RED-
maN-RED
maN- adversative
paN- noun
paN- reservative

Bruce Hayes How do constraint families interact? p. 15
VII. A SIMILAR FRAMEWORK: NOISY HARMONIC GRAMMAR
37. Reference
Boersma and Pater (in press)
38. Basic system
Calculate harmony, as before. As in simple harmony grammar, winner is the candidate with the lowest harmony. But let there be a series of separate “evaluation times”, each involving one run of the
grammar. At each evaluation time, add some random noise to the weights — this will cause output
to vary. Go through many evaluation times to compute a probability distribution over outputs.
39. Tagalog results
Very similar to Maxent Not surprising: both are implementations of stochastic Harmonic Grammar.
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
p t/s k b d g
No
isy
HG
pre
dic
ted
nas
. su
b.
rate
maN- other
paN-RED-
maN-RED
maN- adversative
paN- noun
paN- reservative
VIII. A THIRD FRAMEWORK: STOCHASTIC OT
40. References Boersma (1998), Boersma and Hayes (LI 2001)

Bruce Hayes How do constraint families interact? p. 16
41. Basis
As in noisy harmonic grammar, you add noise to the weights, running the system many times to get a probability distribution.
But no harmony calculation: instead, just sort the constraints by their weights and then select the winner using good-old-fashioned OT.
A somewhat unreliable learning algorithm, the GLA (“Gradual Learning Algorithm”) is used for this theory.
42. Tagalog in Stochastic OT learned with Gradual Learning Algorithm
Weights learned
FAITH-paN-reserv 905.5
*NC̥ 904.1
FAITH-paN-noun 900.9
*[ng 899.2
*[n/ng 899.1
NASSUB 897.3
FAITH-maN-RED 897.0
FAITH-maN-advers 895.3
FAITH-paN-RED 888.9
*[m/n/ng -697.3
FAITH-maN-other -4,684.9
Observe evidence of non-convergence: *[m/n/ng and FAITH-maN-other keep getting demoted.

Bruce Hayes How do constraint families interact? p. 17
43. Results
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
p t/s k b d g
GL
A p
red
icte
d n
as.
sub
. ra
te
Fit of GLA maN- other
Fit of GLA paN-RED-
Fit of GLA maN-RED
Fit of GLA maN- adversative
Fit of GLA paN- noun
Fit of GLA paN- reservative
44. We think this is a crummy grammar
Quantitative degree of fit is lower. Qualitative properties are especially bad. This grammar is unable to distinguish maŋ-other from paŋ-RED—only 5 lines, not 6.
Reason: both FAITH-maN-other and FAITH-paN-RED are demoted too low to matter.
Almost no place effect within voiceless: *NC̥ is too far above the place-based constraints for their differences to matter.
Graceful sigmoidality is replaced by choppy ups and downs. Reason: theory is based on conflicting constraints. For variation weights have to
be close, and the weight of one constraint can’t be simultaneously close to the weight of two other constraints.
These problems persist when we hand-weight the constraints: we think it’s a problem with the theory, not the learning algorithm.
45. Upshot
We think the intersecting constraint family problem can shed light on conflicting theories.
Harmonic grammar (both maxent and noisy) makes clear prediction about how this should happen: Saturation at the peripheries, maximal differences medially more precisely: the wug-shaped curve family

Bruce Hayes How do constraint families interact? p. 18
Modulo noise, these are pretty much what we’re seeing in the Tagalog data. Stochastic OT makes quirky, non-general predictions; and these match poorly to the
Tagalog data.
IX. SECOND EXAMPLE: HUNGARIAN VOWEL HARMONY
46. Why a second example?
both intersecting families are phonological we have experimental data, showing the patterns are productive
47. Recall the Height and Count effects
These were presented above as illustrating two miniature intersecting constraint families. Let’s also fold in two extreme cases to complete the frequency spectrum:
B stems always take back suffixes. F stems (front rounded) always take front suffixes.
48. Same patterns, with two peripheral categories and a larger data base
Data: Hungarian Webcorpus (Kornai et al 2006), counting most of the suffixes in the language.
B BI Beː Bɛ BNI BNeː BNɛ F
Note that the pattern here is like in Tagalog: most stems have just one outcome; it’s the aggregate across the lexicon we’re interested in.
Henceforth, we’ll combine all the vowel based constraints into just one category.
49. The role of consonants in Hungarian vowel harmony
Backness harmony in the zones of variation is influenced by the consonant or consonant cluster at the end of stem.

Bruce Hayes How do constraint families interact? p. 19
Four consonant environments that all prefer front harmony: final bilabial noncontinuants ([p, b, m]) final sibilants ([s, z, ʃ, ʒ, ts, tʃ, dʒ]) final coronal sonorants ([n, ɲ, l, r]) final two-consonant clusters
These are shown to be productive in wug-testing (Hayes et al. 2009)
50. The consonant effects are surprisingly large
Simple taxonomy: no consonant environment present one consonant environment present two consonant environments present (e.g., cluster ending in sibilant)
51. How do the vowel and consonant families intersect?
We can look at three things: raw data wug test results modeling results

Bruce Hayes How do constraint families interact? p. 20
52. Corpus data
These are rather messy.
Pro
port
ion
back
har
mon
y
B BI Beː BNI Bɛ BNeː BNɛ N F We think this is due to insufficient data (there just aren’t that many stems in the zones of
variation; about 800 total) Note discontinuous line for two C environments; indicate zero data in some places. So: our suggestion is that this is just random noise.
53. Wug test data (Hayes et al. 2009)
Pro
port
ion
back
har
mon
y
B BI Beː BNI Bɛ BNeː BNɛ N F
We see this as a wug-shaped curve, with saturation at the ends and maximal difference medially.
Why smoother than the raw data?

Bruce Hayes How do constraint families interact? p. 21
Conjecture: speakers learn simple, general constraints, not a cell-by-cell frequency matching.
54. Maxent model
For constraints used, see Hayes et al. (2009); different choices yield similar results.
Pro
port
ion
back
har
mon
y
There are still glitches, which Hayes et al. (2009) attribute to simplicity and naturalness biases.
B BI Beː BNI Bɛ BNeː BNɛ N F
But the grammar has managed to iron a fair amount of the idiosyncracy seen in the raw data pattern.
55. Other frameworks
They get similar results (even stochastic OT); Hungarian is not enough of a challenge to distinguish them.
For our main argument, we rely on Tagalog and the French study not presented here.
56. Hungarian summary
Hungarian is: a case of two phonological constraint families intersecting in the way we have
claimed, with saturation at both extremes of the vowel constraint family but medial differences.
a case that probably never be clearly interpretable had we not done an experiment: the unruly pattern seen in the real-language data is replaced by a quite orderly one in the nonce-probe study.
57. Overall summary
Intersecting constraint families can tell us something about the theory of stochastic grammar.

Bruce Hayes How do constraint families interact? p. 22
Empirically, they give rise to wug-shaped curve families, with peripheral saturation and medial differences.
This pattern is generated automatically by harmonic grammar, which we take to be an argument in its favor.
References Boersma, Paul. 1998. Functional Phonology: Formalizing the Interaction Between Articulatory and Perceptual
Drives. The Hague: Holland Academic Graphics. Boersma, Paul & Bruce Hayes. 2001. Empirical tests of the gradual learning algorithm. Linguistic Inquiry 32. 45–
86. Boersma, Paul & Joe Pater. 2008. Convergence properties of a Gradual Learning Algorithm for Harmonic Grammar.
Manuscript. University of Amsterdam and University of Massachusetts, Amherst. To appear in xxx English, Leo. 1986. Tagalog-English dictionary. Manila: Congregation of the Most Holy Redeemer; distributed by
Philippine National Book Store. Goldwater, Sharon & Mark Johnson. 2003. Learning OT Constraint Rankings Using a Maximum Entropy Model. In
Jennifer Spenader, Anders Eriksson & Östen Dahl (eds.), Proceedings of the Stockholm Workshop on Variation within Optimality Theory, 111–120. Stockholm: Stockholm University.
Guzman, Videa P De. 1978. A Case for Nonphonological Constraints on Nasal Substitution. Oceanic Linguistics 17(2). 87–106.
Halácsy, Péter, András Kornai, László Németh, András Rung, István Szakadát & Viktor Trón. 2004. Creating open language resources for Hungarian. Proceedings of the 4th international conference on Language Resources and Evaluation (LREC2004).
Hayes, Bruce & Zsuzsa Cziráky Londe. 2006. Stochastic Phonological Knowledge: The Case of Hungarian Vowel Harmony. Phonology 23(01). 59–104. doi:10.1017/S0952675706000765.
Hayes, Bruce & Tanya Stivers. 1996. The phonetics of post-nasal voicing. Hayes, Bruce, Colin Wilson & Ben George. 2009. Maxent Grammar Tool.
http://www.linguistics.ucla.edu/people/hayes/MaxentGrammarTool/. Hayes, Bruce, Kie Zuraw, Zsuzsa Cziráky Londe & Peter Siptár. 2009. Natural and unnatural constraints in
Hungarian vowel harmony. Language 85. 822–863. Kornai, András, Péter Halácsy, V Nagy, Cs Oravecz, Viktor Trón & D Varga. 2006. Web-based frequency
dictionaries for medium density languages. In Adam Kilgarriff & Marco Baroni (eds.), Proceedings of the 2nd International Workshop on Web as Corpus ACL-6, 1–9.
Lombardi, Linda. 1999. Positional faithfulness and voicing assimilation in Optimality Theory. Natural Language and Linguistic Theory 17. 267–302.
Pater, Joe. 1999. Austronesian nasal substitution and other NC effects. In René Kager, Harry van der Hulst & Wim Zonneveld (eds.), The Prosody-Morphology Interface, 310–343. Cambridge: Cambridge University Press.
Pater, Joe. 2001. Austronesian nasal substitution revisited: What’s wrong with *NC (and what’s not). In Linda Lombardi (ed.), Segmental Phonology in Optimality Theory: Constraints and Representations, 159–182. Cambridge: Cambridge University Press.
Pater, Joe. 2009. Weighted constraints in generative linguistics. Cognitive Science 33. 999–1035. Potts, Christopher, Joe Pater, Karen Jesney, Rajesh Bhatt and Michael Becker. 2010. Harmonic Grammar with
Linear Programming: From linear systems to linguistic typology. Phonology 27: 77-117. Prince, Alan & Paul Smolensky. 1993/2004. Optimality Theory: Constraint interaction in generative grammar.
Malden, Mass., and Oxford, UK: Blackwell. Schachter, Paul & Fe T Otanes. 1972. Tagalog Reference Grammar. Berkeley, CA: University of California Press. Wilson, Colin. 2006. Learning Phonology with Substantive Bias: An Experimental and Computational Study of
Velar Palatalization. Cognitive Science 30(5). 945–982. Zuraw, Kie. 2010. A model of lexical variation and the grammar with application to Tagalog nasal substitution.
Natural Language and Linguistic Theory 28(2). 417–472.