hoe schaakt een computer? arnold meijster. why study games? fun historically major subject in ai...
TRANSCRIPT

Hoe schaakt een computer?Hoe schaakt een computer?
Arnold Meijster

Why study games? Why study games?
Fun Historically major subject in AI Interesting subject of study because they are hard
Games are of interest for AI researchers Solution is a strategy (strategy specifies move for every possible
opponent reply). Time limits force an approximate solution Evaluation function: evaluate “goodness” of game position Examples: chess, checkers, othello/reversi, backgammon, poker,
bridge

Game setup Two players: MAX and MIN
MAX moves first and they take turns until the game is over.
Another view: games are a search problem Initial state: e.g. board configuration of chess Successor function: list of (move,state) pairs specifying legal
moves. Goal/Terminal test: Is the game finished? Utility function: Gives numerical value of terminal states. E.g. win
(+1), loose (-1) and draw (0)
MAX uses a search tree to determine next move.

(Partial) Game Tree for Tic-Tac-Toe

Optimal strategies Assumption: Both players play optimally !!
Find the strategy for MAX assuming an infallible MIN opponent.
Given a game tree, the optimal strategy can be determined by computing the minimax value of each node of the tree:
MINIMAX-VALUE(n)=UTILITY(n) If n is a terminalmaxs successors(n) MINIMAX-VALUE(s) If n is a
max nodemins successors(n) MINIMAX-VALUE(s) If n is a
min node

MinMax – First ExampleMinMax – First Example
Max’s turnMax’s turn
Would like the “9” points (the maximum)Would like the “9” points (the maximum)
But if Max chooses the left branch, Min But if Max chooses the left branch, Min will choose the move to get 3will choose the move to get 3 left branch has a value of 3left branch has a value of 3
If Max chooses right, Min can choose If Max chooses right, Min can choose any one of 5, 6 or 7 (will choose 5, the any one of 5, 6 or 7 (will choose 5, the minimum)minimum) right branch has a value of 5right branch has a value of 5
Right branch is largest (the maximum) Right branch is largest (the maximum) so choose that moveso choose that move
5
3 5
3 9 6 75
Max
Min
Max

MinMax – Second MinMax – Second ExampleExample

Tic-Tac-Toe: Three-Ply Game Tree


MinMax – Pseudo CodeMinMax – Pseudo Codeint Max() {int best = -INFINITY; /* first move is best */if (isTerminalState()) return Evaluate();GenerateLegalMoves();while (MovesLeft()) {
MakeNextMove();val = Min(); /* Min’s turn next */UnMakeMove();if (val > best) best = val;
}return best;
}

MinMax – Pseudo Code MinMax – Pseudo Code int Min() {int best = INFINITY; /* differs from MAX */if (isTerminalState()) return Evaluate();GenerateLegalMoves();while (MovesLeft()) {
MakeNextMove();val = Max(); /* Max’s turn next */UnMakeMove();if (val < best) // different than MAX
best = val;}return best;
}

Problem of minimax search
Number of game states explodes when the number of moves increases. Solution: Do not examine every node
Idea: stop evaluating moves when you find a worse result than the previously examined moves. Does not benefit the player to play that
move, it need not be evaluated any further. Save processing time without affecting
final result

α is the value of the best (i.e., highest-value) choice found so far at any choice point along the path for max
If v is worse than α, max will avoid it prune that branch
Define β similarly for min
The α-β pruning algorithm

MinMax – AlphaBeta Pruning MinMax – AlphaBeta Pruning ExampleExample
From Max’s point of view, 1 is already From Max’s point of view, 1 is already lower than 4 or 5, so no need to evaluate lower than 4 or 5, so no need to evaluate 2 and 3 (bottom right) 2 and 3 (bottom right) Prune Prune

Minimax: 2-ply deep

α-β pruning example

α-β pruning example

α-β pruning example

α-β pruning example

α-β pruning example

Properties of α-β Pruning does not affect final result (same as
minimax)
Good move ordering improves effectiveness of pruning
With "perfect ordering," time complexity = O(bm/2) Branching factor of sqrt(b) !! Alpha-beta pruning can look twice as far as minimax in the same
amount of time Chess: 4-ply lookahead is a hopeless chess player!
4-ply ≈ human novice 8-ply ≈ typical PC, human master 12-ply ≈ Deep Blue, Kasparov
Optimization: repeated states are possible. Store them in memory = transposition table

MiniMax and ChessMiniMax and Chess
With a complete tree, we can determine the best possible With a complete tree, we can determine the best possible movemove
However, a complete tree is impossible for chess!However, a complete tree is impossible for chess!
At a given time, chess has ~ 35 legal moves. At a given time, chess has ~ 35 legal moves. 35 at one ply, 3535 at one ply, 3522 = 1225 at two plies … 35 = 1225 at two plies … 3566 = 2 billion and = 2 billion and
35351010 = 2 quadrillion = 2 quadrillion Games last 40 moves (or more), so 35Games last 40 moves (or more), so 354040
For large games (like Chess) we can’t see the end For large games (like Chess) we can’t see the end of the game. of the game.

Games of imperfect information
SHANNON (1950): Cut off search earlier (replace TERMINAL-
TEST by CUTOFF-TEST)
Apply heuristic evaluation function EVAL (replacing utility function of alpha-beta)

Heuristic EVAL Idea: produce an estimate of the expected utility of the
game from a given position.
Performance depends on quality of EVAL.
Requirements: Computation should not take too long. For non-terminal states the EVAL should be strongly
correlated with the actual chance of winning.
Only useful for quiescent (no wild swings in value in near future) states Requires quiescence search


Evaluation functions Typically a linear weighted sum of features
Eval(s) = w1 f1(s) + w2 f2(s) + … + wn fn(s)
e.g., w1 = 10 with f1(s) = (number of white queens) – (number of black queens), etc.
Rule of thumb weight values for chess:Pawn=1Bishop, Knight=3Rook=5Queen=10 King=99999999

Heuristic difficulties
Heuristic counts pieces won!
Consider two cases:1)Black to play2)White to play
It really makes a difference when to apply the evaluation function!!!

Horizon effect
A program with a fixed depth search less than 14 will think it can avoidthe queening move

Horizon effect

Mate in 19!Mate in 19!

Mate in 40!Mate in 40!
Source: http://www.gilith.com/chess/endgames/kr_kn.html
Mate in 40 with Ke7.
Worse are Kc5, Kc6, Kd5, Kd7, Ke5 and Ke6 which throw away the win.

Mate in 39!Mate in 39!
White mates in 39 after Ng7.
Worse are:Kg4: white mates in 16Kg5, Kg6, Kh4: white mates in 15Kh6: white mates in 13Nc7, Nd6: white mates in 12Nf6: white mates in 10.

Mate (in 0)Mate (in 0)

Mate (in 1)Mate (in 1)

Mate (in 0)Mate (in 0)
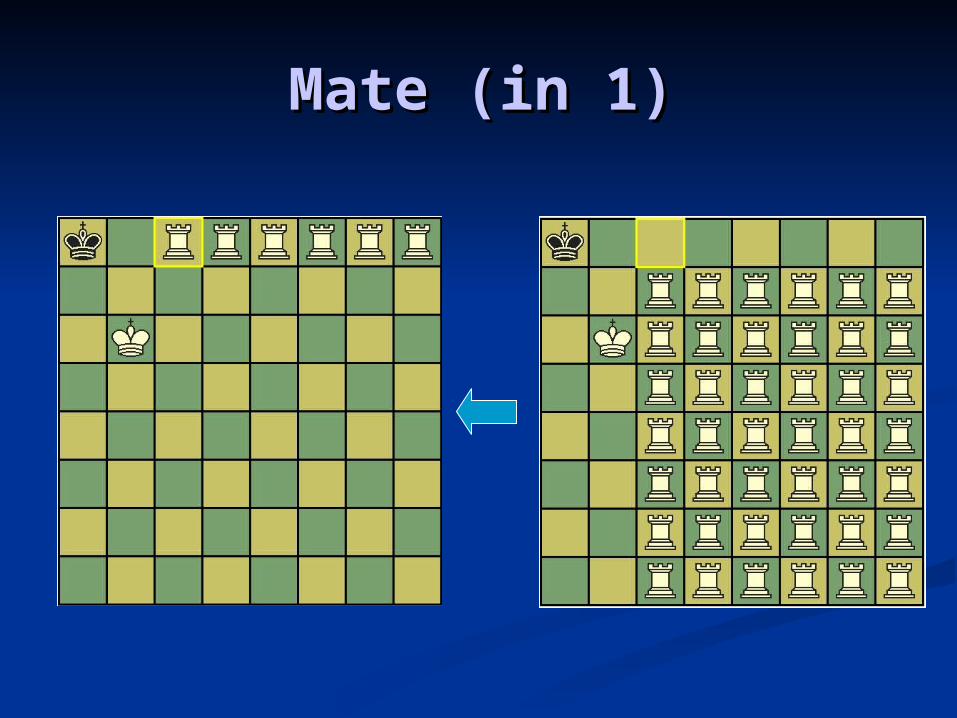
Mate (in 1)Mate (in 1)

Previous states (black to Previous states (black to move)move)

Nalimov dbase: backward search
for all mate-in-n-positions dofor all mate-in-n-positions do
for all reverse moves m by black dofor all reverse moves m by black do
if move m leads (forced) to mate in n if move m leads (forced) to mate in n
then determine all mate in n+1 positionsthen determine all mate in n+1 positions

Endgame databases…Endgame databases…


How end game databases changed chessHow end game databases changed chess
All 5 piece endgames solved (can have > 10^8 states) & All 5 piece endgames solved (can have > 10^8 states) & many 6 piecemany 6 piece KRBKNN (~10^11 states): longest path-to-mate 223KRBKNN (~10^11 states): longest path-to-mate 223
Rule changesRule changes Max number of moves from capture/pawn move to Max number of moves from capture/pawn move to
completioncompletion
Chess knowledgeChess knowledge KRKN game was thought to be a draw, butKRKN game was thought to be a draw, but
White wins in 51% of WTMWhite wins in 51% of WTM White wins in 87% of BTMWhite wins in 87% of BTM

Summary Games are fun
They illustrate several important points about AI Perfection is unattainable -> approximation Uncertainty constrains the assignment of values to states
A computer’s strength at chess comes from:A computer’s strength at chess comes from: How deep can it searchHow deep can it search How well can it evaluate a board positionHow well can it evaluate a board position
In some sense, like humans – a chess grandmaster can evaluate In some sense, like humans – a chess grandmaster can evaluate positions better and can look further aheadpositions better and can look further ahead
Games are to AI as grand prix racing is to automobile design.
