high throughput sequencing. agenda introduction to sequencing applications bioinformatics analysis...
TRANSCRIPT

High Throughput Sequencing

Agenda
• Introduction to sequencing• Applications• Bioinformatics analysis pipelines• What should you ask yourself before
planning the experiment

Introduction to sequencing
What is sequencing?
Finding the sequence of a DNA/ RNA molecule
:// . . / / / /http cancergenome nih gov newsevents multimedialibrary images CancerBiology
What can we sequence?

Sanger sequencing
• Up to 1,000 bases molecule• One molecule at a time
• Widely used from 1970-2000• First human genome draft was
based on Sanger sequencing• Still in use for single molecules
:// . . / / / /http www genomebc ca education articles sequencing

High Throughput SequencingNext Generation Sequencing (NGS) / Massively parallel sequencing
• Sequencing millions of molecules in parallel• Do not need prior knowledge of what you’re
sequencing
Platform Read length No. of reads per run
454 sequencing Up to 1,000 bp ~1 M (1 million)SOLiD 50-75 bp ~1 G (1 billion)HiSeq 100-150 bp ~0.5 G
We will discuss Illumina’s platform only

Sequencing Workflow
1. Extract tissue cells2. Extract DNA/RNA from cells3. Sample preparation for sequencing4. Sequencing5. Bioinformatics analysis
Why is it important to understand the “wet lab” part?
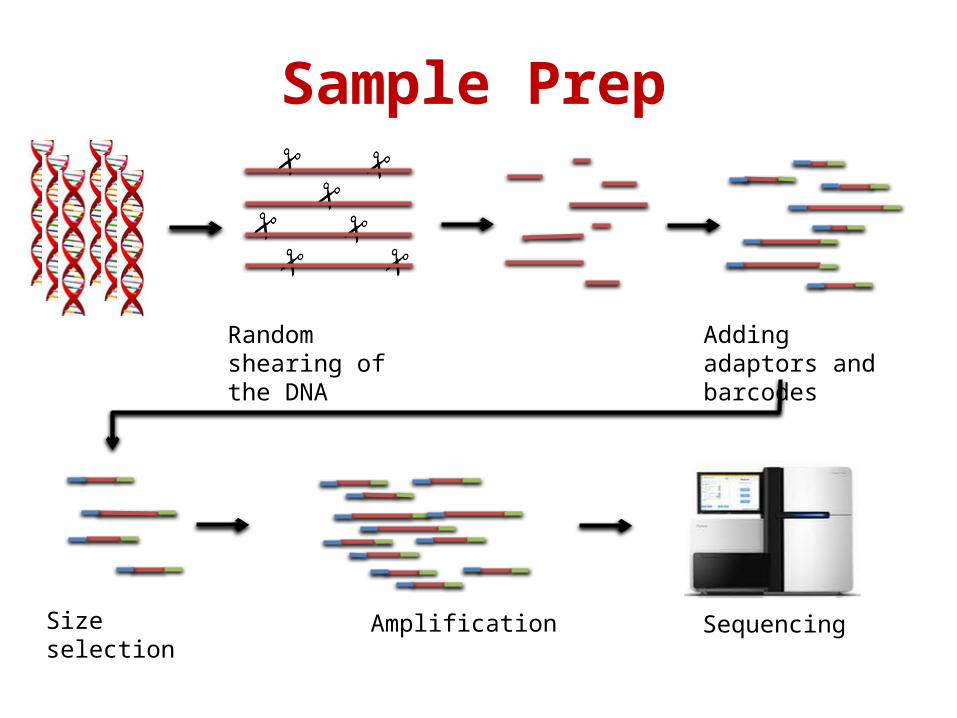
Sample Prep
Random shearing of the DNA
Adding adaptors and barcodes
Size selection Amplification Sequencing
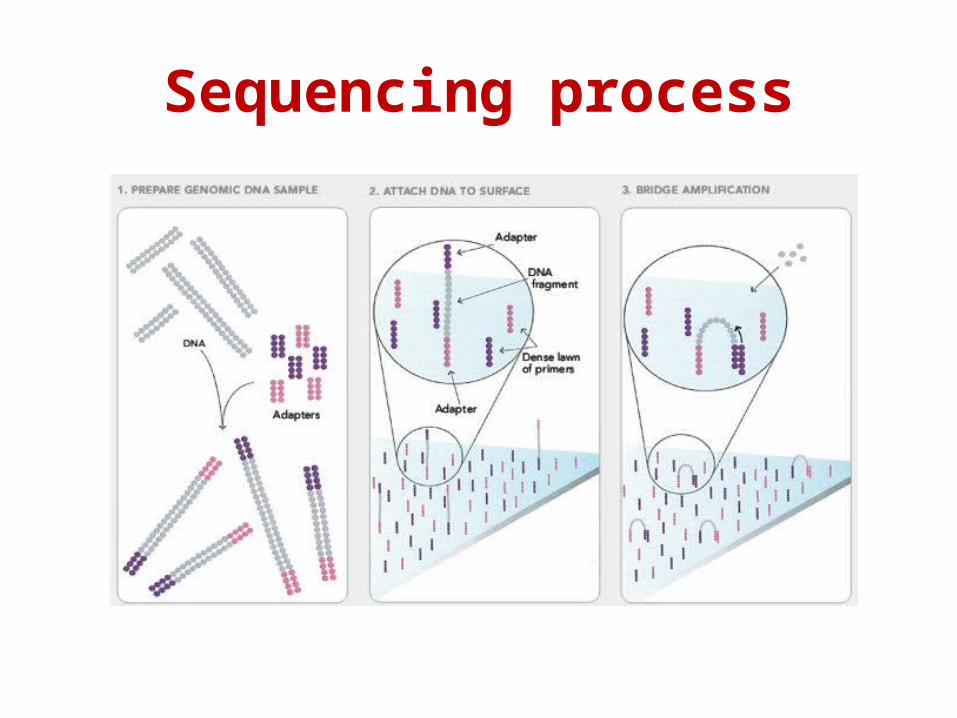
Sequencing process
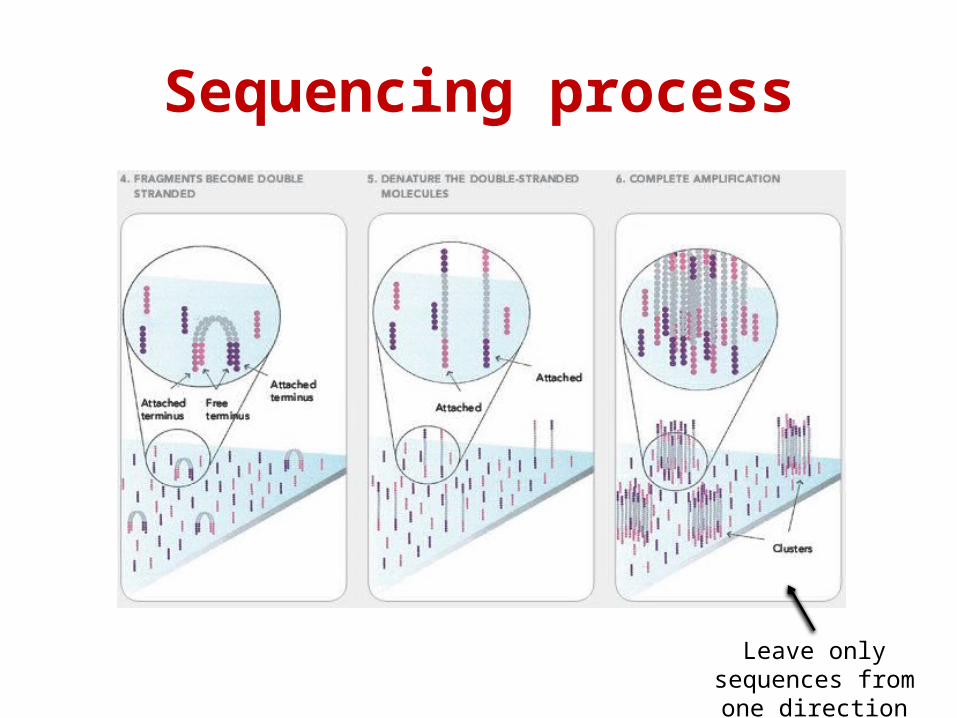
Sequencing process
Leave only sequences from one direction
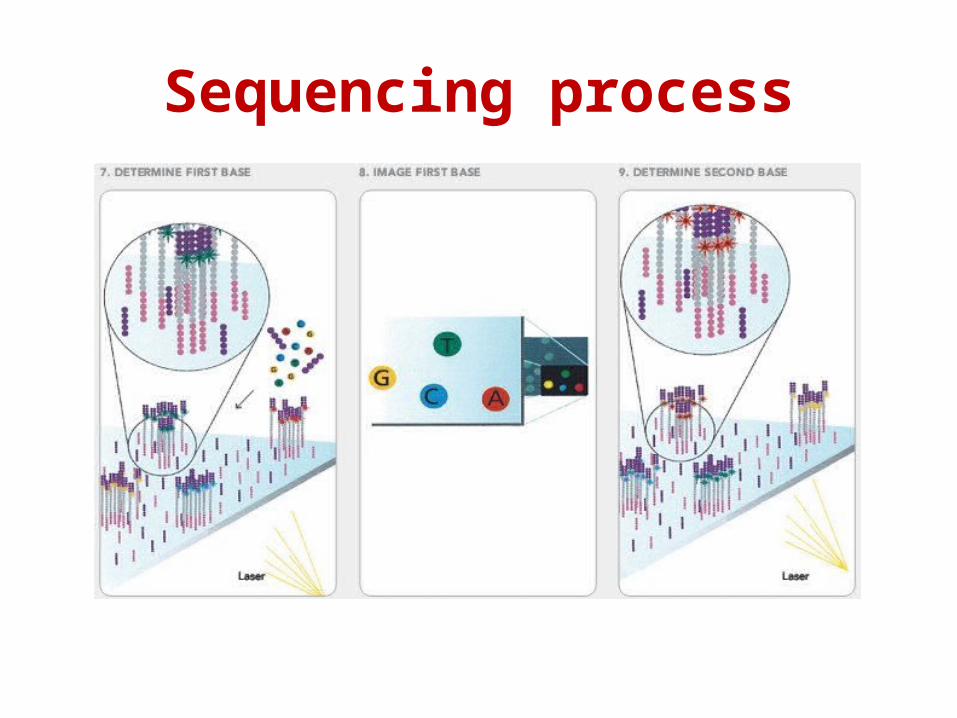
Sequencing process
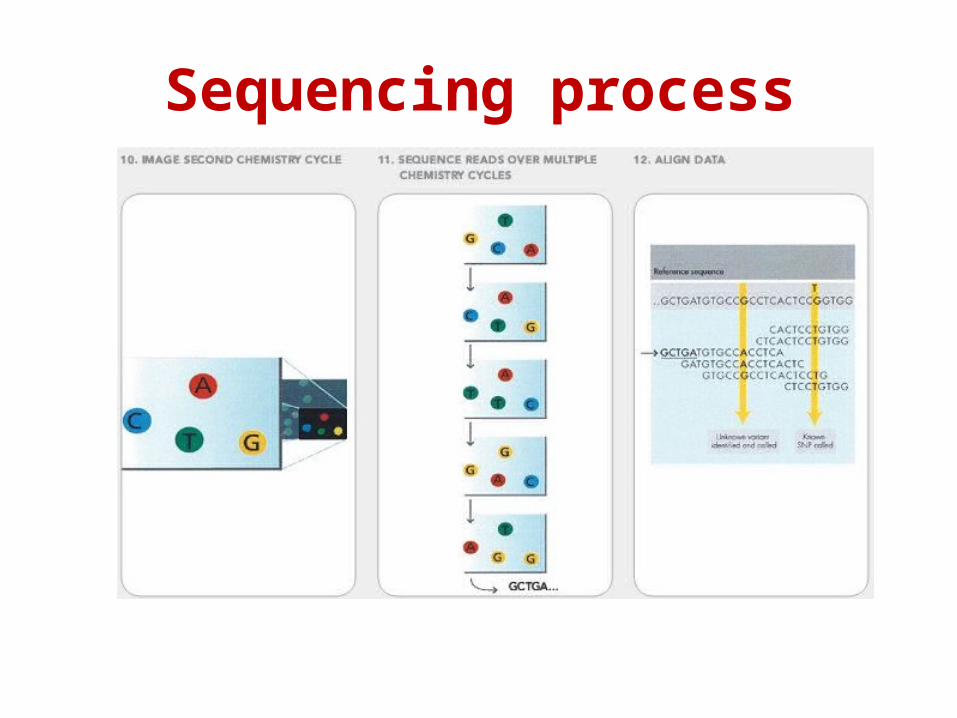
Sequencing process
Sequencing process

Applications

• Resequencing – sequencing the genome of an
organism with a known genome
• Exome sequencing / Targeted sequencing –
sequencing only selected regions from the genome
• De-novo sequencing– sequencing the genome of
an organism with a unknown genome
DNA sequencing
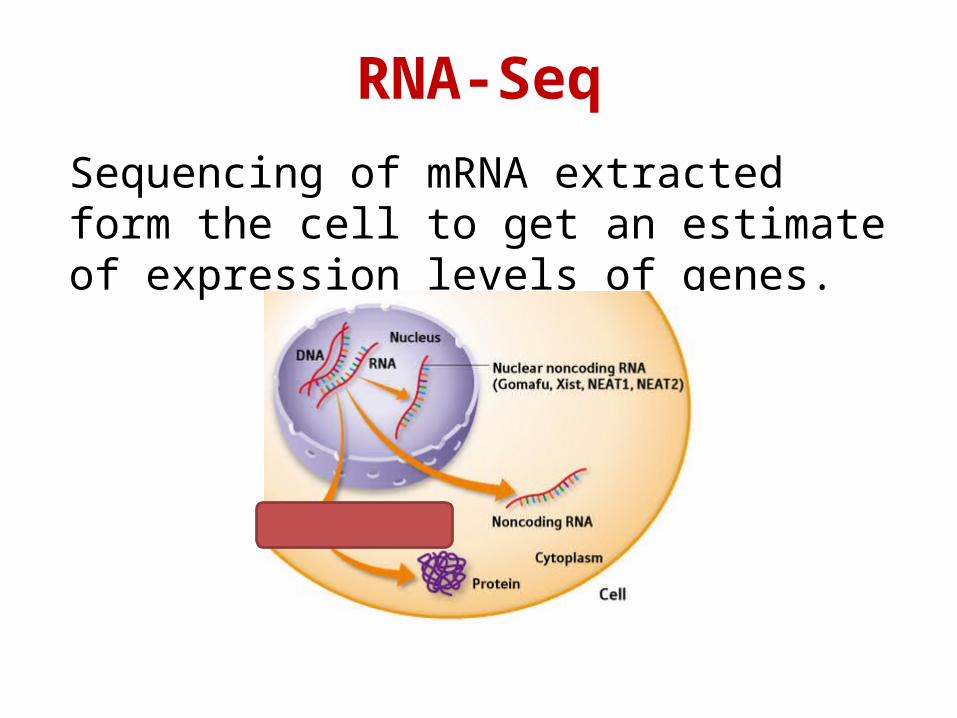
Sequencing of mRNA extracted form the cell to get an estimate of expression levels of genes.
RNA-Seq

Counting vs. Reading
RNA-Seq vs. DNA-sequencing
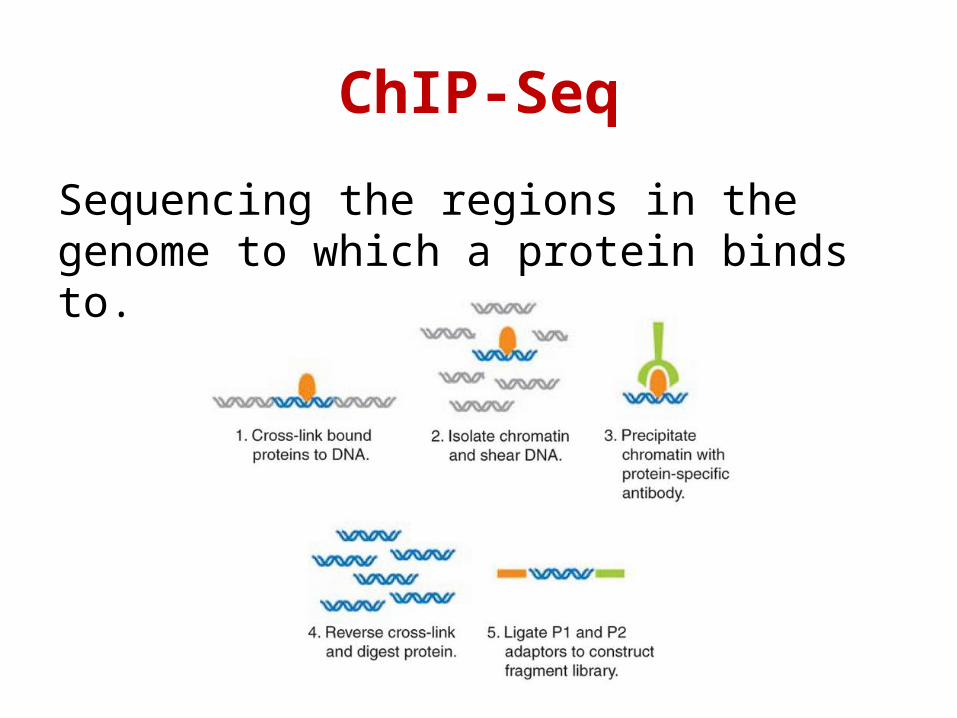
Sequencing the regions in the genome to which a protein binds to.
ChIP-Seq
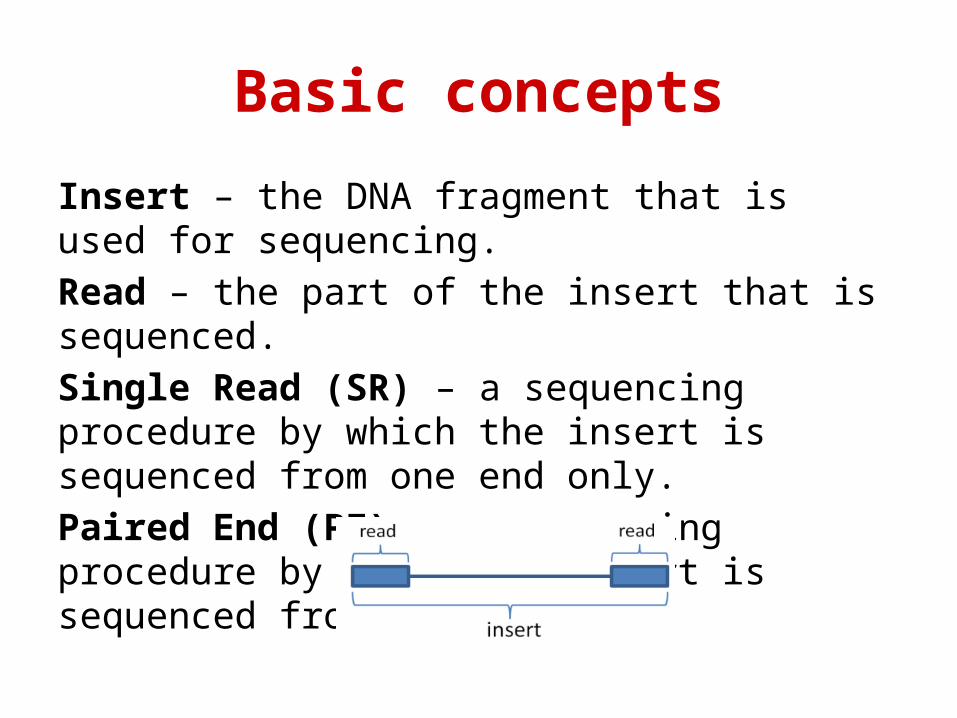
Basic concepts
Insert – the DNA fragment that is used for sequencing. Read – the part of the insert that is sequenced. Single Read (SR) – a sequencing procedure by which the insert is sequenced from one end only. Paired End (PE) – a sequencing procedure by which the insert is sequenced from both ends.

Bioinformatics Analysis Pipelines
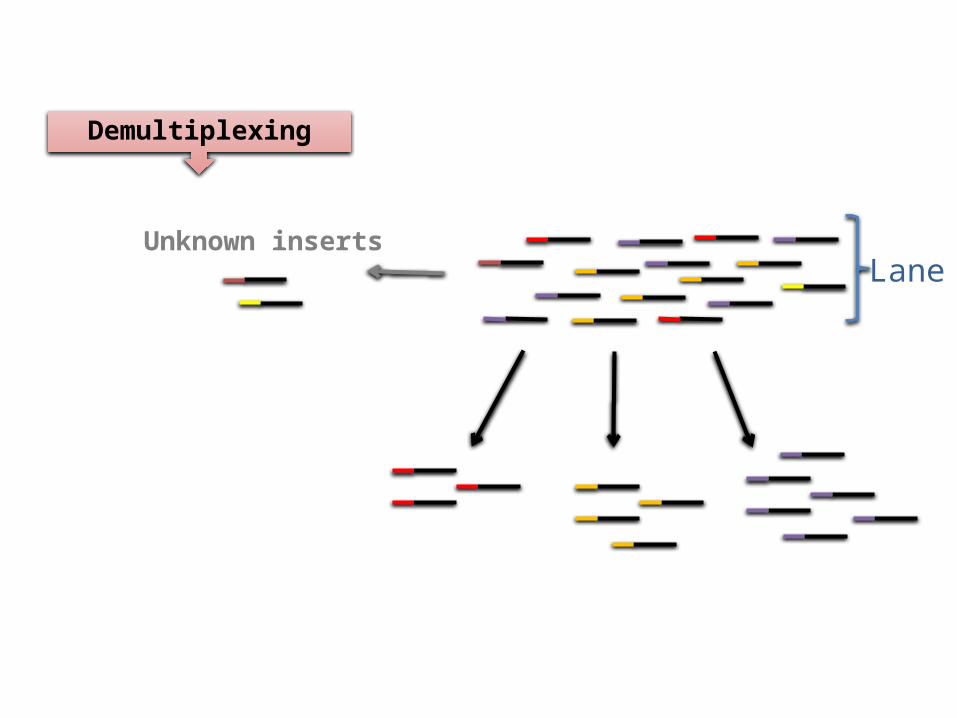
Demultiplexing
LaneUnknown inserts
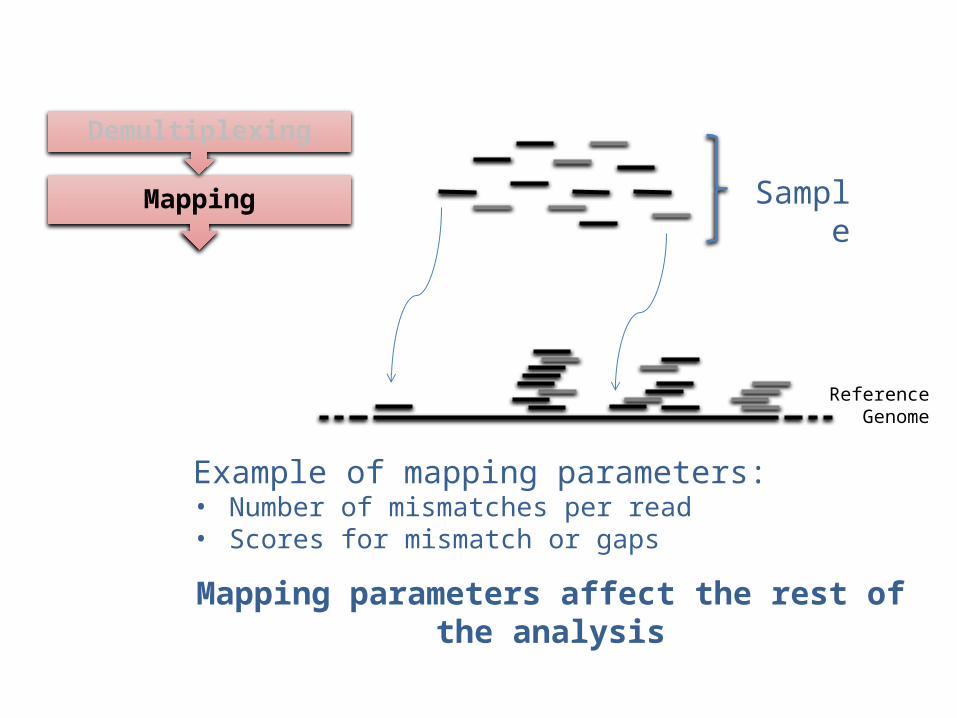
Reference Genome
SampleMapping
Demultiplexing
Example of mapping parameters:• Number of mismatches per read • Scores for mismatch or gaps
Mapping parameters affect the rest of the analysis
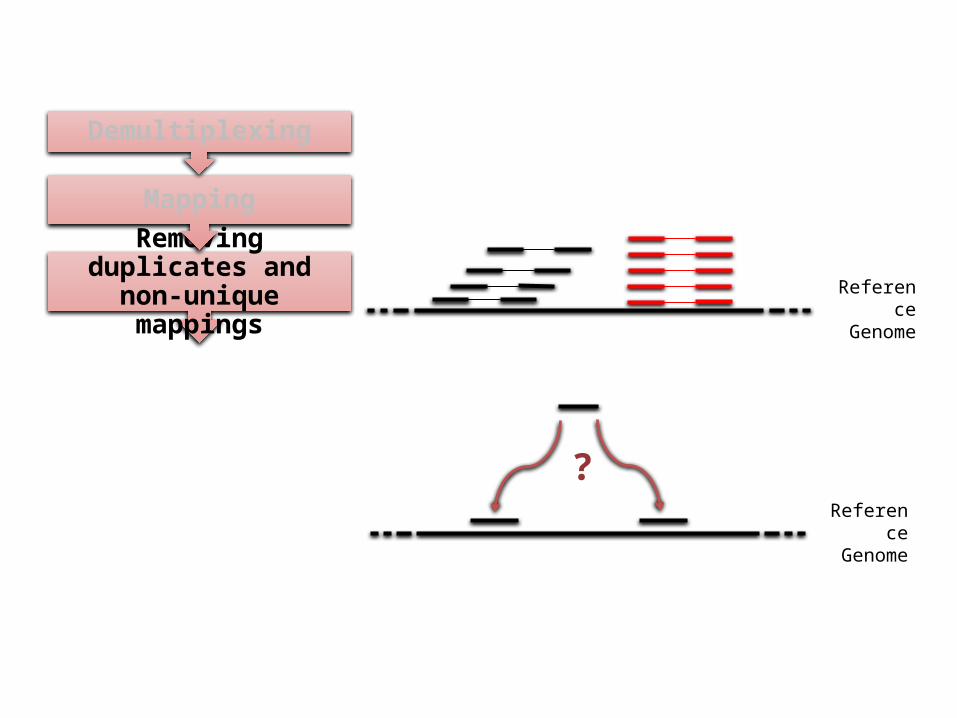
Removing duplicates and non-unique mappings
Mapping
Demultiplexing
Reference Genome
Reference Genome
?

Resequencing/ Exome Pipeline
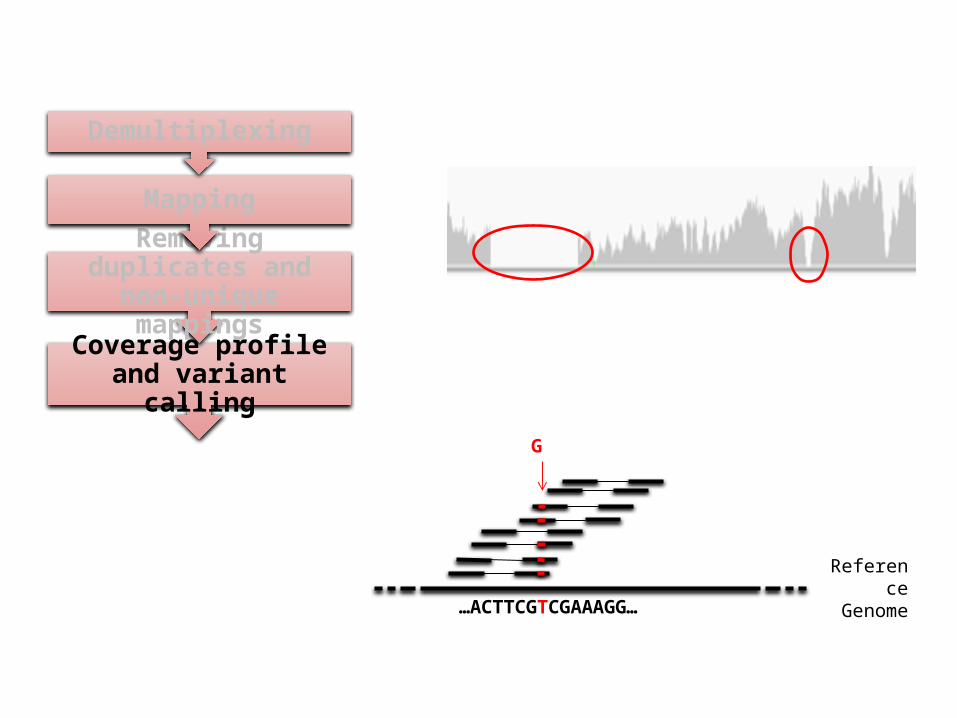
Coverage profile and variant calling
Removing duplicates and non-unique mappings
Mapping
Demultiplexing
Reference Genome
…ACTTCGTCGAAAGG…
G
Coverage profile and variant calling
Removing duplicates and non-unique mappings
Mapping
Demultiplexing
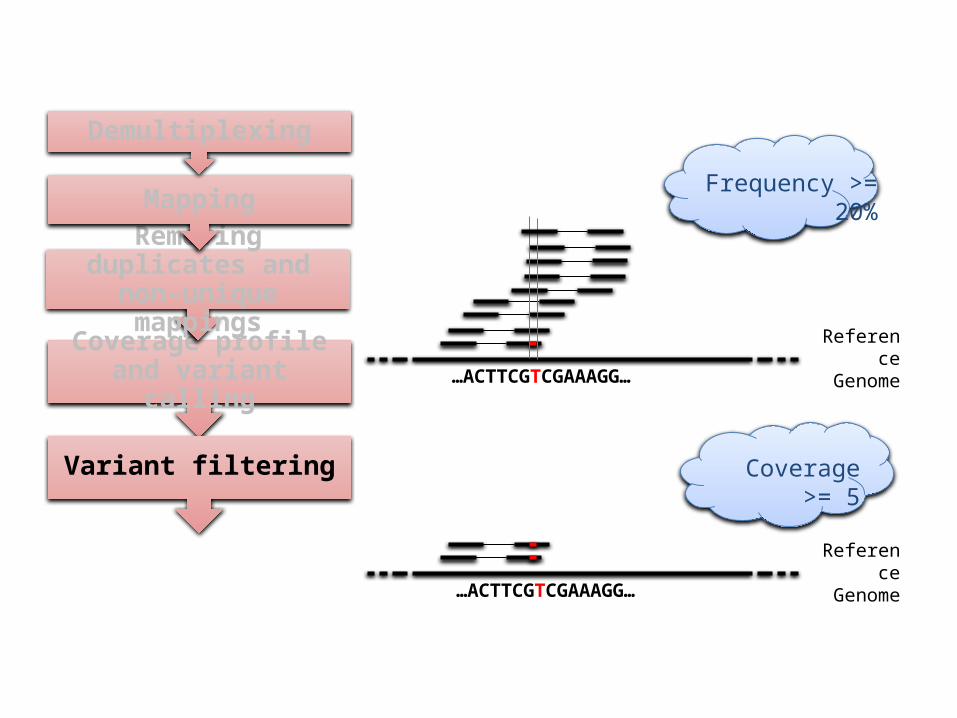
Variant filtering
Reference Genome
…ACTTCGTCGAAAGG…
Reference Genome
…ACTTCGTCGAAAGG…
Frequency >= 20%
Coverage >= 5
Variant calling
Removing duplicates and non-unique mappings
Mapping
Demultiplexing
Variant filtering
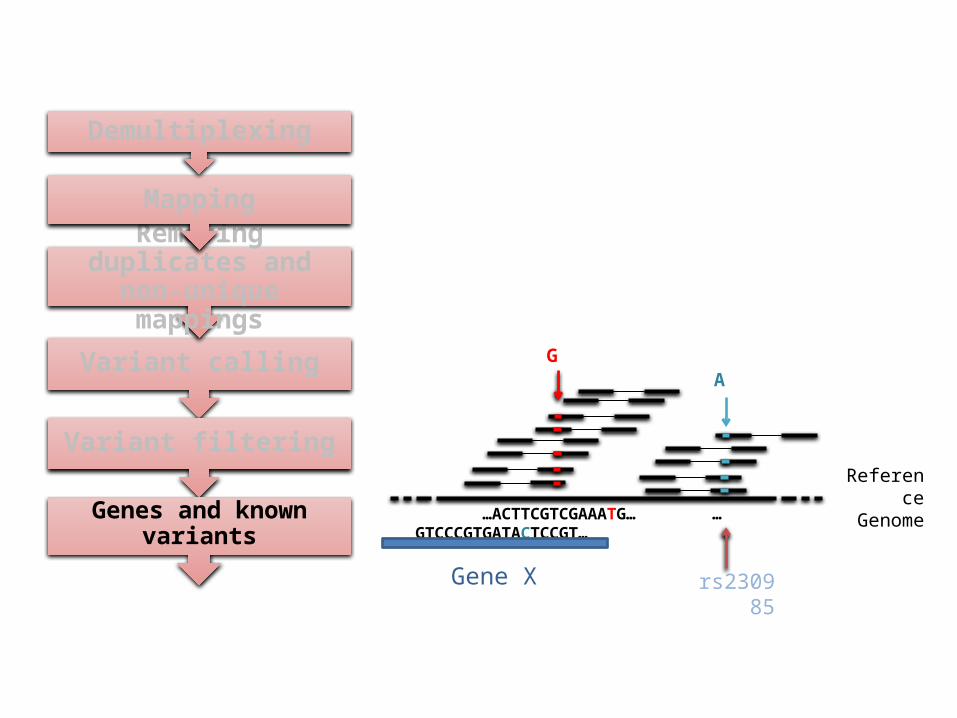
Genes and known variants
Reference Genome
…ACTTCGTCGAAATG… …GTCCCGTGATACTCCGT…
GA
rs230985Gene X
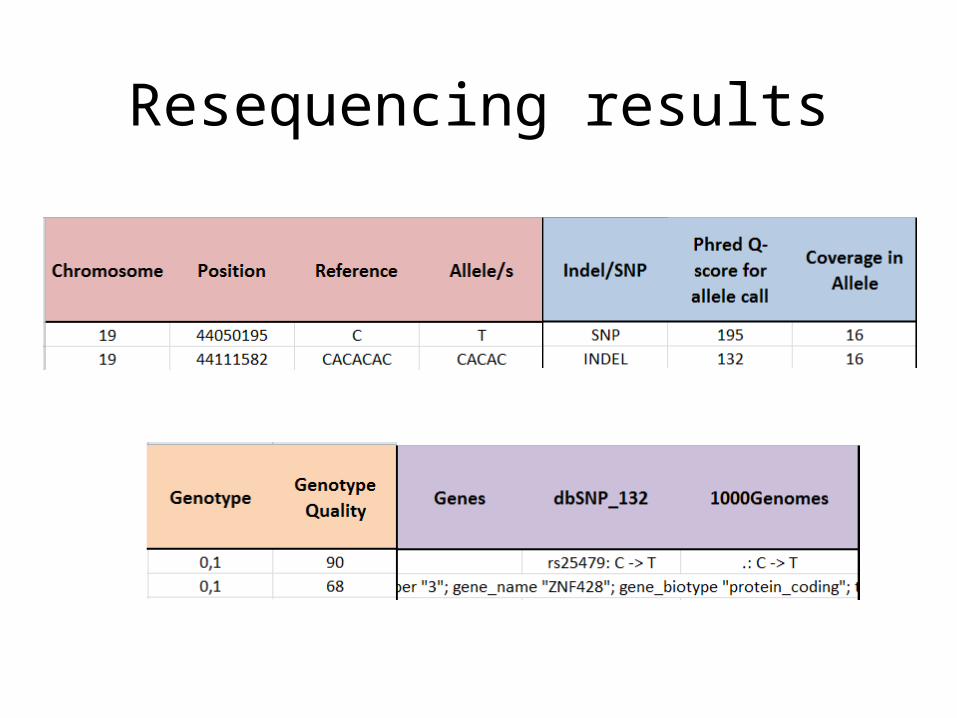
Resequencing results
Coverage profile and variant calling
Removing duplicates and non-unique mappings
Mapping
Demultiplexing
Variant filtering
Genes and known variants
Finding suspicious variants
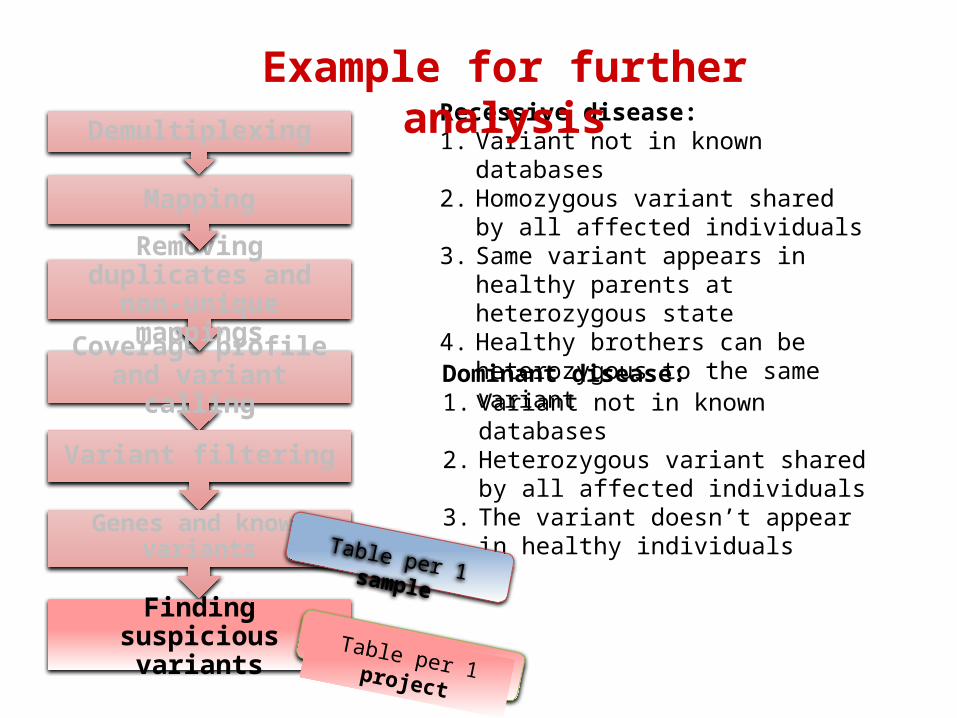
Recessive disease:1. Variant not in known databases2. Homozygous variant shared by all
affected individuals3. Same variant appears in healthy parents
at heterozygous state4. Healthy brothers can be heterozygous
to the same variant
Dominant disease:1. Variant not in known databases2. Heterozygous variant shared by all
affected individuals3. The variant doesn’t appear in healthy
individuals
1 Table per project
1 Table per sample
Example for further analysis
Coverage profile and variant calling
Removing duplicates and non-unique mappings
Mapping
Demultiplexing
Variant filtering
Genes and known variants
Finding suspicious variants
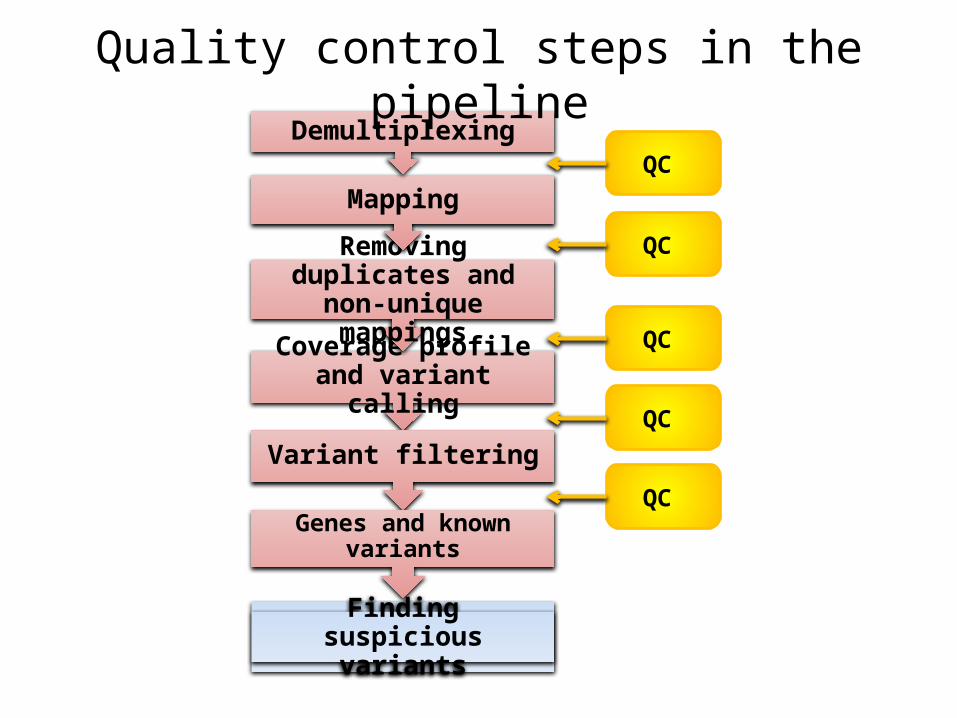
QC
QC
QC
QC
QC
Quality control steps in the pipeline

How is de-novo assembly different from resequencing analysis ?

RNA-Seq Pipeline
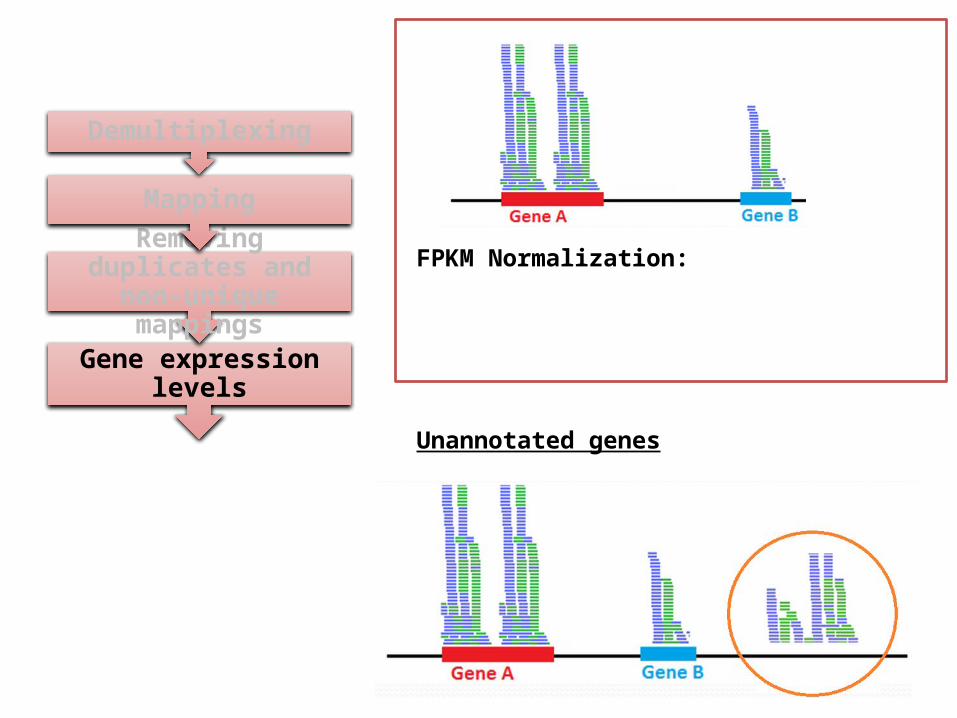
Gene expression levels
Removing duplicates and non-unique mappings
Mapping
Demultiplexing
FPKM Normalization:
Unannotated genes
Gene expression levels
Removing duplicates and non-unique mappings
Mapping
Demultiplexing
Differential gene expression
Differential expression parameters:• Threshold - Minimum number of reads for pair
testing• Normalization• Replicates
Differential expression parameters affect the results
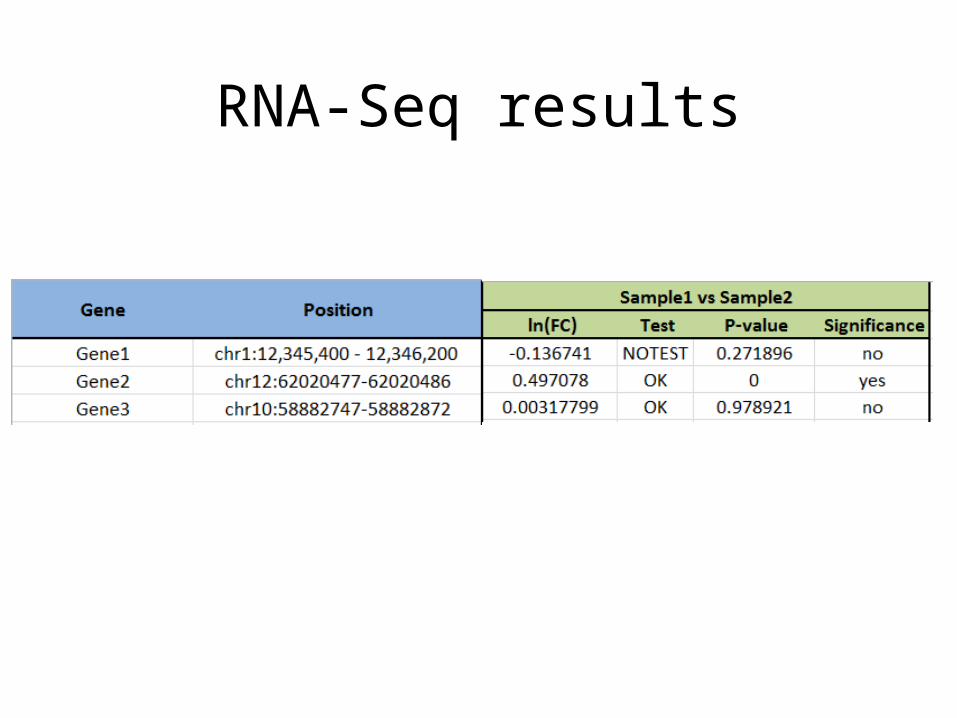
RNA-Seq results

CoverageCoverage – resequencingNumber of bases that cover each base in the genome in average.
“Coverage” – RNA-Seq• Depends on the expression profile of each
sample.• Highly expressed genes will be detected with less
“coverage” than lowly expressed genes.

What should you ask yourself before sequencing when planning the experiment
• Reference genome:– What is my reference genome? – Does it have updated annotations? – What annotations are known? – Are my samples closely related to the reference genome?
• Do I expect to have contaminations in my sample?• Do I have validations from other technologies? (RT-PCR,
SNPchip…)• Do I have controls and replicates?• RNA-Seq: am I interested in alternative splicing?• Resequencing: What kind of mutations do I expect to find?