high throughput processing of the structural information of the protein data bank zoltán szabadka,...
Post on 21-Dec-2015
218 views
TRANSCRIPT

High Throughput Processing of the Structural Information of the
Protein Data Bank
Zoltán Szabadka, Vince GrolmuszDepartment of Computer Science
Eötvös University, Budapest

What is wrong with the PDB?
• It is not uniform, each author has a different style• It is hard to process it automatically
– Residue numbering is not always sequential
– The chemical symbols of the atoms are often missing
– It is not easy to tell how many ligands there are in an entry, chain ids are not used consistently
– It is not clearly indicated if a molecule has missing atoms, and which atoms are missing
• There is a need for a “front-end” database to the PDB

database of structure andcoordinate data
test sets ofdocking algorithms list of
binding sites
statisticalinformation
Flow of data
Internet local PDB mirrordownload and check for updates
structural decomposition
SQL query SQL query SQL query

What type of molecules are there in a PDB entry?
• Protein chains (P)
• DNA/RNA chains (N)
• Ligands (L)
• Metals and other small ions (I)
• Water molecules (W)

Information stored in the database
• Covalent structure of molecules
• List of components of each entry
• Coordinate data for each atom
• Interactions between molecules

E/R diagram of the databasecovalent structure
idid
symbol
molecule contains atom bond type
type
monomercontains
id
num
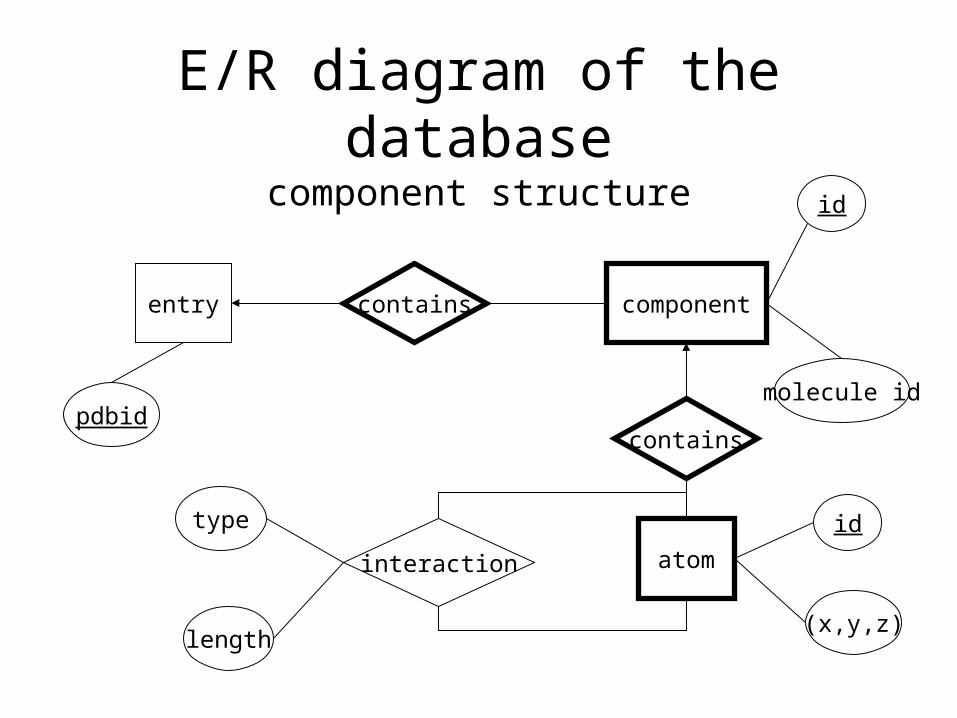
E/R diagram of the databasecomponent structure
entry componentcontains
pdbid
id
molecule id
atom
contains
interaction
(x,y,z)
idtype
length

PDB file formats
PDB format
This is the original PDB file format, it contains data records in separate lines, each with fixed length and format, eg. ATOM, HETATM,
SEQRES, CONECT, etc.
mmCIF formatThis is a relational database description language, a file contains
data tables called categories.
XML formatThe same tables are described by XML tags. The file sizes are huge, a file contains more data tags then data.

Structural units of an entry
• The basic structural unit of both the PDB and the mmCIF format is the so called monomer. It can be a molecule, a molecule fragment or just an atom.
• Each such monomer has an at most three letter long code, called monomer id, eg. ALA for alanine, MG for magnesium ion, ACE for acethyl group, or HOH for water.
• A protein chain consists of many amino acid monomers, each having a sequence number that indicates its position within the chain.
• Similarly, DNA/RNA chains consist of many nucleic acid monomers.
• Metals, small ions, water and most ligands are one monomer having a unique monomer id.
• The basic problem is that there are certain ligand molecules that consist of two or more monomers, and this information is not always properly annotated in the PDB entries in either formats.

mmCIF data categories• entity
List of molecules in the entry, can be of three types: polymer, non-polymer and water. Each molecule has an entity id.
• entity_polyContains the type of polymer entities, eg. polypeptide(L)
• struct_asymList of the components in the asymmetric unit. Each component has an asym id and an entity id.
• pdbx_poly_seq_schemeDescribes the sequence of monomers in a polymer entity.
• pdbx_nonpoly_schemeList of the monomers belonging to the non-polymer entities.
• atom_siteCoordinate data for atoms, whose positions could be experimentally
determined.

Structural decompositionbased on the mmCIF format
• First we read the list of components in the asymmetric unit.
• For each component, we read its entity type, and for each polymer entity, its polymer type.
• Then we read the sequence of monomers for the polymer entities, and the list of monomers belonging to the non-polymer entities.
• The structure of monomers if known ‘a priori’ from a file named components.cif, which can be found at RCSB’s web site.
• So for each monomer, we have a list of atoms, lacking coordinate information. Now we go through the table atom_site, and for each atom, we find the monomer it belongs to, and fill the coordinates for the atom just found. If an atom of a monomer is not found, it will be marked as missing.

Definition of molecule types
• Protein chain: a polymer entity of type “polypeptide(L)”, which is at least 10 monomers long
• DNA/RNA chain: a polymer entity, which is at least 5 monomers long and its type is either “polydeoxiribonucleotide”, “polyribonucleotide”, or more then half of its monomers are nucleic acids (A,C,G,I,T,U monomer id)
• Ion: there is a predefined list of monomer ids, containing metals and small ions
• Water: the monomers of the water entity
• Ligand: all monomers, that do not belong to the above categories will form the set of ligand monomers

Ligands and binding sites
• We define a graph on the atoms that have coordinate data. It will have two types of edges:– covalent: if the distance of the two atoms is less then 1.25 times the sum
of their covalent radii– VdW: if it is not covalent, but the distance of the two atoms is less then
the sum of their Van der Waals radii
• The graph is built using a 3 dimensional kd-tree in O(n log n) time• We go through the edges:
– if an edge of covalent type connects two ligand molecules, then they will be joined together in one new molecule
– if an edge connects a ligand to a protein chain, then this intermolecular interaction will be recorded in the protein-ligand interaction table, marking the binding site of this ligand on the protein surface

PDB version: June 6, 2005
• Number of PDB entries: 31,217
• Number of entries processed: 26,445
• Number of protein chains: 59,842
• Number of different sequences: 18,333
• Number of ligands: 53,834
• Number of different ligand molecules: 6,016
• Number of all atoms: 269,237,779– Number of atoms in protein chains: 240,243,785
– Number of atoms in DNA/RNA chains: 7,709,842
– Number of atoms in ligands and ions: 2,479,339
– Number of atoms in water: 18,804,813

Distribution of elements in ligands and ions
Organic elements
H
C
O
N
P
S
Other
Inorganic elements MGFECAZNCLNAMNFKCUCDWIBRHGXCONIOther
The distribution of the organic and the most frequent inorganic elements among the ligands and ions. We found 70 different elements.

Distribution of elements in protein chains
Element Number Monomers
P 499MIS, CSP, PTR, LLP, SEP, TPO, CYQ, GPL, PAS, ASQ, NEP, SDP, LYX
F 116EFC, FTR, YOF, BFD, LEF, 4FW, 4F3, MFC
AS 53 CAS, CAF, CZZ, CSR, CZ2HG 48 CMHI 13 TYI, PHIBE 9 BFDB 4 CLB, CLD, SBL, SBDBR 4 DBYCL 2 CLB, CLDPB 2 CSBV 2 SVA
Element Number %H 120638461 50,22C 75710684 31,51O 22672185 9,44N 20660541 8,60S 540432 0,22SE 20730 0,01
There were 17 different elements in the protein chains, the tables show the number of occurrences, and for the non-standard elements, the monomers that contain them.

Distribution of protein monomersLEU 8,81 8,77ALA 8,09 8,25GLY 7,58 7,66VAL 6,97 7,08GLU 6,50 6,57SER 6,22 6,10LYS 5,99 5,93ASP 5,75 5,73THR 5,72 5,71ILE 5,44 5,56ARG 4,97 4,95PRO 4,68 4,65ASN 4,40 4,34PHE 3,91 3,90GLN 3,81 3,73TYR 3,52 3,47HIS 2,44 2,46MET 2,05 2,14TRP 1,47 1,43CYS 1,45 1,39MSE 0,17 0,14
The table shows the distribution of the 20 natural amino acids and selenomethionine in the different chains and in all chains. The other non-standard monomers are listed below.
ACE 186 ABA 19 5HP 7 ASI 3 BHD 2 AEI MHL ARO EHPMLY 172 CXM 18 YCM 7 ALY 3 CYM 2 PAQ MCL LAL 3AHCGU 147 CSS 16 SCY 6 HMR 3 NVA 2 OSE MFC CLB DHLPCA 122 DAL 16 FTR 6 ORN 3 MSA 2 SNC CLD BAL MTYSEP 85 CSX 15 SAC 5 SET 3 CMT 2 TBM GLZ C6C BUCNH2 83 TPQ 15 MIS 5 NEP 3 DAH 2 DHN PCC DAS MGYCME 76 FME 15 DLE 5 TYI 3 143 2 CR5 DHA OAS DABPTR 55 MLZ 14 AYA 5 CAF 3 CZ2 2 LLY DPN 5CS PECKCX 48 MVA 11 TRQ 5 HTR 3 TRO 2 EFC SVA MPT HLUCSD 48 IIL 10 IAS 4 TA4 3 LEF 2 IML TMD NPH MDOMLE 46 SME 10 TRN 4 SEC 2 HSL 2 DBY CSA DSE SBLTPO 44 CSE 9 BFD 4 DOH 2 DCY 2 2MR S1H CY4 GLQYOF 39 MHO 9 CMH 4 CSB 2 DVA 2 SEG AHP TRF TYYCEA 37 STY 9 DSN 4 DTR 2 MSO 2 CYD AHB SOC BCSCAS 30 NLE 8 CSR 4 DMT 2 NIY 2 GHG 4F3 DHI 175LLP 28 M3L 8 NEM 4 STA 2 LYZ 2 DMG SBD TMB PYXCSO 24 SAR 8 OMT 4 MME 2 CCS 2 LYX GPL GLH MNVOCS 22 SEB 7 HIC 4 DGL 2 CSZ 2 ASB TYQ CZZ SDPCSW 21 BMT 7 DAR 3 ASQ 2 C5C 1 DDE CAY 4HT TYNTYS 20 MEN 7 CYG 3 CSP 2 PAS 1 CYQ PHI DTY 4FW

Protein-Ligand interactions
10gs
A
C
1
2
3
4 The table above shows the number of protein-ligand interactions, the number of entries they occur in, and the number of different interaction types while more and more con-ditions are met.
condition interaction entry int. type1 50988 12798 152891&4 45872 12072 141961&4&2b 20055 5752 65581&4&2b&5 13176 4660 49001&4&2b&3&5 10285 3655 36911&4&2a&3&5 6053 2193 2261
Conditions:1 bond type=VDW2a no missing atom from protein2b <10% missing atoms from protein3 no missing atom from ligand4 protein size btween 1000 and 100005 ligand size between 10 and 100

Distribution of missing atoms
0
2000
4000
6000
8000
10000
0 1-10 11-100 101-1000 1001-10000 10001-
number of missing atoms
nu
mb
er
of
PD
B e
ntr
ies
The distribution of the number of missing atoms from protein chains in the PDB entries. Note, that there are relatively few entries, where only a few atoms are missing.

Distribution of missing segments
0
1000
2000
3000
4000
5000
6000
1 4 7
10
13
16
19
22
25
28
31
34
37
40
0
100
200
300
400
500
1 4 7
10
13
16
19
22
25
28
31
34
37
40
0
200
400
600
800
1000
1200
1400
1 4 7
10
13
16
19
22
25
28
31
34
37
40
The distribution of the lengths of missing chain segments at the beginning, at the middle and at the end of the chains. The length is measured in amino acids. Note that in the middle of the chain, typically 4-7 amino acids are missing.

Thank You!