high performance computing for event generators at the lhc
TRANSCRIPT

High Performance Computing for Event Generators at the LHC
• A Multi-Threaded Version of MCFM, J.M. Campbell, R.K. Ellis, W. Giele, 2015.
• Higgs boson production in association with a jet at NNLO using jettiness subtractions,R. Boughezal, C. Focke, W. Giele, X. Liu, F. Petriello, 2015.
• Z-boson production in association with a jet at next-to-next-to-leading order in perturbative QCDR. Boughezal, J.M. Campbell, R.K. Ellis, C. Focke, W. Giele, X. Liu, F. Petriello, 2015.
• Color singlet production at NNLO in MCFM, R. Boughezal, J.M. Campbell, R.K. Ellis, C. Focke, W. Giele, X. Liu, F. Petriello, C. Williams, 2016.

Introduction

LHC physics & Event Generators
• Experiments require precise predictions of known physics to extract new physics such as e.g. the Higgs boson.
• One of the goals at the LHC is to measure its properties of the newly discovered Higgs.
• This requires measuring the Higgs couplings to other particles at high precision.
• Given the precision of the LHC experiments measurements, more and more accurate predictions are needed (lots of background events compared to signal).
• This requires high performance computing to get the desired accuracies on the theory predictions.
• It forces us to focus on high performance computing in development of tools for the experimenters.

The MCFM parton level event generator
• The event generator we use is MCFM.• “An update on vector boson pair production at
hadron colliders”, J.M. Campbell, R.K. Ellis, Phys. Rev. D60:113006 (1999)
• MCFM has been evolving since 1999 and currently it can make predictions for hundreds of processes at the LHC.
• Current LHC phenomenology requires a higher and higher precision.
• This requires to include higher order corrections to be calculated in the event generator.
• This will result in an exponential increase of required computer resources.

Making predictions
• MCFM makes predictions at the parton level order-by-order in the strong coupling constant.
• This means it will predict the jet momenta, and not its content.
• One can match a shower monte carlo such as PYTHIA to MCFM to get the particle content of the jets.
• The event generator consists of two parts:• The calculation of to parton scattering amplitudes.
• The integration of the partons over phase space to get the observables.
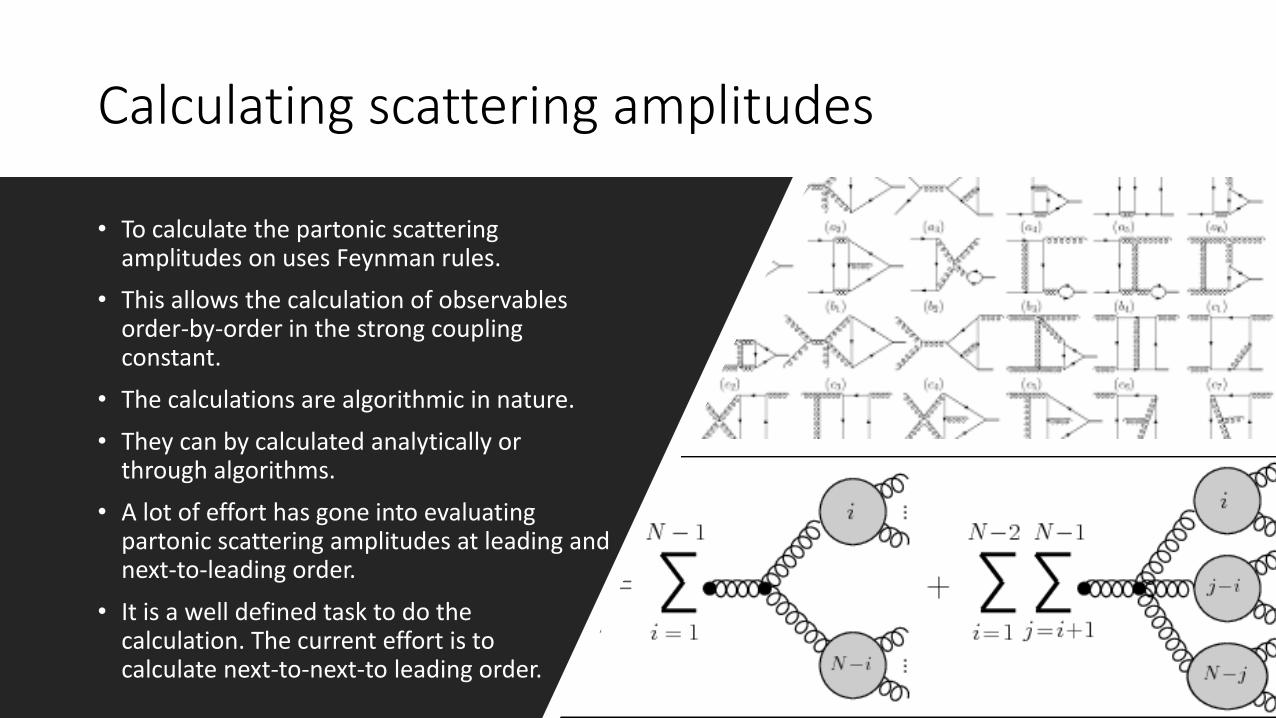
Calculating scattering amplitudes
• To calculate the partonic scattering amplitudes on uses Feynman rules.
• This allows the calculation of observables order-by-order in the strong coupling constant.
• The calculations are algorithmic in nature.
• They can by calculated analytically or through algorithms.
• A lot of effort has gone into evaluating partonic scattering amplitudes at leading and next-to-leading order.
• It is a well defined task to do the calculation. The current effort is tocalculate next-to-next-to leading order.

Phase space integration and Vegas
• The integration of the partonic scattering amplitude over phase space is more of “black art”.
• The integrations are high dimensional integrations (10-15 dimensions) over very complex functions.
• The standard tool used is VEGAS which is an adaptive integration algorithm.
• While imperfect, it performs well at next-to-leading order. At next-to-next-to leading order it is struggling a bit.
• Here is where almost all the computer time is spent, typical ~109 events.
• The goal is to do this in order hours ona medium sized cluster

High Performance Computing: MPI
• Runs a copy of the program on each node.
• Does simple communications between nodes by sending messages (data) between the nodes allowing simple parallelization.
• It is simple to program, but requires a non-standard extension of the compiler.
• It is made to run a job on different nodes, each with its own CPU and memory with limited exchange of data over a network.
• However, current CPU’s include more and more computing cores (threads) for parallelization which will cause problemsusing MPI.

High Performance Computing: openMP
• Runs on a single motherboard with unified memory.
• Made to make use of the multi-threading on modern CPU chips.
• Supports shared memory between threads which is crucial to get good scaling.
• openMP is part of the C/C++/Fortran standard.
• It is straightforward to add openMPdirectives into your existing program.
• To speed-up your program some thoughthas to be given to use of memory.

High Performance Computing hybrid MPI/openMP
• While openMP is perfect for multi-threaded parallel programming, you still need a way to distribute it over a cluster.
• For this you can use MPI, making your program scale on large clusters such as the CORI cluster at NERSC as well as your local cluster or your own desktop.
• We could change the existing MCFM event generator pretty easily by adding openMPcompiler directives and a few MPI instruction lines.
• Making it work and validation took awhile.

Paradigm shift in programming philosophy
• One important concept to understand in parallel programming is memory bound vs compute bound limits.
• We are used to use serial programming. Instead of recalculating things, storing and reusing data was often preferable.
• However, in parallel programming having many threads making memory requests will make all the threads sitting idle and the program speed is dictated by memory access (your program does not scale).
• By using shared memory or recalculatinginstead of storing data will overcome thisand make your time scale with the number of used threads.

Paradigm shift in programming philosophy
• Ones first instinct is to run independent jobs, each with different random numbers on each thread and combine the different results.
• This will run into massive memory bound issues and no acceleration is obtain. Even worse often execution slows down significantly.
• Proper use of openMP is crucial for proper scaling which involves giving some thought about memory usage.
• Optimizing the shared memory usage is critical to reach the compute limit.

Making a parallel event generator

Putting it all together• I gave an overview of all components needed
to construct the event generator which will run and scale on modern processors and clusters.
• We can now put everything together and use it on realistic physical predictions to see how it works.
• The first step is to use openMP and get the event generator to scale properly on a single node/motherboard.A Multi-Threaded Version of MCFM, J.M. Campbell, R.K. Ellis, W. Giele, 2015.
• The next step is to build in support forrunning on clusters using MPI.Color singlet production at NNLO in MCFM, R. Boughezal, J.M. Campbell, R.K. Ellis, C. Focke,W. Giele, X. Liu, F. Petriello, C. Williams, 2016.

How to parallelize
• The Monte Carlo adaptive integration is done through VEGAS.
• In each iteration the grid is optimized using the nevent generated events.
• This means in the next iteration, the randomly generated events follow more the scattering amplitude.
• This allows a fairly simple parallelization of the event generation
do i=1,iterations
do j=1,nevents
Evaluate a randomly generated event
endo
Optimize grid

Including openMP
• We use openMP so the inner loop is spread over the available threads.
• For the optimization of the grid the results of all threads are used.
• To debug the parallelized event generation, we ensured exactly the same events were generated independent of the number of threads used.
• Using this the bugs (due to parallelization) were readily exposed.
do i=1,iterations
do j=1,nevents
Evaluate a randomly generated event
endo
Optimize grid

Hardware used• We use 4 different configurations to test openMP
version of MCFM:
• Standard desktop using an Intel core I7-4770 (4 cores/8 threads, 3.4Ghz, 8MB cache)
• Double Intel x5650 processor (2x6 cores, 2.66Ghz,12Mb cache)).
• Quadruple AMD 6128 HE opteron (4x8 cores, 2Ghz, 12Mb cache.
• Xeon Phi co-processor (60 cores/240 threads, 1.1Ghz, 28.5 Mb).
• These are all single motherboards and could be in a workstation
• The Xeon Phi slots into the PCI-bus of a workstation.

First look at LO
• We see the effect of hyper threading on the Intel Core I7.
• The Intel Xeon scales very well and is fully compute bound.
• We see a memory bound issue for the AMD 6128 above 16 used treads
• Similar for the Xeon Phi co-processor.
• Leading Order is not particularly computer intensive, we need more compute intensive processes.
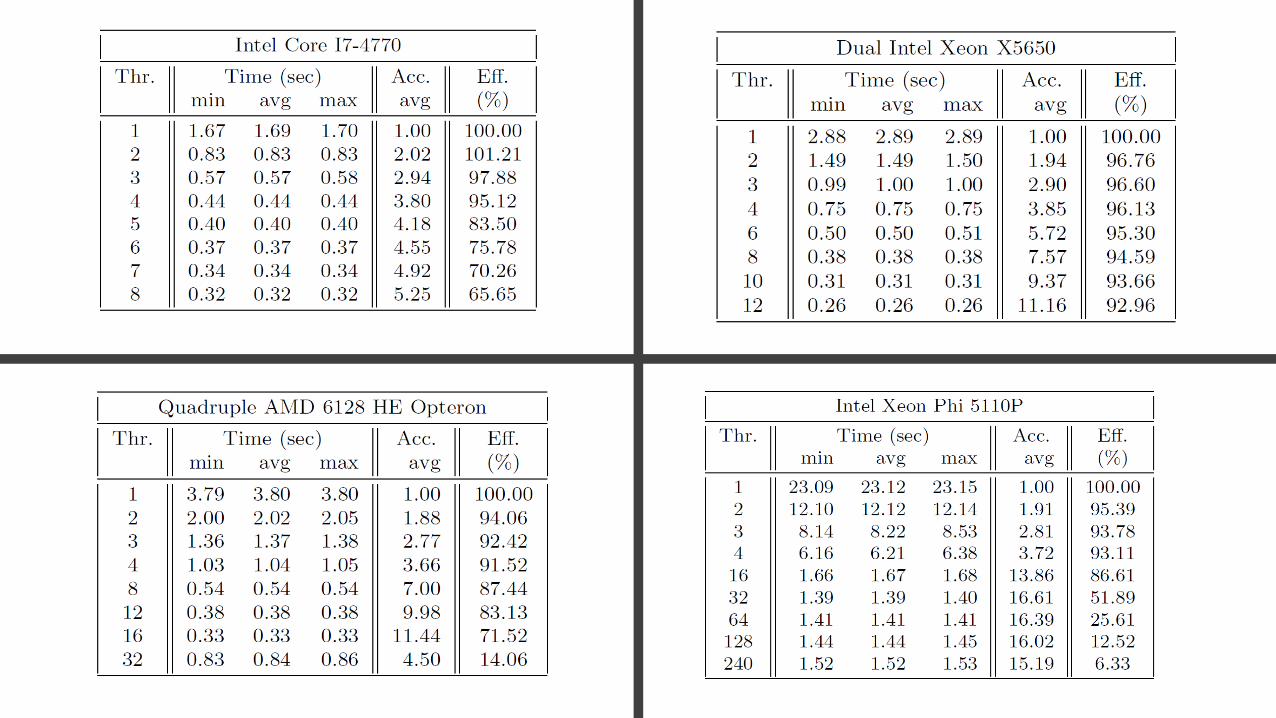

NLO performance
• At Next-to-Leading order much more has to be calculated.
• As a result we see good scaling, without any memory bound issues
• The Xeon Phi co-processor has 60 processors each with 4 cores/threads. You can see some artifacts at 60/120/180 boundaries
• The overall performance of MCFM using openMP is very good, e.g. on the AMD motherboard performance is increases by ~32!

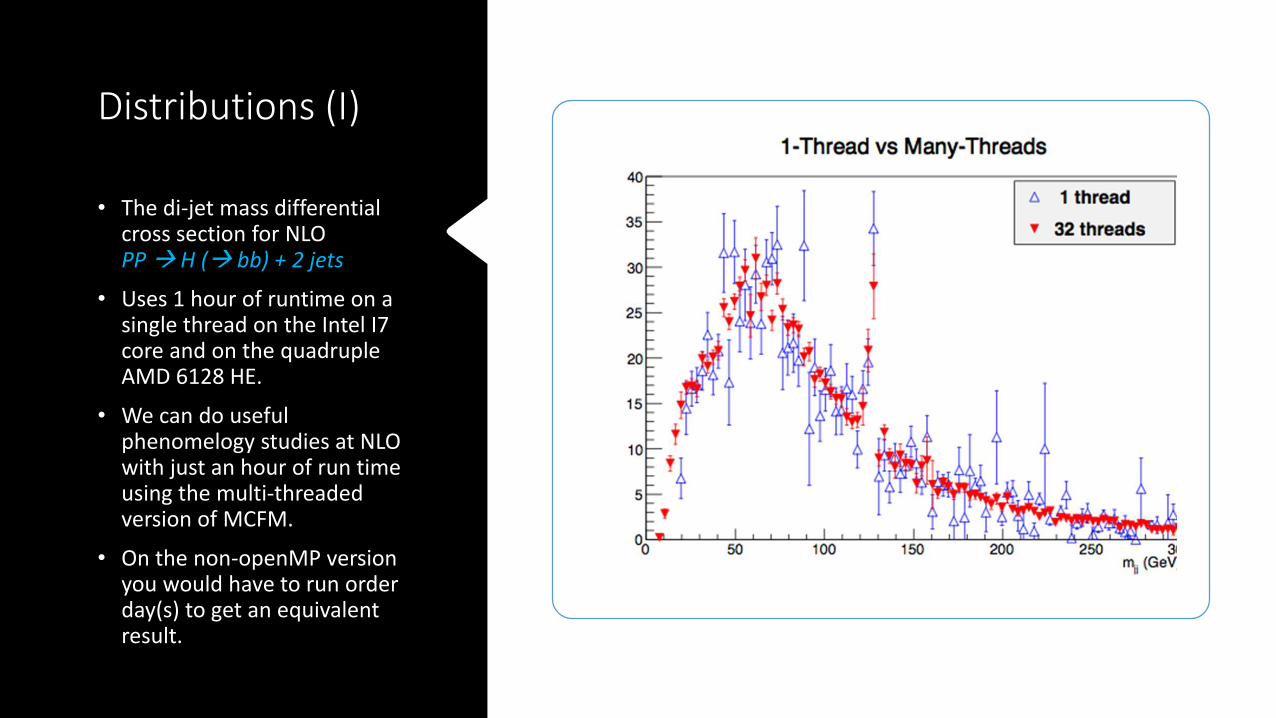
Distributions (I)
• The di-jet mass differential cross section for NLOPP H ( bb) + 2 jets
• Uses 1 hour of runtime on a single thread on the Intel I7 core and on the quadruple AMD 6128 HE.
• We can do useful phenomelogy studies at NLO with just an hour of run time using the multi-threaded version of MCFM.
• On the non-openMP version you would have to run order day(s) to get an equivalent result.
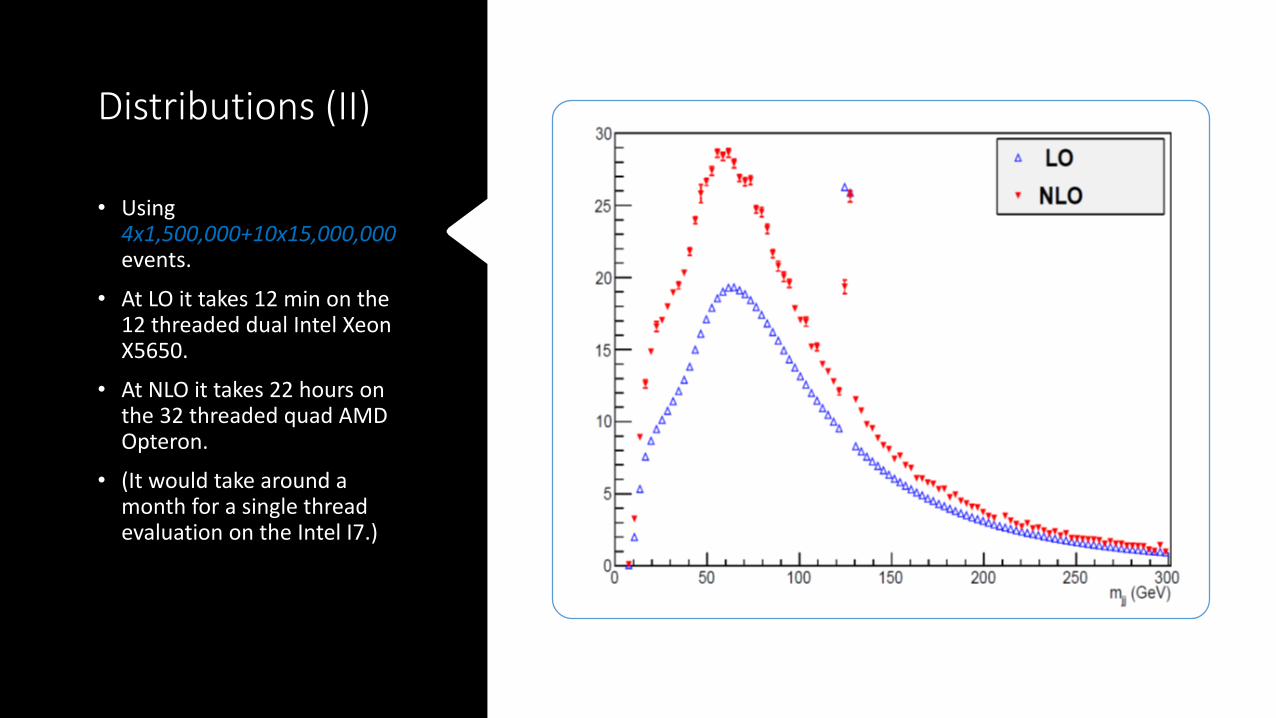
Distributions (II)
• Using 4x1,500,000+10x15,000,000events.
• At LO it takes 12 min on the 12 threaded dual Intel Xeon X5650.
• At NLO it takes 22 hours on the 32 threaded quad AMD Opteron.
• (It would take around a month for a single thread evaluation on the Intel I7.)

Going to NNLO
• The LHC accuracy more and more necessitates going to Next-to-Next-to Leading Order.
• From LO NLO we went from ~10 minutes to ~10 hours using openMPon a single motherboard.
• For NNLO we would need month(s) we need to run on a cluster.
• This means we have to include MPI into the code.

Implementing MPI
• The implementation is easy by adding a few code lines.
• The syntax is somewhat awkward as is the compilation (requiring a “modified compiler”).
• Because there is no shared memory, debugging is quite trivial compared to openMP.
• Because MPI is not standardized often some runtime tinkering is needed (depends a bit on cluster hardware etc).
do i=1,iterations
do j=1,nevents
Evaluate a randomly generated event
endo
Optimize grid
call mpi_bcast(xi,ngrid*MXDIM,mpi_double_precision,. 0,mpi_comm_world,ierr)
!$omp parallel do !$omp& schedule(dynamic) !$omp& default(private) !$omp& shared(incall,xi,ncall,ndim,sfun,sfun2,d,cfun,cfun2,cd) !$omp& shared(rank,size)
do calls = 1, ncall/size

Hardware used• We use 3 different configurations to test hybrid
openMP/MPI version of MCFM:
• Double Intel x5650 processor (2x6 cores, 2.66Ghz,12Mb cache) which is part of a 24 node cluster.
• Quadruple AMD 6128 HE opteron (4x8 cores, 2Ghz, 12Mb cache) which is part of a 32 node cluster.
• Xeon Phi co-processor (60 cores/240 threads, 1.1Ghz, 28.5 Mb). The NERSC Cori cluster uses an more recent version of the Xeon Phi on each node:• 9,668 single-socket compute nodes in the system.
• Each node contains an Intel® Xeon Phi™ Processor 7250 @ 1.40GHz.
• 68 cores per node with support for 4 hardware threads each (272 threads total).

Scaling on NERSC
• The process is NLO PPH+2 jets.
• Two 6-core intel chips per node→ 6 openMPthreads/MPI task
• Scales as expected up to ~5,000 threads (running on NERC)
• Note that above 5,000 threads we get low on events/thread and we become memory bound.

A first look at NNLO
• Runtime of ppW+ for LO/NLO/NNLO from 1 up to 288 cores.
• The cluster consists of 24 nodes, each containing 2 processors of 6 cores.
• Two running modes:
• 1 MPI job per node: 1x12 (divided cache)
• 2 MPI jobs per node, i.e. 1 MPI job per processor: 2x6
• Used 4x100,000+10x1,000,000 Vegas events.
• LO/NLO stopped scaling above 50/100 cores memory dominated regime.
• 1x12 runs slower than 2x6 because openMP does not have to sync cache between the 2 processors in the 2x6 case.

NNLOperformance
• Better to run 1 MPI job/processor than 1 MPI job/node.
• LO is memory bound.
• NNLO is computing bound.
• Going an order higher in PQCD takes about order of magnitude in time.
• We see we can run NNLO W production in just over 5 minutes on 288 nodes.

Scaling behavior
• The NNLO scaling for all singlet processes included in MCFM 8.0 as a function of the number of MPI jobs.
• Used 4x100,000+10x1,000,000Vegas events.
• Each MPI job is one processor with 6 cores.
• Only the PPH shows the onset of non-scaling at 48 MPI jobs.
• All other processes can be speed up efficiently using a larger cluster.

Scaling behavior
• Run times for all processes in the first release on NNLO MCFM.
• Other decay modes are also included.
• We see good scaling. For the simpler processes we see the memory bound limit transition starting.
• It will be no problem to run with 10-100 times more events: still less than 24 hr.

Results for LHC

NNLO phenomenology
• With the hybrid openMP/MPI version of MCFM we can make NNLO predictions for the LHC.
• The uncertainties in the NNLO predictions should be sufficiently small compared to the experimental uncertainties.
• We can make accurate predictions on moderate clusters on a time scale of a day.
• As a consequence, we can now expand to more complicated final states such as e.g. ppV+jets

NNLO phenomenology
• Here are some results ppZ+ jet at NNLO.
• Thse are complicated processes and require a large cluster (like NERSC) to run.
• This process is not yet in the public version of MCFM.
• But it will be included in the next version (together with processes like ppW+jet, ppH+jet. ppphoton+jet).
• We hope that improved methods of phase space integration will reduce the required run time.

Alternatives

Scaling on GPU’s
• Use a desktop with a multi-core processor and a Nvidia GPU.
• The most time consuming part on NNLO is the double bremsstrahlung tree level evaluation
• One can program a GPU to do tree level recursion relations!
• The speedup times in the table are on a GPU several generations out
• Expect an order of magnitude more gain on a modern GPU (from 0.66 Teraflops 5.5 Teraflops for DP).
Thread-Scalable Evaluation of Multi-Jet Observables, W. Giele, G. Stavenga, J. Winter, 2010

Conclusions

Conclusions
• We successfully were able to make a multi-threaded version of MCFM, able to run and scale well on workstations and all sizes of big clusters.
• Our competitors have sofar not succeeded making their code parallel.
• With this publicly available threaded version of MCFM we can do efficient NNLO phenomenology at the LHC for color singlet (i.e. no jets) processes at the LHC.
• We are working on many fronts to include new processes and advance the numerical techniques such as phase space integration to be able to include more complicated processes at NNLO.
• The next version(s) of MCFM will also include ppV+jet, ppH+jet, ppphoton+jet, ppVV,…