herbstworkshop zum thema „methodisch probleme in ... · treatment needs (cpitn), int dent j. 1982...
TRANSCRIPT

1
Herbstworkshop zum Thema
„Methodisch Probleme in Diagnostischen Studien“
am 22./23. November 2012
in der Abteilung Medizinische Statistik, Universitätsmedizin Göttingen
Beteiligte AG’s:
AG Epidemiologische Methoden
AG Statistische Methoden in der Medizin
AG Statistische Methoden in der Epidemiologie
AG Statistische Methodik in der klinischen Forschung
der Fachgesellschaften:
2
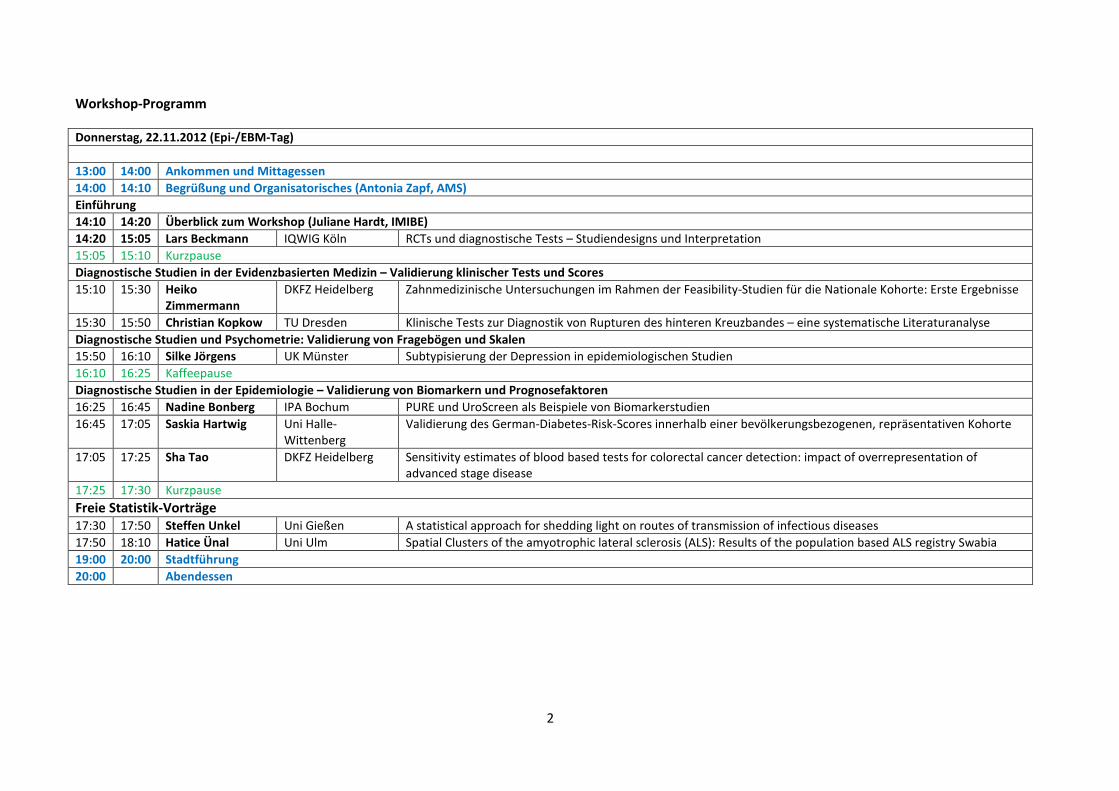
Workshop-Programm
Donnerstag, 22.11.2012 (Epi-/EBM-Tag)
13:00 14:00 Ankommen und Mittagessen
14:00 14:10 Begrüßung und Organisatorisches (Antonia Zapf, AMS)
Einführung
14:10 14:20 Überblick zum Workshop (Juliane Hardt, IMIBE)
14:20 15:05 Lars Beckmann IQWIG Köln RCTs und diagnostische Tests – Studiendesigns und Interpretation
15:05 15:10 Kurzpause
Diagnostische Studien in der Evidenzbasierten Medizin – Validierung klinischer Tests und Scores
15:10 15:30 Heiko Zimmermann
DKFZ Heidelberg Zahnmedizinische Untersuchungen im Rahmen der Feasibility-Studien für die Nationale Kohorte: Erste Ergebnisse
15:30 15:50 Christian Kopkow TU Dresden Klinische Tests zur Diagnostik von Rupturen des hinteren Kreuzbandes – eine systematische Literaturanalyse
Diagnostische Studien und Psychometrie: Validierung von Fragebögen und Skalen
15:50 16:10 Silke Jörgens UK Münster Subtypisierung der Depression in epidemiologischen Studien
16:10 16:25 Kaffeepause
Diagnostische Studien in der Epidemiologie – Validierung von Biomarkern und Prognosefaktoren
16:25 16:45 Nadine Bonberg IPA Bochum PURE und UroScreen als Beispiele von Biomarkerstudien
16:45 17:05 Saskia Hartwig Uni Halle-
Wittenberg
Validierung des German-Diabetes-Risk-Scores innerhalb einer bevölkerungsbezogenen, repräsentativen Kohorte
17:05 17:25 Sha Tao DKFZ Heidelberg Sensitivity estimates of blood based tests for colorectal cancer detection: impact of overrepresentation of
advanced stage disease
17:25 17:30 Kurzpause
Freie Statistik-Vorträge
17:30 17:50 Steffen Unkel Uni Gießen A statistical approach for shedding light on routes of transmission of infectious diseases
17:50 18:10 Hatice Ünal Uni Ulm Spatial Clusters of the amyotrophic lateral sclerosis (ALS): Results of the population based ALS registry Swabia
19:00 20:00 Stadtführung
20:00 Abendessen

3
Freitag, 23.11.2012 (Statistik-Tag)
09:00 09:30 AG-Sitzungen (parallel)
09:30 09:35 Kurzpause
Statistische Methoden in Diagnostischen Studien
09:35 09:55 Kristin Mühlenbruch
DIfE Potsdam Evaluation von Verbesserungen bei Risikoprädiktionsmodellen: Einfluss der gewählten Risikokategorien auf den Net
Reclassification Improvement
09:55 10:15 Michael Schneider MHH Hannover Angewendete Methoden zur systematischen Untersuchung der diagnostischen Wertigkeit von multiplen
diagnostischen Tests
10:15 10:35 Daniela Wenzel MHH Hannover Difference of two Dependent Sensitivities and Specificities: Comparison of Various Approaches
10:35 10:50 Kaffeepause
10:50 11:10 Katharina Lange UM Göttingen Analyse verschiedener diagnostischer Gütemaße in faktoriellen Versuchsanlagen
Diagnostische Meta-Analysen
11:10 11:30 Wiebke Sieben IQWIG Köln Zusammenfassung diagnostischer Studien – ein Vorschlag zur Vorgehensweise
11:30 11:50 Gerta Rücker Uni Freiburg Modelling of ROC curves in meta-analysis of diagnostic test accuracy studies
11:50 11:55 Kurzpause
11:55 12:15 Annika Hoyer LMU München Statistical Methods for Meta-Analysis of Diagnostic Tests accounting for Prevalence – A new Model using trivariate
Copulas
12:15 12:35 Oliver Kuss Uni Halle-
Wittenberg
Meta-analysis for the comparison of two diagnostic tests to a common gold standard: First experiences with
quadrivariate statistical models
12:35 12:50 Feedback & Ausblick
12:50 13:30 Ausklingen und Austausch bei Brötchen und Getränken

4
Abstracts
(in der Reihenfolge wie im Programm)

5
Titel: RCTs und diagnostische Tests – Studiendesigns und Interpretation
Autoren: Lars Beckmann1, Johanna Buncke2, Ralf Bender1, Fülöp Scheibler1
Institute: 1: Institut für Qualität und Wirtschaftlichkeit im Gesundheitswesen (IQWiG)
2: Johannes Gutenberg-Universität Mainz
Email: [email protected], [email protected] , [email protected]
Abstract:
Der therapeutische Nutzen eines diagnostischen Tests lässt sich nicht anhand der diagnostischen
Güte als Surrogat beurteilen. Analog zur Beurteilung des Nutzens von Medikamenten sind dazu
randomisierte kontrollierte Studien (Randomised Controlled Trials, RCTs) in Zusammenhang mit
spezifischen Therapien notwendig. In der Literatur werden verschiedene theoretische Studiendesigns
für die Durchführung von RCTs für die Nutzenbewertung von diagnostischen Tests diskutiert [1-3].
Vereinfacht lassen sich die Designs in drei Gruppen einteilen: das Anreicherungsdesign, die Marker-
basierte Strategie und das Interaktionsdesign.
Aufbauend auf den Ergebnissen eines systematisches Reviews zu publizierten und geplanten RCTs zur
Positronenemissionstomographie [4] diskutieren wir die Studiendesigns hinsichtlich der Frage, in wie
weit die Studien geeignet sind, den Nutzen eines Tests nachzuweisen. So können RCTS basierend auf
dem Anreicherungsdesign oder der Marker-basierten Strategie nicht a priori als Nutzenstudien bzgl.
eines Tests angesehen werden. Vielmehr hängt die Interpretation der Ergebnisse von
Voraussetzungen bzgl. der involvierten Therapien ab. Dagegen können Interaktionsdesigns, in denen
theoretisch ein Nutzen ohne weitere Voraussetzungen abgeleitet werden kann, aus praktischen und
ethischen Erwägungen nicht immer, bzw. nur mit Informationsverlust, durchgeführt werden.
Des Weiteren diskutieren wir in wie weit die Rolle eines Tests in der diagnostischen Kette im
Versorgungsalltag sich in RCTs wiederspiegeln kann und welche Punkte bei der Auswertung und
Interpretation zu beachten sind.
Zusammenfassend lässt sich sagen, dass RCTs zur Nutzenbewertung von diagnostischen Tests
prinzipiell immer durchführbar sind. Die Wahl eines spezifischen Studiendesigns hängt von
praktischen und ethischen Voraussetzungen ab ebenso wie von a priori Annahmen über die
Therapien, in deren Zusammenhang der Test angewendet wird. Alternative Ansätze wie die
Verwendung der diagnostischen Güte als Surrogat sowie Linked Evidence sind kritisch zu sehen,
wenn die Studien als Grundlage für evidenzbasierte Entscheidungen dienen sollen.
Literatur:
1. Janatzek, S., Nutzen diagnostischer Tests – vom Surrogat zur Patientenrelevanz. Z Evid
Fortbild Qual Gesundhwes, 2011. 105(7): p. 504-9.
2. Lijmer, J.G. and P.M. Bossuyt, Various randomized designs can be used to evaluate medical
tests. J Clin Epidemiol, 2009. 62(4): p. 364-73.
3. Sargent, D.J., et al., Clinical trial designs for predictive marker validation in cancer treatment
trials. J Clin Oncol, 2005. 23(9): p. 2020-7.
4. Scheibler, F., et al., Randomized controlled trials on PET: a systematic review of topics,
design, and quality. J Nucl Med, 2012. 53(7): p. 1016-25.

6
Zahnmedizinische Untersuchungen im Rahmen der Feasibility-Studien für
die Nationale Kohorte: Erste Ergebnisse
Zimmermann H.¹, Hagenfeld D.², Beldoch M.², Zimmermann N.², El Sayed N.², Diercke K.², Kaaks R.³,
Greiser K.H.³, Fricke J.³, Seydel H.³, Ramroth H.¹, Schmitter M.², Kocher T.⁴, Kühnisch J.⁵, Kim T.-S.²,
Becher H.¹
¹ Institute of Public Health, University Hospital Heidelberg, Germany
² Section of Periodontology, Department of Conservative Dentistry, University Hospital Heidelberg, Germany
³ Division of Cancer Epidemiology, German Cancer Research Center (DKFZ), Heidelberg, Germany
⁴ Department of Periodontology, Policlinics for Restorative Dentistry, Periodontology and Endodontology,
Greifswald,Germany
⁵ Section of Pediatric Dentistry, Policlinics for Restorative Dentistry and Periodontology, University Hospital of
Munich,Germany
Eine der Studien zur Vorbereitung der nationalen Kohorte [1] beschäftigte sich mit der Erhebung der
Zahngesundheit. Das primäre Ziel war die Untersuchung der Machbarkeit, die Untersuchung der
benötigten Zeiten, sowie die Frage, wie zuverlässig eine geschulte Studienassistentin die Erhebung
des Zahnstatus vornehmen kann.
Es wurden 405 Probanden in 3 Zentren (Augsburg (n=79), Greifswald (n=111) und Heidelberg
(n=215)) rekrutiert, die u.a. im Hinblick auf zahnmedizinische Parameter wie Zahnstatus,
Taschentiefen [2], Attachmentlevel und Plaque untersucht wurden. In Heidelberg wurde die
Untersuchung mit einer anderen Machbarkeitsstudie, der Untersuchung von
Rekrutierungsmöglichkeiten für Migranten, kombiniert. In Heidelberg waren nach Abschluss der
Studie im Mai 2012 96 Probanden deutscher Nationalität (43m/ 53w), 69 türkischstämmige
Probanden (31m/ 38w) und 50 Aussiedler (18m/ 32w) aus der früheren Sowjetunion rekrutiert. Zur
Kompensation sprachlicher Barrieren bei Migranten wurde sowohl die Rekrutierung, als auch die
Untersuchung durch zusätzliches mehrsprachiges Personal sowie entsprechende Instrumentarien
unterstützt. In diesem Beitrag werden Ergebnisse der in Heidelberg rekrutierten Probanden
vorgestellt. Es wurden Analysen zu Reliabilität, Sensitivität bei Taschentiefenmessungen zwischen
Zahnarzt und Studienassistentin durchgeführt. Zur Überprüfung der Übereinstimmung wurde auf
Maße wie Kappa und zur Veranschaulichung auf Bubbleplots zurückgegriffen.
Ergebnisse: Das mittlere Alter der deutschen Probanden beträgt 43.66 (21-69), bei den
türkischstämmigen Probanden 39.93 (18-66), und bei den Aussiedlern 44.14 (20-67) Jahre. Die
Mehrheit der Zahnfleischtaschentiefe der deutschen Probanden liegt unter 4 mm. Bei 33.2% der
Deutschen wurden Taschentiefen ≥5mm gemessen. Mit zunehmender Erfahrung der
Studienassistentin konnte eine Verringerung der erforderlichen Zeit für die Erhebung des
Parodontalstatus festgestellt werden. Migranten sind deutlich schwieriger zu einer Studienteilnahme
zu motivieren. Die durchschnittliche Dauer der zahnmedizinischen Untersuchungen ist bei Migranten
signifikant höher.
[1] http://www.nationale-kohorte.de/wissenschaftliches-konzept.html
[2] Development of the World Health Organization (WHO) community periodontal index of
treatment needs (CPITN), Int Dent J. 1982 Sep

7
Klinische Tests zur Diagnostik von Rupturen des hinteren Kreuzbandes – eine systematische
Literaturanalyse
Christian Kopkow, BSc. PT, MPH; E-Mail: [email protected]
Technische Universität Dresden, Institut und Poliklinik für Arbeits- und Sozialmedizin, Direktor: Univ.-
Prof. Dr. Andreas Seidler, MPH
Hintergrund
Rupturen des hinteren Kreuzbandes sind eine ernsthafte Verletzung des Kniegelenks. Die
Durchführung einer gezielten körperlichen Untersuchung ist wesentlicher Bestandteil des
diagnostischen Prozesses. Hinsichtlich der klinischen körperlichen Untersuchung der Integrität des
hinteren Kreuzbandes existiert eine Vielzahl an publizierten Testverfahren mit teilweise unklarer
Validität.
Ziele
Die Zielstellungen der Arbeit lauten: a) welche Testverfahren eignen sich zur Einschlussdiagnostik
hinterer Kreuzbandrupturen, b) welche Testverfahren eignen sich zur Ausschlussdiagnostik hinterer
Kreuzbandrupturen und c) Abbildung des aktuellen Forschungsstandes und Aktualisierung
bestehender Übersichtsarbeiten hinsichtlich körperlicher Tests zur Diagnose hinterer
Kreuzbandrupturen.
Methodik
Es wurde eine systematische Suche in den elektronischen Datenbanken MEDLINE, EMBASE und
AMED durchgeführt. Zusätzlich erfolgte eine Handsuche. Es wurden Studien eingeschlossen, die im
direkten Vergleich einen oder mehrere klinische Indextestverfahren zur Diagnostik einer hinteren
Kreuzbandruptur untersuchten. Als Referenzstandard wurde Arthrotomie, Arthroskopie sowie MRT
definiert. Zwei Reviewer führten unabhängig voneinander jeweils Titel-Abstract-Sichtung,
Volltextsichtung und methodische Bewertung der eingeschlossenen Studien mittels des
QUADASTools durch. Die Darstellung der Ergebnisse erfolgte mittels diagnostischer Vierfeldertafel.
Zudem werden Forest plots, Crosshair plots und ROCellipse plots abgebildet.
Ergebnisse
Es konnten elf Studien eingeschlossen werden, in denen insgesamt elf verschiedene
Indextestverfahren evaluiert wurden. Die methodische Qualität der eingeschlossenen Studien als
auch die ermittelten Angaben zu Sensitivität und Spezifität sind heterogen. Von den insgesamt elf
identifizierten Studien waren neun „cohort type accuracy studies“ und zwei „case-control type
accuracy studies“. Alle Studien untersuchten die Indextestverfahren im Kliniksetting an
Patientenpopulationen mit fast ausschließlich hohen Rupturprävalenzen und an zumeist kleinen
Patientenkollektiven (n < 20). Eine Meta-Analyse konnte aufgrund der geringen Anzahl an
eingeschlossenen Studien nicht durchgeführt werden.
Fazit
Aufgrund der ungenügenden methodischen Qualität und der geringen Anzahl an identifizierten
Studien sowie der heterogenen Datenlage lässt sich kein körperliches Indextestverfahren als
alleiniges klinisches körperliches Testverfahren zur Diagnostik einer HKB-Ruptur empfehlen.

8
Subtypisierung der Depression in Epidemiologischen Studien
Jörgens, S1; Wersching, H1,2; Baune, B3; Arolt, V1; Berger, K2
1 Klinik für Psychiatrie und Psychotherapie, Universitätsklinik Münster, Deutschland
2 Institut für Epidemiologie und Sozialmedizin, Universitätsklinik Münster, Deutschland
3 School of Medicine, Discipline of Psychiatry, University of Adelaide, Australia
Hintergrund: In den letzten Jahren hat sich in Forschung und Praxis die Spezifizierung depressiver
Erkrankungen in verschiedene Depressionssubtypen durchgesetzt. Die Einteilung in einen
melancholischen und atypischen Subtyp spiegelt unterschiedliche, klinische Symptome wider und ist
durch die Beteiligung biologischer Mechanismen untermauert. Probleme bei der Vergleichbarkeit
publizierter Studien bestehen vor allem aufgrund der unterschiedlichen praktischen Auslegung der
Kriterien für die einzelnen Subtypen. Ziel der vorliegenden Analyse ist die Überprüfung der
Notwendigkeit einer standardisierten Klassifikation.
Methodik: Bei der BiDirect-Studie handelt es sich um eine Beobachtungsstudie, welche den
Zusammenhang von Arteriosklerose und Depression untersucht. Im Zeitraum vom 02/2010- 09/2011
wurden im Rahmen dieser Studie 399 stationäre Patienten mit einer Depression rekrutiert und mit
MINI 5.0, Hamilton-Interview sowie 6 IDS_C Items untersucht. Für diese Population wurde eine
Einteilung in die Depressionssubtypen anhand verschiedener Kriterien vorgenommen.
Ergebnisse: Unter Verwendung der verschiedenen Klassifikations-Kriterien kommt es zu
Unterschieden in der Populationszusammensetzung bezüglich der einzelnen Depressions-Subtypen,
so liegt z.B. der Anteil atypisch depressiver Patienten liegt zwischen 6,09 und 10,5%.
Schlussfolgerung:
Aufgrund der heterogenen Ergebnisse bezüglich der Populationszusammensetzung in Abhängigkeit
des gewählten Kriteriums erscheint eine Vereinheitlichung der Klassifikation in epidemiologischen
Studien nötig, um eine Verzerrung der Auftretenshäufigkeit verschiedener Depressionsformen zu
vermeiden. Ein Vorschlag wird diskutiert.
Literatur: Seemüller et al. Atypical symptoms in hospitalised patients with major depressive
episode: frequency, clinical characteristics, and internal validity. J Affect Disord. 2008
Jun;108(3):271-8.

9
PURE und UroScreen als Beispiele von Biomarkerstudien
Nadine Bonberg
Institut für Prävention und Arbeitsmedizin der Deutschen Gesetzlichen Unfallversicherung, Institut der Ruhr-
Universität Bochum (IPA)
Protein Research Unit Ruhr within Europe (PURE), Ruhr-Universität Bochum
Im Rahmen des geplanten Workshops soll die Blasenkrebsstudie im Rahmen von PURE als eine Studie
zur Identifizierung von Biomarkern und UroScreen als eine Studie zur Validierung von Biomarkern
vorgestellt werden.
Im Jahr 2010 wurde das Proteinforschungsinstitut PURE an der Ruhr-Universität Bochum gegründet.
Ziel innerhalb von PURE ist es Biomarker zu identifizieren, die in frühen, noch symptomlosen
Krankheitsstadien eine Erkrankung erkennen können. Weiterhin sollen Marker getestet werden, die
zum Monitoring von Therapieverläufen oder zur Prädiktion von Therapieerfolgen eingesetzt werden
können. Eine Studie in PURE befasst sich zurzeit mit der Identifizierung von Biomarkern für
Harnblasenkrebs. UroScreen ist eine Längsschnittstudie zur Früherkennung von Harnblasenkrebs, an
der 1.609 aktive oder berentete Chemiearbeiter teilgenommen haben. In dieser Studie wurden die
Tumormarker NMP22 und UroVysion™ validiert, zu denen konkrete Ergebnisse vorgestellt werden
sollen.

10
Validierung des German-Diabetes-Risk-Scores innerhalb einer bevölkerungsbezogenen, repräsentativen Kohorte
Hartwig S1, Kuss O
1, Tiller D
1, Greiser KH
2, Schulze MB
3, Dierkes J
4, Werdan K
5, Haerting J
1, Kluttig A
1
1 Institut für Medizinische Epidemiologie, Biometrie und Informatik, Martin-Luther-Universität Halle-Wittenberg, Halle (Saale)
2 Abteilung Epidemiologie von Krebserkrankungen, Deutsches Krebsforschungszentrum, Heidelberg
3 Abteilung Molekulare Epidemiologie, Deutsches Institut für Ernährungsforschung Potsdam-Rehbrücke, Nuthetal
4 Institut für Medizin, Universität Bergen
5 Klinik für Innere Medizin III, Martin-Luther-Universität Halle-Wittenberg, Halle (Saale)
Hintergrund:
2007 entwickelten Schulze et al. im Rahmen der EPIC-Potsdam-Studie den Deutschen-Diabetes-Risiko-Score
(DRS) zur Abschätzung des individuellen 5-Jahres-Diabetes-Risikos [1, 2]. Ziel der vorliegenden Arbeit war die
Validierung dieses Scores innerhalb der bevölkerungsrepräsentativen CARLA-Studie [3].
Studiendesign/Methoden:
Die Studienpopulation setzte sich aus 690 Frauen und 805 Männern im Alter von 45-83 Jahren zusammen,
welche zur Basisuntersuchung frei von Diabetes waren.
Für jeden Probanden wurde das individuelle Risiko mithilfe des für eine vier-Jahres-Follow-Up-Zeit
modifizierten DRS bestimmt. Zur Validierung des Scores wurden die geschätzte und die beobachtete Diabetes-
Inzidenz in sechs Gruppen verglichen und ROC-Analysen (Receiver-Operator-Characteristic) durchgeführt.
Weiterhin wurde die Veränderung der Vorhersagekraft des Scores durch Erweiterung um metabolische
Parameter und durch verschiedene Subgruppenanalysen überprüft.
Ergebnisse:
Während der Nachbeobachtungszeit ergab sich bei 58 Probanden eine neu diagnostizierte Diabetes-
Erkrankung. Die mediane 4-Jahres-Erkrankungswahrscheinlichkeit lag bei 6,5%.
Mit steigendem DRS-Wert zeigte sich eine höhere beobachtete Inzidenz. Die Wahrscheinlichkeiten an Diabetes
zu erkranken waren zwischen Berechnung und Beobachtung vergleichbar. Aufgrund geringer Fallzahlen,
besonders in den Gruppen mit niedrigem Risiko ergaben sich jedoch teilweise unpräzise Schätzungen. Die
Fläche unter der ROC-Kurve (ROC-AUC) betrug 0,70 (95%CI: 0.64-0.77).
Die Validität des Scores verbesserte sich durch Hinzunahme des Blutglukosewertes (AUC: 0.81; 95%CI: 0.76-
0.86) und des HbA1c-Wertes (AUC: 0.84; 95%CI: 0.80-0.91) sowie durch Ausschluss von Probanden ≥65 Jahre
(AUC: 0.77; 95%CI: 0.70-0.84).
Schlussfolgerungen:
Zusammenfassend zeigte der DRS in CARLA gegenüber EPIC-Potsdam deutlich schwächere Ergebnisse, was
teilweise durch Kohortenunterschiede erklärt werden kann. Dennoch kann ein hoher Scorewert einen Hinweis
auf ein gesteigertes Diabetesrisiko geben.
Reference List
[1] Schulze MB, Hoffmann K, Boeing H, Linseisen J, Rohrmann S, Mohlig M, et al. An accurate risk score
based on anthropometric, dietary, and lifestyle factors to predict the development of type 2 diabetes.
Diabetes Care 2007 Mar;30(3):510-5.
[2] Schulze MB, Weikert C, Pischon T, Bergmann MM, Al Hasani H, Schleicher E, et al. Use of multiple
metabolic and genetic markers to improve the prediction of type 2 diabetes: the EPIC-Potsdam Study.
Diabetes Care 2009 Nov;32(11):2116-9.
[3] Greiser KH, Kluttig A, Schumann B, Kors JA, Swenne CA, Kuss O, et al. Cardiovascular disease, risk factors
and heart rate variability in the elderly general population: design and objectives of the CARdiovascular
disease, Living and Ageing in Halle (CARLA) Study. BMC Cardiovasc Disord 2005;5:33.

11
Title: Sensitivity estimates of blood based tests for colorectal cancer detection: Impact of over-
representation of advanced stage disease
Authors: Sha Tao, Sabrina Hundt, Ulrike Haug, Hermann Brenner
Institute: Division of Clinical Epidemiology and Aging Research (C070), German Cancer Research
Center, Im Neuenheimer Feld 581, D-69120 Heidelberg, Germany
Email: [email protected]
Abstract
A large number of blood-based markers have been proposed for early detection of colorectal cancer
(CRC). Their sensitivity for detecting CRC has mostly been evaluated in clinical settings, and found to
be higher in more advanced stages compared with earlier stages of the disease. The aim of this study
is to estimate the overall sensitivity of blood-based markers expected in screening settings, where
the proportion of advanced stages is typically lower than in clinical settings. A systematic literature
review was performed on studies evaluating sensitivity and specificity of blood-based markers for
early detection of CRC. For each study, overall sensitivity expected in screening settings was
estimated by weighting stage-specific sensitivities according to the stage distribution of CRC
expected in the screening setting. The latter was derived from 12,605 CRC cases diagnosed in the
German screening colonoscopy program during 2003 – 2007. Overall, 73 studies evaluating 55 blood-
based markers were identified. Adjusted sensitivity was lower than reported sensitivity in 120 (90 %)
evaluations of different markers. Median absolute reduction in sensitivity after adjustment was 9.0 %
(interquartile range: 4.0 – 13.0) units, whereas median relative reduction was 19.5 % (interquartile
range: 11.3 – 33.3 %). Blood-based markers for CRC detection reported from clinical settings showed
higher sensitivities than expected in the screening setting in most cases, mainly due to substantially
higher proportions of advanced stage cancers. Adjustment of sensitivity to the stage distribution
expected in the screening setting is crucial to obtain realistic and comparable estimates of
sensitivities.

12
A statistical approach for shedding light on routes of transmission of infectious diseases
Steffen Unkel¹ ², C. Paddy Farrington², Heather J. Whitaker² and Richard Pebody³
¹Medical Statistics Group, Institute of Medical Informatics, Faculty of Medicine,
Justus Liebig University Giessen, Germany.
²Department of Mathematics and Statistics,
The Open University, Milton Keynes, United Kingdom.
³Health Protection Agency, London, United Kingdom.
e-mail: [email protected]
Recently, new statistical methods were proposed for investigating and quantifying
heterogeneities relevant to the transmission of infectious diseases, based on
associations within individuals between ages at infection for different infections (Unkel
et al. , 2012). Central to this methodological framework is the use of serological survey
data, which provide readily sources of individual data on several infections. It was found
that infections are often highly correlated within individuals in early childhood, the
associations persisting into adulthood only for infections sharing a transmission route.
Whereas childhood association is likely to stem from confounding of different transmission routes, associations in adulthood seem to be route-specific. An application
of this methodology is discussed for making inferences about routes of transmission
when these are unknown or uncertain. An example of such an application is presented,
to elucidating the transmission route of human polyomaviruses BKV and JCV (Farrington
et al., 2013).
References S. Unkel, C. P. Farrington, H. J. Whitaker, R. Pebody (2012): Time-varying frailty
models and the estimation of heterogeneities in transmission of infectious diseases.
Journal of the Royal Statistical Society Series C, under revision.
C. P. Farrington, H. J. Whitaker, S. Unkel, R. Pebody (2013): Correlated infections:
quantifying individual heterogeneity in the spread of infectious diseases. American
Journal of Epidemiology, Vol. 177, in press.

13
Spatial Clusters of the amyotrophic lateral scleros is (ALS):
Results of the population based ALS registry Swabia
H. Uenal¹, A. Rosenbohm², G. Berry¹, J. Kufeld¹, A. Ludolph², D. Rothenbacher¹, G. Nagel¹
¹ Institut für Epidemiologie und Medizinischen Biometrie, Universität Ulm, Ulm ² Neurologische Universitätsklinik Ulm, Ulm
Background The amyotrophic lateral sclerosis (ALS) is a rare, neurodegenerative disease, which leads to rapid progressive muscular paralysis. Relevant etiological risk factors are hence thereby barely known. The main objective of this paper is to visualize geographical cluster in Swabia and to investigate the regions with significant formation of clusters having ALS to investigate for possible risk factors and also environmental factors that may be lead to ALS (p.e. population density). Methods Since October 2008, all ALS-patients are recorded in this ALS registry in Swabian region of South Germany (ALS - registry Swabia). Retrospective cases were distinguished between 1 October 2008 and 30 September 2010 in our target population in Southern Germany. Population numbers were determined at county level and small spatial, standardized incidence rates (indirect method) were estimated using the Poisson distribution for the counties in 16 age classes. Exact age-standardized incidence rates (EU population 2010) is compared with expected age-and –population standardized incidence rates (new EU standard population 1990) to compare the influence of the different European standard population weights and to investigate .possible spatial clusters in ALS using Kulldorff-statistics. The completeness of the registry is estimated using capture recapture methods. Results In our study region of about 8.6 million inhabitants, 426 ALS cases (53% men, 47% women) were identified. The mean age of retrospective ALS cases was 64.9 (SD = 12.0) years, 63.7 (11.9) for men and 66.2 (12.1) for men. The 35% high proportion of female patients aged 75 years or older suggests and supports a high quality of our registry. The absolute number of new cases varied in the counties between 0-32 cases. The exact European age-standardized incidence rate of ALS was 2.4 per 100,000 population per year (95% confidence interval (CI): 2.11-2.56). Due to the nature of the disease only small numbers of cases, spatial incidence rates and 95% confidence intervals are estimated with the help of Poisson-distribution at county level. The cartographical representation of the crude and standardized incidence rates exhibit a significant variability between the counties in the region of Swabia. Applying spatial scan statistics, there were primary clusters in county Göppingen and county Bodenseekreis (p-value = 0.24 and p-value = 0.57) with observed ALS cases. An illustration using capture recapture method estimated missing cases (N= 108) in the study region were imputed as a scenario. Using the capture recapture estimated total number of cases (N=524), using the exact European age-standardized incidence rate of ALS was 2.9 per 100,000 personyears. Conclusion The age-standardized incidence rate in the region of Swabia is consistent with incidence rates from other European countries. A cluster analysis enables us to investigate geographic clusters of ALS and helps us to compare the 42 different counties.

14
Evaluation von Verbesserungen bei Risikoprädiktionsmodellen mit dem Net Reclassification Improvement
Kristin Mühlenbruch¹ ([email protected])
Alexandros Heraclides¹, Ewout W. Steyerberg², Olga Kuxhaus¹, Hannelore Liero³, Hans-Georg Joost⁴, Heiner
Boeing⁵, Matthias B. Schulze¹
¹ Abteilung Molekulare Epidemiologie, Deutsches Institut für Ernährungsforschung Potsdam-Rehbrücke,
Nuthetal, ² Department of Public Health, Erasmus MC, Rotterdam, Niederlande; ³ Institut für Mathematik,
Universität Potsdam, ⁴ Abteilung Pharmakologie, Deutsches Institut für Ernährungsforschung Potsdam-
Rehbrücke, Nuthetal, und ⁵ Abteilung Epidemiologie, Deutsches Institut für Ernährungsforschung Potsdam-
Rehbrücke, Nuthetal
Hintergrund: Der Net Reclassification Improvement (NRI) wird seit seiner Entwicklung [1] in zahlreichen
Studien verwendet [2], um den prädiktiven Wert neuer Risikomarker in Risikoprädiktionsmodellen zu
beurteilen. Als Reklassifizierungsstatistik basiert die Berechnung des NRI auf Risikokategorien. Allerdings gibt es
bislang keine einheitliche Verwendung bezüglich der Anzahl an Risikokategoiren, der Cut-offs, sowie für die
Beurteilung des Umfangs der Verbesserung anhand des NRI-Wertes oder seiner statistischen Signifikanz. Wir
untersuchten nun, inwiefern der Wert des NRI sowie seiner Einzelkomponenten (NRIFälle und NRINicht-Fälle) von
der Wahl dieser Risikokategorien (Anzahl und Cut-off-Werte) abhängt. Zusätzlich haben wir unterschiedliche
Gewichtungen für die Einzelkomponenten und deren statistische Signifikanz näher betrachtet.
Methoden: Die European Prospective Investigation into Cancer and Nutrition (EPIC) – Potsdam-Studie, eine
prospektive Kohortenstudie, umfasst 25167 Teilnehmer zur Basiserhebung. In einem mittleren Follow-up-
Zeitraum von 7 Jahren wurden 849 inzidente Typ-2-Diabetes-Fälle beobachtet. Basierend auf dem Deutschen
Diabetes-Risiko-Test® (DRT) [3] wurden in der ersten Analyse 3 (verkürzte) Modelle verwendet und hinsichtlich
Fläche unter der ROC-Kurve (ROC-AUC) und NRI verglichen. Für die Berechnung des NRI wurden variierende
Cut-off-Werte für zwei und drei Risikokategorien, sowie eine variierende Anzahl an Risikokategorien (2 bis 50)
verwendet. Für die weitere Analyse wurde der DRT mit einem um Familienanamnese erweiterten Modell
hinsichtlich ROC-AUC und NRI verglichen. Für die Betrachtung des NRI wurden 2 bis 10 Risikokategorien mit
Gewichtungen von 0,1 bis 0,9 für die Einzelkomponenten verwendet und deren p-Werte berechnet. Für
variierende Cut-off-Werte für 2 Risikokategorien wurde anstelle eines p-Wertes ein 95%- Konfidenzintervall der
Einzelkomponenten zur Beurteilung des NRI-Wertes berechnet.
Ergebnisse: Ein erster Modellvergleich von nicht-modifizierbaren Risikofaktoren mit zusätzlich Taillenumfang
ergab eine Verbesserung der Diskriminierung um 0,11 sowie Risikoklassifizierung in fünf Risikokategorien um
54.7%. Der zweite Modellvergleich von nicht-modifizierbaren Risikofaktoren und Taillenumfang mit zusätzlich
modifizierbaren Lebensstilfaktoren ergab eine Verbesserung in der ROC-AUC um 0,01 und einen NRI von 3.49%.
Für beide Modellvergleiche zeigten die Ergebnisse zusätzlich, dass der NRI mit steigender Anzahl an
Risikokategorien steigt und gegen den stetigen NRI konvergiert. Die variierenden Cut-off-Werte resultierten in
einer starken Variabilität des NRI für 2 und 3 Kategorien, insbesondere bei einer größeren Modellverbesserung.
Für den dritten Modellvergleich ergab sich eine Verbesserung der Diskriminierung um 0,007 und der NRI betrug
9,98%. Die unterschiedliche Gewichtung der Einzelkomponenten zeigte Einfluss auf den Wert sowie auf die
Signifikanz des NRI. Außerdem zeigen die Einzelkomponenten gegenläufige Trends nach Wahl der Cut-off-
Werte für 2 Risikokategorien.
Schlussfolgerung: Die Wahl der Risikokategorien und insbesondere der Cut-off-Werte für diese Kategorien
zeigen deutlichen Einfluss auf den Wert des NRI. Dieser Einfluss scheint besonders ausgeprägt, wenn die
Verbesserung der Prädiktion groß ist. Eine begrenzte Anzahl an Risikokategorien sollte nur verwendet werden,
wenn diese klinische Relevanz haben. Außerdem ist eine detaillierte Betrachtung des NRI und seiner
Komponenten sowie mögliche Gewichtungen und bevorzugt die Berechnung eines Konfidenzintervalls zu
empfehlen.
Literatur: [1] Pencina, M.J., et al., Evaluating the added predictive ability of a new marker: from area under the ROC curve
to reclassification and beyond. Stat Med, 2008. 27(2): p. 157-72; discussion 207-12.
[2] Tzoulaki I, Liberopoulos G, Ioannidis JP. Use of reclassification for assessment of improved prediction: an
empirical evaluation. Int J Epidemiol 2011;40(4):1094-105.
[3] Schulze, M.B., et al., An accurate risk score based on anthropometric, dietary, and lifestyle factors to predict
the development of type 2 diabetes. Diabetes Care, 2007. 30(3): p. 510-5.

15
Michael Schneider, Valentina Lesnjak, Daniela Wenzel, Christine Falk und Cornelia Blume
Medizinische Hochschule Hannover, Carl Neuberg Str. 1, 30625 Hannover
Angewendete Methoden zur systematischen Untersuchun g der diagnostischen Wertigkeit von multiplen diagnostischen Tests
In der Transplantationsmedizin sind das Verständnis und die Erforschung immunologischer Grundlagen von besonderer Bedeutung. So werden an der Medizinischen Hochschule Hannover seit mehr als 10 Jahren im Rahmen des Nierenbiopsieprogramms der Klinik für Nephrologie (Prof. Dr. H. Haller) ambulant Protokoll- und Indikationsbiopsien durchgeführt und seit 05/2011 diese nebst Plasmaproben im Rahmen eines durch Ethikantrag unterstützen IFB-Projekts (SU02) zur Analyse von Biomarkern verwendet. Hierbei wurden in Plasmaproben von 120 Patienten die Konzentrationen von mehr als 50 Zytokinen, Chemokinen und Wachtumsfaktoren bestimmt. Auf deren Basis sollen statistische Analysen unter Einbeziehung des pathologischen Befundes aufgebaut werden.
Die diagnostische Wertigkeit der registrierten Biomarker soll nun hinsichtlich der Diagnose und Differentialdiagnose von Abstoßungsreaktionen untersucht werden. Hierdurch erhoffen wir uns neue Erkenntnisse in der Diagnostik wie auch in der prognostischen Früherkennung von Abstoßungsreaktionen nach Nierentransplantation. Primäres Ziel der statistischen Auswertung ist zunächst die systematische Untersuchung der diagnostischen Wertigkeit der vorgestellten Biomarkern, sowohl vollständig als Einzelwerte, wie auch als ausgewählte Testkombinationen. Hierfür werden primär robuste statistische Verfahren eingesetzt. Darüber hinaus sollen spezielle Testmodelle untersucht werden, die sich aus klinischen wie auch biowissenschaftlichen Fragestellungen ergeben. Bedeutsame Ergebnisse sollen in folgenden prospektiven Studien evaluiert werden. Die eingesetzten Auswertungsmethoden sollen auch auf andere, bisher nicht untersuchte Marker übertragen werden.
In diesem Vortrag stellen wir die Methoden und die relevanten Ergebnisse unserer Auswertungen vor.

16
Difference of two Dependent Sensitivities and Specificities: Comparison of Various Approaches
Daniela Wenzel1, Antonia Zapf2
1Department for Biostatistics, Medical School Hannover
2Department of Medical Statistics, University Medical Center Goettingen
In diagnostic studies a new diagnostic test is often compared with a standard test in a within-subject
design. Furthermore in phase III studies (in place validation of a diagnostic test) primary endpoints
are usually sensitivity and specificity as recommended in the according EMA guideline for diagnostic
agents. For the estimation of the difference between two dependent tests confidence intervals for
the difference of two dependent rates (i.e. sensitivities or specificities) can be used. There are many
feasible intervals, but no clear recommendation which one to apply in this case. Newcombe
compared in 1998 ten approaches for the whole parameter space and gave summarized results. But
it is well known that the goodness of the intervals depends especially on whether the rate is close to
the limits or not. For this reason we will investigate a reduced parameter space, as it is relevant for
diagnostic studies (for example sensitivity and specificity greater or equal than 0.8), and present the
results for individual scenarios. Furthermore we add some recent approaches (Agresti and Tango
confidence intervals, non-parametric methods based on relative effects and "free marginal GEE`s").
With simulation studies (type one error, interval length, MSE and power) we figured out that the
Wald interval, the non-parametric intervals and the Tango interval can be recommended for the
calculation of a confidence interval for the difference of two sensitivities or specificities in diagnostic
trials in a paired design.
References:
1. Newcombe, R.G. “Improved confidence intervals for the difference between binomial
proportions based on paired data”, Statistics in Medicine 17, 2635-50 (1998).
2. Brunner E. and Munzel U. “The nonparametric Behrens-Fisher problem – asymptotic theory
and small sample approximation”, Biometrical Journal, 42, 17-25 (2000).
3. Leisenring W. et al. “A marginal regression modeling framework for evaluating medical
diagnostic tests”, Statistics in Medicine, 16, 1263-1281 (1997).
4. Dickel H. et al. “Increased sensitivity of patch testing by standardized tape stripping
beforehand: a multicenter diagnostic accuracy study”, Contract Dermatitis, 62, 294-302
(2010).

17
Analyse verschiedener diagnostischer Gütemaße in faktoriellen Versuchsanlagen Katharina Lange1 Edgar Brunner Abt. Medizinische Statistik, Universitätsmedizin Göttingen, Humboldallee 32, 37073 Göttingen,
Diagnostische Studien gewinnen im Bereich der klinischen Forschung zunehmend an Bedeutung, sodass die Entwicklung neuer statistischer Verfahren zur Evaluation dieser Studien ein wichtiges Themengebiet der biostatistischen Methodenforschung bildet. Da die Ausgangslage bei Studien dieses Typs äußerst heterogen sein kann, stellt die Entwicklung umfassender statistischer Verfahren ein komplexes Problem dar: Bei Diagnosestudien existiert zum einen eine Vielzahl an Möglichkeiten zur Definition der diagnostischen Güte wie beispielweise Sensitivität und Spezifität, prädiktive Werte, Likelihood-Ratios oder auch die Fläche unter der ROC-Kurve. Zum anderen können hier vielfältige Versuchsdesigns und Datenstrukturen (faktorielle Versuchsanlagen mit verbundenen und unverbundenen Stichproben) auftreten. In diesem Vortrag soll ein nichtparametrischer Analyseansatz vorgestellt werden, welcher es gestattet, verschiedene diagnostische Gütemaße mit einer einheitlichen Methodik zu analysieren. Die Grundlage dieses Ansatzes bildet dabei eine Analysemethodik für die Fläche unter der ROC-Kurve, die sich zu einem Auswertungsverfahren von Sensitivität und Spezifität erweitern lässt, sodass selbst bei unterschiedlichsten diagnostischen Studien eine einheitliche Handhabung in der Evaluation möglich wird. Die hier dargestellten Ansätze lassen sich dabei insbesondere auf eine Vielzahl an faktoriellen Versuchsanlagen anwenden, sodass die präsentierte Methodik ein äußerst hilfreiches Werkzeug für die Analyse vieler diagnostischer Studien bildet. Literatur [1] Kaufmann J, Werner C, Brunner E (2005). Nonparametric Methods for Analysing the Accuracy of Diagnostic Tests with Multiple Readers. Statistical Methods in Medical Research 14:129–146 [2] Lange K, Brunner E (2012). Sensitivity, specificity and ROC-curves in multiple reader diagnostic trials — A unified, nonparametric approach. Statistical Methodology 9: 490–500. [3] Lange K . (2008). Nichtparametrische Modelle für faktorielle Diagnosestudien, Georg-August- Universität Göttingen, Diplomarbeit [4] Lange K . (2011). Nichtparametrische Analyse diagnostischer Gütemaße bei Clusterdaten, Georg-August-Universität Göttingen, Dissertation

18
Titel: Zusammenfassung diagnostischer Studien – ein Vorschlag zur Vorgehensweise
Autoren: Wiebke Sieben, Lars Beckmann, Ralf Bender
Institution: Institut für Qualität und Wirtschaftlichkeit im Gesundheitswesen (IQWiG)
E-Mail: [email protected]
Abstract: Dem Anwender stehen für die meta-analytische Zusammenfassung der
diagnostischen Güte aus mehreren Studien seit einiger Zeit Ansätze für eine bivariate Betrachtung
zur Auswahl, bei denen die korrelierten Zielgrößen Sensitivität und Spezifität gemeinsam in
gemischten Modellen modelliert werden. Dabei ist oft nicht der gepoolte Schätzer einer Technologie
sondern vielmehr der Vergleich zweier Technologien von Interesse. Um eine zusätzliche Quelle für
Heterogenität zu vermeiden ist ein möglicher Ansatz, sich bei bivariaten Meta-Analysen auf
vergleichende Studien zu beschränken, innerhalb derer jeweils mindestens zwei diagnostische Verfahren verwendet und ausgewertet wurden.
Dabei hat sich als besondere Schwierigkeit herausgestellt, dass meist nur wenige vergleichende
Studien zu einer Fragestellung vorliegen. Aufgrund durchgeführter Simulationen ist davon
auszugehen, dass selbst bei vollständig erfüllten Modellannahmen die
Überdeckungswahrscheinlichkeit der Konfidenzregionen für die Sensitivitäts- und Spezifitäts-
Schätzerpaare für jeden Test stark unter dem vorgegebenen Niveau liegt, wenn nur wenige Studien
in die Analyse eingehen. In diesem Vortrag präsentieren wir die Wahl des Modellierungsansatzes, die
Umsetzung in SAS und schlagen ein Vorgehen für die Darstellung und Interpretation in Abhängigkeit
von der Anzahl der Studien und des Verzerrungspotenzials vor.

19
Modelling of ROC curves in meta-analysis of diagnostic test accuracy studies
Gerta Rücker Institute of Medical Biometry and Medical Informatics University Medical Center Freiburg E-mail: [email protected] For meta-analyses of diagnostic test accuracy studies, statistical models such as the bivariate model and the hierarchical model have been developed for analysis. Open questions refer to identifying and interpreting summary ROC curves when there is only one pair of sensitivity and specificity reported per study. The objective of this DFG project is to refine our existing method of analysis that models selection of the reported pair of sensitivity and specificity at the study level. To this aim, three levels are modelled: (i) the individual level, (ii) the study level, and (iii) the meta-analysis level. It is assumed that study investigators have considered the whole empirical ROC curve and selected the cut-off of the biomarker that maximised an appropriately weighted Youden index. Decision making based on the whole study data (second level) then leads to a dependence between otherwise unrelated individuals, as soon as the individual test diagnosis depends on the chosen cut-off and this in turn depends on the observations made in all other individuals within the same study. Under certain assumptions, the model allows to obtain a summary ROC curve by estimating study-specific ROC curves for the studies in the meta-analysis. As the model accounts for selection, it avoids overestimation of diagnostic accuracy. By establishing a suitable parametrisation for all levels, including covariates, we aim to obtain an overall likelihood for this Youden index-based cut-off selection model. Reference: Rücker G, Schumacher M. Summary ROC curve based on the weighted Youden index for selecting an optimal cutpoint in meta-analysis of diagnostic accuracy. Statistics in Medicine. 2010;29:3069–3078.

20
Statistical Methods for Meta-Analysis of Diagnostic Tests accounting for Prevalence – A new Model using trivariate Copulas
Annika Hoyer¹, Oliver Kuss²
¹Institut für Statistik, Ludwig-Maximilians-Universität München, [email protected] ²Institut für Medizinische Epidemiologie, Biometrie und Informatik, Medizinische Fakultät, Martin-Luther-Universität Halle-Wittenberg, Halle (Saale) In real life and somewhat contrary to biostatistical textbook knowledge, sensitivity and specificity (and not only predictive values) of diagnostic tests can vary with the underlying prevalence of disease and Leeflang et al. [1] give empirical examples and plausible mechanisms causing this phenomenon. In meta-analyses of diagnostic studies, accounting for this fact naturally leads to a trivariate expansion of the standard bivariate GLMM [2]. We propose a new model to this task using trivariate copulas and beta-binomial marginal distributions for sensitivity, specificity and prevalence. This model has a closed-form likelihood, so standard software (e.g., SAS PROC NLMIXED) can be used. For both the standard and the copula model, some complexity is introduced by the design of the respective diagnostic trial where casecontrol designs with prevalences fixed by the researcher do not allow the estimation of prevalences, whereas cohort designs do. We illustrate the methods by the example of Scheidler et al. [3] on radiological evaluation of lymph node metastases in patients with cervical cancer. [1] Leeflang MMG, Bossuyt PMM, Irwig L. Diagnostic test accuracy may vary with prevalence: implications for evidence-based diagnosis. Journal of Clinical Epidemiology 2009;62:5-12. [2] Chu H, Nie L, Cole SR, Poole C. Meta-analysis of diagnostic accuracy studies accounting for disease prevalence: Alternative parameterizations and model selection. Statist Med 2009;28:2384-2399. [3] Scheidler J, et al. Radiological evaluation of lymph node metastases in patients with cervical cancer. A meta-analysis. JAMA. 1997;278(13):1096-1101.

21
Meta-analysis for the comparison of two diagnostic tests to a common gold standard: First experiences with quadrivariate stat istical models
Oliver Kuss¹, Annika Hoyer²
¹Institut für Medizinische Epidemiologie, Biometrie und Informatik, Medizinische Fakultät, Martin-Luther-Universität Halle-Wittenberg, Halle (Saale), [email protected] ²Institut für Statistik, Ludwig-Maximilians-Universität München Meta-analysis of diagnostic studies is still a rapidly developing area of biostatistical research. Only recently, methods for the meta-analytic comparison of two diagnostic tests to a common gold standard have been called for by applied researchers and proposed [1,2], an older method is also available [3]. In these meta-analyses the parameters of interest are the differences of sensitivities and specificities (with their corresponding confidence intervals) between the two diagnostic tests while accounting for the various associations within single studies, between the two tests and within patients. In line with [1] we propose statistical models with a quadrivariate response (where sensitivity of test 1, specificity of test 1, sensitivity of test 2, and specificity of test 2 are the four responses) as a sensible approach to this task. Using a quadrivariate Generalized linear mixed model (GLMM) naturally generalizes the common standard model of meta-analysis for a single diagnostic test. Quadrivariate copula models [4] are also possible. In the talk we report on first experiences with the respective models using an example data set to compare two drugs in pharmacological stress echocardiography for the diagnosis of coronary artery disease [5]. [1] No authors given. Evaluating Practices and Developing Tools for Comparative Effectiveness Reviews of Diagnostic Test Accuracy. Task 3: Methods for the Joint Meta-Analysis of Multiple Tests. Draft Methods Report. Agency for Healthcare Research and Quality U.S. Department of Health and Human Services. http://www.effectivehealthcare.ahrq.gov/ehc/products/291/1120/DiagnosticTest Methods_DraftReport_20120531.pdf, accessed 09/13/2012 [2] Beckmann L, Sieben W, Bender R. Anwendung von Hotelling’s T2-Statistik zum Vergleich von zwei diagnostischen Tests in Meta-Analysen. Vortrag, 58. Biometrisches Kolloquium, March 2012, Berlin. [3] Siadaty MS, Philbrick JT, Heim SW, Schectman JM. Repeated-measures modeling improved comparison of diagnostic tests in meta-analysis of dependent studies. J Clin Epidemiol. 2004 Jul;57(7):698-711. [4] Kuss O, Hoyer A, Solms A. Meta-analysis for diagnostic accuracy studies: A new statistical model using beta-binomial distributions and bivariate copulas. (under review) [5] Picano E, Bedetti G, Varga A, Cseh E. The comparable diagnostic accuracies of dobutamine-stress and dipyridamole-stress echocardiographies: A metaanalysis. Coron Artery Dis. 2000 Mar,11(2):151-9