hbase interact with shell
TRANSCRIPT


LIST
List all tables in HBase
Syntax :
Htase :> list

CREATE
Create table;
Pass table name
Syntax :
Hbase :> creat ‘tablename’,’colFamily’

MORE EXAPLES
hbase> create 'tableToBeCreated', {NAME => 'colFammily1', VERSIONS => 5}
hbase> create 'tableToBeCreated', {NAME => 'colFammily1'}, {NAME => 'colFammily2'}, {NAME => 'f3'}
hbase> # The above in shorthand would be the following:
hbase> create 'tableToBeCreated', 'colFammily1', 'colFammily2', 'f3'
hbase> create 'tableToBeCreated', {NAME => 'colFammily1', VERSIONS => 1, TTL => 2592000, BLOCKCACHE => true

DESCRIBE
Describe the named table:
e.g.
hbase> describe 'table1'
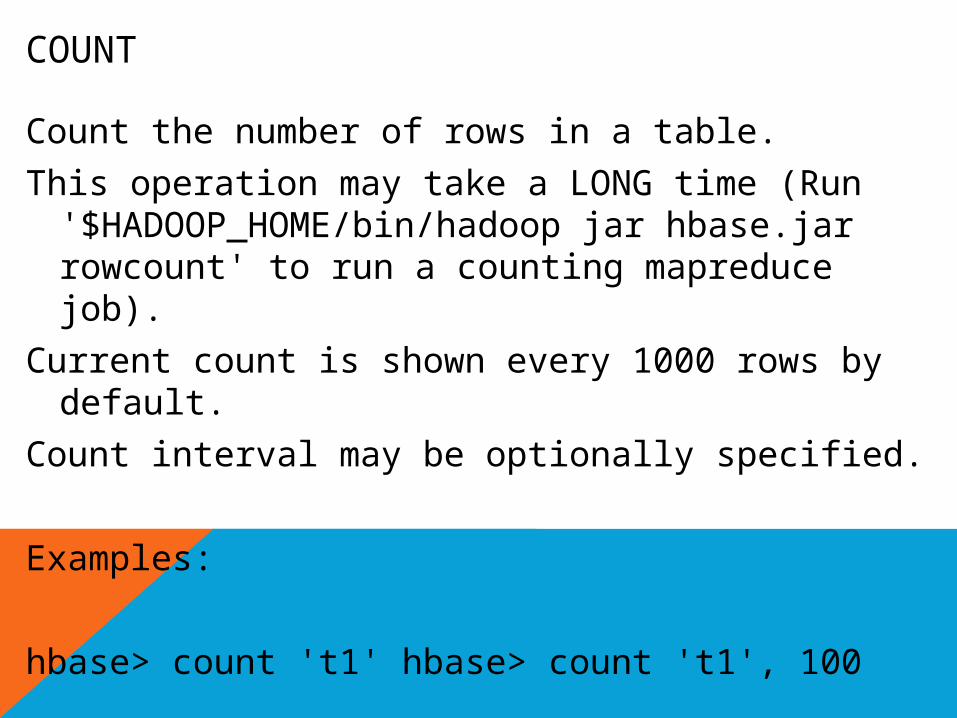
COUNT
Count the number of rows in a table.
This operation may take a LONG time (Run '$HADOOP_HOME/bin/hadoop jar hbase.jar rowcount' to run a counting mapreduce job).
Current count is shown every 1000 rows by default.
Count interval may be optionally specified.
Examples:
hbase> count 't1' hbase> count 't1', 100

DELETE
Put a delete cell value at specified table/row/column and optionally timestamp coordinates.
Eg:
Delete ‘table’,’colfam:columnname’

DELETEALL
Delete all cells in a given row; pass a table name, row, and optionally a column and timestamp
Delete ‘table’,’rowkey’

DISABLE
Disable the named table: e.g.
"hbase> disable 't1'"

DROP
Drop the named table. Table must first be disabled.
Eg:
Drop ‘tablename’

ENABLE
Enable the named table
Eg:
Enable ‘tablename’

EXISTS
Does the named table exist? e.g.
"hbase> exists 't1'"
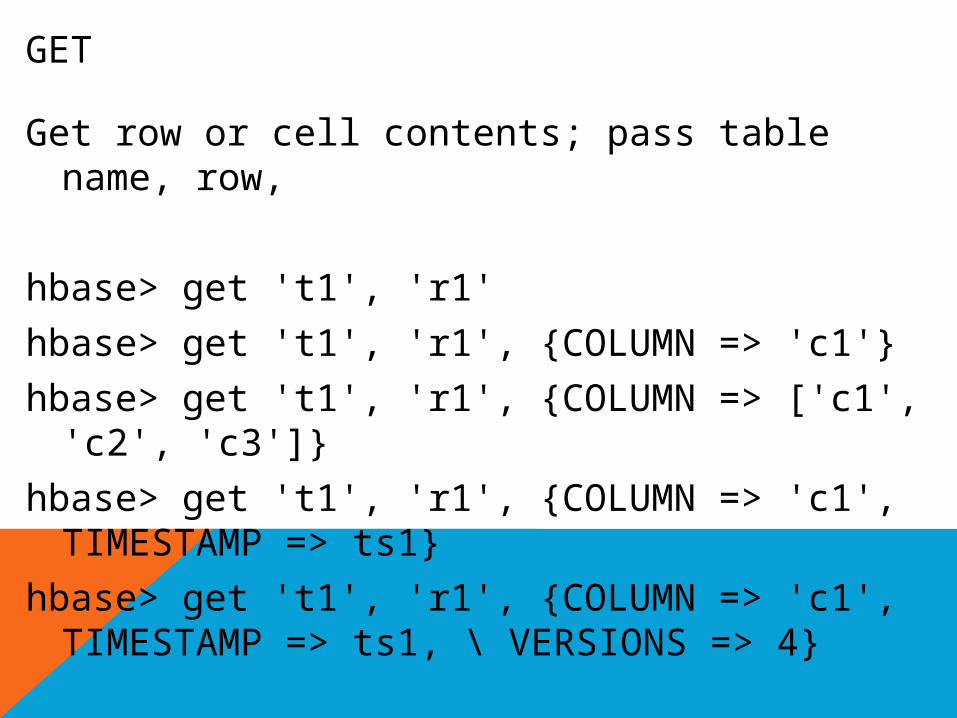
GET
Get row or cell contents; pass table name, row,
hbase> get 't1', 'r1'
hbase> get 't1', 'r1', {COLUMN => 'c1'}
hbase> get 't1', 'r1', {COLUMN => ['c1', 'c2', 'c3']}
hbase> get 't1', 'r1', {COLUMN => 'c1', TIMESTAMP => ts1}
hbase> get 't1', 'r1', {COLUMN => 'c1', TIMESTAMP => ts1, \ VERSIONS => 4}

PUT
Put a cell 'value' at specified table/row/column and optionally timestamp coordinates.
To put a cell value into table 't1' at row 'r1' under column 'c1'
do:
hbase> put 't1', 'r1', 'c1', 'value'

SCAN
Scan a tableTo scan all members of a column family, leave the qualifier empty as in 'col_family:'.
hbase> scan 't1’

STATUS
Show cluster status.
Can be 'summary', 'simple', or 'detailed'.
The default is 'summary'.
Examples:
hbase> status
hbase> status 'simple'
hbase> status 'summary'
hbase> status 'detailed'

SHUTDOWN
Shut down the cluster.

TRUNCATE
Disables, drops and recreates the specified table.

VERSION
Output this HBase version
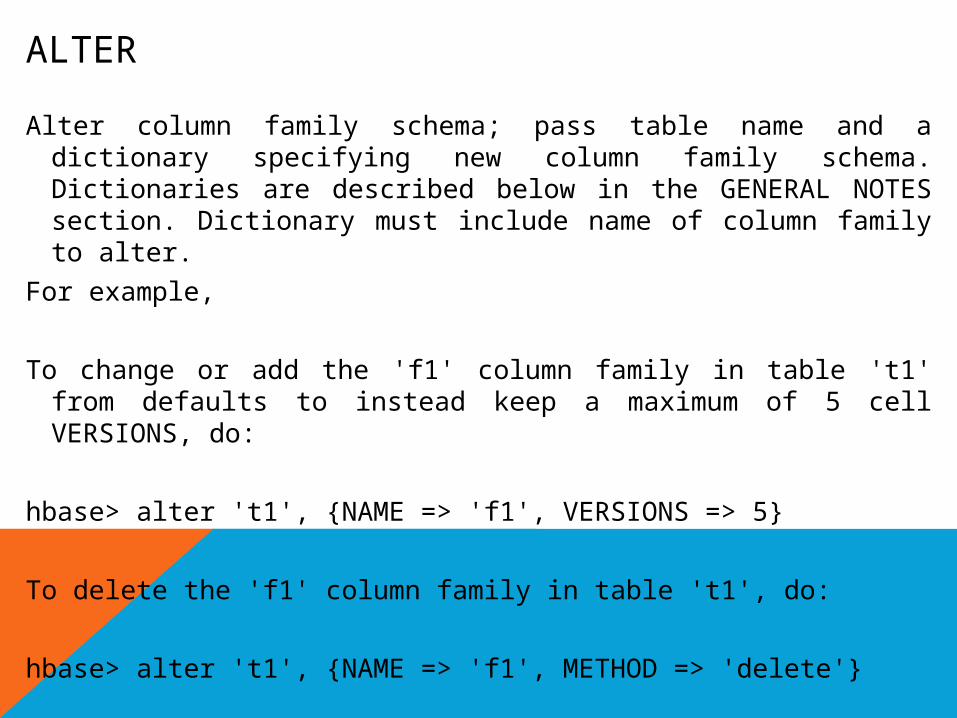
ALTER
Alter column family schema; pass table name and a dictionary specifying new column family schema. Dictionaries are described below in the GENERAL NOTES section. Dictionary must include name of column family to alter.
For example,
To change or add the 'f1' column family in table 't1' from defaults to instead keep a maximum of 5 cell VERSIONS, do:
hbase> alter 't1', {NAME => 'f1', VERSIONS => 5}
To delete the 'f1' column family in table 't1', do:
hbase> alter 't1', {NAME => 'f1', METHOD => 'delete'}

EXIT
Type hbase> exit
to leave the HBase Shell

SCRIPTING
You can pass scripts to the HBase Shell by doing the following:
bin/hbase shell PATH_TO_SCRIPT
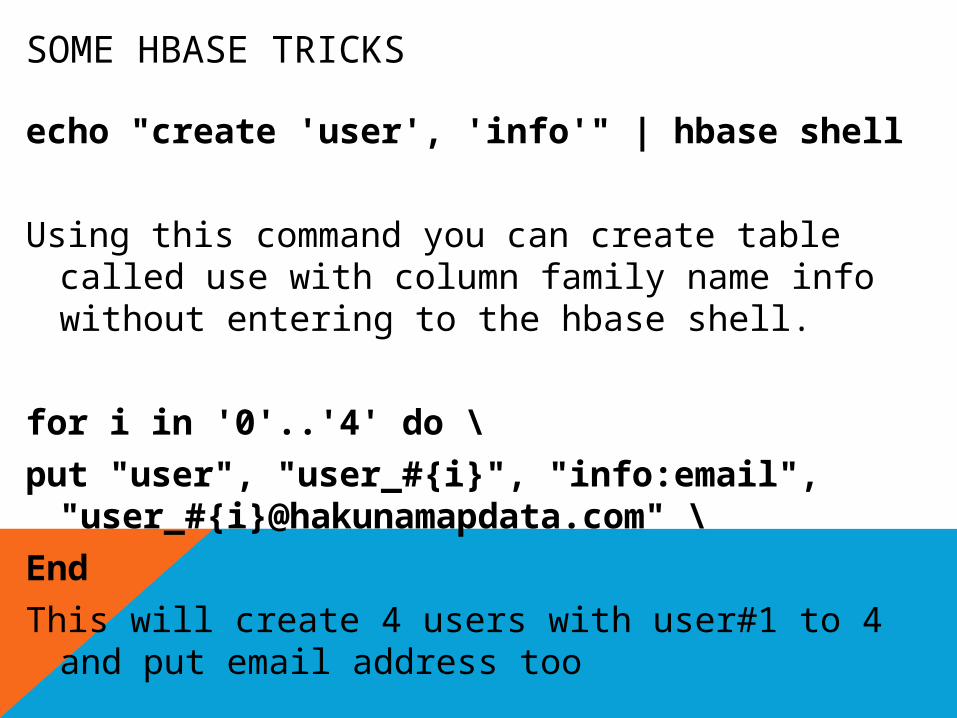
SOME HBASE TRICKS
echo "create 'user', 'info'" | hbase shell
Using this command you can create table called use with column family name info without entering to the hbase shell.
for i in '0'..'4' do \
put "user", "user_#{i}", "info:email", "user_#{i}@hakunamapdata.com" \
End
This will create 4 users with user#1 to 4 and put email address too

SCRIPT FOR HBASE
cat hbase_user_part_scan.txt scan 'user', {STARTROW => 'user_1', STOPROW => 'user_3'} exit
$ hbase shell hbase_user_part_scan.txt
This script will scan the user table and give output.

USING BASH SCRIPT
#!/bin/bash TABLE=$1 STARTROW=$2 STOPROW=$3 exec hbase shell <<EOF scan "${TABLE}", {STARTROW => "${STARTROW}", STOPROW => "${STOPROW}"} EOF
$ ./part_scan.sh user user_1 user_3

SEE WHEN A RECORD WAS ADDED
get 'user', 'user_1‘
Time.at(1344763701019/1000)
Will show you the human understable time like
Sun Aug 12 11:28:21 +0200 2012
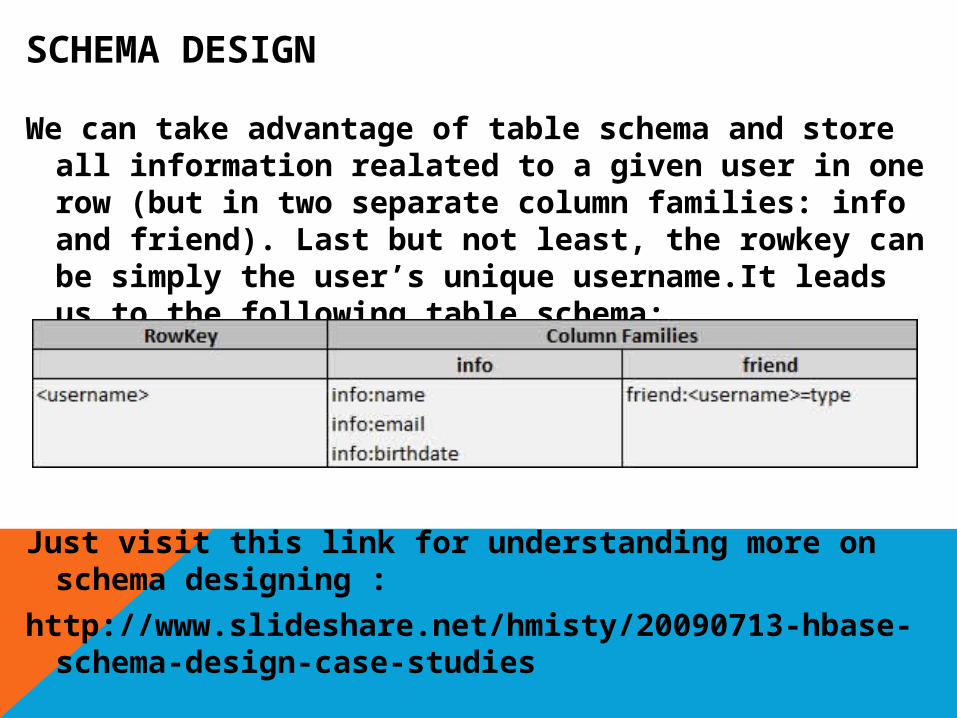
SCHEMA DESIGN
We can take advantage of table schema and store all information realated to a given user in one row (but in two separate column families: info and friend). Last but not least, the rowkey can be simply the user’s unique username.It leads us to the following table schema:
Just visit this link for understanding more on schema designing :
http://www.slideshare.net/hmisty/20090713-hbase-schema-design-case-studies

ADDING MORE DATA TO HBASE TABLES
$ hbase shell
hbase(main):001:0> create 'user', 'info', 'friend'
hbase(main):002:0> put 'user', 'username1', 'friend:username2', 'childhood'
hbase(main):003:0> put 'user', 'username1', 'friend:username3', 'childhood'
hbase(main):004:0> put 'user', 'username2', 'friend:username3', 'childhood'
hbase(main):005:0> put 'user', 'username2', 'friend:username4', 'childhood'
hbase(main):006:0> put 'user', 'username3', 'friend:username5', 'childhood'
hbase(main):007:0> put 'user', 'username1', 'friend:username5', 'childhood‘
Or you can write an script to create these value

SPECIFYING DIFFERENT CONFIGURATION FOR HBASE SHELL
HBase Shell is started by using the hbase shell command. This command uses the HBase configuration file (hbase-site.xml) for the client to find the cluster to connect to. After connecting to the cluster, it starts a prompt, waiting for commands. As shown in the following code, you can also use the --config option, which allows you to pass a different
configuration for HBase Shell to use:
hbase --config <configuration_directory> shell

SOME HELPFUL COMMANDS : EXERCISE
Get a specified row by using the get command:
Delete a specified cell by using the delete command:
Delete all the cells in a given row using the deleteall command:
enable the balancer

ANSWERS
get 't1', 'row1'
delete 't1', 'row1', 'f1:c1‘
deleteall 't1', 'row1‘
balance_switch true

CHECKING THE CONSISTENCY OF AN HBASE CLUSTER
Bin/hbase hbck

YOU WANT TO QUERY HBASE USING SQL????
Use hive to query . For that you need to create a table in hive as external table to hbase as follows:
create external table hbase_tablehbase
(key string, v01 string, v02 string, v03 string)
stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
with serdeproperties ("hbase.columns.mapping" =
":key,n:v01,n:v02,n:v03")
tblproperties("hbase.table.name" = "tablehbase");
select * from hbase_hly_temp where v01='808C';
You can give this query in hive to get data from hbase and you have lot of other options with hive just visit :
http://karmasphere.com/hive-queries-on-table-data

BACKING UP AND RESTORING HBASE DATA
• Full shutdown backup using distcp• Using CopyTable to copy data from one table
to another• Exporting an HBase table to dump files on
HDFS
• Restoring HBase data by importing dump files from HDFS
• Backing up NameNode metadata• Backing up region starting keys• Cluster replication
