handling outliers and missing data in statistical data models kaushik mitra date: 17/1/2011 ecsu...
TRANSCRIPT

Handling Outliers and Missing Data in Statistical Data Models
Kaushik MitraDate: 17/1/2011ECSU Seminar, ISI

Statistical Data Models• Goal: Find structure in data• Applications– Finance– Engineering– Sciences
• Biological– Wherever we deal with data
• Some examples– Regression– Matrix factorization
• Challenges: Outliers and Missing data

Outliers Are Quite CommonGoogle search results for `male faces’

Need to Handle Outliers Properly
Noisy image Gaussian filtered image Desired result
Removing salt-and-pepper (outlier) noise

Missing Data Problem
Completing missing tracks
Incomplete tracksCompleted tracks by a sub-optimal method
Desired result
Missing tracks in structure from motion

Our Focus
• Outliers in regression– Linear regression– Kernel regression
• Matrix factorization in presence of missing data

Robust Linear Regression for High Dimension Problems

What is Regression?
• Regression– Find functional relation between y and x• x: independent variable• y: dependent variable
– Given • data: (yi,xi) pairs
• Model y = f(x, w)+n
– Estimate w– Predict y for a new x

Robust Regression
• Real world data corrupted with outliers• Outliers make estimates unreliable
• Robust regression– Unknown
• Parameter, w• Outliers
– Combinatorial problem• N data and k outliers
• C(N,k) ways

Prior Work
• Combinatorial algorithms– Random sample consensus (RANSAC)– Least Median Squares (LMedS)• Exponential in dimension
• M-estimators– Robust cost functions– local minima

Robust Linear Regression model
• Linear regression model : yi=xiTw+ei
– ei, Gaussian noise
• Proposed robust model: ei=ni+si
– ni, inlier noise (Gaussian)
– si, outlier noise (sparse)
• Matrix-vector form– y=Xw+n+s
• Estimate w, s
y1
y2
.
.yN
x1T
x2T
.
.xN
T
n1
n2
. .nN
s1
s2
. .sN
= + +
w1
w2
.wD

Simplification• Objective (RANSAC): Find w that minimizes the
number of outliers
• Eliminate w • Model: y=Xw+n+s • Premultiple by C : CX=0, N ≥ D– Cy=CXw+Cs+Cn– z=Cs+g
– g Gaussian• Problem becomes: • Solve for s -> identify outliers -> LS -> w
20 ||||||||min Cszss
tosubject
20 ||||||||min sXwysws,
tosubject

Relation to Sparse Learning
• Solve: – Combinatorial problem
• Sparse Basis Selection/ Sparse Learning• Two approaches :– Basis Pursuit (Chen, Donoho, Saunder 1995)– Bayesian Sparse Learning (Tipping 2001)
20 ||||||||min Cszss
tosubject

Basis Pursuit Robust regression (BPRR)
• Solve – Basis Pursuit Denoising (Chen et. al. 1995)– Convex problem– Cubic complexity : O(N3)
• From Compressive Sensing theory (Candes 2005)– Equivalent to original problem if
• s is sparse• C satisfy Restricted Isometry Property (RIP)
• Isometry: ||s1 - s2|| = ||C(s1 – s2)||• Restricted: to the class of sparse vectors
• In general, no guarantees for our problem
Cszss
thatsuch1
min

Bayesian Sparse Robust Regression (BSRR)
• Sparse Bayesian learning technique (Tipping 2001)– Puts a sparsity promoting prior on s : – Likelihood : p(z/s)=Ν(Cs,εI)– Solves the MAP problem p(s/z) – Cubic Complexity : O(N3)
N
i issp
1
1)(

Setup for Empirical Studies• Synthetically generated data
• Performance criteria– Angle between ground truth and estimated hyper-planes

Vary Outlier Fraction
BSRR performs well in all dimensions Combinatorial algorithms like RANSAC, MSAC, LMedS not
practical in high dimensions
Dimension = 2 Dimension = 8 Dimension = 32

Facial Age Estimation • Fgnet dataset : 1002 images of 82 subjects
• Regression– y : Age
– x: Geometric feature vector

Outlier Removal by BSRR
• Label data as inliers and outliers• Detected 177 outliers in 1002 images
BSRR
Inlier MAE 3.73
Outlier MAE 19.14
Overall MAE 6.45
•Leave-one-out testing

Summary for Robust Linear Regression
• Modeled outliers as sparse variable • Formulated robust regression as Sparse
Learning problem– BPRR and BSRR
• BSRR gives the best performance• Limitation: linear regression model– Kernel model

Robust RVM Using Sparse Outlier Model

Relevance Vector Machine (RVM)
• RVM model:– : kernel function
• Examples of kernels– k(xi, xj) = (xi
Txj)2 : polynomial kernel
– k(xi, xj) = exp( -||xi - xj||2/2σ2) : Gaussian kernel
• Kernel trick: k(xi,xj) = ψ(xi)Tψ(xj)– Map xi to feature space ψ(xi)
N
ii ewkwy
10),()( ixxx
),( ixxk

RVM: A Bayesian Approach• Bayesian approach– Prior distribution : p(w)– Likelihood :
• Prior specification– p(w) : sparsity promoting prior p(wi) = 1/|wi|– Why sparse?
• Use a smaller subset of training data for prediction• Support vector machine
• Likelihood – Gaussian noise
• Non-robust : susceptible to outliers
),|( wxyp

Robust RVM model
• Original RVM model– e, Gaussian noise
• Explicitly model outliers, ei= ni + si
– ni, inlier noise (Gaussian)
– si, outlier noise (sparse and heavy-tailed)
• Matrix vector form– y = Kw + n + s
• Parameters to be estimated: w and s
N
ijj ewkwy
10)( xx,

Robust RVM Algorithms
• y = [K|I]ws + n– ws = [wT sT]T : sparse vector
• Two approaches– Bayesian– Optimization

Robust Bayesian RVM (RB-RVM)
• Prior specification– w and s independent : p(w, s) = p(w)p(s)– Sparsity promoting prior for s: p(si)= 1/|si|
• Solve for posterior p(w, s|y) • Prediction: use w inferred above • Computation: a bigger RVM– ws instead of w
– [K|I] instead of K

Basis Pursuit RVM (BP-RVM)
• Optimization approach
– Combinatorial
• Closest convex approximation
• From compressive sensing theory– Same solution if [K|I] satisfies RIP• In general, can not guarantee
20 ||]|[||||||min ssw
wIKyws
tosubject
21 ||]|[||||||min ssw
wIKyws
tosubject

Experimental Setup

Prediction : Asymmetric Outliers Case

Image Denoising
• Salt and pepper noise– Outliers
• Regression formulation– Image as a surface over 2D grid• y: Intensity • x: 2D grid • Denoised image obtained by prediction

Salt and Pepper Noise

Some More ResultsRVM RB-RVM Median Filter

Age Estimation from Facial Images
• RB-RVM detected 90 outliers
• Leave-one-person-out testing

Summary for Robust RVM
• Modeled outliers as sparse variables• Jointly estimated parameter and outliers• Bayesian approach gives very good result

Limitations of Regression
• Regression: y = f(x,w)+n– Noise in only “y”– Not always reasonable
• All variables have noise– M = [x1 x2 … xN]– Principal component analysis (PCA)
• [x1 x2 … xN] = ABT – A: principal components– B: coefficients
– M = ABT: matrix factorization (our next topic)

Matrix Factorization in the presence of Missing Data

Applications in Computer Vision
• Matrix factorization: M=ABT
• Applications: build 3-D models from images– Geometric approach (Multiple views)
– Photometric approach (Multiple Lightings)
37
Structure from Motion (SfM)
Photometric stereo
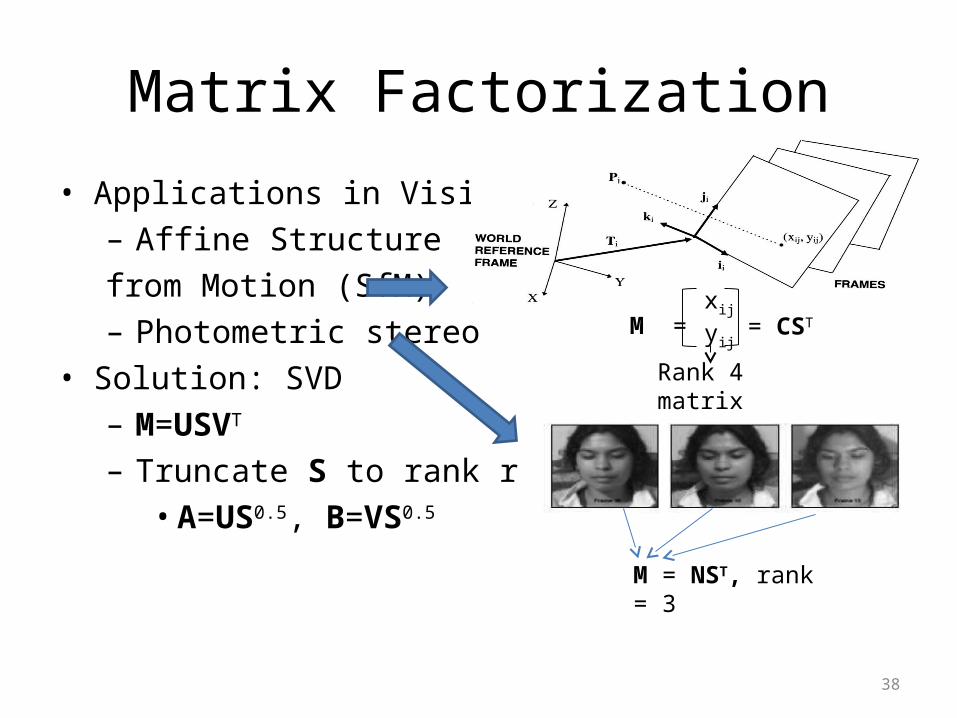
Matrix Factorization
• Applications in Vision– Affine Structure from Motion (SfM)– Photometric stereo
• Solution: SVD– M=USVT
– Truncate S to rank r• A=US0.5, B=VS0.5
38
M =xij
yij= CST
Rank 4 matrix
M = NST, rank = 3

Missing Data Scenario
• Missed feature tracks in SfM
• Specularities and shadow in photometric stereo
39
Incomplete feature tracks

Challenges in Missing Data Scenario
• Can’t use SVD• Solve:
• W: binary weight matrix, λ: regularization parameter• Challenges
– Non-convex problem– Newton’s method based algorithm (Buchanan et. al. 2005)
• Very slow• Design algorithm
– Fast (handle large scale data) – Flexible enough to handle additional constraints
• Ortho-normality constraints in ortho-graphic SfM
)||||||(||||)(||min 222FFF
T BAABMWBA,

Proposed Solution
• Formulate matrix factorization as a low-rank semidefinite program (LRSDP)– LRSDP: fast implementation of SDP (Burer, 2001) • Quasi-Newton algorithm
• Advantages of the proposed formulation:– Solve large-scale matrix factorization problem– Handle additional constraints
41

Low-rank Semidefinite Programming (LRSDP)
• Stated as:• Variable: R• Constants• C: cost • Al, bl: constants
• Challenge• Formulating matrix factorization as LRSDP• Designing C, Al, bl
klbtosubject lT
lT ,...,2,1,min RRARRC
R

Matrix factorization as LRSDP: Noiseless Case
• We want to formulate:
• As:• LRSDP formulation:
),()(||||||||min ,,22
,jifortosubject jiji
TFF
BAMABBA
)(||||||||
)(||||),(||||22
22
TFF
TF
TF
trace
tracetrace
RRBA
BBBAAA
jimjiT
jijiT
,,,, )()( MRRMAB
||,...,2,1, lbtosubject lTT RRARRC l
C identity matrix,Al indicator matrix

Affine SfM
• Dinosaur sequence
• MF-LRSDP gives the best reconstruction
72% missing data

Photometric Stereo
• Face sequence
• MF-LRSDP and damped Newton gives the best result
42% missing data

Additional Constraints:Orthographic Factorization
• Dinosaur sequence

Summary
• Formulated missing data matrix factorization as LRSDP– Large scale problems– Handle additional constraints
• Overall summary– Two statistical data models• Regression in presence of outliers
– Role of sparsity• Matrix factorization in presence of missing data
– Low rank semidefinite program

Thank you! Questions?
48