hadoopdb: an architectural hybrid of mapreduce and dbms technologies for analytical workloads
DESCRIPTION
HadoopDB: An Architectural Hybrid of MapReduce and DBMS Technologies for Analytical Workloads. By: Muhammad Mudassar MS-IT-8. What is going on. Data analysis techniques are changing Enterprises moving to cheaper commodity hardware - PowerPoint PPT PresentationTRANSCRIPT

HADOOPDB: AN ARCHITECTURAL HYBRID OF MAPREDUCE AND DBMS TECHNOLOGIES FOR ANALYTICAL WORKLOADS
By: Muhammad Mudassar
MS-IT-8
1

WHAT IS GOING ON
Data analysis techniques are changing Enterprises moving to cheaper commodity
hardware MPP (Massively Parallel Processing)
architecture inside “Clods” Analytical data is exploding What technology for data analysis?
Parallel databases MapReduce-based systems
2

THE TWO TECHNOLOGIES
Parallel Databases High performance
and efficiency Bad scores in fault
tolerance and run in heterogeneous environment
Few known deployments over 100 nodes
MapReduce-based systems Designed to scale
over 1000 of nodes Fault tolerant and
capable to run in heterogeneous environment
Biggest issue with MapReduce is performance
3

HADOOPDB
A hybrid system to handle demands of data intensive applications
Advantages Scalability of MapReduce Performance and efficiency of parallel databases
Completely build on open source free to use components PostgreSQL as database layer Hadoop MapReduce is used
Amazon’s EC2 cloud is used
4

DESIRED PROPERTIES Performance
A primary characteristic that commercial database systems use to distinguish themselves
Fault tolerance Measured differently for analytical DBMS and
transactional DBMS. For analytical DBMS query restart is to be avoided
Ability to run in heterogeneous environment Nearly impossible to get homogeneous
performance from 100 or 1000 nodes Flexible query interface
Allow user to write user defined functions (UDFs) and queries that should be parallelized automatically.
5
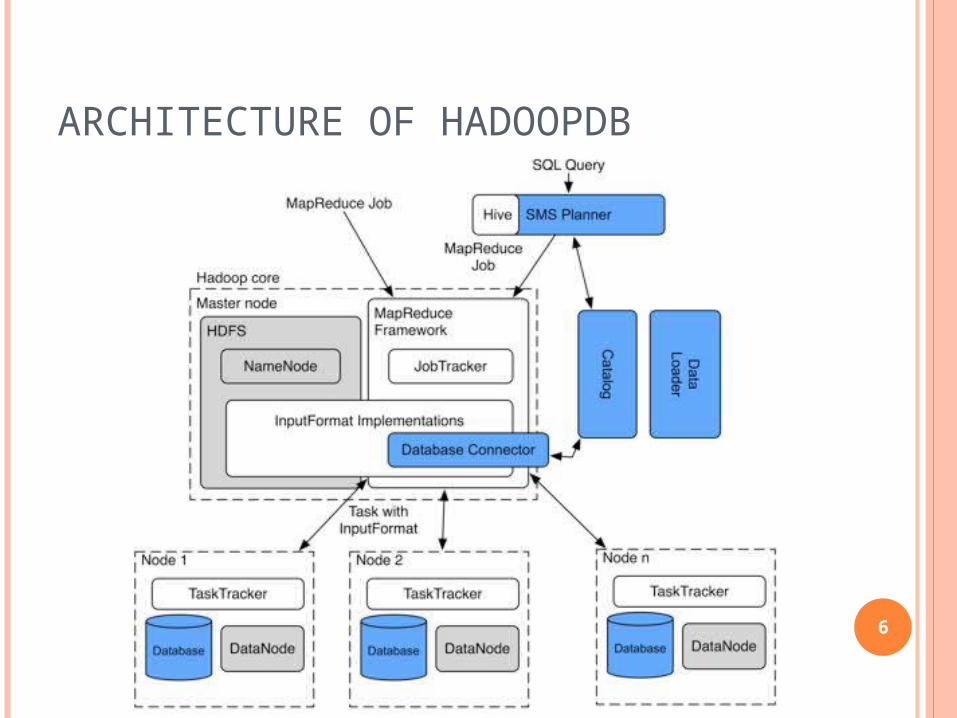
ARCHITECTURE OF HADOOPDB
6

THE HADOOP FRAMEWORK Hadoop consists of 2 layers
Data storage layers which is Hadoop Distributed File System (HDFS)
Data processing or the MapReduce framework HDFS
Block-structure file system managed by NameNode Data handled by DataNodes
MapReduce framework Master-slave architecture based on JobTracker &
TaskTracker JobTracker manages job like assignment keeping track of
jobs and load balancing TaskTrackers perform assigned Map or Reduce tasks
assigned to them 7

THE HADOOPDB’S COMPONENTS HadoopDB extends Hadoop framework with
four components1. Database connector
Interface between DBMS and TaskTacker Database is similar to data blocks in HDFS
2. Catalog Maintain information about database
Database location, driver class meta data like replica location partitioning property
3. Data Loader Globally partition the data on given key Break single node data into chunks Load the chunks to the database
8

THE HADOOPDB’S COMPONENTS
1. SQL to MapReduce to SQL (SMS) Planner HadoopDB provide front end to process SQL
queries SMS planner extends Hive
Parser transforms query to abstract syntax tree Get table schema information from catalog Logical plan generator creates query plan Optimizer breaks up plan to Map or Reduce phases Executable plan generated for one or more
MapReduce jobs SMS tries to push maximum work to database
layer 9

EVALUATING HADOOPDB
Compare HadoopDB to Hadoop Parallel databases (Vertica, DBMS-X)
Features Performance
HadoopDB is expected to approach performance of parallel databases
Scalability
HadoopDB would be scalable
10
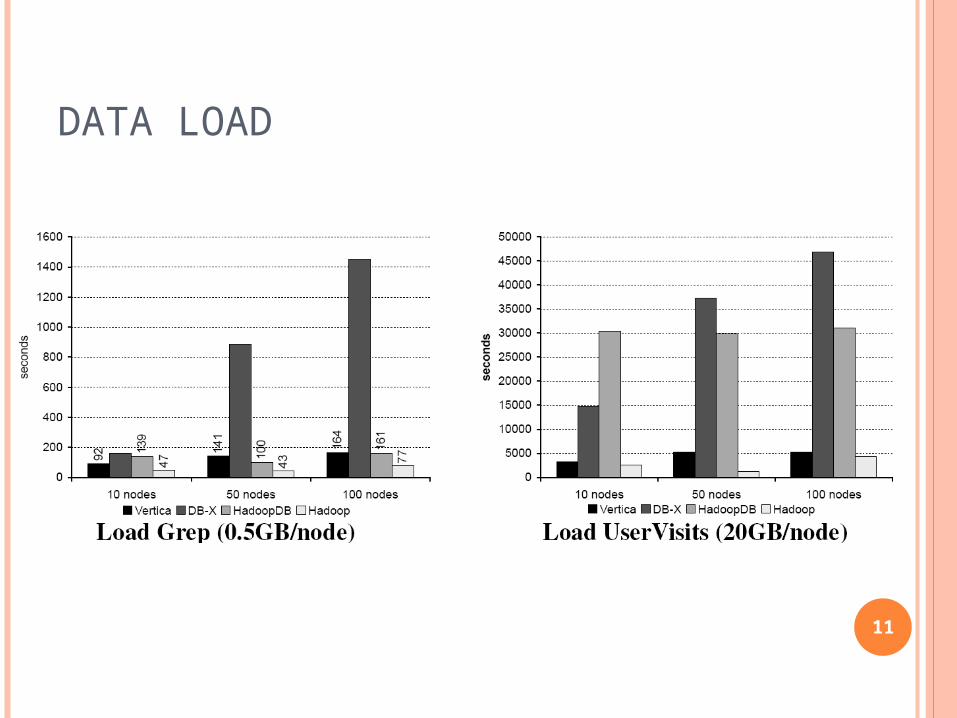
DATA LOAD
11
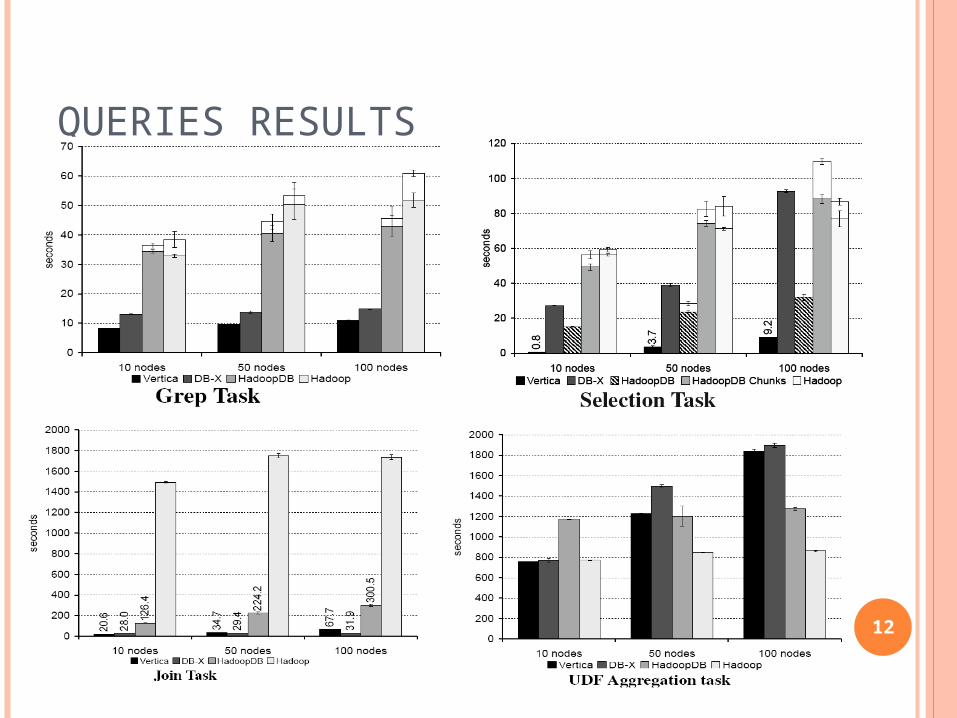
QUERIES RESULTS
12
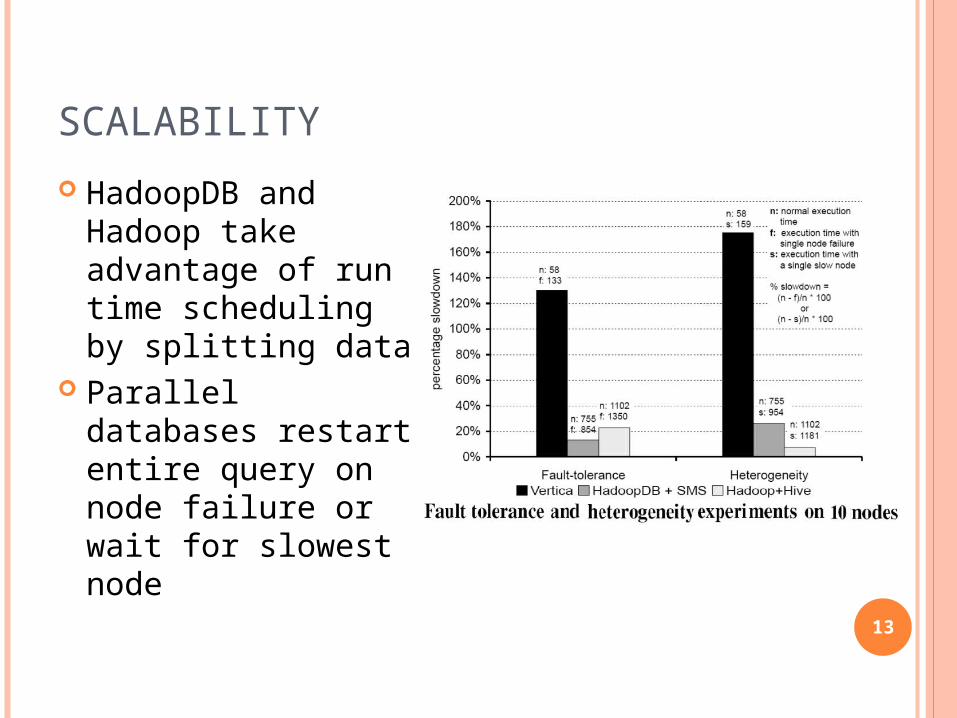
SCALABILITY
HadoopDB and Hadoop take advantage of run time scheduling by splitting data
Parallel databases restart entire query on node failure or wait for slowest node
13

CONCLUSION
HadoopDB Is a Hybrid system Scales better then parallel databases Fault tolerant Approaches the performance of parallel
databases Free and opensource
14