hadoop: tecnologias relacionadas
DESCRIPTION
Tecnologías del ecosistema Hadoop: Pig, Hive. Oozie, HBaseTRANSCRIPT

Hadoop: tecnologías
relacionadas
Tomás Fernández Pena
Máster en Computación de Altas Prestaciones
Universidade de Santiago de Compostela
Computación en Sistemas Distribuidos
Material bajo licencia Creative Commons Attribution-ShareAlike 4.0 International (CC BY-SA 4.0)citius.usc.es

Tecnologías relacionadas Pig Hive Apache Oozie Introducción a HBase
Índice
1 Tecnologías relacionadas
2 Pig
3 Hive
4 Apache Oozie
5 Introducción a HBase
Hadoop: tecnologías relacionadas, CSD
Tecnologías relacionadas Pig Hive Apache Oozie Introducción a HBase
Índice
1 Tecnologías relacionadas
2 Pig
3 Hive
4 Apache Oozie
5 Introducción a HBase
Hadoop: tecnologías relacionadas, CSD

Tecnologías relacionadas Pig Hive Apache Oozie Introducción a HBase
Tecnologías relacionadas (I)
Diversas tecnologías relacionadas:
Pig: lenguaje data-flow de alto nivel para facilitar la programación
MapReduce
Hive: infraestructura de data-warehouse construida sobre Hadoop
Spark: motor de procesamiento de datos de caracter general
compatible con datos Hadoop
Oozie, Cascading, Azkaban, Hamake: planificadores de workflows
para gestionar trabajos Hadoop
Tez: ejecución de DAGs de tareas complejos para queries
interactivas
S4, Storm: procesamiento de flujos de datos (stream processing)
Impala: queries en tiempo real para Hadoop
Hadoop: tecnologías relacionadas, CSD 1/36

Tecnologías relacionadas Pig Hive Apache Oozie Introducción a HBase
Tecnologías relacionadas (II)
HBase: base de datos distribuida no-relacional (NoSQL) que corre
sobre HDFS (inspirado en Google BigTable)
Sqoop: transferencia eficiente de datos eficiente entre Hadoop y
bases de datos relacionales
Whirr: herramientas para iniciar clusters Hadoop y otros servicios
en diferentes proveedores cloud
Ambari: herramienta basada en web para aprovisionar, gestionar y
monitorizar clusters Hadoop
Hue: interfaz web para simplificar el uso de Hadoop
ZooKeeper: servicio centralizado de configuración, nombrado,
sincronización distribuida y servicios de grupos para grandes
sistemas distribuidos
Hadoop: tecnologías relacionadas, CSD 2/36

Tecnologías relacionadas Pig Hive Apache Oozie Introducción a HBase
Tecnologías relacionadas (III)
HCatalog: interfaces para permitir el acceso al Hive metastore
desde diversas herramientas
WebHCat: API REST-like para HCatalog (antes Templeton)
Falcon: solución para el procesamiento y gestión de datos para
Hadoop (movimiento. coordinación, gestión del ciclo de vida,
descubrimiento).
Slider: aplicación para desplegar aplicaciones distribuidas
existentes en YARN (aplicaciones long-running)
Hama: framework de computación Bulk Synchronous Parallel sobre
HDFS
Flume: obtención, agregación y movimiento de grandes ficheros de
log a HDFS
Hadoop: tecnologías relacionadas, CSD 3/36

Tecnologías relacionadas Pig Hive Apache Oozie Introducción a HBase
Tecnologías relacionadas (IV)
BigTop: empaquetamiento y tests para el ecosistema Hadoop
Knox: REST API Gateway para interactuar con clusters Hadoop
incorporando seguridad (autenticación/autorización/auditoría)
Twister: aplicaciones MapReduce iterativas
Mahout: algoritmos escalables de machine learning y minería de
datos sobre Hadoop
Chukwa: sistema de recogida de datos para monitorizar grandes
sistemas distribuidos
Flink: procesamiento in-memory y de streams (similar a Spark)
Pydoop: Python API para Hadoop
Perldoop: Traducción de códigos MR en Perl a Java
Hadoop: tecnologías relacionadas, CSD 4/36

Tecnologías relacionadas Pig Hive Apache Oozie Introducción a HBase
Índice
1 Tecnologías relacionadas
2 Pig
3 Hive
4 Apache Oozie
5 Introducción a HBase
Hadoop: tecnologías relacionadas, CSD

Tecnologías relacionadas Pig Hive Apache Oozie Introducción a HBase
Pig
Iniciado en Yahoo! Research
Eleva el nivel de abstracción paraprocesar grandes conjuntos de datos
. Facilita centrarse en el “qué” en vez de
en el “cómo”
Expresa secuencias de trabajos
MapReduce
Modelo de datos: “bags” anidadas deitems
. “Pig bag”: colección de tuplas
Proporciona operadores relacionales
(JOIN, GROUP BY, etc.)
Fácil definir y usar funciones definidas por
el usuario (UDFs) escritas en Java
Hadoop: tecnologías relacionadas, CSD 5/36

Tecnologías relacionadas Pig Hive Apache Oozie Introducción a HBase
Pig
Dos elementos principales:
. Un lenguaje propio: Pig Latin
. Un entorno de ejecución: local o Hadoop
Programas ejecutados como:
. Scripts en Pig Latin
. Grunt: shell interactivo para ejecutar comandos Pig
. Comandos Pig ejecutados desde Java
PigPen: entorno de desarrollo para Eclipse
Hadoop: tecnologías relacionadas, CSD 6/36
Tecnologías relacionadas Pig Hive Apache Oozie Introducción a HBase
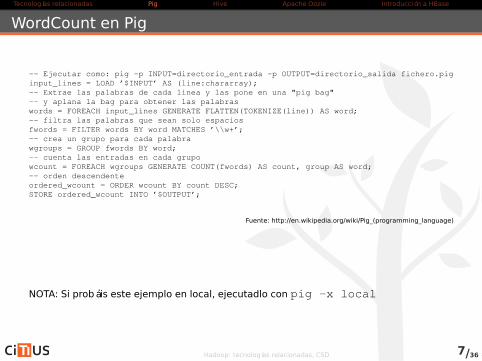
WordCount en Pig
-- Ejecutar como: pig -p INPUT=directorio_entrada -p OUTPUT=directorio_salida fichero.piginput_lines = LOAD ’$INPUT’ AS (line:chararray);-- Extrae las palabras de cada linea y las pone en una "pig bag"-- y aplana la bag para obtener las palabraswords = FOREACH input_lines GENERATE FLATTEN(TOKENIZE(line)) AS word;-- filtra las palabras que sean solo espaciosfwords = FILTER words BY word MATCHES ’\\w+’;-- crea un grupo para cada palabrawgroups = GROUP fwords BY word;-- cuenta las entradas en cada grupowcount = FOREACH wgroups GENERATE COUNT(fwords) AS count, group AS word;-- orden descendenteordered_wcount = ORDER wcount BY count DESC;STORE ordered_wcount INTO ’$OUTPUT’;
Fuente: http://en.wikipedia.org/wiki/Pig_(programming_language)
NOTA: Si probáis este ejemplo en local, ejecutadlo con pig -x local
Hadoop: tecnologías relacionadas, CSD 7/36
Tecnologías relacionadas Pig Hive Apache Oozie Introducción a HBase
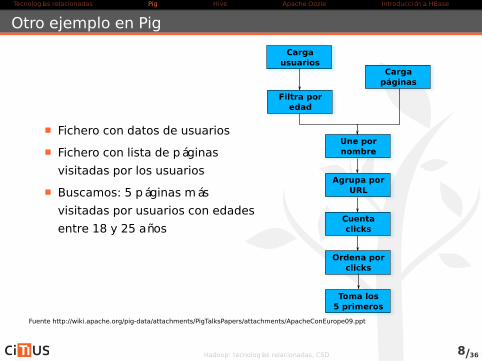
Otro ejemplo en Pig
Fichero con datos de usuarios
Fichero con lista de páginas
visitadas por los usuarios
Buscamos: 5 páginas más
visitadas por usuarios con edades
entre 18 y 25 años
Cargausuarios
Filtra poredad
Cargapáginas
Une pornombre
Agrupa porURL
Cuentaclicks
Ordena porclicks
Toma los5 primeros
Fuente http://wiki.apache.org/pig-data/attachments/PigTalksPapers/attachments/ApacheConEurope09.ppt
Hadoop: tecnologías relacionadas, CSD 8/36

Tecnologías relacionadas Pig Hive Apache Oozie Introducción a HBase
En Pig Latin
Users = load ’users’ as (name, age);Filtered = filter Users by age >= 18 and age <= 25;Pages = load ’pages’ as (user, url);Joined = join Filtered by name, Pages by user;Grouped = group Joined by url;Summed = foreach Grouped generate group,
count(Joined) as clicks;Sorted = order Summed by clicks desc;Top5 = limit Sorted 5;
store Top5 into ’top5sites’;
Hadoop: tecnologías relacionadas, CSD 9/36
Tecnologías relacionadas Pig Hive Apache Oozie Introducción a HBase
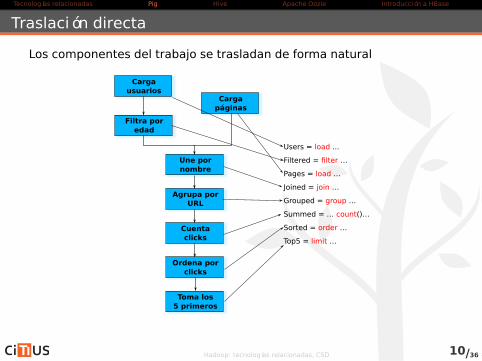
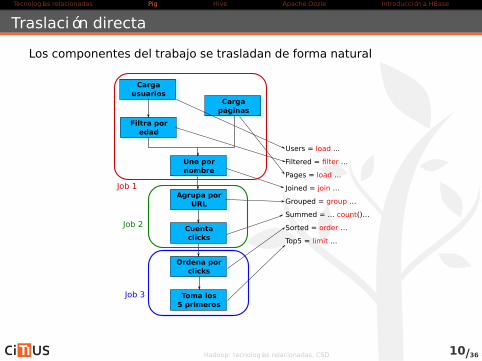
Traslación directa
Los componentes del trabajo se trasladan de forma natural
Cargausuarios
Filtra poredad
Cargapáginas
Une pornombre
Agrupa porURL
Cuentaclicks
Ordena porclicks
Toma los5 primeros
Users = load ...
Filtered = filter …
Pages = load …
Joined = join …
Grouped = group …
Summed = … count()…
Sorted = order …
Top5 = limit …
Hadoop: tecnologías relacionadas, CSD 10/36
Tecnologías relacionadas Pig Hive Apache Oozie Introducción a HBase
Traslación directa
Los componentes del trabajo se trasladan de forma natural
Cargausuarios
Filtra poredad
Cargapáginas
Une pornombre
Agrupa porURL
Cuentaclicks
Ordena porclicks
Toma los5 primeros
Users = load ...
Filtered = filter …
Pages = load …
Joined = join …
Grouped = group …
Summed = … count()…
Sorted = order …
Top5 = limit …
Job 1
Job 2
Job 3
Hadoop: tecnologías relacionadas, CSD 10/36

Tecnologías relacionadas Pig Hive Apache Oozie Introducción a HBase
Número de reducers en Pig
Por defecto, el script Pig se ejecuta con 1 reducer
El número de reducers se puede indicar para todo el script
mediante una variable
SET default_parallel n_reducers;
o bien, indicarlo en las operaciones que implican un Reduce (group,
join, cogroup, order,...), por ejemplo:
STORE .... INTO ’$output’ parallel n_reducers;
Hadoop: tecnologías relacionadas, CSD 11/36
Tecnologías relacionadas Pig Hive Apache Oozie Introducción a HBase
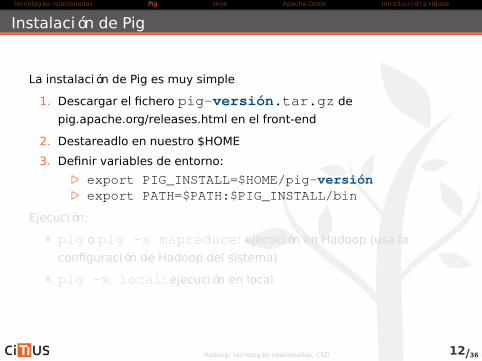
Instalación de Pig
La instalación de Pig es muy simple
1. Descargar el fichero pig-versión.tar.gz de
pig.apache.org/releases.html en el front-end
2. Destareadlo en nuestro $HOME
3. Definir variables de entorno:
. export PIG_INSTALL=$HOME/pig-versión
. export PATH=$PATH:$PIG_INSTALL/bin
Ejecución:
pig o pig -x mapreduce: ejecución en Hadoop (usa la
configuración de Hadoop del sistema)
pig -x local: ejecución en local
Hadoop: tecnologías relacionadas, CSD 12/36

Tecnologías relacionadas Pig Hive Apache Oozie Introducción a HBase
Instalación de Pig
La instalación de Pig es muy simple
1. Descargar el fichero pig-versión.tar.gz de
pig.apache.org/releases.html en el front-end
2. Destareadlo en nuestro $HOME
3. Definir variables de entorno:
. export PIG_INSTALL=$HOME/pig-versión
. export PATH=$PATH:$PIG_INSTALL/bin
Ejecución:
pig o pig -x mapreduce: ejecución en Hadoop (usa la
configuración de Hadoop del sistema)
pig -x local: ejecución en local
Hadoop: tecnologías relacionadas, CSD 12/36
Tecnologías relacionadas Pig Hive Apache Oozie Introducción a HBase
Índice
1 Tecnologías relacionadas
2 Pig
3 Hive
4 Apache Oozie
5 Introducción a HBase
Hadoop: tecnologías relacionadas, CSD

Tecnologías relacionadas Pig Hive Apache Oozie Introducción a HBase
Hive
Desarrollado en Facebook
“Base de datos relacional” sobre Hadoop
Soporta el análisis de grandes datasets en
filesystems compatibles con Hadoop (HDFS,
S3, ...)HiveQL: dialecto de SQL
. Peticiones HiveQL se convierten en un grafo dirigido acíclico de
trabajos MapReduce
Organiza los datos del filesystem en tablas
. Listas de metadatos (p.e. esquemas de tablas) almacenados en una
base de datos (por defecto, Apache Derby)
Soporta particionado de tablas, clustering, tipos de datos
complejos, etc.
Puede llamar a scripts de Hadoop Streaming desde HiveQL
Hadoop: tecnologías relacionadas, CSD 13/36

Tecnologías relacionadas Pig Hive Apache Oozie Introducción a HBase
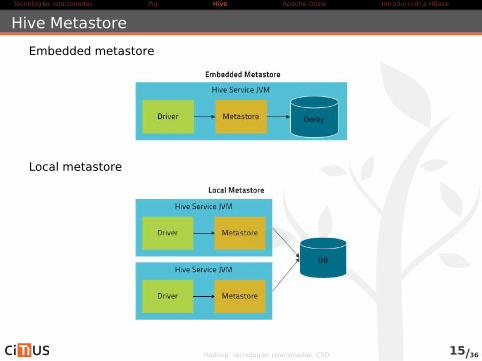
Hive Metastore
Repositorio central de los metadatos de Hive. Dos partes:
Un servicio
Un almacenamiento
Tres modos de configuración
Embedded metastore (por defecto)
Local metastore
Remote metastore
Hadoop: tecnologías relacionadas, CSD 14/36
Tecnologías relacionadas Pig Hive Apache Oozie Introducción a HBase
Hive Metastore
Embedded metastore
Local metastore
Hadoop: tecnologías relacionadas, CSD 15/36
Tecnologías relacionadas Pig Hive Apache Oozie Introducción a HBase
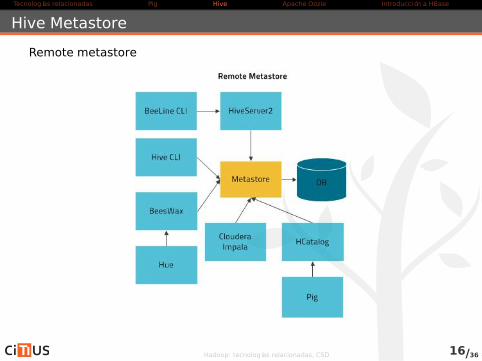
Hive Metastore
Remote metastore
Hadoop: tecnologías relacionadas, CSD 16/36

Tecnologías relacionadas Pig Hive Apache Oozie Introducción a HBase
Tablas Hive
Combinación lógica de datos y metadatos
Los datos residen en HDFS o en otro Hadoop FileSystem, los
metadatos en una base de datos relacional (Metastore)
Managed tables: los datos se sitúan en el directorio warehouse,
bajo control de Hive
External tables: los datos se mantienen fuera del directorio
warehouse (facilita su compartición con otras aplicaciones)
Hadoop: tecnologías relacionadas, CSD 17/36

Tecnologías relacionadas Pig Hive Apache Oozie Introducción a HBase
Particiones y buckets
Particiones
Las tablas se pueden organizan en particiones, basadas en el valor
de columnas de partición
Las tablas se pueden particionar en múltiples dimensiones
Las particiones se definen al crear la tabla (clausula PARTITIONED
BY)
Buckets o clusters
Otro mecanismo para segmentar los datos y optimizar las queries
Se usa un número fijo de buckets y una función hash para distribuir
los valores entre los buckets
Hadoop: tecnologías relacionadas, CSD 18/36
Tecnologías relacionadas Pig Hive Apache Oozie Introducción a HBase
Ejemplo de particiones y buckets
CREATE TABLE order (
username STRING,
orderdate STRING,
amount DOUBLE,
) PARTITIONED BY (country STRING)
CLUSTERED BY (username) INTO 25 BUCKETS;
Se crea una partición por país
Se crean 25 buckets
. Los datos de un usuario siempre al mismo bucket
. Un bucket puede tener datos de múltiples usuarios
. Se usa una función hash para determinar el bucket al que va cada
usuario
Hadoop: tecnologías relacionadas, CSD 19/36
Tecnologías relacionadas Pig Hive Apache Oozie Introducción a HBase
Ejemplo Hive
Encontrar las 5 páginas más visitadas por usuarios entre 18-25 años
SELECT p. url , COUNT(1) as cl icks
FROM users u JOIN page_views p ON (u.name = p. user )
WHERE u.age >= 18 AND u.age <= 25
GROUP BY p. ur l
ORDER BY cl icks
LIMIT 5;
Filtra la vista de páginas usando un script Python
SELECT TRANSFORM(p. user , p. date)
USING ’map_script .py ’
AS dt , uid CLUSTER BY dt
FROM page_views p;
Hadoop: tecnologías relacionadas, CSD 20/36
Tecnologías relacionadas Pig Hive Apache Oozie Introducción a HBase
Instalación de Hive
La instalación de Hive es sencilla
1. Descargar el fichero hive-0.11.0.tar.gz de
http://hive.apache.org/releases.html
2. Destareadlo en nuestro $HOME
3. Definir variables de entorno:
. export HIVE_HOME=$HOME/hive-0.11.0
. export PATH=$PATH:$HIVE_HOME/bin
. Conectarse al NameNode, y como usuario hadoop crear el siguiente
directorio
hadoop fs -mkdir /user/hive/warehouse. Dadle permisos para que todos los usuarios puedan usar hive
hadoop fs -chmod 777 /user/hive/warehouse
Para ejecutarlo, simplemente comando hive
Hadoop: tecnologías relacionadas, CSD 21/36

Tecnologías relacionadas Pig Hive Apache Oozie Introducción a HBase
Ejecución Hive
Igual que Pig, Hive tiene un shell para ejecución interactiva
En el prompt de hive se pueden ir ir ejecutando una a una las
instrucciones Hive
También se pueden ejecutar scripts
Con hive -f script.hive ejecutaríamos el script completo
Además, con hive -e 'comando_hive' se puede ejecutar una
orden simple
Hadoop: tecnologías relacionadas, CSD 22/36

Tecnologías relacionadas Pig Hive Apache Oozie Introducción a HBase
Ejecución Hive
Algunas características
Usando embedded metastore (por defecto), la metainformación seguarda en el directorio local
. Alternativa: usar metastore local o remota, con una base de datos
como MySQL
Al cargar (LOAD) los datos en una tabla desde un fichero, se mueveel fichero al directorio de Hive en HDFS(/user/hive/warehouse)
. Es una simple operación de ficheros
. Los ficheros no se parsean ni se modifican
. Si no se quiere mover los ficheros (p.e. para seguir usando Hadoop o
Pig) hay que crear la tabla EXTERNAL. Alternativa: usar HCatalog
- Permite que Hadoop o Pig usen la metastore de Hive
Hadoop: tecnologías relacionadas, CSD 23/36
Tecnologías relacionadas Pig Hive Apache Oozie Introducción a HBase
Índice
1 Tecnologías relacionadas
2 Pig
3 Hive
4 Apache Oozie
5 Introducción a HBase
Hadoop: tecnologías relacionadas, CSD

Tecnologías relacionadas Pig Hive Apache Oozie Introducción a HBase
Apache Oozie
Ejecución de workflows de trabajos dependientes
Workflows compuestos de diferentes tipos de trabajos Hadoop
(MapReduce, Pig, Hive, etc.)
Permite la ejecución en un cluster de miles de workflows
compuestos por decenas de trabajos y simplifica la re-ejecución de
workflows fallidos
Dos partes
. Workflow engine almacena y ejecuta workflows compuestos de
diferentes tipos de trabajos Hadoop (MP, Pig, Hive,. . . )
. Coordinator Engine ejecuta los workflows basándose en
planificadores definidos y disponibilidad de datos
Hadoop: tecnologías relacionadas, CSD 24/36

Tecnologías relacionadas Pig Hive Apache Oozie Introducción a HBase
Oozie Workflow
Definición del workflow escrita en XML usando HPDL (Hadoop
Process Definition Language)
Un workflow es un DAG compuesto por nodos de dos tipos:
. Action nodes realiza una tarea en el workflow (pe. trabajo MR, o
movimiento de ficheros en HDFS)
. Control-flow nodes gobierna la ejecución del workflow entre acciones
Más información oozie.apache.org/docs/
Hadoop: tecnologías relacionadas, CSD 25/36
Tecnologías relacionadas Pig Hive Apache Oozie Introducción a HBase
Índice
1 Tecnologías relacionadas
2 Pig
3 Hive
4 Apache Oozie
5 Introducción a HBase
Hadoop: tecnologías relacionadas, CSD

Tecnologías relacionadas Pig Hive Apache Oozie Introducción a HBase
Introducción a HBase
Base de datos no-relacional (NoSQL), distribuida, orientada a columnas,
diseñada a partir de Google BigTable
Podemos considerarlo como un map ordenado, disperso,consistente, distribuido, multidimensional
. Filas consistentes en pares clave -> valor
. La clave es multidimensional:
(rowkey,column family,column,timestamp) -> value
Capaz de almacenar teras o petabytes de datos con escalabilidad
lineal (horizontal)
Diseñado para trabajar con HDFS
Particionado automático de las tablas
Incorpora sistemas de recuperación de fallos
Operaciones atómicas a nivel de filas
Hadoop: tecnologías relacionadas, CSD 26/36
Tecnologías relacionadas Pig Hive Apache Oozie Introducción a HBase
Conceptos HBase (I)
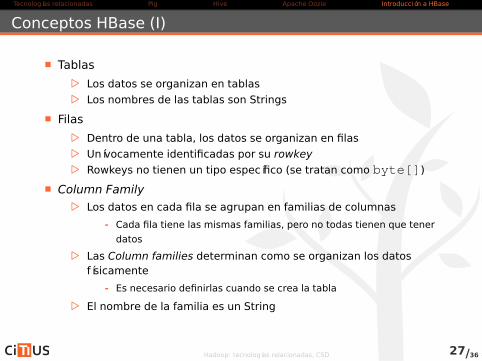
Tablas
. Los datos se organizan en tablas
. Los nombres de las tablas son Strings
Filas
. Dentro de una tabla, los datos se organizan en filas
. Unívocamente identificadas por su rowkey
. Rowkeys no tienen un tipo específico (se tratan como byte[])
Column Family
. Los datos en cada fila se agrupan en familias de columnas
- Cada fila tiene las mismas familias, pero no todas tienen que tener
datos
. Las Column families determinan como se organizan los datosfísicamente
- Es necesario definirlas cuando se crea la tabla
. El nombre de la familia es un String
Hadoop: tecnologías relacionadas, CSD 27/36

Tecnologías relacionadas Pig Hive Apache Oozie Introducción a HBase
Conceptos HBase (II)
Column qualifier o Columna
. Los datos en una Column family se organizan en columnas
. Distintas filas pueden tener distintas columnas
. No hay que definirlas cuando se crea la tabla
. No tienen un tipo específico (se tratan como byte[])
Celda
. La combinación (rowkey, cf, column) identifican de forma única una
celda
. En la celda se almacena un valor
. El valor no tiene un tipo de datos (se trata como byte[])
Versión
. Los valores en una celda tienen asociada una versión
. Las versiones se identifican mediante un timestamp (de tipo long)
. Por defecto, se guardan 3 versiones de un valor
Hadoop: tecnologías relacionadas, CSD 28/36

Tecnologías relacionadas Pig Hive Apache Oozie Introducción a HBase
Ejemplo de tabla
nombre edad email
Juan Pérez@ts
43@ts
info ventas
juan
pepe
ciudad password
Zaragoza@ts
Santiago @ts
12345678@tsqwerty@ts
producto precio
Blue-ray@ts
300 €@ts
Tabla clientes
rowkeys column family column
Hadoop: tecnologías relacionadas, CSD 29/36
Tecnologías relacionadas Pig Hive Apache Oozie Introducción a HBase
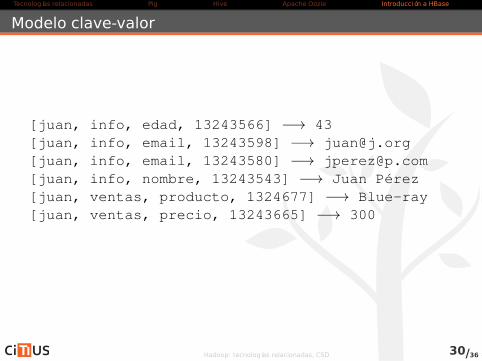
Modelo clave-valor
[juan, info, edad, 13243566] −→ 43[juan, info, email, 13243598] −→ [email protected][juan, info, email, 13243580] −→ [email protected][juan, info, nombre, 13243543] −→ Juan Pérez[juan, ventas, producto, 1324677] −→ Blue-ray[juan, ventas, precio, 13243665] −→ 300
Hadoop: tecnologías relacionadas, CSD 30/36
Tecnologías relacionadas Pig Hive Apache Oozie Introducción a HBase
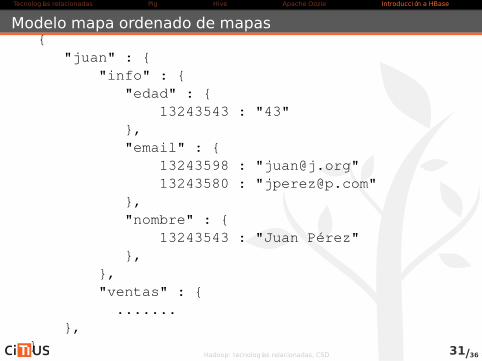
Modelo mapa ordenado de mapas{
"juan" : {"info" : {
"edad" : {13243543 : "43"
},"email" : {
13243598 : "[email protected]"13243580 : "[email protected]"
},"nombre" : {
13243543 : "Juan Pérez"},
},"ventas" : {.......
},}
Hadoop: tecnologías relacionadas, CSD 31/36

Tecnologías relacionadas Pig Hive Apache Oozie Introducción a HBase
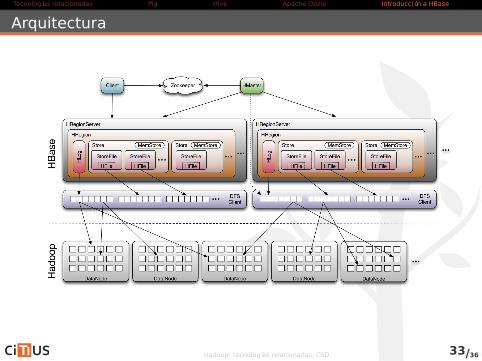
Conceptos HBase (III)
Regiones
. Las tablas se dividen por filas
. Cada división de denomina Region
Region Server
. Las regiones se distribuyen a servidores, denominados Region
servers. El HBase Master distribuye las regiones entre los Region servers
- Un Region server puede almacenar múltiples regiones
- Habitualmente, los Region servers se colocan en los
Datanodes- Usa Apache ZooKeeper para localizar las regiones
ZooKeeper
. servicio centralizado para mantener información de configuración,
nombrado, proporcionando sincronización distribuida y servicios de
grupos
. En HBase mantiene información sobre quién es el máster, las
regiones participantes y donde está la tabla ROOT (permite acceder
a las diferentes regiones)
Hadoop: tecnologías relacionadas, CSD 32/36
Tecnologías relacionadas Pig Hive Apache Oozie Introducción a HBase
Arquitectura
Hadoop: tecnologías relacionadas, CSD 33/36

Tecnologías relacionadas Pig Hive Apache Oozie Introducción a HBase
Almacenamiento físico
Las modificaciones en la tabla se almacenan en memoria en una
estructura llamada MemStore
Los cambios se escriben también en un Write Ahead Log (WAL,
también conocido como HLog) para recuperación en caso de fallo
Hay un MemStore por Column family
Cuando alcanza un cierto tamaño, el MemStore se vuelca a disco
creando un nuevo StoreFile (HFile)
HFiles
Almacenamiento subyacente para HBase
Cada HFile tiene datos de una sola Column family
Una Column family puede estar distribuida en múltiples HFiles
. Los procesos de compactación unen HFiles de una misma Column
family
Hadoop: tecnologías relacionadas, CSD 34/36

Tecnologías relacionadas Pig Hive Apache Oozie Introducción a HBase
Operaciones básicas
Las operaciones básicas disponibles en HBase son
Put añade datos a una tabla
Delete borra datos de una tabla
. los datos se marcan como borrados
. el borrado real se hace en las compactaciones
Scan recupera un conjunto de celdas (o toda la tabla)
Get recupera una celda concreta
Dispone de un HBase shell y un API para diversos lenguajes
(principalmente Java)
Hadoop: tecnologías relacionadas, CSD 35/36

Tecnologías relacionadas Pig Hive Apache Oozie Introducción a HBase
Para saber más
Libros:
. Tom White, “Hadoop: The Definitive Guide”, O’Reilly, third ed. (May
26, 2012)
. Chuck Lam, “Hadoop in action”, Manning Publications, first ed.
(December 22, 2010)
. Alan Gates, “Programming Pig”, O’Reilly, first ed. (October 20, 2011)
. E. Capriolo, D. Wampler, J. Ruthergles, “Programming Hive”, O’Reilly,
first ed. (October 2012)
. L. George, “HBase: The Definitive Guide”, O’Reilly, first ed. (October
2011)
. N. Dimidik, A. Khurana, “HBase in Action”, Manning Publications, first
ed. (January 2013)
. A. Murthy, V. Vavilapalli, “Apache Hadoop YARN”, Addison-Wesley,
first ed. (March 2014)
Hadoop: tecnologías relacionadas, CSD 36/36