hadoop summit san diego feb2013
TRANSCRIPT

Hadoop Use Cases At Salesforce.com
Narayan Bharadwaj Director, Product Management
Monitoring & Big Data Salesforce.com
@nadubharadwaj

Safe harbor Safe harbor statement under the Private Securi8es Li8ga8on Reform Act of 1995:
This presenta8on may contain forward-‐looking statements that involve risks, uncertain8es, and assump8ons. If any such uncertain8es materialize or if any of the assump8ons proves incorrect, the results of salesforce.com, inc. could differ materially from the results expressed or implied by the forward-‐looking statements we make. All statements other than statements of historical fact could be deemed forward-‐looking, including any projec8ons of product or service availability, subscriber growth, earnings, revenues, or other financial items and any statements regarding strategies or plans of management for future opera8ons, statements of belief, any statements concerning new, planned, or upgraded services or technology developments and customer contracts or use of our services.
The risks and uncertain8es referred to above include – but are not limited to – risks associated with developing and delivering new func8onality for our service, new products and services, our new business model, our past opera8ng losses, possible fluctua8ons in our opera8ng results and rate of growth, interrup8ons or delays in our Web hos8ng, breach of our security measures, the outcome of intellectual property and other li8ga8on, risks associated with possible mergers and acquisi8ons, the immature market in which we operate, our rela8vely limited opera8ng history, our ability to expand, retain, and mo8vate our employees and manage our growth, new releases of our service and successful customer deployment, our limited history reselling non-‐salesforce.com products, and u8liza8on and selling to larger enterprise customers. Further informa8on on poten8al factors that could affect the financial results of salesforce.com, inc. is included in our annual report on Form 10-‐Q for the most recent fiscal quarter ended July 31, 2012. This documents and others containing important disclosures are available on the SEC Filings sec8on of the Investor Informa8on sec8on of our Web site.
Any unreleased services or features referenced in this or other presenta8ons, press releases or public statements are not currently available and may not be delivered on 8me or at all. Customers who purchase our services should make the purchase decisions based upon features that are currently available. Salesforce.com, inc. assumes no obliga8on and does not intend to update these forward-‐looking statements.

Agenda
• Technology • Big Data use cases • Use case discussion • Q&A

Got “Cloud Data”?
1 billion transac8ons/day Terabytes/day
130k customers Millions of users

Technology

Big Data Ecosystem
Phoenix Oozie

Phoenix “We put the SQL back in NoSQL”
• SQL layer on HBase
• Seamless applica8on integra8on – Standard JDBC interface – DDL statement support
• Low query latency – SQL query è Mul8ple HBase scans – Co-‐processors, custom filters – Milliseconds for small queries – Seconds for tens of millions rows
• hdps://github.com/forcedotcom/phoenix

Contribu8ons
@pRaShAnT1784 : Prashant Kommireddi
Lars Ho<ansl @thefutureian : Ian Varley

Apache Pig
Data Science tools ecosystem

Product Metrics User behavior analysis Capacity planning
Monitoring intelligence Collec8ons Query Run8me
Predic8on
Early Warning System
Collabora8ve Filtering Search Relevancy
Internal App Product feature
Big Data Use Cases

Product Metrics

• Track feature usage/adop8on across 130k+ customers – Eg: Accounts, Contacts, Visualforce, Apex,…
• Track standard metrics across all features – Eg: #Requests, #UniqueOrgs, #UniqueUsers, AvgResponseTime,…
• Track features and metrics across all channels – API, UI, Mobile
• Primary audience: Execu8ves, Product Managers
Product Metrics – Problem Statement

Feature Metrics (Custom Object)
Trend Metrics (Custom Object)
Client Machine
Pig script generator
Hadoop Log Files
Log Pu
ll
User Input (Page Layout) Reports, Dashboards
API
API
Workfl
ow
Form
ula
Fields
Java Program
CollaboraWon (ChaXer)
Workfl
ow
Product Metrics Pipeline

VisualizaWon (Reports & Dashboards)
Note: Feature Names are not displayed

VisualizaWon (Reports & Dashboards)
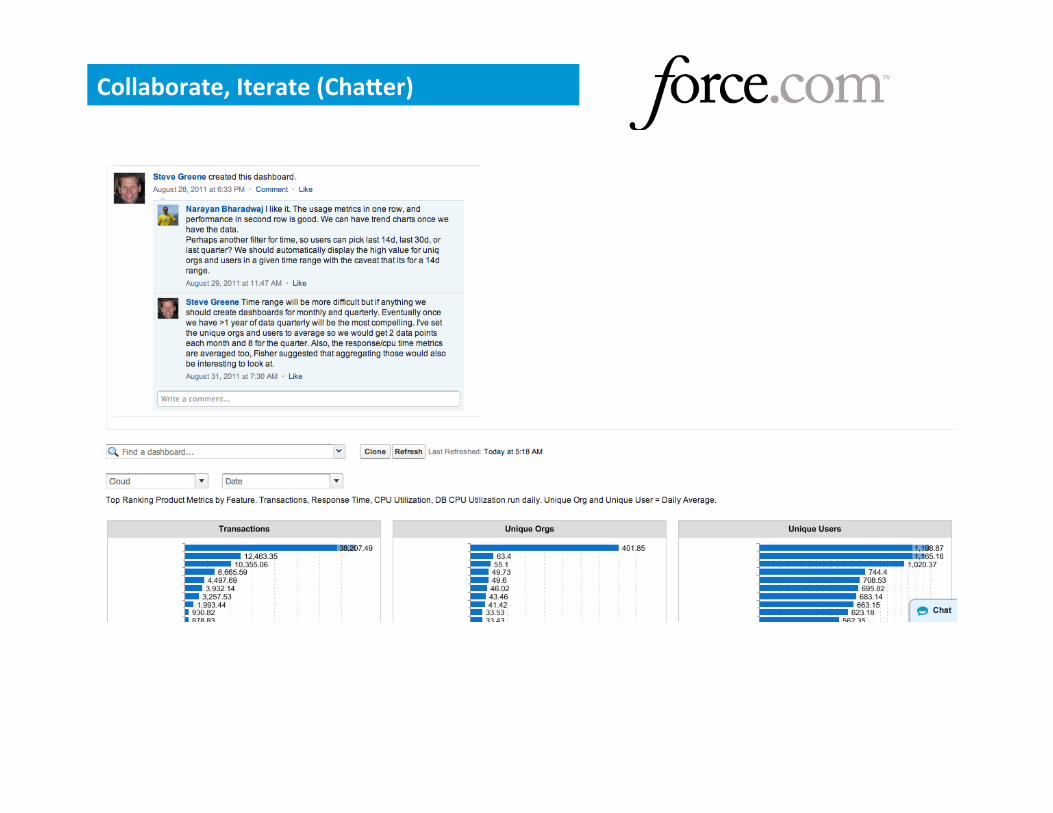
Collaborate, Iterate (ChaXer)

User Behavior Analysis

Problem Statement
§ How do we reduce number of clicks on the user interface? § What are the top user click path sequences? § What are the user clusters/personas?
• Approach: • Markov transi8on for click path, D3.js visuals • K-‐means (unsupervised) clustering for user groups

Markov TransiWons for "Setup" pages
Note: Based on an internal Salesforce org

K-‐means clustering of "Setup" pages
Note: Based on an internal Salesforce org

Collabora8ve Filtering

• Show similar files within an organiza8on – Content-‐based approach – Community-‐base approach
CollaboraWve Filtering – Problem Statement

Popular File

Related File

• Amazon published this algorithm in 2003. – Amazon.com RecommendaJons: Item-‐to-‐Item CollaboraJve Filtering, by
Gregory Linden, Brent Smith, and Jeremy York. IEEE Internet Compu8ng, January-‐February 2003.
• At Salesforce, we adapted this algorithm for Hadoop, and we use it to recommend files to view and users to follow.
We found this relaWonship using item-‐to-‐item collaboraWve filtering

Annual Report Vision Statement
Dilbert Comic Darth Vader Cartoon
Disk Usage Report
Example: CF on 5 files

Annual Report
Vision Statement
Dilbert Cartoon
Darth Vader Cartoon
Disk Usage Report
Miranda (CEO) 1 1 1 0 0
Bob (CFO) 1 1 1 0 0
Susan (Sales) 0 1 1 1 0
Chun (Sales) 0 0 1 1 0
Alice (IT) 0 0 1 1 1
View History Table

Annual Report
Disk Usage Report
Darth Vader Cartoon
Dilbert Cartoon
Vision Statement
RelaWonships between the files

Annual Report
Disk Usage Report
Darth Vader Cartoon
Dilbert Cartoon
Vision Statement 2
2
0
0
31
0
3
1 1
RelaWonships between the files

Annual Report
Vision Statement
Dilbert Cartoon
Darth Vader Cartoon
Disk Usage Report
Dilbert (2) Dilbert (3) Vision Stmt. (3) Dilbert (3) Dilbert (1)
Vision Stmt. (2) Annual Rpt. (2) Darth Vader (3) Vision Stmt. (1) Darth Vader (1)
Darth Vader (1) Annual Rpt. (2) Disk Usage (1)
Disk Usage (1)
The popularity problem: no8ce that Dilbert appears first in every list. This is probably not what we want.
The solu8on: divide the relaWonship tallies by file populariWes.
Sorted relaWonships for each file
Annual Report
Disk Usage Report
Darth Vader Cartoon
Dilbert Cartoon
Vision Statement .82
.63 0
0
.77 .33
0
.77
.45 .58
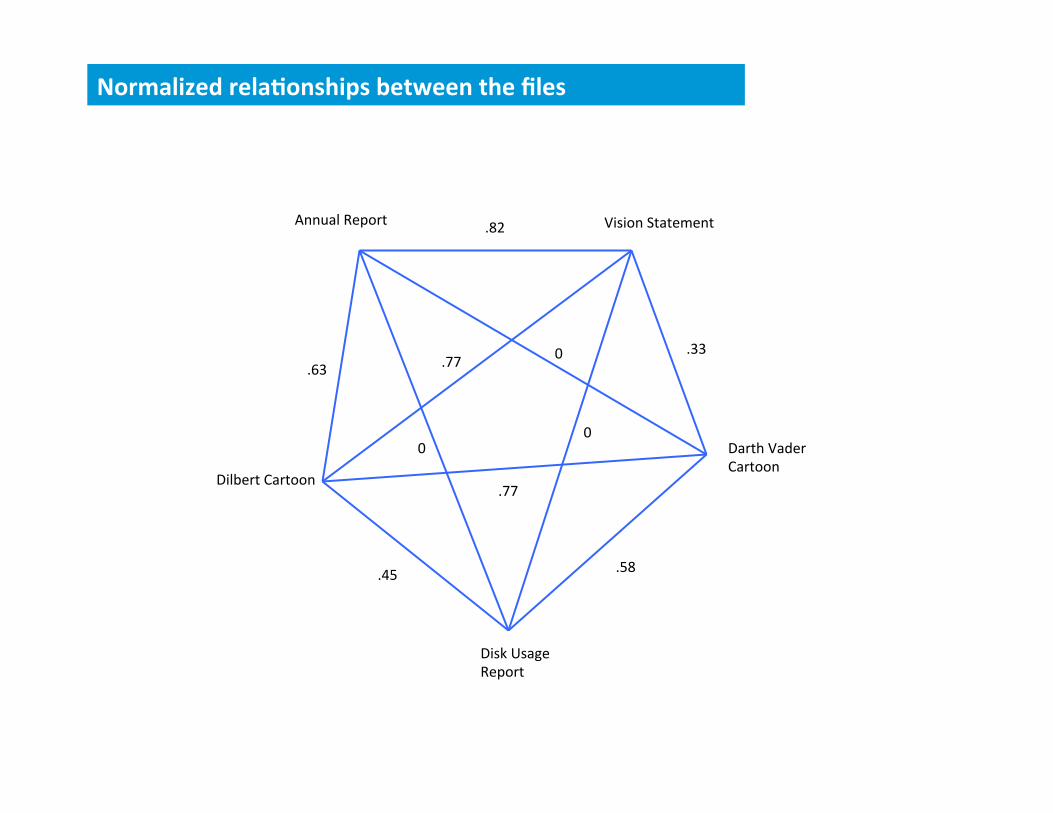
Normalized relaWonships between the files

Annual Report
Vision Statement
Dilbert Cartoon
Darth Vader Cartoon
Disk Usage Report
Vision Stmt. (.82)
Annual Report (.82)
Darth Vader (.77) Dilbert (.77) Darth Vader
(.58)
Dilbert (.63) Dilbert (.77) Vision Stmt. (.77)
Disk Usage (.58)
Dilbert (.45)
Darth Vader (.33)
Annual Report (.63)
Vision Stmt. (.33)
Disk Usage (.45)
High rela8onship tallies AND similar popularity values now drive closeness.
Sorted relaWonships for each file, normalized by file populariWes

1) Compute file populari8es 2) Compute rela8onship tallies and divide by
file populari8es 3) Sort and store the results
The item-‐to-‐item CF algorithm

MapReduce Overview Map Shuffle Reduce
(adapted from hdp://code.google.com/p/mapreduce-‐framework/wiki/MapReduce)

<user, file>
Inverse iden8ty map
<file, List<user>>
Reduce
<file, (user count)>
Result is a table of (file, popularity) pairs that you store in the Hadoop distributed cache.
1. Compute File PopulariWes
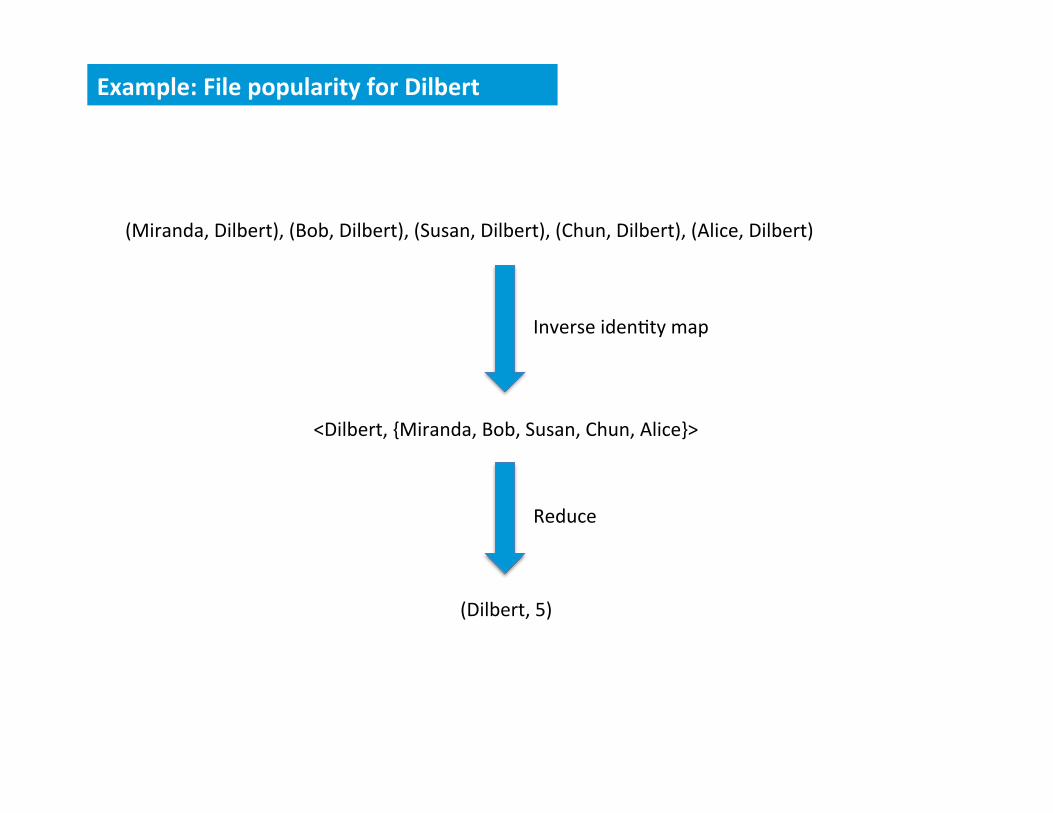
(Miranda, Dilbert), (Bob, Dilbert), (Susan, Dilbert), (Chun, Dilbert), (Alice, Dilbert)
Inverse iden8ty map
<Dilbert, {Miranda, Bob, Susan, Chun, Alice}>
Reduce
(Dilbert, 5)
Example: File popularity for Dilbert

<user, file>
Iden8ty map
<user, List<file>>
Reduce
<(file1, file2), Integer(1)>, <(file1, file3), Integer(1)>, … <(file(n-‐1), file(n)), Integer(1)>
Rela8onships have their file IDs in alphabe8cal order to avoid double coun8ng.
2a. Compute relaWonship tallies -‐ find all relaWonships in view history table

(Miranda, Annual Report), (Miranda, Vision Statement), (Miranda, Dilbert)
Iden8ty map
<Miranda, {Annual Report, Vision Statement, Dilbert}>
Reduce
<(Annual Report, Dilbert), Integer(1)>, <(Annual Report, Vision Statement), Integer(1)>, <(Dilbert, Vision Statement), Integer(1)>
Example 2a: Miranda’s (CEO) file relaWonship votes

<(file1, file2), Integer(1)>
<(file1, file2), List<Integer(1)>
Iden8ty map
Reduce: count and divide by populari8es
<file1, (file2, similarity score)>, <file2, (file1, similarity score)>
Note that we emit each result twice, one for each file that belongs to a rela8onship.
2b. Tally the relaWonship votes -‐ just a word count, where each relaWonship occurrence is a word

<(Dilbert, Vader), Integer(1)>, <(Dilbert, Vader), Integer(1)>, <(Dilbert, Vader), Integer(1)>
<(Dilbert, Vader), {1, 1, 1}>
Iden8ty map
Reduce: count and divide by populari8es
<Dilbert, (Vader, sqrt(3/5))>, <Vader, (Dilbert, sqrt(3/5))>
Example 2b: the Dilbert/Darth Vader relaWonship

<file1, (file2, similarity score)>
Iden8ty map
<file1, List<(file2, similarity score)>>
Reduce
<file1, {top n similar files}>
Store the results in your loca8on of choice
3. Sort and store results

<Dilbert, (Annual Report, .63)>, <Dilbert, (Vision Statement, .77)>, <Dilbert, (Disk Usage, .45)>, <Dilbert, (Darth Vader, .77)>
Iden8ty map
<Dilbert, {(Annual Report, .63), (Vision Statement, .77), (Disk Usage, .45), (Darth Vader, .77)}>
Reduce
<Dilbert, {Darth Vader, Vision Statement}> (Top 2 files)
Store results
Example 3: SorWng the results for Dilbert

• Cosine formula and normaliza8on trick to avoid the distributed cache
• Mahout has CF • Asympto8c order of the algorithm is O(M*N2) in worst case, but is helped by sparsity. €
cosθAB =A • BA B
=AA
•BB
Appendix

Narayan Bharadwaj Monitoring, Big Data @salesforce
@nadubharadwaj
