hadoop, spark, flink, and beam should care - oracle.com · apache spark summary • 2009: amplab...
TRANSCRIPT


Copyright © 2017, Oracle and/or its affiliates. All rights reserved. |
Hadoop, Spark, Flink, and Beam Explained to Oracle DBAs: Why They Should Care
Kuassi Mensah Jean De Lavarene Director Product Mgmt Director Development Server Technologies October 04, 2017

Copyright © 2017, Oracle and/or its affiliates. All rights reserved. |
Safe Harbor Statement
The following is intended to outline our general product direction. It is intended for information purposes only, and may not be incorporated into any contract. It is not a commitment to deliver any material, code, or functionality, and should not be relied upon in making purchasing decisions. The development, release, and timing of any features or functionality described for Oracle’s products remains at the sole discretion of Oracle.
3

Copyright © 2017, Oracle and/or its affiliates. All rights reserved. |
Speaker Bio - Kuassi Mensah
• Director of Product Management at Oracle
(i) Java integration with the Oracle database (JDBC, UCP, Java in the database)
(ii) Oracle Datasource for Hadoop (OD4H), upcoming OD for Spark, OD for Flink and so on
(iii) JavaScript/Nashorn integration with the Oracle database (DB access, JS stored proc, fluent JS )
• MS CS from the Programming Institute of the University of Paris VI
• Frequent speaker JavaOne, Oracle Open World, Data Summit, Node Summit, Oracle User groups (UKOUG, DOAG,OUGN, BGOUG, OUGF, GUOB, ArOUG, ORAMEX, Sangam,OTNYathra, China, Thailand, etc),
• Author: Oracle Database Programming using Java and Web Services
• @kmensah, http://db360.blogspot.com/, https://www.linkedin.com/in/kmensah
4

Copyright © 2017, Oracle and/or its affiliates. All rights reserved. |
Speaker Bio – Jean de Lavarene
• Director of Product Development at Oracle
(i) Java integration with the Oracle database (JDBC, UCP)
(ii) Oracle Datasource for Hadoop (OD4H), upcoming OD for Spark, OD for Flink and so on
• MS CS from Ecole des Mines, Paris
• https://www.linkedin.com/in/jean-de-lavarene-707b8
5

Copyright © 2017, Oracle and/or its affiliates. All rights reserved. |
Program Agenda
From Big Data to Fast Data
Apache Hadoop
Apache Spark
Apache Flink
Apache Beam
Why Should Oracle DBA Care
1
2
3
4
5
6
6

Copyright © 2017, Oracle and/or its affiliates. All rights reserved. |
Program Agenda
From Big Data to Fast Data
Apache Hadoop
Apache Spark
Apache Flink
Apache Beam
Why Should Oracle DBA Care
1
2
3
4
5
7
6

Copyright © 2017, Oracle and/or its affiliates. All rights reserved. |
Data at Rest
• Big Data analysis
– Parallel batch processing: Map/Reduce
• Exponential growth of data volume
– Projection • 44 Zetabytes (44 trillion GB) of data in the digital universe by 2020
• Every online user will generate ~1.7 MB of new data per second
– Need massive-scale infrastructure in the Cloud or on-premise
• Google Search: 40,000+ search queries per second
8

Copyright © 2017, Oracle and/or its affiliates. All rights reserved. |
Fast Data – Streaming Data
• Business shift from reactive to proactive interactions
– Need to process data as it enters the system
– How fast can you analyze your data and gain insights?
• Fast data – Unbound data, continuous flows of events
• Need new processing model: stream processing of unbound data
– New processing frameworks: Spark streaming, Flink, Beam, …
9

Copyright © 2017, Oracle and/or its affiliates. All rights reserved. |
Streaming Data Processing: What, Where When, How?
• What results are calculated? transformations within the pipeline: sums, histograms, ML models
• Where in the event time are results calculated? event-time windowing within the pipeline
• When in processing time are results materialized? the use of watermarks and triggers
• How do refinements of results relate? type of accumulation used: discarding, accumulating & retracting
Read more @ https://www.oreilly.com/ideas/the-world-beyond-batch-streaming-102
10

Copyright © 2017, Oracle and/or its affiliates. All rights reserved. |
Streaming Data Processing Concepts
Stream processing: analyze a fragment/window of data stream • Windowing: Fixed/tumbling, Sliding, Session • Low Latency: Sub-second • Timestamp: Event-time, Ingestion time, Processing time -- cf Star Wars • Watermark: When a window is considered done (completeness with respect to event times)
• In-order processing , Out-of-order processing • Punctuation: segment a stream into tuples, control signal for operators • Triggers: When to materialize the output of the computation
watermark | event time| processing time| punctuations
• Accumulation: disjointed or overlapping results observed for the same window • Delivery guarantee: at least once, exactly once, end to end exactly once (guarantee) • Event prioritization • Backpressure support
11

Copyright © 2017, Oracle and/or its affiliates. All rights reserved. |
Program Agenda
From Big Data to Fast Data
Apache Hadoop
Apache Spark
Apache Flink
Apache Beam
Why Should Oracle DBA Care
1
2
3
4
5
13
6

Copyright © 2017, Oracle and/or its affiliates. All rights reserved. |
Apache Hadoop 1.0
First Open-source MapReduce framework & ecosystem
• Processing model: batch
• 2004: HDFS + MapReduce (Python)
• 2006: Apache Hadoop (Java)
• 2009: 1 TB Sort in 209 sec
• 2010: 100TB sort in 173 min
• 2014: 100TB sort in 72 min
15
Reducers
intermediate data
Hadoop Cluster (e.g., Big Data Appliance)
Cluster Nodes
Mappers Cluster Nodes
Copyright © 2017, Oracle and/or its affiliates. All rights reserved. |
Data HCatalog,
InputFormat, StorageHandler
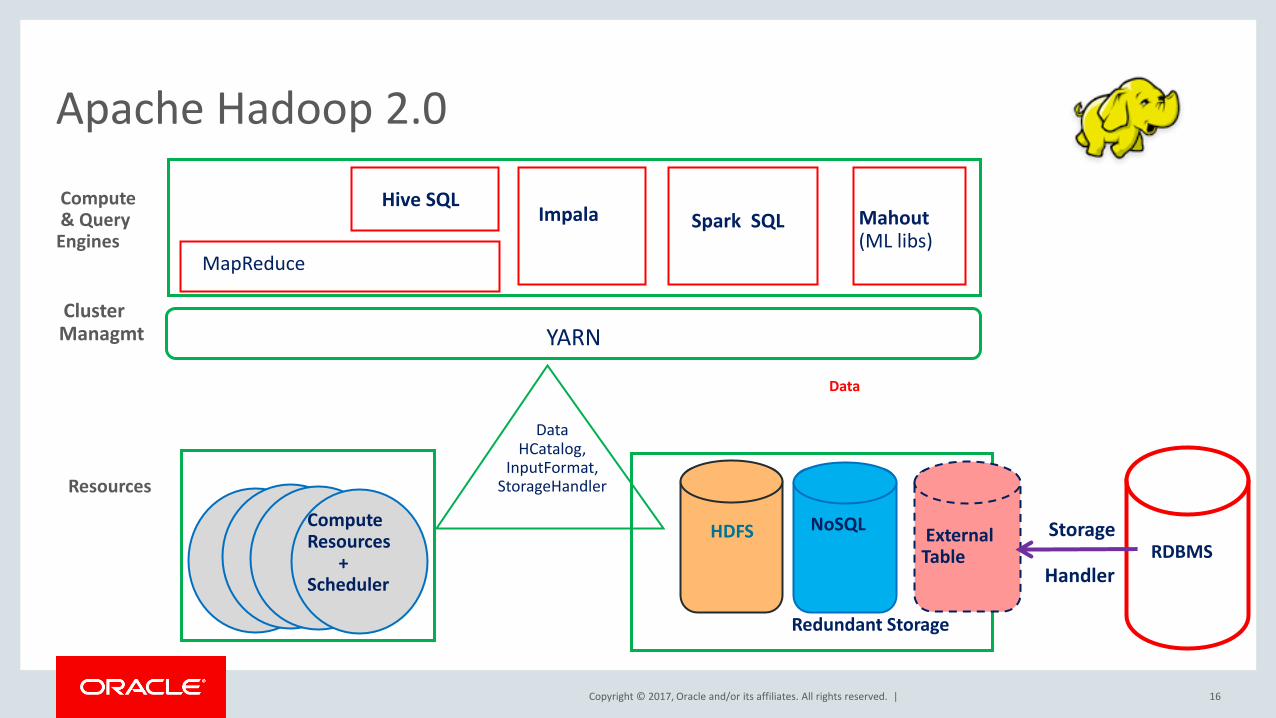
Apache Hadoop 2.0
YARN
HDFS
NoSQL
Redundant Storage
MapReduce
Hive SQL Spark SQL Impala
External Table
RDBMS
Storage Handler
Mahout (ML libs)
Compute Resources + Scheduler
Compute & Query Engines
Cluster Managmt
Resources
Data
16

Copyright © 2017, Oracle and/or its affiliates. All rights reserved. |
Oracle Datasource for Hadoop (OD4H) Turn Oracle database tables into Hadoo Datasources
17 H
Catalo
g
StorageH
and
ler
Inp
utFo
rmat
Table
JDBC
• Direct, parallel, fast, secure and consistent access to Oracle database
• Logical partitioning of the database tables
• Join Big Data and Master Data
• Write back to Oracle

Copyright © 2017, Oracle and/or its affiliates. All rights reserved. |
Hadoop: Real-World Use Cases
• Airbus Uses Big Data Appliance to Improve Flight Testing
• BAE Systems Choose Big Data Appliance for Critical Projects
• AMBEV chose Oracle’s Big Data Cloud Service to expedite their database integration needs.
• Big Data Discovery Helps CERN Understand the Universe
• See more use cases @ http://bit.ly/1Oz2jCF
18

Copyright © 2017, Oracle and/or its affiliates. All rights reserved. |
Hadoop: Strengths & Limitations
• Strengths - Good for batch processing of data-at-rest i.e., Association Rules Mining - Inexpensive disk storage -> can handle enormous datasets
• Limitations: - Limited to batch processing: not suitable for streaming data processing
- Static partitioning - Materialization on each job step - Complex processing requires multi-staging - Disk-based operations prevents data sharing for interactive ad-hoc queries
19

Copyright © 2017, Oracle and/or its affiliates. All rights reserved. |
Program Agenda
From Big Data to Fast Data
Apache Hadoop
Apache Spark
Apache Flink
Apache Beam
Why Should Oracle DBA Care
1
2
3
20
4
5
6

Copyright © 2017, Oracle and/or its affiliates. All rights reserved. |
Apache Spark Summary
• 2009: AMPLab -> based on micro batching; for batch and streaming proc.
• Sort 100 TB 3X faster than Hadoop MapReduce on 1/10th platform
• RDD: fault tolerance abstraction for in-memory data sharing. Pair RDDs as key/value pairs
• Spark Streaming: for real-time streaming data processing
• DataSource API: over Avro, JSON, CSV, Parquet and JDBC (built in Hive)
• Dataframe: high level concept on top of RDD; equivalent to a table
• Spark Applications: RDD or DataFrame or ML APIs in Scala, Python, Java
• Spark Shell: interactive command line for Scala & Python
• Spark SQL: Relational processing, operates on data sources thru the dataframe interface.
21

Copyright © 2017, Oracle and/or its affiliates. All rights reserved. |
Apache Spark - Core Architecture
22
Spark Core
Cluster Manager/Scheduler: Mesos or YARN or Standalone
Spark SQL Spark Streaming
MLib GraphX
DataFrame API
Data Source API
RDBMS

Copyright © 2017, Oracle and/or its affiliates. All rights reserved. |
Spark Core Architecture
23

Copyright © 2017, Oracle and/or its affiliates. All rights reserved. |
How Apache Spark Works
• Create a dataset from external data, then apply parallel operations to it; all work expressed as - transformations : creating new RDDs, or transforming existing RDDs - actions: calling operations on RDDs
• Execution plan as a Directed Acyclic Graph (DAG) of operations
• Every Spark program and shell session work as follows 0. Spark Context: main entry point in Spark APIs 1. Create some input RDDs from external data. 2. Transform them to define new RDDs using transformations like filter(). 3. Ask Spark to persist any intermediate RDDs that will need to be reused. 4. Launch actions such as count() and first() to kick off a parallel computation, which are optimized and executed by Spark executor.
24
Copyright © 2017, Oracle and/or its affiliates. All rights reserved. |
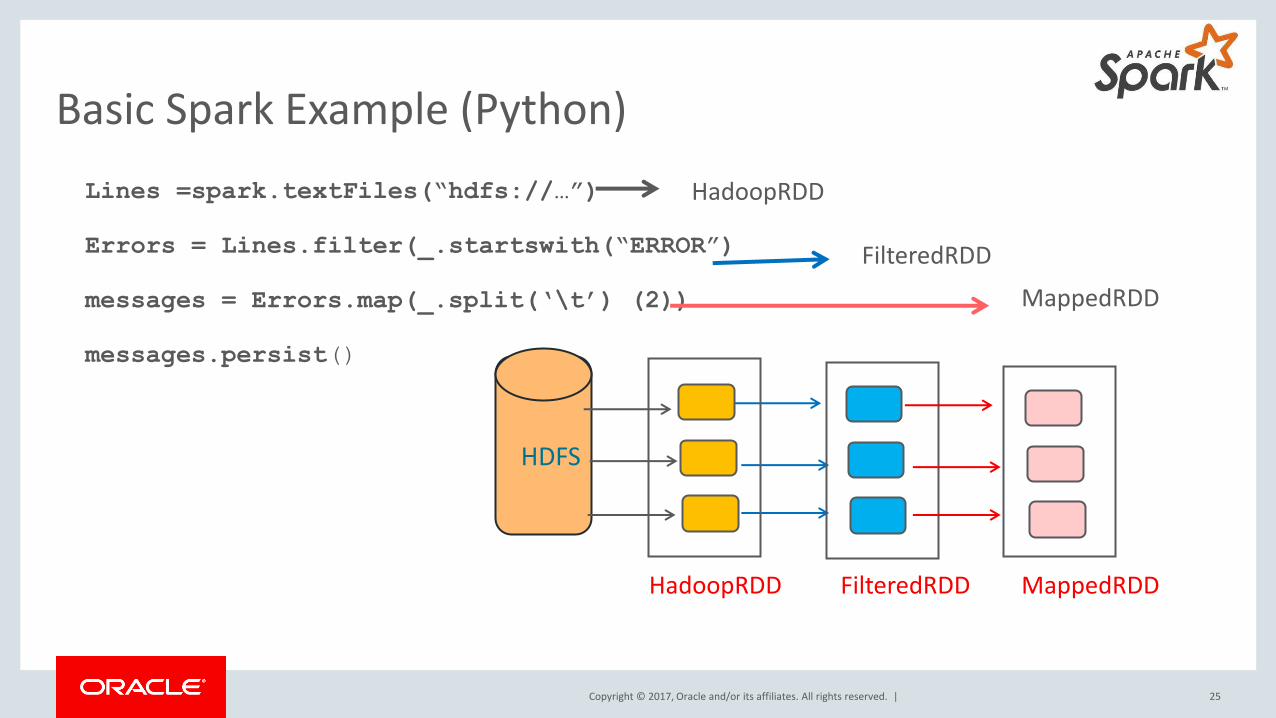
Basic Spark Example (Python)
25
Lines =spark.textFiles(“hdfs://…”)
Errors = Lines.filter(_.startswith(“ERROR”)
messages = Errors.map(_.split(‘\t’) (2))
messages.persist()
HadoopRDD
FilteredRDD
MappedRDD
HadoopRDD FilteredRDD MappedRDD
HDFS

Copyright © 2017, Oracle and/or its affiliates. All rights reserved. |
Spark Workflow
Worker Node
Executor
Cache
Task Task
Worker Node
Executor
Cache
Task Task
Cluster Manager
(Task Scheduler)
Mesos or
YARN or
Standalone
Data Node
Data Node
Spark Driver
Executes User
Application
Spark Context
RDD Objects
DAG
operator
DAG Scheduler (what to run ,
split graph into tasks )
TaskSet
26

Copyright © 2017, Oracle and/or its affiliates. All rights reserved. |
Spark Real World Use Cases
• More than 1000 organizations are using Spark in production
• The largest known Spark cluster has 8000 nodes
• Security, finance: fraud/intrusion detection, risk-based authentication
• Log processing, BI/reporting/ETL
• Mobile usage patterns analysis
• Predictive analytics, data exploration
• Game industry: real-time discovering of patterns in-game events
• e-Commerce: real-time Tx using streaming clustering algorithms
• And so on!
27

Copyright © 2017, Oracle and/or its affiliates. All rights reserved. |
Spark Strengths and Limitations
• Strengths - Speed: in-memory processing (RDD allow in-memory data sharing) - High throughput - Correct under stress: strongly consistent - Supports event processing-time (in-order processing) - Spark Streaming: sub-second buffering increments
• Limitations - Latency of micro-batch (batch first) - Inability to fit windows to naturally occurring events - Supports only tumbling/sliding windows - No event-time windowing (out-of-order processing) - No watermarks support - Triggers: at the end of the window only with Spark
28

Copyright © 2017, Oracle and/or its affiliates. All rights reserved. |
Program Agenda
From Big Data to Fast Data
Apache Hadoop
Apache Spark
Apache Flink
Apache Beam
Why Should Oracle DBA Care
1
2
3
29
4
5
6

Copyright © 2017, Oracle and/or its affiliates. All rights reserved. |
Apache Flink
• 2009: real time, high performance, very low latency streaming
• Single runtime for both streaming and batch processing
• Continuous flow: processes data when it comes
• Pipelined execution is faster
• Batch on bounded stream (special case)
• Correct state upon failure; correct time/window semantics
• Supports Event-Time and Out-of-Order Events
• Own Memory management; no reliance on JVM GC -> no spike
30
Copyright © 2017, Oracle and/or its affiliates. All rights reserved. |
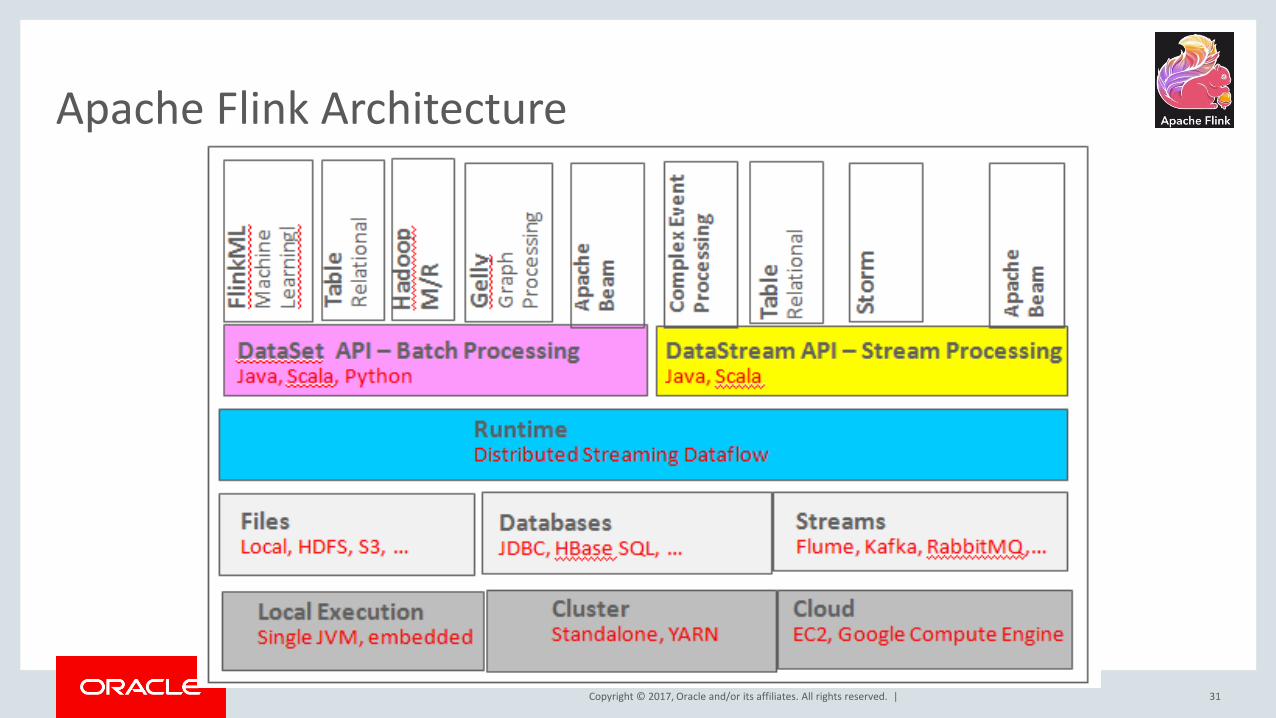
Apache Flink Architecture
31

Copyright © 2017, Oracle and/or its affiliates. All rights reserved. |
Apache Flink Application and Dataflow
33
http://bit.ly/2tCWqlr
Copyright © 2017, Oracle and/or its affiliates. All rights reserved. |
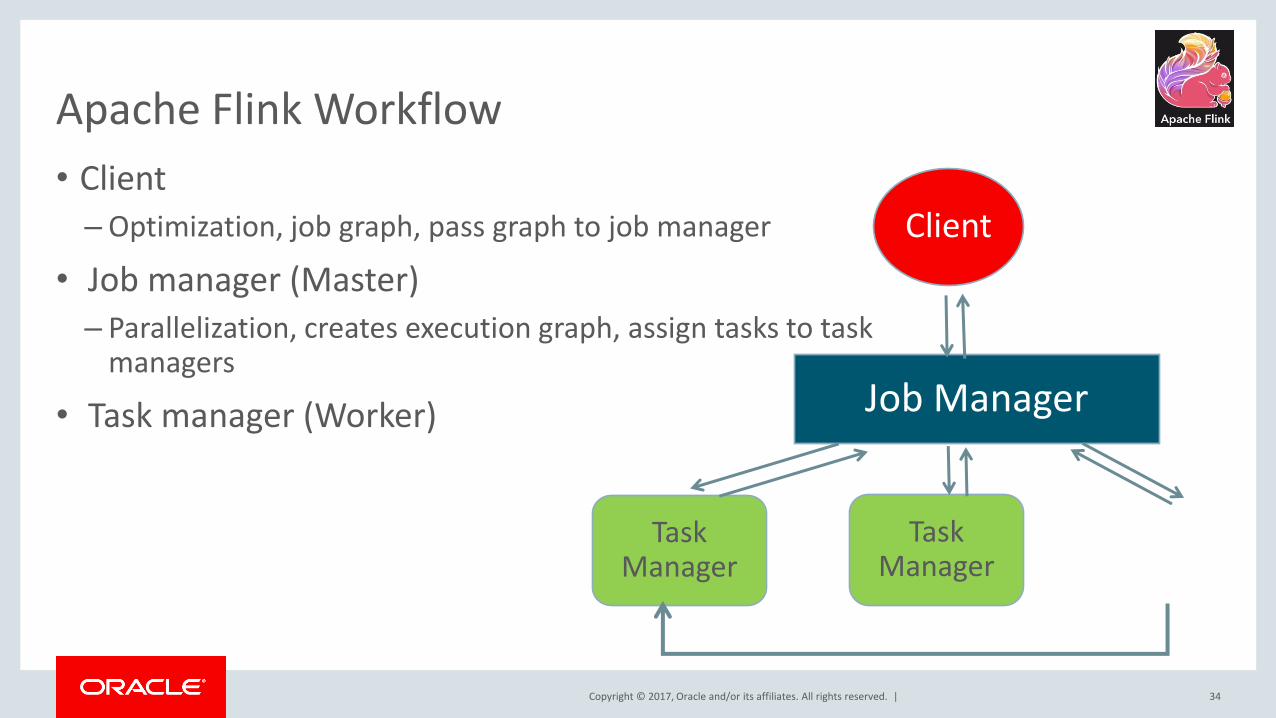
Apache Flink Workflow
• Client
– Optimization, job graph, pass graph to job manager
• Job manager (Master)
– Parallelization, creates execution graph, assign tasks to task managers
• Task manager (Worker)
34
Client
Job Manager
Task Manager
Task Manager

Copyright © 2017, Oracle and/or its affiliates. All rights reserved. |
Apache Flink Real World Use Cases
• Advertizing: real-time one/one targetting
• Financial Services: real-time fraud detection
• Retail: smart logistics, real-time monitoring of items and delivery
• Healthcare: smart hospitals, biometrics
• Telecom: real-time service optimization and billing based on location and usage
• Oil and Gaz: real-time monitoring of rigs and pumps
35

Copyright © 2017, Oracle and/or its affiliates. All rights reserved. |
Flink Strengths and Limitations
• Strengths
– Stream-first: low latency, high throughput
– own memory management no reliance on JVM GC
– Self-driven
• Limitations
– Maturity
– Little large scale deployments
36

Copyright © 2017, Oracle and/or its affiliates. All rights reserved. |
Program Agenda
From Big Data to Fast Data
Apache Hadoop
Apache Spark
Apache Flink
Apache Beam
Why Should Oracle DBA Care
1
2
3
37
4
5
6

Copyright © 2017, Oracle and/or its affiliates. All rights reserved. |
Beam Model: Portability Across Big Data Engines Courtesy Google Next’ 17 “Portable and Parallel Data Processing”
38
Language B SDK
(Python soon)
The Beam Model
Runner 1 Apache Spark
Runner 2 Apache Flink
Runner 3 Google Cloud
Dataflow
Language A SDK
(Java)
Language C SDK
(TBD)
‒ Beam API & Prog Model
‒ Languages: Java, Python
‒ Engine: Spark, Flink, Dataflow, Apex
‒ Deployment : Cloud or on-prem

Copyright © 2017, Oracle and/or its affiliates. All rights reserved. |
Apache Beam Eco-system
39
https://data-artisans.com/blog/why-apache-beam

Copyright © 2017, Oracle and/or its affiliates. All rights reserved. |
Program Agenda
From Big Data to Fast Data
Apache Hadoop
Apache Spark
Apache Flink
Apache Beam
Why Should Oracle DBA Care
1
2
3
45
4
5
6

Copyright © 2017, Oracle and/or its affiliates. All rights reserved. |
The Oracle DBA’s Scope
46
NoSQL
MySQL
Other DBMS
Oracle
Copyright © 2017, Oracle and/or its affiliates. All rights reserved. |
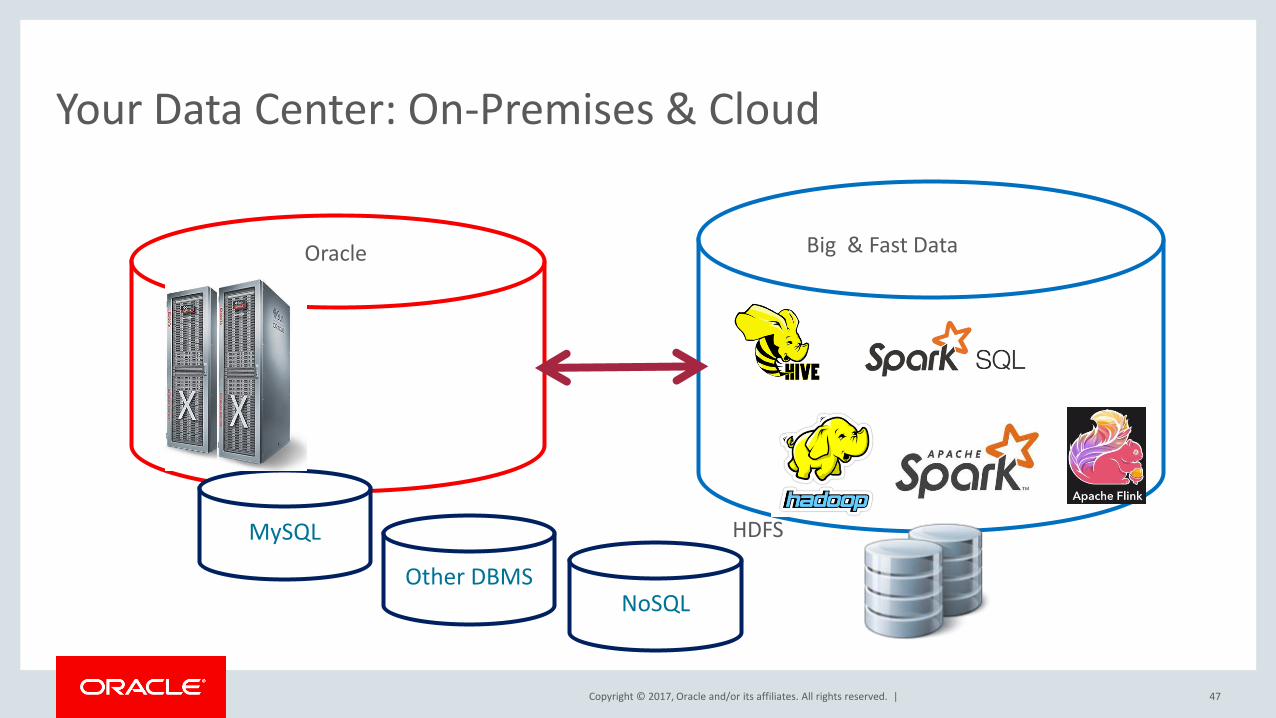
Your Data Center: On-Premises & Cloud
47
NoSQL
MySQL
Other DBMS
Oracle Big & Fast Data
HDFS

Copyright © 2017, Oracle and/or its affiliates. All rights reserved. |
NoSQL
MySQL
Other DBMS
Oracle Big Data
HDFS
48
Career Move – Expanding your Territory

Copyright © 2017, Oracle and/or its affiliates. All rights reserved. |
Career Move – Data Architect, Chief Data Officer
• Big Data Administrator, Data Architect – Manages the Big Data Clusters
– Monitors data and network traffic, prevents glitches
– Integrates, centralizes, protect s and maintains data sources
– Grants and revokes permissions to various clients and nodes.
• Chief Data Officer – Responsible for the overall data strategy within an organization
– Accountable for whatever data is collected, stored, shared, sold or analyzed as well as how the data is collected, stored, shared, sold or analyze
– Ensures that the data is implemented correctly, securely and comply with customers’ privacy, data privacy, government and ethical policies
– Defines company standards and policies for data operation, data accountability, and data quality
49

Copyright © 2017, Oracle and/or its affiliates. All rights reserved. |
Roadmap to Big Data Architect and Chief Data Officer
• Get your hands on Big Data platform, Cloud services or VMs e.g., Oracle BDALite Vbox, Oracle Big Data Cloud Services, Oracle BDA
• Leverage your Oracle background and notions: clusters, nodes, Oracle SQL (Big Data SQL), Big Data Connectors (e.g., Oracle Datasource for Hadoop)
• Get familiar with Big Data databases & storages: HDFS, NoSQL, DBMSes
• Get familiar with key Big Data Frameworks: Hadoop, Spark, Flink, Beam, streaming frameworks (Kafka, Storm), and their integration with Oracle (OD4H, OD4S, and so on)
• Get familiar with Big Data tools and programming: Hive SQL, Spark SQL, visualization tools, R, Java, Scala, and so on
• Read, Practice and Get involved in Big Data projects
50

Copyright © 2017, Oracle and/or its affiliates. All rights reserved. |
Key Takeaways
• Big Data is growing exponentially
• This is the era of Fast Data requiring new processing models
• Hadoop is good for some use cases but cannot handle streaming data
• Spark brings in-memory processing and data abstraction (RDD, etc) and allows real-time processing of streaming data however its micro batch architecture incurs high latency
• Flink brings low latency and promise to address Spark limitations
• DBA should embrace Big Data frameworks and expand their skills and coverage within the data center or in the Cloud.
51

Copyright © 2017, Oracle and/or its affiliates. All rights reserved. |
Resources
• Apache Projects http://hadoop.apache.org/ http://spark.apache.org/ http://flink.apache.org/ https://beam.apache.org/
• Big Data in the Cloud, Big Data Compute Edition https://cloud.oracle.com/en_US/big-data https://cloud.oracle.com/en_US/big-data-compute-edition
• Big Data Connectors https://www.oracle.com/database/big-data-connectors/index.html
52

Copyright © 2017, Oracle and/or its affiliates. All rights reserved. | 53
