hadoop online training by keylabs
TRANSCRIPT

BIG DATA &
HANDLING BIG DATA THROUGH HADOOP
Presented by
Contact us : +1-908-366-7933(USA), : +91-95506-45679(IND).
Email Id : [email protected]

OVERVIEW
Big data. Challenges/problems imposed my big data. Traditional methods vs Hadoop method. Conditions led to use Hadoop. Hadoop design and working. Advantages and Disadvantages of Hadoop. Conclusion / Future work
www.keylabstraining.com Email Id :

What is big data ?
Why can’t we call normal data as big data ?
Where does big data come from?
www.keylabstraining.com Email Id :

Huge amount of Unstructured Data is called
as Big Data.
Normally data is stored in the form of tables
and columns, where as unstructured data it is
stored in logs.
www.keylabstraining.com Email Id :

Data coming from many resources
Social networking profile,activity,logging. Public web information. Data ware house appliances. Internet Archive Store etc…
Question is how much data is generated??
www.keylabstraining.com Email Id :

Few examples: social networking sites(Facebook)
Facebook has 500 terabytes of stored data and
ingest 20TB data daily.
Flights
An average a Flight travelling for 30 minutes
produce 500 TB data
www.keylabstraining.com Email Id :

Electrical (power grid system)
power grid system generates huge amount
of unstructured data.
Business Organization( NYSE)
NYSE generates 1 TB data per day .
www.keylabstraining.com
Email Id : [email protected]

Characteristics of Big Data:
Volume
Variety
Velocity
complexity
www.keylabstraining.com Email Id :

Challenges of Big Data :
Storing huge amounts of data is never a problem
because technology has scaled up.
The main problem is how do we read the
data and analyze it.
Another major problem is to how we compute the data.
www.keylabstraining.com Email Id :
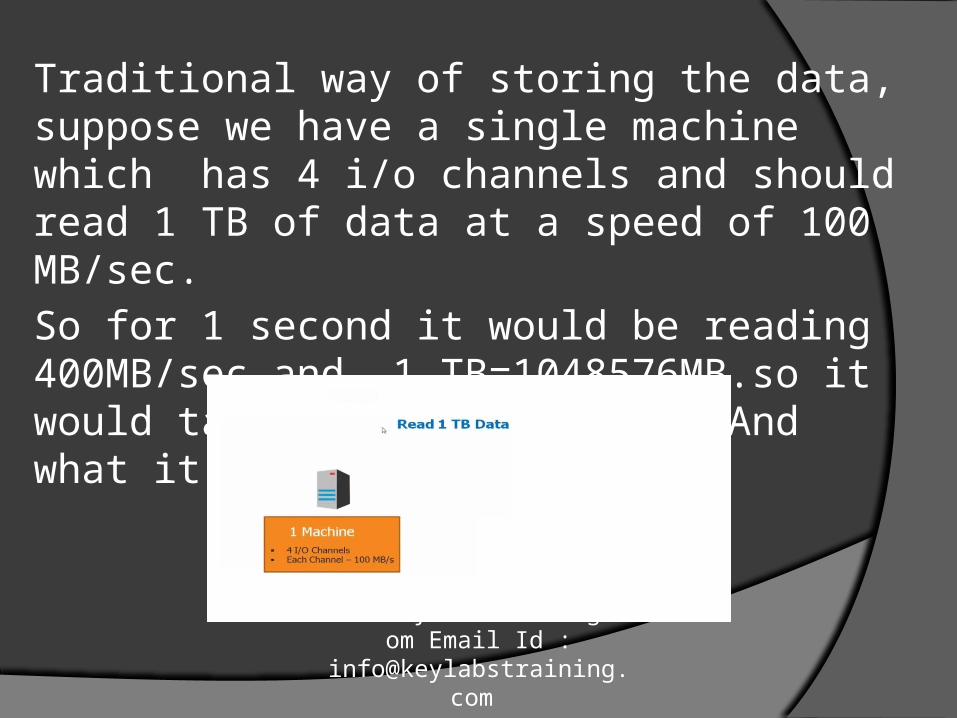
Traditional way of storing the data, suppose we have a single machine which has 4 i/o channels and should read 1 TB of data at a speed of 100 MB/sec.
So for 1 second it would be reading 400MB/sec and 1 TB=1048576MB.so it would take approximately 44. And what it would be for 500 TB.
www.keylabstraining.com Email Id :

DFS:
Distributed file system is nothing but storing the data in multiple machines , this immensely increases the I/O or read speed. Here we consider 10 machines rather one machine and distribute the data. Now it takes 4.5 minutes to read the data.
www.keylabstraining.com Email Id :

Traditional Approach
In Traditional Approach we move the data to master node and compute the data.
This takes a lot of time to compute the data and uses a lot of bandwidth for moving the data.
www.keylabstraining.com Email Id :

HDFS/ MAP REDUCE
In HDFS / MAP REDUCE we split the input data and we even the split the computation into small tasks and assign them to task tracker i.e map / Reduce .
The advantage here is instead of moving data we just move the computation program which is of 1 KB size to compute the data.
www.keylabstraining.com Email Id :

HADOOP :
Hadoop is a framework that allows for distributed processing of large data sets across clusters of commodity computers using a simple programming model ( map- reduce).
www.keylabstraining.com Email Id :

HADOOP Design is mainly based on
Store and parallel process large amounts of data in Terabytes and petabytes.
Compute should move to data. Failure is normal expected and can be
handled easily. Design runs on commodity Hardware
(cost effective ).
www.keylabstraining.com Email Id :
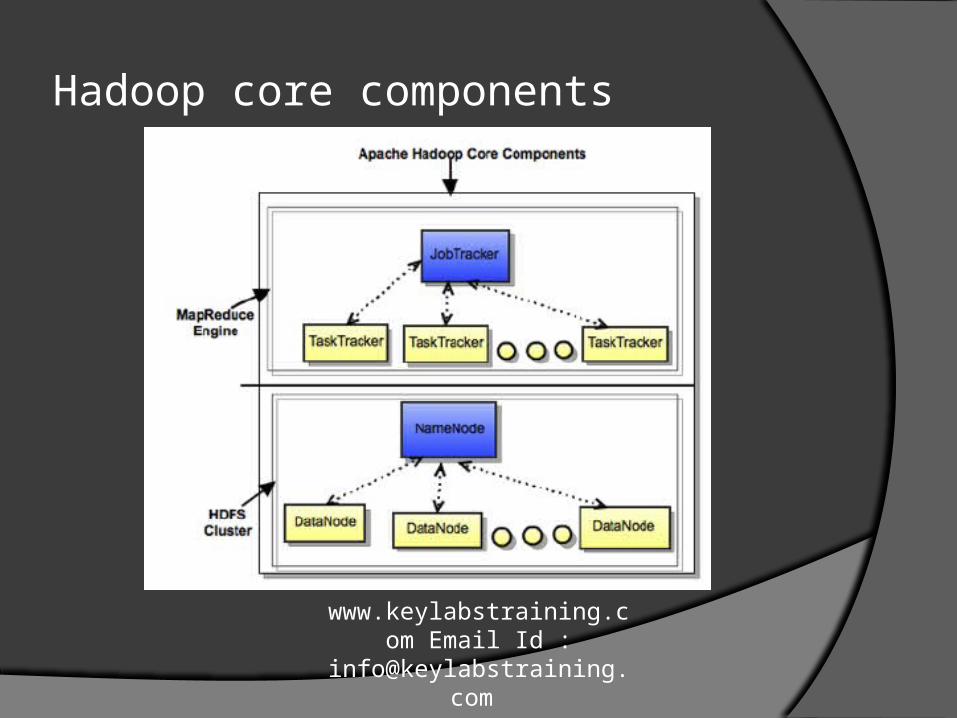

What is HDFS ?
Highly Fault tolerant systems.
Highly Throughput.
Suitable with large data sets.
Can be built of commodity hardware.
www.keylabstraining.com Email Id :
Name node :
master of the system, maintains and manages the block which are present on data nodes. Data node:
These are the actual storage of data. Serves read/write request for the clients.
www.keylabstraining.com Email Id :

JOB TRACKER/ TASK TRACKER
Job tracker is resided at the master node which divides the computation in to small computations and give them to task tracker which is the worker node.
The map reduce operations are done at the task tracker /worker node.
www.keylabstraining.com Email Id :

Working of Hadoop
In coming data Through different sources is distributed and stored in many thousands of commodity hardware.
When a client want to retrieve and analyze the data, He goes to the selected data node using name node / master node.
Then the computation is split in to various tasks by job tracker and map / reduce job are assigned to each task tracker
www.keylabstraining.com Email Id :

when should organization should move to big data and use Hadoop?
Very large data( more Tera bytes)
Where Hadoop is not good? Lots of small files Multiple writers and modifying frequently
www.keylabstraining.com Email Id :

Companies using Hadoop
Facebook Google Yahoo Amazon IBM LinkedIn
www.keylabstraining.com Email Id :

Advantages of Hadoop
Hadoop is an open source, a tool which provide distributed computation and storage.
Redundancy of data allows Hadoop to recover from single node failure.
Hadoop allows users to quickly write efficient parallel code. Hadoop's accessibility and simplicity give it an edge over writing and running large distributed programs. www.keylabstraining.com
Email Id : [email protected]

DISADVANTAGES
Hadoop is not applicable on small data sets because it imposes a lot of burden on name node to store a indexes for all data nodes.
Hadoop is not suitable for Online data Transactions.
www.keylabstraining.com Email Id :

Conclusion/ Future work
In present times Hadoop is one of the efficient methods to solve the problems imposed by Big data.
Currently Hadoop Team is working to improve its performance even with online transactions.
www.keylabstraining.com Email Id :

Thank You