hadoop map reduce concepts
TRANSCRIPT

MapReduce Concepts

Hadoop MapReduce• Hadoop MapReduce is a
– Software framework
– For easily writing applications
– Which process vast amounts of data (multi-terabyte data-sets)
– In-parallel on large clusters (thousands of nodes) of commodity hardware
– In a reliable, fault-tolerant manner.
• A MapReduce job usually splits the input data-set into independent chunks which are processed by the map tasks in a completely parallel manner.
• The framework sorts the outputs of the maps, which are then input to the reduce tasks.
• Typically both the input and the output of the job are stored in a file-system.
• The framework takes care of scheduling tasks, monitoring them and re-executes the failed tasks.

JobTracker and TaskTracker
• The MapReduce framework consists of a
– single master JobTracker and
– one slave TaskTracker per cluster-node.
• The master is responsible for scheduling the jobs' component - tasks on the slaves, monitoring them and re-executing the failed tasks.
• The slaves execute the tasks as directed by the master.
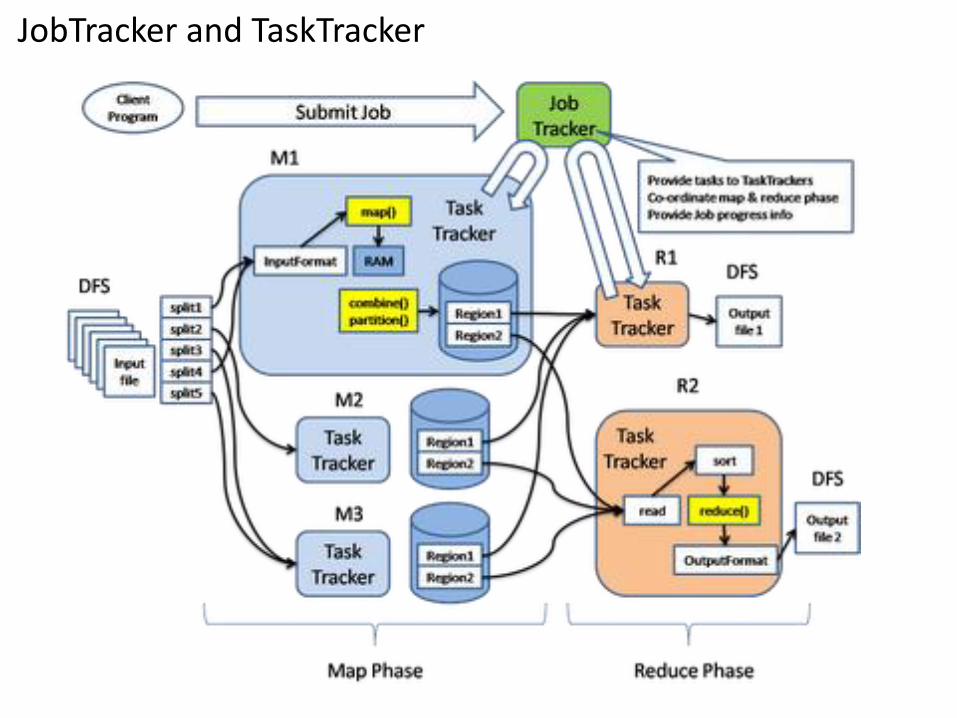
JobTracker and TaskTracker

Job Specification• Minimally, applications specify the input/output locations and
supply map and reduce functions via implementations of appropriate interfaces and/or abstract-classes.
• These, and other job parameters, comprise the job configuration.
• The Hadoop job client then submits the job (jar/executable etc.) and configuration to the JobTracker which then assumes the responsibility of distributing the software/configuration to the slaves, scheduling tasks and monitoring them, providing status and diagnostic information to the job-client.
• Although the Hadoop framework is implemented in JavaTM, MapReduceapplications need not be written in Java.
– Hadoop Streaming is a utility which allows users to create and run jobs with any executables (e.g. shell utilities) as the mapper and/or the reducer.
– Hadoop Pipes is a SWIG- compatible C++ API to implement MapReduceapplications (non JNITM based).

Input Output
• The MapReduce framework operates exclusively on <key, value> pairs.
• That is, the framework views the input to the job as a set of <key, value> pairs and produces a set of <key, value> pairs as the output of the job, conceivably of different types.
• The key and value classes have to be serializable by the framework and hence need to implement the Writable interface.
• Additionally, the key classes have to implement the WritableComparable interface to facilitate sorting by the framework.
• Input and Output types of a MapReduce job:– (input) <k1, v1> -> map -> <k2, v2> -> combine -> <k2, v2> -> reduce -
> <k3, v3> (output)
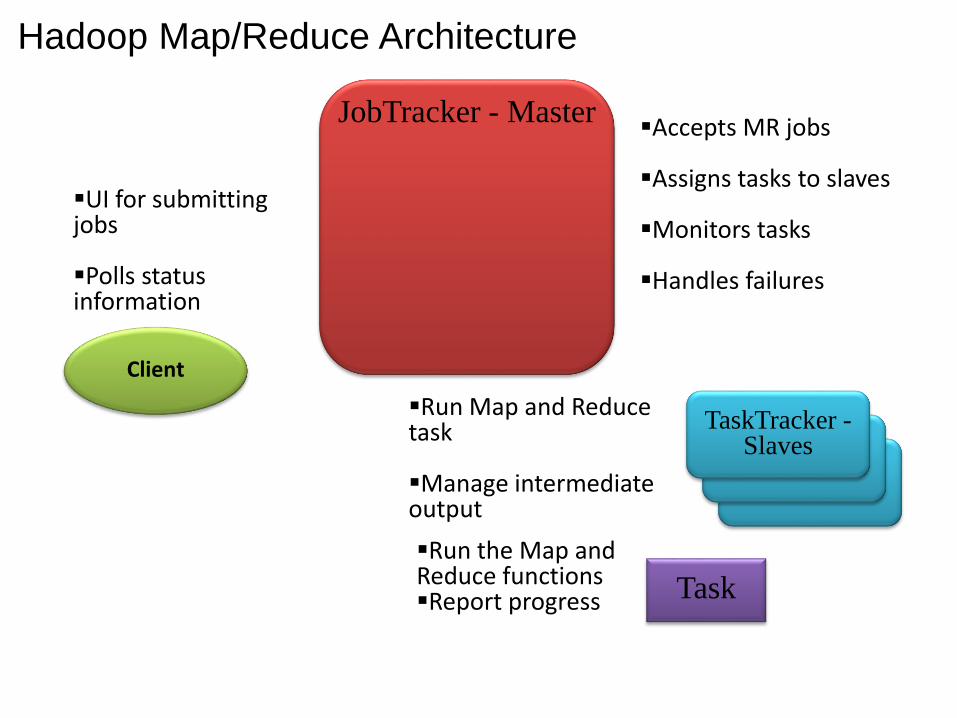
TaskTracker
JobTracker - Master
Client
TaskTracker
TaskTracker -Slaves
Run Map and Reduce task
Manage intermediate output
UI for submitting jobs
Polls status information
Accepts MR jobs
Assigns tasks to slaves
Monitors tasks
Handles failures
Task
Run the Map and Reduce functionsReport progress
Hadoop Map/Reduce Architecture
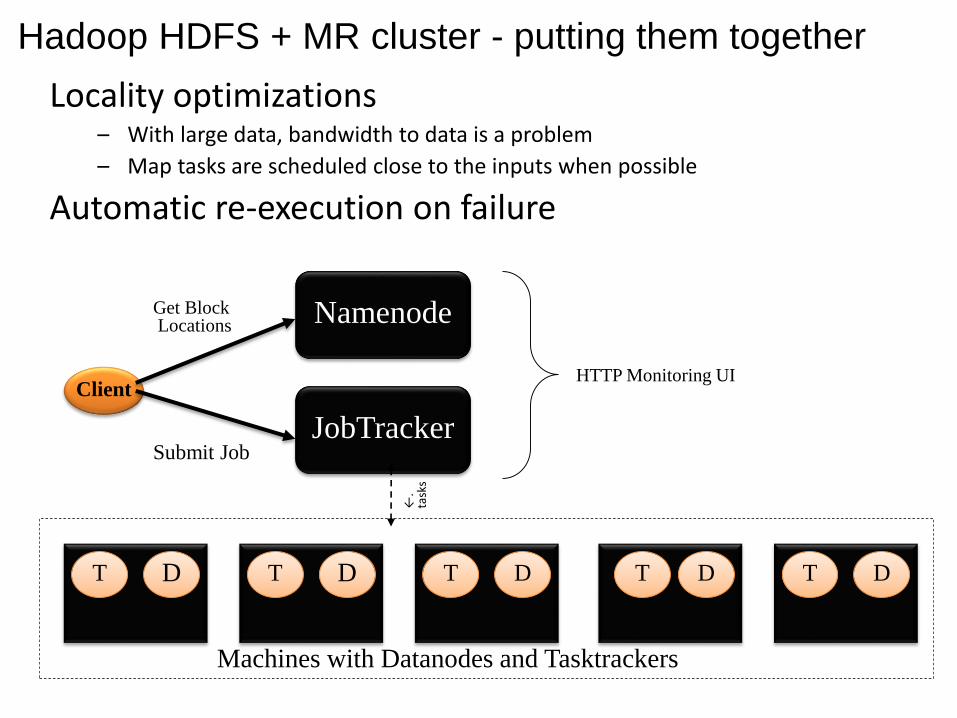
D D D DTT
JobTracker
Namenode
Machines with Datanodes and Tasktrackers
T T TD
Client
Submit Job
HTTP Monitoring UI
Get BlockLocations
Locality optimizations– With large data, bandwidth to data is a problem
– Map tasks are scheduled close to the inputs when possible
Automatic re-execution on failure
←.
task
s
Hadoop HDFS + MR cluster - putting them together
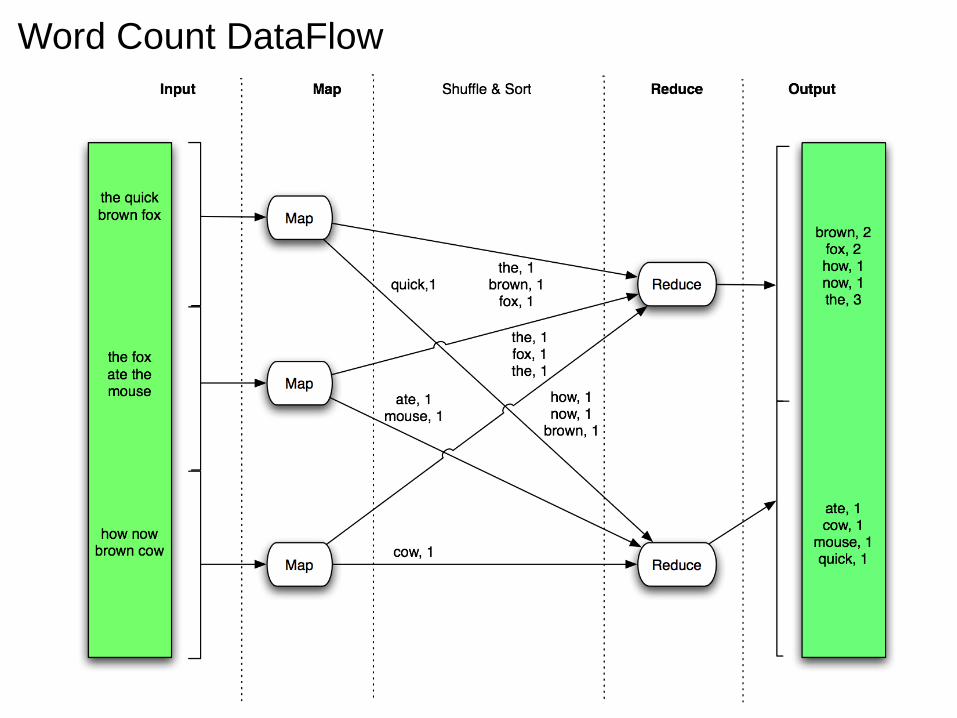
Word Count DataFlow

Ways of using Hadoop
• Map-Reduce Java API– http://hadoop.apache.org/mapreduce/
• Streaming– http://hadoop.apache.org/common/docs/current/mapred_tutorial.html
• Pipes– http://hadoop.apache.org/common/docs/current/api/org/apache/hadoop/mapred/pipes/package-
summary.html
• Pig– http://hadoop.apache.org/pig/
• Hive– http://hive.apache.org

Example: Compute TF-IDF using Map/Reduce
• TF-IDF (Term Frequency, Inverse Document Frequency)
• Is a basic technique
• To compute the relevancy of a document with respect to a particular term
• "Term" is a generalized element contains within a document.
• A "term" is a generalized idea of what a document contains.
• E.g. a term can be a word, a phrase, or a concept.

TF-IDF
• Intuitively, the relevancy of a document to a term can be calculated
• from the percentage of that term shows up in the document
• i.e.: the count of the term in that document divide by the total number of terms in it.
• We called this the "term frequency“

TF-IDF
• On the other hand,
• If this is a very common term which appears in many other documents,
• Then its relevancy should be reduced.
• i.e.: the count of documents having this term divided by total number of documents.
• We called this the "document frequency“

TF-IDF
• The overall relevancy of a document with respect to a term can be computed using both the term frequency and document frequency.
• relevancy = tf-idf = term frequency * log (1 / document frequency)
• This is called tf-idf.
• A "document" can be considered as a multi-dimensional vector where each dimension represents a term with the tf-idf as its value.
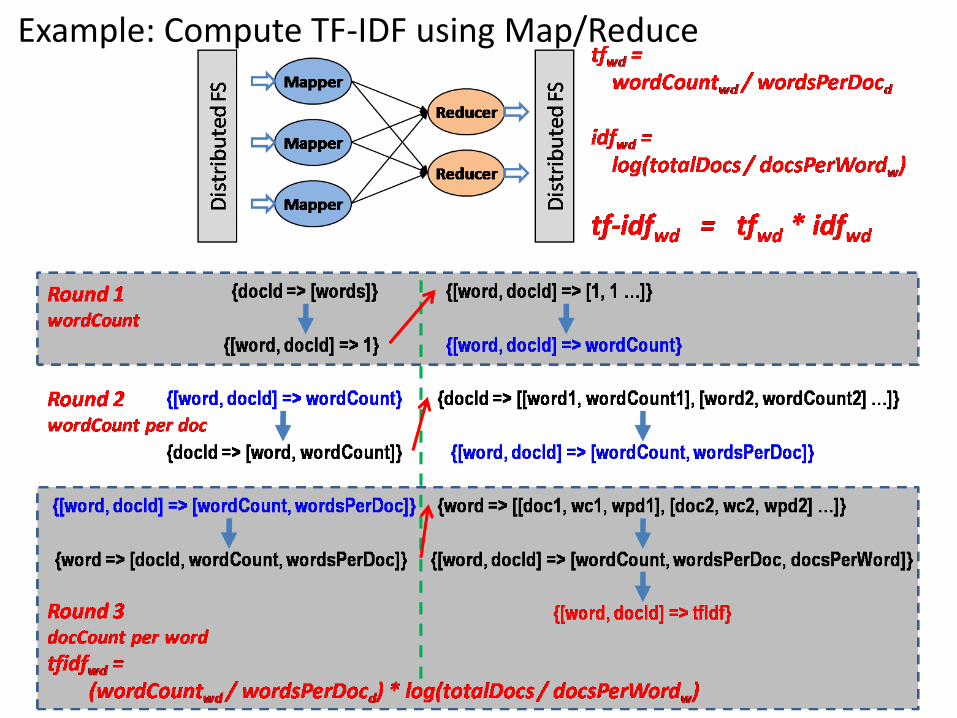
Example: Compute TF-IDF using Map/Reduce

Basic MapReduce Patterns1. Counting and Summing
2. Collating
3. Filtering (“Grepping”), Parsing, and Validation
4. Distributed Task Execution
5. Sorting
6. Iterative Message Passing (Graph Processing)
7. Distinct Values (Unique Items Counting)
8. Cross-Correlation
9. Selection
10. Projection
11. Union
12. Intersection
13. Difference
14. GroupBy and Aggregation
15. Joining
16. Time-series – moving average

Counting and Summing
• Problem Statement:
– There is a number of documents where each document is a set of terms.
– It is required to calculate a total number of occurrences of each term in all documents.
– Alternatively, it can be an arbitrary function of the terms.
– For instance, there is a log file where each record contains a response time and it is required to calculate an average response time.
• Applications: Log Analysis, Data Querying

Counting and SummingSolution:
class Mappermethod Map(docid id, doc d)
for all term t in doc d doEmit(term t, count 1)
class Combinermethod Combine(term t, [c1, c2,...])
sum = 0for all count c in [c1, c2,...] do
sum = sum + cEmit(term t, count sum)
class Reducermethod Reduce(term t, counts [c1, c2,...])
sum = 0for all count c in [c1, c2,...] do
sum = sum + cEmit(term t, count sum)

Collating
• Problem Statement:
– There is a set of items and some function of one item.
– It is required to save all items that have the same value of function into one file or perform some other computation that requires all such items to be processed as a group.
– The most typical example is building of inverted indexes.
• Applications: Inverted Indexes, ETL

CollatingSolution:
Mapper computes a given function for each item and emits value of the function as a key and item itself as a value.
class Mappermethod Map(docid id, doc d)
for all term t in doc d doEmit(term f(t), t)
Reducer obtains all items grouped by function value and process or save them. In case of inverted indexes, items are terms (words) and function is a document ID where the term was found.
class Reducermethod Reduce(term f(t), [t1, t2,...])
//process or saveEmit(term t, count sum)

Filtering (“Grepping”), Parsing, and Validation
• Problem Statement:
– There is a set of records and it is required to collect all records that meet some condition or transform each record (independently from other records) into another representation.
– The later case includes such tasks as text parsing and value extraction, conversion from one format to another.
• Applications: Log Analysis, Data Querying, ETL, Data Validation

Filtering (“Grepping”), Parsing, and ValidationSolution:
Mapper takes records one by one and emits accepted items or their transformed versions

Distributed Task Execution
• Problem Statement:
– There is a large computational problem that can be divided into multiple parts and results from all parts can be combined together to obtain a final result.
• Applications: Physical and Engineering Simulations, Numerical Analysis, Performance Testing

Distributed Task ExecutionSolution:
Problem description is split in a set of specifications and specifications are stored as input data for Mappers.
Each Mapper takes a specification, performs corresponding computations and emits results.
Reducer combines all emitted parts into the final result.
Case Study: Simulation of a Digital Communication System
There is a software simulator of a digital communication system like WiMAX that passes some volume of random data through the system model and computes error probability of throughput.
Each Mapper runs simulation for specified amount of data which is 1/Nth of the required sampling and emit error rate.
Reducer computes average error rate.

Sorting
• Problem Statement:
– There is a set of records and it is required to sort these records by some rule or process these records in a certain order.
• Applications: ETL, Data Analysis

SortingSolution:
Mappers just emit all items as values associated with the sorting keys that are assembled as function of items.
Nevertheless, in practice sorting is often used in a quite tricky way, that’s why it is said to be a heart of MapReduce (and Hadoop).
In particular, it is very common to use composite keys to achieve secondary sorting and grouping.
Sorting in MapReduce is originally intended for sorting of the emitted key-value pairs by key, but there exist techniques that leverage Hadoop implementation specifics to achieve sorting by values.
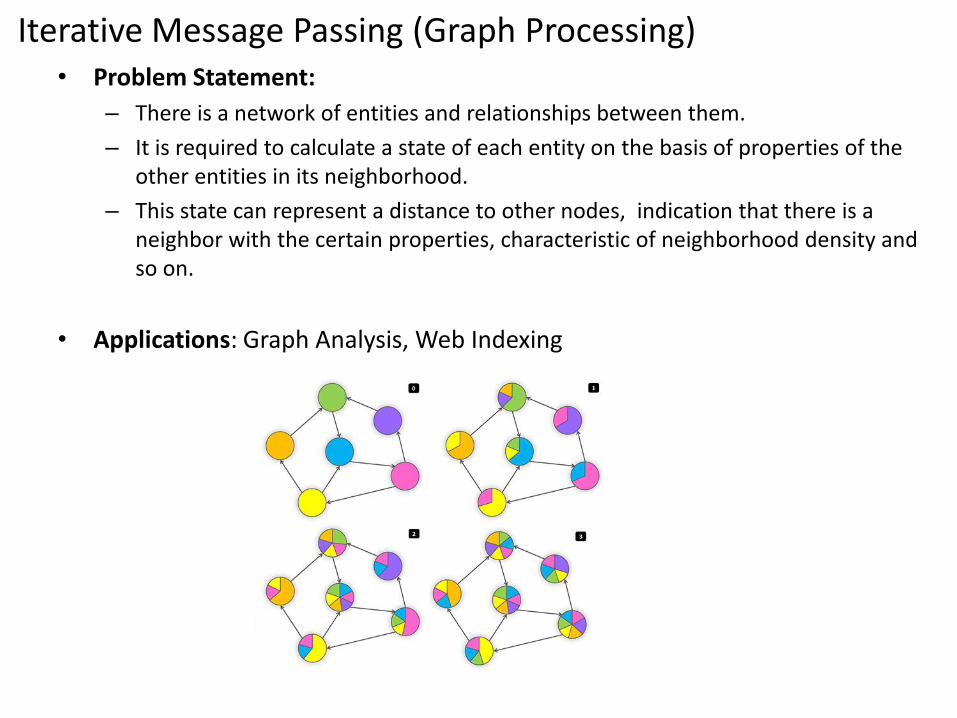
Iterative Message Passing (Graph Processing)• Problem Statement:
– There is a network of entities and relationships between them.
– It is required to calculate a state of each entity on the basis of properties of the other entities in its neighborhood.
– This state can represent a distance to other nodes, indication that there is a neighbor with the certain properties, characteristic of neighborhood density and so on.
• Applications: Graph Analysis, Web Indexing

Iterative Message Passing (Graph Processing)Solution:
A network is stored as a set of nodes and each node contains a list of adjacent node IDs.
Conceptually, MapReduce jobs are performed in iterative way and at each iteration each node sends messages to its neighbors.
Each neighbor updates its state on the basis of the received messages.
Iterations are terminated by some condition like fixed maximal number of iterations (say, network diameter) or negligible changes in states between two consecutive iterations.
From the technical point of view, Mapper emits messages for each node using ID of the adjacent node as a key.
As result, all messages are grouped by the incoming node and reducer is able to re-compute state and rewrite node with the new state.

Iterative Message Passing (Graph Processing)Solution:
class Mappermethod Map(id n, object N)
Emit(id n, object N)for all id m in N.OutgoingRelations do
Emit(id m, message getMessage(N))
class Reducermethod Reduce(id m, [s1, s2,...])
object M = nullmessages = []for all s in [s1, s2,...] do
if IsObject(s) thenM = s
else // s is a messagemessages.add(s)
M.State = calculateState(messages)Emit(id m, object M)

Case Study: Availability Propagation Through The Tree of Categories
• Problem Statement:
– This problem is inspired by real life eCommerce task.
– There is a tree of categories that branches out from large categories (like Men, Women, Kids) to smaller ones (like Men Jeans or Women Dresses), and eventually to small end-of-line categories (like Men Blue Jeans).
– End-of-line category is either available (contains products) or not.
– Some high level category is available if there is at least one available end-of-line category in its subtree.
– The goal is to calculate availabilities for all categories if availabilities of end-of-line categories are know.

Case Study: Availability Propagation Through The Tree of Categories
class NState in {True = 2, False = 1, null = 0}, //initialized 1 or 2 for end-
of-line categories, 0 otherwise
method getMessage(object N)return N.State
method calculateState(state s, data [d1, d2,...])return max( [d1, d2,...] )

Case Study: Breadth-First Search
• Problem Statement: There is a graph and it is required to calculate distance (a number of hops) from one source node to all other nodes in the graph.

Case Study: Breadth-First Search
class NState is distance, initialized 0 for source node, INFINITY for all
other nodes
method getMessage(N)return N.State + 1
method calculateState(state s, data [d1, d2,...])min( [d1, d2,...] )

Distinct Values (Unique Items Counting)• Problem Statement:
– There is a set of records that contain fields F and G. Count the total number of unique values of filed F for each subset of records that have the same G (grouped by G).
– The problem can be a little bit generalized and formulated in terms of faceted search: There is a set of records. Each record has field F and arbitrary number of category labels G = {G1, G2, …} . Count the total number of unique values of filed F for each subset of records for each value of any label.
• Example Applications: Log Analysis, Unique Users Counting
Record 1: F=1, G={a, b}Record 2: F=2, G={a, d, e}Record 3: F=1, G={b}Record 4: F=3, G={a, b}
Result:a -> 3 // F=1, F=2, F=3b -> 2 // F=1, F=3d -> 1 // F=2e -> 1 // F=2

Distinct Values (Unique Items Counting)Solution:
PHASE-1class Mapper
method Map(null, record [value f, categories [g1, g2,...]])for all category g in [g1, g2,...]
Emit(record [g, f], count 1)
class Reducermethod Reduce(record [g, f], counts [n1, n2, ...])
Emit(record [g, f], null )
PHASE-2class Mapper
method Map(record [f, g], null)Emit(value g, count 1)
class Reducermethod Reduce(value g, counts [n1, n2,...])
Emit(value g, sum( [n1, n2,...] ) )

Cross-Correlation
• Problem Statement:
– There is a set of tuples of items.
– For each possible pair of items calculate a number of tupleswhere these items co-occur.
– If the total number of items is N then N*N values should be reported.
– This problem appears in :• text analysis (say, items are words and tuples are sentences),
• market analysis (customers who buy this tend to also buy that).
– If N*N is small - matrix can fit in the memory of a single machine.

Market Basket Analysis• Suppose a store sells N different products and has data on B customer purchases
(each purchase is called a “market basket”)
• An association rule is expressed as “If x is sold, then y is sold”:
– x y
• “Support” for x y: Joint probability of P (x ^ y)
– The probability of finding x and y together in a random basket
• “Confidence” in x y: Conditional probability of P (y | x)
– The probability of finding y in a basket if the basket already contains x
• Goal is finding rules with high support and high confidence
– How are they computed?
– Cooccur [x, x] represents the number of baskets that contain x
– Cooccur [x, y] represents the number of baskets that contain x & y
– Cooccur [x, y] == Cooccur [y, x]
– Support: Calculated as Cooccur [x, y] / B
– Confidence: Calculated as Cooccur [x, y] / Cooccur [x, x]

Cross-CorrelationSolution:
class Mappermethod Map(null, basket = [i1, i2,...] )
for all item i in basket for all item j in basket
Emit(pair [i j], count 1)
class Reducermethod Reduce(pair [i j], counts [c1, c2,...])
s = sum([c1, c2,...])Emit(pair[i j], count s)

Cross-CorrelationSolution:
class Mappermethod Map(null, basket = [i1, i2,...] )
for all item i in basket H = new AssociativeArray : item -> counterfor all item j in basket
H{j} = H{j} + 1Emit(item i, stripe H)
class Reducermethod Reduce(item i, stripes [H1, H2,...])
H = new AssociativeArray : item -> counterH = merge-sum( [H1, H2,...] )for all item j in H.keys()
Emit(pair [i j], H{j})

SelectionSolution:
class Mappermethod Map(rowkey key, tuple t)
if t satisfies the predicateEmit(tuple t, null)

ProjectionSolution:
class Mappermethod Map(rowkey key, tuple t)
tuple g = project(t) // extract required fields to tuple gEmit(tuple g, null)
class Reducermethod Reduce(tuple t, array n) // n is an array of nulls
Emit(tuple t, null)

UnionSolution:
class Mappermethod Map(rowkey key, tuple t)
Emit(tuple t, null)
class Reducermethod Reduce(tuple t, array n) // n is an array of one or two nulls
Emit(tuple t, null)

IntersectionSolution:
class Mappermethod Map(rowkey key, tuple t)
Emit(tuple t, null)
class Reducermethod Reduce(tuple t, array n) // n is an array of one or more nulls
if n.size() >= 2Emit(tuple t, null)

DifferenceSolution:
// We want to compute difference R – S. // Mapper emits all tuples and tag which is a name of the set this record came from. // Reducer emits only records that came from R but not from S.
class Mappermethod Map(rowkey key, tuple t)
Emit(tuple t, string t.SetName) // t.SetName is either 'R' or 'S'
class Reducermethod Reduce(tuple t, array n) // array n can be ['R'], ['S'], ['R' 'S'], or ['S', 'R']
if n.size() = 1 and n[1] = 'R'Emit(tuple t, null)

Join• A JOIN is a means for combining fields from two tables by using values
common to each.
• ANSI standard SQL specifies four types of JOIN: INNER, OUTER, LEFT, and RIGHT.
• As a special case, a table (base table, view, or joined table) can JOIN to itself in a self-join.
• Join algorithms
– Nested loop
– Sort-Merge
– Hash
SELECT *FROM employeeINNER JOIN department ON employee.DepartmentID = department.DepartmentID;
SELECT *FROM employee JOIN department ON employee.DepartmentID = department.DepartmentID;
SELECT * FROM employeeLEFT OUTER JOIN department ON employee.DepartmentID = department.DepartmentID;

Nested loop
For each tuple r in R doFor each tuple s in S do
If r and s satisfy the join conditionThen output the tuple <r,s>

Sort-Merge
p in P; q in Q; g in Qwhile more tuples in inputs do
while p.a < g.b doadvance p
end whilewhile p.a > g.b do
advance g //a group might begin hereend whilewhile p.a == g.b do
q = g //mark group beginningwhile p.a == q.b do
Add <p,q> to the resultAdvance q
end whileAdvance p //move forward
end whileg = q //candidate to begin next group
end while

Sort-Merge : MapReduce• This algorithm joins of two sets R and L on some key k.
• Mapper goes through all tuples from R and L, extracts key k from the tuples, marks tuple with a tag that indicates a set this tuple came from (‘R’ or ‘L’), and emits tagged tuple using k as a key.
• Reducer receives all tuples for a particular key k and put them into two buckets – for R and for L.
• When two buckets are filled, Reducer runs nested loop over them and emits a cross join of the buckets.
• Each emitted tuple is a concatenation R-tuple, L-tuple, and key k.
• This approach has the following disadvantages:
– Mapper emits absolutely all data, even for keys that occur only in one set and have no pair in the other.
– Reducer should hold all data for one key in the memory. If data doesn’t fit the memory, its Reducer’s responsibility to handle this by some kind of swap.

Sort-Merge : MapReduce PseudocodeSolution:
class Mappermethod Map(null, tuple [join_key k, value v1, value v2,...])
Emit(join_key k, tagged_tuple [set_name tag, values [v1, v2, ...] ] )
class Reducermethod Reduce(join_key k, tagged_tuples [t1, t2,...])
H = new AssociativeArray : set_name -> valuesfor all tagged_tuple t in [t1, t2,...] // separate values into 2 arrays
H{t.tag}.add(t.values)for all values r in H{'R'} // produce a cross-join of the two arrays
for all values l in H{'L'}Emit(null, [k r l] )

Hash Join• The Hash Join algorithm consists of a ‘build’ phase and a ‘probe’ phase.
• In its simplest variant, the smaller dataset is loaded into an in-memory hash table in the build phase.
• In the ‘probe’ phase, the larger dataset is scanned and joined with the relevant tuple(s) by looking into the hash table.
for all p in P doLoad p into in memory hash table H
end for
for all q in Q doif H contains p matching with q then
add <p,q> to the resultend if
end for

Hash Join : MapReduce Pseudocode• Let’s assume that we join two sets – R and L, R is relative small. If so, R can
be distributed to all Mappers and each Mapper can load it and index by the join key.
class Mappermethod Initialize
H = new AssociativeArray : join_key -> tuple from RR = loadR()for all [ join_key k, tuple [r1, r2,...] ] in R
H{k} = H{k}.append( [r1, r2,...] )
method Map(join_key k, tuple l)for all tuple r in H{k}
Emit(null, tuple [k r l] )

Reference
F. N. Afrati and J. D. Ullman. Optimizing joins in a map-reduce environment. In EDBT, pages 99-110, 2010
R. Vernica, M. J. Carey, and C. Li. Ecient parallel set-similarity joins using mapreduce. In SIGMOD, pages 495-506, 2010.
H. Yang, A. Dasdan, R.-L. Hsiao, and D. S. P. Jr. Map-Reduce-Merge: simplified relational data processing on large clusters. In SIGMOD Conference, pages 1029–1040, 2007.
Processing theta-joins using MapReduce, Alper Okcan, Mirek Riedewald, SIGMOD '11
Foto N. Afrati, Jeffrey D. Ullman: Optimizing Multiway Joins in a Map-Reduce Environment. IEEE Trans. Knowl. Data Eng. 23(9): 1282-1298 (2011)
V-SMART-Join: A Scalable MapReduce Framework for All-Pair Similarity Joins of Multisetsand Vectors, Ahmed Metwally, Christos Faloutsos, PVLDB Proceedings of the VLDB Endowment, vol. 5 (2012)

End of session
Day – 2: MapReduce Concepts