hadoop and sql: delivery analytics across the organization
TRANSCRIPT

© 2015 IBM Corporation
Hadoop and SQL: Delivering Analytics Across the organization (DHS-2147)
Nicholas Berg, Seagate
Adriana Zubiri, IBM
27-Oct-2015 2:30 PM-3:30 PM

• IBM’s statements regarding its plans, directions, and intent are subject to change or withdrawal
without notice at IBM’s sole discretion.
• Information regarding potential future products is intended to outline our general product direction
and it should not be relied on in making a purchasing decision.
• The information mentioned regarding potential future products is not a commitment, promise, or
legal obligation to deliver any material, code or functionality. Information about potential future
products may not be incorporated into any contract.
• The development, release, and timing of any future features or functionality described for our
products remains at our sole discretion.
Performance is based on measurements and projections using standard IBM benchmarks in a
controlled environment. The actual throughput or performance that any user will experience will vary
depending upon many factors, including considerations such as the amount of multiprogramming in the
user’s job stream, the I/O configuration, the storage configuration, and the workload processed.
Therefore, no assurance can be given that an individual user will achieve results similar to those stated
here.
Please Note:
2

A New SeagateSEAGATE is in a unique position to CREATE EVEN MORE VALUE
for our customers by integrating our 35+ years of storage expertise in
HDD with FLASH, SYSTEMS, SERVICES AND CONSUMER DEVICES
to deliver unique solutions that enable our customers to
ENJOY AND GET VALUE FROM THEIR DATA
more than ever before.HYBRID SOLUTIONS
HDD FLASH
SILICON
BRANDED
SYSTEMS

• $14B Annual Revenue
• 2 billion drives shipped
• Stores more than 40% of the world’s data
• 43,000 Cloud services clients worldwide
• 50,000 Employees, 26 countries
• 9 Manufacturing plants: US, China, Malaysia,
N.Ireland, Singapore, Thailand
• 5 Design centers: US, Singapore, South Korea
• Vertically integrated factories from Silicon
fabrication to Drive assembly
SYSTEMSHD FLASH SILICON PREMIUM HYBRID SOLUTIONSSYSTEMSFLASH BRANDEDHYBRID SOLUTIONS
LSI

Where to start with Hadoop - find a use case
• Experimented with text analysis of Call Center logs
Proved out the use case, but Big Data text analytics built into Call Center support applications met the need without in-house costs
• Marketing organization had some social media Big Data Use cases
These are being met by companies specializing in this kind of Big Data analysis
• Reviewed other potential use cases such as:
Mining data center support, performance and maintenance logs
Mining large data sets for IT Security
• Tested loading up some volume factory test log data and run some analytics
Compelling use case for Hadoop: Deeper and wider analysis of Factory and Field data

Traditional Data Architecture Pressured
4.4 ZB in 2013
85% from New Data Types
15x Machine Data by 2020
44 ZB by 2020
ZB = 1B TB

Seagate’s high-level plans for Hadoop
• Enterprise Hadoop cluster as extension of EDW (augmentation)
Ability to store and analyze 10x-20x Factory and Field data
Much longer retention of relevant manufacturing data
Multi-purpose analytic environment supporting hundreds of potential users across Engineering, Manufacturing and Quality
• Possible local factory Hadoop clusters for special-purpose processing
• Eventual integration across multiple clusters and sites
• At a high level, Hadoop will enable us to
Ask questions we could never ask before...
About data volumes we could never collect and store before…
Doing analysis we could never perform in reasonable time…
And connecting data that could never before be retained for combined analysis

Hadoop: a dynamic and ever changing landscape
• When we first started our Hadoop journey, MapReduce was the main way to access and query HDFS data
• Two years on, the Hadoop world had changed with SQL being a major force in Hadoop (Hive, Impala, BigSQL)
• SQL on Hadoop helps address three main Hadoop challenges:
Addresses a skills gap: Hadoop MapReduce needs Java coders vs. using existing SQL skills
SQL provides integration with existing environments and tools (i.e. databases and BI tools)
Enables Hadoop to move from batch processing to interactive analysis
• New memory based Apache projects are being developed that allow for even faster interactive analysis like Apache Spark but SQL is still core to these too

Big data for the enterprise
• We put together a five year Big Data vision statement and strategy plan
Socialized strategy plan for feedback
• Decided to conducted a large scale Hadoop pilot
We wanted to really understand what Hadoop’s real capabilities and potential were
• Purchased 60 node cluster: 3 management nodes, 57 data nodes. (Now increased to two cluster 60 + 100 nodes)
• Performed an analysis on which Hadoop distribution to use
• Defined what use cases to run in our large scale pilot

Choosing a Hadoop software distribution
• Two main flavors: open source oriented or more proprietary
• Open source oriented solutions are the most beneficial:
Portable - easily move your Hadoop cluster from vendor to vendor
Avoids vendor lock into expensive and proprietary technology
Open source projects ensure interoperability with other open source projects
• Other important considerations:
Integration with RDMSs, BI solutions and other platforms
R&D investment and support capability
Consulting and training
• Seagate chose IBM because we believe they have the most advanced SQL “add-on” Hadoop capability, some other strong Hadoop tools like BigR and excellent support services

Evolving to a Logical Data Warehouse
• A Logical Data Warehouse combines traditional data warehouses with big data systems to evolve your analytics capabilities beyond where you are today
• Hadoop does not replace your EDW. EDW is a good “general purpose” data management solution for integrating and conforming enterprise data to produce your everyday business analytics
• A typical EDW may have 100’s of data feeds, dozens of integrated applications and run 1000’s to 100,000’s of queries a day
• Hadoop is more specialized and much less mature. For now it will have only a few application integration points and run fewer queries at a lower concurrency, answering different questions
• A Hadoop cluster of 60-100 nodes is a supercomputer. What would you use a supercomputer for? Probably to answer the really big questions

Some early practices and learnings
• Incremental phased delivery, or use case by use case
• Form a “data lake” or “data reservoir” for all enterprise data
• Data availability must come first, model and transform the data in place within Hadoop
resist moving the data again
• Lots of talk about schema on read but for Data Warehousing types of uses, this is impractical
Data modeling is still required but can be simplified
• Have multiple clusters: Development, Test and then two or more Production, one for Ad Hoc data exploration & experimentation, one for more governed uses with guaranteed cluster availability to run important jobs
• Use existing custom query/analytics solution to provide “transparent” access to Hadoop
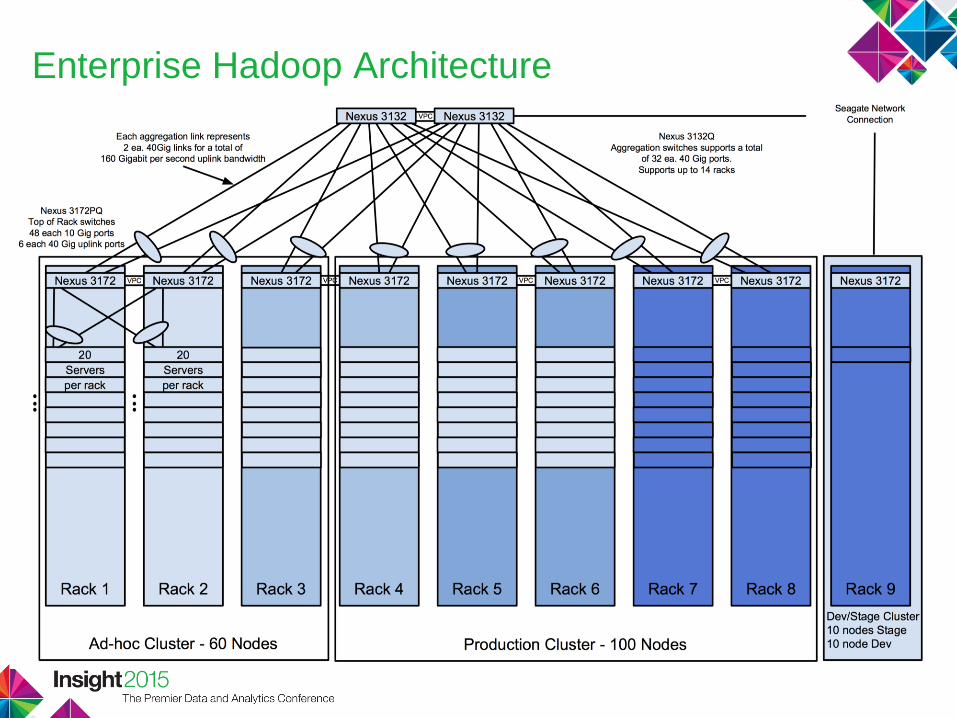
Enterprise Hadoop Architecture

The Data Lake: data tiering
13
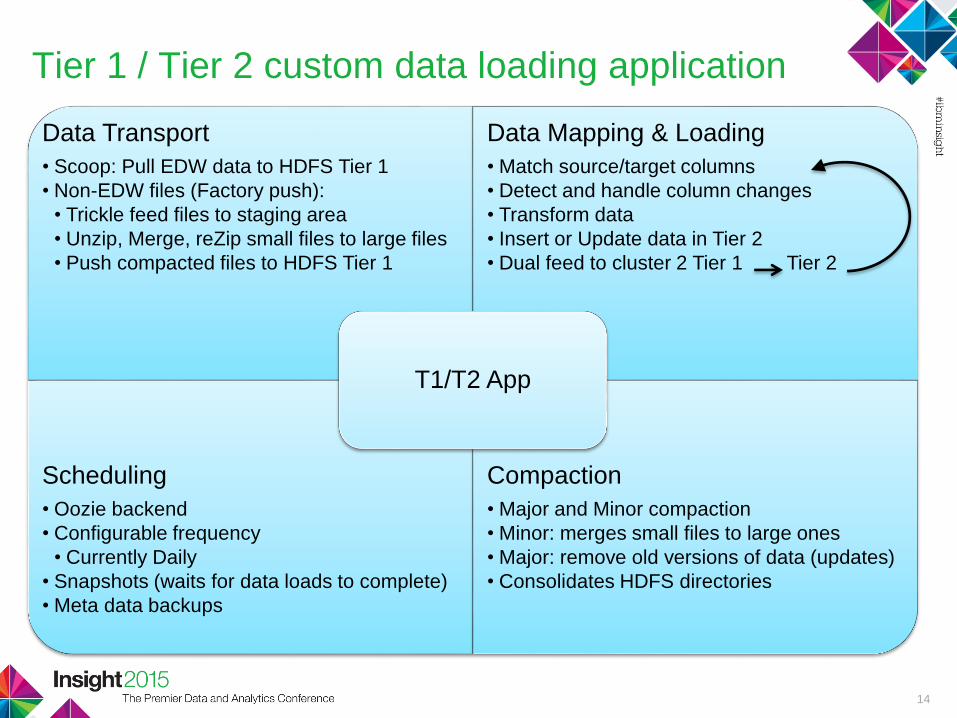
Tier 1 / Tier 2 custom data loading application
14
Data Transport
• Scoop: Pull EDW data to HDFS Tier 1
• Non-EDW files (Factory push):
• Trickle feed files to staging area
• Unzip, Merge, reZip small files to large files
• Push compacted files to HDFS Tier 1
Data Mapping & Loading
• Match source/target columns
• Detect and handle column changes
• Transform data
• Insert or Update data in Tier 2
• Dual feed to cluster 2 Tier 1 Tier 2
Scheduling
• Oozie backend
• Configurable frequency
• Currently Daily
• Snapshots (waits for data loads to complete)
• Meta data backups
Compaction
• Major and Minor compaction
• Minor: merges small files to large ones
• Major: remove old versions of data (updates)
• Consolidates HDFS directories
T1/T2 App
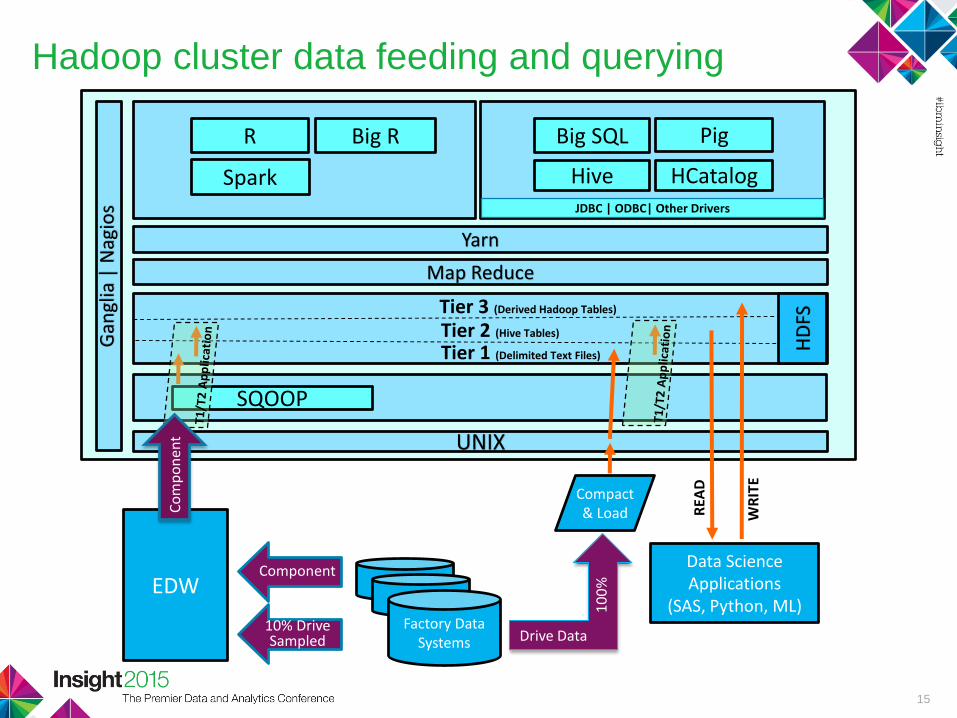
Hadoop cluster data feeding and querying
15
EDW
Factory Data Systems
UNIX
HD
FS
SQOOP
Map Reduce
Big SQL
Hive
Pig
HCatalog
Big RR
Gan
glia
| N
agio
s
Compact & Load
Tier 3 (Derived Hadoop Tables)
Tier 2 (Hive Tables)
Tier 1 (Delimited Text Files)
Component
REA
D
JDBC | ODBC| Other Drivers
WR
ITE
Data Science Applications
(SAS, Python, ML)10% Drive Sampled Drive Data
10
0%
SparkC
om
po
nen
t
Yarn

Adding Hive update support• Hive is a good structured table format for querying but it does
not support row updates to large fact tables
This type of capability is known in the database arena as ACID
ACID (Atomicity, Consistency, Isolation, Durability) is a set of properties that guarantee that database transactions are processed reliably
Atomicity: requires that each transaction be "all or nothing”. If one part of the transaction fails, the entire transaction fails, and the database state is left unchanged
Consistency: Any data written to the database must be valid according to all defined rules, including constraints, cascades, triggers, and any combination thereof
Isolation: ensures that the concurrent execution of transactions results are the same if transactions were executed serially
Durability: means that once a transaction has been committed, it will remain so, even in the event of power loss, crashes, or errors
16
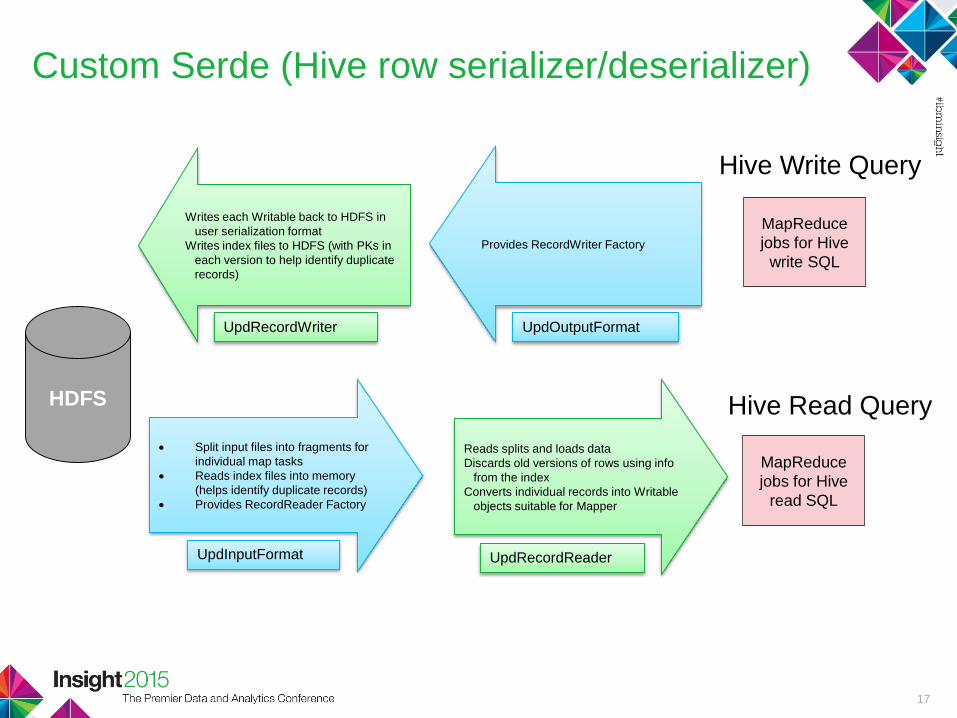
Custom Serde (Hive row serializer/deserializer)
17
Split input files into fragments for
individual map tasks
Reads index files into memory
(helps identify duplicate records)
Provides RecordReader Factory
UpdInputFormat
Reads splits and loads data
Discards old versions of rows using info
from the index
Converts individual records into Writable
objects suitable for Mapper
UpdRecordReader
HDFS
MapReduce
jobs for Hive
read SQL
Provides RecordWriter Factory
UpdOutputFormat
Writes each Writable back to HDFS in
user serialization format
Writes index files to HDFS (with PKs in
each version to help identify duplicate
records)
UpdRecordWriter
MapReduce
jobs for Hive
write SQL
Hive Read Query
Hive Write Query

Hadoop challenges(an emerging and evolving platform)
• Knowing which Hadoop projects to “bet on”, which data formats and compression types to use
• Speed of change: probably has more code been written than any other IT platform
Need to upgrade cluster software frequently (once a quarter)
• Gaps: Some things not ready like ACID, real-time queries
• Resource management for different types of workloads
• Lack of BI tools that can really take advantage of huge data sets and visualize them
• Still very batch processing orientated but interactive is gaining traction with Spark etc.
• Provisioning large numbers of machines, hardware failures
• Integrating remote clusters, cross cluster data movement and inter-cluster processing

Hadoop projects – setting expectations
• Completely new and an awful lot to learn, design & implementation are huge tasks
• Hadoop is still quite immature and lacks robustness
Exhibits instability, buggy, new code released too early
• Speed of change: management need to understand that plans will be dynamic and will change with the evolving technology
Have less formal schedules, manage expectations to the low side
• Be flexible and adaptable as technology changes and matures
Be ready to change and adapt to new technology or if support dries up on a Hadoop project
• Developing IT skills quickly
Finding experienced and talented Hadoop staff or consultants
Keeping up with the data scientists
• Convincing security and data center teams to give Hadoop users UNIX level access

20
• IBM Open Platform –Foundation of 100% pure open source Apache Hadoop components
• Standardizing as the Open Data Platform (http://opendataplatform.org)
About the IBM Open Platform for Apache Hadoop
All Standard Apache Open Source Components
HDFS
YARN
MapReduce
Ambari HBase
Spark
Flume
Hive Pig
Sqoop
HCatalog
Solr/Lucene
ODP
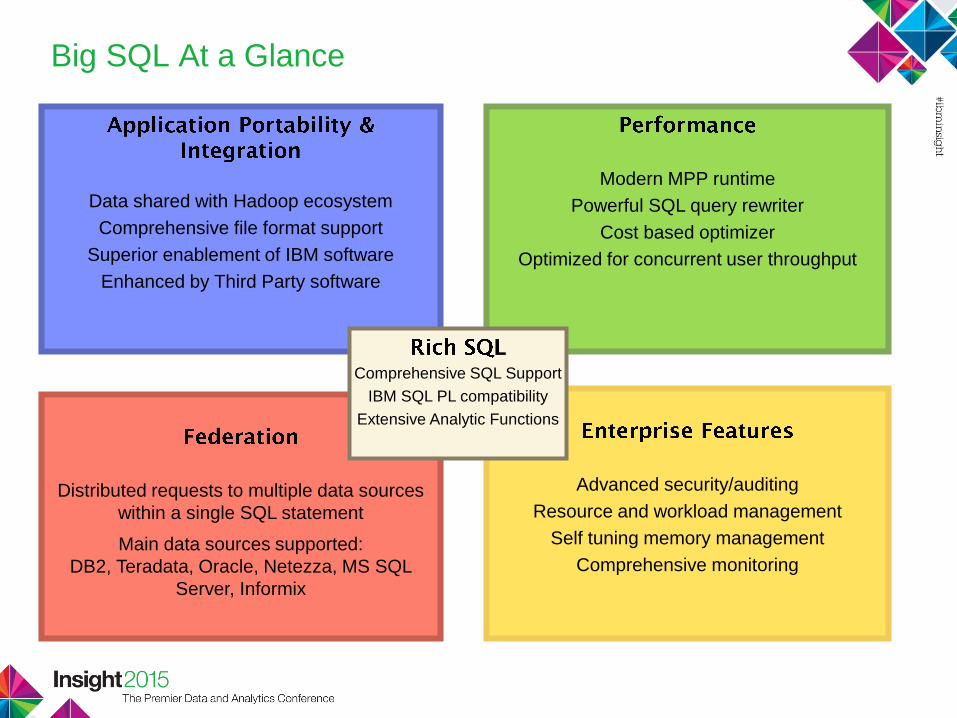
Data shared with Hadoop ecosystem
Comprehensive file format support
Superior enablement of IBM software
Enhanced by Third Party software
Modern MPP runtime
Powerful SQL query rewriter
Cost based optimizer
Optimized for concurrent user throughput
Distributed requests to multiple data sources
within a single SQL statement
Main data sources supported:
DB2, Teradata, Oracle, Netezza, MS SQL
Server, Informix
Advanced security/auditing
Resource and workload management
Self tuning memory management
Comprehensive monitoring
Comprehensive SQL Support
IBM SQL PL compatibility
Extensive Analytic Functions
Big SQL At a Glance

New functionality in Big SQL in 2015
• Ambari Installation and configuration
• Hbase support
• Rich Management User Interface
• Data types
New primitive data types support (decimal, char, varbinary)
Complex data types support (array, struct, map)
Enhancements to varchar and date
• Platforms
Power support
RHEL 6.6 anmd 7.1 support
• More Performance
HDFS caching
UDFs performance improvements
ANALYZE enhancements (2.5X faster than 3.0 FP2)
Native implementations of key Hive built-in functions
SQL Enhancements
New analytic procedures
New olap functions and aggregate
functionality
Offset support for limit and fetch
first
Ability to directly define and
execute Hive User Define
Functions (UDFs)
Other Improvements
Improved support for concurrent
LOAD operations
Support for importing with the
Teradata Connector for Hadoop
(TDH)
Added SQL server 2012 and
DB2/Z support
CMX compression support now
supported in the native I/O engine
High Availability (FP2)
Technical Previews
Yarn/Slider Integration
Spark integration (FP2)
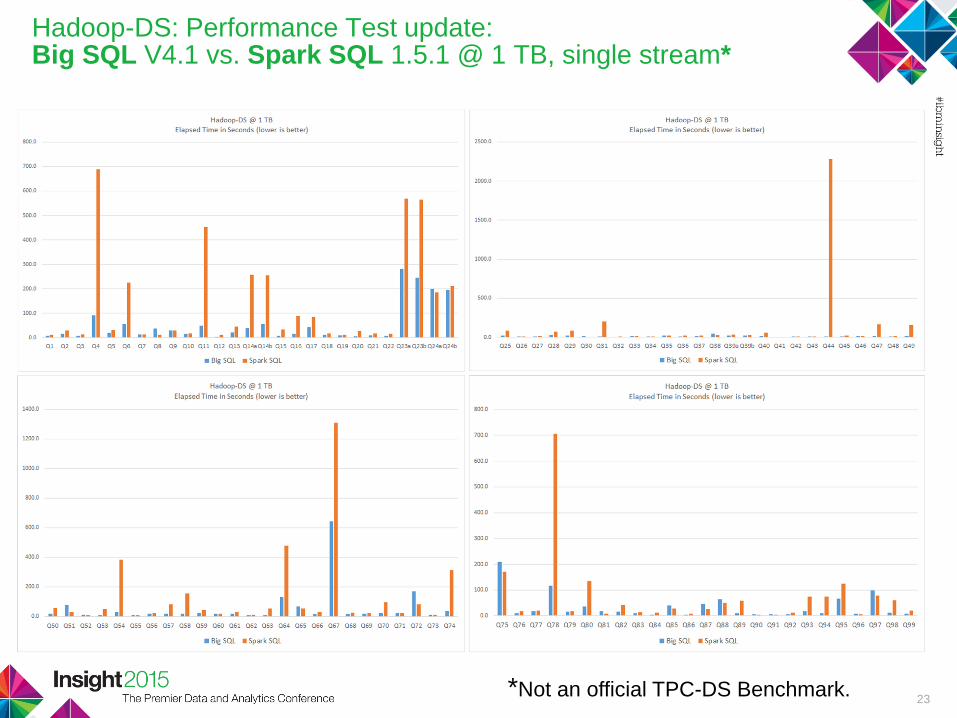
Hadoop-DS: Performance Test update:Big SQL V4.1 vs. Spark SQL 1.5.1 @ 1 TB, single stream*
23*Not an official TPC-DS Benchmark.
24
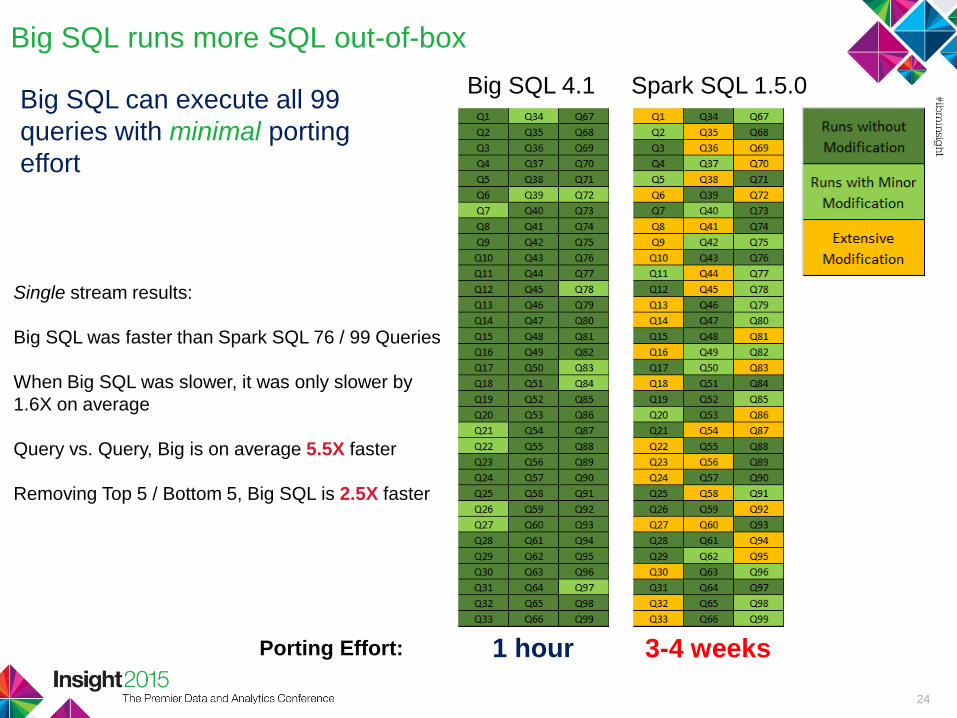
Big SQL runs more SQL out-of-box
Big SQL 4.1 Spark SQL 1.5.0
1 hour 3-4 weeksPorting Effort:
Big SQL can execute all 99
queries with minimal porting
effort
Single stream results:
Big SQL was faster than Spark SQL 76 / 99 Queries
When Big SQL was slower, it was only slower by
1.6X on average
Query vs. Query, Big is on average 5.5X faster
Removing Top 5 / Bottom 5, Big SQL is 2.5X faster

But, … what happens when you scale it?
Scale Single Stream 4 Concurrent Streams
1 TB • Big SQL was faster on 76 / 99
Queries
• Big SQL averaged 5.5X faster
• Removing Top / Bottom 5, Big SQL
averaged 2.5X faster
• Spark SQL FAILED on 3 queries
• Big SQL was 4.4X faster*
10 TB • Big SQL was faster on 80/99 Queries
• Spark SQL FAILED on 7 queries
• Big SQL averaged 6.2X faster*
• Removing Top / Bottom 5, Big SQL
averaged 4.6X faster
• Big SQL elapsed time for workload was
better than linear
• Spark SQL could not complete the
workload (numerous issues). Partial results
possible with only 2 concurrent streams.
*Compares only queries that both Big SQL and Spark SQL could complete (benefits Spark SQL)
More Users
More
Data
26
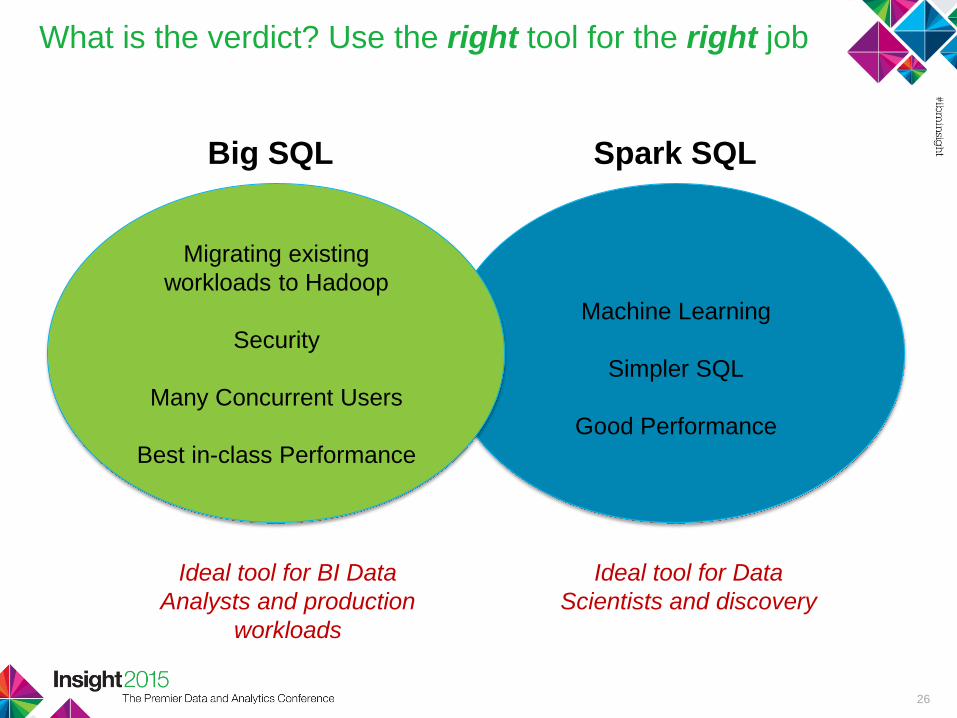
What is the verdict? Use the right tool for the right job
Machine Learning
Simpler SQL
Good Performance
Ideal tool for BI Data
Analysts and production
workloads
Ideal tool for Data
Scientists and discovery
Big SQL Spark SQL
Migrating existing
workloads to Hadoop
Security
Many Concurrent Users
Best in-class Performance
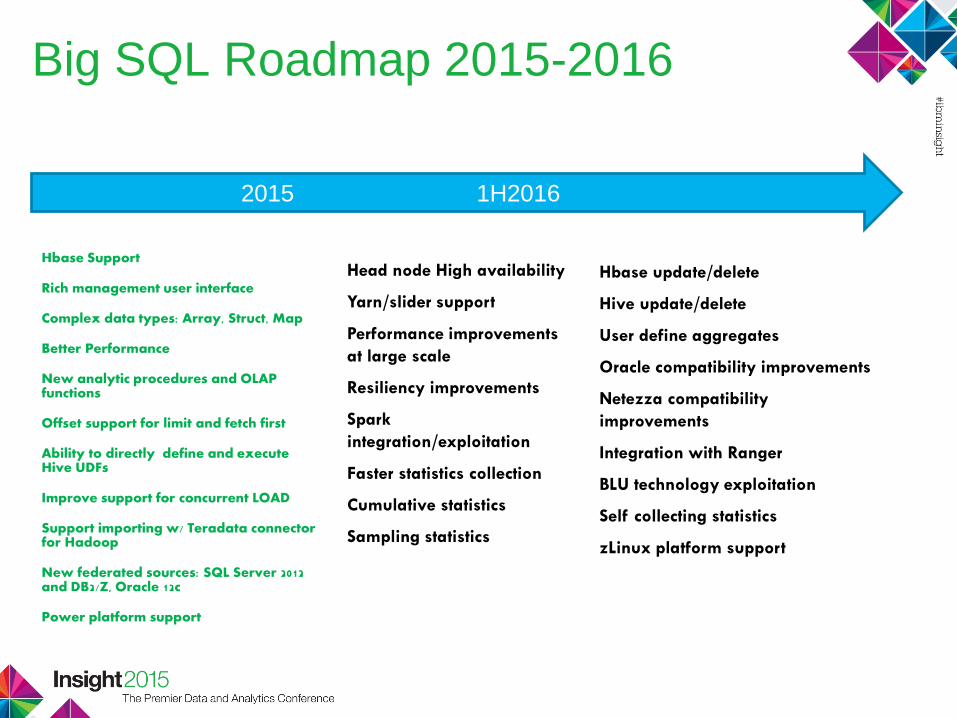
Big SQL Roadmap 2015-2016
27
Hbase Support
Rich management user interface
Complex data types: Array, Struct, Map
Better Performance
New analytic procedures and OLAP functions
Offset support for limit and fetch first
Ability to directly define and execute Hive UDFs
Improve support for concurrent LOAD
Support importing w/ Teradata connector for Hadoop
New federated sources: SQL Server 2012 and DB2/Z, Oracle 12c
Power platform support
Head node High availability
Yarn/slider support
Performance improvements
at large scale
Resiliency improvements
Spark
integration/exploitation
Faster statistics collection
Cumulative statistics
Sampling statistics
Hbase update/delete
Hive update/delete
User define aggregates
Oracle compatibility improvements
Netezza compatibility
improvements
Integration with Ranger
BLU technology exploitation
Self collecting statistics
zLinux platform support
2015 1H2016

We Value Your Feedback!
Don’t forget to submit your Insight session and speaker
feedback! Your feedback is very important to us – we use it
to continually improve the conference.
Access the Insight Conference Connect tool at
insight2015survey.com to quickly submit your surveys from
your smartphone, laptop or conference kiosk.
28
