guia del modulo estadisticade... · 1 uta ing. m.b.a william teneda . universidad tÉcnica de...
TRANSCRIPT

1 UTA Ing. M.B.A William Teneda
UNIVERSIDAD TÉCNICA DE AMBATO
GUIA DEL MODULO
ESTADISTICA
Ing. M.B.A William Fabián Teneda Llerena

2 UTA Ing. M.B.A William Teneda
CAPITULO I
ESTADIGRAFOS DE POSICION Y
ESTADIGRAFOS DE DISPERSION
I.1 Objetivos
• Diferenciar entre los estadígrafos de posición y los estadígrafos de dispersión.
• Demostrar el interés en la aplicación de los estadígrafos.
• Comprender como se desarrollan y se aplica las medidas de tendencia central
[estadígrafos de posición] y los estadígrafos de dispersión.
I.2 Marco Teórico
I.2.1 DISTRIBUCIÓN DE FRECUENCIAS
La distribución de frecuencias es un método para organizar y resumir datos. Con este
método los datos que componen una serie se clasifican y ordenan indicándose el
número de veces que se repite el valor.
ELABORACIÓN DE UNA TABLA DE FRECUENCIAS
Variable Discreta.- es necesario familiarizarse con algunos símbolos.
n = tamaño muestra
N = tamaño población
X i = identificación de cada valor observado
n i = frecuencia absoluta
h i = frecuencia relativa
N i = frecuencia absoluta acumulada
H i = frecuencia relativa acumulada

3 UTA Ing. M.B.A William Teneda
Y i = indican los valores que toman las variables
y’ i = marca de clase
m = número de valores que toma la variable Yi. También se
considera el número de intervalos o marcas de clase en la variable.
Ejercicio.
Supongamos una población constituida por 200 cajas y se desea examinarlas,
determinándose el número de piezas defectuosas que contiene cada caja. Por
diferentes razones se desea que la investigación no sea exhaustiva, es decir
seleccionar una muestra de tamaño 20, correspondiendo a una investigación
parcial.
N = 200 n = 20
El resultado de esta encuesta, se anota a continuación, siendo X1 la primera
caja examinada y 3 el número de piezas defectuosas encontradas en esa caja.
x1= 3 x6= 3 x11= 3 x16= 2
x2= 2 x7= 1 x12= 3 x17= 4
X3= 0 X8= 1 X13= 4 X18= 2
x4= 2 x9= 0 x14= 4 x19= 4
x5= 3 x10= 1 x15= 3 x20= 2
Variable contínua.- debemos conocer
m = número de intervalos
c = amplitud del ancho del intervalo
Yi ni hi Ni Hi
0 2 0,10 2 0,101 3 0,15 5 0,252 5 0,25 10 0,503 6 0,30 16 0,804 4 0,20 20 1,00
20 1 ---- ----

4 UTA Ing. M.B.A William Teneda
𝑐𝑐 =𝑋𝑋 𝑚𝑚á𝑥𝑥 − 𝑋𝑋 𝑚𝑚í𝑛𝑛
𝑚𝑚
Histograma, usado para variables continuas. En el eje OX se señalan los extremos de
los intervalos. Se construyen unos rectángulos de base la amplitud del intervalo y de
altura la frecuencia absoluta.
Polígono de frecuencias, se obtiene uniendo los puntos medios de los segmentos
superiores de los rectángulos del diagrama.
Gráfico de sectores, es el resultado de dividir un círculo en sectores circulares de
ángulos proporcionales a las frecuencias absolutas de cada valor de la variable. Para
calcular los grados de cada sector se divide la frecuencia entre el número de datos y
se multiplica por 360.Se utiliza para variable discreta y continua.
1.2.2. MEDIDAS DE TENDENCIA CENTRAL [ESTADÍGRAFOS DE POSICIÓN]
Estas medidas tienden a ubicarse en el centro del conjunto.
Proporcionan un valor simple y representativo, que resume un gran volumen de
información.
1. Media Aritmética
2. Mediana
3. Moda
4. Media Geométrica
5. Media Armónica
6. Media Cuadrática
7. Media Cúbica
8. Cuartiles, Deciles y Percentiles
1. Media Artimética

5 UTA Ing. M.B.A William Teneda
La media aritmética se puede calcular para datos agrupados y no agrupados.
La media aritmética de un conjunto de valores x1 , x2, x3,............xn se obtiene
sumando todos los valores y dividiendo por el número de datos n.
XI= 1,26 X=
X2=1,75 n
Exi
X3= 1,64 x=
X4= 1,45 n
x1+x2+x3+x4+x5
X5= 1,38 x= 1,25+1,75+1,64+1,45+1,38 = 7,47
5 5
= 1,44
Y’1 – y2 ni yi yini Ni
2 – 4 1 3 3 1
4 – 6 3 5 15 4
6 – 8 7 7 49 11
8 – 10 2 9 18 13
10 – 12 4 11 44 17
Eni= 17 Exiyi= 129
X=
nT
Exini
X= 129
17
= 1,58
2. Mediana

6 UTA Ing. M.B.A William Teneda
De un conjunto ordenado de datos es aquel valor tal que la mitad de los datos
son iguales o inferiores a él y la otra mitad son iguales o superiores.
Si el número de datos es pequeño los ordenamos y cogemos el valor central.
Caso 1: Cuando el número de datos es impar:
Si los valores son 4,6,4,5,7,3,9. Los ordenamos 3,4,4,5,6,7,9, cómo son 7
datos
cogemos el dato que ocupa el lugar 4 que es 5.
Caso 2: Cuando el número de datos es impar:
Si los valores son 4,6,5,7,3,9. Los ordenamos 3,4,5,6,7,9, cómo son 6 datos
cogemos los datos que ocupan el lugar 3 que es 5 y el lugar 4 que es 6. la
mediana es la media de los dos números es este caso 5,5 =(5+6)/2
ejercicios de mediana
Y’1 – y2 ni yi yini Ni
2 – 4 1 3 3 1
4 – 6 3 5 15 4
6 – 8 7 7 49 11
8 – 10 2 9 18 13
10 – 12 4 11 44 17
me = yj-1+c (
Nj
(n/2) – Nj -1
me = 6+2 ( 3.5 +4
11
)
me = 6 + 2 +
11
4.5
me = 6.81
3. Moda
La moda de un conjunto de datos es el dato que tiene mayor frecuencia.
El intervalo modal es el de mayor frecuencia absoluta. Cuando tratamos con
datos agrupados antes de definir la moda, se ha de definir el intervalo modal.

7 UTA Ing. M.B.A William Teneda
La moda, cuando los datos están agrupados, es un punto que divide al
intervalo modal en dos partes de la forma p y c-p, siendo c la amplitud del
intervalo, que verifiquen
que:
Siendo la frecuencia absoluta del intervalo modal las frecuencias absolutas de
los intervalos anterior y posterior, respectivamente, al intervalo modal.
ejercicios de moda
Y’1 – y2 ni Yi yini Ni
2 – 4 1 3 3 1
4 – 6 3 5 15 4
• 6 – 8 7 7 49 11
8 – 10 2 9 18 13
10 – 12 4 11 44 17
md = yj-1+c (
nj+1+nj-1
(nj+1) )
md = 6+2 ( 2 )
2+8
md = 6 +
5
4
md = 6.8
4. Media Geométrica
Es considerada como una medida de posición simbolizada por Mo y su
resultado al ser calculado debe estar comprendido entre la media armónica y la
aritmética.

8 UTA Ing. M.B.A William Teneda
Sea una distribución de frecuencias (x , n ). La media geométrica, que
denotaremos por G. se define como la raíz N-ésima del producto de los N
valores de la distribución.
Si los datos están agrupados en intervalos, la expresión de la media
geométrica, es la misma, pero utilizando la marca de clase (Xi).
El empleo más frecuente de la media geométrica es el de promediar variables
tales como porcentajes, tasas, números índices. etc., es decir, en los casos en
los que se supone que la variable presenta variaciones acumulativas.
Ventajas e inconvenientes:
- En su cálculo intervienen todos los valores de la distribución.
- Los valores extremos tienen menor influencia que en la media aritmética.
- Es única.
- Su cálculo es más complicado que el de la media aritmética.
Además, cuando la variable toma al menos un x = 0 entonces G se anula, y si
la variable toma valores negativos se pueden presentar una gama de casos
particulares en los que tampoco queda determinada debido al problema de las
raíces de índice par de números negativos.
5. Media Armónica
Se utiliza como una medida de tendencia central para conjunto que consisten
en caja de cambios.
La media armónica, que representaremos por H, se define como sigue:

9 UTA Ing. M.B.A William Teneda
Es la inversa de la media aritmética de las inversas de los valores de la variable,
responde a la siguiente expresión:
....3
3
21
2
1
1 +++==
∑ xn
xn
xn
n
xn
nH
i
i
Obsérvese que la inversa de la media armónica es la media aritmética de los
inversos de los valores de la variable. No es aconsejable en distribuciones de
variables con valores pequeños. Se suele utilizar para promediar variables tales
como productividades, velocidades, tiempos, rendimientos, cambios, etc.
Ventajas e inconvenientes:
- En su cálculo intervienen todos los valores de la distribución.
- Su cálculo no tiene sentido cuando algún valor de la variable toma valor
cero.
- Es única.
· Relación entre las medias:
ejercicio de media armónica X1=0,15 M-1 = n = Q 3
X2=0,18 E(/xi) (1/0,15)+(1/0,18)+(1/0,17)
G
X3=0,17 M-1= 0,165
M-1 = n = Q 10
E(/Yi) 0,0614
G
M-1= 162,866

10 UTA Ing. M.B.A William Teneda
6. Media Cuadrática
La media cuadrática es igual a la raíz cuadrada de la suma de los cuadrados
de los valores dividida entre el número de datos:
Esta media como medida de asociación tiene aplicaciones tanto en ciencias
biológicas como en medicina.
A veces la variable toma valores positivos y negativos, como ocurre, por
ejemplo, en los errores de medida. En tal caso se puede estar interesado en
obtener un promedio que no recoja los efectos del signo. Este problema se
resuelve, mediante la denominada media cuadrática. Consiste en elevar al
cuadrado todas las observaciones (así los signos negativos desaparecen), en
obtener después su media aritmética y en extraer, finalmente, la raíz cuadrada
de dicha media para volver a la unidad de medida original.
ejercicio de media cuadrática
m2 = √ Eyi2*ni = √1020
n 20
= 7,4
7. Media Cúbica
La media cúbica es una medida derivada de la media aritmética y consiste en
obtener el valor del lado que tiene el cubo media de un conjunto de n cubos.
yi ni Yi*ni Yi2*ni
2
4
6
8
10
2
3
5
6
4
4
12
30
48
40
8
48
180
384
400
1020

11 UTA Ing. M.B.A William Teneda
ejercicio de media cubica X1= 5 X2=6 m3 = √
X3=10 5
53+63+103+123+73
X4=12 m3= 8,80
X5=7
8. Cuartiles, Deciles y Percentiles
Los cuartiles son los tres valores de la variable que dividen a un conjunto de
datos Ordenados en cuatro partes iguales.
Q1, Q2 y Q3 determinan los valores correspondientes al 25%, al 50% y al 75%
de los datos. Q2 coincide con la mediana.
Los deciles son los nueve valores que dividen la serie de datos en diez partes
iguales. Los deciles dan los valores correspondientes al 10%, al 20%... y al
90% de los datos. D5 coincide con la mediana.
Los percentiles son los 99 valores que dividen la serie de datos en 100 partes
iguales. Los percentiles dan los valores correspondientes al 1%, al 2%... y al
99% de los datos. P50 coincide con la mediana.
I.2.3 ESTADIGRAFOS DE DISPERSION
Se llaman medidas de dispersión aquellas que permiten retratar la distancia de los
valores de la variable a un cierto valor central, o que permiten identificar la
concentración de los datos en un cierto sector del recorrido de la variable. Se trata
de coeficiente para variables cuantitativas.
1. Varianza
2. Desviación Típica
3. Desviación Media
12 UTA Ing. M.B.A William Teneda
1. Varianza
Varianza: Es la media de los cuadrados de las desviaciones de los datos
respecto a la media.
2. Desviación Típica
Desviación Típica: Es la raíz cuadrada de la varianza. Se calcula aplicando
esta fórmula.
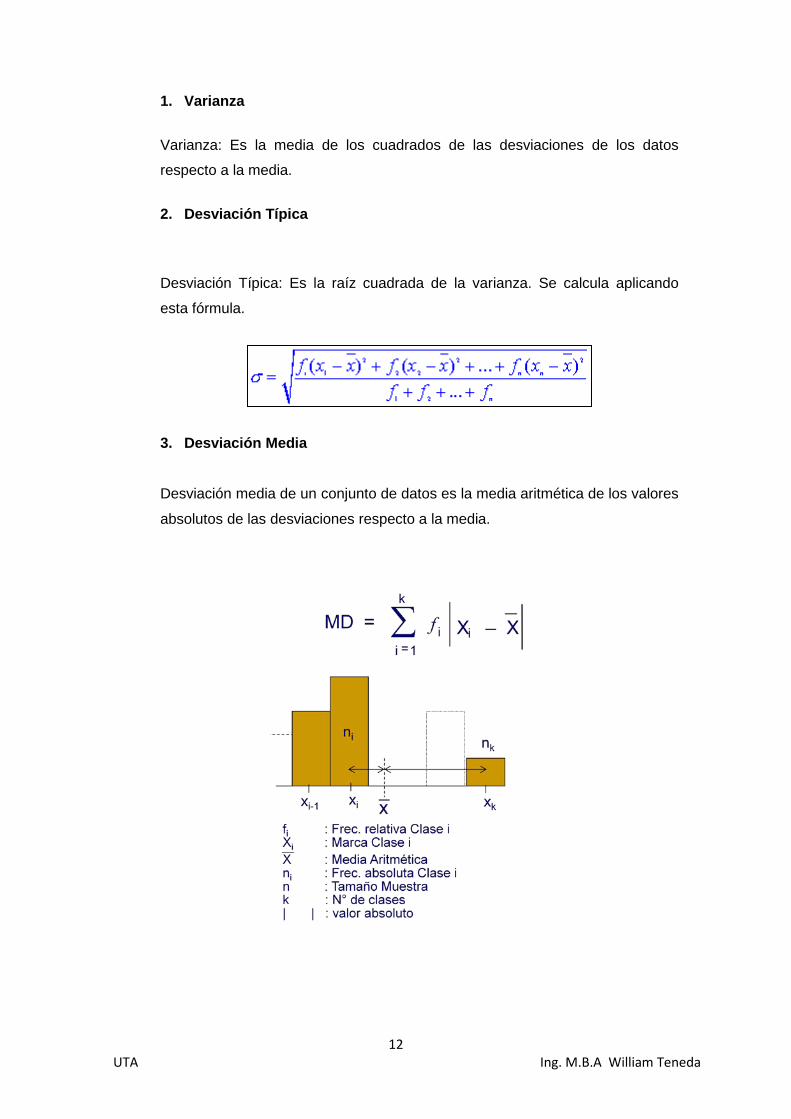
3. Desviación Media
Desviación media de un conjunto de datos es la media aritmética de los valores
absolutos de las desviaciones respecto a la media.

13 UTA Ing. M.B.A William Teneda
I.3 Términos y Conceptos claves
Variable.- una variable es una cantidad sujeta a variación existen 2 tipos de variables;
las cuantitativas y cualitativas.
Dentro de las variables cuantitativas podemos distinguir las variables discretas y las
variables continuas.
a) Variables Discretas .- valores enteros
b) Variables Continuas.- valores fraccionables
Tablas Y Graficas.- la presencia de datos en una investigación se las puede
representar de varias formas que pueden ser: textuales, cuadros o tablas y gráficas.
I.4 Preguntas y Problemas i. Las notas de una estudiante han sido 85, 76, 93, 82 y 96. Calcular los
estadígrafos de posición y de dispersión. ii. Un conjunto de números contiene 6 seises, 7 sietes, 8 ochos, 9 nueves y 10
dieces. Calcular los estadígrafos de posición y de dispersión. iii. Tres profesores de economía dieron notas medias en sus cursos, con 32, 25 y
17 estudiantes de 79, 74 y 82 puntos, respectivamente. Hallar la puntuación
media de los tres cursos.
I.5 Bibliografía Complementaria
• Robert Pagano. Estadística Para Las Ciencias Del Comportamiento 7 Edición.
Editorial – Thomson. Impreso En Litograf Nueva Época. Enero 2006, México Df
• Estadística De Gilbert. Editorial – Interamericana Impreso En México 1980.
Primera Edición
• Estadística De Schaum. Segunda Edición. Editorial – Mcgraw – Hill.
• Ronald E. Walpole, Raymond H. Myers. Probabilidad Y
Estadística. Editorial: 2007 Pearson Education De Mexico
• Jack R. Benjamin. Probabilidad Y Estadistica. Editorial: 1981
Mcgraw–Hill Latinoamericana Editores S.A De C.V.
• Probabilidad Y Estadistica. William Navidi. Editorial: Mcgraw –
Hill/Interamericana Editores S.A De C.V. Edicon 2006.

14 UTA Ing. M.B.A William Teneda
• Probabilidad Y Estadistica. Autor: J. Susan Milton Y Jesse C. Arnold. Editorial:
Mcgraw – Hill/Interamericana Editores S.A De C.V. Octava Ediciòn.
• Ronald E.; Raymond H. Probabilidad Y Estadística Para Ingeniería Y Ciencias.
Editorial: Pearson Educación “Printed In México”. Año: Octava Edición 2007.
• Ciro Matìnez Bencardino. Estadística Básica, Probabilidad Y Estadística.
Editorial: Ecoe Ediciones. Quinta Edición ,Agosto De 1990

15 UTA Ing. M.B.A William Teneda
CAPITULO II
REGRESION Y CORRELACION
2.1Objetivos
• Emplear adecuadamente los diferentes tipos de regresiones.
• Dominar la utilización de las regresiones.
2.2Marco Teórico
REGRESIONES
La regresión es una técnica estadística utilizada para simular la relación existente
entre dos o más variables. Por lo tanto se puede emplear para construir un modelo
que permita predecir el comportamiento de una variable dada.
La regresión es muy utilizada para interpretar situaciones reales, pero comúnmente se
hace de mala forma, por lo cual es necesario realizar una selección adecuada de las
variables que van a construir las ecuaciones de la regresión, ya que tomar variables
que no tengan relación en la práctica, nos arrojará un modelo carente de sentido, es
decir ilógico.
Según sea la dispersión de los datos (nube de puntos) en el plano cartesiano, pueden
darse alguna de las siguientes relaciones, Lineal, Logarítmica, Exponencial,
Cuadrática, entre otras.
Regresión Lineal El objetivo de la técnica de regresión es establecer la relación estadística que existe
entre la variable dependiente (Y) y una o más variables independientes (X1, X2,… Xn).
Para poder realizar esto, se postula una relación funcional entre las variables. Que en
la práctica es la relación lineal:
ŷ= b0 + b1x1 +… bnxn
donde los coeficientes b0 y b1, … bn, son los parámetros que definen la variación
promedio de y, para cada valor de x..

16 UTA Ing. M.B.A William Teneda
El análisis de regresión se utiliza para fines de predicción. Y el análisis de correlación
se utiliza para medir la fuerza de la asociación entre las variables cuantitativas.
- El parámetro b0, conocido como la “ordenada en el origen,” nos indica cuánto es Y
cuando X = 0. El parámetro b1, conocido como la “pendiente,” nos indica cuánto
aumenta Y por cada aumento en X.
- La técnica consiste en obtener estimaciones de estos coeficientes a partir de una
muestra de observaciones sobre las variables Y y X.
REGRESIÓN POLINOMIAL
En situaciones donde la relación funcional entre la respuesta Y y la variable independiente x no se puede aproximar de manera adecuada mediante una relación lineal, es, algunas veces, posible obtener un ajuste razonable considerando una relación polinomial. Es decir, podemos ajustar el conjunto de datos a una relación funcional de la forma:
Y = Bo + Box + B2x2 + Brxr + e
Donde B0, B1,…, Br son coeficientes de regresión que tienen que estimarse. Si los datos constan de los n pares (.xi, Yi), i= 1,…..,n, entonces los estimadores de mínimos cuadrados de, B0,.....,Br— llamémoslos BO,..., Br— son aquellos valores que minimizan
Para determinar estos valores, obtenemos las derivadas parciales de la suma de cuadrados anterior, respecto a BO,... Br, y luego, igualamos a cero con el objetivo de determinar los valores minimizantes. Al hacer esto y reordenando después las ecuaciones resultantes, obtenemos que los estimadores de mínimos cuadrados, BO,BI,…Br satisfacen el conjunto de r + 1 ecuaciones lineales, llamadas ecuaciones normales.

17 UTA Ing. M.B.A William Teneda
Al ajustar una función polinomial a un conjunto de pares de datos, con
frecuencia es posible determinar el grado necesario del polinomio mediante un estudio del diagrama de dispersión. Que queremos enfatizar que siempre se debe usar el menor grado posible que parezca describir los datos adecuadamente. (Así, por ejemplo, aunque normalmente es posible encontrar un polinomio de grado n que pase por todos los n pares (xi, Yi), i=1,…,n, sería difícil tener mucha confianza en tal ajuste.)
- Resulta muy arriesgado, aún más que en el caso de la regresión lineal, usar un polinomio ajustado para predecir el valor de una respuesta a un nivel de entrada x0
que este lejos de los niveles de entrada xi, i=1,…,n usados para encontrar el polinomio de ajuste. (El polinomio de ajuste puede ser válido sólo en una región alrededor de las xi, i=1,…,n y no incluir a x0).
Regresión Lineal Múltiple
• Muchas aplicaciones del análisis de regresión involucran situaciones donde se
tiene más de una variable de regresión. Un modelo de regresión que contiene más
de un regresor recibe el nombre de modelo de regresión múltiple
• Como ejemplo, supóngase que la vida eficaz de una herramienta de corte depende
de la velocidad de corte y del ángulo de la herramienta. Un modelo de regresión
múltiple que puede describir esta relación es el siguiente
• 𝑦𝑦 = 𝛽𝛽𝑜𝑜 + 𝛽𝛽1𝑥𝑥1 + 𝛽𝛽2𝑥𝑥2 + є

18 UTA Ing. M.B.A William Teneda
FORMULAS PARA EL CALCULO DE REGRESIONES
1. REGRESION LINEAL: 𝑦𝑦� = 𝑏𝑏0 + 𝑏𝑏1𝑥𝑥
y 𝑦𝑦� = 𝑏𝑏0 + 𝑏𝑏1𝑥𝑥
𝑏𝑏1 =𝑛𝑛∑𝑥𝑥𝑥𝑥𝑦𝑦𝑥𝑥 − (∑𝑥𝑥𝑥𝑥)(∑𝑦𝑦𝑥𝑥)𝑛𝑛∑𝑥𝑥2 𝑥𝑥 − (∑𝑥𝑥𝑥𝑥) 2
𝑏𝑏0 = ∑𝑦𝑦𝑥𝑥𝑛𝑛− 𝑏𝑏1 ∑𝑥𝑥𝑥𝑥
𝑛𝑛
𝑟𝑟2 =𝑏𝑏0 ∑𝑦𝑦𝑥𝑥 + 𝑏𝑏1 ∑𝑥𝑥𝑥𝑥𝑦𝑦𝑥𝑥 −
1𝑛𝑛 (∑𝑦𝑦𝑥𝑥) 2
∑(𝑦𝑦 𝑥𝑥2) − 1𝑛𝑛 (∑𝑦𝑦𝑥𝑥) 2
∑𝑦𝑦𝑥𝑥 = 𝑛𝑛𝑏𝑏0 + 𝑏𝑏1 ∑𝑥𝑥𝑥𝑥
∑𝑥𝑥𝑥𝑥𝑦𝑦𝑥𝑥 = 𝑏𝑏0 ∑𝑥𝑥𝑥𝑥 + 𝑏𝑏1 ∑𝑥𝑥𝑥𝑥2 x
2. REGRESION LOGARITMICA: 𝑦𝑦� = 𝑏𝑏0 + 𝑏𝑏1𝑙𝑙𝑛𝑛𝑥𝑥
𝑏𝑏1 = 𝑛𝑛 ∑(𝑙𝑙𝑛𝑛𝑥𝑥𝑥𝑥 )𝑦𝑦𝑥𝑥−(∑ 𝑙𝑙𝑛𝑛𝑥𝑥𝑥𝑥 )(∑𝑦𝑦𝑥𝑥 )𝑛𝑛 ∑ 𝑙𝑙𝑛𝑛𝑥𝑥 2𝑥𝑥−(∑𝑙𝑙𝑛𝑛𝑥𝑥𝑥𝑥 ) 2 y
𝑏𝑏0 =∑𝑦𝑦𝑥𝑥𝑛𝑛
−𝑏𝑏1 ∑ 𝑙𝑙𝑛𝑛𝑥𝑥𝑥𝑥
𝑛𝑛
𝑟𝑟2 =𝑏𝑏0 ∑𝑦𝑦𝑥𝑥+𝑏𝑏1 ∑(𝑙𝑙𝑛𝑛𝑥𝑥𝑥𝑥 )𝑦𝑦𝑥𝑥−1
𝑛𝑛(∑𝑦𝑦𝑥𝑥 ) 2
∑(𝑦𝑦𝑥𝑥2)−1𝑛𝑛(∑𝑦𝑦𝑥𝑥) 2 𝑦𝑦� = 𝑏𝑏0 + 𝑏𝑏1𝑙𝑙𝑛𝑛𝑥𝑥
∑𝑦𝑦𝑥𝑥 = 𝑛𝑛𝑏𝑏0 + 𝑏𝑏1 ∑ 𝑙𝑙𝑛𝑛𝑥𝑥𝑥𝑥
∑(𝑙𝑙𝑛𝑛𝑥𝑥𝑥𝑥)𝑦𝑦𝑥𝑥 = 𝑏𝑏0 ∑ 𝑙𝑙𝑛𝑛𝑥𝑥𝑥𝑥 + 𝑏𝑏1 ∑ 𝑙𝑙𝑛𝑛𝑥𝑥𝑥𝑥2
x

19 UTA Ing. M.B.A William Teneda
3. REGRESION EXPONENCIAL: 𝑙𝑙𝑛𝑛𝑦𝑦� = 𝑙𝑙𝑛𝑛𝑏𝑏0 + 𝑏𝑏1𝑥𝑥 y
𝑏𝑏1 = 𝑛𝑛 ∑𝑥𝑥𝑥𝑥(𝑙𝑙𝑛𝑛𝑦𝑦𝑥𝑥 )−(∑𝑥𝑥𝑥𝑥)(∑𝑙𝑙𝑛𝑛𝑦𝑦𝑥𝑥 )𝑛𝑛 ∑𝑥𝑥2𝑥𝑥−(∑𝑥𝑥𝑥𝑥) 2 𝑦𝑦� = 𝑎𝑎𝑒𝑒𝑏𝑏𝑥𝑥
𝑙𝑙𝑛𝑛𝑏𝑏0 = ∑ 𝑙𝑙𝑛𝑛𝑦𝑦𝑥𝑥𝑛𝑛
− 𝑏𝑏1 ∑𝑥𝑥𝑥𝑥𝑛𝑛
𝑙𝑙𝑛𝑛𝑦𝑦� = 𝑙𝑙𝑛𝑛𝑏𝑏0 + 𝑏𝑏1𝑥𝑥
𝑟𝑟2 =𝑙𝑙𝑛𝑛𝑏𝑏0 ∑ 𝑙𝑙𝑛𝑛𝑦𝑦𝑥𝑥 + 𝑏𝑏1 ∑𝑥𝑥𝑥𝑥(𝑙𝑙𝑛𝑛𝑦𝑦𝑥𝑥) −
1𝑛𝑛 (∑ 𝑙𝑙𝑛𝑛𝑦𝑦𝑥𝑥) 2
∑(𝑙𝑙𝑛𝑛𝑦𝑦 𝑥𝑥2)− 1𝑛𝑛 (∑ 𝑙𝑙𝑛𝑛𝑦𝑦𝑥𝑥) 2
∑ 𝑙𝑙𝑛𝑛𝑦𝑦𝑥𝑥 = 𝑛𝑛𝑙𝑙𝑛𝑛𝑏𝑏0 + 𝑏𝑏1 ∑𝑥𝑥𝑥𝑥
∑𝑥𝑥𝑥𝑥(𝑙𝑙𝑛𝑛𝑦𝑦𝑥𝑥) = 𝑙𝑙𝑛𝑛𝑏𝑏0 ∑𝑥𝑥𝑥𝑥 + 𝑏𝑏1 ∑𝑥𝑥𝑥𝑥2 x
4. REGRESION POTENCIAL: 𝑙𝑙𝑛𝑛𝑦𝑦� = 𝑙𝑙𝑛𝑛𝑏𝑏0 + 𝑏𝑏1𝑙𝑙𝑛𝑛𝑥𝑥 y
𝑏𝑏1 = 𝑛𝑛 ∑ 𝑙𝑙𝑛𝑛𝑥𝑥𝑥𝑥 (𝑙𝑙𝑛𝑛𝑦𝑦𝑥𝑥 )−(∑𝑙𝑙𝑛𝑛𝑥𝑥𝑥𝑥 )(∑𝑙𝑙𝑛𝑛𝑦𝑦𝑥𝑥 )𝑛𝑛 ∑ 𝑙𝑙𝑛𝑛𝑥𝑥 𝑥𝑥2−(∑ 𝑙𝑙𝑛𝑛𝑥𝑥𝑥𝑥 ) 2 𝑦𝑦� = 𝑎𝑎𝑥𝑥𝑏𝑏
𝑙𝑙𝑛𝑛𝑏𝑏0 = ∑ 𝑙𝑙𝑛𝑛𝑦𝑦𝑥𝑥𝑛𝑛
− 𝑏𝑏1 ∑ 𝑙𝑙𝑛𝑛𝑥𝑥𝑥𝑥𝑛𝑛
𝑙𝑙𝑛𝑛𝑦𝑦� = 𝑙𝑙𝑛𝑛𝑏𝑏0 + 𝑏𝑏1𝑙𝑙𝑛𝑛𝑥𝑥
𝑟𝑟2 =𝑙𝑙𝑛𝑛𝑏𝑏0 ∑ 𝑙𝑙𝑛𝑛𝑦𝑦𝑥𝑥 + 𝑏𝑏1 ∑ 𝑙𝑙𝑛𝑛𝑥𝑥𝑥𝑥(𝑙𝑙𝑛𝑛𝑦𝑦𝑥𝑥) −
1𝑛𝑛 (∑ 𝑙𝑙𝑛𝑛𝑦𝑦𝑥𝑥) 2
∑(𝑙𝑙𝑛𝑛𝑦𝑦 𝑥𝑥2)− 1𝑛𝑛 (∑ 𝑙𝑙𝑛𝑛𝑦𝑦𝑥𝑥) 2
∑ 𝑙𝑙𝑛𝑛𝑦𝑦𝑥𝑥 = 𝑛𝑛𝑙𝑙𝑛𝑛𝑏𝑏0 + 𝑏𝑏1 ∑ 𝑙𝑙𝑛𝑛𝑥𝑥𝑥𝑥
∑(𝑙𝑙𝑛𝑛𝑥𝑥𝑥𝑥)(𝑙𝑙𝑛𝑛𝑦𝑦𝑥𝑥) = 𝑙𝑙𝑛𝑛𝑏𝑏0 ∑ 𝑙𝑙𝑛𝑛𝑥𝑥𝑥𝑥 + 𝑏𝑏1 ∑ 𝑙𝑙𝑛𝑛𝑥𝑥𝑥𝑥2
5. REGRESION CUADRATICA: 𝑦𝑦� = 𝑏𝑏0 + 𝑏𝑏1𝑥𝑥 + 𝑏𝑏2𝑥𝑥2
1) ∑𝑦𝑦 = 𝑛𝑛𝑏𝑏0 + 𝑏𝑏1 ∑𝑥𝑥 + 𝑏𝑏2 ∑𝑥𝑥2 2) ∑𝑥𝑥𝑦𝑦 = 𝑏𝑏0 ∑𝑥𝑥 + 𝑏𝑏1 ∑𝑥𝑥2 + 𝑏𝑏2 ∑𝑥𝑥3 3) ∑𝑥𝑥2𝑦𝑦 = 𝑏𝑏0 ∑𝑥𝑥2 + 𝑏𝑏1 ∑𝑥𝑥3 + 𝑏𝑏2 ∑𝑥𝑥4
𝑟𝑟2 =𝑏𝑏0 ∑𝑦𝑦 + 𝑏𝑏1 ∑𝑥𝑥𝑦𝑦 + 𝑏𝑏2 ∑𝑥𝑥2𝑦𝑦 − 1
𝑛𝑛 (∑𝑦𝑦) 2
∑(𝑦𝑦2)− 1𝑛𝑛 (∑𝑦𝑦) 2

20 UTA Ing. M.B.A William Teneda
6. REGRESION CUBICA: 𝑦𝑦� = 𝑏𝑏0 + 𝑏𝑏1𝑥𝑥 + 𝑏𝑏2𝑥𝑥2 + 𝑏𝑏3𝑥𝑥3 1) ∑𝑦𝑦 = 𝑛𝑛𝑏𝑏0 + 𝑏𝑏1 ∑𝑥𝑥 + 𝑏𝑏2 ∑𝑥𝑥2 + 𝑏𝑏3 ∑𝑥𝑥3 2) ∑𝑥𝑥𝑦𝑦 = 𝑏𝑏0 ∑𝑥𝑥 + 𝑏𝑏1 ∑𝑥𝑥2 + 𝑏𝑏2 ∑𝑥𝑥3 + 𝑏𝑏3 ∑𝑥𝑥4 3) ∑𝑥𝑥2𝑦𝑦 = 𝑏𝑏0 ∑𝑥𝑥2 + 𝑏𝑏1 ∑𝑥𝑥3 + 𝑏𝑏2 ∑𝑥𝑥4 + 𝑏𝑏3 ∑𝑥𝑥5 4) ∑𝑥𝑥3𝑦𝑦 = 𝑏𝑏0 ∑𝑥𝑥3 + 𝑏𝑏1 ∑𝑥𝑥4 + 𝑏𝑏2 ∑𝑥𝑥5 + 𝑏𝑏3 ∑𝑥𝑥6
𝑟𝑟2 =𝑏𝑏0 ∑𝑦𝑦 + 𝑏𝑏1 ∑𝑥𝑥𝑦𝑦 + 𝑏𝑏2 ∑𝑥𝑥2𝑦𝑦 + 𝑏𝑏3 ∑𝑥𝑥3 𝑦𝑦 − 1
𝑛𝑛 (∑𝑦𝑦) 2
∑(𝑦𝑦2)− 1𝑛𝑛 (∑𝑦𝑦) 2
7. REGRESION MULTIPLE: 1) ∑𝑦𝑦 = 𝑛𝑛𝑏𝑏0 + 𝑏𝑏1 ∑𝑥𝑥1 + 𝑏𝑏2 ∑𝑥𝑥2 2) ∑𝑥𝑥1𝑦𝑦 = 𝑏𝑏0 ∑𝑥𝑥1 + 𝑏𝑏1 ∑𝑥𝑥1
2 + 𝑏𝑏2 ∑𝑥𝑥1𝑥𝑥2 3) ∑𝑥𝑥2𝑦𝑦 = 𝑏𝑏0 ∑𝑥𝑥2 + 𝑏𝑏1 ∑𝑥𝑥1𝑥𝑥2 + 𝑏𝑏2 ∑𝑥𝑥2
2
𝑟𝑟2 =𝑏𝑏0 ∑𝑦𝑦 + 𝑏𝑏1 ∑𝑥𝑥𝑦𝑦 + 𝑏𝑏2 ∑𝑥𝑥2𝑦𝑦 −
1𝑛𝑛 (∑𝑦𝑦) 2
∑(𝑦𝑦2) − 1𝑛𝑛 (∑𝑦𝑦) 2
2.3Términos y Conceptos claves
• Interpretación de los Coeficientes de Regresión:
Interpretación del intercepto :
Indica el valor promedio de la variable de respuesta Y cuando X es cero. Si se tiene
certeza de que la variable predictoria X no puede asumir el valor 0, entonces la
interpretación no tiene sentido.
Interpretación de la pendiente :
Indica el cambio promedio en la variable de respuesta Y cuando X se incrementa
en una unidad.
• Análisis de Residuales
Un residual es la diferencia entre el valor observado y el valor estimado por
la línea de regresión ,
El residual puede ser considerado como el error aleatorio observado.

21 UTA Ing. M.B.A William Teneda
2.4 Problemas
Se desea desarrollar un modelo de regresión polinómica para predecir la temperatura ambiente para la calefacción doméstica durante el mes de enero en función del consumo de combustible ambiente.
Observación Temperatura
Ambiente Consumo Mensual De
Petróleo Cantidad De Aislamiento
(Diaria Promedio) Para Calefacción [Galones] En El Ático
[°F] [Pulgadas]
1 40 27,5 3
2 27 36,4 3
3 40 16,4 10
4 73 4,1 6
5 64 9,4 6
6 34 23,1 6
7 9 36,7 6
Regresión Cúbica
X1 Y Y2 X1Y X21Y X3
1Y
27,5 40 1600 1100 30250 831875
36,4 27 729 982,8 35773,92 1302171
16,4 40 1600 656 10758,4 176437,8
4,1 73 5329 299,3 1227,13 5031,233
9,4 64 4096 601,6 5655,04 53157,38
23,1 34 1156 785,4 18142,74 419097,3
36,7 9 81 330,3 12122,01 444877,8
153,6 287 14591 4755,4 113929,24 3232647

22 UTA Ing. M.B.A William Teneda
X21 X3
1 X41 X5
1 X61
756,25 20796,875 571914,063 15727636,72 432510009,8
1324,96 48228,544 1755519 63900891,66 2325992456
268,96 4410,944 72339,4816 1186367,498 19456426,97
16,81 68,921 282,5761 1158,56201 4750,104241
88,36 830,584 7807,4896 73390,40224 689869,7811
533,61 12326,391 284739,632 6577485,502 151939915,1
1346,89 49430,863 1814112,67 66577935,07 2443410217
4335,84 136093,122 4506714,92 154044865,4 5374003645
Fórmulas
321
bbbbo
=
∑∑∑∑
YXYX
XYY
31
21
Matriz Inversa
∑∑∑∑∑∑∑∑∑∑∑∑∑∑∑
61
51
41
31
51
41
31
21
41
31
211
31
211
xxxxxxxxxxxxxxxn
=
3232647,12113929,24
4755,4287
53740036454154044865,64506714,91136093,1224154044865,64506714,91136093,1224335,8464506714,91136093,1224335,84153,6
136093,1224335,84153,67
321
bbbbo
07-2,08942E05-1,30796E-0,000225760,00091455-05-1,30796E-80,000830680,01463819-0,060961830,0002257610,01463819-0,266422941,16835825-
0,00091455-60,060961791,16835825-5,80046665
=
321
bbbbo
3232647,12113929,24
4755,4287

23 UTA Ing. M.B.A William Teneda
7902272251 -0,003591836379108 0,243669352
7294009 -6,27687081670896 97,6351505
====
bbbbo
Ecuación Cúbica
bo X b1 X b2 X b3 Y 23 +++=
Y = -0,0036X3 + 0,2437X2 - 6,2769X+ 97,635
Coeficiente De Determinación Y De Correlación
22
232
2
)(1)(
)(1321
∑∑
∑ ∑ ∑ ∑∑−
−+++=
Yn
Y
Yn
YXbYXbXYbYboR
28246127732555,043672 =R
85438150,904760502 =R
72785720,95118899=R
Gráfica:
0
20
40
60
80
0 10 20 30 40
Consumo De Combustible [Galones]
Tem
pera
tura
Pro
med
io
Diar
ia [°
F]

24 UTA Ing. M.B.A William Teneda
¿Qué temperatura debería tener el ambiente si el consumo de tuviera 35 galones para el modelo utilizado en el literal anterior?
Y = -0,0036X3 + 0,2437X2 - 6,2769X+ 97,635
Y= 22,4378184793661 °F
Regresión Cuadrática
X1 Y Y2 X1Y X21Y X2
1 X31 X4
1
27,5 40 1600 1100 30250 756,25 20796,875 571914,063
36,4 27 729 982,8 35773,92 1324,96 48228,544 1755519
16,4 40 1600 656 10758,4 268,96 4410,944 72339,4816
4,1 73 5329 299,3 1227,13 16,81 68,921 282,5761
9,4 64 4096 601,6 5655,04 88,36 830,584 7807,4896
23,1 34 1156 785,4 18142,74 533,61 12326,391 284739,632
36,7 9 81 330,3 12122,01 1346,89 49430,863 1814112,67
153,6 287 14591 4755,4 113929,24 4335,84 136093,122 4506714,92
Formulas
∑∑∑∑∑∑∑∑
41
31
21
31
211
211
xxxxxxxxn
21
bbbo
=
∑∑∑
YXYX
Y
21
1
4506714,92136093,1224335,84136093,1224335,84153,6
4335,84153,67
21
bbbo
=
113929,244755,4
287

25 UTA Ing. M.B.A William Teneda
Matriz Inversa
Ecuación Cuadrática
boXbXbY ++= 12 2
81,913 2,3958X - 0,0188X 2 +=Y
Coeficiente De Determinación Y De Correlación
22
22
2
)(1)(
)(121
∑∑
∑ ∑ ∑ ∑−
−++=
Yn
Y
Yn
YXbXYbYboR
28246645952493,296282 =R
56395020,882895282 =R
71661540,93962507=R
Grafico:
05-1,192E0,00050563-90,003711740,00050563-0,0224841330,18017899-0,003711750,18017899-71,79742071
113929,244755,4
287
=
21
bbbo
564475910,0188209222991347-2,395816317530581,9132665
===
bbbo
0
20
40
60
80
0 10 20 30 40
Consumo De Combustible [Galones]
Tem
pera
tura
Pro
med
io
Diar
ia [°
F]

26 UTA Ing. M.B.A William Teneda
El conocido urbanista siente que hay una relación entre una segunda variable independiente la cantidad de aislamiento. Establezca la regresión múltiple y analice los datos
Regresión Múltiple
X1 X2 Y X1X2 X1Y X2Y X21 X2
2
27,5 3 40 82,5 1100 120 756,25 9
36,4 3 27 109,2 982,8 81 1324,96 9
16,4 10 40 164 656 400 268,96 100
4,1 6 73 24,6 299,3 438 16,81 36
9,4 6 64 56,4 601,6 384 88,36 36
23,1 6 34 138,6 785,4 204 533,61 36
36,7 6 9 220,2 330,3 54 1346,89 36
153,6 40 287 795,5 4755,4 1681 4335,84 262
Fórmulas
1. ∑∑ ∑ −=+ nboYXbXb 21 21
2. n
YXYX
nXX
XXbnX
Xb ∑∑∑∑ ∑ ∑∑ ∑ −=
−+
− 1
121
21
212
1 2)(
1
3. n
YXYX
nX
Xbn
XXXXb ∑∑∑∑ ∑∑ ∑ ∑ −=
−+
− 2
2
222
2121
21
)(21
1. o7-2872401153,6 bbb =+
2. [ ] [ ] -1542,282,2142857-2965,4171431 =+ bb
3. [ ] [ ] 4133,4285714282,2142857-1 =+ bb

27 UTA Ing. M.B.A William Teneda
2. 8-1,59744412 0,08515934 -1 =bb
3. 0,498696792 0,40660295 1 =+− bb
-1,098747420,32144361 =b
101,972188-1,888532816-3,41816522
===
bobb
Ecuación Múltiple
Y = bo – b1X1 + b2X2
Y = 101,9721 – 1,8885X1 -3,41816X2
Coeficiente De Determinación Y De Correlación
22
221
2
)(1)(
)(121
∑∑
∑ ∑ ∑ ∑−
−++=
Yn
Y
Yn
YXbYXbYboR
28242772,350632 =R
0,981710562 =R
0,99081308=R

28 UTA Ing. M.B.A William Teneda
2.5 Bibliografía Complementaria
• Robert Pagano. Estadística Para Las Ciencias Del Comportamiento 7 Edición.
Editorial – Thomson. Impreso En Litograf Nueva Época. Enero 2006, México Df
• Estadística De Gilbert. Editorial – Interamericana Impreso En México 1980.
Primera Edición
• Estadística De Schaum. Segunda Edición. Editorial – Mcgraw – Hill.
• Ronald E. Walpole, Raymond H. Myers. Probabilidad Y
Estadística. Editorial: 2007 Pearson Education De Mexico
• Jack R. Benjamin. Probabilidad Y Estadistica. Editorial: 1981
Mcgraw–Hill Latinoamericana Editores S.A De C.V.
• Probabilidad Y Estadistica. William Navidi. Editorial: Mcgraw –
Hill/Interamericana Editores S.A De C.V. Edicon 2006.
• Probabilidad Y Estadistica. Autor: J. Susan Milton Y Jesse C. Arnold. Editorial:
Mcgraw – Hill/Interamericana Editores S.A De C.V. Octava Ediciòn.
• Ronald E.; Raymond H. Probabilidad Y Estadística Para Ingeniería Y Ciencias.
Editorial: Pearson Educación “Printed In México”. Año: Octava Edición 2007.
• Ciro Matìnez Bencardino. Estadística Básica, Probabilidad Y Estadística.
Editorial: Ecoe Ediciones. Quinta Edición ,Agosto De 1990.
• Estadistica de Inferencia. Héctor Aníbal Saltos.

29 UTA Ing. M.B.A William Teneda
CAPITULO III
INTRODUCCION A LAS PROBABILIDADES
3.1 Objetivos
• Aplicar las probabilidades en ejercicios prácticos
• Dominar el empleo de la Distribución normal, Binomial y Poisson .
• Explicar y predecir procesos reales que se presentan en la naturaleza y la
tecnología con la ayuda de la estadística para resolver problemas inherentes a
la ingeniería civil y mecánica.
3.2 Marco Teórico
PROBABILIDAD
Probabilidad de un suceso es el número al que tiende la frecuencia relativa
asociada al suceso a medida que el número de veces que se realiza el
experimento crece.
P(X) =
NUMERO DE SUCESO POSIBLES
NUMERO DE EXITOS
TABLA DE CONTINGENCIA El procedimiento Tablas de contingencia crea tablas de clasificación doble y
múltiple y, además, proporciona una serie de pruebas y medidas de asociación
para las tablas de doble clasificación. La estructura de la tabla y el hecho de
que las categorías estén ordenadas o no determinan las pruebas o medidas
que se utilizaban.
Los estadísticos de tablas de contingencia y las medidas de asociación sólo se
calculan para las tablas de doble clasificación. Si especifica una fila, una
columna y un factor de capa (variable de control), el procedimiento Tablas de
contingencia crea un panel de medidas y estadísticos asociados para cada
valor del factor de capa (o una combinación de valores para dos o más
variables de control). Por ejemplo, si sexo es un factor de capa para una tabla
de casado (sí, no) en función de vida (vida emocionante, rutinaria o aburrida),
los resultados para una tabla de doble clasificación para las mujeres se

30 UTA Ing. M.B.A William Teneda
calculan de forma independiente de los resultados de los hombres y se
imprimen en paneles uno detrás del otro.
ANALISIS COMBINATORIO
Combinación
Los coeficientes binomiales o combinaciones son una serie de números
estudiados en combinatoria que indican el número de formas en que se pueden
extraer subconjuntos a partir de un conjunto dado. Sin embargo, dependiendo
del enfoque que tenga la exposición, se suelen usar otras definiciones
equivalentes.
Ejercicios De Combinación
En una clase de 35 alumnos se quiere elegir un comité formado por tres
alumnos. ¿Cuántos comités diferentes se pueden formar?
C 335 = 35*34*33
3*2*1
= 6545
A una reunión asisten 10 personas y se intercambian saludos entre todos.
¿Cuántos saludos se han intercambiado?
C 210 = 10*9
2
= 45
En
Permutación matemáticas, dado un conjunto finito con todos sus elementos diferentes, llamamos
permutación a cada una de las posibles ordenaciones de los elementos de dicho
conjunto.
Por ejemplo, en el conjunto {1,2,3}, cada ordenación posible de sus elementos,
sin repetirlos, es una permutación. Existe un total de 6 permutaciones para
estos elementos: "1,2,3", "1,3,2", "2,1,3", "2,3,1", "3,1,2" y "3,2,1".
La noción de permutación suele aparecer en dos contextos:
• Como noción fundamental de combinatoria, centrándonos en el
problema de su recuento.
• En teoría de grupos, al definir nociones de simetría.

31 UTA Ing. M.B.A William Teneda
Ejercicios De Permutaciones
¿Cuántos números de 5 cifras diferentes se puede formar con los dígitos: 1, 2,
3, 4, 5.?
m = 5 n = 5
P5= 5! = 5*4*2*3*1 = 120
Con las cifras 2, 2, 2, 3, 3, 3, 3, 4, 4; ¿cuántos números de nueve cifras se
pueden formar?
m = 9 a = 3 b = 4 c = 2 a + b + c = 9
Sí entran todos los elementos.
Sí importa el orden.
Sí se repiten los elementos.
ESPACIO MUESTRAL Y SUCESOS
Experimentos, espacios muéstrales y sucesos La teoría de las probabilidades trata
formalmente de experimentos y de sus resultados donde el término experimento se
usa en el sentido más general. Se denomina espacio muestral la colección de todos los
posibles resultados de un experimento. Los elementos del conjunto S de este espacio
se denominan puntos muestrales, cada uno de ellos asociado con uno y sólo un
resultado distinto. La precisión para distinguir resultados es cosa de criterio y
dependerá en la práctica de la utilización que se hará del modelo.
Ejemplo. Un experimento consiste en lanzar una moneda y después lanzarla una segunda
vez si sale cara. Si sale cruz en el primer lanzamiento, entonces se lanza un dado una vez.
Para listar los elementos del espacio muestral que proporcione la mayor información,
construimos el diagrama de árbol de la figura 2.1. Las diversas trayectorias a lo largo de
las ramas del árbol dan los distintos puntos muéstrales. Al comenzar con la rama superior
izquierda y movernos a la derecha a lo largo de la primera trayectoria, obtenemos el punto
muestral HH, que indica la posibilidad de que ocurran caras en dos lanzamientos sucesivos
de la moneda. Asimismo, el punto muestral T3 indica la posibilidad.

32 UTA Ing. M.B.A William Teneda
VALOR ESPERADO O ESPERANZA Si P es la probabilidad de éxito de un suceso en un solo ensayo, el numero
esperado o esperanza de ese suceso en N ensayos, estará dado por el producto
de N y la probabilidad de éxito P.
E = n.p(x)
Ejemplo.
En el lanzamiento 900 veces de dos dados, ¿Cuál es la esperanza de que la suma
de sus caras de un valor menor de 6.?
Probabilidad de éxito de un solo ensayo.
(1,1) (1,2) (2,1) (2,2) (2,3) (3,2) (3,1) (1,3) (4,1) (4,4)
p(x): 10/36 n=900
E=np=900*(10/36)=9000/36= 250
“La esperanza o valor esperado es de que 250 de los 900 lanzamientos, la
suma de sus caras sea menor de 6”
DISTRIBUCION BINOMIAL
Procesos de Bernoulli: Un proceso de Bernoulli es una serie de n experimentos
aleatorios que verifican:
Cada experimento tiene dos resultados posibles, que se llaman éxito y fracaso.
La probabilidad p de éxito es la misma en cada experimento, y esta
probabilidad no se ve afectada por el conocimiento de los resultados anteriores.
La probabilidad q de fracaso viene dada por q = 1 - p.

33 UTA Ing. M.B.A William Teneda
Ejemplos :
Una moneda lanzada al aire 15 veces. Los dos resultados posibles son cara y
cruz. La probabilidad de cara en un lanzamiento es 1/2
Se pregunta a 200 alumnos de de un Instituto de Enseñanza Secundaria si
estudian Francés. Los dos resultados posibles son sí y no. Si se considera
éxito la respuesta sí, la probabilidad p de éxito indica la proporción de
estudiantes del Instituto que responden sí (estudian francés, pues suponemos
que no mienten).
Tirar un dado de seis caras 10 veces y considerar que el resultado de una
tirada, es que salga un número par o un número impar. Los resultados posibles
en este caso son par e impar.
El espacio muestral, cada uno de los sucesos y la probabilidad de que ocurran,
en un proceso de Bernoulli, aparecen muy nítidamente cuando se construye un
árbol de probabilidades del proceso.
Por ejemplo vamos a construir el árbol de probabilidades de un proceso de
Bernoulli de tres experimentos:
El espacio muestral del proceso está formado por cada uno de los caminos del
árbol de probabilidades. La probabilidad de un camino, por ejemplo, del camino
: EFE es :
Si en un proceso de Bernouilli asignamos el valor 1 al éxito y 0 al fracaso y
consideramos el valor Sj , suma de todos los valores de un resultado concreto
(un camino) con j éxitos ; la probabilidad que corresponde a cada valor de la
variable Sj es :

34 UTA Ing. M.B.A William Teneda
Ejercicios De Distribución Binomial
La probabilidad de éxito de una determinada vacuna es 0,72. Calcula la
probabilidad de a que una vez administrada a 15 pacientes:
a) Ninguno sufra la enfermedad
b) Todos sufran la enfermedad
c) Dos de ellos contraigan la enfermedad
Solución :
Se trata de una distribución binomial de parámetros B(15, 0'72)
DISTRIBUCIÓN DE POISSON
En teoría de probabilidad y estadística, la distribución de Poisson es una
distribución de probabilidad discreta. Expresa la probabilidad de un número k
de eventos ocurriendo en un tiempo fijo si estos eventos ocurren con una tasa
media conocida, y son independientes del tiempo desde el último evento.
La distribución fue descubierta por Siméon-Denis Poisson (1781–1840) que
publicó, junto con su teoría de probabilidad, en 1838 en su trabajo Recherches

35 UTA Ing. M.B.A William Teneda
sur la probabilité des jugements en matières criminelles et matière civile
("Investigación sobre la probabilidad de los juicios en materias criminales y
civiles"). El trabajo estaba enfocado en ciertas variables aleatorias N que
cuentan, entre otras cosas, un número de ocurrencias discretas (muchas veces
llamadas "arribos") que tienen lugar durante un intervalo de tiempo de duración
determinada. Si el número esperado de ocurrencias en este intervalo es λ,
entonces la probabilidad de que haya exactamente k ocurrencias (siendo k un
entero no negativo, k = 0, 1, 2, ...) es igual a:
dónde
• e es el base del logaritmo natural (e = 2.71828...),
• k! es el factorial de k,
• k es el número de ocurrencias de un evento,
• λ es un número real positivo, equivalente al número esperado de
ocurrencias durante un intervalo dado. Por ejemplo, si los eventos
ocurren de media cada 4 minutos, y se está interesado en el número de
eventos ocurriendo en un intervalo de 10 minutos, se usaría como
modelo una distribución de Poisson con λ = 2.5.
Ejercicios De Distribución De Poisson
1. Si un banco recibe en promedio 6 cheques sin fondo por día, ¿cuáles
son las probabilidades de que reciba, a) cuatro cheques sin fondo en un día
dado, b) 10 cheques sin fondos en cualquiera de dos días consecutivos?
Solución:
a) x = variable que nos define el número de cheques sin fondo que llegan al
banco en un día cualquiera = 0, 1, 2, 3, ....., etc, etc.
l = 6 cheques sin fondo por día
e = 2.718

36 UTA Ing. M.B.A William Teneda
b)
x= variable que nos define el número de cheques sin fondo que llegan al banco
en dos días consecutivos = 0, 1, 2, 3, ......, etc., etc.
l = 6 x 2 = 12 cheques sin fondo en promedio que llegan al banco en dos días
consecutivos
Nota: l siempre debe de estar en función de x siempre o dicho de otra forma,
debe “hablar” de lo mismo que x.
2. En la inspección de hojalata producida por un proceso electrolítico
continuo, se identifican 0.2 imperfecciones en promedio por minuto. Determine
las probabilidades de identificar a) una imperfección en 3 minutos, b) al menos
dos imperfecciones en 5 minutos, c) cuando más una imperfección en 15
minutos.
Solución:
a) x = variable que nos define el número de imperfecciones en la hojalata
por cada 3 minutos = 0, 1, 2, 3, ...., etc., etc.
l = 0.2 x 3 =0.6 imperfecciones en promedio por cada 3 minutos en la hojalata
b) x = variable que nos define el número de imperfecciones en la hojalata
por cada 5 minutos = 0, 1, 2, 3, ...., etc., etc.
l = 0.2 x 5 =1 imperfección en promedio por cada 5 minutos en la hojalata

37 UTA Ing. M.B.A William Teneda
=1-(0.367918+0.367918) = 0.26416
c) x = variable que nos define el número de imperfecciones en la hojalata
por cada 15 minutos = 0, 1, 2, 3, ....., etc., etc.
l = 0.2 x 15 = 3 imperfecciones en promedio por cada 15 minutos en la hojalata
= 0.0498026 + 0.149408 = 0.1992106
.
DISTRIBUCIÓN NORMAL
La distribución normal fue reconocida por primera vez por el francés Abraham
de Moivre (1667-1754). Posteriormente, Carl Friedrich Gauss (1777-1855)
elaboró desarrollos más profundos y formuló la ecuación de la curva; de ahí
que también se la conozca, más comúnmente, como la "campana de Gauss".
La distribución de una variable normal está completamente determinada por
dos parámetros, su media y su desviación estándar, denotadas generalmente
por y .
Al igual que ocurría con un histograma, en el que el área de cada rectángulo es
proporcional al número de datos en el rango de valores correspondiente si, tal y
como se muestra en la Figura 2, en el eje horizontal se levantan
perpendiculares en dos puntos a y b, el área bajo la curva delimitada por esas
líneas indica la probabilidad de que la variable de interés, X, tome un valor
cualquiera en ese intervalo. Puesto que la curva alcanza su mayor altura en

38 UTA Ing. M.B.A William Teneda
torno a la media, mientras que sus "ramas" se extienden asintóticamente hacia
los ejes, cuando una variable siga una distribución normal, será mucho más
probable observar un dato cercano al valor medio que uno que se encuentre
muy alejado de éste.
Propiedades de la distribución normal:
La distribución normal posee ciertas propiedades importantes que conviene
destacar:
1. Tiene una única moda, que coincide con su media y su
mediana.
2. La curva normal es asintótica al eje de abscisas. Por ello,
cualquier valor entre y es teóricamente posible. El
área total bajo la curva es, por tanto, igual a 1.
3. Es simétrica con respecto a su media . Según esto, para
este tipo de variables existe una probabilidad de un 50% de
observar un dato mayor que la media, y un 50% de observar
un dato menor.
4. La distancia entre la línea trazada en la media y el punto de
inflexión de la curva es igual a una desviación típica ( ).
Cuanto mayor sea , más aplanada será la curva de la
densidad.
5. El área bajo la curva comprendido entre los valores situados
aproximadamente a dos desviaciones estándar de la media
es igual a 0.95. En concreto, existe un 95% de posibilidades
de observar un valor comprendido en el intervalo
.
6. La forma de la campana de Gauss depende de los
parámetros y (Figura 3). La media indica la posición de
la campana, de modo que para diferentes valores de la
gráfica es desplazada a lo largo del eje horizontal. Por otra
parte, la desviación estándar determina el grado de
apuntamiento de la curva. Cuanto mayor sea el valor de ,
más se dispersarán los datos en torno a la media y la curva
será más plana. Un valor pequeño de este parámetro indica,

39 UTA Ing. M.B.A William Teneda
por tanto, una gran probabilidad de obtener datos cercanos al
valor medio de la distribución.
Ejemplo 1:
Utilizando la tabla del área bajo la curva normal, plantearemos algunos problemas que
servirán de modelo.
a.- para Z = 1.5 y Z = -.1.4
Z = 1.5 la tabla da : 0.4332
Z = 1.4 la tabla da : 0.4192
P(-1.4 < Z < 1.5) = 0.4332+0.4192 = 0.8524
P = 85.24%
b.- si se plantea P( Z < 1.5 corresponden al
siguiente gráfico:
0.5000+0.4232 = 0.9332 = 93.32%

40 UTA Ing. M.B.A William Teneda
c.- otro problema seria P(Z > 1.5) = ?
0.5000-0.4332 = 0.0668 = 6.68%
DISTRIBUCIONES t DE STUDENT
El lector sabe cómo hacer deducciones acerca de la mayoría de la población si
cabe suponer que la distribución muestral de las medias es normal. Sin
embargo, cabe preguntarse qué puede hacerse si se desconoce δ y n es
pequeña, de modo que no puede hacerse esta suposición de normalidad.
Contestaremos a esta pregunta en el presente capítulo. Se encontrará una
familia de distribuciones t(una distinta para cada valor de n), pero no se toma,
porque pronto se descubrirá que, conforme n aumenta, la distribución t
correspondiente se asemeja mucho a la distribución normal, e incluso cuando n
es pequeña, se aplica una distribución tefe la misma manera en que se hace
con una distribución normal.
Se aprenderá cuándo utilizar puntuaciones i y cuándo utilizar puntuaciones z y
cómo emplear puntuaciones t, para una media de la población y para
diferencias en las medias de dos poblaciones. Por último, se descubrirá cómo
tratar puntuaciones apareadas en muestras que no son independientes.
Características De Las Distribuciones t
Las distribuciones t de Student tienen las siguientes características:
1. No hay sólo una distribución t sino una distribución distinta para cada valor
den. Hay una curva normal estándar, y un cuadro de una página puede dar
áreas debajo de esta curva para la mayor parte de los valores de z que nos

41 UTA Ing. M.B.A William Teneda
interesan. Hay toda una familia de curvas t "estándar". Si se formara un cuadro
para las áreas debajo de la curva t para cada n (equivalente al cuadro para las
áreas debajo de la curva normal estándar), se necesitaría todo un volumen. Los
cuadros t serán muy abreviados.
2. Cada curva t es simétrica a los lados de 0. E-lío significa que la mitad
derecha de la curva t tiene este aspecto
Y la mitad izquierda es una imagen en espejo; la curva entera tendrá este
aspecto:
A causa de lo anterior, la media de toda distribución f es 0.
3. El punto más alto de la curva ocurre cuando t = 0.
4. Al aumentar n, la curva t se acerca cada vez más a la curva normal. Es fácil
advertir lo anterior considerando algunas gráficas superpuestas:
Si n es de 30, o más, la distribución t y la distribución normal estándar están lo
suficientemente cercanas de modo que las áreas abajo de esta última pueden
utilizarse como aproximación a las áreas debajo de la primera. Esta cercanía

42 UTA Ing. M.B.A William Teneda
de las curvas f y z para valores altos de n es lo que justifica el empleo de la
ecuación s/Vn como aproximación de xδ cuando n es grande y se desconoce
δ
5. Cada distribución t es una distribución de probabilidad; esto es: el área
debajo de toda la curva es una, y la probabilidad de que una puntuación t esté
entre a y b es igual a área debajo de la curva entre las líneas t = a y t = b.
¿CUANDO SE USA UNA DISTRIBUCIÓN t?
La distribución t se usa en las siguientes circunstancias:
a) La población tiene distribución normal y,
b) Se desconoce o- (pero se conoce s o puede calcularse) y
c) n ≤ 30.
Si la población no tiene distribución normal, se cometerá un error. ¿Qué tan
grande es el error? Depende de qué tan lejos esté la población de la
distribución normal. Si es casi normal, el error será pequeño. Si está muy lejos
de ser normal, la distribución t es casi inútil. En la práctica, el problema es que
a menudo se desconoce si la población sigue o no una curva normal.
GRADOS DE LIBERTAD
¿Cómo se usa una distribución t?
Antes de continuar, debemos desviarnos un momento para explicar los grados
de libertad.
Imaginemos tres niños que juegan un juego muy sencillo; a saber: tres cartas
están marcadas, 0, 10 y 20 respectivamente. Se barajan las cartas y cada niño
por turno toma una. Jaime es impulsivo y toma una carta en primer lugar; tiene
10 puntos. María elige en seguida y obtiene 0. Tomás toma la última carta y
debe tener 20 puntos. Sin embargo, si Jaime sacó la carta 0 y María la carta
20, Tomás sacará la carta 10. El punto es que, una vez que dos niños han
elegido su carta, la tercera está fija. Dos de los niños eligieron libremente: hay
dos grados de libertad.

43 UTA Ing. M.B.A William Teneda
Sin puntuaciones tienen media X, n -1 puede elegirse libremente y la última es
regida; hay n -1 grados de libertad.
Para encontrar un intervalo de confianza o poner a prueba una hipótesis acerca
de la media valiéndose de la distribución f para una muestra de dimensión n, el
número de grado de libertad es n - 1. La letra D se utiliza para denotar el
número de grados de libertad.
D = n - 1
DISTRIBUCION JI CUADRADO En primer lugar, conózcase la letra griega x (ji); no hay equivalente en
castellano, pero fonéticamente corresponde a ji. La veremos únicamente en la
forma x2 y nos referiremos a “distribuciones de ji cuadrada” o “pruebas de ji
cuadrada”.
Se han conocido varias familias de distribuciones de probabilidad; a saber:
distribuciones binomial, normal y. Ahora se conocerá otra familia de
distribuciones de probabilidad; al igual que con las distribuciones t, habrá una
distribución x2 diferente para cada número de grados de libertad. Antes de
conocer a fondo una distribución x2 veamos un problema en el cual se necesita.
Ejemplo 1. Estudios efectuados en 1950 comprobaron que, entre todos los
varones con 30 años de edad, 20 por 100 habían cursado la escuela superior,
50 por 100 tenían certificado de escuela secundaria pero no de escuela
superior, y 30 por 100 no habían llegado a la escuela secundaria. ¿La
distribución de la población actual es semejante? Se efectúa un estudio de 1
000 varones tomados aleatoriamente de quienes hoy tienen 30 años de edad, y
se descubre que 250 se han graduado en colegio superior, 520 en escuela
secundaria y 230 no han terminado la secundaria. Hágase una prueba a nivel
de significación de .01.
H: No hay cambio en la distribución entre 1950 y la actualidad. (Adviértase que
Ho es un supuesto no acerca de la media ola proporción de una población, sino
acerca de la distribución global de una población.)
H1: La población actual (esto es: todos los varones que en la actualidad tienen
30 años de edad) posee distribución distinta que la población en 1950.
Sea O—la letra 0, no el número 0— abreviatura de frecuencia Observada (en
~a actualidad) y E denote frecuencia Esperada. Si no hay cambio en la
distribución entre 1950, y la actualidad, los datos proporcionados pueden

44 UTA Ing. M.B.A William Teneda
presentarse de la manera siguiente:
Graduados de colegio superior
Graduados de escuela secundaria
No graduados de escuela secundaria
Total de graduados
En 1950, 20 por 100 tenían estudios superiores. En consecuencia, cabía
esperar que en una muestra de 1 000,20 por 100 ó 200 varones fuesen
graduados de colegio superior, 50 por 100 ó500 varones hubiesen terminado la
escuela secundaria, y 30 por 100 ó 300 “no hubiesen terminado la secundaria”.
Adviértase que comenzamos escalando la columna E de modo que la suma
sea igual a la de la columna 0. Es inadecuado expresar la columna O en
números de varones (total 1 000) y la columna E en porcentajes o proporciones
(total 1006 1, respectivamente). Las dos columnas deben sumar el número total
de cifras en la muestra.
Ahora debe hacerse una decisión de elección: ¿qué debe utilizarse como
requisito para aceptar o rechazar HΣ(O—E) describe la diferencia entre las dos
distribuciones? Pero Σ (0 — E) = Σ0—ΣE = n — n=0. 0, como se muestra en la
columna O—E que sigue, 50+20-70 = 0.
Graduados de escuela
superior
Graduados de secundaria
No graduados de secundaria
Total de graduados
¿Recuerda que al explicar medidas de variabilidad consideramos Σ(x−x)n
pero
resultó que∑(X—𝑋𝑋) siempre es igual a 0? Después ensayamos Σ(x-𝑋𝑋)2 y por
último Σ(x−𝑋𝑋)2
n la varianza.
En consecuencia, en este caso podemos advertir si Σ(0-E)2 manifiesta la
diferencia entre las dos distribuciones. Σ(0-E)2 = O únicamente si hay ajuste
O E
250 200
520 500
230 300
1000 100
O E O-E (O
− E)2
(O − E)2/E
250 200 50 2500 12.5
520 500 20 400 8
230 200 -70 4900 16.3
1000 1000 0 7800 29.6

45 UTA Ing. M.B.A William Teneda
perfecto entre las frecuencias observada y esperada, y puede ser muy grande
si no concuerdan.
En lugar de limitarnos a usar Σ(0-E)2 empleamos Σ(0-E)2/E. El motivo de lo
anterior es que una partida grande en la columna (0-E) 2es más perturbadora si
proviene de una categoría con frecuencia esperada o calculada pequeña que si
la frecuencia esperada es grande, de manera que en el primer caso presenta
mayor ponderación. Una anotación de 2500 en la columna (0-E)2 se convierte
en 12.5 si la frecuencia esperada E es 200, pero será sólo 5.0 si la frecuencia
esperada es 500, y 2.5 si la frecuencia esperada o calculada en la categoría es
1 000.
Ahora definiremos x2ρ:
x2ρ = Σ (0−E)2E
3.3 Término y Conceptos claves
Definición: El conjunto de todos los resultados posibles de un experimento
estadístico se llama espacio muestral y se representa con el símbolo S.
HIPOTESIS ESTADÍSTICAS
Al intentar alcanzar una decisión, es útil hacer hipótesis (o conjeturas) sobre la
población implicada. Tales hipótesis, que pueden ser o no ciertas, se llaman
hipótesis estadísticas. Son, en general, enunciados acerca de las
distribuciones de probabilidad de las poblaciones.
Hipótesis nula
En muchos casos formulamos una hipótesis estadística con el único
propósito de rechazarla o invalidarla. Así, si queremos decidir si una moneda
está trucada, formulamos la hipótesis de que la moneda es buena (o sea, p =
0.5, donde p es la probabilidad de cara). Análogamente, si deseamos
decidir si un procedimiento es mejor que otro, formulamos la hipótesis de que
no hay diferencia entre ellos (o sea, que cualquier diferencia observada se debe

46 UTA Ing. M.B.A William Teneda
simplemente a fluctuaciones en el muestreo de la misma población). Tales
hipótesis se suelen llamar hipótesis nula y se denotan Ho
Hipótesis alternativa
Toda hipótesis que difiera de una dada se llamará una hipótesis alternativa.
Por ejemplo, si una hipótesis es p = 0.5, hipótesis alternativas podrían ser p =
0.7, p ≠ 0.5 o p > 0.5. Una hipótesis alternativa a la hipótesis nula se
denotará por H1.
ERRORES DE TIPO I Y DE TIPO II
Si rechazamos una hipótesis cuando debiera ser aceptada, diremos que se ha
cometido un error Tipo I.
Por otra parte, si aceptamos una hipótesis que debiera ser rechazada, diremos
que se ha cometido un error de Tipo II. En ambos casos, se ha producido un
juicio erróneo.
Para que las reglas de decisión (o contrastes de hipótesis) sean buenas, deben
diseñarse de modo que minimicen los errores de la decisión. Y no es una
cuestión sencilla, porque para cualquier tamaño de la muestra, un intento de
disminuir un tipo de error suele ir acompañado de un crecimiento del otro tipo.
En la práctica, un tipo de error puede ser más grave que el otro, y débil alcanzarse
un compromiso que disminuya el error más grave. La única forma de disminuir
ambos al la vez es aumentar el tamaño de la muestra, que no siempre es
posible.
Tipos de errores
Definición.- El rechazo de la hipótesis nula cuando es verdadero se llama error
de tipo 1
Definición.-No rechazarla hipótesis nula cuando es falsa se llama error de tipo
2

47 UTA Ing. M.B.A William Teneda
¿Cómo sabremos si está cometiendo un error de tipo I o de tipo II?
Examinar la lógica de la influencia estadística.
¿Cómo saber si hemos rechazado o no una hipótesis nula equivocadamente?
Coleccionar muestras y extraemos inferencias de las mismas única y
exclusivamente.
¿No hay manera entonces de saber qué experimentos proporcionan resultados adecuados y cuáles no?
La respuesta es si. Si tuviéramos que repetir el experimento y obtener
resultados parecidos tendríamos mayor confianza de no estar cometiendo un
error de tipo I
3.4 Preguntas y Problemas Claves
1. Defina cada uno de los conceptos de la sección "términos importantes".
2. Supongamos que se cumplen los supuestos fundamentales de la prueba t.
¿Cuáles son las características de la distribución muestral de t?
3. Explique lo que significa grados de libertad. Proponga un ejemplo.
4. ¿Cuáles son los supuestos fundamentales para el uso apropiado de la prueba
t?
5. Analice las semejanzas y las diferencias entre las pruebas z y t.
6. Explique brevemente por qué la prueba z es más poderosa que la prueba t.

48 UTA Ing. M.B.A William Teneda
7. ¿Cuál de las siguientes afirmaciones es más correcta desde el punto de vista
técnico? 1) Tenemos el 95% de confianza de que la media de la población se
encuentra en el intervalo 80-90, o bien,
8. 2) tenemos el 95% de confianza de que el intervalo 80-90 contiene la media de
la población. Explique.
9. Explique por qué gl = N - 1 cuando se utiliza la prueba t con una sola muestra.
10. Si el coeficiente de correlación de una muestra tiene un valor diferente de cero
(por ejemplo, r = 0.45), esto significa automáticamente que la correlación en la
población también es diferente de cero. ¿Es correcta esta afirmación?
Explique.
11. Con el mismo conjunto de datos muéstrales, ¿el intervalo de confianza de 99%
para la media poblacional es mayor o menor que el intervalo de confianza de
95% ? ¿Le parece a usted lógico? Explique.
12. Un conjunto muestral de 30 datos tiene una media de 82 y una desviación
estándar de 12. ¿Podemos rechazar la hipótesis de que se trata de una
muestra aleatoria, extraída de una población normal con µ = 85? Utilice α =
0.012colas Para tomar su decisión, otra
13. ¿Es razonable considerar una muestra con N = 22, __X obt = 42 y s = 9 como una
muestra aleatoria extraída de una población normal con µ =38? Utilice α =
0.05 1 cola para tomar su decisión. Suponga que __X obt está en la dirección
correcta, otra
14. En cada una de las siguientes muestras aleatorias, determine los intervalos de
confianza de 95 y el 99% para la media poblacional:
i. __X obt = 25, s = 6, N = 15
ii. __X obt = 120, s = 8, N = 30

49 UTA Ing. M.B.A William Teneda
iii. __X obt = 30.6, s = 5.5, N = 24
iv. Vuelva a resolver la parte a con N = 30. ¿Qué ocurre con el
intervalo de confianza cuando N crece? Otra
15. Supongamos que se desconoce la desviación estándar poblacional del
problema 21 del capítulo 12, página 291. Utilice de nuevo α = 0.052 Colas, ¿Qué
podría concluir con respecto a la técnica de la estudiante? Explique la
diferencia entre la conclusión del problema 21 y la de este problema, clínica,
salud.
16. si una variable aleatoria tiene distribución normal estándar, calcula la
probabilidad de que tome un valor:
(a) menor que 1.50; (b) mayor que 2.16;
(c) mayor que -1.175;
17. escriba el valor de z si la probabilidad de que una variable aleatoria de
distribución normal estándar tome un valor:
(a) menor que z es 0.9911; (b) mayor que z es 0.1093;
(c) mayor que z es 0.6443; (d) menor que z es 0.0217
e) entre –z y z es 0.9298
18. una variable aleatoria tiene una distribución normal con µ= 62.4hallar su
desviación estándar si la probabilidad de que tome un valor mayor que 79.2 es
verifica que
z0.005=2.575
z0.025=1.96
3.5 Bibliografía Complementaria
• Robert Pagano. Estadística Para Las Ciencias Del Comportamiento 7 Edición.
Editorial – Thomson. Impreso En Litograf Nueva Época. Enero 2006, México Df

50 UTA Ing. M.B.A William Teneda
• Estadística De Gilbert. Editorial – Interamericana Impreso En México 1980.
Primera Edición
• Estadística De Schaum. Segunda Edición. Editorial – Mcgraw – Hill.
• Ronald E. Walpole, Raymond H. Myers. Probabilidad Y
Estadística. Editorial: 2007 Pearson Education De Mexico
• Jack R. Benjamin. Probabilidad Y Estadistica. Editorial: 1981
Mcgraw–Hill Latinoamericana Editores S.A De C.V.
• Probabilidad Y Estadistica. William Navidi. Editorial: Mcgraw –
Hill/Interamericana Editores S.A De C.V. Edicon 2006.
• Probabilidad Y Estadistica. Autor: J. Susan Milton Y Jesse C. Arnold. Editorial:
Mcgraw – Hill/Interamericana Editores S.A De C.V. Octava Ediciòn.
• Ronald E.; Raymond H. Probabilidad Y Estadística Para Ingeniería Y Ciencias.
Editorial: Pearson Educación “Printed In México”. Año: Octava Edición 2007.
• Ciro Matìnez Bencardino. Estadística Básica, Probabilidad Y Estadística.
Editorial: Ecoe Ediciones. Quinta Edición ,Agosto De 1990.
• Estadistica de Inferencia. Héctor Aníbal Saltos.