graphconnect europe 2016 - faster lap times with neo4j - srinivas suravarapu
TRANSCRIPT

FASTER LAP TIMES WITH NEO4J Srinivas Suravarapu Chief Architect – Scribestar Ltd @srinivas_s

Scribestar • A content collaboration platform for the legal community.
The solution is targeted at lawyers and how they draft legal content.
• From an information systems point of a view it is a collaboration platform and is concerned with getting related users changing related content to work effectively.
• We are about 20 people and the platform is built on on .NET and uses Neo4j as its primary store. (now)

Relational Stores Looking back at some Content management systems. • They tend to base themselves on a Relational DBMS and
serve content using BLOBs As content grows, a monolithic store pretty quickly starts affecting users ability to perform functions which do not have anything to do with content itself. BLOBs are good for a few pieces of content but when all you have is content, you have to go back to the drawing board on where you store it.

NOSQL Stores Some have managed to use document oriented databases Able to serve large content to the web quickly. When you combine content in some form of ML format with fragments of relational data inevitably present in every system, they rely heavily on how you model your aggregates. Working with multiple aggregates sitting behind service boundaries tend to bring up consistency issues, and we tend to offload a lot of implementation complexity to the application tier.

Polyglot Persistence Using multiple storage technologies to store the information is inevitable. The type of data and how its consumed by parts of your application should be the driver to choose your data store. We store our relation information using a graph and store content in a file store. The ability of the user to collaborate effectively on the content is isolated and not affected by users collaborating on the metadata.
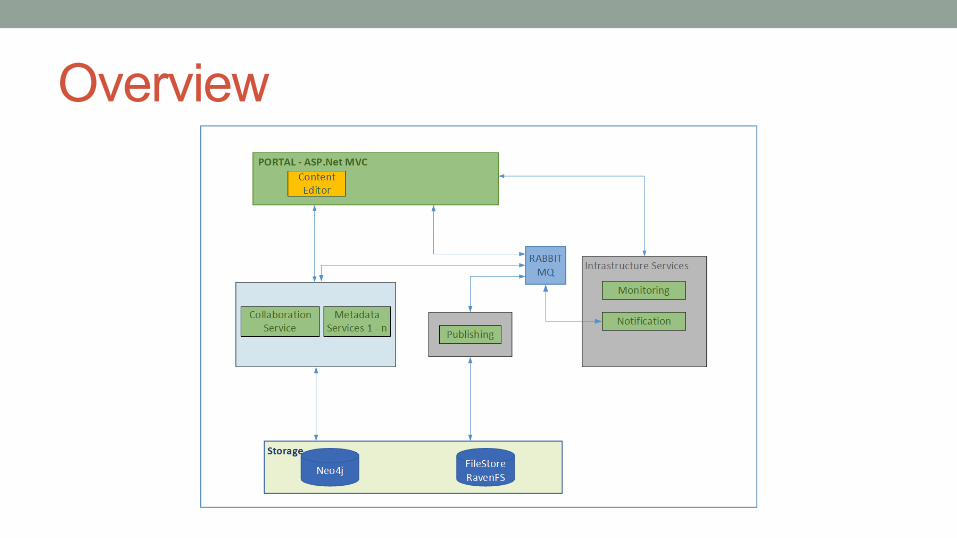
Overview

Wish list • Constantly being compared to the capabilities of desktop
publishing tools • Should be fast and secure • We cannot loose content • Corruption of content is not an option • Everyone should be able to change the same piece of
content at the time (You Only think you need it)
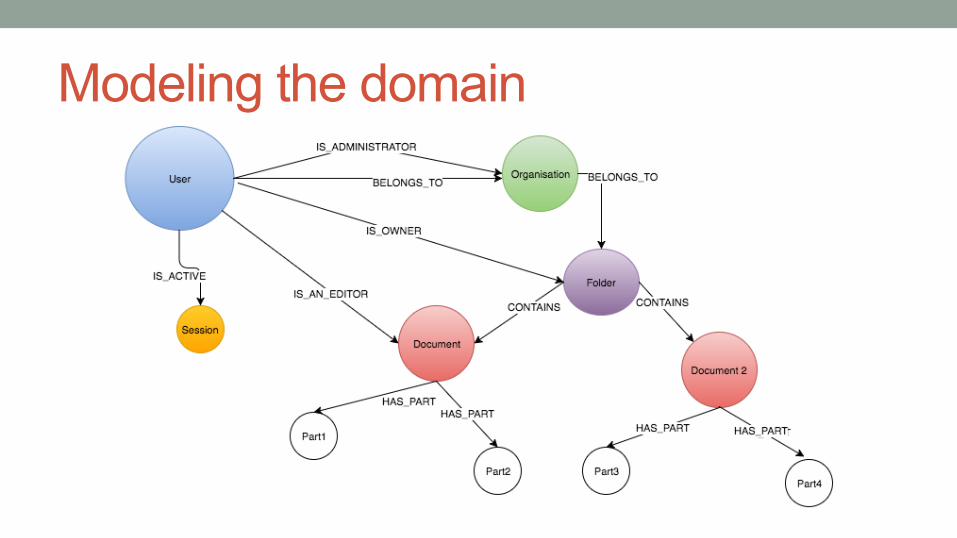
Modeling the domain
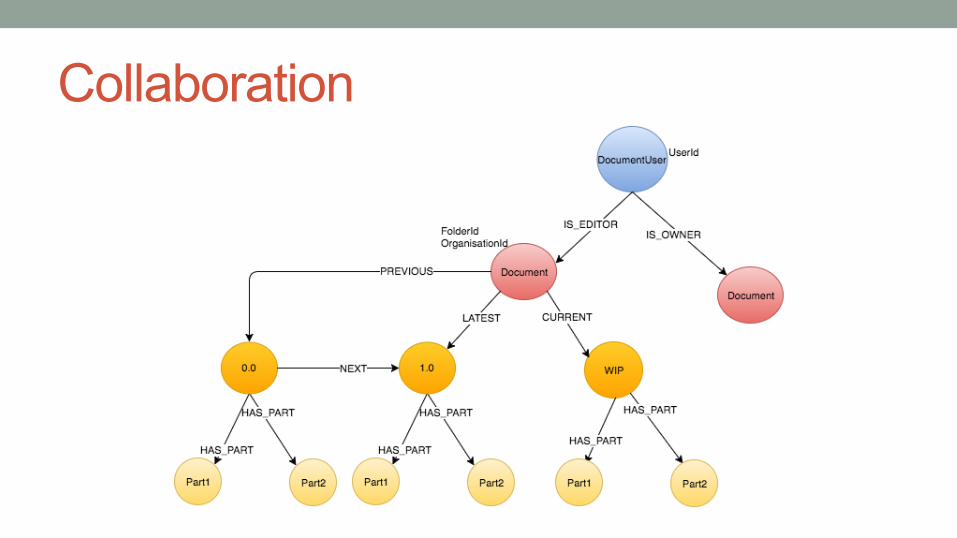
Collaboration
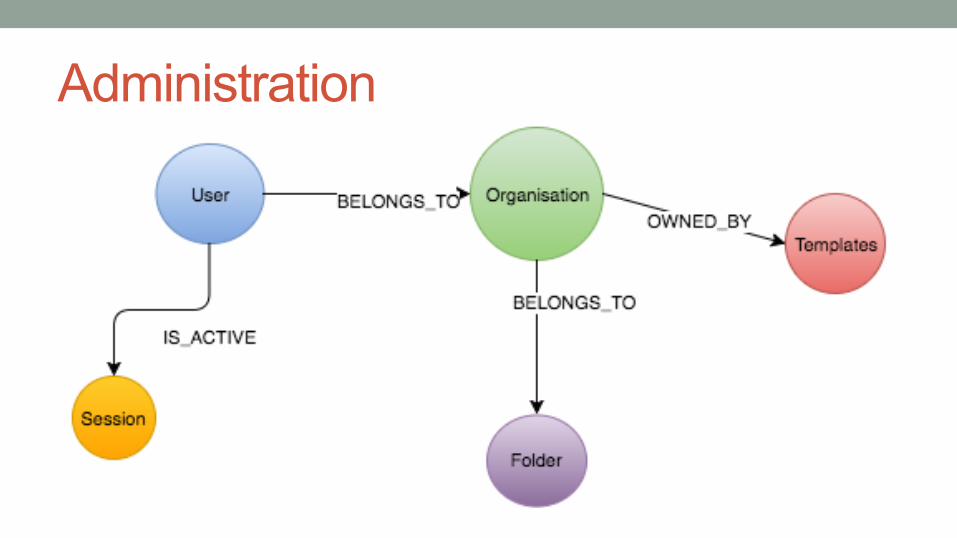
Administration
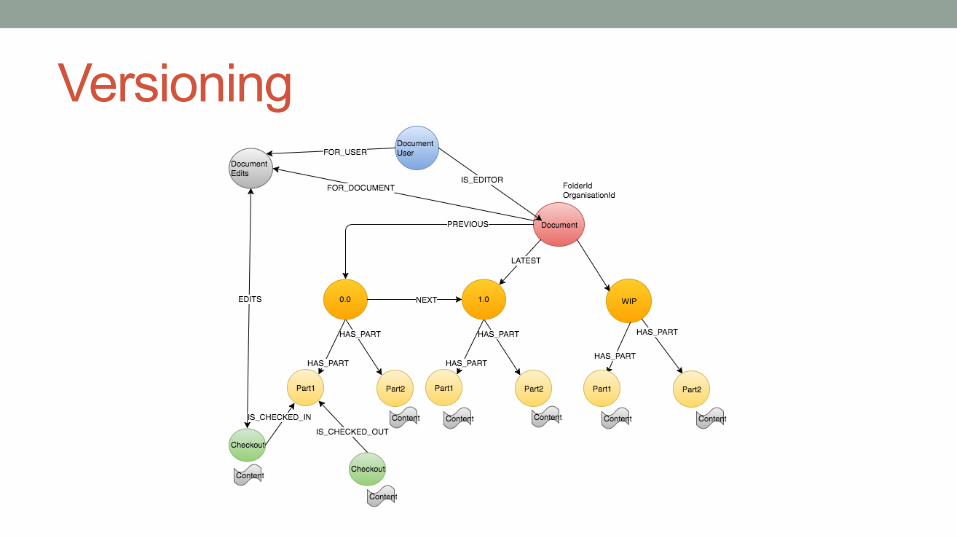
Versioning

Modeling the domain • Stay as close as possible to the domain and let the graph
be a reflection of the users actions in the system over time • Bounded contexts still apply and the rules of how you
share information between two aggregates remain, think how you can have multiple graphs that are smaller.
• Keeping the graph acyclic and directed keeps it simple however this is entirely based on the context of your problem.


Code Tips • Principles of how to interact with a database haven’t
changed • The notion of using parameters, indexes or constraints exists. • Don’t read the same information repeatedly if it doesn’t change • Writes, the principles of concurrency haven't changed. • Watch out for queries that are reused, its easier to write separate
queries for separate concerns, duplication is fine. • The unexpected side effects of query reuse for different concerns
turns out to be a killer. • Use the profile and explain options to analyse your queries

Cypher Tuning • Neo4j
• Switch query logging on to capture slow running queries, threshold is subject to what you want
• Switch metrics to be output to graphite or CSV files • Have a suite of tests which run regularly and test concurrency and
load. • Use the feedback and tweak any slow running queries. • Repeat the exercise until you don’t find any queries being written
into the querylog, that should ensure you have fast queries • Always look at getting to the node you are interested first like
SELECT on SELECT in SQL , MATCH on MATCH is effective.

The business benefits • We built our new solution in 8 months, compared to the
former that was built for about 2+ years • We did this with half the size of the original team • The system is at least X times quicker than where it used
to be, where X is a two digit number J • The complexity of work has reduced – Indicators
• Team hasn’t come up with I don’t know how big this is in a while • With the definition of the cycle time widening, the cycle times have
dropped for the same complexity

The business benefits • The complexity of work reduced
• With the definition of the cycle time widening, the cycle times to drop the same level of complexity reduced significantly.
• Being able to visualize the data real time provides valuable analytics for the user
• Cypher is absolutely powerful in its ability to get you to where you need to on the graph
• Reduces the need to understand the implementation immediately to some degree.

Moving into the future • Visualizing the information using tools to get some insight into
user behavior, this will help us evolve the product. • Some of the principles we have used should help us scale out
without contention – famous last words , remains to be seen. • Who knows we may be able to store large files in hybrid
technology of Neo and something else, alternative stores like Riak or any self hosted S3 styled products
• Would be great to have a light-weight Linkurious plugin on the neo dashboard
• Precedents and taxonomy subject to research

The agility you obtain using a graph is great, changing the underlying model is no where near as painful or dreadful, the value of visualization simply exceeds any cost involved in the transition

See Some Code?