goodbye, bottlenecks: how scale-out and in-memory solve etl
TRANSCRIPT

Grab some coffee and enjoy the pre-show banter
before the top of the
hour!

The Briefing Room
Goodbye, Bottlenecks: How Scale-Out and In-Memory Solve ETL

Twitter Tag: #briefr The Briefing Room
Reveal the essential characteristics of enterprise software, good and bad
Provide a forum for detailed analysis of today’s innovative technologies
Give vendors a chance to explain their product to savvy analysts
Allow audience members to pose serious questions... and get answers!
Mission

Twitter Tag: #briefr The Briefing Room
Topics
August: REAL-TIME DATA
September: HADOOP 2.0
October: DATA MANAGEMENT

Twitter Tag: #briefr The Briefing Room
Why Data Gets in a Jam
Ø ETL is dated technology
Ø New super-highways are needed
Ø Data gravity is real

Twitter Tag: #briefr The Briefing Room
Analyst: Robin Bloor
Robin Bloor is Chief Analyst at The Bloor Group
[email protected] @robinbloor

Twitter Tag: #briefr The Briefing Room
Splice Machine
Splice Machine is a SQL-on-Hadoop database
The product is ACID-compliant and can power both OLAP and OLTP workloads
Splice Machine is built on Java-based Apache Derby and HBase/Hadoop

Twitter Tag: #briefr The Briefing Room
Guest: Rich Reimer
Rich Reimer, VP of Marketing and Product Management Rich has over 15 years of sales, marketing and management experience in high-tech companies. Before joining Splice Machine, Rich worked at Zynga as the Treasure Isle studio head, where he used petabytes of data from millions of daily users to optimize the business in real-time. Prior to Zynga, he was the COO and co-founder of a social media platform named Grouply. Before founding Grouply, Rich held executive positions at Siebel Systems, Blue Martini Software and Oracle Corporation as well as sales and marketing positions at General Electric and Bell Atlantic.

Splice Machine Proprietary and Confiden4al
ETL: Gatekeeper to Real-‐Time Big Data
Rich Reimer VP, Product Management
August 11, 2015
Splice Machine Proprietary and Confiden4al
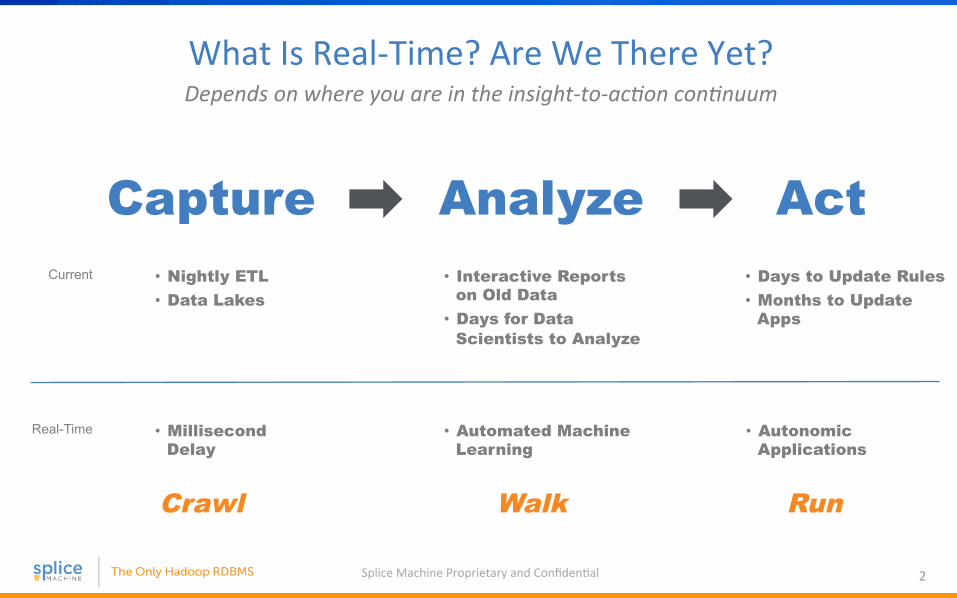
What Is Real-‐Time? Are We There Yet?
2
Capture Analyze Act
Depends on where you are in the insight-‐to-‐ac4on con4nuum
Current
Real-Time
• Nightly ETL • Data Lakes
• Interactive Reports on Old Data
• Days for Data Scientists to Analyze
• Millisecond Delay
• Automated Machine Learning
• Days to Update Rules • Months to Update
Apps
• Autonomic Applications
Crawl Walk Run
Splice Machine Proprietary and Confiden4al
ETL: Boring, Unglamorous, Inevitable Burden
3
“ETL is something you do that nobody no4ces un4l you don’t do it.” -‐ Author Unknown

Splice Machine Proprietary and Confiden4al
But It’s Killing You Slowly…
4
Iner4a and hidden costs dragging your business down
ERP
CRM
…
Data Warehouse
ETL
ODS
Systems of Record
Expensive Scale-up hardware and
proprietary software
Tuning Ongoing database tuning to address performance issues
Script Maintenance
Constant updating of ETL scripts to handle changing
sources and reports
Unable to Meet Business Needs
Takes weeks or months to change or create new reports
Delayed Reports Errors or performance issues cause miss of ETL window
and delay reports
Data Too Old Data is hours or days old, when business needs it near real-time
Too Slow Can take hours or even days to finish
ETL pipeline

Splice Machine Proprietary and Confiden4al
Big Data Makes It Worse
5
ETL becomes bigger boCleneck as data grows
ETL Bo'leneck
Applica1ons Analysis
Source: 2013 IBM Briefing Book
30-40% data growth per year

Splice Machine Proprietary and Confiden4al 6
Scale-‐Out: The Future of Databases Drama4c improvement in price/performance
Scale Up (Increase server size)
Scale Out (More small servers)
vs. $ $ $ $ $ $

Splice Machine Proprietary and Confiden4al
Fixing ETL: Incremental Approach
7
Incremental evolu4on to reduce lag from days to seconds
ETL: Scale-up
ETL: Scale-out
ELT T Only
Legacy Now Now Future
Days/Hours Hours/Minutes Minutes/Seconds No Lag
Transform
Transform Transform
OLTP OLAP OLTP
Transform
OLTP/OLAP OLTP OLAP OLAP
Timing
Timing
Architecture
Lag
Approach

Splice Machine Proprietary and Confiden4al 8
Reference Architecture: Typical Data Processing Pipeline How do you reduce lag from days to minutes to seconds?
Ad Hoc Analytics
Executive Business Reports
Operational Reports & Analytics
ERP
CRM
Supply Chain
HR
…
Data Warehouse
Datamart
Stream or Batch Updates
Mixed Workload Apps ODS
ETL
Systems of Record
Extract
Transform
Load
Splice Machine Proprietary and Confiden4al 9
Ad Hoc Analytics
Executive Business Reports
Operational Reports & Analytics
ERP
CRM
Supply Chain
HR
…
Data Warehouse
Datamart
Stream or Batch Updates
Mixed Workload Apps
ETL
Systems of Record
Extract
Transform
Load
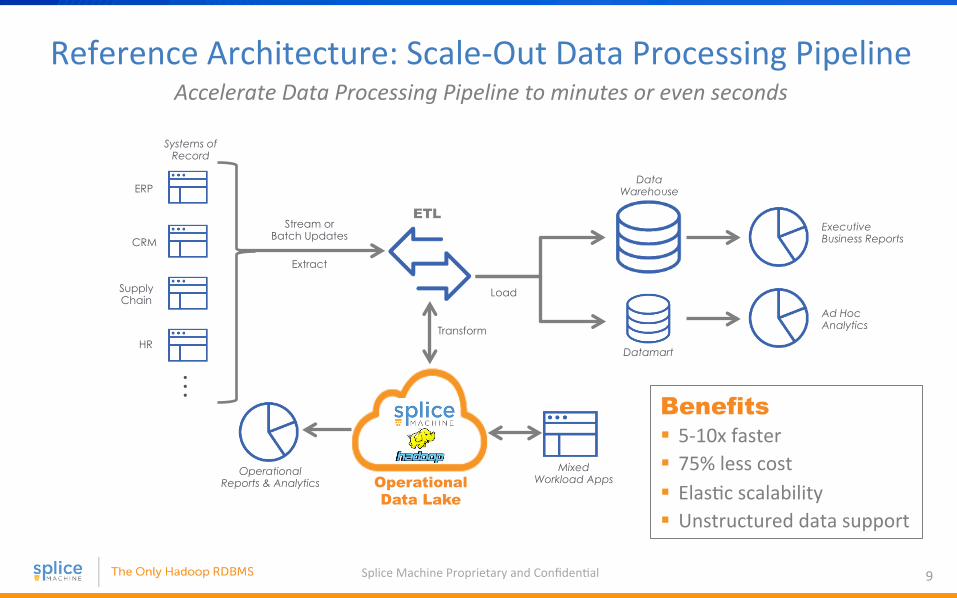
Reference Architecture: Scale-‐Out Data Processing Pipeline Accelerate Data Processing Pipeline to minutes or even seconds
Operational Data Lake
Benefits § 5-‐10x faster § 75% less cost § Elas4c scalability § Unstructured data support

Splice Machine Proprietary and Confiden4al 10
You Need More Than Hadoop By Itself For ETL Errors or data quality issues force ETL restarts
Restart ETL to fix errors or update records
Hours
Seconds
Use transac4on to restart step or update records
Hadoop RDBMS ETL
Hadoop ETL Apps
ETL Analy4cs
Apps
ETL
Hours
Analy4cs
Benefits § SQL-‐based transforms § Improved data quality § Faster recovery with transac4ons

Splice Machine Proprietary and Confiden4al
Streamlining the Structured Data Pipeline in Hadoop
11
Source Systems
ERP
…
CRM
Sqoop
Apply Inferred Schema
Stored as flat files
SQL Query Engines BI Tools
Tradi3onal Hadoop Pipeline
vs.
Source Systems
ERP
…
CRM
Existing ETL Tool
Stored in same
schema
BI Tools
Streamlined Hadoop Pipeline Benefits § Less cost and complexity
§ Faster w/ fewer transla4ons
§ Improved data quality § Bejer SQL support

Splice Machine Proprietary and Confiden4al 12
Seamless Integra4on of Structured and Unstructured Data Op4mizing storage and querying of structured data as part of ELT or Hadoop query engines
OLTP Systems
ERP
CRM
Supply Chain
HR
…
Structured Data
Unstructured Data
HCATALOG
Pig
SCHEMA ON INGEST:
Streamlined, structured-to-
structured integration
1
2
3
SCHEMA BEFORE READ: Repository for structured data or metadata from ELT process on unstructured data
SCHEMA ON READ: Ad-hoc Hadoop queries across structured and unstructured data

Splice Machine Proprietary and Confiden4al
Case Study: Opera4onal Data Lake
13 13
Overview Computer technology corpora4on Update database technology for: ODS layer replacement ETL processing and analysis of Omniture data Real-‐4me OLTP for Global Tech Support app
Challenges Oracle and Teradata too expensive to scale
Many Oracle queries couldn’t complete
Can only hold 7 days worth of data in Oracle
Missing ETL window with current Hadoop data lake
Solu1on Diagram
(400TB)
OLTP Systems
ERP
CRM
Supply Chain
Benefits
75% less cost with commodity scale out
Incremental ETL processing gracefully handle data quality issues
5x-‐10x faster comple4ng queries on which Oracle failed
✔

Splice Machine Proprietary and Confiden4al 14
Internet of Things
ETL/Opera4onal Data Lake Digital Marke4ng
Precision Medicine
Use Cases
Splice Machine | Proprietary & Confiden4al
Fraud Detec4on

Splice Machine Proprietary and Confiden4al 15
Who Are We?
Affordable, Scale-‐Out – Commodity hardware Elas3c – Easy to expand or scale back Transac3onal – Real-‐4me updates & ACID Transac4ons ANSI SQL – Leverage exis4ng SQL code, tools, & skills Flexible – Support opera4onal and analy4cal workloads
10x Bejer
Price/Perf
THE HADOOP RDBMS
Replace Oracle with Splice Machine to scale out your applica4ons

Splice Machine Proprietary and Confiden4al 16
Proven Building Blocks: Hadoop and Derby
APACHE DERBY § ANSI SQL-‐99 RDBMS § Java-‐based § ODBC/JDBC Compliant
APACHE HBASE/HDFS § Auto-‐sharding § Real-‐4me updates § Fault-‐tolerance § Scalability to 100s of PBs § Data replica4on

Splice Machine Proprietary and Confiden4al 17
Distributed, Parallelized Query Execu4on
Parallelized computa4on across cluster Moves computa4on to the data U4lizes HBase co-‐processors No MapReduce
HBase Co-‐Processor
HBase Server Memory Space
LEGEND

Splice Machine Proprietary and Confiden4al
ANSI SQL-‐99 Coverage
18
§ Data types – e.g., INTEGER, REAL, CHARACTER, DATE, BOOLEAN, BIGINT
§ DDL – e.g., CREATE TABLE, CREATE SCHEMA, ALTER TABLE, DELETE, UPDATE TABLE
§ Predicates – e.g., IN, BETWEEN, LIKE, EXISTS § DML – e.g., INSERT, DELETE, UPDATE, SELECT § Query specifica3on – e.g., GROUP BY,
HAVING § SET func3ons – e.g., UNION, ABS, MOD, ALL § Aggrega3on func3ons – e.g., AVG, MAX,
COUNT § String func3ons – e.g., SUBSTRING,
concatena4on, UPPER, LOWER, TRIM, LENGTH
§ Constraints – e.g., PRIMARY KEY, FOREIGN KEY, UNIQUE, NOT NULL
§ Condi3onal func3ons – e.g., CASE, searched CASE
§ Privileges – e.g., privileges for SELECT, DELETE, INSERT, EXECUTE
§ Joins – e.g., INNER JOIN, LEFT OUTER JOIN § Transac3ons – e.g., COMMIT, ROLLBACK,
Snapshot Isola4on § Sub-‐queries § Triggers § User-‐defined func3ons (UDFs) § Views – including grouped views
Splice Machine Proprietary and Confiden4al 19
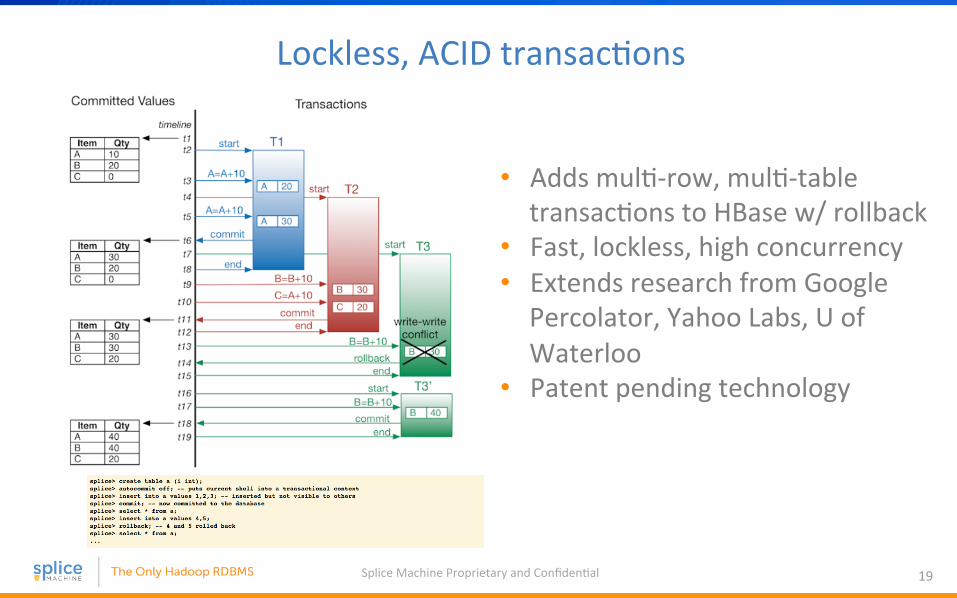
Lockless, ACID transac4ons
• Adds mul4-‐row, mul4-‐table transac4ons to HBase w/ rollback
• Fast, lockless, high concurrency • Extends research from Google Percolator, Yahoo Labs, U of Waterloo
• Patent pending technology

Splice Machine Proprietary and Confiden4al
What People are Saying…
20
Recognized as a key innovator in databases
Scaling out on Splice Machine presented some major benefits
over Oracle ...automa4c balancing between clusters...avoiding the costly
licensing issues. Quotes
Awards
An alterna3ve to today’s
RDBMSes, Splice Machine effec4vely
combines tradi4onal rela4onal database technology with the scale-‐out capabili4es
of Hadoop.
The unique claim of … Splice Machine is that it can run
transac3onal applica3ons as well as support analy4cs on
top of Hadoop.

Splice Machine Proprietary and Confiden4al
Ini4al Advisory Board
21
Advisory Board includes luminaries in databases and technology
Roger Bamford Former Principal Architect at Oracle
Father of Oracle RAC
Mike Franklin Computer Science Chair, UC Berkeley
Director, UC Berkeley AMPLab Founder of Apache Spark
Marie-‐Anne Neimat Co-‐Founder, Times-‐Ten Database Former VP, Database Eng. at Oracle
Ken Rudin Head of Analy4cs at Facebook
Former GM of Oracle Data Warehousing
Abhinav Gupta Co-‐Founder, VP Engineering at Rocket Fuel
Runs 15PB HBase Cluster

Splice Machine Proprietary and Confiden4al 22
The First Step to Real-‐Time Big Data Requires Fixing ETL
ETL on Hadoop § Drive lag down from
hours è minutes è seconds § Start by replacing ODS with
Opera4onal Data Lake § 5-‐10x faster and ¼ cost
Splice Machine § Replace RDBMSs like Oracle
and MySQL § Best of both worlds
§ SQL and transac4ons of RDBMSs § Scale-‐out of NoSQL
§ 10x bejer price/performance
Transform
Transform Transform
OLTP OLAP OLTP
Transform
OLTP/OLAP OLTP OLAP OLAP
ETL: Scale-up ETL: Scale-out ELT T Only

Splice Machine Proprietary and Confiden4al
ETL: Gatekeeper to Real-‐Time Big Data
Rich Reimer VP, Product Management
August 11, 2015

Splice Machine Proprietary and Confiden4al
Focused on Opera4onal Workloads
24

Splice Machine Proprietary and Confiden4al 25
Oracle Vs Splice Machine TCO comparison
Oracle RAC Costs List Price Unit 3 Year Cost (Discounted 60%)
Oracle Database Enterprise Edi4on with RAC
$37,750 64 $966,400
3 years DB Maintenance (22% list price/yr)
$24,915 64 $637,824
3 years Opera4ng System Support (Oracle Linux)
$6,897 4 $11,035
Server Costs (mid-‐range, Intel Xeon-‐based)
$16,000 4 $64,000
Primary Storage $143,360 $143,360
TOTAL $228,922 $1,822,619
Assumes Oracle Enterprise Edi4on ($47.5K/CPU) and RAC ($23K/CPU)
Splice Machine Costs List Price Unit 3 Year Cost (without discount)
Splice Machine Annual Subscrip4on
$10,000 7 $210,000
Cloudera Enterprise Edi4on Annual Subscrip4on
$7,500 8 $180,000
Server Costs with Storage $5,000 8 $40,000
TOTAL $22,500 $430,000
76% TCO Reduc3on

Twitter Tag: #briefr The Briefing Room
Perceptions & Questions
Analyst: Robin Bloor

Life in the Data Lake
Robin Bloor, Ph.D.

Hadoop: One Ring to Rule Them All
Hadoop has become the de facto processing environment for big
data.
Is it going to become the de facto environment for
ALL SERVER COMPUTING?

Empires to Conquer
u Big Data
u Analytics
u Real-time analytics
u OLTP
u Document shares
u Office systems
✔ ︎
✔ ︎
?
?
? ?
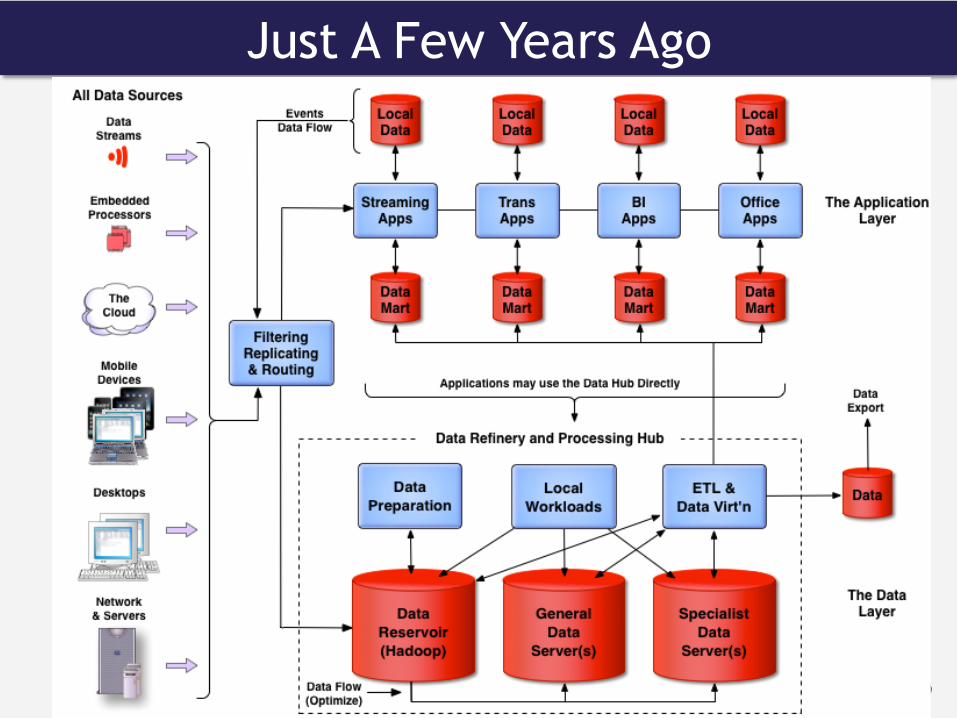
Just A Few Years Ago

What Hadoop Dreams Of

Hadoop Possibilities?
u Hadoop is evolving faster than any equivalent technology I can remember
u It has a very long way to go to become the “server OS for everything.”
u First it would need to become a genuine OS
u It has no stated direction.
u It may vanish into the cloud.
u Nevertheless it is interesting to watch

The Net Net
Meanwhile, it has become a lab for server software

u It’s not just ETL: it’s ETL, data cleansing, metadata capture, MDM, etc. How do you accommodate that?
u Do you have any ETL customer experiences to report?
u How’s your OLTP business going? (Is this ETL emphasis a complementary activity?)
u How well are you doing versus Oracle?

u How well does it integrate with other technologies?
u What is your current largest customer(s)?
u Do you have any direct competition on Hadoop?

Twitter Tag: #briefr The Briefing Room

Twitter Tag: #briefr The Briefing Room
Upcoming Topics
www.insideanalysis.com
August: REAL-TIME DATA
September: HADOOP 2.0
October: DATA MANAGEMENT

Twitter Tag: #briefr The Briefing Room
THANK YOU for your
ATTENTION!
Some images provided courtesy of Wikimedia Commons and by basykes [CC BY 2.0 (http://creativecommons.org/licenses/by/2.0)], via Wikimedia Commons (https://upload.wikimedia.org/wikipedia/
commons/9/94/Beijing_traffic_jam.jpg)