geospatially enabling your spark and accumulo clusters with locationtech
TRANSCRIPT

APPLICATIONS WITH
GEOSPATIALLY ENABLE YOUR
Rob Emanuele @lossyrob @

APPLICATIONS WITH
GEOSPATIALLY ENABLE YOUR
Rob Emanuele @lossyrob @

What we’ll be covering…
What does “processing geospatial data at scale” mean?
What are Accumulo and Spark?
What is LocationTech?
How GeoMesa, GeoWave, and GeoTrellis can GeoSpatially enable your projects.

PROCESSING GEOSPATIAL DATA @ SCALE

PROCESSING GEOSPATIAL DATA @ SCALE
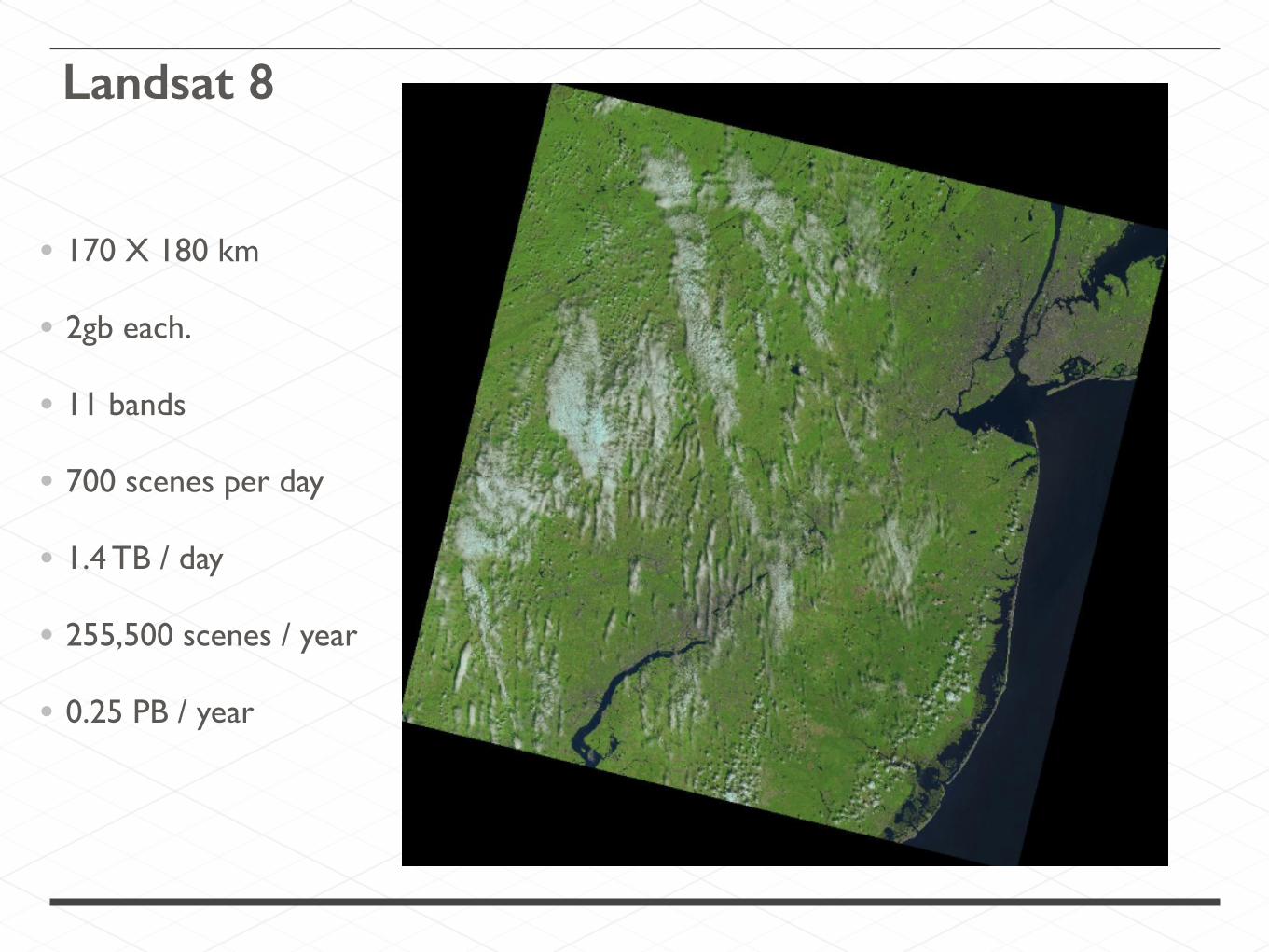
• 170 X 180 km
• 2gb each.
• 11 bands
• 700 scenes per day
• 1.4 TB / day
• 255,500 scenes / year
• 0.25 PB / year
Landsat 8
Landsat 8 on
• All Landsat 8 scenes from 2015 and beyond.• Selection of cloud-free scenes from 2013 and 2014.
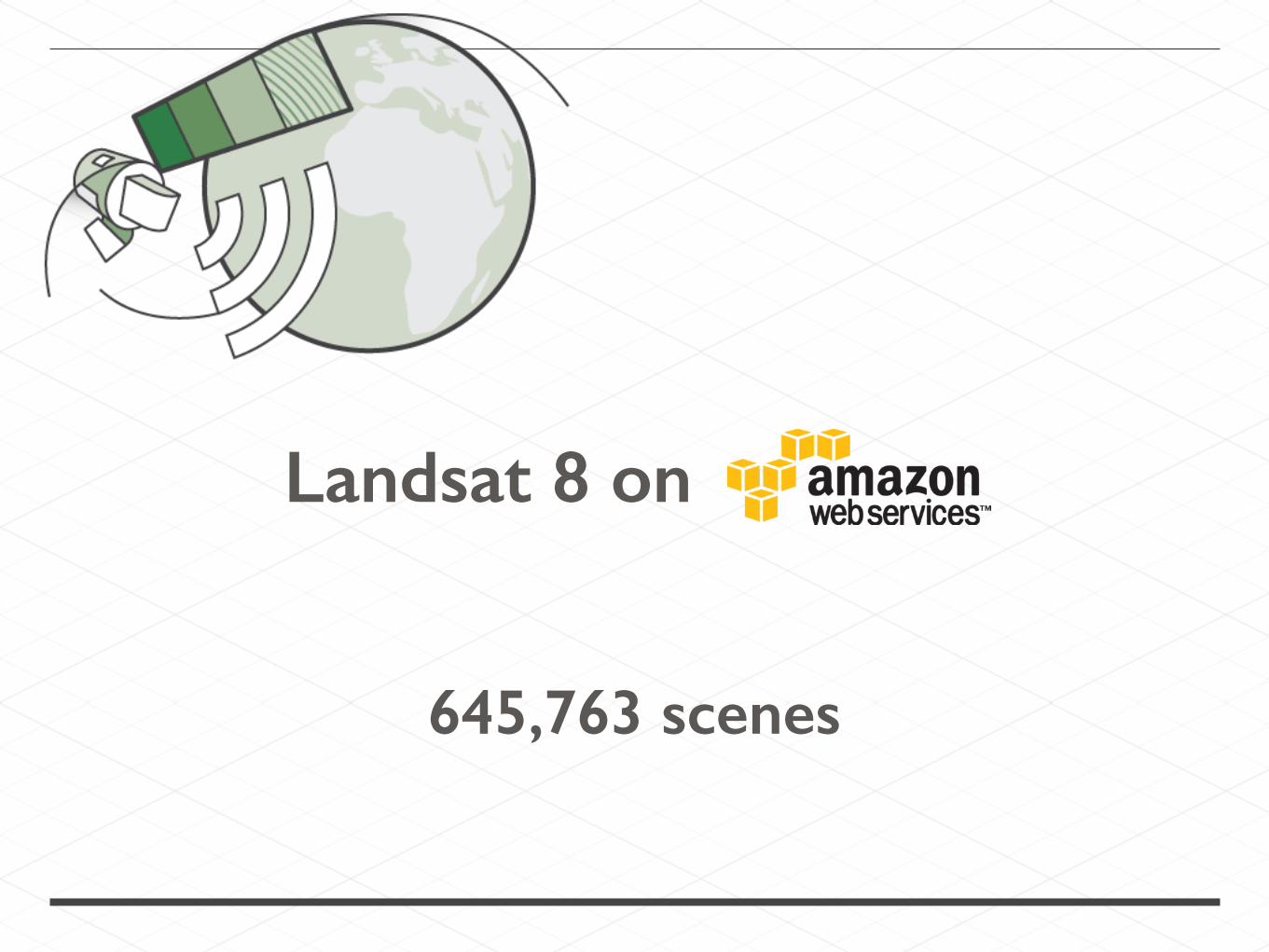
Landsat 8 on
645,763 scenes
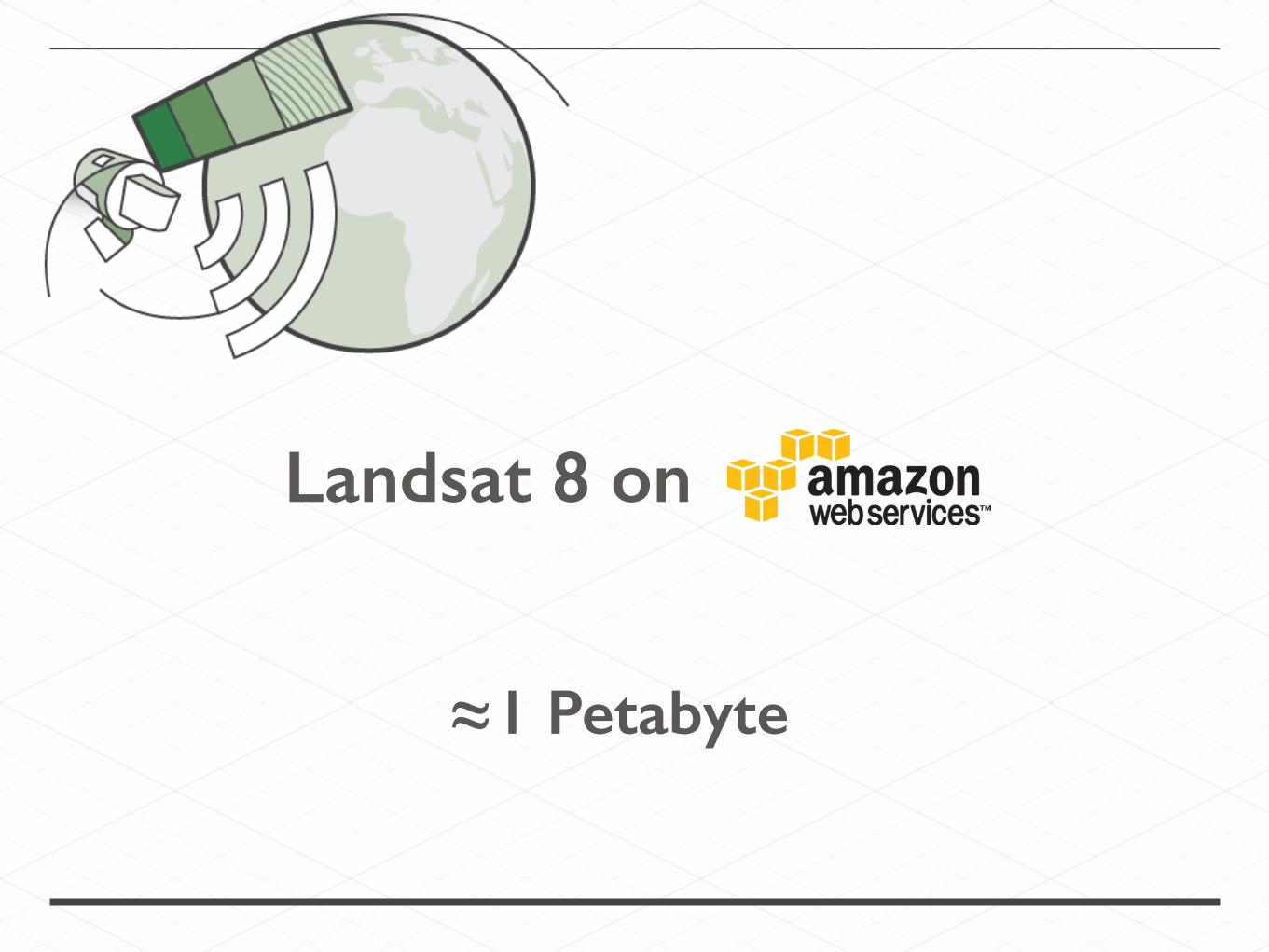
Landsat 8 on
≈1 Petabyte

64 GB

32 Landsat 8 Scenes
This many people’s phones could hold all the Landsat 8 AWS is holding.

PROCESSING GEOSPATIAL DATA @ SCALE

PROCESSING GEOSPATIAL DATA @ SCALE

PROCESSING GEOSPATIAL DATA @ SCALE




Apache Spark
a distributed computation engine.
An API that lets you work with distributed data as a collection.
Written in Scala, with language bindings for use with Java, Python, and R.
Hey Flyers Fans, what is the total count of Landsat 8 Scenes on your phones?

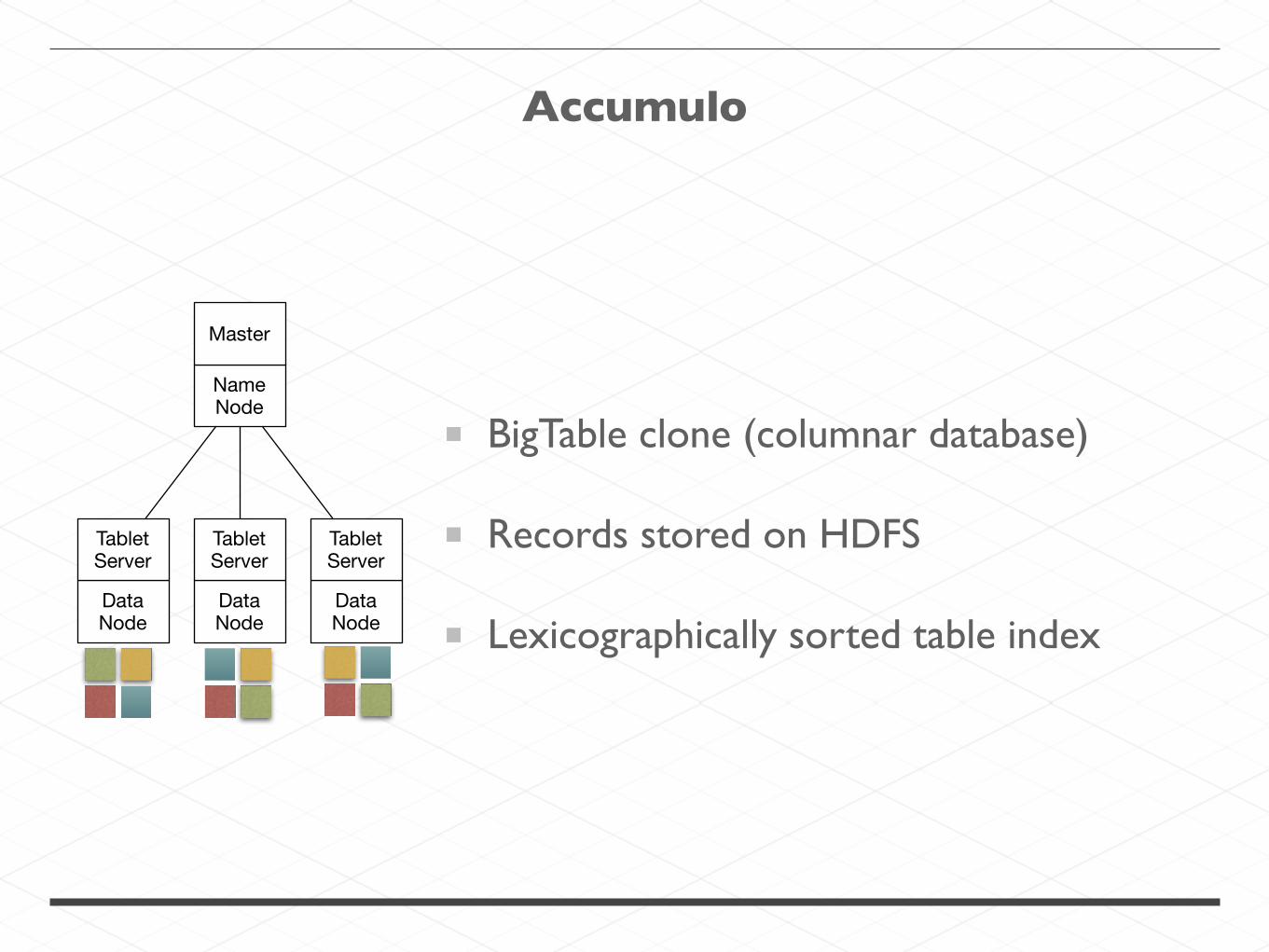
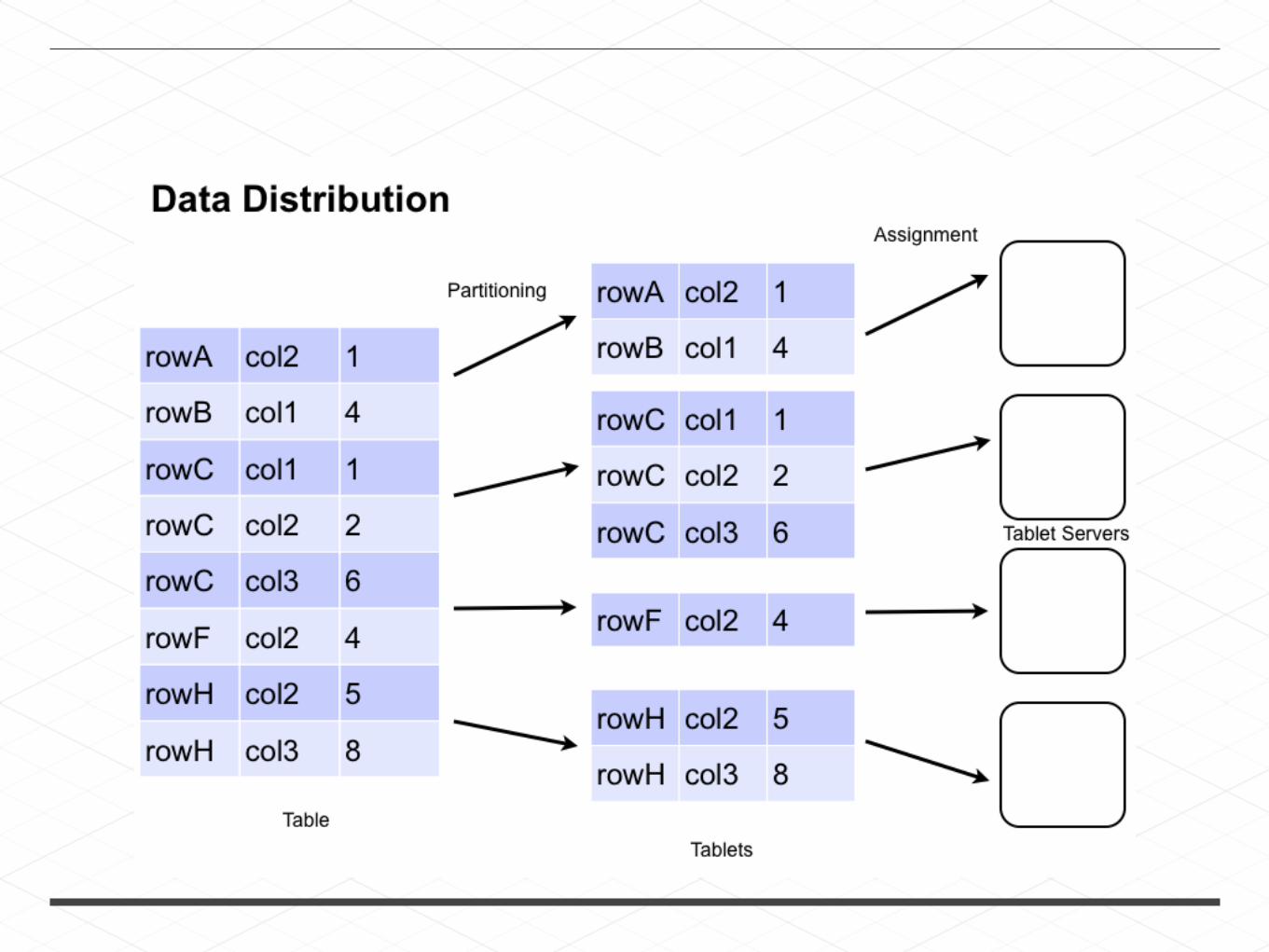
Data Node
Data Node
Data Node
Name Node
Master
Tablet Server
Tablet Server
Tablet Server
Accumulo
BigTable clone (columnar database)
Records stored on HDFS
Lexicographically sorted table index
Hey Flyers Fans, what is the total count of Landsat 8 Scenes on your phones per month?


PROCESSING GEOSPATIAL DATA @ SCALE

PROCESSING GEOSPATIAL DATA @ SCALE




WHAT IS ?


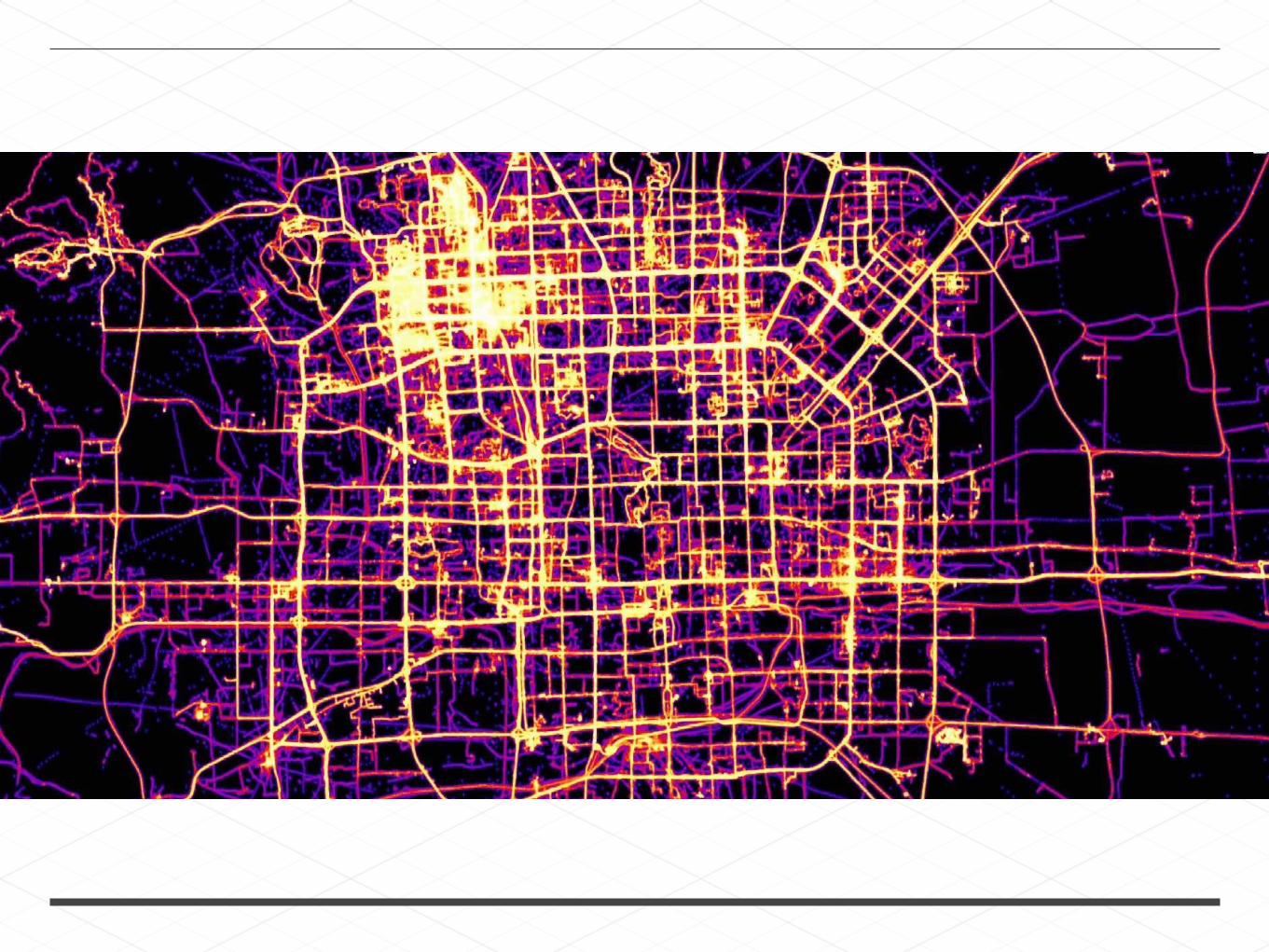
SPACE FILLING CURVES
Hey Flyers Fans, what is the total count of Landsat 8 Scenes on your phones per month, per country?
Hey Flyers Fans, what is the total count of Landsat 8 Scenes on your phones per country?
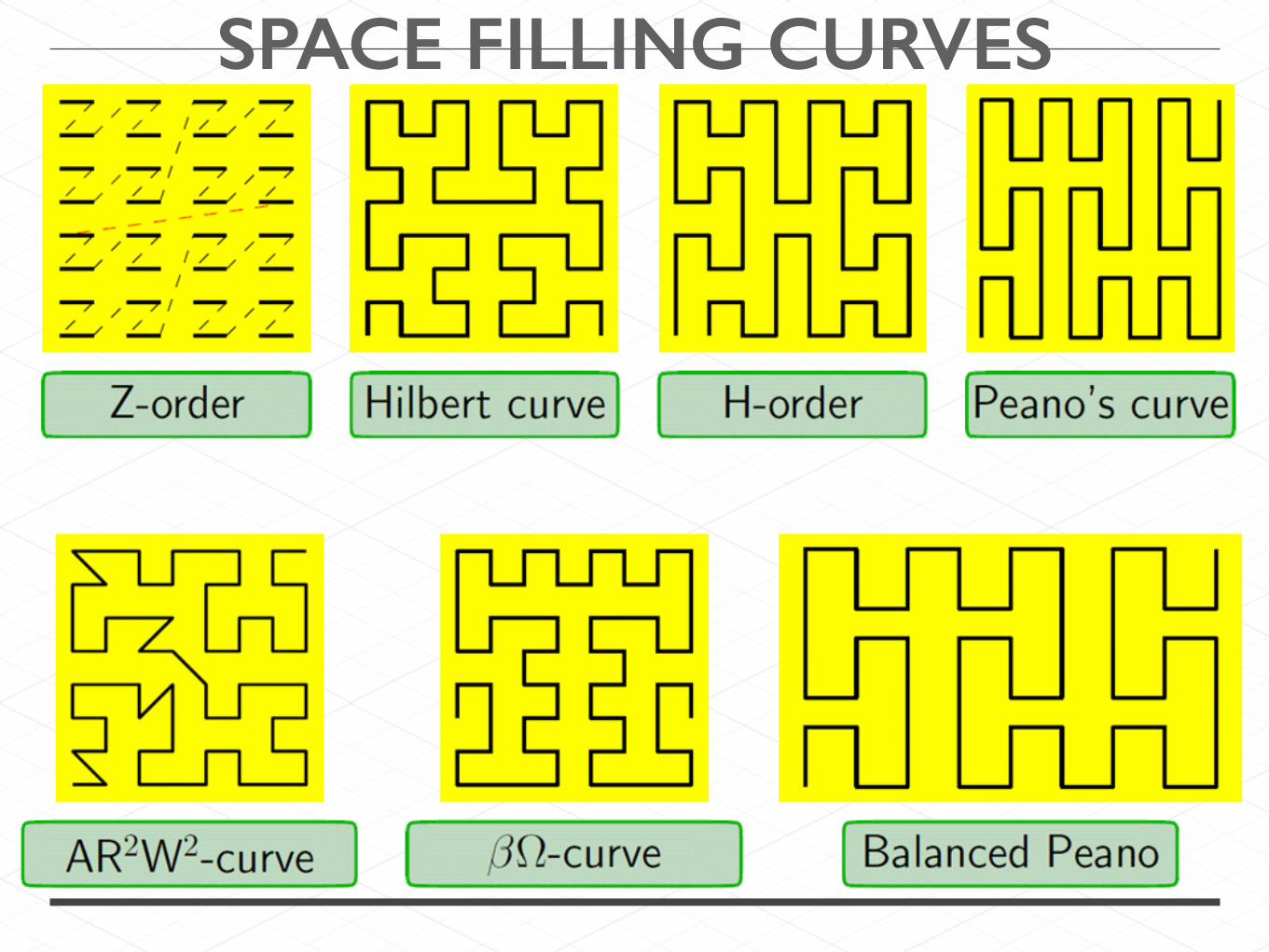
SPACE FILLING CURVES
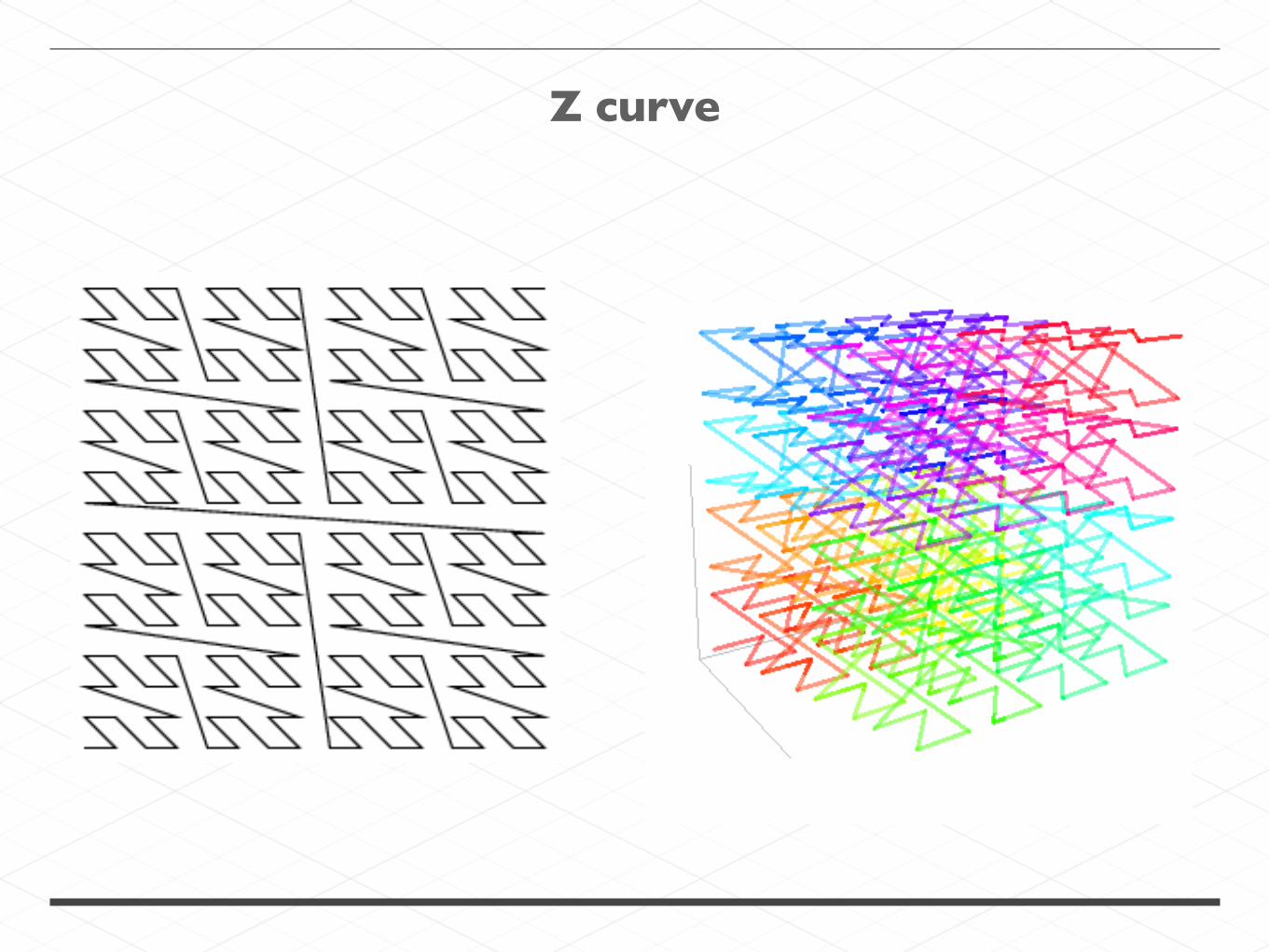
Z curve
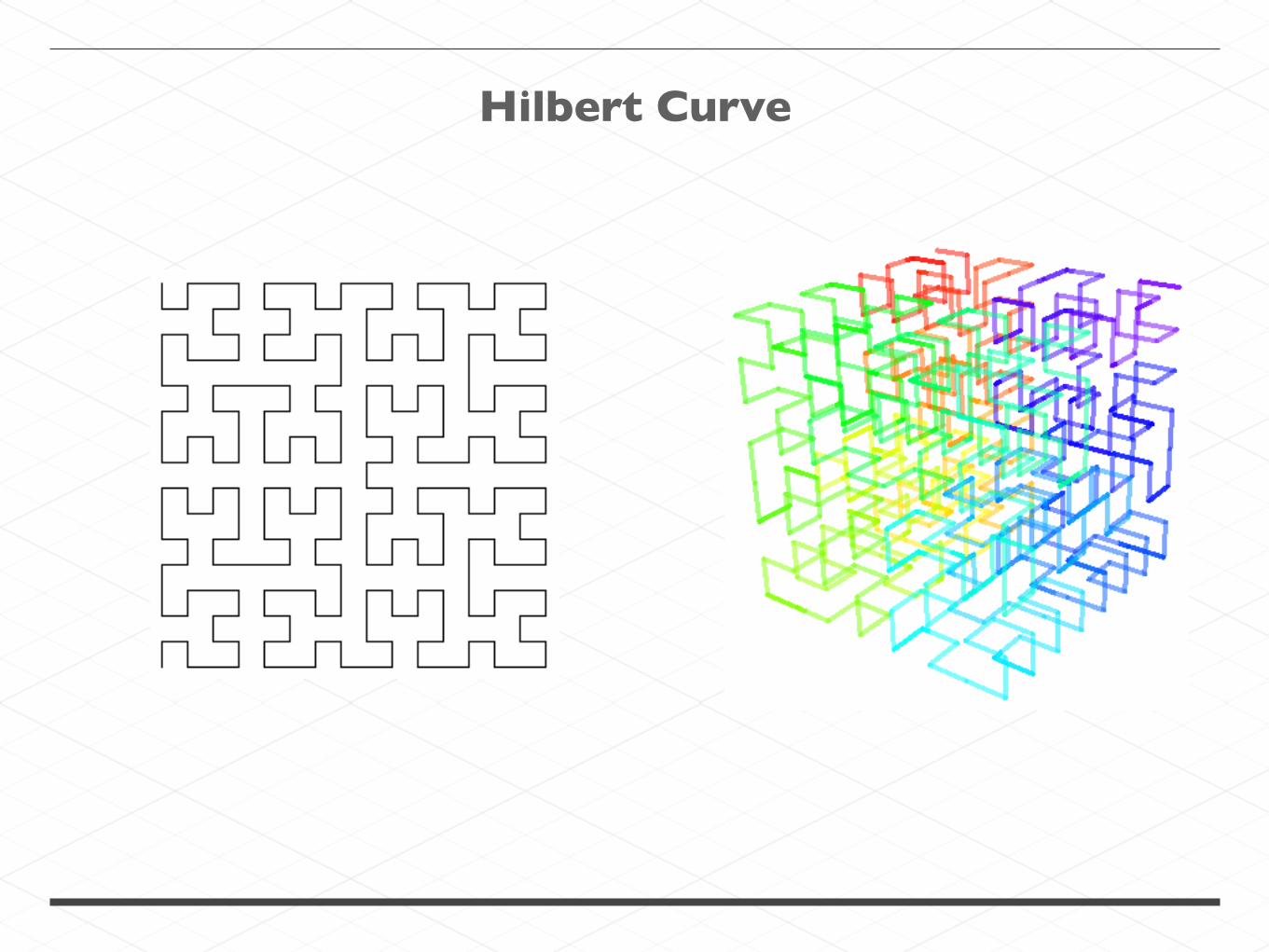
Hilbert Curve
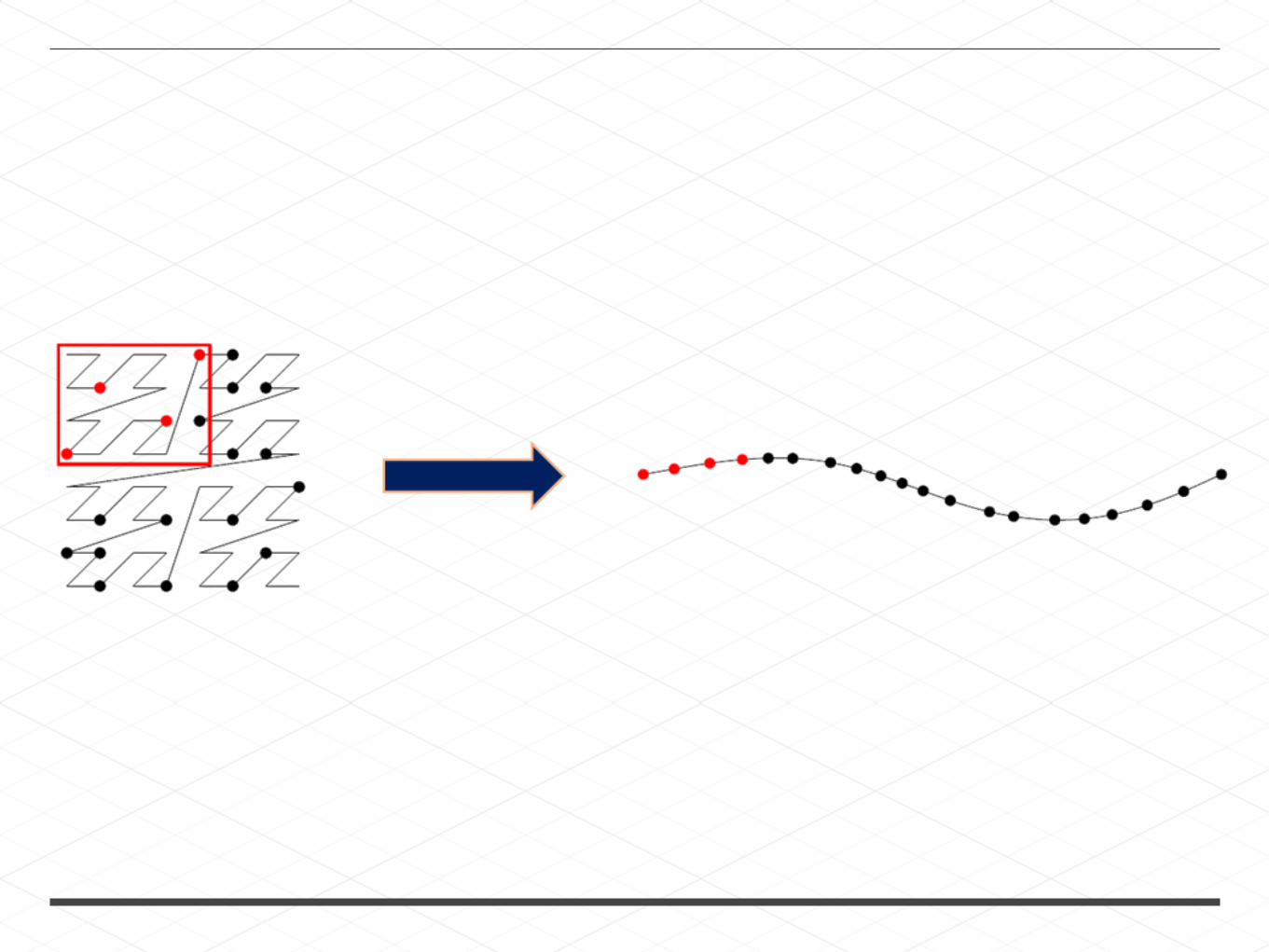

Hey Flyers Fans, what is the total count of Landsat 8 Scenes on your phones A) per month, B) per country,
C) per both?


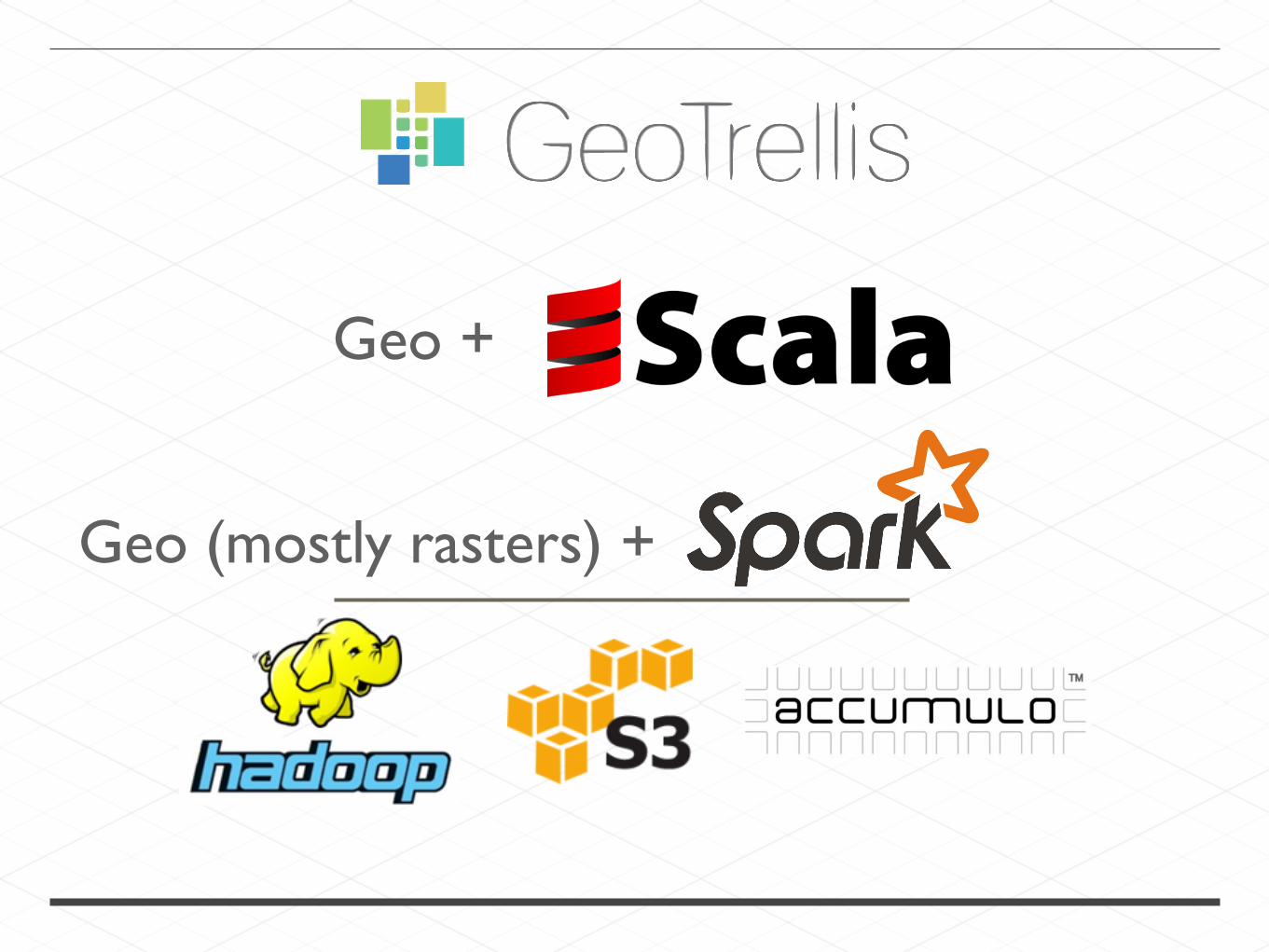
Geo +
accessed through
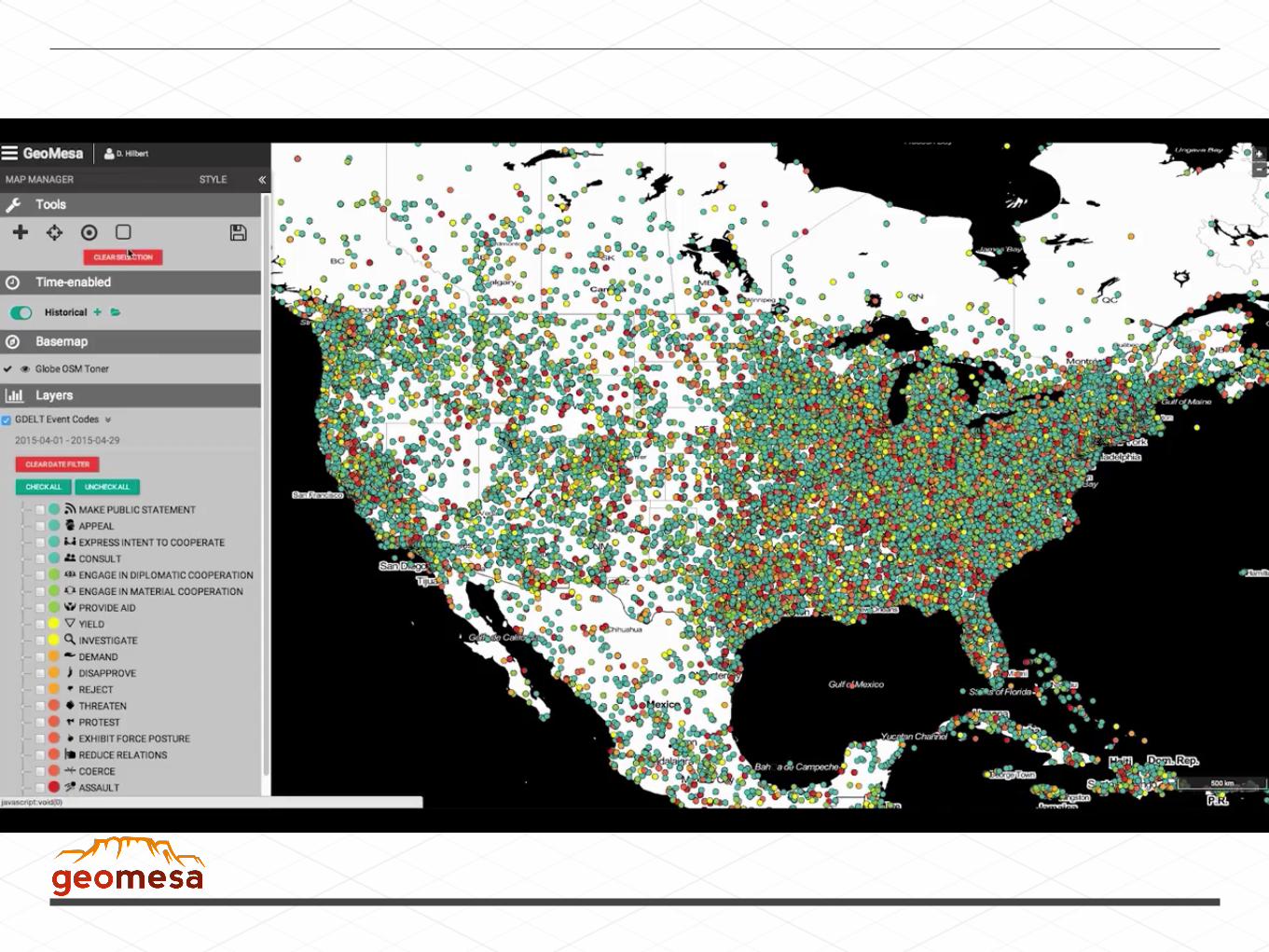
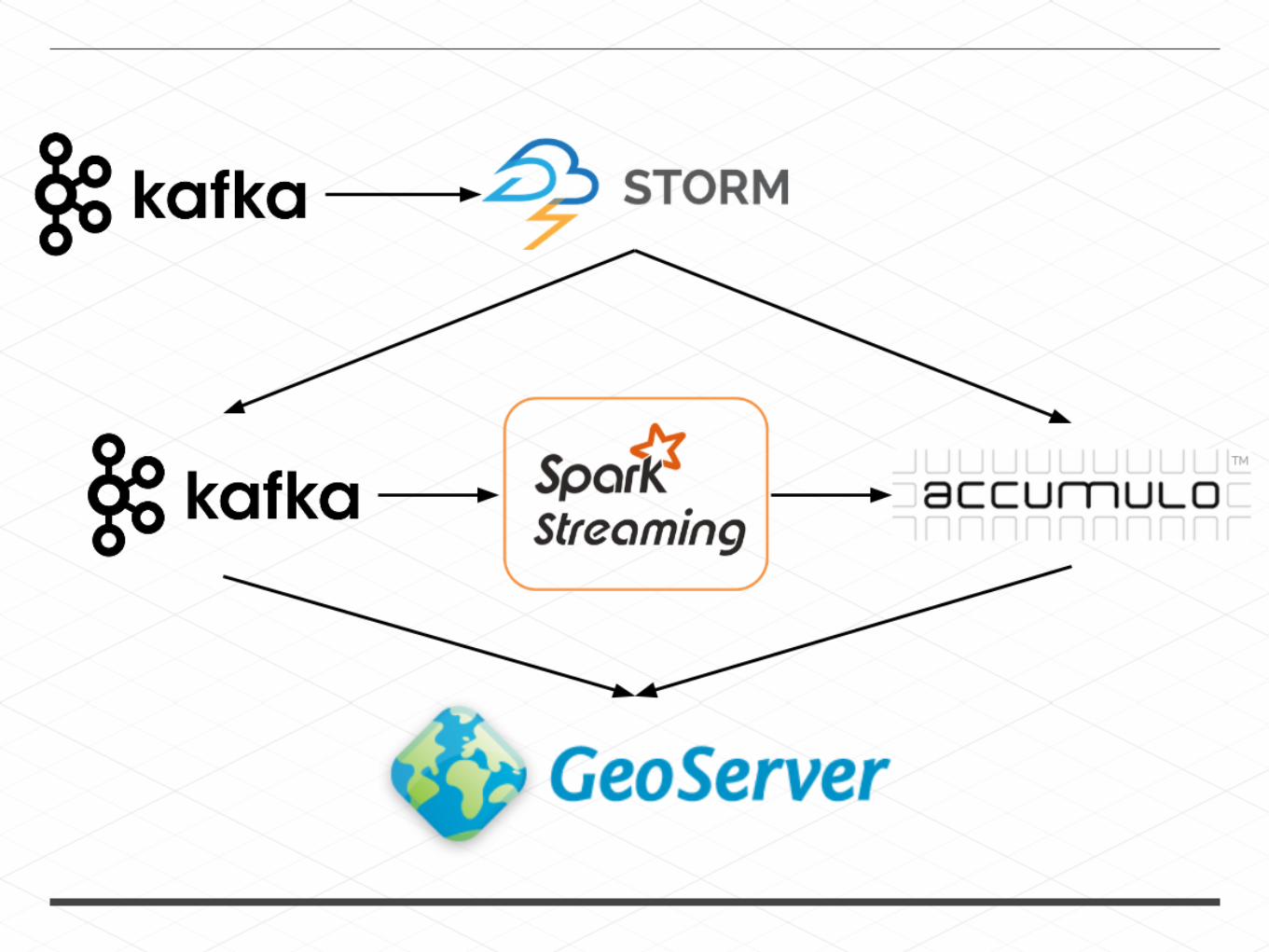

SELECT tweet.text, user.name FROM tweet, userWHERE bbox(tweet.location, -115, 45, -110, 50) AND tweet.user_id = user.user_id
+


Geo +
accessed through
GEOWAVE
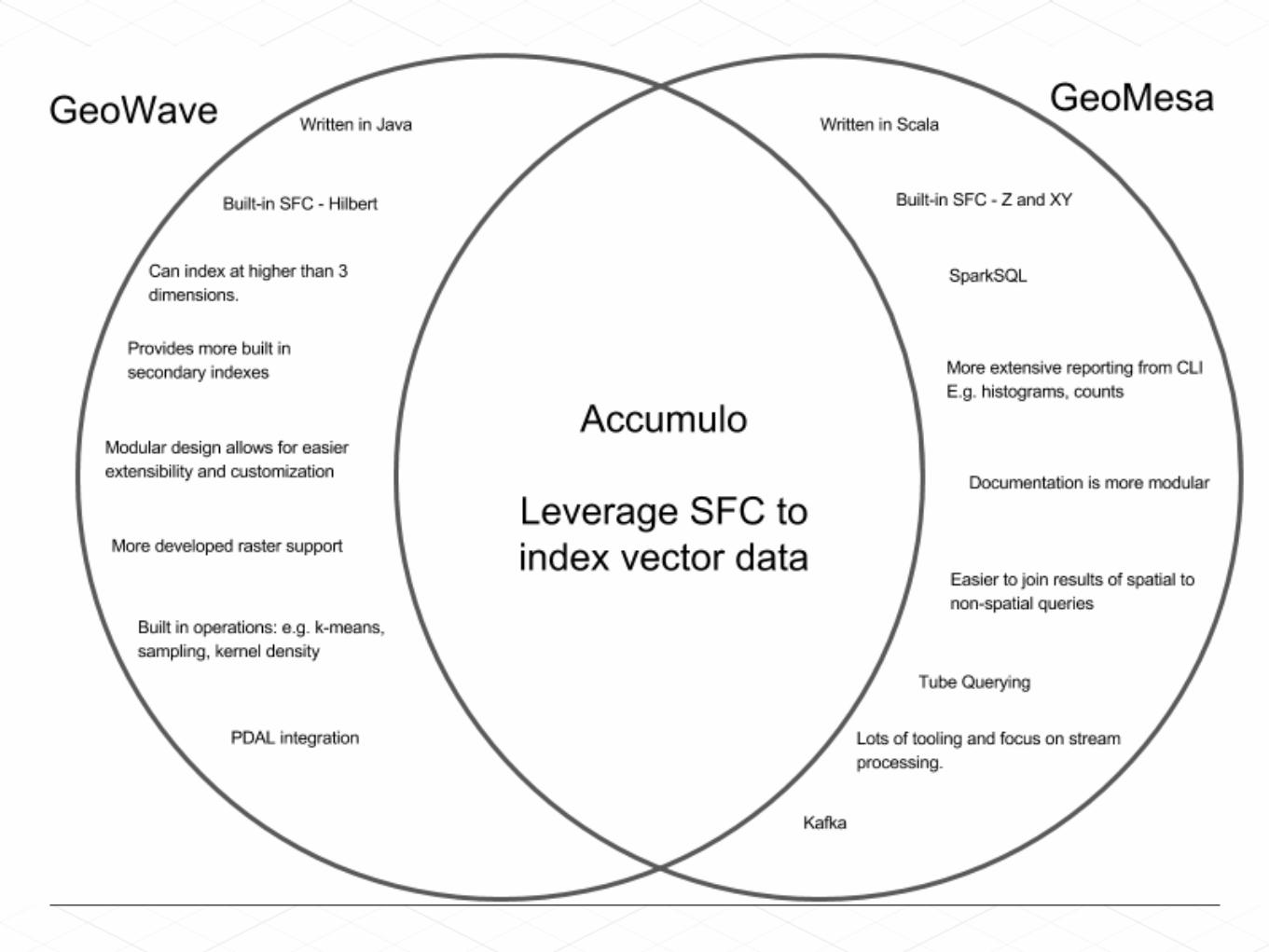


Geo +
Geo (mostly rasters) +

100 spot instance m3.xlarge workers @ $0.04 / hr = $4.00 / hr
400 CPUs / ≈1.5 TB memory
1 master m3.xlarge on-demand instance @ $0.26 / hr
EMR cluster charge, $0.07 / hr
$4.37 / hr
Rendering elevation with hillshade + NLCD on AWS EMR

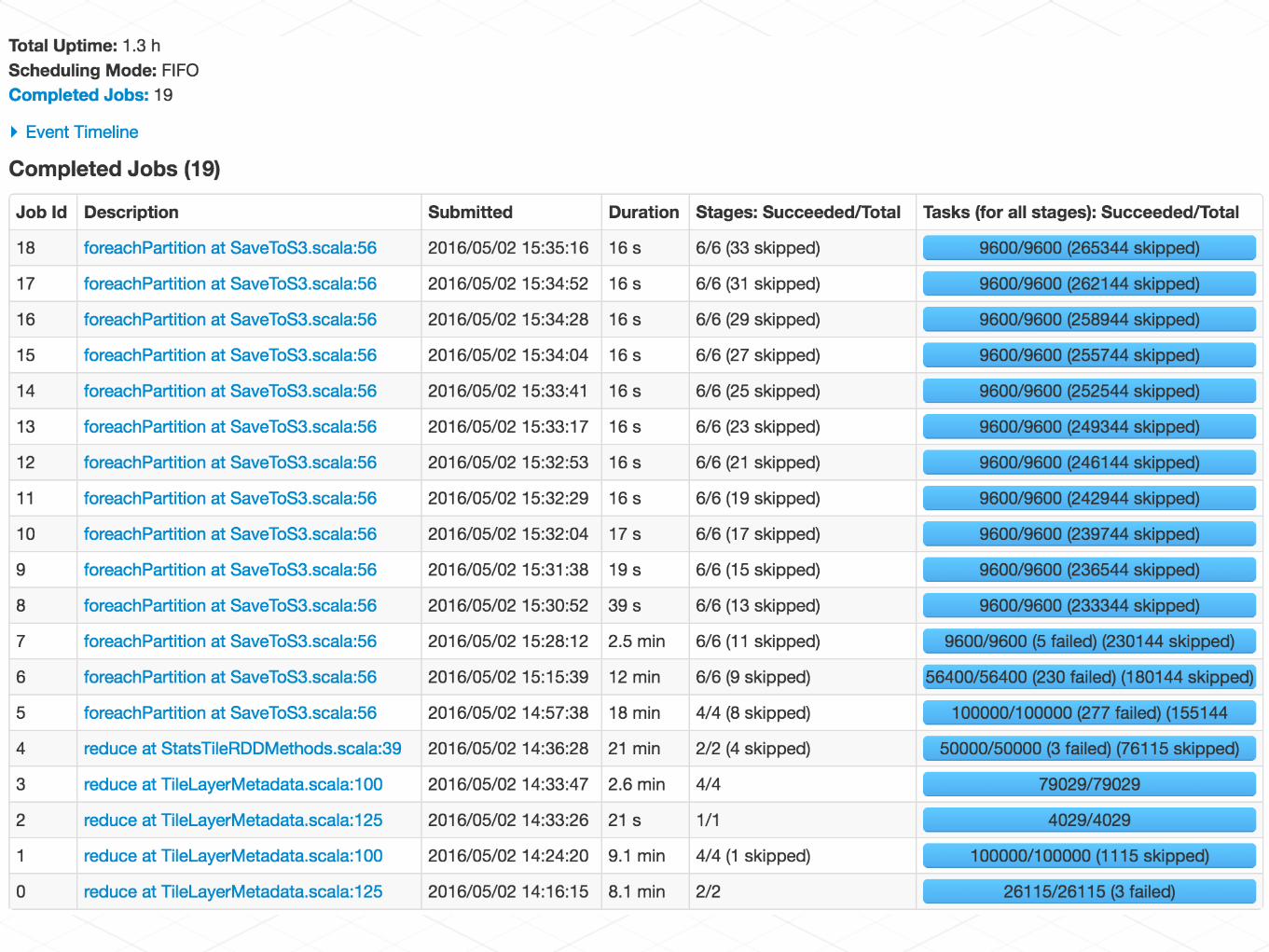
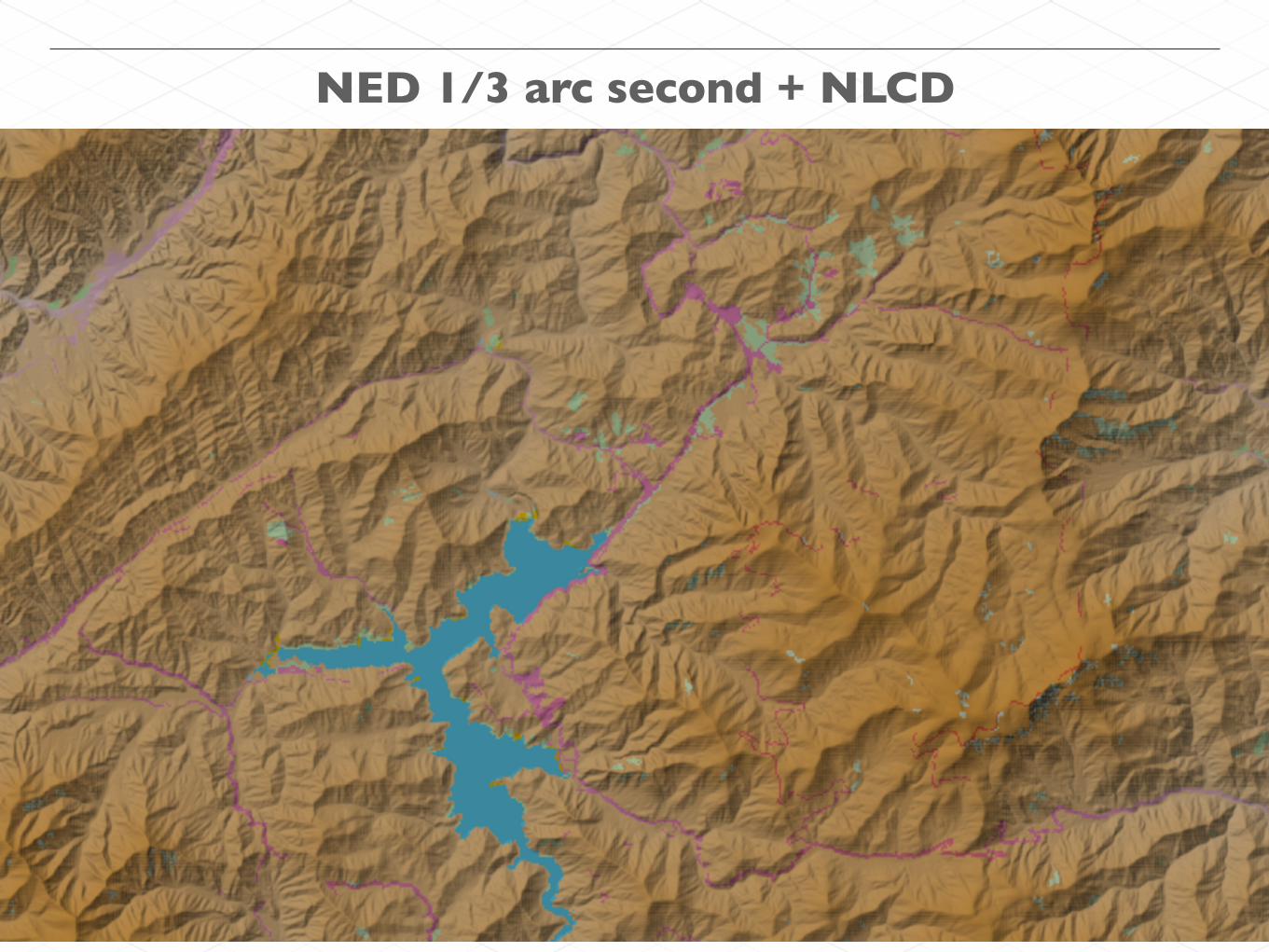
NED 1/3 arc second + NLCD

NED 1/3 arc second + NLCD

NED 1/3 arc second + NLCD

Hey Flyers Fans, can you take the average pixel value of each scene’s band and derive a EPSG:3857 tile set of PNGs to be served on web
maps?


Collaboration
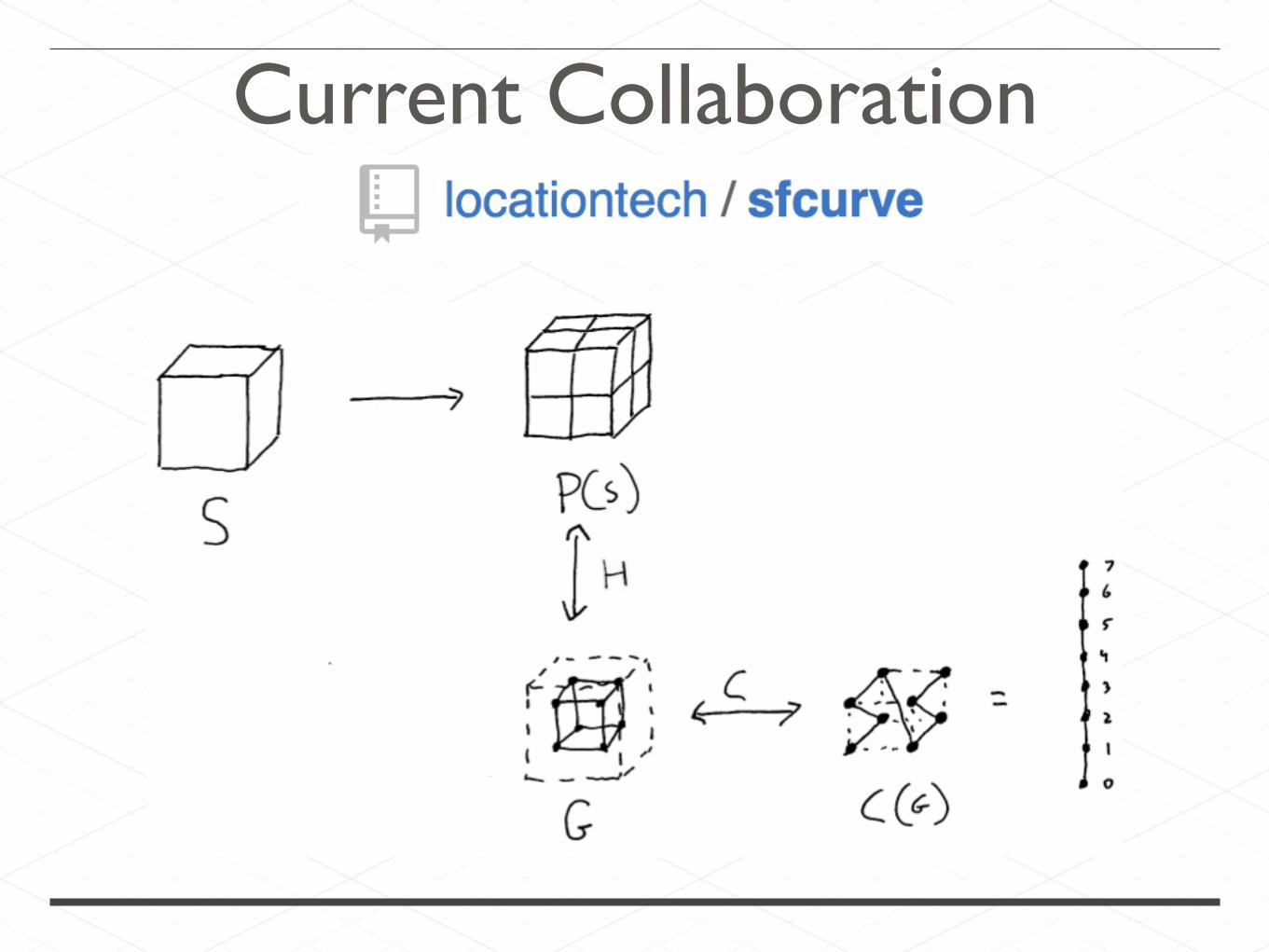
Current Collaboration

Current Collaboration

Future Collaboration

Future Collaboration

• Come see us at our booth
• Join the locationtech-iwg mailing list
• Share you big geospatial data challenges
Get involved!

THANK YOU
@lossyrob
gitter.im/geotrellis/geotrellis
github.com/geotrellis/geotrellis