ge iot predix time series & data ingestion service using apache apex (hadoop)
TRANSCRIPT

Predix Time Serieswith Apache Apex

Hello!VenkatPredix Data Services, GE DigitalBig Data & Analytics@WalmartLabs.
PramodSenior Architect, DataTorrent Inc, Apex PPMC Member

QuickSurvey

▪Predix Platform Overview▪Predix Time Series▪Apache Apex▪Stream Processing with Apex – Journey and
Learning▪Demo▪Q & A
Outline

▪Platform for Industrial Internet▪Based on Cloud Foundry▪Provides rich set of services for rapid
development▪Managed and Secured infrastructure▪Marketplace for Services
Predix Platform

Want big impact?
Use big image.

Predix Platform Architecture

Who we are?
Team Data ServicesLove Java and GoDistributed SystemsBig & Fast DataWe are Hiring!
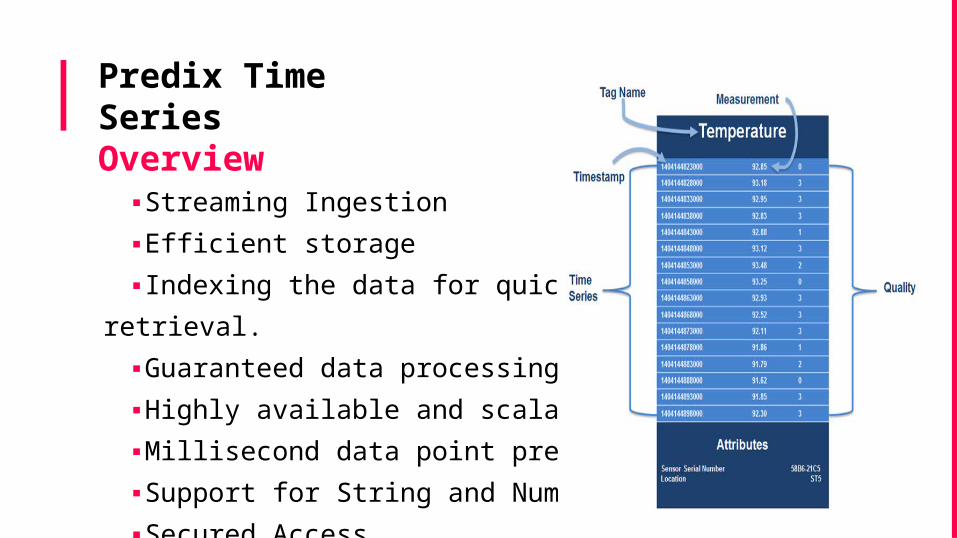
Predix Time SeriesOverview
▪Streaming Ingestion▪Efficient storage ▪Indexing the data for quick retrieval.▪Guaranteed data processing▪Highly available and scalable.▪Millisecond data point precision▪Support for String and Numbers▪Secured Access

Predix Time SeriesArchitecture

▪Support Interpolation ▪Aggregations (percent, avg, sum,
count)▪Filter by Attributes, Quality and
Value▪Support for Limit and Order By▪Both GET and POST to retrieve
data points▪Sub-second query performance
Predix Time Series API Sample
{ "tags": [ { "name": ["WIND_SPEED"], "filters": { "attributes": { "farm":["CA"] } }, "limit": 1000, "groups": { } } ]}

▪Signup @ Predix.io▪Create Time Series Instance▪Bind to an application▪Get credentials and connect your
device▪Query the data
Predix Time Series Get Started?

Apache Apex Overview
▪ Streaming Analytics Platform
▪ Event based, low latency▪ Scalable and Highly
available▪ Managed State▪ Library of pre-built
operators

Apex Platform

Stream Processing
EventsReader
Filter Operator
Filter Operator
“Top K”Operator
“Top K”Operator
DatastoreWriter
PartitionStream
UnifyStream
DAG
Local/Remote
Find Top K engines with High/Low Oil pressure

Windowing Support
Application window
Sliding/Tumbling Window
Checkpoint window
No artificial latency

Application Specification

Why Apache ApexDevelopment
High Performance and Distributed
Dynamic Partitions
Rich set of operator library
Support for atleast-once, atmost-once and exactly-once processing semantics
Operations
Hadoop/Yarn Compatibility
Fault tolerance and Platform Stability
Ease of deployment and operability
Enterprise grade security

Time Series DAG
Skimmed Version of the DAG

Partitioning Strategies

InputOperator
DetectionOperator
OutputOperator
Logical DAG
DetectionOperator
Input Operator
DetectionOperator
UnifierOperator
DetectionOperator`
OutputOperator
1
2
3
Physical DAG

▪Utilize hashcode and mask to determine Partition
▪Mask picks the last n bits of the hashcode of the tuple
▪StreamCodec can be used to specify custom hashcode
▪Custom partitioner can be used to change default map
Stream Split
tuple:{Sensor, 98871231, 34, GOOD}
Hashcode: 001010100010101
Mask (0x11) Partition
00 1
01 2
10 3
11 4

MxN PartitioningInput
OperatorDetectionOperator
DetectionOperator
OutputOperator
OutputOperator
Input Operator
Input Operator
DetectionOperator
OutputOperator
DetectionOperator
Default Mechanism
StatelessPartitioner<property> <name>dt.application.<streamingApp>.operator.<name>.attr.PARTITIONER</name> <value>com.datatorrent.common.partitioner.StatelessPartitioner:4</value></property>

Parallel Partitioning
InputOperator
DetectionOperator
DetectionOperator
OutputOperator
OutputOperator
Input Operator
Input Operator
DetectionOperator
OutputOperator
<property> <name>dt.application.<streamApp>.operator.<name>.port.input.attr.PARTITION_PARALLEL</name> <value>true</value></property>

Unifier
▪Combines outputs of multiple partitions▪Runs as an operator▪Logic depends on the operator functionality
▸Example if operator is computing average, unifier is computing final average from individual average and counts
▪Default unifier if none specified▪Helps with skew▪Cascading unification possible if unification needs to be
done in multiple stages

Custom partitioning
▪Custom stream splitting
▪Distribution of state during initial or dynamic partitioning Kafka operators scale according to number of kafka partitions Re-distribution of state during dynamic partitioning
tuple:{Sensor, 98871231, 34, GOOD}
Hashcode: 001010100010101
Mask (0x00) Partition
00 1
00 2
00 3
00 4

Time Series DAG

Check pointing is tied to the application id. This problem becomes pertinent if you are relying on that state to do further processing.
Solution
Store states that matter externally, eg. HDFS, Zookeeper, Redis.
Problems Encountered

Kafka Source was moving an offset as committed as soon as it read. Becomes a problem when the message is not completely processed by the DAG
Solution
Kafka Source was modified to wait till the messages are
entirely processed in the DAG. Thanks to the community! We also
implemented an offset manager and stored the
offset in ZK
Problems Encountered

Gracefully stopping DAG during upgrade, to get exactly once semantics, when downstream systems cannot handle duplicates or support transactions
Solution
Added a property to Mute the Source
Operators and drain the messages before you bring the streaming pipeline down. APIs
available for automation.
Problems Encountered

Event time based processing and out of order data arrival
Solution
We have built some Spooling Data structures
working with the apex team. Working to open
source this.
Problems Encountered

Key Takeaways
▪Upgradeability and tolerance for failure▪Monitoring DAG for failures▪Static partitioning helps only so much▪Continuous Integration and Deployment▪Performance Testing and Benchmarking▪Ship and Store logs

Fault Tolerance

Fault tolerance
▪Operator state is checkpointed to a persistent store▸Automatically performed by engine, no additional work
needed by operator▸In case of failure operators are restarted from
checkpoint state▸Frequency configurable per operator▸Asynchronous and distributed by default▸Default store is HDFS
▪Automatic detection and recovery of failed operators▸Heartbeat mechanism
▪Buffering mechanism to ensure replay of data from recovered point so that there is no loss of data
▪Application master state checkpointed

Message Processing SemanticsAtleast once [1..n]▪On recovery operator state is restored to a checkpoint
▪Data is replayed from the checkpoint so it is effectively a rewind
▪Messages will not be lost▪Default mechanism and is suitable for most
applications▪End-to-end exactly once i.e., data is written only once
to store in case of fault recovery▸Idempotent operations▸Rewinding output▸Writing meta information to store in transactional
fashion▸Feedback from external store on last processed
message

Message Processing SemanticsAtmost once [0,1]▪On recovery the latest data is made available to
operator▪Useful in use cases where some data loss is
acceptable and latest data is sufficientWindowed exactly once [0,1]▪Operators checkpointed every window▪Can be combined with transactional mechanisms to
ensure end-to-end exactly once behavior

Stream Locality
▪By default operators are deployed in containers (processes) randomly on different nodes across the hadoop cluster
▪Custom locality for streams▸Rack local: Data does not traverse network switches▸Node local: Data is passed via loopback interface and
frees up network bandwidth▸Container local: Messages are passed via in memory
queues between operators and does not require serialization
▸Thread local: Messages are passed between operators in a same thread equivalent to calling a subsequent function on the message

What happens during launch?
▪User launches an application using the management console or command line client
▪DAG gets assembled on the client▪DAG and dependency jars gets saves to HDFS▪App Master (StrAM) gets launched on a
Hadoop node▸Converts logical plan to physical plan▸Figures out execution plan▸Requests containers from Hadoop▸Launches StreamingContainer in individual
containers with relevant operators

Kafka Operator
▪Supports both High and Low Level API Implementation▪Finer level control of offset for Exactly-Once Semantics▪Supports ONE_TO_ONE and ONE_TO_MANY Partition
Strategy▪Consume by size and number of messages▪Fault tolerent to recover from offsets

Debugging Issues
▪Distributed systems are hard to debug▪LocalMode comes handy for developer testing and
debugging▪Enable Yarn log aggregation
▸yarn logs –applicationID <App_Id>▪DataTorrent webconsole provides streaming access to
AppMaster and Container logs▪Understanding what happens where
▸AppMaster▸NodeManager▸Containers

Demo




Thanks!!Any questions?You can find us at @venkyz and @pramod

Bulk Upload - DAG
Rule Based Alerting - DAG