fragmented handwritten digit recognition using grading
TRANSCRIPT

Fragmented handwritten digit recognition using gradingscheme and fuzzy rules
JYOTISMITA CHAKI1,* and NILANJAN DEY2
1School of Information Technology and Engineering, Vellore Institute of Technology, Vellore, India2Deptartment of Information Technology, Techno India College of Technology, Kolkata, India
e-mail: [email protected]; [email protected]
MS received 20 August 2019; revised 17 May 2020; accepted 5 June 2020
Abstract. The handwritten digit recognition issue turns into one of the well-known issues in machine learning
and computer vision applications. Numerous machine learning methods have been utilized to resolve the
handwritten digit recognition problem. However, sometimes the digit is not completely present in the image due
to issues related to scanning or environmental conditions (light, illumination, dirt, etc.). Although different
efficient methodologies of handwritten digit recognition are proposed, there is not much work done on frag-
mented handwritten digit recognition. The objective of the proposed research work is to handle this circum-
stance to assemble a consistent digit recognition system that can precisely handle three types (English, Bangla,
and Devanagari) of fragmented handwritten digit images. To solve the confusion, a technique is created to
classify handwritten digits based on geometrical functions that are utilized to calculate handwritten digit features
to assess if a digit belongs to a specific class. A grading scheme and a set of specified fuzzy rules determine the
performance of classification. Experiments have been directed on the three familiar datasets, i.e., MNIST
database (English), NumtaDB (Bangla) and Deva numeral database (Devanagari). Since fragmented digit
delivers a lesser amount of information, the work also attempts to create a tentative size threshold above which
outcomes become erratic and whether such thresholds are standardized or vary depending on other factors. Since
the fragmented handwritten digital image does not have a public database, a method is formed to produce
repeatable fragmented handwritten digital images from the entire image. Experimental outcomes validate that
the proposed approach is effective in recognizing fragmented handwritten digits to an acceptable degree of
fragmentation.
Keywords. Fragmented handwritten digit; geometrical functions; fuzzy rules; grading scheme; fragmentation
threshold.
1. Introduction
Handwritten digit recognition is an interesting issue that has
been deeply thought-out for a long time. The motivation
behind why handwritten digit recognition is yet a signifi-
cant area is because of its immense real-world applications
and financial ramifications. The industry requires a decent
recognition rate along with maximum consistency. A
higher recognition rate on handwritten digits rises the
recognition accuracy for digit data, which generally occurs
in numeral strings. When a numeral string is recognized,
the recognition probability of the string is the multiplication
of the recognition probability of every isolated handwritten
digit (presuming that every handwritten digit is appropri-
ately parted from the string by the segmentation procedure).
Moreover, it is impractical to have a handwritten digit
recognition system with 100% recognition exactness.
Hence, the consistency is significantly more vital than the
recognition accuracy in real-life systems.
Although handwritten digit recognition has abundant
applications, the main problem is that their quality turns out
to be degraded because of bad storage conditions and nat-
ural environmental impacts. A damaged handwritten digit
loses its usefulness to deliver recognizing indications since
its shape characteristic may get changed. A classification
system that trusts such features may create unreliable and
unpredictable outcomes. The objective of the proposed
research work is to handle such a state to develop a reliable
handwritten digit recognition system that can precisely
handle three types (English, Bangla, and Devanagari) of
fragmented handwritten digit images. Since fragmented
handwritten digit image also offers less information, the
work will also try to determine a visibility size threshold
beyond which outcomes turn out to be inconsistent and
whether thresholds of this kind are standardized or vary
according to different reasons.*For correspondence
Sådhanå (2020) 45:197 � Indian Academy of Sciences
https://doi.org/10.1007/s12046-020-01410-5Sadhana(0123456789().,-volV)FT3](0123456789().,-volV)

Large numbers of research works are there in the present
literature that utilizes different properties for handwritten
digit recognition. Most of these works though have used
images of the whole digit, an assumption that may not
always be satisfied. Different data modeling methods like
gradient feature [1], triangle feature [2], structural charac-
teristics, modified edge maps, image projections, multi-
zoning, concavities measurement, HoG features [3],
k-means segmentation [4], primitive descriptors [5],
mathematical morphology [6], bat algorithm [7], moment-
based features [8], genetic algorithm [9], mojette transform
[10], stacked generalized auto-encoders [11], etc. are used
by the researchers for the recognition of whole handwritten
digit image. A variety of comparison classifiers and metrics
have been used like support vector machine [1, 12], radial
basis neural network [13], Q-learning deep belief network
[14], spiking neural network [5, 15], AlexNet [16], Goo-
gleNet [17], Multi-Layer Perceptron [18], spiking deep
convolutional neural network [19], convolutional neural
network [20–23], backpropagation neural network [24],
hopfield neural network [25], Naıve Bayes [26], etc.
It is mandatory to mention here that most of the previous
surveys (except [27]) related to the recognition of whole
handwritten digit images and have not come by significant
amount supplementary work which precisely recognizes
fragmented handwritten digit image.
The objective of this study is not only to enhance the
recognition performance but also to ensure maximum
robustness for fragmented handwritten digital recognition
applications. To recognize fragmented handwritten digits, a
geometric function-based grading scheme and the fuzzy
rule-based system is designed. For every fragmented digit,
a separate grade is assigned based on the geometric func-
tion along with the fuzzy rule is proposed according to the
characteristic of the specified digit. Fuzzy Logic is con-
sidered as one of the efficient techniques where smart
behavior is attained through the creation of some parame-
ters’ fuzzy classes. The benefit here is that human under-
standability of the rule and the criteria. Mostly those rules
are specified by a domain specialist and the fuzzy classes.
Many of the previous researchers have used various
machine learning techniques for digit recognition. In
machine learning, a machine is trained to learn a concept by
giving examples, and by developing pattern models to
discriminate between two (or more) classes of objects.
When there is no one specific line discriminating two
classes, or rather, when there is variation between distin-
guishing features of training and testing data (especially in
case of fragmented digit recognition where the training data
consists of the whole image and the testing data is frag-
mented), the fuzzy logic technique is considered more
suitable. Before extracting features from fragmented digits,
some pre-processing steps are proposed to enhance the
recognition rates of the samples. Three familiar datasets,
i.e., MNIST database (English), NumtaDB (Bangla) and
Deva numeral database (Devanagari) are used with the
purpose of validation of the efficacy of the proposed tech-
nique. As there is no public fragmented handwritten digit
database, a procedure is designed to produce the repro-
ducible fragmented handwritten digit images from the
whole one.
The organization of the manuscript is as follows. In
section 2, the proposed method is introduced along with the
block diagram. Experimentations and results are demon-
strated in section 3 and finally, conclusions are given in
section 4.
2. Proposed method
In this paper, a new method is established for the classifi-
cation of fragmented handwritten digit images based on a
grading scheme and fuzzy rules. Figure 1 shows the
flowchart of the proposed method.
Three (English, Bangla, and Devanagari) datasets are
split into testing and training images. As there is no free
dataset for a fragmented handwritten digit image, the
fragmented handwritten digit images are formed from the
whole handwritten digit image. Here the only testing ima-
ges are fragmented. The proposed system is divided into
two stages: pre-processing and classification. Here the
classification accuracy is calculated in two ways:
Figure 1. Flowchart of the proposed method.
197 Page 2 of 23 Sådhanå (2020) 45:197

considering a grading scheme and grading scheme plus
fuzzy rule-based classification. Before feature extraction,
pre-processing of the handwritten digit images is done to
make it tilt and translation invariant. Then for every frag-
mented testing handwritten digit image, geometrical func-
tions are used to measure characteristics on the handwritten
digits and fuzzy rules are used to determine whether a
fragmented digit belongs to a particular class.
2.1 Creation of fragmented digit image
A new method is established which can be utilized to
generate the reproducible bottom fragmented handwritten
digit image from an entire handwritten digit image inevi-
tably. Specified the image size P� Q. The amount Fð Þ offragmented handwritten digit image that is missing is
dependent on a variable i by the following way:
F ¼ 2
i
� �ð1Þ
Minor fragmented handwritten digits are handled in this
work where a minimum of 70% of the original data is
present; this means that only 30% of the handwritten digit
data is missing. The minor fragmentation can be defined by
using:
i ¼ 20; F ¼ 10%;
i ¼ 18:8; F ¼ 20%;
i ¼ 10; F ¼ 30%
ð2Þ
The scopes for the fragmented handwritten digit image
from the top will be 1 : P½ �; 1 : Q� Q � Fð Þð Þ½ �. The visual
representation of the creation of the fragmented handwrit-
ten digit image is shown in figure 2.
2.2 Pre-processing
Handwritten digit pre-processing may have beneficial
effects on the excellence of feature extraction and the
outcomes of image analysis [28].
The preprocessing task of recognizing handwrit-
ten numbers has been divided into the following steps:
binarization, tilt correction, thinning, and translation cor-
rection. As here the handwritten digit images are frag-
mented, so it is very hard to normalize its orientation and
scaling factor. The raw images have variation in scaling,
orientation, and translation.
2.2 a. BinarizationBinarization is often carried out before the phase of digital
recognition [29]. The input digits should ideally have dual
tones, i.e., white and black (usually 1 and 0). Here 1 rep-
resents foreground (digit) pixels and 0 represents the
background pixels [30].
2.2b. Tilt correctionIrrespective of the size and tilt of a specified digit, a useful
digit recognition system must be able to attain high effi-
ciency. For handwritten digits, tilt, which is characterized
by the slope of the particular writing trend regarding the
vertical line, is one of the main discrepancies in writing
styles. The recognition system must be indifferent to tilt.
The algorithm for tilt correction is described below: The
image is split into three horizontal partitions of the same
height. The centroid of the three partitions is calculated and
linked. The slope of the linking line describes the slope u of
the image. The tilt corrected image is attained by applying
the conversion which is defined by equation (3) to the entire
white pixel coordinate points (x, y) of the original image.
x0 ¼ x� y tan u� dð Þy0 ¼ y
ð3Þ
where x0 and y0 are tilt corrected coordinates and d is the
default tilt.
2.2c ThinningHandwritten digits may have distinct orientations; dig-
its may be curved in shape and may not be parallel to each
other within a page. As a consequence, it is a hard job to
extract and subsequently recognize individual digits in such
papers. Thinning is one of the most important stages in a
single-pixel digit recognition method because of its prop-
erty to hold the original digit shape.
A thinning algorithm is proposed in this manuscript that
can be utilized for thinning handwritten digits. The result-
ing thin digits are the middle lines of the handwritten digits
and therefore this algorithm is invariant to the original
pattern rotations. The thin handwritten digit has a single-
pixel width. The algorithm maintains the topology of the
handwritten digit. This algorithm removes each point on the
outer contour of the handwritten digit to make it single
pixel wide. Three oriented and flipped rules are proposed
which are applied to each pixel of the handwritten digit to
produce the thinned image. The algorithm stops when no
further alterations arise. Figure 3 shows the rules for
thinning.Figure 2. Visual representation of the creation of the fragmented
handwritten digit image.
Sådhanå (2020) 45:197 Page 3 of 23 197

2.2d Translation correctionAfter the binarization, there would be extra 0’s on all four
sides of an image matrix. The background is contracted
until the handwritten digit image fits perfectly into the
bounding rectangle to stabilize the translation factor. To
achieve this, the standard bilinear transformation is used, by
which, every input bitmap P, of size m� n, is transformed
into a normalized bitmap Q, of size p� q. Both P and Q are
quadrilateral regions.
2.3 Creation of geometrical functions
The proposed geometrical functions are utilized to calculate
the features of the fragmented handwritten digits to decide
whether they belong to a specific class. The functions find
specific geometric attributes such as, in specific direction
openings, closed portion, and lines (vertical, horizontal or
slanted), that distinguish a collection of classes or a certain
class. Most of the functions deliver a way to differentiate
digits that the classification system often confuses. Every
fragmented handwritten digit has some specific geometrical
functions. These functions are designed to recognize
handwritten digits when 30% of the digits are missing from
the bottom.
The depiction is made by subsequent characteristics:
Contour Pixels Detection (CPD): This function
explores in a certain direction to find a digit pixel onto
the contour of the digit (figure 4a). To create this function
first the centroid of the digit is identified. Then, from the
centroid, the contour pixels in 360 directions (anti-
Figure 3. Rules for thinning.
Figure 4. Geometric attributes of digits.
197 Page 4 of 23 Sådhanå (2020) 45:197

clockwise direction) of the digits are identified at 1�separation.
Top Close Contour (TCC): This function applies CPD
at the centroid of the 3rd row to 10th row of the digit, in
the direction of 0�–360� with separation of 5� and counts
the total number of pixels in the direction of 0�–360�(figure 4b).
Bottom Central Open Contour (BCOC): This function
hunts for openings in 6 direction (250�, 260�, 270�, 280�,290�, 300�) by applying the CPD at the centroid of the 3rd
row to 10th row of the digit and counts the total number of
pixels in above mentioned 6 directions (figure 4c). The
function is applied at the centroid of the first 10 rows of
the handwritten digit, to investigate if the bottom-central
portion of the digit is closed.
Bottom Open Contour (BOC): This function hunts for
openings in direction of 270� by applying the CPD
(figure 4d). The function is applied at the centroid of the
3rd row to the 8th row of the handwritten digit to confirm
if the middle portion of the digit is open.
Bottom-Left Open Contour-1 (BLOC1): This function
applies CPD at the centroid of the 4th row to the18th row
of the digit in the direction of 210�–260� with separation
of 5� to determine whether the bottom-left part of the digit
is open (figure 4e).
Top Open Contour-1 (TOC1): This function applies
CPD at the centroid of the top 10 rows of the digit, in the
direction of 45�–120� with separation of 2� to determine
whether the top part of the digit is open (figure 4f).
Top Open Contour-2 (TOC2): This function applies
CPD at the centroid of the 15th row to the 20th row of the
digit in the direction of 0�–180� with separation of 2� to
determine whether the top part of the bottom portion of the
digit is open (figure 4g).
Top-Right Open Contour (TROC): This function
applies CPD at the centroid of the 3rd row to the10th
row of the digit, in the direction of 0�–45� with separation
of 5� to determine whether the top-right part of the digit is
open (figure 4h).
Bottom-Right Open Contour (BROC): This function
applies CPD at the centroid of the 15th row to the 20th row
of the digit, in the direction of 340�–360� with separation
of 5� to determine whether the bottom-right part of the
digit is open (figure 4i).
Left Open Contour-1 (LOC1): This function applies
CPD at the centroid of the first 10 rows of the digit in the
direction of 110�–260� with separation of 5� to determine
whether the left part of the digit is open (figure 4j).
Left Open Contour-2 (LOC2): This function applies
CPD at the centroid of the 11th row to the 19th row of the
digit, in the direction of 150�–230� with separation of 10�to determine whether the left part of the lower portion of
the digit is open (figure 4k).
Line Detection (LD): The existence of lines in various
parts of the digit image is identified by a line of 8 pixels
height and 1-pixel width that is convolved with the digit
image through in different directions. Horizontal lines are
identified by the following rules: direction 350�–360� and0�–10� is used to detect right horizontal line; direction
170�–180� and 180�–190� is used to detect left horizontal
line. Similarly, vertical lines are identified by the follow-
ing rules: direction 10�–70� is used to detect right slanted
line; direction 80�–90� and 90�–110� is used to detect top
vertical line; direction 195�–245� is used to detect left
slanted line; direction 245�–270� and 270�–280� is used to
detect bottom vertical line (figure 4l). Here 5� separation
is used between angles.
Right-Top-Center Open Contour (RTCOC): This func-
tion applied CPD at the position min xð Þ þ 5 of the 15th to
20th row of the digit in the direction of 70�–120� with
separation of 1� to determine whether the right top center
portion of the digit is open (figure 4m).
Left-Bottom-Center Open Contour (LBCOC): This
function applied CPD at the position max xð Þ � 5 of the
15th to 20th row of the digit in the direction of 220�–270� with separation of 1� to determine whether the
right bottom center portion of the digit is open
(figure 4n).
Figure 5. Pictorial depiction of equation (4).
Figure 6. The process to include a new digit to a pattern set.
Sådhanå (2020) 45:197 Page 5 of 23 197

Bottom-Left Open Contour-2 (BLOC2): This function
applies CPD at the max xð Þ row of the digit in the direction
of 180�–260� with separation of 2� to determine whether
the bottom-left part from the maximum x-coordinate of the
digit is open (figure 4o).
Right Open Contour (ROC): This function hunts for
openings in direction of 340�–360� and 0�–45� by
applying the CPD (figure 4p). The function is applied at
min xð Þ þ 5 of the 5th row to the 12th row of the
handwritten digit to confirm if the right portion of the
digit is open.
2.4 Classification
The test fragmented digit is classified into two steps: (1)
creation of pattern set and grading the test image and (2)
grading scheme plus fuzzy rules. First to create the pattern
set, the distance between the digit tð Þ of size Q1 � Q2 and a
pattern set Pnð Þ is calculated using equation (4). The pic-
torial depiction of eq. (4) is shown in figure 5.
D Pn; tð Þ ¼ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiXQ1�1
i¼1
XQ2�1
j¼1
Pn i½ � j½ � � t i½ � j½ �ð Þ2vuut ð4Þ
If the digit image is of the same class as the closest
pattern set and the distance is below the threshold f , thedigit tð Þ is added to that pattern set. Then the digit adjusts
the pattern set using equation (5).
Pk i½ � j½ � ¼ Pk i½ � j½ � � NPat kð Þ þ t i½ � j½ �NPat kð Þ þ 1
ð5Þ
Here NPat kð Þ is the number of digit images that earlier
contributed to the pattern set development. Modification of
the pattern set using training images imposes several
epochs for the training procedure. For each epoch, a random
initial point in the training set is used to avoid dependence
on the outcome cause from the starting point in the training
set. A new pattern set is formed when the distance between
a digit image and its nearest existing pattern set is above a
specified threshold f or when the digit’s class does not
match the nearest pattern set class. By following these steps
twenty-seven pattern sets are formed for nine digits of three
(English, Bangla, and Devanagari) languages. Figure 6
illustrates the procedure of including a new digit to a pattern
set. According to the following example, the new digit
belongs to the pattern set 4.
After creating the pattern set, the Euclidean distance
between the fragmented test digit and the pattern set is
measured and represented with a numeric grade G Dð Þð Þusing a linear function as shown in equation (6).
G Dð Þ ¼ 1� 0:9 D� Dkð Þ=Da ð6ÞA test digit k is categorized in the specific language
(English, Bangla or Devanagari) class with the maximum
grade amongst the pattern sets in the acceptance distance
Dað Þ to digit k.If there is a close distinction in grades between distinct
classes, fuzzy rules are implemented to remove or confirm a
class. The subsequent nine rules for each language i.e.,
(ER0–ER9) for English, (BR0–BR9) for Bangla and (DR0–
DR9) for Devanagari permit to assess whether the digit
belongs to a specific language class (0–9). The inputs of the
rules are geometric attributes calculated from the hand-
written fragmented digits. If the digit is forbidden as a class
member characterized by the rule, the rule delivers a -1
output. Rules provide a value that is positive to categorize
the handwritten digit as a language class member signified
by the rule.
ER0 ¼�1 BCOC[ 0:5
top 3 class of0:9 min vertical line lengthð Þ0:2 �
� �min BCOCð Þ
(
ER1 ¼�1 BCOC[ 0:5
top 3 class of0:9 min horizontal line lengthð Þ0:2 �
� �min BCOCð Þ
(
ER2 ¼�1 LOC1[ 0:3
top 3 class of0:9 max horizontal line lengthð Þ0:2 �
� �min LOC1; LOC2ð Þ
(
ER3 ¼�1 LOC1[ 0:3
top 3 class oftop 2 class of
�1 BOC\0
0:9 min BOCð Þ� �
max horizontal line lengthð Þ0:2 horizontal line length\0:3
8<:
9=; min LOC1; LOC2ð Þ
8><>:
197 Page 6 of 23 Sådhanå (2020) 45:197

ER4 ¼�1 TOC1[ 0:3
top 2 class of0:9 max horizontal line length þ vertical line lengthð Þ�1 �
� �min TOC1ð Þ
(
ER5 ¼�1 Horizontal line length\0:4
top 3 class of0:9 min vertical line lengthð Þmin vertical line lengthð Þ�1 �
� �max horizontal line lengthð Þ
8<:
ER6 ¼ �1 TROC þ BROCð Þ[ 0:40:9 min TROC þ BROCð Þ
�
ER7 ¼�1 BLOC1[ 0:5
top 4 class of0:9 max horizontal line lengthð Þ�1 horizontal line length\0:6
� �min BLOC1ð Þ
(
ER8 ¼ max TCCþ TOC2gf
ER9 ¼�1 TCC\0:8
top 2 class of0:9 max vertical line lengthð Þ0:2 �
� �max TCCð Þ
(
BR0 ¼�1 BCOC[ 0:5
top 3 class of0:9 max TOC1ð Þ0:2 �
� �min BCOCð Þ
(
BR1 ¼�1 TOC2\0:5
top 4 class of0:9 min BLOC2ð Þ0:2 �
� �max TOC2ð Þ
(
BR2 ¼�1 LOC1[ 0:3
top 3 class of0:9 max horizontal line lengthð Þ0:2 �
� �min LOC1; LOC2ð Þ
(
BR3 ¼�1 RTCOC[ 0:4
top 2 class of0:9 min LBCOCð Þ0:2 �
� �min RTCOCð Þ
(
BR4 ¼ max TCCþ TOC2gf
BR5 ¼�1 BCOC[ 0:3
top 4 class oftop 2 class of
� TCC[ 0:20:9 min TCCð Þ
� �max TCCð Þ
0:2 TCC\0:7
8<:
9=; min BCOCð Þ
8><>:
BR6 ¼�1 RTCOC[ 0:4
top 2 class of0:9 max LBCOCð Þ0:2 �
� �min RTCOCð Þ
(
BR7 ¼�1 TCC\0:8
top 2 class of0:9 max vertical line lengthð Þ0:2 �
� �max TCCð Þ
(
Sådhanå (2020) 45:197 Page 7 of 23 197

The threshold to develop the pattern set has been adapted
experimentally to a value of 4. Experiments were carried
out utilizing only grades and grade plus fuzzy rules.
The research results are compared with Multilayer Per-
ceptron (MLP) network outcomes as most of the previous
researchers used MLP for the recognition of digit images.
The number of hidden units in the hidden layer network
was changed from 10 to 100� units with a 16:N:10 con-
figuration, where N is the number of hidden units in the
hidden layers. Also, AlexNet, GoogleNet and other rule-
based techniques that are used by the previous researchers
are used to establish the efficiency of the proposed method.
3. Experimentations and results
Experiments were conducted with three different datasets:
70,000 digital English handwritten digit images partitioned
into 10 classes with 7000 images per class obtained from
[31], 20,000 digital Bangla handwritten digit images
BR8 ¼�1 TOC2\0:8
top 2 class of0:9 min TOC1ð Þ0:2 �
� �max TOC2ð Þ
(
BR9 ¼�1 TOC2\0:8
top 4 class oftop 2 class of
�1 BLOC2\0:80:9 max BLOC2ð Þ
� �min BLOC2ð Þ
0:2 BLOC2[ 0:7
8<:
9=; max TOC2ð Þ
8><>:
DR0 ¼ min BCOCgf
DR1 ¼�1 TCC\0:8
top 2 class of0:9 max vertical line lengthð Þ0:2 �
� �max TCCð Þ
(
DR2 ¼�1 LOC1[ 0:3
top 2 class of0:9 min BOCð Þ0:2 �
� �min LOC1; LOC2ð Þ
(
DR3 ¼�1 LOC1[ 0:3
top 3 class of0:9 max LOC1; LOC2ð Þ0:2 �
� �min LOC1; LOC2ð Þ
(
DR4 ¼�1 TOC1[ 0:3
top 2 class of0:9 max BOCð Þ0:2 �
� �min TOC1ð Þ
(
DR5 ¼�1 LOC1[ 0:3
top 2 class of0:9 max BOCð Þ0:2 �
� �min LOC1; LOC2ð Þ
(
DR6 ¼ min ROCgf
DR7 ¼�1 TOC1[ 0:3
top 2 class of0:9 min BOCð Þ0:2 �
� �min TOC1ð Þ
(
DR8 ¼�1 TOC1[ 0:3
top 3 class of0:9 min TCCð Þ0:2 �
� �max Horizontal Line Lengthð Þ
(
DR9 ¼�1 TCC\0:8
top 2 class of0:9 max LOC2ð Þ0:2 �
� �max TCCð Þ
(
197 Page 8 of 23 Sådhanå (2020) 45:197

partitioned into 10 classes with 2000 images per class
obtained from [32] and 2880 digital Devanagari handwrit-
ten digit images partitioned into 10 classes with 288 images
per class obtained from [33]. The 64-bit operating system
(Windows 7) with MATLAB software package R2009a and
4 GB RAM was used to test the proposed solution. Of the
collected digit images, 80% were for training purposes and
the remaining 20% images were for testing in terms of their
scaling and orientation variation. Figure 7 shows the Eng-
lish (figure 7a), Bangla (figure 7b) and Devanagari (fig-
ure 7c) digit sample used in the training dataset, with 5
samples per class.
3.1 Creation of fragmented digits
From the testing samples, fragmented (10%, 20% and 30%
digit pixels cropped from the bottom) digit images were
created as designated before. The pictorial representation of
some of the fragmented (30%) test English handwritten
digit images is shown in figure 8. The same technique is
used to create the Bangla and Devanagari fragmented
digits.
3.2 Pre-processing
Before extracting the features from the digit images, the
training and testing images were pre-processed to correct
the degradation of the image. First, the images are bina-
rized. Then the tilt correction, thinning and translation
correction is done as described before. Figure 9 provides an
example of the outcome of the pre-processed module. The
fragmented images are resized to 20 9 28 pixels and the
whole digits are resized to 28 9 28 pixels.
3.3 Modeling the classification scheme
Classification is done in 4 ways to test the efficiency of the
proposed method: (1) Using only grading scheme, (2)
Using fuzzy ? grading scheme when for the recognition of
whole digits (i.e., both training and the testing dataset
contains whole digit image data), (3) Using
fuzzy ? grading scheme when for the recognition of frag-
mented digits (i.e., training and the testing dataset contains
whole and fragmented digit image data respectively) and
(4) Using fuzzy ? grading scheme when for the recogni-
tion of fragmented digits (i.e., both training and the testing
dataset contains fragmented digit image data).
3.3a Classification using only the grading schemeFirst, the classification is performed only considering the
grading scheme. Figure 10 demonstrates the percentage
Figure 7. Training dataset digit sample.
Figure 8. (a) Whole handwritten digit image, (b) 30% frag-
mented digit image.
Figure 9. (a) Binarized image, (b) Tilt corrected, (c) Thinningand (d) Translation corrected.
Sådhanå (2020) 45:197 Page 9 of 23 197

overall performance classification outcomes acquired by
considering only the grading scheme on the 20% frag-
mented testing digit database for different acceptance dis-
tance [0.0–1.2]. Considering Da ¼ 0:7, the highest outcome
for grading classification achieved which is 80%, 75.8%
and 83.8% for English, Bangla and Devanagari fragmented
testing digit respectively. It can be noted that the case of the
nearest pattern set classification is acquired for case
Da ¼ 0. The classification rate for this case attained is 72%
(English), 68% (Bangla) and 75% (Devanagari).
The confusion matrix for the classification of English,
Bangla, and Devanagari fragmented (20%) digit images
using grading scheme is shown in figures 11a–c,
respectively.
3.3b Classification of whole digits (training and the testingdataset contains whole digit images) using fuzzy ? gradingscheme
After that, the classification outcome is acquired by
considering the grading scheme plus hierarchical fuzzy
rule-based method on English, Bangla and Devanagari
handwritten digits as mentioned when there is no frag-
mentation in both training and testing digits.
The classification procedure of a single English digit
from each class is shown here.
Digit-0:Step 1: The bottom central open contour is applied to each
digit. If the obtained membership value is greater than 0.5,
the digit is forbidden as the class member of digit-0. The
top three classes (maximum grade value) are selected based
on the minimum value of BCOC (figure 12a).
Step 2: Vertical line length is calculated from the three
classes obtained from step 1. The digit having minimum
vertical line length is considered as digit-0 (figure 12b).
Digit-1Step 1: The bottom central open contour is applied to each
digit. If the obtained membership value is greater than 0.5,
Figure 10. Classification of fragmented digits using the grading
scheme.
Figure 11. Confusion matrix representation using the grading
scheme.
197 Page 10 of 23 Sådhanå (2020) 45:197

the digit is forbidden as the class member of digit-1. The
top three classes (maximum grade value) are selected based
on the minimum value of BCOC (figure 13a).
Step 2: Horizontal line length is calculated from the three
classes obtained from step 1. The digit having minimum
horizontal line length is considered as digit-1 (figure 13b).
Digit-2Step 1: Left open contour-1 is applied to each digit. If the
obtained membership value is greater than 0.3, the digit is
forbidden as the class member of digit-2. The top three
classes (maximum grade value) are selected based on the
minimum value of LOC1 and LOC2 (figure 14a).
Step 2: Horizontal line length is calculated from the three
classes obtained from step 1. The digit having maximum
horizontal line length is considered as digit-2 (figure 14b).
Digit-3Step 1: Left open contour-1 is applied to each digit. If the
obtained membership value is greater than 0.3, the digit is
forbidden as the class member of digit-3. The top three
classes (maximum grade value) are selected based on the
minimum value of LOC1 and LOC2 (figure 15a).
Figure 12. Classification procedure of fragmented Digit-0.
Figure 13. Classification procedure of fragmented Digit-1.
Figure 14. Classification procedure of fragmented Digit-2.
Figure 15. Classification procedure of fragmented Digit-3.
Sådhanå (2020) 45:197 Page 11 of 23 197
Step 2: Horizontal line length is calculated from the three
classes obtained from step 1. If the obtained membership
value is less than 0.3, the digit is not considered as the class
member of digit-3. The top two classes are selected based
on the maximum horizontal line length (figure 15b).
Step 3: Bottom open contour is applied to the two classes
obtained from step 2. The digit having minimum BOC is
considered as digit-3 (figure 15c).
Digit-4Step 1: Top open contour-1 is applied to each digit. If the
obtained membership value is greater than 0.3, the digit is
forbidden as the class member of digit-4. The top two
classes (maximum grade value) are selected based on the
minimum value of TOC1 (figure 16a).
Step 2: Horizontal and vertical line length is calculated
from the two classes obtained from step 1. The digit having
maximum (Horizontal ? Vertical) line length is considered
as digit-4 (figure 16b).
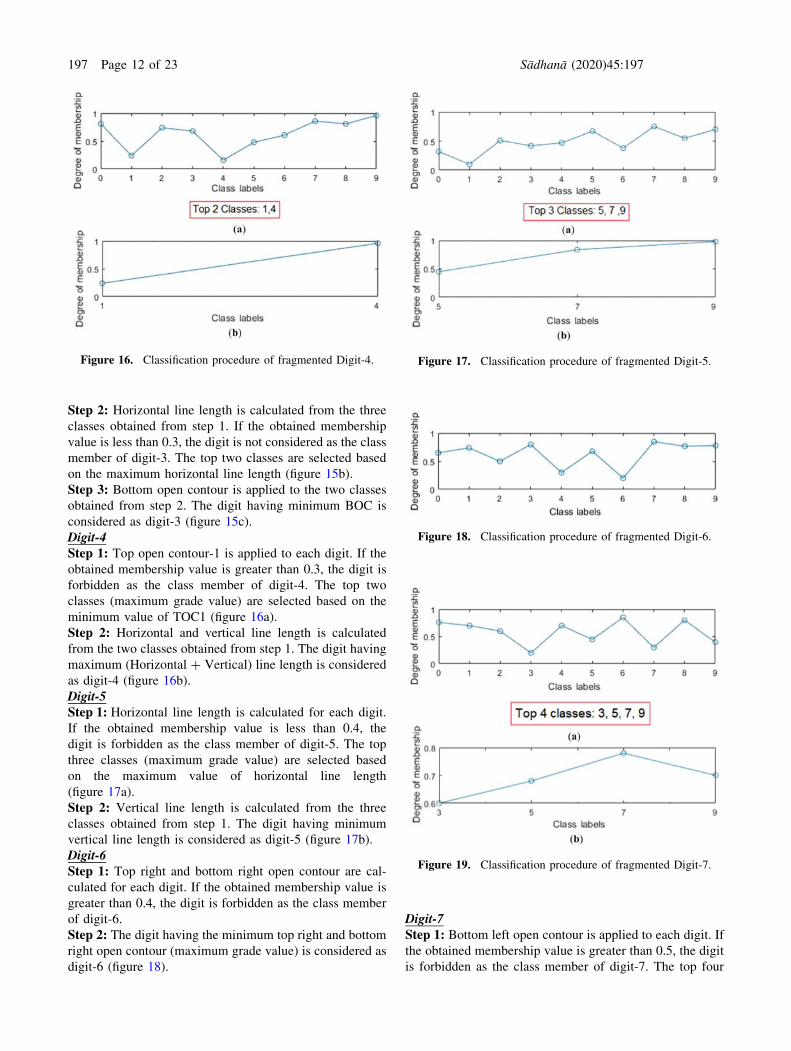
Digit-5Step 1: Horizontal line length is calculated for each digit.
If the obtained membership value is less than 0.4, the
digit is forbidden as the class member of digit-5. The top
three classes (maximum grade value) are selected based
on the maximum value of horizontal line length
(figure 17a).
Step 2: Vertical line length is calculated from the three
classes obtained from step 1. The digit having minimum
vertical line length is considered as digit-5 (figure 17b).
Digit-6Step 1: Top right and bottom right open contour are cal-
culated for each digit. If the obtained membership value is
greater than 0.4, the digit is forbidden as the class member
of digit-6.
Step 2: The digit having the minimum top right and bottom
right open contour (maximum grade value) is considered as
digit-6 (figure 18).
Digit-7Step 1: Bottom left open contour is applied to each digit. If
the obtained membership value is greater than 0.5, the digit
is forbidden as the class member of digit-7. The top four
Figure 16. Classification procedure of fragmented Digit-4. Figure 17. Classification procedure of fragmented Digit-5.
Figure 18. Classification procedure of fragmented Digit-6.
Figure 19. Classification procedure of fragmented Digit-7.
197 Page 12 of 23 Sådhanå (2020) 45:197

classes (maximum grade value) are selected based on the
minimum BLOC1 value (figure 19a).
Step 2: Horizontal line length is calculated from the four
classes obtained from step 1. If the obtained membership
value is less than 0.6, the digit is not considered as the class
member of digit-7. The digit having maximum horizontal
line length is considered as digit-7 (figure 19b).
Digit-8Step 1: Top close contour and top open contour-2 are
applied to each digit. The digit having a maximum number
of pixels in (TCC?TOC2) (maximum grade value) is
considered as digit-8 (figure 20).
Digit-9Step 1: The top close contour feature vector is constructed
from each digit. If the obtained membership value is less
than 0.8, the digit is forbidden as the class member of digit-
9. The top two classes (maximum grade value) are selected
based on the maximum TCC value (figure 21a).
Step 2: Vertical line length is calculated from the four
classes obtained from step 1. The digit having maximum
vertical line length is considered as digit-9 (figure 21b).
The same procedure is applied for Bangla and Devana-
gari language for the classification of whole digits as
mentioned in section 2.4.
The classification results are listed in table 1. The
recognition rates are 94.8%, 94% and 94.8% for English,
Bangla, and Devanagari digits, respectively. The confusion
matrix for the classification of three types of whole digit
images is shown in figures 22, 23 and 24 respectively.
3.3c Classification of fragmented digits (training and thetesting dataset contains the whole and fragmented imagedata respectively) using fuzzy ? grading scheme
After that, the classification outcome is acquired by
considering the grading scheme plus hierarchical fuzzy
rule-based method on the 20% fragmented testing digit
database for the acceptance distance 0.7.
From each of the entire English handwritten digit test
samples, three types of fragmented images were gener-
ated. The percentages of fragmentation were 30%, 20%,
and 10%. Table 2 shows the overall accuracy of the
three types of fragmented images. The class label out-
puts of fragmented (20%) digit-0 images are shown in
figure 25. This plot contains the membership values of
digit 0, 1 and 7. Class labels 1–100 is for digit-0, class
labels 101–200 is for digit-1, class labels 201–300 is for
digit-7.
The class label outputs of fragmented (20%) digit-1
images are shown in figure 26. This plot contains the
membership values of digit 0, 1 and 7. Class labels 1–100 is
for digit-0, class labels 101–200 is for digit-1, class labels
201–300 is for digit-7.
The class label outputs of fragmented (20%) digit-2
images are shown in figure 27. This plot contains the
membership values of digit 1, 2 and 3. Class labels 1–100 is
for digit-1, class labels 101–200 is for digit-2, class labels
201–300 is for digit-3.
The class label outputs of fragmented (20%) digit-3
images are shown in figure 28. This plot contains the
membership values of digit 2 and 3. Class labels 1–100 is
for digit-2, class labels 101–200 is for digit-3.Figure 20. Classification procedure of fragmented Digit-8.
Figure 21. Classification procedure of fragmented Digit-9.
Table 1. The accuracy percentage of three types of whole digit
images using the grading scheme and fuzzy rules.
Class
Language
English Bangla Devanagari
Digit-0 93 95 97
Digit-1 96 92 96
Digit-2 92 94 92
Digit-3 94 93 94
Digit-4 93 96 95
Digit-5 95 91 93
Digit-6 96 94 92
Digit-7 97 97 95
Digit-8 95 96 97
Digit-9 97 92 97
Sådhanå (2020) 45:197 Page 13 of 23 197

The class label outputs of fragmented (20%) digit-4
images are shown in figure 29. This plot contains the
membership values of digit 1 and 4. Class labels 1–100 is
for digit-1, class labels 101–200 is for digit-4.
The class label outputs of fragmented (20%) digit-5
images are shown in figure 30. This plot contains the
membership values of digit 5, 7 and 9. Class labels 1–100 is
for digit-5, class labels 101–200 is for digit-7, class labels
201–300 is for digit-9.
Figure 22. Confusion matrix representation for English whole
digit images recognition using the grading scheme plus fuzzy
rules.
Figure 24. Confusion matrix representation for Devanagari
whole digit images recognition using the grading scheme plus
fuzzy rules.
Table 2. The accuracy percentage of the English fragmented
digit images using the grading scheme and fuzzy rules.
Class
Fragmentation
10% 20% 30%
Digit-0 88 82 78
Digit-1 94 90 85
Digit-2 82 79 70
Digit-3 87 84 72
Digit-4 80 78 70
Digit-5 81 80 63
Digit-6 87 84 76
Digit-7 92 90 85
Digit-8 90 89 80
Digit-9 96 94 86
Figure 25. Classification plot of Digit-0.
Figure 23. Confusion matrix representation for Bangla whole
digit images recognition using the grading scheme plus fuzzy
rules.
197 Page 14 of 23 Sådhanå (2020) 45:197

The class label outputs of fragmented (20%) digit-6
images are shown in figure 31. This plot contains the
membership values of digit 4 and 6 as other classes are
forbidden as the class member of digit-6. Class labels
1–100 is for digit-4, class labels 101–200 is for digit-6.
The class label outputs of fragmented (20%) digit-7
images are shown in figure 32. This plot contains the
membership values of digit 3, 5, 7 and 9. Class labels 1–100
is for digit-3, class labels 101–200 is for digit-5, class labels
201–300 is for digit-7 and class labels 301–400 is for digit-
9.
The class label outputs of fragmented (20%) digit-8
images are shown in figure 33. This plot contains the
membership values of digit 1, 2, 3, 4, 5, 6, 7, 8 and 9. Class
labels 1–100 is for digit-0, class labels 101–200 is for digit-
1, class labels 201–300 is for digit-2, class labels 301–400
is for digit-3, class labels 401–500 is for digit-4, class labels
501–600 is for digit-5, class labels 601–700 is for digit-6,
class labels 701–800 is for digit-7, class labels 801–900 is
for digit-8 and class labels 901–1000 is for digit-9.
Figure 26. Classification plot of Digit-1.
Figure 27. Classification plot of Digit-2.
Figure 28. Classification plot of Digit-3.
Figure 29. Classification plot of Digit-4.
Figure 30. Classification plot of Digit-5.
Figure 31. Classification plot of Digit-6.
Figure 32. Classification plot of Digit-7.
Figure 33. Classification plot of Digit-8.
Sådhanå (2020) 45:197 Page 15 of 23 197

The class label outputs of fragmented (20%) digit-9
images are shown in figure 34. This plot contains the
membership values of digit 8 and 9. Class labels 1–100 is
for digit-8, class labels 101–200 is for digit-9.
Table 2 shows the correct recognition rates for English
fragmented (30%, 20% and 10%) handwritten digits which
are 76.5%, 85% and 87.7%, respectively.
From table 2, one can recognize that the appropriate
recognition rate is high if the fragmentation percentage is
low. Besides, the classification rate of the fragmented
images of 10% is better than the fragmented images of 20%
and 30%. This may be due to a huge amount of information
present in that specific fragmented part that contributes to
better recognition.
The confusion matrix for the classification of English
fragmented (20%) digit images using this method is shown
in figure 35.
The fuzzy rule-based hierarchical approach is adapted for
the classification of fragmented Bangla and Devanagari
handwritten digits as mentioned in section 2.4. The clas-
sification procedure is similar to the English fragmented
digit classification. Tables 3 and 4 show the correct
recognition rates for 10%, 20%, and 30% fragmented
Bangla and Devanagari digits respectively. The recognition
rates are 88.2%, 82.4% and 76.1% for Bangla and 92%,
89% and 85.5% for Devanagari fragmented digits. The
confusion matrix for the classification of 20% fragmented
Bangla and Devanagari digit images using this method is
shown in Figures 36 and 37 respectively.
3.3d Classification of fragmented digits (both training andthe testing dataset contains fragmented image data) usingfuzzy ? grading scheme
The fuzzy rule-based hierarchical approach is adapted for
the classification of English, Bangla and Devanagari
handwritten digits as mentioned when both training and
testing digits are 20% fragmented which is listed in table 5.
The recognition rates are 90.5%, 88.7% and 90.9% for
English, Bangla, and Devanagari digits respectively. The
confusion matrix for the classification of three types of
fragmented digit images is shown in figures 38, 39 and 40.
From the above experimentation, it is clear that if the
setup is uniform, i.e., both training and testing images are
either whole or fragmented, the efficiency of the proposed
approach is delivering a better recognition rate.
Figure 34. Classification plot of Digit-9.
Figure 35. Confusion matrix representation for English frag-
mented (20%) digit images recognition using the grading
scheme plus fuzzy rules.
Table 3. The accuracy percentage of the Bangla fragmented
digit images using the grading scheme and fuzzy rules.
Class
Fragmentation
10% 20% 30%
Digit-0 90 85 79
Digit-1 85 79 70
Digit-2 88 80 64
Digit-3 88 81 78
Digit-4 90 84 81
Digit-5 86 79 72
Digit-6 87 81 74
Digit-7 95 90 86
Digit-8 89 85 83
Digit-9 84 80 74
Table 4. The accuracy percentage of the Devanagari fragmented
digit images using the grading scheme and fuzzy rules.
Class
Fragmentation
10% 20% 30%
Digit-0 96 93 90
Digit-1 93 90 86
Digit-2 88 85 82
Digit-3 87 85 80
Digit-4 94 91 88
Digit-5 91 87 84
Digit-6 90 87 82
Digit-7 94 90 87
Digit-8 95 93 90
Digit-9 92 89 86
197 Page 16 of 23 Sådhanå (2020) 45:197

3.4 Analysis of the proposed method with otherrelated methods mentioned in the literature
The analysis is conducted by considering the whole digit
images in the training and fragmented (20%) digit images
in the testing dataset. The reason behind the consideration
of this type of dataset is: we don’t have any prior
knowledge of the amount of the fragmentation of the test
digit. As the fragmentation percentage is not known to us,
we can’t make the training images fragmented for the
classification of the fragmented test image.
Figure 41 shows the protocol used for the analysis. Here
English (Q), Bangla (Q) and Devanagari (Q) are the frag-
mented query sample taken from English, Bangla and
Devanagari test set, respectively.
Six types of classifiers are used for the analysis purpose
such as Fuzzy system [5], AlexNet [16], GoogleNet [17],
MLP [18], multi column multi scale CNN [34], Multiob-
jective Harmony Search algorithm [35]. After doing the
pre-processing step, the system is first trained by using a
Figure 36. Confusion matrix representation for 20% fragmented
Bangla digit images recognition using the grading scheme plus
fuzzy rules.
Figure 37. Confusion matrix representation for 20% fragmented
Devanagari digit images using the grading scheme plus fuzzy
rules.
Table 5. The accuracy percentage of three types of fragmented
digit images using the grading scheme and fuzzy rules.
Class
Language
English Bangla Devanagari
Digit-0 87 91 96
Digit-1 92 85 92
Digit-2 88 89 88
Digit-3 89 86 87
Digit-4 85 91 92
Digit-5 89 86 89
Digit-6 91 88 85
Digit-7 94 95 91
Digit-8 93 90 96
Digit-9 97 86 93
Figure 38. Confusion matrix representation for English frag-
mented (20%) digit images.
Sådhanå (2020) 45:197 Page 17 of 23 197

particular language training digit samples and respective
training module of the abovesaid classifiers. Then the sys-
tem uses the same classifier to classify the same language
fragmented digit.
The efficiency of the MLP model is tested on the English
fragmented testing database. MLP’s highest overall accu-
racy for English fragmented (20%) digits with the network
configuration 16:70:10 are 70%, for the Bangla dataset with
network configuration 16:87:10 is 65% and for Devanagari
dataset, with network configuration 16:67:10 is 79%. Fig-
ure 42 demonstrates the classification of English frag-
mented (20%) digits using MLP.
Figure 43 illustrates the performance of AlexNet [16]
(figure 43a) and GoogleNet [17] (figure 43b) for English
fragmented (20%) digit classification. The overall accuracy
obtained was 77.1% (English), (64%) Bangla, (78%)
Devanagari and 79% (English), 65% (Bangla), 81%
Figure 39. Confusion matrix representation for Bangla frag-
mented (20%) digit images.
Figure 40. Confusion matrix representation for Devanagari
fragmented (20%) digit images.
Figure 41. Protocol used for analysis; (a) Analysis using Englishdataset, (b) Analysis using Bangla dataset, (c) Analysis using
Devanagari dataset.
Figure 42. Classification results of English fragmented (20%)
digits for various number of hidden units.
197 Page 18 of 23 Sådhanå (2020) 45:197

(Devanagari) using AlexNet and GoogleNet respectively
for 20% fragmented digits.
The reason behind the low percentage of accuracy using
these two methods is probably due to the variation in
training (whole) and testing (fragmented) data because the
significant variation in training and testing data can degrade
the performance of AlexNet and GoogleNet very quickly
and significantly. AlexNet is also often very computation-
ally expensive, because of the large number of parameters
that are normally present in the fully connected layers of
Alexnet. GoogLeNet shows faster speed and smaller model
size compared to AlexNet. GoogLeNet has computational
efficacy, enabling this model to run on devices with limited
computational resources, particularly with low memory.
In [5], researchers have used four primitive descriptions
(closure which is the closed-contour like shape, the smooth
curve which is not closed, protrusion which contains sharp
bending at certain points and straight-line segment) and
rule-based technique to classify whole digits. But this
technique is not appropriate for the fragmented digit
recognition. Table 6 demonstrates the primitive description
obtained by using this method for one English train and test
sample image from each category. For the other two lan-
guages (Bangla and Devanagari) digits, the same procedure
is adopted.
From table 6 it is clear that the primitive features are not
the same (significant variations exist) for the same class
training and fragmented testing images. Also, intraclass
primitive features variations are there which creates diffi-
culty while using these features to train a system. Table 7
shows some of the intraclass primitive features variations
for English sample digits.
Experimentation is conducted using the approach used in
[5] on three (English, Bangla, and Devanagari) frag-
mented testing database to test the efficiency of the method
and the accuracy obtained is 50%, 42%, and 53% respec-
tively for 20% fragmented images. The reason behind the
low recognition rate can be the intraclass feature variation
Figure 43. Confusion matrix representation for English frag-
mented (20%) digit images using (a) AlexNet and (b) GoogleNet.
Table 6. The primitive description obtained for one English
train and test sample image from each class by using the approach
used in [5].
Sådhanå (2020) 45:197 Page 19 of 23 197

as well as the feature variations of the same class training
and testing dataset.
The proposed method is compared with the methodology
adapted by [34, 35]. In [34] the authors have used multi
column multi scale CNN for the recognition of digits and
obtained good recognition rates for whole digit recognition.
The recognition rate obtained by using the method of [34]
for the English, Bangla and Devanagari fragmented digit is
83.6%, 81.4%, and 75.9% respectively. In [35] authors used
multiobjective Harmony Search algorithm for the recogni-
tion of whole digit images. The recognition rate obtained by
using the method of [35] for the English, Bangla and
Devanagari fragmented digit is 73.3%, 72.8%, and 71.5%
respectively. Figure 44 illustrates the performance of multi-
column multi-scale CNN [34] (figure 44a) and
Table 7. Intraclass primitive features variations for English
digits.
Figure 44. Confusion matrix representation for English frag-
mented (20%) digit images using (a) multi-column multi-scale
CNN and (b) multiobjective Harmony Search algorithm.
Figure 45. Some examples of handwritten digit images that
recognized incorrectly.
197 Page 20 of 23 Sådhanå (2020) 45:197

multiobjective Harmony Search algorithm [35] (fig-
ure 4(b) for English fragmented digit classification.
The reason behind the low percentage of accuracy using
these two methods [34, 35] is probably due to the variation
in training (whole) and testing (fragmented) data.
The fuzzy rule errors are generated in some cases due
to the lapse of these features. For example, in the case
when the English digit ‘‘3’’ was incorrectly recognized as
English Digit ‘‘5’’, Bangla digit ‘‘1’’ was incorrectly rec-
ognized as Bangla digit ‘‘9’’ etc, the fuzzy rules were not
able to determine clearly. Some examples of handwritten
digit images that recognized incorrectly are shown in
figure 45.
The most common ambiguous pairs are ‘‘5–3’’ and
‘‘4–9’’ for English digits, ‘‘1–9’’ for Bangla digits that have
similar shapes and structures due to the handwriting habits
of individuals. The deteriorated consistency of digital
handwritten digit images such as damaged digits, missing
strokes, noise from assailants and touching strokes. These
cases may be produced by poor handwriting by individuals
or introduced through the scanning procedure, standard-
ization of size, and inappropriate segmentation. With such
unclear and damaged inputs, it is extremely hard for a
computer to produce a correct prediction.
To link the current work with other previous works, it
should be noted that most of the existing methods have
been created for the recognition of the entire digit image. In
[27], the authors have developed the scheme for the clas-
sification of fragmented digit images. Therefore, the
experimentation was carried out utilizing the current
training images and fragmented digit test images to com-
pare the approach of [27] with the proposed approach.
The following performance specifications are calculated:
(1) Correct rate: the ratio of fragmented digits properly
classified, (2) Error rate: the ratio of fragmented digits
incorrectly classified. Table 8 validates the outcomes of the
proposed method compared with the outcomes of
[5, 6, 17, 18, 27] for the recognition of fragmented hand-
written digits. In the proposed approach, a smaller number
of features are used than those of other researches. The
consistency of the result of the proposed method is more
robust than their results for the recognition of fragmented
handwritten digits. The specific geometrical functions and
fuzzy rules for class help in the final classification of the
fragmented handwritten digits. Because the number of final
feature type is small, the rejected rate of this proposed
approach is low.
Fragmented digit (20%) recognition cost is measured by
taking the average time taken to recognize the digit. The
proposed method took 60 min, 20 min, 27 min and to
recognize 14,000 English, 400 Bangla, and 576 Devanagari
fragmented digits respectively.
Table 8. Comparison of Recognition Outcomes.
Approach used Dataset used
Correct rate (%) Error rate (%)
F: 10% F: 20% F: 30% F: 10% F: 20% F: 30%
Dash et al [5] English 54 50 47 46 50 53
Bangla 46 42 39 54 58 61
Devanagari 57 53 49 43 47 51
Krizhevsky et al [16] English 80 77.1 74.3 20 22.9 25.7
Bangla 69 64 62.7 31 36 37.3
Devanagari 82 78 74.1 18 22 25.9
Zhong et al [17] English 85.1 79 75 14.9 21 25
Bangla 71 65 60.4 29 35 39.6
Devanagari 83.7 81 76.1 16.3 19 23.9
Keshta [18] English 78 70 67 22 30 33
Bangla 71 65 60 29 35 40
Devanagari 83 79 72 17 21 28
Ouchtati et al [27] English 61 57 50 39 43 50
Bangla 58 53 49 42 47 51
Devanagari 66 60 56 34 40 44
Sarkhel et al [34] English 85.4 83.6 80.1 14.6 16.4 19.9
Bangla 83.5 81.4 78.5 16.5 18.6 21.5
Devanagari 77.1 75.9 71.6 22.9 24.1 28.4
Gupta et al [35] English 79.5 73.3 69.1 20.5 26.7 30.9
Bangla 75.4 72.8 68.5 24.6 27.2 31.5
Devanagari 78.5 71.5 67.4 21.5 28.5 32.6
Proposed approach English 87.7 85 76.5 12.3 15 23.5
Bangla 88.2 82.4 76.1 11.8 17.6 23.9
Devanagari 92 89 85.5 8 11 14.5
Sådhanå (2020) 45:197 Page 21 of 23 197

4. Conclusions
A new grading scheme plus a geometric fuzzy model have
been proposed in this paper to address the issue of frag-
mented handwritten digit recognition of three different
languages. This model took the geometrical function as an
automatic extractor of features, enabling the grading
scheme and fuzzy rules to be the predictor of output. The
proposed model’s reliability and efficacy were assessed in
two aspects: accuracy of recognition and overall perfor-
mance of reliability. The MNIST digit dataset (English),
NumtaDB dataset (Bangla) and Deva numeral dataset
(Devanagari) are used to demonstrate the advantage of the
hybrid model is proposed. Compared to other research
works, the proposed approach is producing the best results
for fragmented digit recognition. From the testing out-
comes, it could be confirmed that the recognition result of
10% fragmented digit images is high compared to 20% and
30% category of fragmentations probably due to the more
digit information present in the digit image. Also, it can be
noticed that in this algorithm the main challenging work is
to do the pre-processing of the digit images efficiently. As
the features are based on geometric functions, if the
handwritten digits are not properly pre-processed, the
algorithm can not extract the best geometric features from
the fragmented handwritten digits. Thus, overall recogni-
tion performance can degrade.
Future options for this work may be as follows: (1)
Constructing an effective method that can correctly rec-
ognize fragmented handwritten digital images where only
50% of digital data is viewed; (2) Experiments with other
shape-based techniques; (3) Validation of fragmented digit
images with other classifiers such as Neuro-fuzzy and
Support Vector Machine classifiers and (4) Experimenta-
tion considering fragmentation in eight major directions. To
do this, different geometrical features along with the fuzzy
rules to be developed.
References
[1] Raju G, Moni B S and Nair M S 2014 A novel handwritten
character recognition system using gradient based features
and run length count. Sadhana. 39: 1333–1355[2] Miswan S A, Azmi M S, Arbain N A, Tahir A and Radzid A
R 2018 Rearrangement of coordinate selection for triangle
features improvement in digit recognition. J. Telecommun.Electron. Comput. Eng. (JTEC). 10: 115–119
[3] Nongmeikapam K, Kumar W K, Meetei O N and Tuithung T
2019 Increasing the effectiveness of handwritten Manipuri
Meetei-Mayek character recognition using multiple-HOG-
feature descriptors. Sadhana. 44: 114–118[4] Lee G C, Yeh F H, Chen Y J and Chang T K 2017 Robust
handwriting extraction and lecture video summariza-
tion. Multimed. Tools Appl. 76: 7067–7085
[5] Dash K S, Puhan N B and Panda G 2018 Unconstrained
handwritten digit recognition using perceptual shape prim-
itives. Pattern Anal. Appl. 21: 413–436.[6] Kumar V V, Srikrishna A, Babu B R and Mani M R 2010
Classification and recognition of handwritten digits by using
mathematical morphology. Sadhana. 35: 419–426[7] Boufenar C, Batouche M and Schoenauer M 2018 An
artificial immune system for offline isolated handwritten
arabic character recognition. Evol. Syst. 9: 25–41.[8] Tuba E and Bacanin N 2015 An algorithm for handwritten
digit recognition using projection histograms and SVM
classifier. In 2015 23rd Telecommunications Forum Telfor(TELFOR), pp. 464–467
[9] Das N, Sarkar R, Basu S, Kundu M, Nasipuri M and Basu D
K 2012 A genetic algorithm based region sampling for
selection of local features in handwritten digit recognition
application. Appl. Soft Comput. 12: 1592–1606[10] Singh P K, Das S, Sarkar R, and Nasipuri M 2017
Recognition of handwritten Indic script numerals using
Mojette transform. In: Proceedings of the First InternationalConference on Intelligent Computing and Communication(pp. 459–466)
[11] Sheu J S and Huang Y L 2016 Implementation of an
interactive TV interface via gesture and handwritten numeral
recognition. Multimed. Tools Appl. 75: 9685–9706[12] Mohammadpoor M, Mehdizadeh A and Noghabi H A 2018
A novel method for persian handwritten digit recognition
using support vector machine. Majlesi J. Electr. Eng. 12:63–67
[13] Karayiannis N B and Behnke S 2018 New radial basis neural
networks and their application in a large-scale handwritten
digit recognition problem. In: Recent Advances in ArtificialNeural Networks (pp. 61–116)
[14] Qiao J, Wang G, Li W and Chen M 2018 An adaptive deep
Q-learning strategy for handwritten digit recognition. NeuralNetw. 107: 61–71
[15] Kulkarni S R and Rajendran B 2018 Spiking neural networks
for handwritten digit recognition—supervised learning and
network optimization. Neural Netw. 103: 118–127[16] Krizhevsky A, Sutskever I and Hinton G E 2012 Imagenet
classification with deep convolutional neural networks.
In: Advances in Neural Information Processing Systems(pp. 1097–1105)
[17] Zhong Z, Jin L and Xie Z 2015 High performance offline
handwritten chinese character recognition using googlenet
and directional feature maps. In: 2015 13th InternationalConference on Document Analysis and Recognition (ICDAR)(pp. 846–850)
[18] Keshta I M 2017 Handwritten digit recognition based on
output-independent multi-layer perceptrons. HAND. 8[19] Mozafari M, Ganjtabesh M, Nowzari-Dalini A, Thorpe S J
and Masquelier T 2019 Bio-inspired digit recognition using
reward-modulated spike-timing-dependent plasticity in deep
convolutional networks. Pattern Recognit. 94: 87–95[20] Pratt S, Ochoa A, Yadav M, Sheta A and Eldefrawy M 2019
Handwritten digits recognition using convolution neural
networks. J. Comput. Sci. Coll. 34: 40–46[21] Masood S Z, Shu G, Dehghan A and Ortiz E G 2017 License
plate detection and recognition using deeply learned convo-
lutional neural networks. arXiv preprint arXiv:1703.07330
197 Page 22 of 23 Sådhanå (2020) 45:197

[22] Zhao H H, and Liu H 2019 Multiple classifiers fusion and
CNN feature extraction for handwritten digits recogni-
tion. Granul. Comput. 1–8[23] Sufian A, Ghosh A, Naskar A and Sultana F 2019 Bdnet:
bengali handwritten numeral digit recognition based on
densely connected convolutional neural networks. arXiv
preprint arXiv:1906.03786
[24] Wang Y, Yao H, Yu W, Wang D, Zhou S and Sun X 2019
Gradual recovery based occluded digit images recogni-
tion. Multimed. Tools Appl. 78: 2571–2586[25] Duan S, Dong Z, Hu X, Wang L, and Li H 2016 Small-world
Hopfield neural networks with weight salience priority and
memristor synapses for digit recognition. Neural Comput.Appl. 27: 837–844
[26] Shamim S M, Miah M B A, Sarker A, Rana M and Al Jobair
A 2018 Handwritten digit recognition using machine learn-
ing algorithms. Glob. J. Comput. Sci. Technol.[27] Ouchtati S, Redjimi M and Bedda M 2015 An offline system
for the recognition of the fragmented handwritten numeric
chains. Int. J. Future Comput. Commun. 4: 33–39[28] Chaki J and Dey N 2018 A Beginner’s Guide to Image
Preprocessing Techniques. CRC Press, Boca Raton
[29] Roy P, Dutta S, Dey N, Dey G, Chakraborty S and Ray R
2014 Adaptive thresholding: a comparative study. In: 2014International Conference on Control, Instrumentation, Com-munication and Computational Technologies (ICCICCT)(pp. 1182–1186)
[30] Satapathy S C, Raja N S M, Rajinikanth V, Ashour A S
and Dey N 2018 Multi-level image thresholding using Otsu
and chaotic bat algorithm. Neural Comput. Appl. 29:
1285–1307
[31] MNIST Dataset (http://yann.lecun.com/exdb/mnist/). Last
access date: 08.03.2019
[32] NumtaDB dataset (https://www.kaggle.com/BengaliAI/
numta)
[33] Deva numeral dataset (https://www.kaggle.com/ashokpant/
devanagari-character-dataset)
[34] Sarkhel R, Das N, Das A, Kundu M and Nasipuri M 2017 A
multi-scale deep quad tree based feature extraction method
for the recognition of isolated handwritten characters of
popular indic scripts. Pattern Recognit. 71: 78–93[35] Gupta A, Sarkhel R, Das N, and Kundu M 2019 Multiob-
jective optimization for recognition of isolated handwritten
Indic scripts. Pattern Recognit. Lett. 128: 318–325
Sådhanå (2020) 45:197 Page 23 of 23 197