formalisms for grammatical knowledge representation
TRANSCRIPT

Artificiallntelligence Review 6, 365--381, 1992. 0 1992 KiuwerAcademic Publishers. Printed in the Netherlands.
Formalisms for grammatical knowledge representation
BILL KELLER
School of Cognitive & Computing Sciences, University of Sussex, Falmer, Brighton BN1 9QH, UK. billkacogs.susx.ac.uk
Abstract. Computational linguists require descriptively powerful, computationally effective formalisms for representing grammatical information or knowledge. A wide variety of formalisms have been employed in natural language processing systems over the past several decades, including simple phrase structure grammars, aug- merited transition networks, logic grammars and unification-based grammar for- malisms. Until fairly recently however, comparatively little attention has been given to the issues which underly good grammar formalism design in computational linguistics.
This paper examines a number of fundamental issues in the design of formalisms for representing grammatical knowledge. We begin by examining the role of grammar formalisms in computational linguistics, and the trend towards declarative descriptions of grammar. Grammar formalism design is then considered with respect to choices of linguistic representation and grammar notation. The consequences of some specific design choices for the linguistic and computational utility of grammar formalisms are discussed.
Key Words: natural language, grammar, parsing, knowledge representation, con- stituent structure, feature sti'uctures, unification.
1. LANGUAGES AND GRAMMARS
A fundamental assumption of modem linguistics is that a language may be formally defined as a collection of mathematical objects of some kind: e.g. sequences of symbols, parse trees, or other more general sorts of mathematical structure. This definition of language is deliberately broad, and covers a great deal besides what we might usually consider to be the 'natural languages' (e.g. English, Japanese, or Swahih'). The space of all possible languages is clearly quite vast, but linguists believe that the natural languages correspond to some well-defined subspace within it. In studying the natural languages linguists are engaged in mapping out the nature and special properties of this subspace. That is to say, they seek to discover and explain the structural properties which distinguish natural languages from other, 'non-natural' languages.
There is general agreement amongst linguists that the natural languages are infinite collections of objects. All natural languages appear to involve syntactic operations which give rise to, or license linguistic expressions of unbounded length. Typical examples of such operations in English include co-ordination

366 BILL KELLER
(e.g. Sam and Moria and Peter and Jane a n d . . . ) and recursive embedding (e.g. the dog that chased the cat that bit the rat that stole the grain that . . . ) . Because there are no linguistic grounds for imposing a finite upper bound on the length of expressions which may be formed using these operations, it follows that the collection of all well-formed expressions of English must be at least countably infinite in size. Given that any natural language contains an infinite collection of expressions however, it is clear that no natural language can be described simply by listing each its expressions. Rather, it is necessary to provide a precise, finitdy-specified definition of membership for its dements. Such a definition is known as a grammar.
There is a close connection between the study of language and the study of grammar. A particular grammar characterizes a particular language: it defines the class of linguistic expressions which belong to that language, and assigns to each expression a structural representation. A family of grammars (for example, the context-free grammars or the indexed grammars 1) characterizes a whole family of languages. Thus, one way to characterizing the special properties of the natural languages would be to provide a characterization of what their grammars are like. For linguists who accept this position, investigation of the natural languages becomes a study of the organizing principles and special properties of their grammars.
Computational linguists are also concerned with the properties of languages and their grannnars. There is however, a significant difference in aims between the fields of computational linguistics and general linguistics. The proper object of study in computational linguistics is not natural lanbnja_ge itself, but rather language processing (Thompson 1981; Shieber 1988). To be sure, this does not mean that research in linguistics has no bearing on natural language processing. On the contrary, computational linguists draw freely on the observations and insights of linguists regarding the natural languages and their grammars. Nor, for that matter, does it mean that computational linguistics is a wholly applied discipline, concerned only with the sorts of engineering problems which arise in developing working computer systems for processing natural languages. While the construction of such systems is an important practical objective for the field, there are many key issues in computational linguistics which can be addressed without reference to concrete applications. Examples include the computational properties of particular classes of grammar and their associated parsing algo- rithms, the design of formalisms for representing and manipulating linguistic information, or the role played by world knowledge in semantic interpretation and the resolution of ambiguity. Whether working on concrete applications or abstract theoretical problev~s however, the computational linguist is predomi- nantly concerned with la~ age processing, and this has particular conse- quences for the sorts of 'oxmalisms which computational linguists develop and use in their work.

FORMALISMS FOR GRAMMATICAL KNOWLEDGE REPRESENTATION 367
2. THEORIES, FRAMEWORKS AND FORMALISMS
A grammar formalism is a specialized formal language for writing down grammars of a certain kind. Grammar formalisms are developed and used by people who need to provide precise and explicit descriptions of languages (or at least fragments of languages). Certainly, the majority of workers in computa- tional linguistics require such formalisms. As noted above, a practical goal of the field is the construction of computer systems for processing language, and for this purpose it is necessary to design tools for representing linguistic knowledge which are formal enough to be implemented on computers. On the other hand, most linguists do not write formal grammars and accordingly do not work with grammar formalisms. At first blush, this may appear rather surpris- ing. After all, the stated goal of the dominant paradigm in linguistics is the construction of a general 'theory of grammar': a system of general concepts and principles which explains the properties exhibited by all natural languages. On closer inspection, it turns out that many so-called 'theories of grammar' are not properly speaking theories at all. In scientific disciplines, theories are made mathematically precise, and are set out as statements in some appropriate formalism. This degree of mathematical rigor is essential if the predictions made by a theory are to be thoroughly investigated and tested against the available empirical evidence.
In emphasising the concepts and principles which are supposed to underly all natural languages, linguists are not particuiarly concerned with the detailed description of individual languages. As a consequence, they are also generally unconcerned with issues of formalization and explicitness. What linguists call 'theories of grammar' are typically little more than unformalized collections of assumptions about the way in which language 'works' or is organized, providing only loose frameworks for grammatical description. There are a few notable exceptions. In particular, the frameworks of Generalized Phrase Structure Grammar (GPSG) (Gazdar et al. 1985), Lexical Functional Grammar (LFG) (Kaplan and Bresnan 1982; Kaplan 1989) and Head-Driven Phrase Structure Grammar (HPSG) (Pollard and Sag 1987) are distinguished in having asso- ciated grammar formalisms embodying many of their underlying concepts and principles. Here, the grammar formalism is intended to serve as a formal execution of the framework, from which putative universal principles of gram- mar may be derived as theorems. Most frameworks fall well short of this degree of formal rigour however, and some (for example, Chomsky's (1981) Govern- ment Binding framework) lack any officially endorsed formal execution.
In view of the informal nature of much work in linguistics, it is not surprising to find that computational linguists are concerned with the design of formalisms for representing grammatical knowledge. For the computational linguist, a grammatical framework lacking any kind of formal execution is of little theoreti- cal or practical interest: it cannot be studied in computational terms, and it cannot be implemented on a computer.

368 BILL KELLER
3. PROCEDURAL AND DECLARATIVE FORMALISMS
Much of the terminology relating to the study of grammar has a rather procedural flavour. Sequences of symbols are 're-written', features 'trickle down' and 'percolate up' trees, and whole constituents are 'moved', 'copied' and 'deleted'. Procedural metaphors such as these can be of value in providing informal, text-book explanations of the way in which a formalism 'works', and may even be suggestive of mechanisms underlying natural language under- standing or generation. In spite of this however, there are good reasons for maintaining a clear distinction between descriptions of languages on the one hand, and procedures for parsing or generating language on the other.
The distinction between grammars and processing algorithms has not always been maintained by computational linguists. During the 1970s for example, augmented transition network (ATN) grammars (Woods 1970) were widely used in natural language processing systems. The ATN formalism embodies a model of language recognition or parsing as a process of traversing arcs between states in a network. Each arc is associated with a set of conditions which determine when the arc can be followed, and a set of actions which build up partial, structural descriptions of the input if the arc is followed. As a parse proceeds from state to state these structures are stored in registers, the contents of which can later be examined and modified in arbitrary ways. As a result, the ATN formalism is both computationally powerful and inherently procedural. Indeed, the formalism is really just a procedural programming language for specifying parsers of a certain kind.
Much of the popularity of the ATN formalism stemmed from a belief that its procedural characteristics support efficient language processing. With careful ordering of the conditions and actions associated with arcs, it is possible to exploit the formalism's underlying processing strategy (top-down, depth-first search with backtracking) in order to control the amount of computational effort needed to find a particular parse. Unfortunately, the presence of linguisti- cally unmotivated, 'flow of control' information in a grammar has several undesirable consequences (Kaplan 1987). First, linguistic description and pro- cessing algorithm become hopelessly intertwined with the result that the gram- mar is hard to understand simply as a description of a language. Second, grammar development is hindered by lack of modularity: changes in one part of the grammar may have unforeseen and unwanted side-effects elsewhere. Third, because the formalism is tied to a particular implementation strategy, the possibility of experimenting with alternative and perhaps more efficient imple- mentation strategies is lost.
For reasons such as these, computational linguists have more recently turned their attention towards declarative formalisms for specifying grammars. In contrast to procedural formalisms such as the ATN, declarative grammar formalisms can be understood without reference to underlying models of language processing. Precisely because declarative formalisms are independent of particular processing strategies however, they offer a number of advantages over procedural formalisms:

F O R M A L I S M S F O R G R A M M A T I C A L K N O W L E D G E R E P R E S E N T A T I O N 369
- - p e r s p i c u i t y : a declarative grammar can be read simply as a description of a language;
- - f l e x i b i l i t y : t h e computational linguist is free to experiment with novel pro- cessing strategies, and to choose the most appropriate strategy for a given application;
- - p o r t a b i l i t y : t h e declarative encoding of grammars facilitates exchange of linguistics analyses between different formalisms and applications;
- - b i d i r e c t i o n a l i t y : a declarative grammar formalism is in principle neutral with respect to parsing and generation; for applications which involve both the analysis and generation of natural language, there are clear advantages of representational economy and modularity to be gained in using a single grammar.
4. FORMALISM DESIGN AND EVALUATION
Many of the issues which arise in the specification of grammar formalisms are similar to those in the development of general AI knowledge representation languages. A grammar formalism is, after all, a particular kind of knowlege representation language: one which is presumably well-suited to the description of linguistic objects or knowledge. In order to define such a language in a mathematically respectable way, it is necessary to specify three things: - - l i n g u i s t i c r e p r e s e n t a t i o n : a precise definition of a class of mathematical
structures for representing linguistic objects; - - g r a m m a r n o t a t i o n : a precise formal notation for writing down descriptions
of particular languages; - - i n t e r p r e t a t i o n : a precise account of the way in which well-formed constructs
of the grammar notation (the 'grammar rules') are intended to serve as descriptions of linguistic objects.
The importance of providing a formal interpretation or semantics is to be stressed in view of the fact that grammar formalisms, like programming lan- guages and AI knowledge representation languages, make great use of novel notational devices. Without a precise semantics, the meaning of the grammar notation remains obscure, and the formalism difficult to use coherently. This aside, in specifying the notational and representational apparatus of a grammar formalism the computational linguist has considerable freedom. Different design choices can lead to formalisms with radically different linguistic and computa- tional properties however. In particular, these choices will affect the following parameters: - - m a t h e m a t i c a l e x p r e s s i v i t y : the sorts of languages that a formalism can
actually be used to describe. - - n o t a t i o n a l e x p r e s s i v i t y : t h e extent to which a formalism supports concise
descriptions of languages and can be used to capture useful generalizations about linguistic phenomena.
- - c o m p u t a t i o n a l e f f e c t i v e n e s s : t h e computational properties of the formalism and the practical limitations of any processing algorithms.

370 BILL KELLER
The consequences of some specific design choices are discussed in the sections which follow.
4.1. Choice of linguistic representation
A standard representational assumption is that, at one level of description at least, linguistic expressions may be represented by strings. Strings are just finite sequences of symbols -- representafing say, sequences of words or phonemes -- and capture the linear (i.e. left-to-right or temporal) structure of linguistic expressions. As a choice of representational structure however, strings are just too impoverished to support useful descriptions of linguistic phenomena. Con- sequently, additional and informationally richer kinds of representation are also employed.
In many systems of grammar constituent structure trees (or parse trees) are used to represent the internal organization of linguistic expressions. Constituent structure trees support descriptions of linguistic phenomena which are ex- pressed in terms of three kinds of structural information: -- category label: the type or category of a constituent; - - immediate dominance: the whole-part relation between constituents; and - - linear precedence: the left-to-right or temporal ordering of constituents.
An example of a constituent structure tree is shown in Figure 1. This tree represents a structural analysis of the string Sam sees Moira as a constituent of type sentence (i.e. the top-most, or root node of the tree is labeled S). The sentence consists of a noun phrase (NP) constituent Sam and a verb phrase (VP) constituent sees Moira. The VP, in turn, consists of a verb (V) constituent sees and a NP constituent Moira. The root node of the tree is said to imme- diately dominate the nodes labeled NP and VP. In addition, the left-to-right orientation of the tree indicates that the noun phrase precedes the verb phrase, and so on.
A surprisingly rich and linguistically useful armory of structural concepts and relations can be defined in terms of the basic relations of immediate dominance and linear precedence. Examples from the linguistics literature include struc-
S
NP VP
V NP
I I Sam sees Moira
Fig. 1. A simple constituent structure tree.

FORMALISMS FOR GRAMMATICAL KNOWLEDGE REPRESENTATION 371
tural relations such as 'clause mate' (see Partee et al. 1990) and 'command' (Langaker 1969). Such derived relations prove useful in capturing general conditions on the well-formedness of linguistic expressions. On the other hand, certain kinds of grammatical information resist satisfactory formulation in terms of the configuration of constituent structure trees alone. In particular, it has proved notoriously difficult to provide adequate, general definitions of the grammatical relations (e.g. subject, object, etc.).
Over the past decade, a number of new grammar formalisms have been developed which share a remarkably similar view of the problems of represent- ing grammatical information or knowledge. In these formalisms, partially-speci- fied, record-like objects known as feature structures are used to represent linguistic objects of various kinds (e.g. syntactic categories, semantic structures, phonological representations and so on). Feature structures provide for the representation of linguistic objects in terms of hierarchical sets of feature labels (or attributes) and associated feature values. Each feature label is a simple symbol such as cat, sub] or tense which uniquely names a particular feature. Feature values may be either simple or complex: a simple value is just an atomic symbol such as S, singular or past, while a complex value is an embedded feature structure. Feature structures may be viewed as rooted directed graphs in which edges are labeled by the names of features and nodes correspond to feature values. Some examples are shown in Figure 2.
The feature structure in (a) can be understood as a partial representation of a sentence (i.e. the value of cat is S) with a subject which is singular in number, and a predicate in the third person. The feature structure in Co) can also be regarded as a representation of a sentence. In this case however, category information is provided about the subject (which is a noun phrase) and the predicate (with is a verb phrase). Furthermore, the subject and predicate are constrained to carry identical specifications for the feature agr (for 'agreement'). This is indicated by re-entrancy in the graph: both of the edges labeled by agr point to the same graph node.
From an information-processing perspective, a feature structure represents just what is known about a linguistic object at a particular point in a computa- tion. Because information may grow as a computation proceeds, feature struc- tures are generally viewed as inherently partial representations of linguistic objects. They admit a natural ordering according to information content (called subsumption) and support appropriate notions of compatibility and incom- patibility of information. For example, the information contained in the feature structures shown in (a) and (b) is compatible in the sense that there are no conflicting requirements about features and their values. In fact, it is possible to regard both feature structures as partial representations of the same linguistic object. Accordingly, the information which they contain may be unified (Kay 1979, Shieber 1986) to produce a new and more accurate representation of this object. The unification of (a) and (b) is in fact the feature structure shown in (c). This feature structure contains all of the information represented in (a) and (b) separately (including information about shared feature values) but no more than this.
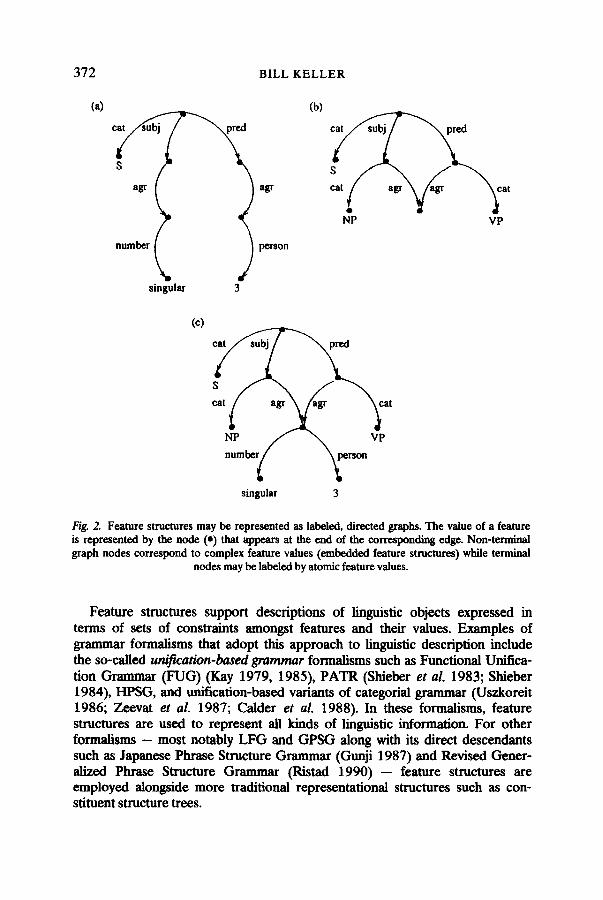
372 BILL KELLER
(a) (b)
number ~ d
singular 3
agr
person
ed
NP VP
(c)
7-- singular 3
Fig. 2. Feature structures may be represented as labeled, directed graphs. The value of a feature is represented by the node (*) that appears at the end of the corresponding edge. Non-terminal graph nodes correspond to complex feature values (embedded feature structures) while terminal
nodes may be labeled by atomic feature values.
Feature structures support descriptions of linguistic objects expressed in terms of sets of constraints amongst features and their values. Examples of grammar formalisms that adopt this approach to linguistic description include the so-called unification-based grammar formalisms such as Functional Unifica- tion Grammar (FUG) (Kay 1979, 1985), PATR (Shieber et al. 1983; Shieber 1984), HPSG, and unification-based variants of categorial grammar (Uszkoreit 1986; Zeevat et al. 1987; Calder et al. 1988). In these formalisms, feature structures are used to represent all kinds of linguistic information. For other formalisms -- most notably LFG and GPSG along with its direct descendants such as Japanese Phrase Structure Grammar (Gunji 1987) and Revised Gener- alized Phrase Structure Grammar (Ristad 1990) -- feature structures are employed alongside more traditional representational structures such as con- stituent structure trees.

FORMALISMS FOR GRAMMATICAL KNOWLEDGE REPRESENTATION 373
4.2. Choice of grammar notation
The way in which linguistic objects are represented fixes the terms in which linguistic phenomena are described, and to this extent the sorts of linguistic generalizations that can be stated. Nevertheless, formal and explicit language descriptions must be expressed in some suitable notation, and the choice of representation places few constraints on the form of that notation. Many differ- ent systems of notation can be used to describe the same sorts of objects, although some choices of notation may be more useful than others. In the design of grammar formalisms, the choice of notation is of central importance because it determines both the linguistic and computational properties of a formalism.
4.2.1. Mathematical expressivity One way of evaluating the linguistic utility of a particular grammar formalism is to examine the class of string sets which it can be used to define. It can be shown, for example, that there are natural languages whose string sets are not regular languages. 2 For this reason, any grammar formalism that can only be used to write down grammars for the regular languages lacks the mathematical expressivity required to characterize the natural languages, and may be judged linguistically inadequate. On the other hand, it is widely agreed that the strings sets of the natural languages can in principle be characterized by the indexed grammars) Thus, the indexed grammars provide a rough upper bound on the mathematical expressivity needed to describe the natural languages.
More generally, mathematical expressivity is concerned with the sorts of structural descriptions or analyses of linguistic expressions which can be cap- tured by a given grammar formalism. Although two different grammar for- malisms may be capable of describing precisely the same class of string sets (weak equivalence) they may yet differ with respect to the kinds of structural analyses they can assign to these strings. A grammar formalism may be deemed inadequate in this stronger sense of mathematical expressivity if it is incapable of providing an appropriate account of the structural properties of the expres- sions in a given language.
The goals of linguistic theory would appear to cut in favour of formalisms which are mathematically restrictive. This is because such restrictions amount to clear and empirically testable claims about the formal properties of the natural languages. Thus, the version of the GPSG formalism presented in Gazdar et al. (1985) embodied the particularly strong empirical claim that the natural lan- guages are in fact context-free languages. A number of convincing counter- examples to this claim have now been advanced (Shieber 1985; Culy 1985; Huybregts 1985), but the sorts of grammatical phenomena which place the natural languages outside the class of context-free languages are surprisingly difficult to find, and seem to restricted in mathematically interesting ways. This suggests that it may be fruitful for linguists to investigate grammar formalisms with only marginally more mathematical expressivity than the context-free grammars. The mildly context sensitive grammar formalisms (Joshi 1985) --

374 BILL KELLER
which include Tree Adjoining Grammar (TAG) (Joshi et al. 1975; Joshi 1985), Head Grammar (Pollard 1984), Linear Indexed Grammar (LIG) (Gazdar 1988), and Combinatory Categorial Grammar (Steedman 1985, 1987) -- appear to have just the fight amount of additional mathematical expressivity. These formalisms have been investigated from the point of view of their strong mathematical expressivity by Weir (1988).
From the perspective of computational linguistics, the issue of mathematical expressivity appears in a rather different light. The computational linguist engaged in building a given application may not be overly concerned with mathematical expressivity in choosing a grammar formalism. The chief concern will be that the formalism is at least capable of describing the application language in a reasonably economical way, and admits some practically efficient procedural interpretation. In general, restrictions on the mathematical expres- sivity of grammar formalisms are of interest to computational linguists only in so far as they support the goal of efficient language processing.
4.2.2. Notat ional expressivity
People who write grammars are not concerned simply with the class of languages that can be described with a given grammar formalism, they are also very interested in h o w these descriptions may be expressed. Ideally, a grammar formalism should provide for descriptions of linguistic phenomena which reflect the user's intuitions about the way language is organized. Other things being equal, a grammar formalism that provides for concise and elegant descriptions of languages will be preferred to one that does not.
Consider for example the simple context-free phrase structure grammar (CF- PSG) shown below:
S - N P V P
V P -~ V N P N P ~ S a m [ Moira
V -- sees
CF-PSG rules are a well-known and perspicuous notation for describing constituent structure trees like that given previously in Figure 1. Each of the grammar rules given above can be interpreted as a statement about the local organization of nodes in a tree. For example, the rule S --, NP VP states that a node with category label S immediately and exhaustively dominates nodes labeled NP and VP, in that order (i.e. a sentence consists of a noun phrase followed by a verb phrase). The CF-PSG formalism is perhaps attractive in virtue of its formal simplicity, but for the purpose of describing even relatively small fragments of the natural languages it represents a rather poor choice of notation. In particular, the simple rule notation does not support general state- ments about such grammatical phenomena as agreement (e.g. between subject and verb) subcategorization (e.g. for verbs), or constituent order. A rather better choice of rule notation is afforded by the Definite Clause Grammar (DCG) formalism (Pereira and Warren 1980) as illustrated by the following grammar fragment.

FORMALISMS FOR GRAMMATICAL KNOWLEDGE REPRESENTATION 375
s -" np(Number), vp(Number) vp(Number) --. v(intrans, Number) vp(Number) -* v(trans, Number), np(Number) np(singular) --[saml np(plural) - - [dogsl v(intrans, singular) ~ [runs] v(intrans, plural) -- [run] v(trans, singular) -- [likes] • • .
The DCG formalism is a rather natural generalization of CF-PSGs in which category labels are allowed to take arguments. The arguments can be used to encode featural information -- e.g. to distinguish between intransitive and transitive verbs, singular and plural noun phrases etc. -- and permit the user to make explicit, general statements about the weU-formedness of linguistic expres- sions. For example, the DCG rules presented above capture a regularity about the well-formedness of simple declarative sentences in English. This is, namely, that the noun phrase and the verb phrase must bear the same specification for Number O.e. either singular or plural). Such regularities cannot be captured using simple context-free phrase structure rules alone. 4
As it happens, DCGs are also mathematically more expressive than simple CF-PSGs. It is important to realize however, that notational and mathematical expressivity are quite separate notions. To see this, consider the following gram- mar rules written in the so-called immediate dominance~linear precedence OD/ LP) rule format (Pullum 1982; Gazdar et al. 1985).
S --, NP, VP NP < VP VP --, V, NP V < NP VP --, V, NP, VP
In an ID/LP grammar, information about immediate dominance and linear precedence is factored into separate components of the grammar. Thus, the ID rule S ~ NP, VP states that a sentence consists of a noun phrase and a verb phrase, but says nothing at all about the linear order of these constituents. Instead, this information is specified by the LP rules. For example, the LP rule NP < VP requires that whenever a noun phrase and a verb phrase occur together as immediate constituents of the same phrase, then the noun phrase precedes the verb phrase. By factoring information about immediate dominance and linear precedence in this way it is possible to make explicit, and general statements about the order of constituents in a particular language. Again, such statements cannot be captured using simple context-free phrase structure rules. In contrast to DCGs however, ID/LP grammars remain a particularly restrictive class: with respect to mathematical expressivity they are weakly equivalent to the CF-PSGs.
Some examples of the diverse range of notational devices to be found in the unification-based grammar formalisms are illustrated in Figure 3. In spite of

376 BILL KELLER
PATR:
Functional Uni
S ~ NPVP (s tense) - ( v P tense) (NP number) - (VP number)
~cation Grammar: CSET - - (SUBJ PRED) PA'ITERN - (SUBJ PRED) CAT - S TENSE -- (PRED TENSE) SUBJ - [CAT - NP]
. [ CAT- VP ] PRED / NUMBER Z <SUBJ NUMBER) I
[PERSON (SUBJPERSON) I
Lexical Functional Grammar: S - * NP VP
(t S tmJ) - t =
Fig. 3. Some examples of rule notation in the unification-based grammar formalisms.
their notational diversity, the unification-based grammars share a number of important characteristics: - - context-free backbone: the use of an augmented, but basically context-free
phrase structure rule format; - - feature structures: the use of feature structures to represent linguistic infor-
marion of various kinds; - - constraint languages: the use of constraints on features and values to
describe the well-formedness of linguistic objects; - - unification: the use of unification as the primary means of combining lin-
guistic information and solving well-formedness constraints. The PATR formalism is perhaps the simplest of the unification-based gram-
mar formalisms. Grammars written in PATR comprise sets of grammar rules like that shown in Figure 3. The rule consists of a context-free phrase structure rule annotated by a set of unifications (called path equations) between features and values. The context-free part of the rule describes how strings can be combined by concatenation to form larger phrases, while the path equations describe how the feature structures associated with these strings are related. The rule shown in the figure encodes subject-verb agreement by requiting that the feature structures associated with the NP and VP carry identical specifications for number, and also for person. In addition, the feature structures associated with S and VP are required to share the same value for tense.
In a functional unification grammar, linguistic information of all kinds is described in terms of feature matrices called functional descriptions (FDs). FDs provide a relatively transparent notation for describing feature structure like those given previously in Figure 2. The FD shown in Figure 3 describes essen- tially the same information as the PATR rule. It can be understood as a (partial) description of a sentence having a noun phrase subject and a verb phrase

F O R M A L I S M S F O R G R A M M A T I C A L K N O W L E D G E R E P R E S E N T A T I O N 377
predicate. Two special attributes -- CSET and PATTERN respectively -- are used to distinguish constituents such as SUBJ and PRED from other attributes of the sentence such as TENSE, and to provide information about linear order (in this case, the SUBJ precedes the PRED). Path equations are used to enforce agreement between constituents. For example, the two equations NUMBER -- (SUBJ NUMBER) and PERSON .~ (SUBJ PERSON), which occur under the attribute PRED, ensure that the subject and predicate must agree with respect to both number and person. More generally, FDs may be disjunctive specifica- tions of feature structures, permitting considerable conciseness of description. Indeed, a functional unification grammar is really nothing more than one large disjunctive FD.
Our final example is a grammar rule written in the rule notation of LFG. The LFG formalism provides for the simultaneous description of two distinct levels of linguistic representation: - - c-structure: a standard constituent structure tree; - - f-structure: a feature structure representing information about grammatical
relations (i.e. subject, object, etc.) as well as other features such as number and tense.
The c-structure is described by standard CF-PSG rules. Rule annotations called functional schemata define a mapping from c-structure nodes to elements of the f-structure. In the functional schemata, up and down arrows ("1' and "~") are used to pick out nodes of the c-structure. For example, the schema 0SUBJ) ~- l which annotates the NP in the rule shown in Figure 3 requires that the SUBJ value of the f-structure associated with the S (1) node is just the f-structure associated with the NP (~) node. Likewise, the equation t -- ~ states that the f-structures associated with the S (1) and VP (l) notes are to be iden- tified.
4.2.3. Computational effectiveness Computational linguists require grammar formalisms which admit practically efficient procedural interpretations. There is a temptation to suppose that grammar formalisms which are restricted in terms of their mathematical expres- sivity may provide a key to efficient language processing. It is well known, for example, that the recognition problem for context-free languages (that is, the problem whether an arbitrary string belongs to a given context-free language) is decidable in polynomial time. Context-free recognition algorithms such as the CYK algorithm (Kasami 1965; Younger 1967) and Earley's algorithm (Earley 1970) can solve this problem in time proportional to n 3 (where n is the number of symbols in the input string). Polynomial time recognition algorithms are also available for the mildly context-sensitive grammar formalisms mentioned previ- ously (Vijay-Shanker and Weir 1989, 1990). In contrast, exponential time is required to solve the string recognition problem for the indexed languages, and for even wider classes of languages the problem may be undecidable.
Such results must be used with some care. In particular, the relevance of notational expressivity in determining the computational properties of particular grammar formalisms cannot be ignored. As Barton et al. (1987) point out,

378 B I L L K E L L E R
mathematically restrictive formalisms may still employ notational devices that can be used to encode computationally hard problems. For example, the GPSG formalism is a particularly elegant notation which allows for very concise encodings of context-free grammars. In fact, a generalized phrase structure grammar may represent an exponential reduction in grammar size compared to an equivalent encoding expressed in terms of simple CF-PSG rules. Linguisti- cally, this is what makes the GPSG formalism attractive. Computationally however, such conciseness is the source of considerable complexity in direct processing of GPSG grammars.
Inspection of the grammar formalisms actually designed and used by com- putational linguists shows that they tend to be very expressive mathematically. Indeed, in computational terms they are often as powerful as general-purpose programming languages. On the other hand, they also tend to be very conserva- tive notationally. In the final analysis, it seems that the goal of computational effectiveness takes precedence over notational niceties. A great deal of research in computational linguistics is currently directed towards finding ways of enhancing notational expressivity without sacrificing computational effective- ness.
5. SUMMARY
Computational linguists require formalisms for representing grammatical knowl- edge which are highly expressive, flexible and computationally effective. To this end, current research in grammar formalism design is focussed on declarative formalisms, and in particular constraint- and unitication-based grammars.
Grammar formalism design involves appropriate choices of linguistic repre- sentation and notation. These choices are important because they determine both the sorts of linguistic descriptions which a grammar formalism can be used to express, and the computational properties of the formalism. Choice of lin- guistic representation fixes the basic terms in which descriptions may be couched, and the kinds of generalizations which can in principle be stated. Choice of grammar notation determines the linguistic and computational utility of a formalism. In general, grammar formalism design in computational linguis- tics must steer a course between the competing requirements of notational power and computational effectiveness. Investigation of existing grammar for- malisms may suggest ways in which these requirements can be met.
NOTES
i An introduction to the context-free grammars can be found in Hopcroft and Ullman (1979). The indexed grammars were first described by Aho (1968), although Hopcroft and UUman provide a less technical presentation.

FORMALISMS FOR GRAMMATICAL KNOWLEDGE REPRESENTATION 379
2 The regular languages are a relatively simple class of languages that have been studied intensively by both linguists and computer scientists. Regular languages are characterized by simple computing devices known as finite-state automata (see Hopcroft and Ullman 1979). 3 But see Miller (1991) for a dissenting voice. 4 It is of course possible to construct a CF-PSG which describes the same sentences as the DCG fragment. However, such a grammar would require two separate and unrelated sentence rules: one rule for singular sentences, and one rule for plural sentences. Multiple rules would likewise be required for singular and plural verb phrases.
REFERENCES
Aho, A. V. (1968) 'Indexed Grammars -- An Extension of Context-free Grammars', Journal of the ACM 15, 647--671.
Barton, G. E., Berwick, R. C. and Ristad, E. S. (1987) Computational Complexity and Natural Languages, MIT Press: Cambridge, Mass.
Calder, J., Klein E. and Zeevat, H. (1988) 'Unification Categorial Grammar: A Concise, Ex- tendable Grammar for Natural Language Processing', in Proceedings of COLING 88, 83-- 86.
Chomsky, N. (1981 ) Lectures on Government and Binding, Foils, Dordrecht. Culy, C. (1985) 'The Complexity of the Vocabulary of Bambara', Linguistics and Philosophy 8,
345--351. Earle),, J. (1970) 'An Efficient Context-free Parsing Algorithm', Communications of the ACM 14,
453--460. Gazdar, G. (1988) 'Applicability of Indexed Grammars to Natural Languages', in U. Reyle and C.
Rohrer (eds.), Natural Language Parsing and Linguistic Theories, D. Reidel, Dordrecht, pp. 69--94.
Gazdar, G., Klein, E, Pullum, G. K. and Sag, I. A. (1985) Generalized Phrase Structure Gram- mar, Basil Blackwell, Oxford.
Gunji, T. (1987) Japanese Phrase Structure Grammar, Dordrecht, Reidel. Hoperoft, J. and Ullman, J. (1979) Introduction to Automata Theory, Languages, and Computa-
tion, Addison-Wesley, Reading, MA. Huybregts, R. (1985) 'The Weak Inadequacy of Context-free Phrase Structure Grammar', in G.
de Haan, M. Trommelen and W. Zonnenveld (eds.), Van Periferie naar Kern, Foris, Dor- drecht, pp. 81--99.
Joshi, A. K. (1985) 'Tree Adjoining Grammars: How Much Context-sensitivity Is Required to Provide Reasonable Structural Descriptions?', in D. Dowty, L. Karttunen and A. Zwicky (eds.), Natural Language Processing -- Theoretical, Computational and Psychological Perspec- tive, Cambridge University Press, New York, pp. 206--250.
Joshi, A. K., Levy, L. and Takahashi, M. (1975) 'Tree Adjunct Grammars', Journal of the Computer and System Sciences 10( 1 ), 136-- 163.
Kaplan, R. M. (1987) 'Three Seductions of Computational Psycholinguistics', in P. Whitelock et al. (eds.), Linguislic Theory and Computer Applications, Academic Press, London, pp. 149-- 188.
Kaplan, R. M. (1989) 'The Formal Architecture of LexicaI-Functional Grammar', Information Science and Engineering 5, 305--322.
Kaplan, R. M. and Bresnan, J. (1982) 'Lexical-Functional Grammar: A Formal System for Grammatical Representation', in J. Bresnan (ed.), The Mental Representation of Grammatical Relations, MIT Press, Cambridge, Mass., pp. 173--281.
Kasami, T. (1965) 'An Efficient Recognition and Syntax Algorithm for Context-free Languages', Scientific Report AFCRL-65-758, Air Force Cambridge Research Lab., Bedford: Mass.
Kay, M. (1979) 'Functional Grammar', in Proceedings of the Fifth Annual Meeting of the Berkeley Linguistics Society, pp. 142--158.

380 BILL KELLER
Kay, M. (1985) 'Parsing in Functional Unification Grammar', in D. Dowty, L. Karttunen and A. Zwicky (eds.), Natural Language Parsing, Cambridge University Press, Cambridge, pp. 251-- 278.
Langaker, R. W. (1969) 'On Pronominalization and the Chain of Command', in D. Reidel and S. Schane (eds.), Modern Studies in English, Prentice Hall, Englewood Cliffs, New Jersey, pp. 160--186.
Miller, P. H. (1991) 'Scandinavian Extraction Phenomena Revisited: Weak and Strong Generative Capacity', Linguistics and Philosophy 14, 101--113.
Partee, B. H., ter Meulen, A. and Wall, R. E. (1990) 'Mathematical Methods in Linguistics', Studies in Linguistics and Philosophy 30, Kluwer Academic Pubfishers, Dordrechi.
Pereira, F. C. N. and Warren, D. (1980) 'Definite Clause Grammars for Language Analysis - - A Survey of the Formalism and a Comparison with Augmented Transition Networks', Artificial Intelligence 13, 231--278. Reprinted in B. J. Grosz, K. Sparck Jones and B. L. Webber (eds.), (1986) Readings in Natural Language Processing, Morgan Kaufm , Los Altos, pp. 101--124.
Pollard, C. (1984) 'Generalized Phrase Structure Grammars, Head Grammars, and Natural Language', Ph.D. Thesis, Stanford University.
Pollard, C. and Sag, L A. (1987) Information-Based Syntax and Semantics: Volume 1 -- Funda- mentals. CSLI Lecture Notes No. 13., Chicago University Press, Chicago.
Pullum, G. K. (1982) 'Free Word Order and Phrase Structure Rules', in J. Pustejovsky and P. Sells (eds.), Proceedings of the 12th Annual Meeting of the North Eastern Linguistic Society, Graduate Linguistics Student Association, University of Massachusetts, Amherst, pp. 209-- 220.
Ristad, E. S. (1990) 'Computational Structure of GPSG Models', Linguistics and Philosophy 13, 521--587.
Shieber, S. M. (1984) 'The Design of a Computer Language for Linguistic Information', in Proceedings of COLING 8 4 , 363--366.
Shieber, S. M. (1985) 'Evidence Against the Context-freeness of Natural Language', Linguistics and Philosophy 8, 333--343.
Shieber, S. M. (1986) An Introduction to Unification-Based Approaches to Grammar, CSLI Lecture Notes No. 4., Chicago University Press, Chicago.
Shieher, S. M. (1988) 'Separating Linguistic Analyses from Linguistic Theories', in U. Reyle and C. Rohrer (eds.), Natural Language Parsing and Linguistic Theories, D. Reidel, Dordrecht, pp. 33--68.
Shieber, S. M., Uszkoreit, H., Robinson, J. and Tyson, M. (1983) 'The Formalism and Imple- mentation of PATR II', in B. Grosz and M. Stickel (eds.), Research on Interactive Acquisition and Use ofKnotcqedge, SRI International, Menlo Park, CA.
Steedman, M. J. (1985) 'Dependency and Coordination in the Grammar of Dutch and English', Language 61,523--568.
Steedman, M. J. (1987) 'Combinatory Grammars and Parasitic Gaps', in N. J. Haddock, E. Klein, and G. Morrill (eds.), Categorial Grammar, Unification Grammar and Parsing, Edinburgh Working Papers in Cognitive Science, University of Edinburgh, Vol. 1., pp. 30--70.
Thompson, H. S. (1981) 'Natural Language Processing: A Critical Analysis of the Structure of the Field, with some Implications for Parsing', in K. Sparck-Jones and Y. A. Wilks (eds.), Automatic Natural Language Parsing, Ellis Horwood, Wiley, Chichester, New York, pp. 23-- 31.
Uszkoreit, H. (1986) 'Categorial Unification Grammar', in Proceedings of COL1NG 86, 187-- 194.
Vijay-Shanker, K. and Weir, D. J. (1989) 'The Recognition of Combinatory Categorial Grammars, Linear Indexed Grammars and Tree Adjoining Grammars', in International Workshop on Parsing Technologies, Pittsburgh, PA.
Vijay-Shanker, K. and Weir, D. J. (1990) 'Polynomial Parsing of Combinatory Categorial Grammars', in 28th meeting Assoc. Comput. Ling., Pittsburgh, PA.
Weir, D. J. (1988) 'Characterizing Mildly Context-Sensitive Grammar Formalisms', Ph.D. Thesis, University of Pennsylvania: Philadephia PA.

FORMALISMS FOR GRAMMATICAL KNOWLEDGE REPRESENTATION 381
Woods, W. A. (1970) 'Transition Network Grammars for Natural Language Analysis', Commu- nications of the ACM 13, 591--606. Reprinted in B. J. Grosz, K. Sparck-Jones and B. L. Webber (eds.), Readings in Natural Language Processing, Morgan Kaufmann, Los Altos., pp. 71--88.
Younger, D. H. (1967) 'Recognition and Parsing of Context4ree Languages in Time n 3', Informa- don and Control 10, 189--208.
Zeevat, H., Klein, E., and Calder, J. (1987) 'Unification Catcgorial Grammar', in N. Haddock, E. Klein and G. Morrill (eds.), Categorial Grammar, Uno$cation Grammar and Parsing, Edin- burgh Working Papers in Cognitive Science, University of Edinburgh, VoL 1., pp. 195--233.