for dummies - molmed slides... · 1989 introduction of the ... francis collins and lap-chee tsui...
TRANSCRIPT

GENETICS FOR
DUMMIES

COURSE
FOR
PEOPLE
who want to know more about genetics
INTRODUCTION to BASIC GENETICS
ANNEMIEKE VERKERK

First Day, Wednesday 1 November, room OWR-72
Moderators: Annemieke Verkerk & Robert Kraaij
Time Speaker Subject
09.15-09.30 Registration and coffee
09.30-10.30 Annemieke Verkerk Basic genetics: history & concepts
10.30-10.45 Coffee break
10.45-11.45 Robert Kraaij Molecular genetics (1)
11.45-12.00 Coffee break
12.00-13.00 Robert Kraaij Molecular genetics (2)
13.00-13.45 Lunch
13.45-14.45 André Uitterlinden Introduction to complex genetics (1)
14.45-15.00 Coffee break
15.00-16.00 André Uitterlinden Introduction to complex genetics (2)

http://r2blog.com/r2s-picture-phun/

SOME
HISTORY
Photo Credit: The Warder Collection, NY

CHARLES DARWIN (1809-1882) UK
1859 : launched evolution theory _life evolves from one species to another _evolution is driven by natural selection _and characteristics can somehow be past on to next generations and change

1860
CHARACTERISTICS ARE TRANSMITTED
Mendel (Austria) 1822 - 1884
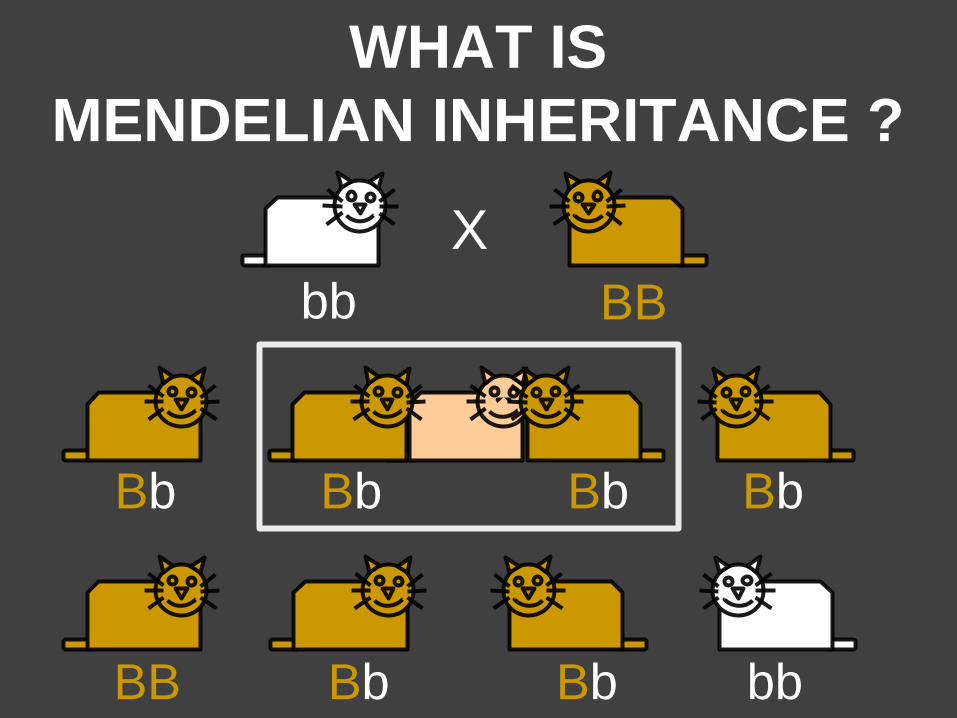
WHAT IS
MENDELIAN INHERITANCE ?
BB
X
bb
X Bb Bb Bb Bb
BB bb Bb Bb

1869 Friedrich Miescher (Switserland) 1878 Albrecht Kossel (Germany) 1919 Phoebus Levene (Litouwen, USA) 1928 Frederick Griffith (UK) 1927 Nikolai Koltsow (Russia) 1937 William Astbury (UK) 1943 Oswald Avery (Canada, USA) Colin MacLeod (Canada) Maclyn McCarty (USA) 1951 Linus Pauling (USA) 1952 Alfred Hershey, Martha Chase (USA) 1952 Rosalind Franklin, Maurice Wilkins (UK) 1953 Francis Crick, James Watson (USA)
SEARCH FOR THE “inheritance molecule”

X-RAY
CRYSTALLOGRAPHY
1953
London’s King’s College: “DNA is a molecule in which two “strands” form a tightly linked pair”.
Rosalind Franklin Maurice Wilkins

Watson and Crick proposed: that the structure of DNA was a winding helix in which pairs of bases Adenine -- Thymine Guanine --- Cytosine held the two strands together.
James Watson (age 25; still alive!) Francis Crick (age 36)
MODEL OF THE DNA
DOUBLE HELIX

Publication of Watson and Crick in Nature in April 1953

In 1962 Francis Crick, James Watson and Maurice Wilkins were awarded the Nobel Prize in Physiology or Medicine, for their discovery of the structure of DNA Rosalind Franklin, had passed away before then (1958).
http://www.flickr.com/photos/dullhunk/3965917511/sizes/m/in/photostream/

SOME OTHER MILESTONES 1970 Discovery that DNA can be cleaved by Restriction Enzymes and isolation of the first restriction enzyme HindII Hamilton O. Smith (Nobel Prize Physiology/Medicine 1978) 1977 Development of the DNA Sanger sequencing method Fred Sanger (Nobel Prize Chemistry 1958) 1985 DNA can be replicated in vitro by Polymerase Chain Reaction – PCR Kary Mullis (Nobel Prize Chemistry 1993) 1989 Introduction of the term fingerprinting and use of DNA polymorphisms in paternity testing and murder cases…, using PCR Alec Jeffreys (Knighted by Queen Elizabeth in 1994) 1988-1989 Identification of the gene for Cystic Fribrosis on chromosome 7, the first disease gene identified by positional cloning Francis Collins and Lap-Chee Tsui 1990 Start Human Genome Project – sequence total human DNA 1998 first large scale detection of Single Nucleotide Polymorphisms (SNPs) using PCR and Sanger sequencing

SOME OTHER MILESTONES 1999 start of The SNP consortium: aim: to discover 300.000 SNPs in the human genome in two years result: described 1.4 million SNPs 2001-2003 Human Genome Project : from working draft to “finished” Sequence MAP 2002 start International HapMapProject: aim: investigate SNPs in populations 2005 Start publications on Population studies with Genome Wide Association Studies (GWAS) 2007 Start development techniques for Next Generation Sequencing 2010 First paper on gene finding with Next Generation Sequencing 2012 ENCODE project consortium: our junk DNA isn’t junk: many regulatory elements present 2011-2017 Development op Non-invasive prenatal testing = NIPT test 2014-2017 Clinical exome sequencing

HUMAN
GENETICS
BASICS

body
some NUMBERS Cells in your body: Cell nucleus: contains DNA consisting of chromosome pairs Length of DNA in one nucleus: m Genome: base pairs
codes for genes
http://www.turbosquid.com/3d-models/3d-human-body-cell-model/125447
100.000.000.000.000 cells = 1014
23
22.000
3.000.000.000 = 3 x 109
2

THE GENOME
= the entire genetic information of an organism stored in all chromosomes together, all genes (coding) + non-coding sequences , all basepairs
chromosomes provided by Diane van Opstal and Laura van Zutven Clinical Genetics EMC

BUILD UP of a CHROMOSOME
The complex of DNA and attached proteins in the cell nucleus = Chromatin = very tightly packed
2 sorts of chromatin (after G-banding coloring): Dark bands : Heterochromatin: very compact and not very active Light bands :Euchromatin: less compact and contains most genes and is active
1. 2. 3. 4. 5.
DNA consist of 4 bases: A : adenine T : thymine G : guanine C : cytosine
bases form pairs (G-C and A-T) on a backbone of _dexoyribose sugar _phosphate groups

KARYOGRAM
All chromosomes in somatic cells are in pairs = 2n = diploid

TYPES OF
CHROMOSOMES
telomere
telomere
centromere
Acro-centric
13 14 15 21 22
Telo-centric not in humans
mouse
Meta-centric arms equal length
1 2 3 6
Sub-metacentric arms unequal
length 4 5 8 9 10 11
short arm -p
long arm -q
12 16 17 18 X Y
p-arm
q-arm
7 19 20
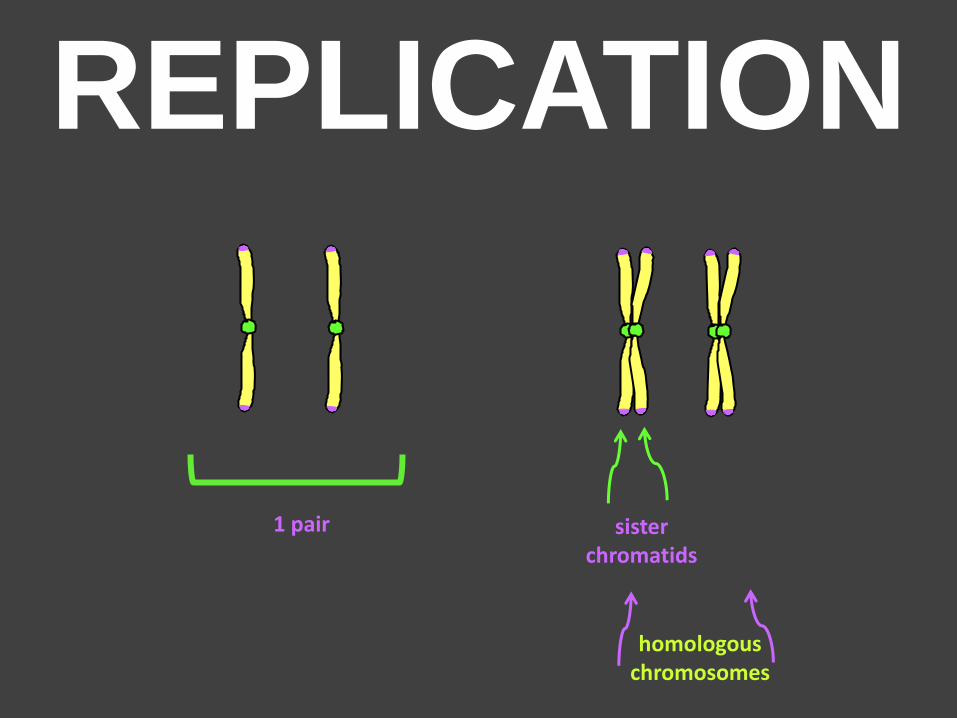
REPLICATION
1 pair sister chromatids
homologous chromosomes
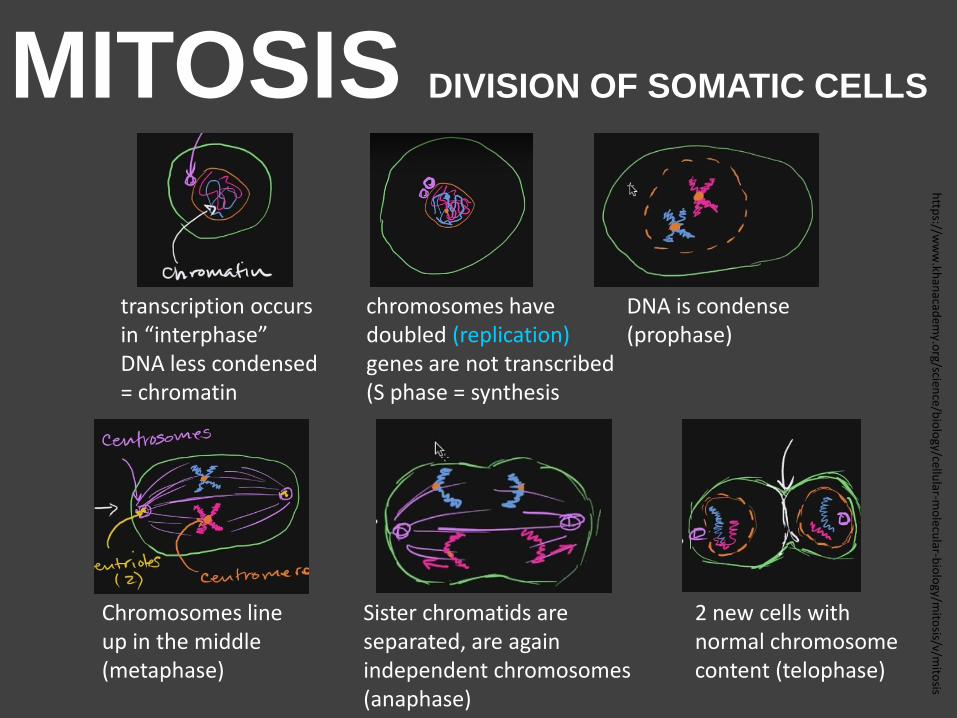
MITOSIS DIVISION OF SOMATIC CELLS
transcription occurs in “interphase” DNA less condensed = chromatin
chromosomes have doubled (replication) genes are not transcribed (S phase = synthesis
DNA is condense (prophase)
Chromosomes line up in the middle (metaphase)
Sister chromatids are separated, are again independent chromosomes (anaphase)
2 new cells with normal chromosome content (telophase)
http
s://ww
w.kh
anacad
emy.o
rg/science/b
iolo
gy/cellular-m
olecu
lar-bio
logy/m
itosis/v/m
itosis

MITOSIS DIVISION OF SOMATIC CELLS
http://www.youtube.com/watch?v=AhgRhXl7w_g als wmv
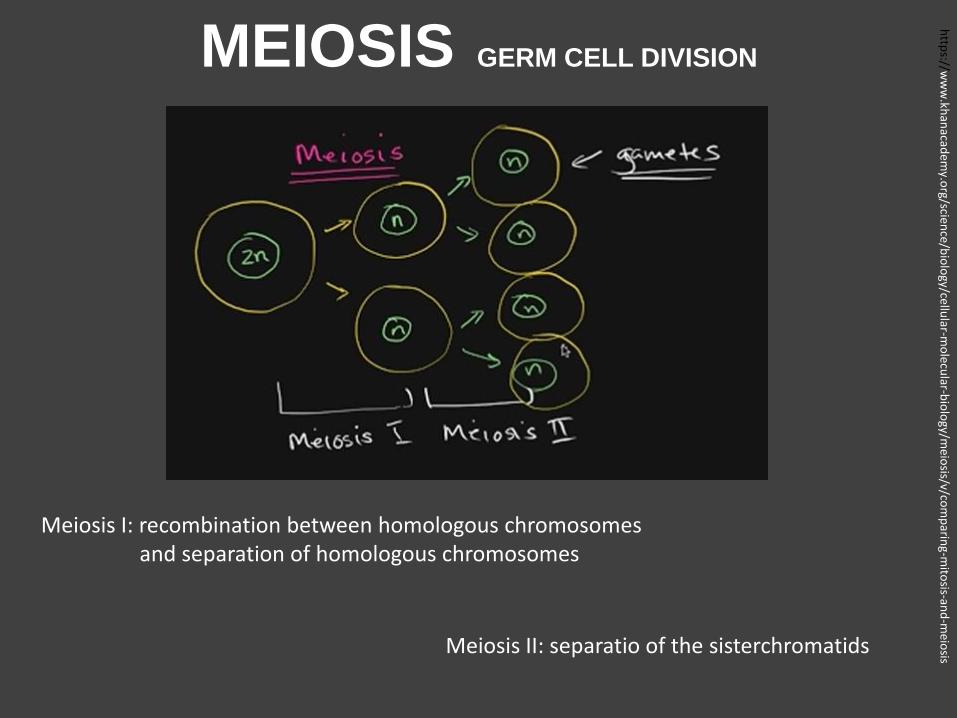
MEIOSIS GERM CELL DIVISION
http
s://ww
w.kh
anacad
emy.o
rg/science/b
iolo
gy/cellular-m
olecu
lar-bio
logy/m
eiosis/v/co
mp
aring-m
itosis-an
d-m
eiosis
Meiosis I: recombination between homologous chromosomes and separation of homologous chromosomes
Meiosis II: separatio of the sisterchromatids

MEIOSIS GERM CELL DIVISION
during production of germ cells chromosomes exchange pieces of DNA = recombination or crossing over to create genetic diversity
1. recombination between homologous chromosomes
2. pairs of chromosomes are separated
3. sister chromatids are separated
MEIOSIS DIVISION OF GERM CELLS
https://www.youtube.com/watch?v=D1_-mQS_FZ0

STRUCTURE OF A GENE a promoter region: binding of proteins for regulation 5’ UTR region : for stability of mRNA Exons: together code for a protein Introns: separate exons, are non coding 3’ UTR region: for stability of mRNA splice sites: on the exon-intron boundaries, sequense necessary for correct splicing out of introns
Exon1 Exon2 Exon3 Intron1 Intron2 Promoter
DNA 3’UTR 5’UTR GT………….….AG GT………….….AG AG AG G-T/A G-T/A
all exons from all 22.000 genes together are called the EXOME
Consists of:
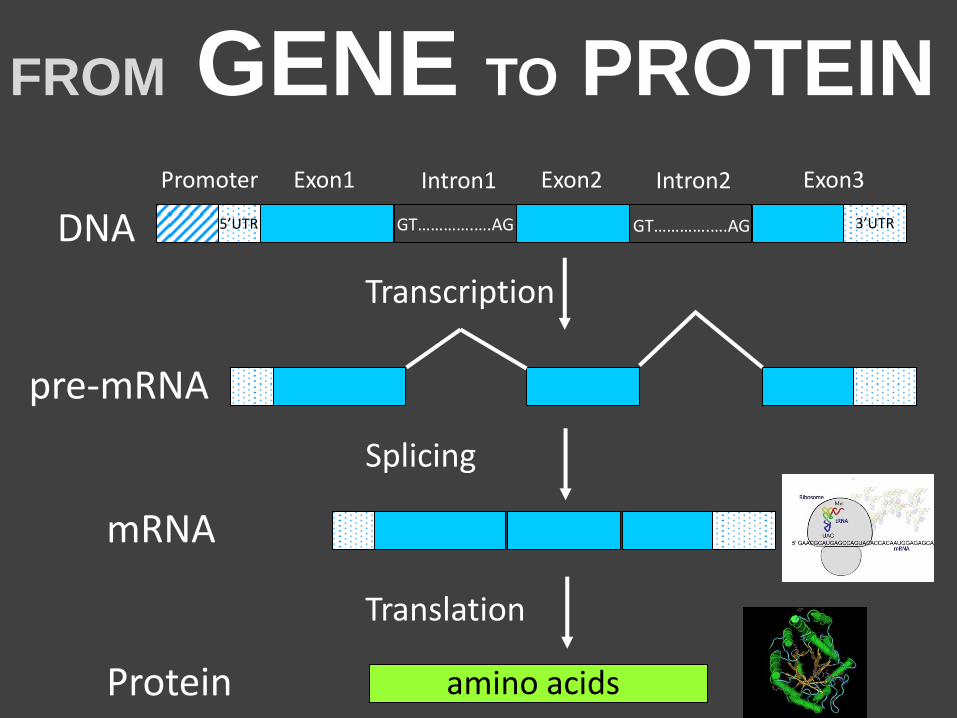
GT………….….AG GT………….….AG
Exon1 Exon2 Exon3 Intron1 Intron2 Promoter
DNA
Splicing
Transcription
Translation
3’UTR
FROM GENE TO PROTEIN
5’UTR
pre-mRNA
Protein amino acids
mRNA

DNA versus RNA Deoxyribonucleic - Ribonucleic acid
double strand - single strand stable - unstable
H
H
H
H
CH3 Uracil OH
OH
OH
OH

GENE REGULATION methylation
from a distance
histon modification
epigenetics
http://www.roadmapepigenomics.org/

http://www.nature.com/news/epigenome-the-symphony-in-your-cells-1.16955
GENE METHYLATION AND EXPRESSION EXPLAINED WITH BEETHOVEN
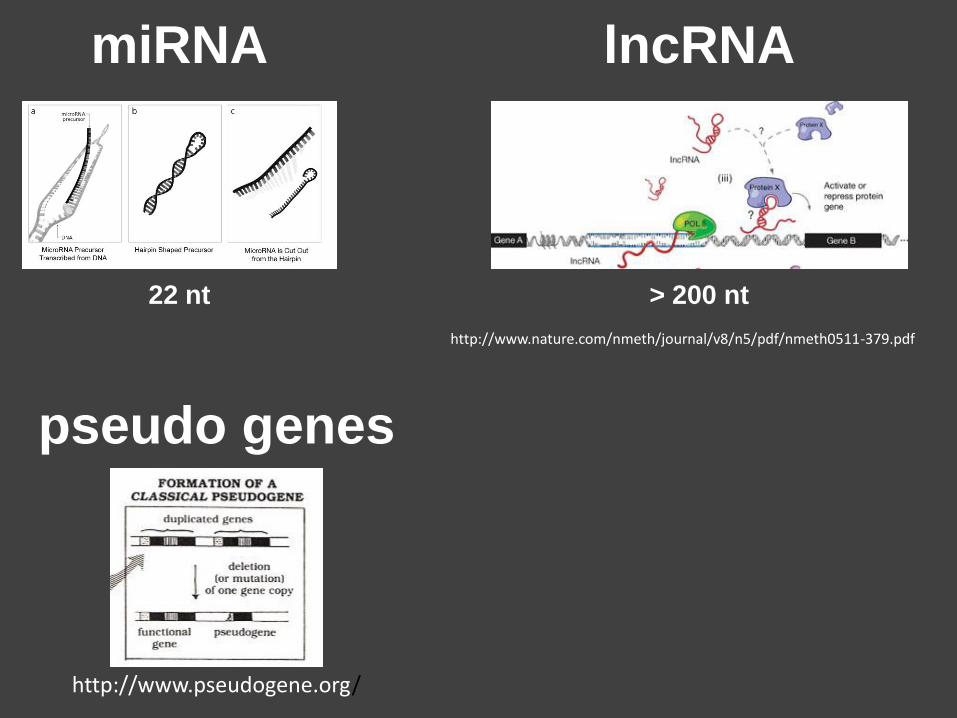
miRNA
22 nt
lncRNA
> 200 nt
http://www.nature.com/nmeth/journal/v8/n5/pdf/nmeth0511-379.pdf
pseudo genes
http://www.pseudogene.org/

HUMAN
GENETICS
diseases

Phenotype : all physical and mental properties of an organism Genotype: the order and composition of your base pairs
Your genotype largely determines your phenotype
PHENOTYPE-GENOTYPE
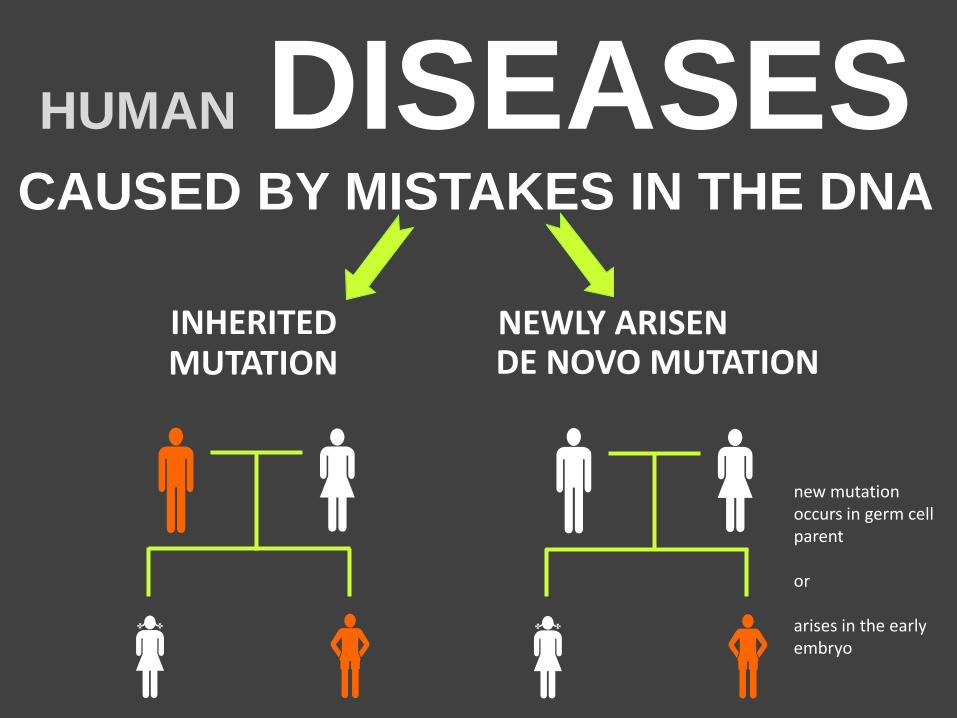
HUMAN DISEASES CAUSED BY MISTAKES IN THE DNA
INHERITED MUTATION
new mutation occurs in germ cell parent or arises in the early embryo
NEWLY ARISEN
DE NOVO MUTATION
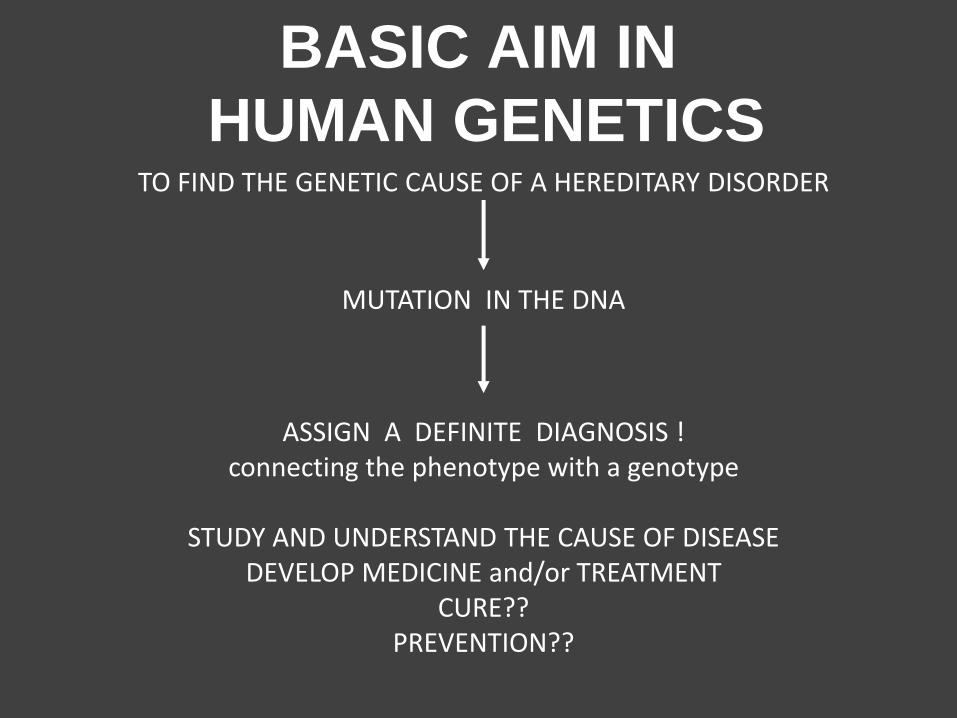
BASIC AIM IN
HUMAN GENETICS TO FIND THE GENETIC CAUSE OF A HEREDITARY DISORDER
ASSIGN A DEFINITE DIAGNOSIS ! connecting the phenotype with a genotype
STUDY AND UNDERSTAND THE CAUSE OF DISEASE
DEVELOP MEDICINE and/or TREATMENT CURE??
PREVENTION??
MUTATION IN THE DNA

TYPES OF DISEASES I
Mendelian disorders - monogenic one disease – one genedefect
Autosomal or X-linked -- dominant or recessive
Complex disorders
Interactions between (many) genes and environment
Chromosomal disorders
Translocations, inversions, deletions, aneuploidy
Somatic genetic disorders
Predisposition to cancer
Mitochondrial diseases (mutation in mitochondrial DNA)

TYPES OF DISEASES II “Complex” diseases
more than one gene involved
- genetic background plays a role
- environment plays a role
thousands of people needed
combinations of Variations in DNA
are risk factors small effect
one or a few families needed
caused by Mutation in DNA
large effect
“Simple” diseases
monogenetic
one disease – one genedefect
more severe phenotype
often early onset
relatively rare
Mendelian inheritance
e.g. cystic fibrosis,
osteogenesis imperfecta,
intellectual disability,
Duchennes muscular dystrophy
mild phenotype
late onset
common
complex inheritance
e.g. osteoporosis,
diabetes, asthma,
heart disease, stroke,
psychiatric disorders

1992 1998 1966 1994
1968
1971 1975 1978 1983 1985 1988 1990
1966-1998
Around 6600 monogenetic DISEASES
5108 - phenotype descriptions, molecular basis known
1596 - phenotype descriptions, molecular basis unknown
http://www.omim.org Update from October 2017
= database of human disorders;
phenotype descriptions
gene descriptions
OMIM online mendelian inheritance
in man
1985

MODELS OF
INHERITANCE
Comstock/Comstock/Getty Images
autosomal dominant: describes any trait that is expressed in a heterozygote (one mutant allele, one normal allele) autosomal recessive: manifests only in a homozygote (two mutant alleles) X-linked: males are hemizygous (XY) recessive: males are affected; females are unaffected carriers
dominant: males are affected; females are “affected”, but often compensate by inactivation of the affected copy not or mildly affected
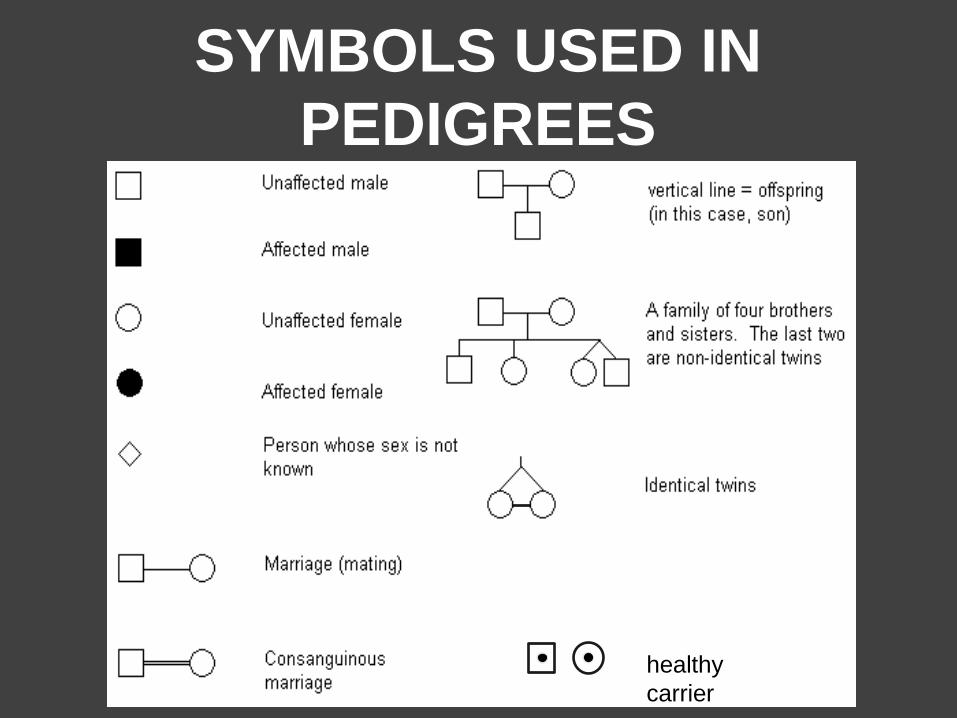
SYMBOLS USED IN
PEDIGREES
healthy
carrier

http://haplopainter.sourceforge.net/
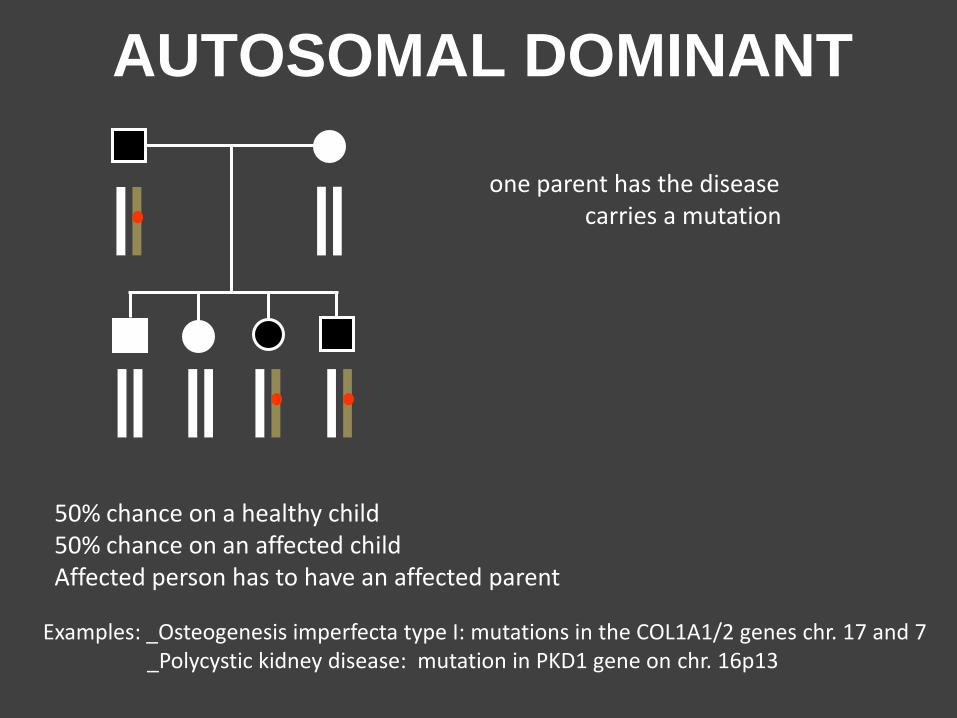
50% chance on a healthy child 50% chance on an affected child Affected person has to have an affected parent
Examples: _Osteogenesis imperfecta type I: mutations in the COL1A1/2 genes chr. 17 and 7 _Polycystic kidney disease: mutation in PKD1 gene on chr. 16p13
AUTOSOMAL DOMINANT
one parent has the disease carries a mutation

25% chance on a healthy child 25% chance on an affected child 50% chance on healthy carrier child
Example: _cystic fibrosis (1/30 persons carrier of a mutation in the CFTR gene on chr. 7q31 70% of carriers have the same mutation)
AUTOSOMAL RECESSIVE
both parents healthy carriers

AUTOSOMAL RECESSIVE WITH CONSANGUINITY
Often in first or second cousin marriages _parents have a common ancestor who carries a mutation on one allele _parents share the same chromosome(s) or part of a chromosome and are healthy carriers of the same gene mutation affected children are homozygous for that area = homozygosity
commonancestor
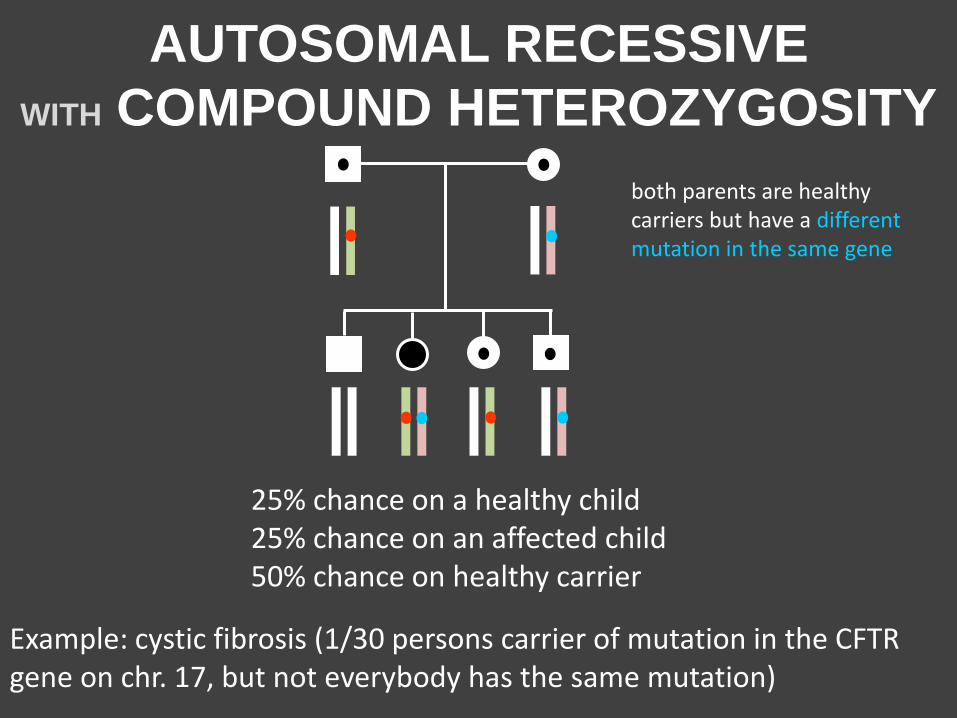
AUTOSOMAL RECESSIVE
WITH COMPOUND HETEROZYGOSITY
25% chance on a healthy child 25% chance on an affected child 50% chance on healthy carrier
Example: cystic fibrosis (1/30 persons carrier of mutation in the CFTR gene on chr. 17, but not everybody has the same mutation)
both parents are healthy carriers but have a different mutation in the same gene

X - LINKED
sons of carriers have a 50% chance to be affected daughters of carriers have a 50% chance to be a carrier
Example: _colourblindness (Xq28, more genes) _Duchenne muscular dystrophy, DMD gene on Xp21
women are healthy carriers of a mutation on one X-chromosome
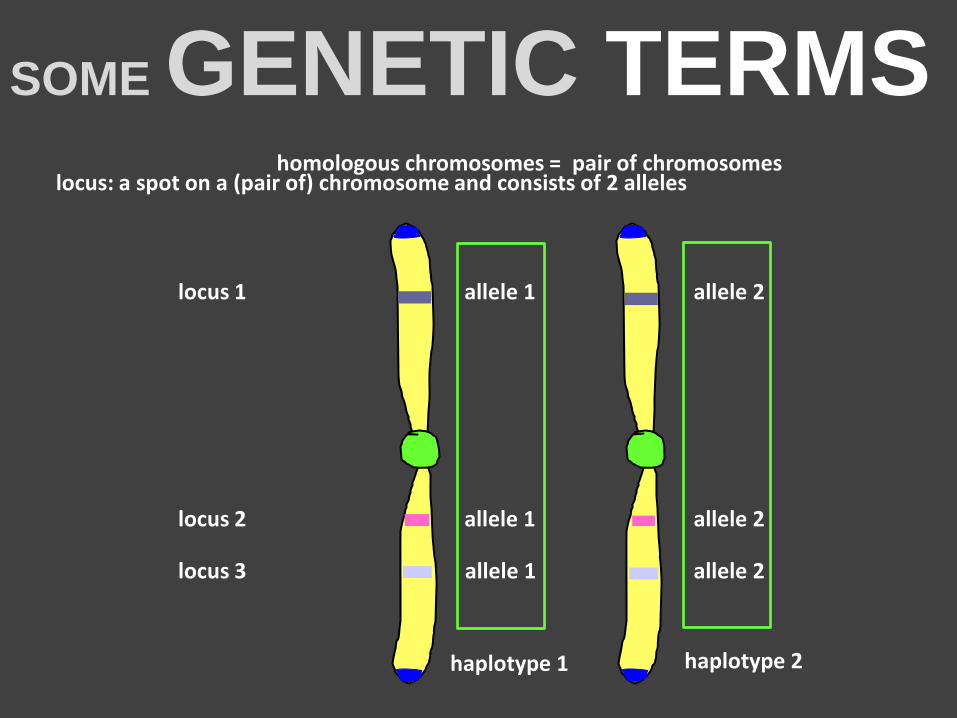
SOME GENETIC TERMS locus: a spot on a (pair of) chromosome and consists of 2 alleles
locus 1 allele 1 allele 2
locus 2 allele 1 allele 2
locus 3 allele 1 allele 2
haplotype 1 haplotype 2
homologous chromosomes = pair of chromosomes

REPEATS / VARIATIONS Besides genes DNA contains repeats and variations: Repeats Satellite repeats: in centromeres and telomeres Alu repeats: > 1 million copies, average 300 bp long, (10% of the genome) (is recognized by an enzyme derived from the bacterium Arthrobacter luteus) Low copy number repeats (LCRs) 10-500 kb with > 95% sequence identity ( 5% of the genome) Trinucleotide repeats: CGG, CAG (14 involved with diseases) Dinucleotide repeats (3% of the genome consists of di (CAn) and tetranucleotide repeats) Variations SNPs = single nucleotide polymorphisms (1 in 200-300 base pairs per genome -- freq > 1%) now > 170 million SNPs are in dbSNP CNV’s = copy number variations _deletions _amplifications (12 % of the genome, size: 1 – few 1000 of kb) Other things: insertions, inversions Combinations of these variations make every person unique

EXAMPLE OF CA repeat TAGAACAAAATAGCGGTATTTTGGGGAGTCTGACTGACCATTGG
ACTAGGGGATTGACCAGTAGGCTGCGATTCGGATGCGGATTGAC
GATTAAAAAGGCTGACCAGAACCATGTTATAAAGAATGCTGGGC
GGCACACACTGTTCNCCCACCTACTCTGGAGACTGAGGCTCAAG
GATTGCTTGAGCCCAGGAATTCGGGGCTGCAGTGAGCCATGATT
GTGTCACTGTATTCCAGCCTGGATGACAGAGTAAGACCCTGTCC
TTCTCTCTCTCTCTTCCTCTTTGGTCTCTCTCGCTCTGTTTCTC
TCTCTCTCTCTTATA
CTACTGGGAAAGTGAATGTTT
GTTTTCCTCGCCANTAGTGGAAGCTATTACGATTAGCTGTGACG
TGCAGGATGCTGCGATGCTGGACTGAACGCCCCCCGGGCTTCTT
TATTAGCTGCTGACGTGCCAGATGCTGACGTGCAGTGAGGAGTC
TGACTGACCATTGGACTAGGGGATTGACCAGTAGGCTGCGATTC
GGATGCGGATTGACGATTAAAAAGGATTACGATTAGCTGTGACG
TGCAGGATGCTGCGATGCTGGACTGAACGCCCCCCGGGCTTCTT
TATTAGCTGCTGACGTGCCAGATGCTGACGTGCAGTGCGGCTGA
CGGTGCTTACCTGGATCGGATGCTACCAGTCGATCGATCGATCG
TAGCGTAGCGTATGCTAGCTAGTGATCGATGCTAGTAGCTAGCT
TAGAACAAAATAGCGGTATTTTGGGGAGTCTGACTGACCATTGG
ACTAGGGGATTGACCAGTAGGCTGCGATTCGGATGCGGATTGAC
GATTAAAAAGGCTGACCAGAACCATGTTATAAAGAATGCTGGGC
GGCACACACTGTTCNCCCACCTACTCTGGAGACTGAGGCTCAAG
GATTGCTTGAGCCCAGGAATTCGGGGCTGCAGTGAGCCATGATT
GTGTCACTGTATTCCAGCCTGGATGACAGAGTAAGACCCTGTCC
TTCTCTCTCTCTCTTCCTCTTTGGTCTCTCTCGCTCTGTTTCTC
TCTCTCTCTCTTATA
CTACTGGGAAAGTGAATGTTTGTTTTCCTCG
CCANTAGTGGAAGCTATTACGATTAGCTGTGACGTGCAGGATGC
TGCGATGCTGGACTGAACGCCCCCCGGGCTTCTTTATTAGCTGC
TGACGTGCCAGATGCTGACGTGCAGTGAGGAGTCTGACTGACCA
TTGGACTAGGGGATTGACCAGTAGGCTGCGATTCGGATGCGGAT
TGACGATTAAAAAGGATTACGATTAGCTGTGACGTGCAGGATGC
TGCGATGCTGGACTGAACGCCCCCCGGGCTTCTTTATTAGCTGC
TGACGTGCCAGATGCTGACGTGCAGTGCGGCTGACGGTGCTTAC
CTGGATCGGATGCTACCAGTCGATCGATCGATCGTAGCGTAGCG
TATGCTAGCTAGTGATCGATGCTAGTAGCTAGCT
a repetition of CA sequences 1 per few thousand base pairs mostly in non-coding sequence length can vary per person and per chromosome, from 3 – 100 CA’s this is a polymorphic repeat, it varies in length (mostly when > 10) a CA repeat can have more than 2 alleles
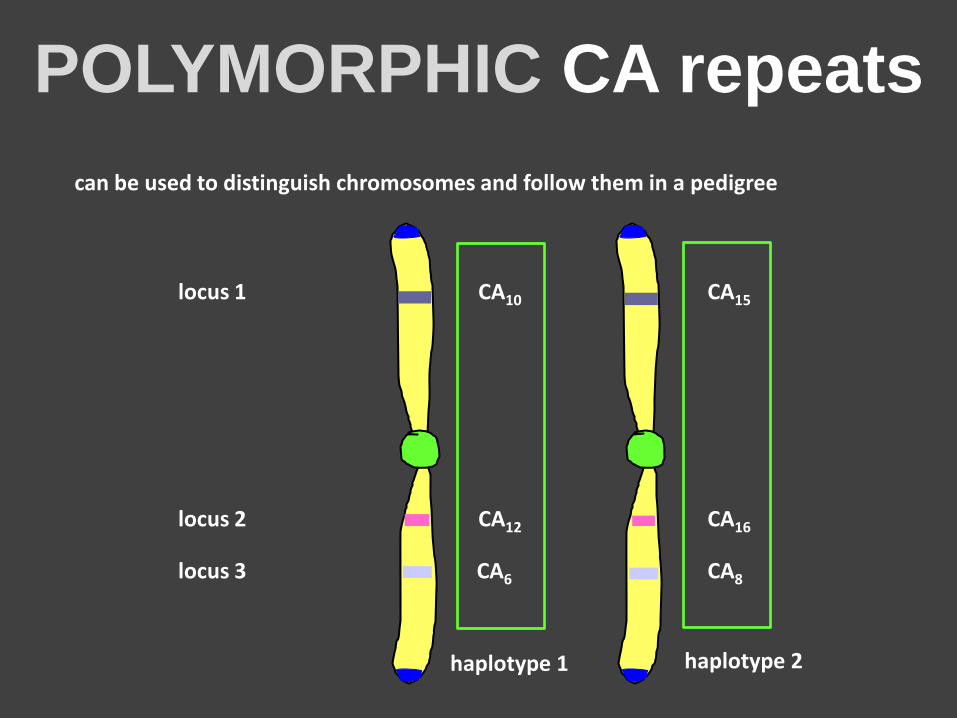
POLYMORPHIC CA repeats
can be used to distinguish chromosomes and follow them in a pedigree
locus 1 CA10 CA15
locus 2 CA12 CA16
locus 3 CA6 CA8
haplotype 1 haplotype 2
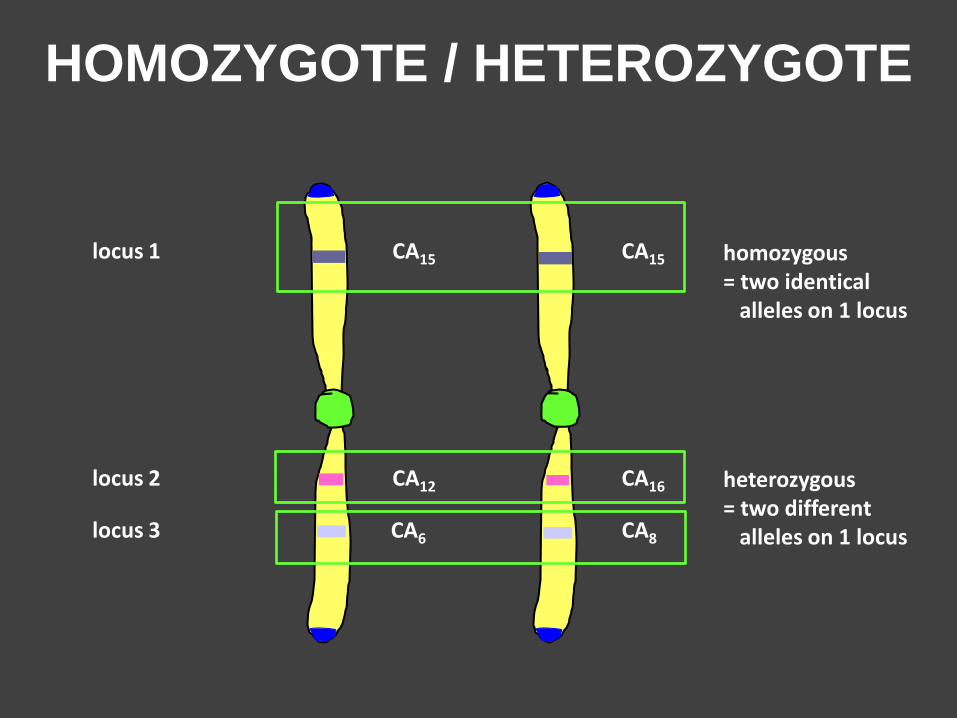
HOMOZYGOTE / HETEROZYGOTE
locus 1 CA15 CA15
locus 2 CA12 CA16
locus 3 CA6 CA8
homozygous = two identical alleles on 1 locus
heterozygous = two different alleles on 1 locus

SEGREGATION
ca10 ca15 ca14 ca18
ca10 ca14 ca15 ca14 ca18
ca10
ca15
ca15
ca15 ca10
ca15 ca14 ca14 ca15
ca16 ca12
ca16 ca16
ca16
This chromosome segregates with the disease in this family and contains a gene mutation = principle of a linkage study
ca10
ca16
ca12
ca10
ca10
ca16
ca16 ca16
ca16 ca16

a single nucleotide polymorphism, a 1 base variant most frequent variant in the genome, on average 1 every 200-300 bp (common SNPs) can occur in coding and non-coding sequence distributed over the whole genome, exons, introns regulatory regions etc. length is only 1 base, can vary per chromosome and between persons a SNP is also polymorphic, but it has only 2 alleles (less informative than a CA repeat) all SNPs are in a database: dbSNP: http://www.ncbi.nlm.nih.gov/projects/SNP/ every SNP is defined by an rs……. number
TGCGATTCGGATGCGGATTGACGATTAAAAAGGATTACGATTAGCTG
TGACGTGCAGGATGCTGCGATGCTGGACTGAACGCCCCCCGGGCTTC
TTTATTAGCTGCTGACGTGCCAGATGCTGACGTGCAGTGCGGCTGAC
GGTGCTTACCTGGATCGGATGCTACCAGTCGATCGATCGATCGTAGC
GTAGCGTATGCTAGCTAGTGATCGATGCTAGTAGCTAGCTAGCTGAT
CGATCATCGATCGTAGCTAGCTAGCTAGCTAGCTGATCGATCGATGC
TAGCTAGCTAGCTAGTCATCTGTGGTGGGGGGTTAAATGCGATTGCC
GCTAGCTAGAACAAAATAGCGGTATTTTGGGGAGTCTGACTGACCAT
TGGACTAGGGGATTGACCAGTAGGCTGCGATTCGGATGCGGATTGAC
GATTAAAAAGGATTACGATTAGCTGTGACGTGCAGGATGCTGCGATG
CTGGACTGAACGCCCCCCGGGCTTCTTTATTAGCTGCTGACGTGCCA
GATGCTGACGTGCAGTGAGGAGTCTGACTGACCATTGGACTAGGGGA
TTGACCAGTAGGCTGCGATTCGGATGCGGATTGACGATTAAAAAGGA
TTACGATTAGCTGTGACGTGCAGGATGCTGCGATGCTGGACTGAACG
TGCGATTCGGATGCGGATTGACAATTAAAAAGGATTACGATTAGCTG
TGACGTGCAGGATGCTGCGATGCTGGACTGAACGCCCCCCGGGCTTC
TTTATTAGCTGCTGACGTGCCAGATGCTGACGTGCAGTGCGGCTGAC
GGTGCTTACCTGGATCGGATGCTACCAGTCGATCGATCGATCGTAGC
GTAGCGTATGCTAGCTAGTGATCGATGCTAGTAGCTAGCTAGCTGAT
CGATCATCGATCGTAGCTAGCTAGCTAGCTAGCTGATCGATCGATGC
TAGCTAGCTAGCTAGTCATCTGTGGTGGGGGGTTAAATGCGATTGCC
GCTAGCTAGAACAAAATAGCGGTATTTTGGGGAGTCTGACTGACCAT
TGGACTAGGGGATTGACCAGTGGGCTGCGATTCGGATGCGGATTGAC
GATTAAAAAGGATTACGATTAGCTGTGACGTGCAGGATGCTGCGATG
CTGGACTGAACGCCCCCCGGGCTTCTTTATTAACTTCTGACGTGCCA
GATGCTGACGTGCAGTGAGGAGTCTGACTGACCATTGGACTAGGGGA
TTGACCAGTAGGCTGCGATTCGGATGCGGATTGACGATTAAAAAGGA
TTACGATTAGCTGTGACGTGCAGGATGCTGCGATGCTGGACTGAACG
EXAMPLE OF a SNP

SOME FACTS ABOUT SNPs
_every individual has about 10 million common SNPs in their genome _ a SNP has a Minor Allele Frequency = MAF that is the frequency at which the less common allele occurs in a given population example SNP: rs1042725 variant located on chromosome 12 (at chromosomal position 66358347 (build 37) CTCAATACTACCTCTGAATGTTACAA[C/T]GAATTTACAGTCTAGTACTTATTAC the ancestral allele = C has allele frequency of 0.6 = major allele the variant allele = T MAF of 0.4 = minor allele 60% of the chromosomes in the population carry a C at this position 40% of the chromosomes in the population carry a T at this position

DIFFERENT TYPES OF SNPs
IN CODING REGIONS
synonymous SNP variation on DNA level no change in amino acid
TTT or TTC both code for
Phenylalanine
no change in protein
non-synonymous SNP variation on DNA level gives change in amino acid
TGG or TGC
Tryptofane Cysteine
change in protein
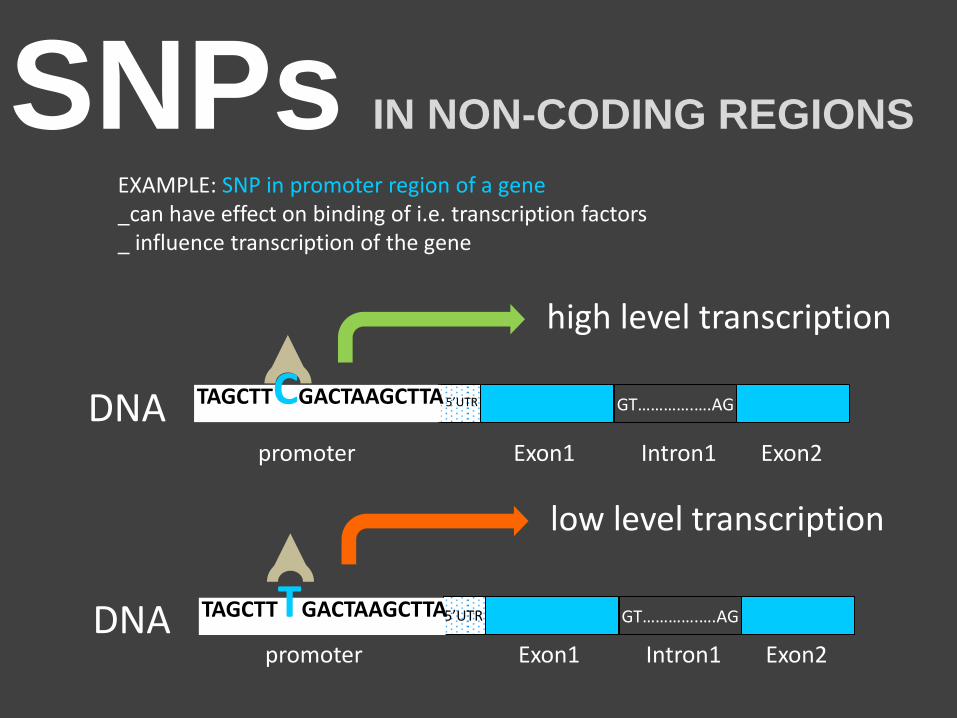
SNPs IN NON-CODING REGIONS
EXAMPLE: SNP in promoter region of a gene _can have effect on binding of i.e. transcription factors _ influence transcription of the gene
GT………….….AG
Exon1 Exon2 Intron1 promoter DNA 5’UTR TAGCTTTGACTAAGCTTA
GT………….….AG
Exon1 Exon2 Intron1 promoter
DNA 5’UTR TAGCTTCGACTAAGCTTA
high level transcription
low level transcription

db SNP dbSNP database was set up in 1998 (by NCBI and NHGRI) = public database of genetic variation (human + other species) _it contains SNPs (99.7%) short insertion/deletion polymorphisms (0.2%) and short tandem repeats and other things (0.1%) _neutral variants as well as disease-causing clinical mutations ! _Academic research laboratories as well as private research companies can contribute variations to dbSNP _consortia contribute: HapMap Project, 1000 Genomes Project, Wash_UV ESP dbSNP progressed from Build 1 with 11 SNPs in 1998 Build 138 with 62.676.337 SNPs in 2013 Build 142 with 112.743.739 SNPs in 2014 Build 144 with 149.735.377 SNPs in 2015 Build 150 with 171.000.000 SNPs in 2017

With the collection of SNPs growing, emphasis shifted to studying SNPs in populations (2002) _How are allele frequencies of SNPs distributed between different populations _How are these variants in individuals associated with a - complex - disease HapMap Project (2002) started: genotyping of 270 samples from different populations (Africa, USA, Japan, China) and produced allele frequencies for millions of SNPs can be used for Genome Wide Association Studies (GWAS)
INTEREST IN
SNPs IN POPULATIONS

WHAT IS A GENOME WIDE
ASSOCIATION STUDY - GWAS
_study designed to identify possible variants in the human genome that contribute to complex diseases _compare the DNA of thousands of people with a specific medical condition (or trait) the DNA of thousands of similar people without that condition searche for differences between their genomes _ = association study because certain variants / SNPs will occur more often in the disease group than in the non-disease group and are "associated" with the condition _these variants are not the direct cause of the condition they contribute to the disease and have a small effect

... ATGCCGATCGCT ...
... ATGCCGATCGCT ...
... ATGCCGATCGCT ...
... ATGCCGATCGCT ...
... ATGCCGATCACT ...
... ATGCCGATCACT ...
a variation/ SNP with MAF of 33%
SNP| G
SNP| A
some individuals have one version the the SNP, some the other
healthy people people with a disease
in a normal population a certain percentage will have one allele, the rest the other
in the disease group a higher than normal incidence of one allele suggests that SNP |A is associated with the disease

_the idea was that association to common genetic variations (MAF >5% in the population) would explain the cause of complex disease but they contribute only a modest risk for the diseases. _ the next idea was that the genetic burden of common diseases must be carried by large numbers of rare variants (MAF 0.05 – 1% of the population) but these also only contribute modestly to disease risk _many loci that have been discovered to be associated to a disease do not map to exons of genes: these loci might contain regulatory or functional sequences is being investigated by the ENCODE project : ENCyclOpedia of DNA Elements https://genome.ucsc.edu/encode goal: build a comprehensive map of functional elements in the human genome

THE
HUMAN
GENOME
PROJECT
National
Human
Genome
Research
Institute, NIH

Started in October 1990 goal: _determine the sequence of all 3 x 109 base pairs _identify all the human genes (20.000-25.000) _store information in databases _improve tools for data analysis _ coordinated and funded by US department of Energy and the National Institutes of Health (NIH) – director Francis Collins _ performed by a consortium of scientists from diff. countries (USA, UK, France, Australia, Japan and others) _public project _was expected to take 15 years

In May 1998 Craig Venter, started the company Celera Genomics and announced that he would sequence the human genome in only two years (privately funded project) _ also he wanted to patent human genes, which is what Watson wanted and was of great concern to Francis Collins _the race and competition started between Collins and Venter

June 26, 2000 It was decided that the competitors announce the completion of the first working draft of the entire human genome together
Craig Venter (Celera) Bill Clinton Francis Collins (NIH)
Febr 2001: first draft of the genome published in separate journals April 2003: announcement of the essentially complete genome May 2006: sequence of the last human chromosome was published
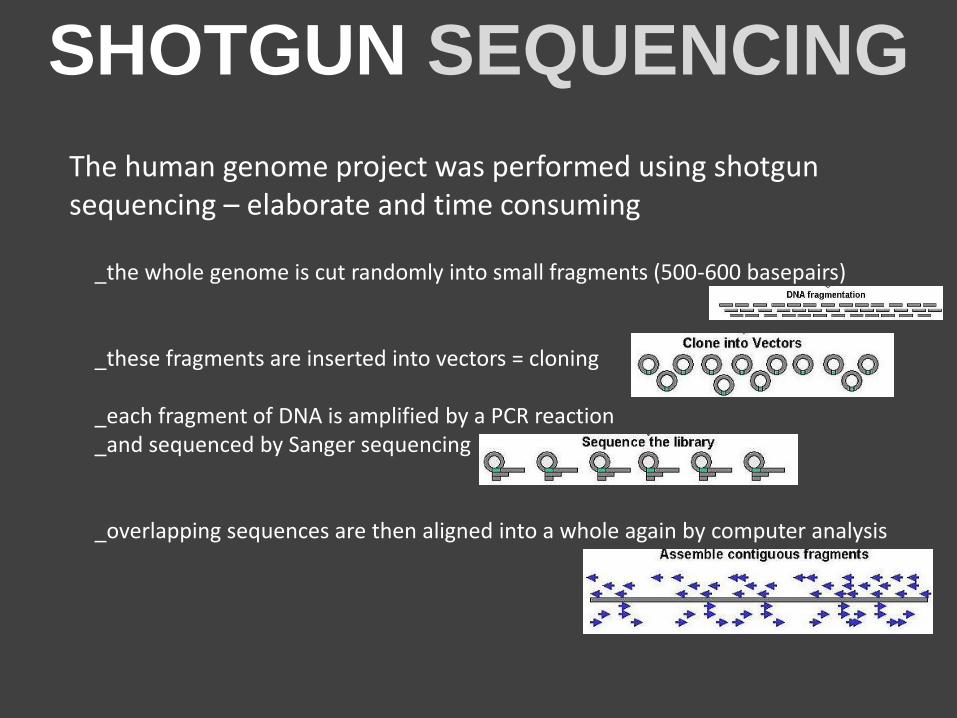
SHOTGUN SEQUENCING
The human genome project was performed using shotgun sequencing – elaborate and time consuming
_the whole genome is cut randomly into small fragments (500-600 basepairs) _these fragments are inserted into vectors = cloning _each fragment of DNA is amplified by a PCR reaction _and sequenced by Sanger sequencing _overlapping sequences are then aligned into a whole again by computer analysis

NEXT
GENERATION
SEQUENCING

FROM SHOTGUN TO NEXT
GENERATION SEQUENCING
because of the human genome project more modern sequencing techniques were developed which are less elaborate and also faster (lectures from Robert Kraaij tomorrow) this started the 1000 genomes project in 2008 with the aim to sequence DNA of 1000 participants uncover genetic variation
1000
GENOMES
PROJECT www.1000genomes.org
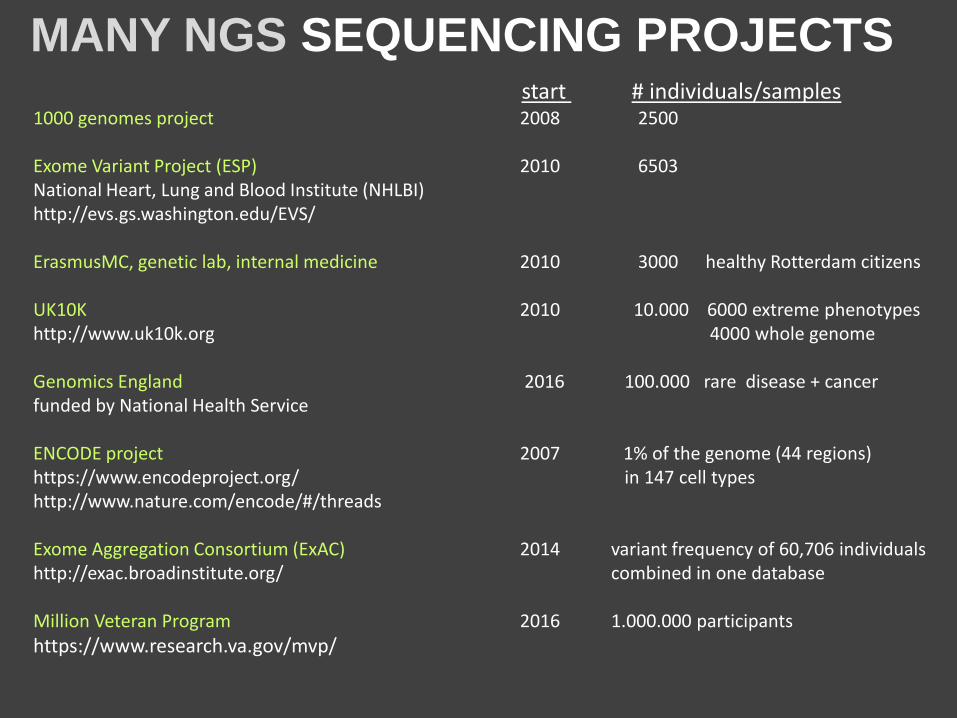
MANY NGS SEQUENCING PROJECTS
1000 genomes project 2008 2500 Exome Variant Project (ESP) 2010 6503 National Heart, Lung and Blood Institute (NHLBI) http://evs.gs.washington.edu/EVS/ ErasmusMC, genetic lab, internal medicine 2010 3000 healthy Rotterdam citizens UK10K 2010 10.000 6000 extreme phenotypes http://www.uk10k.org 4000 whole genome Genomics England 2016 100.000 rare disease + cancer funded by National Health Service ENCODE project 2007 1% of the genome (44 regions) https://www.encodeproject.org/ in 147 cell types http://www.nature.com/encode/#/threads Exome Aggregation Consortium (ExAC) 2014 variant frequency of 60,706 individuals http://exac.broadinstitute.org/ combined in one database Million Veteran Program 2016 1.000.000 participants
https://www.research.va.gov/mvp/
start # individuals/samples
