fluentd at bay area kubernetes meetup
TRANSCRIPT

Logging for Production Systems
in The Container Era
Sadayuki Furuhashi Founder & Software Architect
Bay Area Kubernetes Meetup

A little about me…
Sadayuki Furuhashi
github: @frsyuki
A founder of Treasure Data, Inc. located in Mountain View.
OSS projects I founded:
An open-source hacker.

It's like JSON. but fast and small.
A little about me…

The Container EraServer Era Container Era
Service Architecture Monolithic Microservices
System Image Mutable Immutable
Managed By Ops Team DevOps Team
Local Data Persistent Ephemeral
Log Collection syslogd / rsync ?
Metrics Collection Nagios / Zabbix ?

Server Era Container Era
Service Architecture Monolithic Microservices
System Image Mutable Immutable
Managed By Ops Team DevOps Team
Local Data Persistent Ephemeral
Log Collection syslogd / rsync ?
Metrics Collection Nagios / Zabbix ?
The Container Era
How should log & metrics collection be done in The Container Era?

Problems

The traditional logrotate + rsync on containers
Log Server
Application
Container A
File FileFile
Difficult to use!!Complex text parsers
Application
Container C
File FileFile
Application
Container B
File FileFile
High latency!!Must wait for a day
Ephemeral!!Could be lost at any time

Server 1
Container AApplication
Container BApplication
Server 2
Container CApplication
Container DApplication
Kafka
elasticsearch
HDFS
Container
Container
Container
Container
Small & many containers make storages overloadedToo many connections from micro containers!

Server 1
Container AApplication
Container BApplication
Server 2
Container CApplication
Container DApplication
Kafka
elasticsearch
HDFS
Container
Container
Container
Container
System images are immutableToo many connections from micro containers!
Having M*N configurationmakes hard!

Combination explosion with microservicesrequires too many scripts for data integration
LOG
script to parse data
cron job forloading
filteringscript
syslogscript
Tweet-fetching
script
aggregationscript
aggregationscript
script to parse data
rsyncserver

The centralized log collection service
LOG
We Released!(Apache License)

What’s Fluentd?
Simple core + Variety of plugins
Buffering, HA (failover), Secondary output, etc.
Like syslogd
AN EXTENSIBLE & RELIABLE DATA COLLECTION TOOL

Real World Use Cases

Text logging with --log-driver=fluentdServer
Container
App
FluentdSTDOUT / STDERR
docker run \ --log-driver=fluentd \ --log-opt \ fluentd-address=localhost:24224
{ “container_id”: “ad6d5d32576a”, “container_name”: “myapp”, “source”: stdout}

Metrics collection with fluent-loggerServer
Container
App
Fluentd
from fluent import senderfrom fluent import event
sender.setup('app.events', host='localhost')event.Event('purchase', { 'user_id': 21, 'item_id': 321, 'value': '1'})
tag = app.events.purchase{ “user_id”: 21, “item_id”: 321 “value”: 1,}fluent-logger library

Logging methods for each purpose• Collecting log messages
> --log-driver=fluentd
• Application metrics
> fluent-logger
• Access logs, logs from middleware
> Shared data volume
• System metrics (CPU usage, Disk capacity, etc.)
> Fluentd’s input plugins(Fluentd pulls those data periodically)
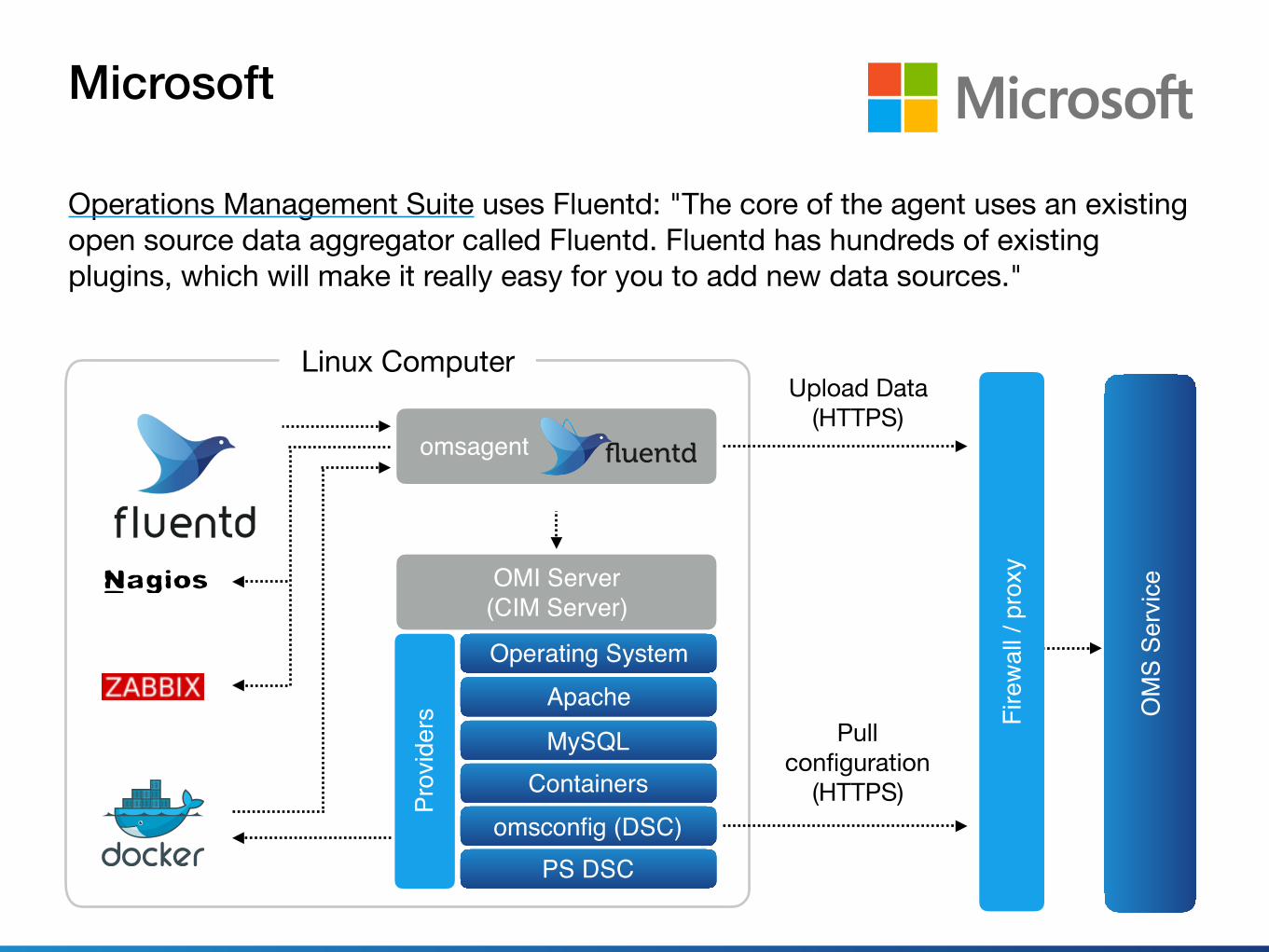
Microsoft
Operations Management Suite uses Fluentd: "The core of the agent uses an existing open source data aggregator called Fluentd. Fluentd has hundreds of existing plugins, which will make it really easy for you to add new data sources."
Syslog
Linux Computer
Operating SystemApache
MySQLContainers
omsconfig (DSC)PS DSC
Prov
ider
s
OMI Server(CIM Server)
omsagent
Fire
wal
l / p
roxy
OM
S Se
rvic
e
Upload Data(HTTPS)
Pullconfiguration
(HTTPS)

Atlassian
"At Atlassian, we've been impressed by Fluentd and have chosen to use it in Atlassian Cloud's logging and analytics pipeline."
Kinesis
Elasticsearchcluster
Ingestionservice

Deployment Patterns

Server 1
Container AApplication
Container BApplication
Server 2
Container CApplication
Container DApplication
Kafka
elasticsearch
HDFS
Container
Container
Container
Container
Primitive deployment…Too many connections from many containers!
Having M*N configurationmakes hard!

Server 1
Container AApplication
Container BApplication
Fluentd
Server 2
Container CApplication
Container DApplication
Fluentd Kafka
elasticsearch
HDFS
Container
Container
Container
Container
destination is always localhost from app’s point of view
Source aggregation decouples config from apps

Server 1
Container AApplication
Container BApplication
Fluentd
Server 2
Container CApplication
Container DApplication
Fluentd
active / standby /load balancing
Destination aggregation makes storages scalable for high traffic
Aggregation server(s)

Aggregation servers• Logging directly from microservices makes log
storages overloaded. > Too many RX connections > Too frequent import API calls
• Aggregation servers make the logging infrastracture more reliable and scalable. > Connection aggregation > Buffering for less frequent import API calls > Data persistency during downtime > Automatic retry at recovery from downtime

Example Use Cases

Streaming from Apache/Nginx to Elasticsearch
in_tail /var/log/access.log
/var/log/fluentd/buffer
but_file

Error Handling and Recovery
in_tail /var/log/access.log
/var/log/fluentd/buffer
but_file
Buffering for any outputs Retrying automatically With exponential wait and persistence on a disk and secondary output

Tailing & parsing files
Supported built-in formats:
Read a log file Custom regexp Custom parser in Ruby
• apache • apache_error • apache2 • nginx
• json • csv • tsv • ltsv
• syslog • multiline • none
pos fileevents.log
?(your app)

Out to Multiple Locations
Routing based on tags Copy to multiple storages
bufferaccess.log
in_tail

Example configuration for real time batch combo

Data partitioning by time on HDFS / S3
access.logbuffer
Custom file formatter
Slice files based on time
2016-01-01/01/access.log.gz 2016-01-01/02/access.log.gz 2016-01-01/03/access.log.gz …
in_tail

The centralized log collection service
LOG
We Released!(Apache License)