fist: scalable xml document filtering by sequencing twig patterns
DESCRIPTION
FiST. FiST: Scalable XML Document Filtering by Sequencing Twig Patterns. Joonho Kwon, Praveen Rao, Bongki Moon, Sukho Lee. School of Electrical Engineering and Computer Science, Seoul National University. Department of Computer Science, University of Arizona. Roadmap. Introduction - PowerPoint PPT PresentationTRANSCRIPT

-1-
VLDB 2005, Trondheim, Norway
FiST: Scalable XML Document Filtering FiST: Scalable XML Document Filtering by Sequencing Twig Patternsby Sequencing Twig Patterns
FiST: Scalable XML Document Filtering FiST: Scalable XML Document Filtering by Sequencing Twig Patternsby Sequencing Twig Patterns
Joonho Kwon, Praveen Rao, Joonho Kwon, Praveen Rao, Bongki Moon, Sukho Bongki Moon, Sukho LeeLee
FiSTFiSTFiSTFiST
School of Electrical School of Electrical Engineering and Computer Engineering and Computer Science, Seoul National Science, Seoul National UniversityUniversity
Department of Computer Department of Computer Science, University of ArizonaScience, University of Arizona

-2-
VLDB 2005, Trondheim, Norway
RoadmapRoadmapRoadmapRoadmap
• IntroductionIntroduction Background and MotivationsBackground and Motivations
• Index StructureIndex Structure Profile SequencesProfile Sequences Sequence IndexSequence Index
• Filtering AlgorithmFiltering Algorithm Progressive Subsequence MatchingProgressive Subsequence Matching Refinement for Branch Node VerificationRefinement for Branch Node Verification
• Experimental Experimental ResultsResults
• ConclusionsConclusions

-3-
VLDB 2005, Trondheim, Norway
IntroductionIntroductionIntroductionIntroduction
• Publish-subscribe systems Publish-subscribe systems Selective dissemination of information (SDI)Selective dissemination of information (SDI) User profiles (or standing queries)User profiles (or standing queries) New content is matched against the user profiles and is delivered to New content is matched against the user profiles and is delivered to
interested usersinterested users
• XML document filteringXML document filtering User profilesUser profiles (or (or twig patterns)twig patterns) are specified in the XPath language are specified in the XPath language Incoming XML document is delivered to users whose profiles have a match Incoming XML document is delivered to users whose profiles have a match
in the documentin the document Reversal in the roles of Reversal in the roles of twig patternstwig patterns and and XML documentsXML documents
• Challenges: Challenges: To minimize theTo minimize the filtering cost filtering cost by effectively organizing a large number of by effectively organizing a large number of
user profilesuser profiles To achieve To achieve good scalabilitygood scalability

-4-
VLDB 2005, Trondheim, Norway
IntroductionIntroductionIntroductionIntroduction
• XFilter (XFilter (VLDB’00VLDB’00) and YFilter () and YFilter (TODS’03TODS’03) ) XFilter – each path expression is mapped to a FSMXFilter – each path expression is mapped to a FSM YFilter – a single NFA for XPath expressions with shared YFilter – a single NFA for XPath expressions with shared
processing processing
• MotivationsMotivations To develop a To develop a scalable XML filtering systemscalable XML filtering system that supports processing that supports processing
of twig patternsof twig patterns To support To support holisticholistic matchingmatching of twig patterns without first matching of twig patterns without first matching
the linear paths in the patterns and then merging these matches the linear paths in the patterns and then merging these matches during post-processingduring post-processing
To inherently support To inherently support ordered matchingordered matching where the nodes in the twig where the nodes in the twig pattern follow the document order in XMLpattern follow the document order in XML

-5-
VLDB 2005, Trondheim, Norway
Tree to Sequence TransformationTree to Sequence TransformationTree to Sequence TransformationTree to Sequence Transformation
• Extended Prüfer Sequences (Extended Prüfer Sequences (PRIXPRIX,, ICDE’04ICDE’04)) Extend Extend leaf nodesleaf nodes of the tree with dummy child nodes of the tree with dummy child nodes
(A,9)
(B,5)
(B,2) (D,4)
(C,8)
(C,7)
BLPS(T):
Tree T
B A C A
(d,1) (d,3) (d,6)
B D C
(A,9)
(B,5)
(B,2) (D,4)
(C,8)
(C,7)
-6-
VLDB 2005, Trondheim, Norway
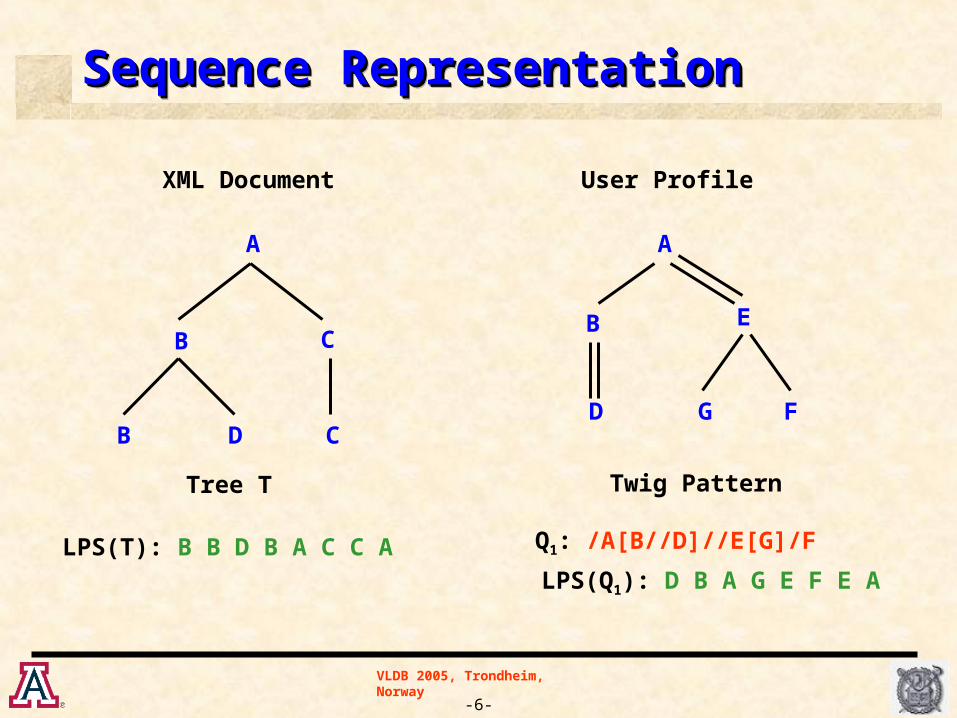
Sequence RepresentationSequence RepresentationSequence RepresentationSequence Representation
A
B
D
E
G F
Q1: /A[B//D]//E[G]/F
LPS(Q1): D B A G E F E A
Twig Pattern
A
B
B D
C
C
LPS(T): B B D B A C C A
Tree T
XML Document User Profile

-7-
VLDB 2005, Trondheim, Norway
FiSTFiSTFiSTFiST
User profiles
Profile sequences
SequenceIndex
FilteringAlgorithm
XML documents
-8-
VLDB 2005, Trondheim, Norway
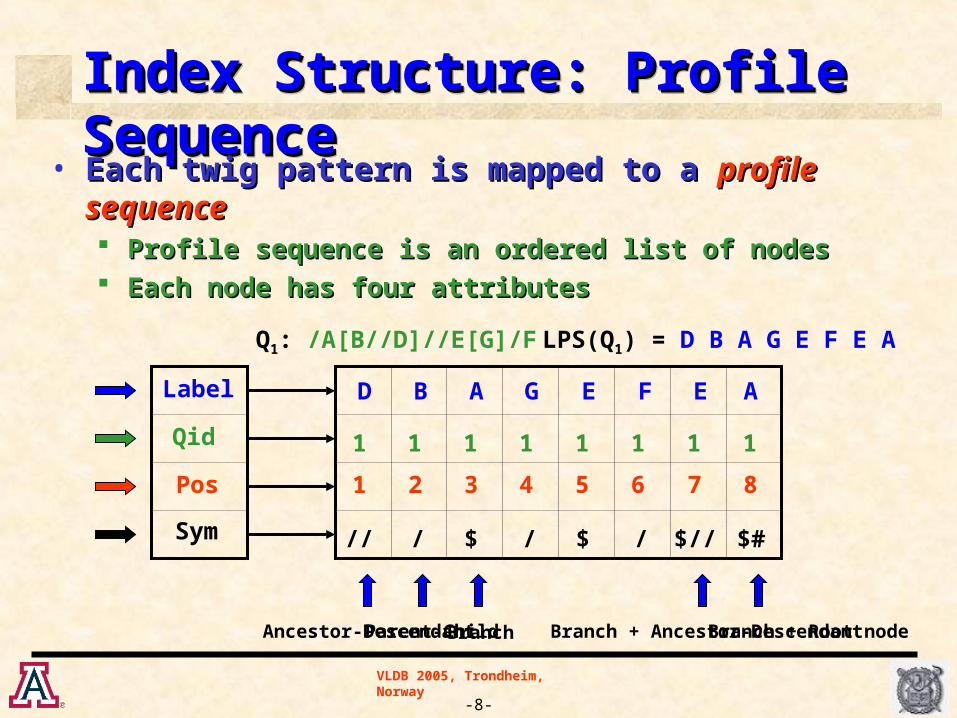
Index Structure: Profile SequenceIndex Structure: Profile SequenceIndex Structure: Profile SequenceIndex Structure: Profile Sequence
• Each twig pattern is mapped to a Each twig pattern is mapped to a profile sequenceprofile sequence Profile sequence is an ordered list of nodes Profile sequence is an ordered list of nodes Each node has four attributesEach node has four attributes
Label
Qid
Pos
Sym
D B A G E F E A
1 2 3 4 5 6 7 8
1 11 1 11 1 1
// / // $$ $// $#
Q1: /A[B//D]//E[G]/F LPS(Q1) = D B A G E F E A
Ancestor-DescendantParent-ChildBranch Branch + Ancestor-DescendantBranch + Root node
-9-
VLDB 2005, Trondheim, Norway
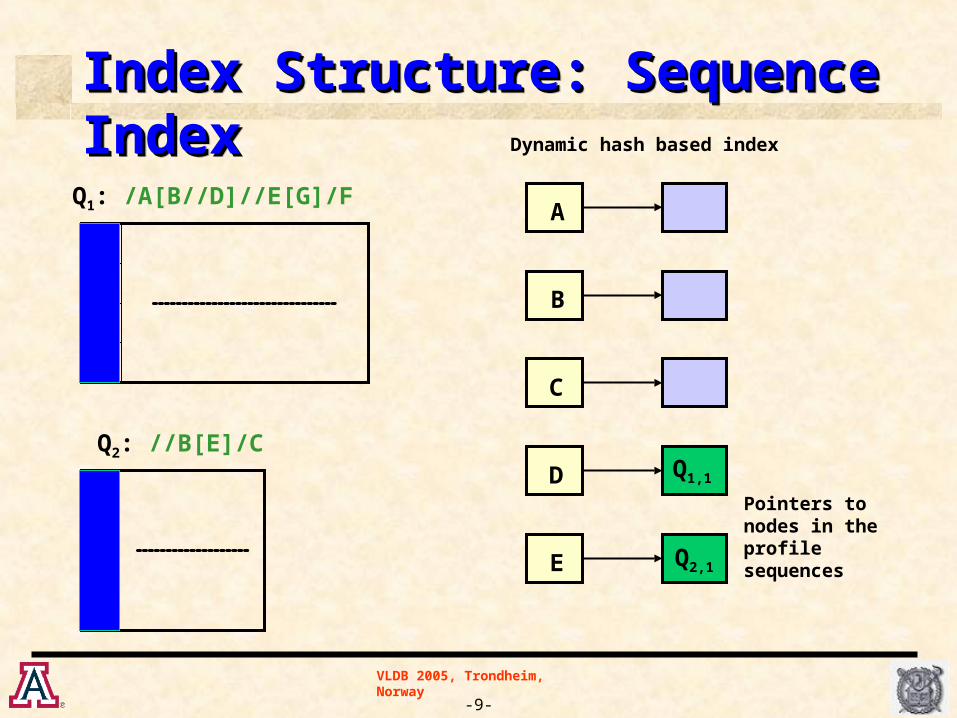
Index Structure: Sequence IndexIndex Structure: Sequence IndexIndex Structure: Sequence IndexIndex Structure: Sequence Index
B
A
C
D
E Q2,1
Q1,1
Q1: /A[B//D]//E[G]/F
Q2: //B[E]/C
1
1
//
D
E
2
1
/
Pointers to nodes in the profile sequences
Dynamic hash based index

-10-
VLDB 2005, Trondheim, Norway
Our Filtering AlgorithmOur Filtering AlgorithmOur Filtering AlgorithmOur Filtering Algorithm
• Progressive Subsequence MatchingProgressive Subsequence Matching PropertyProperty: If tree Q is a subtree of tree T, then LPS(Q) is a : If tree Q is a subtree of tree T, then LPS(Q) is a
subsequence of LPS(T) subsequence of LPS(T) • Praveen Rao and Bongki Moon.Praveen Rao and Bongki Moon. PRIX: Indexing and Querying XML PRIX: Indexing and Querying XML
using Prüfer sequencesusing Prüfer sequences ((ICDE’04)ICDE’04) Identify those profile sequences that have a matching subsequence Identify those profile sequences that have a matching subsequence
in the document sequencein the document sequence NecessaryNecessary but not a but not a sufficientsufficient condition condition
• Refinement for Branch Node VerificationRefinement for Branch Node Verification Progressive subsequence matching phase is followed by a refinement Progressive subsequence matching phase is followed by a refinement
phase to phase to discard false matchesdiscard false matches The connectivity of the branch nodes in the candidates (twig The connectivity of the branch nodes in the candidates (twig
patterns) is verifiedpatterns) is verified

-11-
VLDB 2005, Trondheim, Norway
Progressive Subsequence MatchingProgressive Subsequence MatchingProgressive Subsequence MatchingProgressive Subsequence Matching
• The sequence representation of the document can be The sequence representation of the document can be constructed as the document is parsed (e.g., SAX parser)constructed as the document is parsed (e.g., SAX parser)
• The subsequence matching phase is The subsequence matching phase is progressiveprogressive The sequence representation of the document is generated The sequence representation of the document is generated
incrementallyincrementally and the profile sequences (of twig patterns) that are and the profile sequences (of twig patterns) that are subsequences are identified in stepssubsequences are identified in steps
• Runtime global stack Runtime global stack The stack stores node labels from the current node of the document The stack stores node labels from the current node of the document
being processed to the rootbeing processed to the root Elements are pushed and popped from the stack in document Elements are pushed and popped from the stack in document
traversal ordertraversal order Stack size is upper bound by the depth of the documentStack size is upper bound by the depth of the document

-12-
VLDB 2005, Trondheim, Norway
Incremental Generation of LPSIncremental Generation of LPSIncremental Generation of LPSIncremental Generation of LPS
A
B B E
D E C G F F
D
B
LPS(T): DB EBA CBA GE FE FEA
Stack
A
DB
E
EBA CBA GE FE FEA
</D> leaf, o/p, pop, o/p
</E> leaf, o/p, pop, o/p
</B> non-leaf, pop, o/p
<A> push
<B> push
<D> push
<E> push
</A> non-leaf, pop

-13-
VLDB 2005, Trondheim, Norway
Progressive Subsequence MatchingProgressive Subsequence MatchingProgressive Subsequence MatchingProgressive Subsequence Matching
• Sequence Index is used to Sequence Index is used to simultaneouslysimultaneously find the matching find the matching profiles by parsing the document only onceprofiles by parsing the document only once
• The The Prüfer sequence labelPrüfer sequence label of the document is used as the of the document is used as the hash key in the Sequence Indexhash key in the Sequence Index
• Additional tasks are performed based on the Additional tasks are performed based on the SymSym attribute attribute value (value (e.g., ‘/’, ‘//’,e.g., ‘/’, ‘//’, ‘$’‘$’) in profile sequence nodes to eliminate ) in profile sequence nodes to eliminate most most false matchesfalse matches by using the runtime stack by using the runtime stack The remaining false matches are eventually removed during the The remaining false matches are eventually removed during the
refinement phaserefinement phase

-14-
VLDB 2005, Trondheim, Norway
Conceptual ViewConceptual ViewConceptual ViewConceptual View
• The matching process progresses by copying nodes in the The matching process progresses by copying nodes in the profile sequences into the profile sequences into the Sequence IndexSequence Index (denotes (denotes transitions in a state machine)transitions in a state machine)
A
C
D Q1,1
Sequence Index
B
G
Q1,2
Q1,3D B A G E F E A
1 2 3 4 5 6 7 8
1 11 1 11 1 1
// / // $$ $// $#
Profile Sequence of Q1
Last node - match

-15-
VLDB 2005, Trondheim, Norway
Progressive Subsequence MatchingProgressive Subsequence MatchingProgressive Subsequence MatchingProgressive Subsequence Matching
• Runtime stack contains a section of document LPS up to the Runtime stack contains a section of document LPS up to the nearest branch nodenearest branch node
A
BB
C C
D
E
E
D
C
B
A
XML document T
stack
LPS(T): …. E D C B A … C B A …

-16-
VLDB 2005, Trondheim, Norway
Progressive Subsequence MatchingProgressive Subsequence MatchingProgressive Subsequence MatchingProgressive Subsequence Matching
• Benefits of the runtime stackBenefits of the runtime stack Testing relationships during subsequence matching based on the Testing relationships during subsequence matching based on the
SymSym attribute attribute ‘/’‘/’ and and ‘//’‘//’. Let q and q. Let q and q’’ denote two consecutive nodes denote two consecutive nodes in the profile sequencein the profile sequence• TestPC(q,qTestPC(q,q’’)) - tests parent-child relationship - tests parent-child relationship (/)(/) between between qq’’ and and qq in the in the
documentdocument
• TestAD(q,qTestAD(q,q’’)) - tests ancestor-descendant relationship - tests ancestor-descendant relationship (//)(//) between between qq’’ and and q q in the documentin the document
Avoiding frequent node copys to the Sequence IndexAvoiding frequent node copys to the Sequence Index Limiting the range of subsequence matchingLimiting the range of subsequence matching

-17-
VLDB 2005, Trondheim, Norway
Testing Relationships between NodesTesting Relationships between NodesTesting Relationships between NodesTesting Relationships between Nodes
A
BB
C C
D
E
E
D
C
BA
E C FB
2 2 2 2
1 2 3 4
// / $ /
A
E
F
Q2,1
Twig pattern Q2XML document T
B
C
E
F
B
2
5
$#
Sequence Index
stack
Sym
Recursively testtill the nearest branch node without a ‘/’ or ‘//’
TestADTestPC

-18-
VLDB 2005, Trondheim, Norway
Avoiding Frequent Node CopysAvoiding Frequent Node CopysAvoiding Frequent Node CopysAvoiding Frequent Node Copys
A
BB
C C
D
E
E
D
C
BA
E C FB
2 2 2 2
1 2 3 4
// / $ /
A
E
F
Q2,1
Twig pattern Q2XML document T
B
C
E
F
B
2
5
$#
Sequence Index
A
E
F Q2,4
Q2,1
stack
Sym
Not copied

-19-
VLDB 2005, Trondheim, Norway
Limiting the Range of Subsequence MatchingLimiting the Range of Subsequence MatchingLimiting the Range of Subsequence MatchingLimiting the Range of Subsequence Matching
A
BB
C C
D
E
E
D
C
BA
XML document T
stack
E C FB
2 2 2 2
1 2 3 4
// / $ /
Twig pattern Q2
B
C
E
F
B
2
5
$#
LPS(T): … E D C B A … C B … LPS(Q2): E C B F B
C and E do not share an ancestor descendant relation
-20-
VLDB 2005, Trondheim, Norway
Refinement PhaseRefinement PhaseRefinement PhaseRefinement Phase
• The The connectednessconnectedness property of branch nodes in the property of branch nodes in the candidates (twig patterns) should be tested to identify true candidates (twig patterns) should be tested to identify true matchesmatches
• To enable the refinement process To enable the refinement process Branch node processing – branch nodes in the profile sequences Branch node processing – branch nodes in the profile sequences
during subsequence matchingduring subsequence matching
• The refinement phase The refinement phase Root node processing - last node in the profile sequenceRoot node processing - last node in the profile sequence Uses the information collected during branch node processingUses the information collected during branch node processing

-21-
VLDB 2005, Trondheim, Norway
Branch and Root Node ProcessingBranch and Root Node ProcessingBranch and Root Node ProcessingBranch and Root Node Processing
(A,1)
(B,2) (B,5) (E,7)
(D,3) (E,4) (C,6) (G,8) (F,9) (F,10)stack
B
E C
E B C B
Twig pattern Q3
XML document T
3 3 3 3
1 2 3 4
/ $ / $#
A
B
//B[E]/C
LPS(T): D B E B A C B A G E F E F E A LPS(Q3): E B C B
EC
Root node processing: The intersection of BranchID sets for each branch node in the candidate twig pattern is tested
52 BranchIDsets storenode ids

-22-
VLDB 2005, Trondheim, Norway
FiST: Architecture OverviewFiST: Architecture OverviewFiST: Architecture OverviewFiST: Architecture Overview
Sequence Index + Profile Sequences
Filtering Algorithm
SAX Parser
Send filtereddocument
XPath Twig Patterns(User Profiles) XML Document
Filtering Engine Users
XPath Parser
Sequence Transformation

-23-
VLDB 2005, Trondheim, Norway
Experimental ResultsExperimental ResultsExperimental ResultsExperimental Results
• We measured the performance of FiST and YFilter for a We measured the performance of FiST and YFilter for a variety of XML document sizes and twig patterns.variety of XML document sizes and twig patterns.
• Experimental setupExperimental setup 2.4 GHz Pentium IV with 512 MB RAM running Linux2.4 GHz Pentium IV with 512 MB RAM running Linux
• DatasetsDatasets Synthetic Treebank data using IBM’s XML data generatorSynthetic Treebank data using IBM’s XML data generator 1000 documents were generated using Treebank DTD1000 documents were generated using Treebank DTD Recursion of elements, maximum document depth was 36Recursion of elements, maximum document depth was 36 Dataset sizes Dataset sizes
• [1KB, 10KB) – [1KB, 10KB) – 1k1k• [10KB, 20KB) – [10KB, 20KB) – 10k10k• [20KB, 30KB) – [20KB, 30KB) – 20k20k• [30KB, 123KB) – [30KB, 123KB) – 30k30k

-24-
VLDB 2005, Trondheim, Norway
Experimental ResultsExperimental ResultsExperimental ResultsExperimental Results
• User profiles (twig patterns) were generated using the User profiles (twig patterns) were generated using the XPath Generator in YFilterXPath Generator in YFilter Uniform – Uniform – (z = 0)(z = 0) Skewed – Skewed – (z = 0.9)(z = 0.9) Maximum depth – Maximum depth – 1010 # of branches –# of branches – 3 to 7 3 to 7 # of twig patterns –# of twig patterns – 50000 to 150000 50000 to 150000
• For each twig set and document set, we measured the For each twig set and document set, we measured the average filtering cost average filtering cost per documentper document filtering time + document parsing timefiltering time + document parsing time

-25-
VLDB 2005, Trondheim, Norway
Experimental ResultsExperimental ResultsExperimental ResultsExperimental Results
• We compared YFilter and FiST by observing the trends in We compared YFilter and FiST by observing the trends in filtering cost for three different filtering cost for three different aspects of scalabilityaspects of scalability
# of twig patterns # of branches
size of input documents

-26-
VLDB 2005, Trondheim, Norway
Experimental ResultsExperimental ResultsExperimental ResultsExperimental Results
• FiST was implemented in C++ and YFilter was developed in JavaFiST was implemented in C++ and YFilter was developed in Java
• For fairness of comparison, we chose the following For fairness of comparison, we chose the following evaluation metricevaluation metric
scaleup =scaleup =
• Wall clock time (Wall clock time (document parsing + filteringdocument parsing + filtering))
• We observed that FiST scaled better than YFilter under various We observed that FiST scaled better than YFilter under various situationssituations FiST’s filtering cost decreased with decrease in the number of matching FiST’s filtering cost decreased with decrease in the number of matching
user profilesuser profiles YFilter’s filtering cost increased as the size of the twig patterns increasedYFilter’s filtering cost increased as the size of the twig patterns increased
(observed – base)
base

-27-
VLDB 2005, Trondheim, Norway
Varying XML Document SizesVarying XML Document SizesVarying XML Document SizesVarying XML Document Sizes
• We measured the We measured the scaleupscaleup for FiST and YFilter for FiST and YFilter
• FiST’s filtering cost grew slower than YFilterFiST’s filtering cost grew slower than YFilter
uniform skewed
-28-
VLDB 2005, Trondheim, Norway
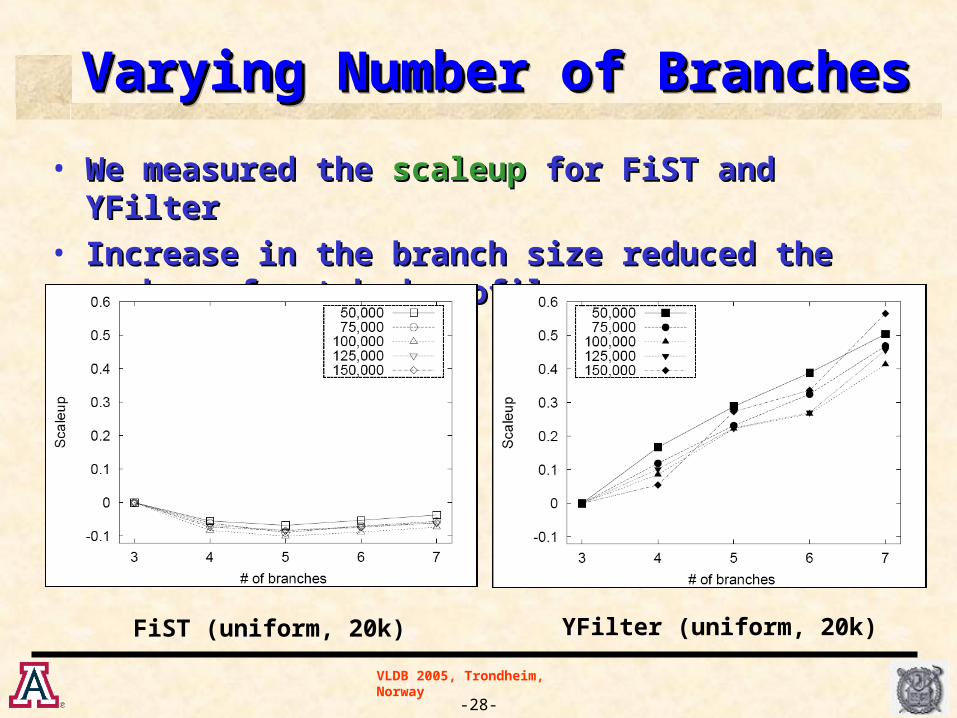
Varying Number of BranchesVarying Number of BranchesVarying Number of BranchesVarying Number of Branches
• We measured the We measured the scaleup scaleup for FiST and YFilterfor FiST and YFilter
• Increase in the branch size reduced the number of matched Increase in the branch size reduced the number of matched profilesprofiles
FiST (uniform, 20k) YFilter (uniform, 20k)
-29-
VLDB 2005, Trondheim, Norway
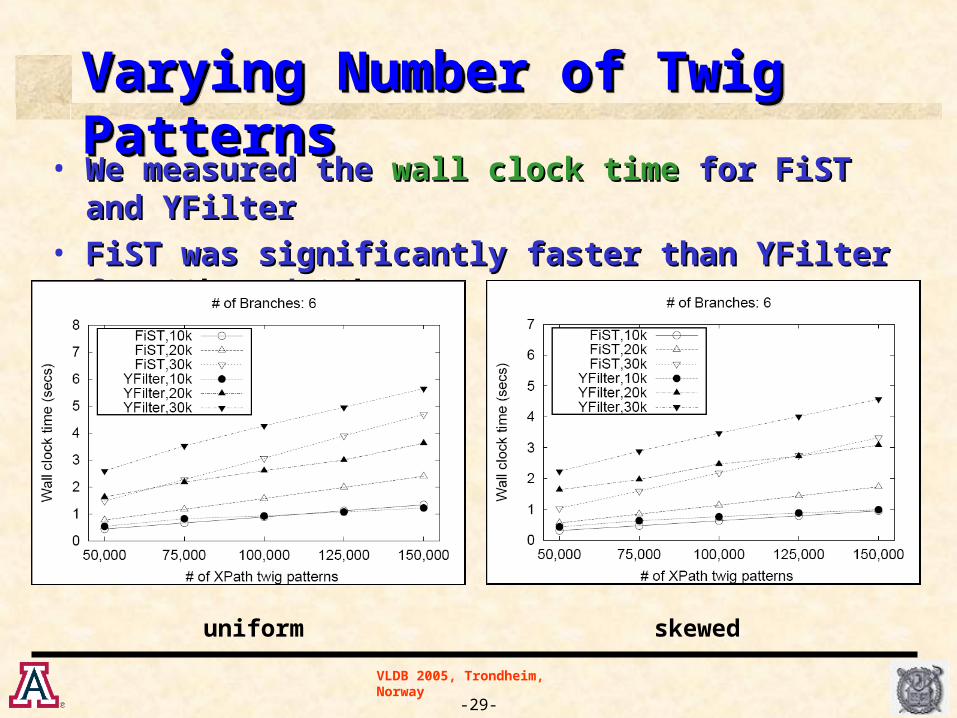
Varying Number of Twig PatternsVarying Number of Twig PatternsVarying Number of Twig PatternsVarying Number of Twig Patterns
• We measured the We measured the wall clock time wall clock time for FiST and YFilterfor FiST and YFilter
• FiST was significantly faster than YFilter for FiST was significantly faster than YFilter for 20k 20k andand 30k 30k
uniform skewed

-30-
VLDB 2005, Trondheim, Norway
ConclusionsConclusionsConclusionsConclusions
• We have developed an XML filtering system called FiST We have developed an XML filtering system called FiST that supports holistic matching of twig patterns that supports holistic matching of twig patterns Avoids first matching the linear paths in the twigs and then merging Avoids first matching the linear paths in the twigs and then merging
the matches during post-processingthe matches during post-processing Transform twig patterns into profile sequencesTransform twig patterns into profile sequences
• Inherent support for Inherent support for ordered matchingordered matching of twig patterns of twig patterns
• Runtime stackRuntime stack Stack size is upper bound by the depth of the documentStack size is upper bound by the depth of the document
• Holistic matching yielded good scalability for our filtering Holistic matching yielded good scalability for our filtering system under various situationssystem under various situations
-31-
VLDB 2005, Trondheim, Norway
Questions?Questions?Questions?Questions?
For more information,For more information,
www.cs.arizona.edu/~bkmoonwww.cs.arizona.edu/~bkmoon