finding relevant tweets in social media
TRANSCRIPT

Separating the Wheat from the ChaffFinding Relevant Tweets in Social Media Streams
Na’im Tyson, PhD
Sciences, About.com
April 20, 2017
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 1 / 23
1 Introduction
2 Ingesting Text Data
3 Document Preprocessing
4 Process Steps
5 Tokenization
6 Vectorization
7 Clustering
8 Model Diagnostics
9 Roads Not Taken
10 References
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 2 / 23
1 Introduction
2 Ingesting Text Data
3 Document Preprocessing
4 Process Steps
5 Tokenization
6 Vectorization
7 Clustering
8 Model Diagnostics
9 Roads Not Taken
10 References
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 2 / 23
1 Introduction
2 Ingesting Text Data
3 Document Preprocessing
4 Process Steps
5 Tokenization
6 Vectorization
7 Clustering
8 Model Diagnostics
9 Roads Not Taken
10 References
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 2 / 23
1 Introduction
2 Ingesting Text Data
3 Document Preprocessing
4 Process Steps
5 Tokenization
6 Vectorization
7 Clustering
8 Model Diagnostics
9 Roads Not Taken
10 References
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 2 / 23
1 Introduction
2 Ingesting Text Data
3 Document Preprocessing
4 Process Steps
5 Tokenization
6 Vectorization
7 Clustering
8 Model Diagnostics
9 Roads Not Taken
10 References
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 2 / 23

1 Introduction
2 Ingesting Text Data
3 Document Preprocessing
4 Process Steps
5 Tokenization
6 Vectorization
7 Clustering
8 Model Diagnostics
9 Roads Not Taken
10 References
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 2 / 23

1 Introduction
2 Ingesting Text Data
3 Document Preprocessing
4 Process Steps
5 Tokenization
6 Vectorization
7 Clustering
8 Model Diagnostics
9 Roads Not Taken
10 References
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 2 / 23
1 Introduction
2 Ingesting Text Data
3 Document Preprocessing
4 Process Steps
5 Tokenization
6 Vectorization
7 Clustering
8 Model Diagnostics
9 Roads Not Taken
10 References
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 2 / 23
1 Introduction
2 Ingesting Text Data
3 Document Preprocessing
4 Process Steps
5 Tokenization
6 Vectorization
7 Clustering
8 Model Diagnostics
9 Roads Not Taken
10 References
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 2 / 23
1 Introduction
2 Ingesting Text Data
3 Document Preprocessing
4 Process Steps
5 Tokenization
6 Vectorization
7 Clustering
8 Model Diagnostics
9 Roads Not Taken
10 ReferencesTyson (About.com) Finding Relevance in Tweets April 20, 2017 2 / 23

Introduction Consultant Role
Your Role as Consultant. . .
• Advise on open source and proprietary analytical solutions for small- tomedium-sized businesses
• Build solutions to solve business goals using Open Source Software(whenever possible)
• Develop systems to monitor solutions over time (when requested) OR
• Develop diagnostics to monitor model behaviour
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 3 / 23

Introduction Consultant Role
Your Role as Consultant. . .
• Advise on open source and proprietary analytical solutions for small- tomedium-sized businesses
• Build solutions to solve business goals using Open Source Software(whenever possible)
• Develop systems to monitor solutions over time (when requested) OR
• Develop diagnostics to monitor model behaviour
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 3 / 23
Introduction Consultant Role
Your Role as Consultant. . .
• Advise on open source and proprietary analytical solutions for small- tomedium-sized businesses
• Build solutions to solve business goals using Open Source Software(whenever possible)
• Develop systems to monitor solutions over time (when requested) OR
• Develop diagnostics to monitor model behaviour
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 3 / 23

Introduction Consultant Role
Your Role as Consultant. . .
• Advise on open source and proprietary analytical solutions for small- tomedium-sized businesses
• Build solutions to solve business goals using Open Source Software(whenever possible)
• Develop systems to monitor solutions over time (when requested) OR
• Develop diagnostics to monitor model behaviour
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 3 / 23
Introduction Client Description
Brand Intelligence Firm
• Boutique Social Monitoring & Analysis Firm
• Provide quantitative summaries from qualitative data (tweets, facebookposts, web pages, etc.)
• Analytics Dashboards
• How do they acquire data?
• Data Collector/Aggregation Services• Collect social data from multiple APIs• Saves engineering resources
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 4 / 23
Introduction Client Description
Brand Intelligence Firm
• Boutique Social Monitoring & Analysis Firm
• Provide quantitative summaries from qualitative data (tweets, facebookposts, web pages, etc.)
• Analytics Dashboards
• How do they acquire data?
• Data Collector/Aggregation Services• Collect social data from multiple APIs• Saves engineering resources
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 4 / 23
Introduction Client Description
Brand Intelligence Firm
• Boutique Social Monitoring & Analysis Firm
• Provide quantitative summaries from qualitative data (tweets, facebookposts, web pages, etc.)
• Analytics Dashboards
• How do they acquire data?
• Data Collector/Aggregation Services• Collect social data from multiple APIs• Saves engineering resources
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 4 / 23
Introduction Client Description
Brand Intelligence Firm
• Boutique Social Monitoring & Analysis Firm
• Provide quantitative summaries from qualitative data (tweets, facebookposts, web pages, etc.)
• Analytics Dashboards
• How do they acquire data?
• Data Collector/Aggregation Services• Collect social data from multiple APIs• Saves engineering resources
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 4 / 23
Introduction Client Description
Brand Intelligence Firm
• Boutique Social Monitoring & Analysis Firm
• Provide quantitative summaries from qualitative data (tweets, facebookposts, web pages, etc.)
• Analytics Dashboards
• How do they acquire data?
• Data Collector/Aggregation Services• Collect social data from multiple APIs• Saves engineering resources
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 4 / 23
Introduction Project Scope
Business Problem
Imagine: One batch of data - tweets
Relevance: How do you know which ones are relevant to the brand?
Labeling: Would Turkers make good labelers for marking tweets as relevant?
Cost: How many tweets will they label for creating amodel?
Scalability: Labeling thousands or hundreds of thousands oftweets
Consistency: How do you know whether they are consistentlabelers?
• Implementation of consistency labelingstatistics
Goal: Establish a system for programmatically computing relevance of tweets
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 5 / 23
Introduction Project Scope
Business Problem
Imagine: One batch of data - tweets
Relevance: How do you know which ones are relevant to the brand?
Labeling: Would Turkers make good labelers for marking tweets as relevant?
Cost: How many tweets will they label for creating amodel?
Scalability: Labeling thousands or hundreds of thousands oftweets
Consistency: How do you know whether they are consistentlabelers?
• Implementation of consistency labelingstatistics
Goal: Establish a system for programmatically computing relevance of tweets
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 5 / 23
Introduction Project Scope
Business Problem
Imagine: One batch of data - tweets
Relevance: How do you know which ones are relevant to the brand?
Labeling: Would Turkers make good labelers for marking tweets as relevant?
Cost: How many tweets will they label for creating amodel?
Scalability: Labeling thousands or hundreds of thousands oftweets
Consistency: How do you know whether they are consistentlabelers?
• Implementation of consistency labelingstatistics
Goal: Establish a system for programmatically computing relevance of tweets
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 5 / 23
Introduction Project Scope
Business Problem
Imagine: One batch of data - tweets
Relevance: How do you know which ones are relevant to the brand?
Labeling: Would Turkers make good labelers for marking tweets as relevant?
Cost: How many tweets will they label for creating amodel?
Scalability: Labeling thousands or hundreds of thousands oftweets
Consistency: How do you know whether they are consistentlabelers?
• Implementation of consistency labelingstatistics
Goal: Establish a system for programmatically computing relevance of tweets
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 5 / 23
Introduction Project Scope
Business Problem
Imagine: One batch of data - tweets
Relevance: How do you know which ones are relevant to the brand?
Labeling: Would Turkers make good labelers for marking tweets as relevant?
Cost: How many tweets will they label for creating amodel?
Scalability: Labeling thousands or hundreds of thousands oftweets
Consistency: How do you know whether they are consistentlabelers?
• Implementation of consistency labelingstatistics
Goal: Establish a system for programmatically computing relevance of tweets
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 5 / 23
Introduction Project Scope
Business Problem
Imagine: One batch of data - tweets
Relevance: How do you know which ones are relevant to the brand?
Labeling: Would Turkers make good labelers for marking tweets as relevant?
Cost: How many tweets will they label for creating amodel?
Scalability: Labeling thousands or hundreds of thousands oftweets
Consistency: How do you know whether they are consistentlabelers?
• Implementation of consistency labelingstatistics
Goal: Establish a system for programmatically computing relevance of tweets
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 5 / 23

Introduction Project Scope
Business Problem
Imagine: One batch of data - tweets
Relevance: How do you know which ones are relevant to the brand?
Labeling: Would Turkers make good labelers for marking tweets as relevant?
Cost: How many tweets will they label for creating amodel?
Scalability: Labeling thousands or hundreds of thousands oftweets
Consistency: How do you know whether they are consistentlabelers?
• Implementation of consistency labelingstatistics
Goal: Establish a system for programmatically computing relevance of tweets
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 5 / 23

Introduction Project Scope
Business Problem
Imagine: One batch of data - tweets
Relevance: How do you know which ones are relevant to the brand?
Labeling: Would Turkers make good labelers for marking tweets as relevant?
Cost: How many tweets will they label for creating amodel?
Scalability: Labeling thousands or hundreds of thousands oftweets
Consistency: How do you know whether they are consistentlabelers?
• Implementation of consistency labelingstatistics
Goal: Establish a system for programmatically computing relevance of tweets
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 5 / 23

Ingesting Text Data Scraping & Crawling
Most of the methods in this section—except the last two—came from[Bengfort (2016)]
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 6 / 23

Ingesting Text Data Scraping & Crawling
Two Sides of the Same Coin?
• Scraping (from a web page) is an information extraction task
• Text content, publish data, page links or any other goodies
• Crawling is an information processing task
• Traversal of a website’s link network by crawler or spider• Find out what you can crawl before you start crawling!
• Type into Google search: <DOMAIN NAME> robots.txt
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 7 / 23

Ingesting Text Data Scraping & Crawling
Two Sides of the Same Coin?
• Scraping (from a web page) is an information extraction task
• Text content, publish data, page links or any other goodies
• Crawling is an information processing task
• Traversal of a website’s link network by crawler or spider• Find out what you can crawl before you start crawling!
• Type into Google search: <DOMAIN NAME> robots.txt
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 7 / 23

Ingesting Text Data Scraping & Crawling
Two Sides of the Same Coin?
• Scraping (from a web page) is an information extraction task
• Text content, publish data, page links or any other goodies
• Crawling is an information processing task
• Traversal of a website’s link network by crawler or spider• Find out what you can crawl before you start crawling!
• Type into Google search: <DOMAIN NAME> robots.txt
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 7 / 23

Ingesting Text Data Scraping & Crawling
Two Sides of the Same Coin?
• Scraping (from a web page) is an information extraction task
• Text content, publish data, page links or any other goodies
• Crawling is an information processing task
• Traversal of a website’s link network by crawler or spider
• Find out what you can crawl before you start crawling!• Type into Google search: <DOMAIN NAME> robots.txt
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 7 / 23

Ingesting Text Data Scraping & Crawling
Two Sides of the Same Coin?
• Scraping (from a web page) is an information extraction task
• Text content, publish data, page links or any other goodies
• Crawling is an information processing task
• Traversal of a website’s link network by crawler or spider• Find out what you can crawl before you start crawling!
• Type into Google search: <DOMAIN NAME> robots.txt
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 7 / 23

Ingesting Text Data Scraping & Crawling
Two Sides of the Same Coin?
• Scraping (from a web page) is an information extraction task
• Text content, publish data, page links or any other goodies
• Crawling is an information processing task
• Traversal of a website’s link network by crawler or spider• Find out what you can crawl before you start crawling!
• Type into Google search: <DOMAIN NAME> robots.txt
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 7 / 23
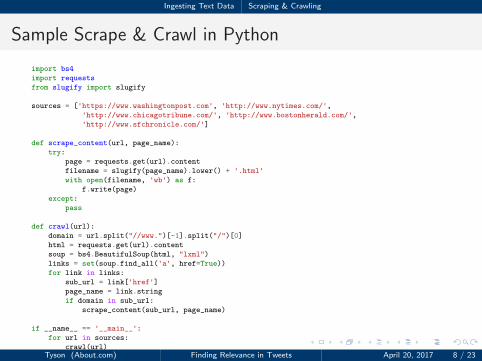
Ingesting Text Data Scraping & Crawling
Sample Scrape & Crawl in Python
1 import bs4
2 import requests
3 from slugify import slugify
45 sources = ['https://www.washingtonpost.com', 'http://www.nytimes.com/',
6 'http://www.chicagotribune.com/', 'http://www.bostonherald.com/',
7 'http://www.sfchronicle.com/']
89 def scrape_content(url, page_name):
10 try:
11 page = requests.get(url).content
12 filename = slugify(page_name).lower() + '.html'
13 with open(filename, 'wb') as f:
14 f.write(page)
15 except:
16 pass
1718 def crawl(url):
19 domain = url.split("//www.")[-1].split("/")[0]
20 html = requests.get(url).content
21 soup = bs4.BeautifulSoup(html, "lxml")
22 links = set(soup.find_all('a', href=True))
23 for link in links:
24 sub_url = link['href']
25 page_name = link.string
26 if domain in sub_url:
27 scrape_content(sub_url, page_name)
2829 if __name__ == '__main__':
30 for url in sources:
31 crawl(url)Tyson (About.com) Finding Relevance in Tweets April 20, 2017 8 / 23
Ingesting Text Data RSS Reading
• RSS = Real Simple Syndication
• Standardized XML format for syndicated text content
1 import bs4
2 import feedparser
3 from slugify import slugify
45 feeds = ['http://blog.districtdatalabs.com/feed',
6 'http://feeds.feedburner.com/oreilly/radar/atom',
7 'http://blog.revolutionanalytics.com/atom.xml']
89 def rss_parse(feed):
10 parsed = feedparser.parse(feed)
11 posts = parsed.entries
12 for post in posts:
13 html = post.content[0].get('value')
14 soup = bs4.BeautifulSoup(html, 'lxml')
15 post_title = post.title
16 filename = slugify(post_title).lower() + '.xml'
17 TAGS = ['h1', 'h2', 'h3', 'h4', 'h5', 'h6', 'h7', 'p', 'li']
18 for tag in soup.find_all(TAGS):
19 paragraphs = tag.get_text()
20 with open(filename, 'a') as f:
21 f.write(paragraphs + '\n \n')
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 9 / 23

Ingesting Text Data RSS Reading
• RSS = Real Simple Syndication
• Standardized XML format for syndicated text content
1 import bs4
2 import feedparser
3 from slugify import slugify
45 feeds = ['http://blog.districtdatalabs.com/feed',
6 'http://feeds.feedburner.com/oreilly/radar/atom',
7 'http://blog.revolutionanalytics.com/atom.xml']
89 def rss_parse(feed):
10 parsed = feedparser.parse(feed)
11 posts = parsed.entries
12 for post in posts:
13 html = post.content[0].get('value')
14 soup = bs4.BeautifulSoup(html, 'lxml')
15 post_title = post.title
16 filename = slugify(post_title).lower() + '.xml'
17 TAGS = ['h1', 'h2', 'h3', 'h4', 'h5', 'h6', 'h7', 'p', 'li']
18 for tag in soup.find_all(TAGS):
19 paragraphs = tag.get_text()
20 with open(filename, 'a') as f:
21 f.write(paragraphs + '\n \n')
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 9 / 23
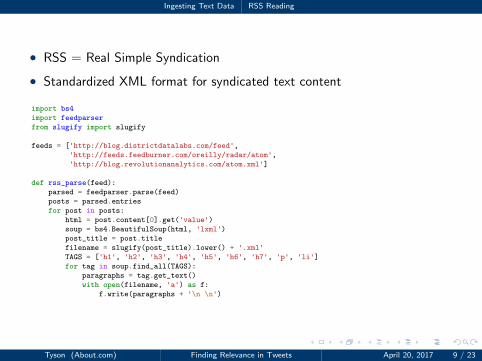
Ingesting Text Data RSS Reading
• RSS = Real Simple Syndication
• Standardized XML format for syndicated text content
1 import bs4
2 import feedparser
3 from slugify import slugify
45 feeds = ['http://blog.districtdatalabs.com/feed',
6 'http://feeds.feedburner.com/oreilly/radar/atom',
7 'http://blog.revolutionanalytics.com/atom.xml']
89 def rss_parse(feed):
10 parsed = feedparser.parse(feed)
11 posts = parsed.entries
12 for post in posts:
13 html = post.content[0].get('value')
14 soup = bs4.BeautifulSoup(html, 'lxml')
15 post_title = post.title
16 filename = slugify(post_title).lower() + '.xml'
17 TAGS = ['h1', 'h2', 'h3', 'h4', 'h5', 'h6', 'h7', 'p', 'li']
18 for tag in soup.find_all(TAGS):
19 paragraphs = tag.get_text()
20 with open(filename, 'a') as f:
21 f.write(paragraphs + '\n \n')
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 9 / 23
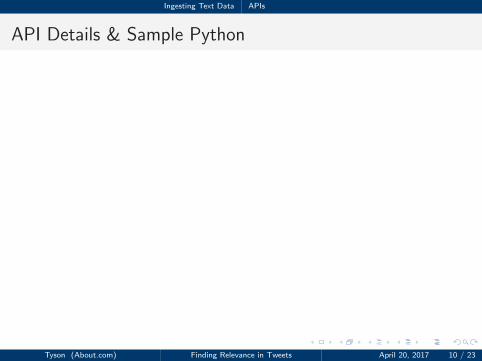
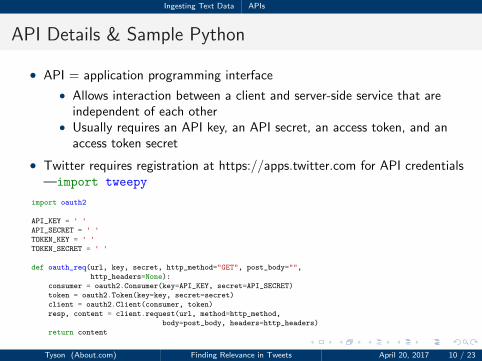
Ingesting Text Data APIs
API Details & Sample Python
• API = application programming interface
• Allows interaction between a client and server-side service that areindependent of each other
• Usually requires an API key, an API secret, an access token, and anaccess token secret
• Twitter requires registration at https://apps.twitter.com for API credentials—import tweepy
1 import oauth2
23 API_KEY = ' '
4 API_SECRET = ' '
5 TOKEN_KEY = ' '
6 TOKEN_SECRET = ' '
78 def oauth_req(url, key, secret, http_method="GET", post_body="",
9 http_headers=None):
10 consumer = oauth2.Consumer(key=API_KEY, secret=API_SECRET)
11 token = oauth2.Token(key=key, secret=secret)
12 client = oauth2.Client(consumer, token)
13 resp, content = client.request(url, method=http_method,
14 body=post_body, headers=http_headers)
15 return content
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 10 / 23

Ingesting Text Data APIs
API Details & Sample Python
• API = application programming interface
• Allows interaction between a client and server-side service that areindependent of each other
• Usually requires an API key, an API secret, an access token, and anaccess token secret
• Twitter requires registration at https://apps.twitter.com for API credentials—import tweepy
1 import oauth2
23 API_KEY = ' '
4 API_SECRET = ' '
5 TOKEN_KEY = ' '
6 TOKEN_SECRET = ' '
78 def oauth_req(url, key, secret, http_method="GET", post_body="",
9 http_headers=None):
10 consumer = oauth2.Consumer(key=API_KEY, secret=API_SECRET)
11 token = oauth2.Token(key=key, secret=secret)
12 client = oauth2.Client(consumer, token)
13 resp, content = client.request(url, method=http_method,
14 body=post_body, headers=http_headers)
15 return content
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 10 / 23

Ingesting Text Data APIs
API Details & Sample Python
• API = application programming interface
• Allows interaction between a client and server-side service that areindependent of each other
• Usually requires an API key, an API secret, an access token, and anaccess token secret
• Twitter requires registration at https://apps.twitter.com for API credentials—import tweepy
1 import oauth2
23 API_KEY = ' '
4 API_SECRET = ' '
5 TOKEN_KEY = ' '
6 TOKEN_SECRET = ' '
78 def oauth_req(url, key, secret, http_method="GET", post_body="",
9 http_headers=None):
10 consumer = oauth2.Consumer(key=API_KEY, secret=API_SECRET)
11 token = oauth2.Token(key=key, secret=secret)
12 client = oauth2.Client(consumer, token)
13 resp, content = client.request(url, method=http_method,
14 body=post_body, headers=http_headers)
15 return content
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 10 / 23

Ingesting Text Data APIs
API Details & Sample Python
• API = application programming interface
• Allows interaction between a client and server-side service that areindependent of each other
• Usually requires an API key, an API secret, an access token, and anaccess token secret
• Twitter requires registration at https://apps.twitter.com for API credentials—import tweepy
1 import oauth2
23 API_KEY = ' '
4 API_SECRET = ' '
5 TOKEN_KEY = ' '
6 TOKEN_SECRET = ' '
78 def oauth_req(url, key, secret, http_method="GET", post_body="",
9 http_headers=None):
10 consumer = oauth2.Consumer(key=API_KEY, secret=API_SECRET)
11 token = oauth2.Token(key=key, secret=secret)
12 client = oauth2.Client(consumer, token)
13 resp, content = client.request(url, method=http_method,
14 body=post_body, headers=http_headers)
15 return content
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 10 / 23
Ingesting Text Data APIs
API Details & Sample Python
• API = application programming interface
• Allows interaction between a client and server-side service that areindependent of each other
• Usually requires an API key, an API secret, an access token, and anaccess token secret
• Twitter requires registration at https://apps.twitter.com for API credentials—import tweepy
1 import oauth2
23 API_KEY = ' '
4 API_SECRET = ' '
5 TOKEN_KEY = ' '
6 TOKEN_SECRET = ' '
78 def oauth_req(url, key, secret, http_method="GET", post_body="",
9 http_headers=None):
10 consumer = oauth2.Consumer(key=API_KEY, secret=API_SECRET)
11 token = oauth2.Token(key=key, secret=secret)
12 client = oauth2.Client(consumer, token)
13 resp, content = client.request(url, method=http_method,
14 body=post_body, headers=http_headers)
15 return content
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 10 / 23
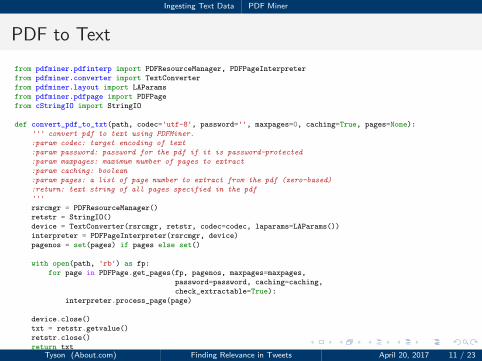
Ingesting Text Data PDF Miner
PDF to Text
1 from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
2 from pdfminer.converter import TextConverter
3 from pdfminer.layout import LAParams
4 from pdfminer.pdfpage import PDFPage
5 from cStringIO import StringIO
67 def convert_pdf_to_txt(path, codec='utf-8', password='', maxpages=0, caching=True, pages=None):
8 ''' convert pdf to text using PDFMiner.
9 :param codec: target encoding of text
10 :param password: password for the pdf if it is password-protected
11 :param maxpages: maximum number of pages to extract
12 :param caching: boolean
13 :param pages: a list of page number to extract from the pdf (zero-based)
14 :return: text string of all pages specified in the pdf
15 '''
16 rsrcmgr = PDFResourceManager()
17 retstr = StringIO()
18 device = TextConverter(rsrcmgr, retstr, codec=codec, laparams=LAParams())
19 interpreter = PDFPageInterpreter(rsrcmgr, device)
20 pagenos = set(pages) if pages else set()
2122 with open(path, 'rb') as fp:
23 for page in PDFPage.get_pages(fp, pagenos, maxpages=maxpages,
24 password=password, caching=caching,
25 check_extractable=True):
26 interpreter.process_page(page)
2728 device.close()
29 txt = retstr.getvalue()
30 retstr.close()
31 return txtTyson (About.com) Finding Relevance in Tweets April 20, 2017 11 / 23
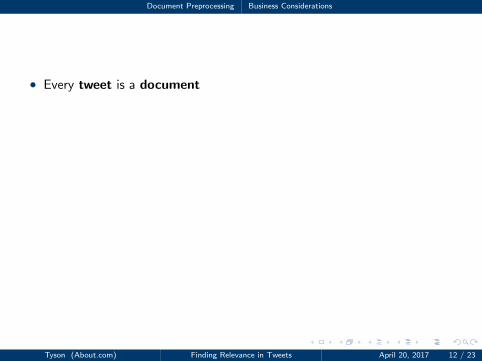
Document Preprocessing Business Considerations
• Every tweet is a document
• Reject retweets
• Ignore (toss) hypertext links
• Why might this be a bad idea?• Hint: can links tell you about relevant tweets?
RT @chriswheeldon2: #pinchmeplease so honored. #Beginnersluck Congrats to all at @AmericanInParis for Best Musical win. @robbiefairchild y
------------------------------------------------------------
RT @VanKaplan: .@AmericanInParis won Best Musical @ Outer Critics Awards! http://t.co/3y9Xem0c9I @PittsburghCLO
------------------------------------------------------------
RT @cope_leanne: Congratulations @AmericanInParis @chriswheeldon2 @robbiefairchild 4 outer Critic Circle wins . So proud .
------------------------------------------------------------
.@robbiefairchild @chriswheeldon2 Congrats on Outer Critics Circle Awards for your brilliant work in @AmericanInParis !!!
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 12 / 23
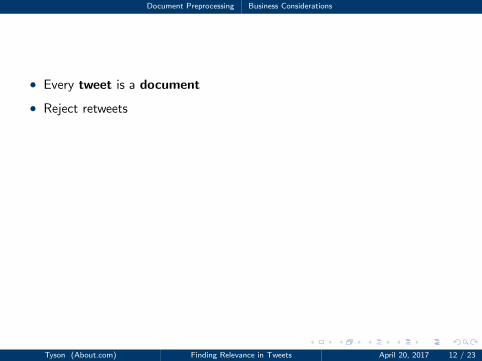
Document Preprocessing Business Considerations
• Every tweet is a document
• Reject retweets
• Ignore (toss) hypertext links
• Why might this be a bad idea?• Hint: can links tell you about relevant tweets?
RT @chriswheeldon2: #pinchmeplease so honored. #Beginnersluck Congrats to all at @AmericanInParis for Best Musical win. @robbiefairchild y
------------------------------------------------------------
RT @VanKaplan: .@AmericanInParis won Best Musical @ Outer Critics Awards! http://t.co/3y9Xem0c9I @PittsburghCLO
------------------------------------------------------------
RT @cope_leanne: Congratulations @AmericanInParis @chriswheeldon2 @robbiefairchild 4 outer Critic Circle wins . So proud .
------------------------------------------------------------
.@robbiefairchild @chriswheeldon2 Congrats on Outer Critics Circle Awards for your brilliant work in @AmericanInParis !!!
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 12 / 23
Document Preprocessing Business Considerations
• Every tweet is a document
• Reject retweets
• Ignore (toss) hypertext links
• Why might this be a bad idea?• Hint: can links tell you about relevant tweets?
RT @chriswheeldon2: #pinchmeplease so honored. #Beginnersluck Congrats to all at @AmericanInParis for Best Musical win. @robbiefairchild y
------------------------------------------------------------
RT @VanKaplan: .@AmericanInParis won Best Musical @ Outer Critics Awards! http://t.co/3y9Xem0c9I @PittsburghCLO
------------------------------------------------------------
RT @cope_leanne: Congratulations @AmericanInParis @chriswheeldon2 @robbiefairchild 4 outer Critic Circle wins . So proud .
------------------------------------------------------------
.@robbiefairchild @chriswheeldon2 Congrats on Outer Critics Circle Awards for your brilliant work in @AmericanInParis !!!
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 12 / 23
Document Preprocessing Business Considerations
• Every tweet is a document
• Reject retweets
• Ignore (toss) hypertext links
• Why might this be a bad idea?
• Hint: can links tell you about relevant tweets?
RT @chriswheeldon2: #pinchmeplease so honored. #Beginnersluck Congrats to all at @AmericanInParis for Best Musical win. @robbiefairchild y
------------------------------------------------------------
RT @VanKaplan: .@AmericanInParis won Best Musical @ Outer Critics Awards! http://t.co/3y9Xem0c9I @PittsburghCLO
------------------------------------------------------------
RT @cope_leanne: Congratulations @AmericanInParis @chriswheeldon2 @robbiefairchild 4 outer Critic Circle wins . So proud .
------------------------------------------------------------
.@robbiefairchild @chriswheeldon2 Congrats on Outer Critics Circle Awards for your brilliant work in @AmericanInParis !!!
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 12 / 23

Document Preprocessing Business Considerations
• Every tweet is a document
• Reject retweets
• Ignore (toss) hypertext links
• Why might this be a bad idea?• Hint: can links tell you about relevant tweets?
RT @chriswheeldon2: #pinchmeplease so honored. #Beginnersluck Congrats to all at @AmericanInParis for Best Musical win. @robbiefairchild y
------------------------------------------------------------
RT @VanKaplan: .@AmericanInParis won Best Musical @ Outer Critics Awards! http://t.co/3y9Xem0c9I @PittsburghCLO
------------------------------------------------------------
RT @cope_leanne: Congratulations @AmericanInParis @chriswheeldon2 @robbiefairchild 4 outer Critic Circle wins . So proud .
------------------------------------------------------------
.@robbiefairchild @chriswheeldon2 Congrats on Outer Critics Circle Awards for your brilliant work in @AmericanInParis !!!
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 12 / 23

Document Preprocessing Business Considerations
• Every tweet is a document
• Reject retweets
• Ignore (toss) hypertext links
• Why might this be a bad idea?• Hint: can links tell you about relevant tweets?
RT @chriswheeldon2: #pinchmeplease so honored. #Beginnersluck Congrats to all at @AmericanInParis for Best Musical win. @robbiefairchild y
------------------------------------------------------------
RT @VanKaplan: .@AmericanInParis won Best Musical @ Outer Critics Awards! http://t.co/3y9Xem0c9I @PittsburghCLO
------------------------------------------------------------
RT @cope_leanne: Congratulations @AmericanInParis @chriswheeldon2 @robbiefairchild 4 outer Critic Circle wins . So proud .
------------------------------------------------------------
.@robbiefairchild @chriswheeldon2 Congrats on Outer Critics Circle Awards for your brilliant work in @AmericanInParis !!!
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 12 / 23
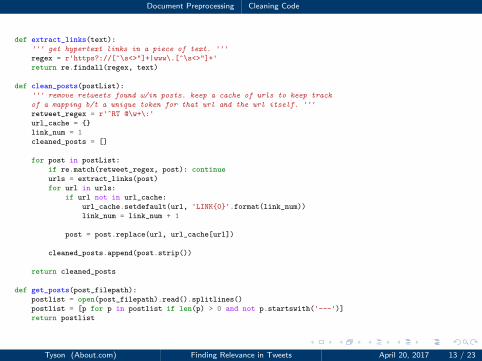
Document Preprocessing Cleaning Code
1 def extract_links(text):
2 ''' get hypertext links in a piece of text. '''
3 regex = r'https?://[^\s<>"]+|www\.[^\s<>"]+'
4 return re.findall(regex, text)
56 def clean_posts(postList):
7 ''' remove retweets found w/in posts. keep a cache of urls to keep track
8 of a mapping b/t a unique token for that url and the url itself. '''
9 retweet_regex = r'^RT @\w+\:'
10 url_cache = {}
11 link_num = 1
12 cleaned_posts = []
1314 for post in postList:
15 if re.match(retweet_regex, post): continue
16 urls = extract_links(post)
17 for url in urls:
18 if url not in url_cache:
19 url_cache.setdefault(url, 'LINK{0}'.format(link_num))
20 link_num = link_num + 1
2122 post = post.replace(url, url_cache[url])
2324 cleaned_posts.append(post.strip())
2526 return cleaned_posts
2728 def get_posts(post_filepath):
29 postlist = open(post_filepath).read().splitlines()
30 postlist = [p for p in postlist if len(p) > 0 and not p.startswith('---')]
31 return postlist
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 13 / 23

Process Steps
Inspired by [Richert (2014)]
• Feature Extraction
• Extract salient features from each tweet; store it as a vector
• Cluster Vectors (of Tweets)
• Determine the cluster for the tweet in question
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 14 / 23

Process Steps
Inspired by [Richert (2014)]
• Feature Extraction
• Extract salient features from each tweet; store it as a vector
• Cluster Vectors (of Tweets)
• Determine the cluster for the tweet in question
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 14 / 23

Process Steps
Inspired by [Richert (2014)]
• Feature Extraction
• Extract salient features from each tweet; store it as a vector
• Cluster Vectors (of Tweets)
• Determine the cluster for the tweet in question
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 14 / 23

Process Steps
Inspired by [Richert (2014)]
• Feature Extraction
• Extract salient features from each tweet; store it as a vector
• Cluster Vectors (of Tweets)
• Determine the cluster for the tweet in question
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 14 / 23
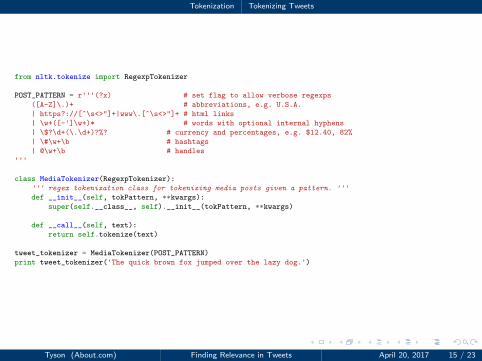
Tokenization Tokenizing Tweets
1 from nltk.tokenize import RegexpTokenizer
23 POST_PATTERN = r'''(?x) # set flag to allow verbose regexps
4 ([A-Z]\.)+ # abbreviations, e.g. U.S.A.
5 | https?://[^\s<>"]+|www\.[^\s<>"]+ # html links
6 | \w+([-']\w+)* # words with optional internal hyphens
7 | \$?\d+(\.\d+)?%? # currency and percentages, e.g. $12.40, 82%
8 | \#\w+\b # hashtags
9 | @\w+\b # handles
10 '''
1112 class MediaTokenizer(RegexpTokenizer):
13 ''' regex tokenization class for tokenizing media posts given a pattern. '''
14 def __init__(self, tokPattern, **kwargs):
15 super(self.__class__, self).__init__(tokPattern, **kwargs)
1617 def __call__(self, text):
18 return self.tokenize(text)
1920 tweet_tokenizer = MediaTokenizer(POST_PATTERN)
21 print tweet_tokenizer('The quick brown fox jumped over the lazy dog.')
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 15 / 23
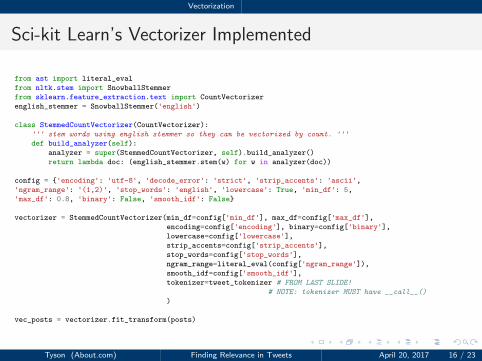
Vectorization
Sci-kit Learn’s Vectorizer Implemented
1 from ast import literal_eval
2 from nltk.stem import SnowballStemmer
3 from sklearn.feature_extraction.text import CountVectorizer
4 english_stemmer = SnowballStemmer('english')
56 class StemmedCountVectorizer(CountVectorizer):
7 ''' stem words using english stemmer so they can be vectorized by count. '''
8 def build_analyzer(self):
9 analyzer = super(StemmedCountVectorizer, self).build_analyzer()
10 return lambda doc: (english_stemmer.stem(w) for w in analyzer(doc))
1112 config = {'encoding': 'utf-8', 'decode_error': 'strict', 'strip_accents': 'ascii',
13 'ngram_range': '(1,2)', 'stop_words': 'english', 'lowercase': True, 'min_df': 5,
14 'max_df': 0.8, 'binary': False, 'smooth_idf': False}
1516 vectorizer = StemmedCountVectorizer(min_df=config['min_df'], max_df=config['max_df'],
17 encoding=config['encoding'], binary=config['binary'],
18 lowercase=config['lowercase'],
19 strip_accents=config['strip_accents'],
20 stop_words=config['stop_words'],
21 ngram_range=literal_eval(config['ngram_range']),
22 smooth_idf=config['smooth_idf'],
23 tokenizer=tweet_tokenizer # FROM LAST SLIDE!
24 # NOTE: tokenizer MUST have __call__()
25 )
2627 vec_posts = vectorizer.fit_transform(posts)
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 16 / 23

Clustering
What is KMeans?
• Clustering algorithm that segments data into k clusters
• Nondeterministic: different starting values may result in a differentassignment of points to clusters
• Run the k-means algorithm several times and then compare the results
• This assumes you have time to do this!• Might be simpler to change tokenization and vectorization methods
Algorithm [Janert (2010), p. 662-663]
choose initial positions for the cluster centroids
repeat:
for each point:
calculate its distance from each cluster centroid
assign the point to the nearest cluster
recalculate the positions of the cluster centroids
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 17 / 23

Clustering
What is KMeans?
• Clustering algorithm that segments data into k clusters
• Nondeterministic: different starting values may result in a differentassignment of points to clusters
• Run the k-means algorithm several times and then compare the results
• This assumes you have time to do this!• Might be simpler to change tokenization and vectorization methods
Algorithm [Janert (2010), p. 662-663]
choose initial positions for the cluster centroids
repeat:
for each point:
calculate its distance from each cluster centroid
assign the point to the nearest cluster
recalculate the positions of the cluster centroids
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 17 / 23

Clustering
What is KMeans?
• Clustering algorithm that segments data into k clusters
• Nondeterministic: different starting values may result in a differentassignment of points to clusters
• Run the k-means algorithm several times and then compare the results
• This assumes you have time to do this!• Might be simpler to change tokenization and vectorization methods
Algorithm [Janert (2010), p. 662-663]
choose initial positions for the cluster centroids
repeat:
for each point:
calculate its distance from each cluster centroid
assign the point to the nearest cluster
recalculate the positions of the cluster centroids
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 17 / 23

Clustering
What is KMeans?
• Clustering algorithm that segments data into k clusters
• Nondeterministic: different starting values may result in a differentassignment of points to clusters
• Run the k-means algorithm several times and then compare the results
• This assumes you have time to do this!
• Might be simpler to change tokenization and vectorization methods
Algorithm [Janert (2010), p. 662-663]
choose initial positions for the cluster centroids
repeat:
for each point:
calculate its distance from each cluster centroid
assign the point to the nearest cluster
recalculate the positions of the cluster centroids
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 17 / 23

Clustering
What is KMeans?
• Clustering algorithm that segments data into k clusters
• Nondeterministic: different starting values may result in a differentassignment of points to clusters
• Run the k-means algorithm several times and then compare the results
• This assumes you have time to do this!• Might be simpler to change tokenization and vectorization methods
Algorithm [Janert (2010), p. 662-663]
choose initial positions for the cluster centroids
repeat:
for each point:
calculate its distance from each cluster centroid
assign the point to the nearest cluster
recalculate the positions of the cluster centroids
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 17 / 23

Clustering
What is KMeans?
• Clustering algorithm that segments data into k clusters
• Nondeterministic: different starting values may result in a differentassignment of points to clusters
• Run the k-means algorithm several times and then compare the results
• This assumes you have time to do this!• Might be simpler to change tokenization and vectorization methods
Algorithm [Janert (2010), p. 662-663]
choose initial positions for the cluster centroids
repeat:
for each point:
calculate its distance from each cluster centroid
assign the point to the nearest cluster
recalculate the positions of the cluster centroids
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 17 / 23
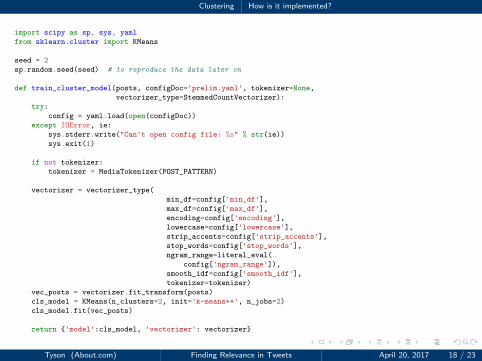
Clustering How is it implemented?
1 import scipy as sp, sys, yaml
2 from sklearn.cluster import KMeans
34 seed = 2
5 sp.random.seed(seed) # to reproduce the data later on
67 def train_cluster_model(posts, configDoc='prelim.yaml', tokenizer=None,
8 vectorizer_type=StemmedCountVectorizer):
9 try:
10 config = yaml.load(open(configDoc))
11 except IOError, ie:
12 sys.stderr.write("Can't open config file: %s" % str(ie))
13 sys.exit(1)
1415 if not tokenizer:
16 tokenizer = MediaTokenizer(POST_PATTERN)
1718 vectorizer = vectorizer_type(
19 min_df=config['min_df'],
20 max_df=config['max_df'],
21 encoding=config['encoding'],
22 lowercase=config['lowercase'],
23 strip_accents=config['strip_accents'],
24 stop_words=config['stop_words'],
25 ngram_range=literal_eval(
26 config['ngram_range']),
27 smooth_idf=config['smooth_idf'],
28 tokenizer=tokenizer)
29 vec_posts = vectorizer.fit_transform(posts)
30 cls_model = KMeans(n_clusters=2, init='k-means++', n_jobs=2)
31 cls_model.fit(vec_posts)
3233 return {'model':cls_model, 'vectorizer': vectorizer}
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 18 / 23
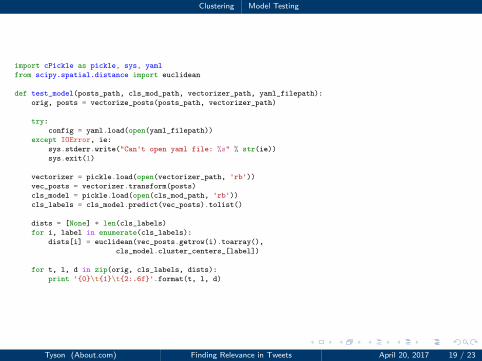
Clustering Model Testing
1 import cPickle as pickle, sys, yaml
2 from scipy.spatial.distance import euclidean
34 def test_model(posts_path, cls_mod_path, vectorizer_path, yaml_filepath):
5 orig, posts = vectorize_posts(posts_path, vectorizer_path)
67 try:
8 config = yaml.load(open(yaml_filepath))
9 except IOError, ie:
10 sys.stderr.write("Can't open yaml file: %s" % str(ie))
11 sys.exit(1)
1213 vectorizer = pickle.load(open(vectorizer_path, 'rb'))
14 vec_posts = vectorizer.transform(posts)
15 cls_model = pickle.load(open(cls_mod_path, 'rb'))
16 cls_labels = cls_model.predict(vec_posts).tolist()
1718 dists = [None] * len(cls_labels)
19 for i, label in enumerate(cls_labels):
20 dists[i] = euclidean(vec_posts.getrow(i).toarray(),
21 cls_model.cluster_centers_[label])
2223 for t, l, d in zip(orig, cls_labels, dists):
24 print '{0}\t{1}\t{2:.6f}'.format(t, l, d)
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 19 / 23
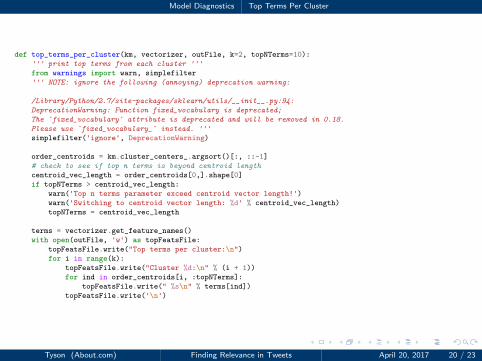
Model Diagnostics Top Terms Per Cluster
1 def top_terms_per_cluster(km, vectorizer, outFile, k=2, topNTerms=10):
2 ''' print top terms from each cluster '''
3 from warnings import warn, simplefilter
4 ''' NOTE: ignore the following (annoying) deprecation warning:
56 /Library/Python/2.7/site-packages/sklearn/utils/__init__.py:94:
7 DeprecationWarning: Function fixed_vocabulary is deprecated;
8 The `fixed_vocabulary` attribute is deprecated and will be removed in 0.18.
9 Please use `fixed_vocabulary_` instead. '''
10 simplefilter('ignore', DeprecationWarning)
1112 order_centroids = km.cluster_centers_.argsort()[:, ::-1]
13 # check to see if top n terms is beyond centroid length
14 centroid_vec_length = order_centroids[0,].shape[0]
15 if topNTerms > centroid_vec_length:
16 warn('Top n terms parameter exceed centroid vector length!')
17 warn('Switching to centroid vector length: %d' % centroid_vec_length)
18 topNTerms = centroid_vec_length
1920 terms = vectorizer.get_feature_names()
21 with open(outFile, 'w') as topFeatsFile:
22 topFeatsFile.write("Top terms per cluster:\n")
23 for i in range(k):
24 topFeatsFile.write("Cluster %d:\n" % (i + 1))
25 for ind in order_centroids[i, :topNTerms]:
26 topFeatsFile.write(" %s\n" % terms[ind])
27 topFeatsFile.write('\n')
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 20 / 23
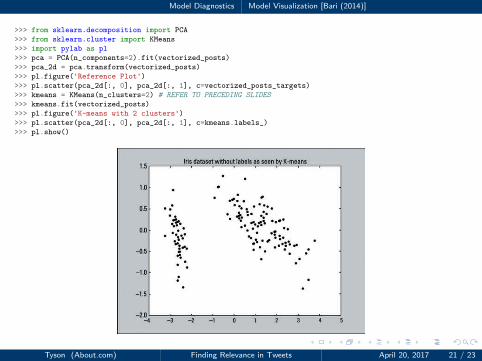
Model Diagnostics Model Visualization [Bari (2014)]
1 >>> from sklearn.decomposition import PCA
2 >>> from sklearn.cluster import KMeans
3 >>> import pylab as pl
4 >>> pca = PCA(n_components=2).fit(vectorized_posts)
5 >>> pca_2d = pca.transform(vectorized_posts)
6 >>> pl.figure('Reference Plot')
7 >>> pl.scatter(pca_2d[:, 0], pca_2d[:, 1], c=vectorized_posts_targets)
8 >>> kmeans = KMeans(n_clusters=2) # REFER TO PRECEDING SLIDES
9 >>> kmeans.fit(vectorized_posts)
10 >>> pl.figure('K-means with 2 clusters')
11 >>> pl.scatter(pca_2d[:, 0], pca_2d[:, 1], c=kmeans.labels_)
12 >>> pl.show()
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 21 / 23
Roads Not Taken
• Batch vs. Stream Processing
• Batch KMeans (sklearn.cluster.MiniBatchKMeans)
• Other types of vectorization and tokenization
• Using unsupervised machine learning as a segue to a supervised solution
• What happened in the end with the client?
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 22 / 23
Roads Not Taken
• Batch vs. Stream Processing
• Batch KMeans (sklearn.cluster.MiniBatchKMeans)
• Other types of vectorization and tokenization
• Using unsupervised machine learning as a segue to a supervised solution
• What happened in the end with the client?
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 22 / 23

Roads Not Taken
• Batch vs. Stream Processing
• Batch KMeans (sklearn.cluster.MiniBatchKMeans)
• Other types of vectorization and tokenization
• Using unsupervised machine learning as a segue to a supervised solution
• What happened in the end with the client?
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 22 / 23

Roads Not Taken
• Batch vs. Stream Processing
• Batch KMeans (sklearn.cluster.MiniBatchKMeans)
• Other types of vectorization and tokenization
• Using unsupervised machine learning as a segue to a supervised solution
• What happened in the end with the client?
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 22 / 23

Roads Not Taken
• Batch vs. Stream Processing
• Batch KMeans (sklearn.cluster.MiniBatchKMeans)
• Other types of vectorization and tokenization
• Using unsupervised machine learning as a segue to a supervised solution
• What happened in the end with the client?
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 22 / 23
References
A. Bari, M. Chaouchi and T. Jung.
Predictive Analytics for Dummies (1st Edition).
For Dummies, 2014.
B. Bengfort, R. Bilbro and T. Ojeda
Applied Text Analysis with Python.
O’Reilly Media, 2016.
Philipp K. Janert.
Data Analysis with Open Source Tools.
O’Reilly Media, 2010.
W. Richert and L. Pedro Coelho
Building Machine Learning Systems with Python.
Packt Publishing, 2014.
Tyson (About.com) Finding Relevance in Tweets April 20, 2017 23 / 23