finding inherent parallelism - - get a free blog
TRANSCRIPT

Finding Inherent Parallelism
Dr Wayne Kelly
Senior Lecturer
Queensland University of Technology
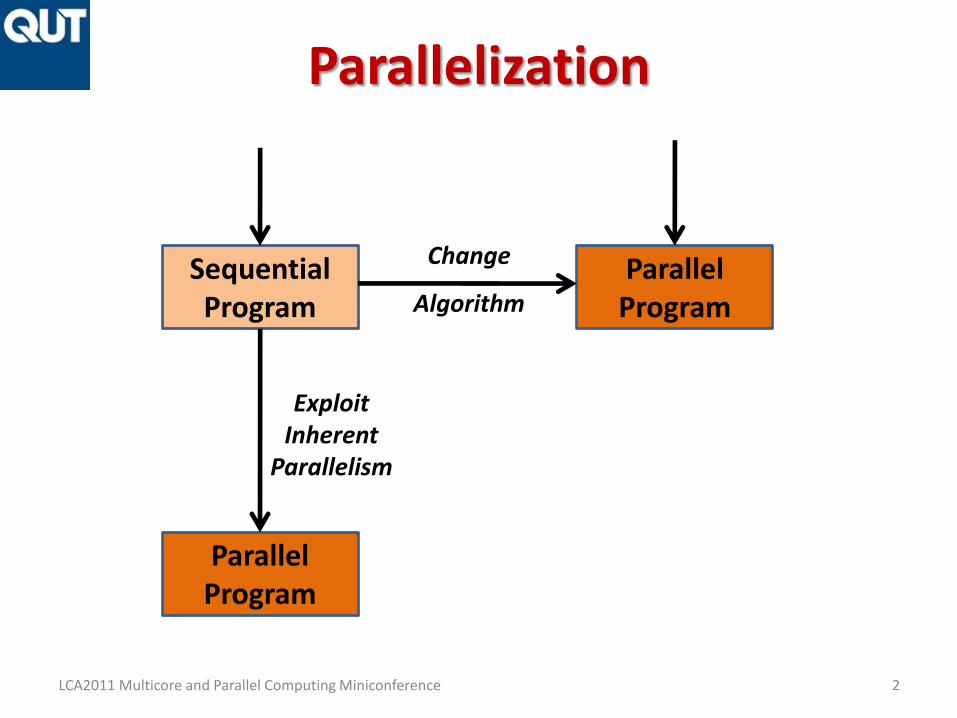
Parallelization
SequentialProgram
ParallelProgram
ParallelProgram
Change
Algorithm
2
ExploitInherent
Parallelism
LCA2011 Multicore and Parallel Computing Miniconference

Inherent Parallelism
1: a = 1;
2: b = x + 1;
3: c = a + b;
for (i=1; i<n; i++)
a[i] = 0;
<<parallel>>
for (i=1; i<n; i++)
a[i] = 0;
1
3
2
3LCA2011 Multicore and Parallel Computing Miniconference

Exploiting Inherent Parallelism
1. Which steps can be performed in parallel?– requires analysis of dependencies
2. Which of those steps are worth while being performing in parallel?– requires profiling or performance prediction
3. What code do we need to generate to efficiently execute those steps in parallel?– mapping computation to threads,
synchronization, aggregation, etc.
4LCA2011 Multicore and Parallel Computing Miniconference

Automatic Parallelization
Parallelization can be performed:• Automatically by a tool/compiler,
and/or• Manually by a programmer.
Unfortunately:
• Current compilers are not generally smart enough to perform parallelization in general.
• Manual parallelization requires highly skilled programmers, is very time consuming and error prone.
5LCA2011 Multicore and Parallel Computing Miniconference

Control and Data Dependencies
Control Dependencies
for (i=0; i<n; i++)
{
a[i] = speed(b[i],2);
if (a[i] > 100)
break;
b[i] += a[i] * i;
}
Data Dependencies
Flow dependence (W -> R):
a = 42;...
b = a + 1;
Output dependence (W -> W):
a = 42;...
a = 0;
Anti dependence (R -> W):
a = b + 1;...
b = 42;
6LCA2011 Multicore and Parallel Computing Miniconference

Array Data Dependence Analysis
for (int i=0; i<n; i++)
for (int j=i; j<n; j++)
a[i, j+1] = a[n,j];
Any data dependencies between loop iterations?
∃ ir, jr, iw, jw : 0 ≤ ir < n ^ ir ≤ jr < n ^
0 ≤ iw < n ^ iw ≤ jw < n ^
iw = n ^ jw+1 = jr
If there is a (flow) data dependence then there must exist at least one iteration (ir, jr) that reads the same array element that is written by some iteration (iw, jw).
7LCA2011 Multicore and Parallel Computing Miniconference
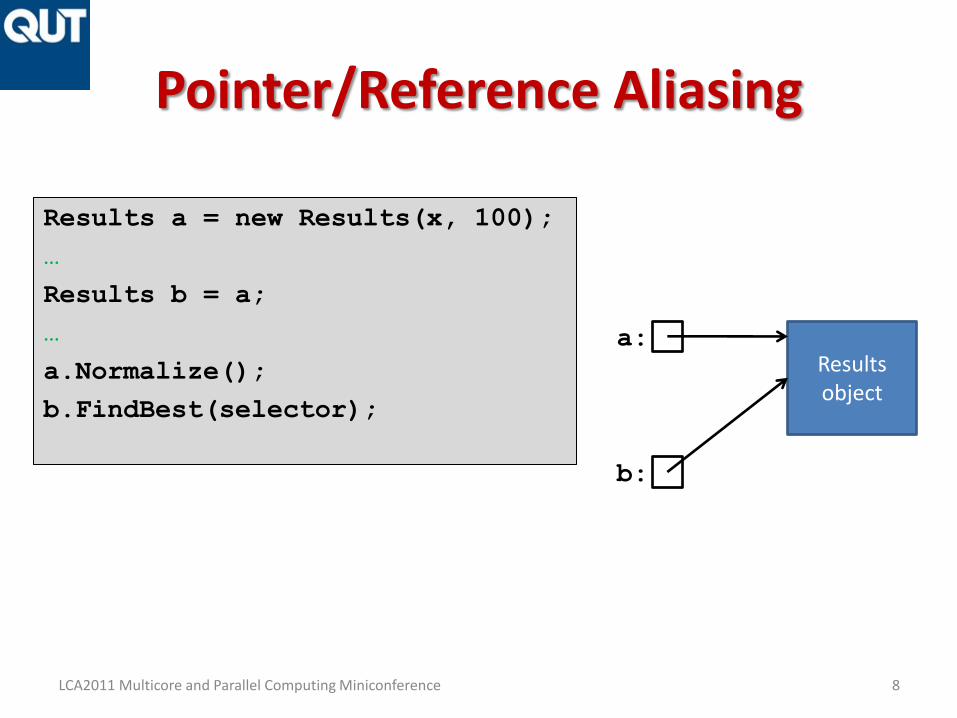
Pointer/Reference Aliasing
Results a = new Results(x, 100);
…
Results b = a;
…
a.Normalize();
b.FindBest(selector);
Resultsobject
a:
b:
8LCA2011 Multicore and Parallel Computing Miniconference

Static Analysis Complicated By
• Complex inter-procedural data flow
• Pointers and pass by reference
• Object-oriented virtual function calls
• Component-oriented development
• This is why 99% of automatic parallelizing compilers are for Fortran or other languages with similar semantic restrictions.
9LCA2011 Multicore and Parallel Computing Miniconference

Conservative Analysis
• Static data dependence analysis is inexact
– Conservatively over estimates data dependencies
– Results in under estimation of parallelism
• For large, complex, object-oriented applications we often end up finding that virtually nothing can be executed in parallel.
• How much potential parallelism are we missing?
10LCA2011 Multicore and Parallel Computing Miniconference

Runtime Analysis
• At runtime we have none of these problems.
• We know precisely:
– which memory locations are accessed
– which virtual methods get invoked
– which components are dynamically loaded
– which branches are taken
– which exceptions are thrown
11LCA2011 Multicore and Parallel Computing Miniconference

Dynamic Data Dependence Analysis
• Instrument the code so as to record which memory addresses are read or written by each instruction as they execute.
Instruction instance
A
Instruction instance
B
mx
WritesReads
Data
dependence
12LCA2011 Multicore and Parallel Computing Miniconference

Problems with Runtime Analysis
• May not detect all data dependencies– May vary with input data
– Cannot guarantee that code is safe to run in parallel.
– But, can prove that code is not parallelizable and why
• Static analysis:– Upper bound on data dependencies
– Lower bound on parallelism
• Dynamic analysis:– Lower bound on data dependencies
– Upper bound on parallelism
13LCA2011 Multicore and Parallel Computing Miniconference

Runtime Structures
• Create a node for each executed instruction which reads or writes.
• Dictionary which maps each memory location to the most recent instruction that wrote it– allows flow and output dependencies to be detected
• Dictionary which maps each memory location to the set of all instructions which have read it since it was last written.– allows anti dependencies to be detected
• Also need to consider object allocation, de-allocation and garbage collection.
14LCA2011 Multicore and Parallel Computing Miniconference

Loop Parallelism• To determine which loops are parallelizable need to
associate instruction instances with loop iterations
Method A
Method B
Loop iteration 1
Loop iteration 3
Method C
Loop iteration 5
Instruction instance A
Instruction instance B
Method D
mx
Last written by reads

Visualization of Data Dependencies
• IDE extension to overlay source code with colour coded arrows linking data dependence source and sink instructions:
for (int i = 0; i < n; i++)
{
a[i] = 0;
int x = b[n-i];
b[i] = foo(i-1);
}
• Refactoring to support Parallelization
16LCA2011 Multicore and Parallel Computing Miniconference

What else can we do?1. Determine which loops appear to be parallelizable
– determine why they are not parallelizable
2. Analyse parallelism considering only flow dependencies to investigate the parallelism that might result if we can apply source transformations such as loop variable privatization to eliminate output and anti dependences.
3. Measure the total theoretical amount of parallelism by determining the earliest execution time of each instruction assuming an infinite number of processors
Total number of instructions executed
Parallelism =
Length of longest sequential path
17LCA2011 Multicore and Parallel Computing Miniconference

What’s the Purpose of the Tool?
1. Help programmers parallelize specific applications.
2. Analyse a large collection of general purpose applications to determine:
a) How much parallelism is typical?
b) What different forms does it commonly arise in?
c) What parallelism are we missing with current techniques?
18LCA2011 Multicore and Parallel Computing Miniconference

Implementation
Data collection:
Dependence info:
IDE:
CIL x86 native
Mono.NETJIT
Intel PIN
XMLDependence info
Visual StudioExtension
EclipsePlug-in
19LCA2011 Multicore and Parallel Computing Miniconference
