finding hidden cliques and clusters by convex optimization
TRANSCRIPT

Finding hidden cliques and clusters byconvex optimization
Brendan Ames
Computing + Mathematical SciencesCalifornia Institute of Technology
CAAM ColloquiumRice University
January 30, 2014

Agenda
• Present a convex relaxation for the maximum cliqueproblem based on nuclear norm relaxation for rankminimization.
• Extend this relaxation to one for the densest k -subgraphand graph clustering problems.
• Give a probabilistic model for ‘‘clusterable’’ data andgraphs, and theoretical recovery guarantees.
• Experimental results and open problems.
• Joint work with Stephen Vavasis, University of Waterloo,and Ting-Kei Pong, University of British Columbia.
1 / 42

Clustering
• Clustering: partition data so that items in each cluster aresimilar to each other and items not in the same clusterare dissimilar.
• Fundamental problem in statistics and machine learning:
• pattern recognition, computational biology, imageprocessing/computer vison, network analysis.
• No consensus on what constitutes a good clustering;depends heavily on application.
• Intractable: usually modeled as some NP-hard problem(e.g. clique, normalized cut, k-means).
2 / 42

Graph clustering
• Similarity Graph: represent data set as a graph
• items = nodes• edges indicate similarity
• Cluster the data set by dividing the graph into densesubgraphs.
• Dense = large average degree
3 / 42

Example: Communities in Social Networks
• Nodes = users
• Edges = “friendship”.
• Densely connectedgroups = communities
4 / 42

Cliques of a graph
• Given graph G = (V ,E), a clique of G is a pairwiseadjacent subset of V .
• C ⊆ V is a clique of G if uv ∈ E for all u, v ∈ C.
• The subgraph G(C) induced by C is complete.
5 / 42

Cliques of a graph
• Given graph G = (V ,E), a clique of G is a pairwiseadjacent subset of V .
• C ⊆ V is a clique of G if uv ∈ E for all u, v ∈ C.
• The subgraph G(C) induced by C is complete.
5 / 42

The Maximum Clique problem
• Optimization version: Find largest clique of G; size of thelargest clique is the clique number ω(G).
• Decision version: Given graph G, integer k : does Gcontain a clique of cardinality at least k?
• Complexity: NP-complete, NP-hard to approximate ω(G)within a ratio of N1−ε for any ε > 0, (N = |V |)
• Many applications: communication, power, and socialnetworks, mathematical biology, cryptography.
6 / 42

Worst case vs planted case
• Complexity results are worst case.
• There are some graphs for which finding the maximumclique is as difficult as hardest problems known.
• Not necessarily true for all graphs.
• We focus on identifying trade-offs between clique sizeand density of nonclique edges that ensure we can solveClique efficiently.
7 / 42

Matrix representation of cliques• Characteristic vector of C: vector v ∈ 0,1V with
vi = 1 if i ∈ C and vi = 0 otherwise
• If C is a clique with characteristic vector v, let X = vvT .
• Nonzero entries of X form a |C| × |C| all-ones block inAG + I.
8 / 42

Matrix representation of cliques• Characteristic vector of C: vector v ∈ 0,1V with
vi = 1 if i ∈ C and vi = 0 otherwise
• If C is a clique with characteristic vector v, let X = vvT .
• Nonzero entries of X form a |C| × |C| all-ones block inAG + I.
8 / 42

Matrix representation of cliques (2)• X ∈ 0,1V×V corresponds to a k -clique if and only if
• it is the adjacency matrixof a subgraph of G:
Xij = 0 if i 6= j or ij /∈ E ,
• it contains k2 nonzeroentries (
(k2
)edges):∑
i,j∈V
Xij = k2,
• it is symmetric, and
• rank(X ) = 1
9 / 42

Clique as rank minimization
• G has a k -clique if and only if there exists rank-onesymmetric binary matrix X such that∑∑
Xij = k2
Xij = 0 ∀ ij /∈ E , i 6= j .
• Clique is equivalent to the rank minimization problem:
minX∈0,1V×V
X∈ΣV
rank(X ) : eT Xe = k2,Xij = 0 if (i , j) ∈ E
where E = V × V −
E ∪ (u,u) : u ∈ V
.
10 / 42

Affine Rank minimization
• Affine rank minimization problem: find minimum ranksolution of a given set of linear equations:
minrank(X ) : A(X ) = b.
• Well-known to be NP-hard.
• Fazel 2002: Relax using the nuclear norm ‖X‖∗
rank(X ) = ‖σ(X )‖0 ⇒ ‖X‖∗ = ‖σ(X )‖1 =∑
i
σi(X )
11 / 42

Geometry of nuclear norm relaxation• Relax by replacing rank(X ) with ‖X‖∗ =
∑σi(X )
• ‖ · ‖∗ is the convex envelope of rank onB = X : ‖X‖ ≤ 1.
12 / 42

Geometry of nuclear norm relaxation• Relax by replacing rank(X ) with ‖X‖∗ =
∑σi(X )
• ‖ · ‖∗ is the convex envelope of rank onB = X : ‖X‖ ≤ 1.
12 / 42

Guaranteed low-rank recovery• Recht, Fazel, Parrilo 2007, Candes and Recht 2008:
If A and b are given by sufficiently many (m = Ω(rn log n)random observations of a rank-r n × n matrix then
arg minrank(X ) : A(X ) = b = arg min‖X‖∗ : A(X ) = b
13 / 42

Nuclear norm relaxation of Clique
• We have the rank minimization problem:
minX∈0,1V×V
X∈ΣV
rank(X ) : eT Xe = k2, Xij = 0 if (i , j) ∈ E
• Relax rank with the nuclear norm, drop binary andsymmetry constraints:
min‖X‖∗ : eT Xe = k2, Xij = 0 if (i , j) ∈ E
(NNR)
• When does the solution of the relaxation coincide withthat of the rank minimization problem?
14 / 42

The planted case
Construction:• Add edges between
nodes in vertex set V ∗
of size k .
• Each remaining edgeis added to Eindependently withfixed probability p.
• V ∗ is a clique of G(called a planted orhidden clique).
15 / 42

The planted case
Construction:• Add edges between
nodes in vertex set V ∗
of size k .
• Each remaining edgeis added to Eindependently withfixed probability p.
• V ∗ is a clique of G(called a planted orhidden clique).
15 / 42

The planted case
Construction:• Add edges between
nodes in vertex set V ∗
of size k .
• Each remaining edgeis added to Eindependently withfixed probability p.
• V ∗ is a clique of G(called a planted orhidden clique).
15 / 42

The planted case
Construction:• Add edges between
nodes in vertex set V ∗
of size k .
• Each remaining edgeis added to Eindependently withfixed probability p.
• V ∗ is a clique of G(called a planted orhidden clique).
15 / 42

The planted case
Construction:• Add edges between
nodes in vertex set V ∗
of size k .
• Each remaining edgeis added to Eindependently withfixed probability p.
• V ∗ is a clique of G(called a planted orhidden clique).
15 / 42

The planted case
Construction:• Add edges between
nodes in vertex set V ∗
of size k .
• Each remaining edgeis added to Eindependently withfixed probability p.
• V ∗ is a clique of G(called a planted orhidden clique).
15 / 42

Recovery guarantee in the planted case
Theorem (Ames-Vavasis 2009)There exists scalar c > 0 (depending only on p) such that if
k ≥ c√
N
then
• V ∗ is the unique maximum clique of G, and
• X ∗ = vvT is the unique optimal solution of (NNR)
with high probability.
16 / 42

What happens if edges are deleted?• Guarantee does not tolerate edge deletion noise.
• Suppose edge uv is deleted for some u, v ∈ V ∗.
• Then V ∗ is not a clique and X ∗ is not feasible for (NNR).
17 / 42

What happens if edges are deleted?• Guarantee does not tolerate edge deletion noise.
• Suppose edge uv is deleted for some u, v ∈ V ∗.
• Then V ∗ is not a clique and X ∗ is not feasible for (NNR).
17 / 42

The densest k-subgraph problem
• Want a dense subgraph of size k , not necessarily aclique.
• Densest k -subgraph problem (DKS): find subgraphH ⊆ G on k nodes with maximum density:
d(H) =|E(H)||V (H)|
=|E(H)|
k.
• NP-hard: proof is by reduction to Clique; hard toapproximate.
• Maximizing d(H) = maximizing |E(H)| over all k -nodesubgraphs.
18 / 42

Duality of density and number of missingedges
• Let V ∗ ⊆ V be a k -subset with characteristic vector v.
• Introduce a correction Y for entries of X = vvT thatshould be 0:
Yij =
−Xij , if ij ∈ E
0, otherwise.
• If V ∗ is almost a clique then G(V ∗) should be very denseand Y should be very sparse.
• Cardinality of Y acts as a dual of density of G(V ∗) :
|E(G(V ∗))| =
(k2
)− ‖Y‖0
2
19 / 42

Relaxation as Principal Component Pursuit
• Can relax (DKS) as
min ‖X‖∗ + γ‖Y‖1
st eT Xe = k2
Xij + Yij = 0 if ij ∈ EX ∈ [0,1]V×V
(DKSR)
where γ is a regularization parameter.
• Relax ‖Y‖0 using the `1-norm ‖Y‖1, rank(X ) with thenuclear norm ‖X‖∗.
20 / 42

Planted case• Start with set of N nodes V .
• Add all edges between nodes in V ∗ ⊆ V .
• Add noise:• Add potential edges with probability p• Delete some edges in V ∗ × V ∗ with probability q
21 / 42

Planted case• Start with set of N nodes V .
• Add all edges between nodes in V ∗ ⊆ V .
• Add noise:• Add potential edges with probability p• Delete some edges in V ∗ × V ∗ with probability q
21 / 42

Planted case• Start with set of N nodes V .
• Add all edges between nodes in V ∗ ⊆ V .
• Add noise:• Add potential edges with probability p• Delete some edges in V ∗ × V ∗ with probability q
21 / 42

Recovery guarantee
Theorem (Ames 2013)There exist constants c1, c2, c3 > 0 depending on p,q suchthat if
k ≥ c1
√N
and γ ∈ (c2/k , c3/k) then
• G(V ∗) is the unique densest k-subgraph of G, and
• X ∗ = vvT is the unique optimal solution of (DKSR)
with high probability.
22 / 42

The Weighted Similarity Graph
• Given data and affinity function f indicating similaritybetween any two items.
• Can model the data as weighted similarity graphGS = (V ,E ,W ) as follows:
• Each item is represented by a node in V .
• We add an edge between each pair of two nodes i , jwith edge weight Wij = f (i , j).
• Wij is large if i and j are highly similar.
23 / 42
Example: Communities in Social Networks
• Nodes = users
• Edges = “friendship”.
• Densely connectedgroups = communities
24 / 42

Example: Clustered Euclidean data• Suppose each data point in the i th cluster Ci is placed
uniformly at random in a ball centered at ci ∈ Rd .
• Distance within clusters will be small compared to thedistance between clusters if centers are well-separated.
• Choose Wij = exp(−‖xi − xj‖2).
25 / 42

Example: Clustered Euclidean data• Suppose each data point in the i th cluster Ci is placed
uniformly at random in a ball centered at ci ∈ Rd .
• Distance within clusters will be small compared to thedistance between clusters if centers are well-separated.
• Choose Wij = exp(−‖xi − xj‖2).
25 / 42

The Densest r -Disjoint Clique Problem• To cluster the data we want to partition the graph into
cliques with heavy support.
• A r -disjoint-clique subgraph of a graph G is a subgraph ofG induced by r disjoint cliques.
• Densest r -disjoint-clique problem (RDC): find ar -disjoint-clique subgraph such that the sum of thedensities of the r complete subgraphs induced by thecliques is maximized.
• Density of complete subgraph induced by C:
d(C) =1|C|
∑i∈C
∑j∈C
Wij =vT WvvT v
where v is the characteristic vector of C.26 / 42

Lifting procedure for RDC
• Let C1, . . . ,Cr define a r -disjoint-clique subgraph withcharacteristic vectors v1,v2, . . . ,vr
• Lift the r characteristic vectors v1,v2, . . . ,vr to therank-r matrix variable X :
X =∑ vivT
i
‖vi‖2 .
• X has trace exactly equal to r and satisfies
Tr(WX ) =∑ vT
i Wvi
‖vi‖2
27 / 42

Lifted solutionsLifted solution X must satisfy:
• Inlier rows sum to 1.Outlier rows equal 0:
Xe ≤ e
• X is symmetric doublynonnegative:
Xij ≥ 0, X 0
• rank(X ) = Tr(X ) = r
• other combinatorialconstraints
28 / 42

Relaxation to SDP
• Ignoring rank constraint and relaxing combinatorialconstraints on X gives the semidefinite program:
max Tr(WX )
st Xe ≤ eTr(X ) = rXij ≥ 0 ∀ i , j ∈ VX 0.
• Tr(X ) = ‖X‖∗ = r acts a surrogate for rank(X ) = r
29 / 42

The Planted cluster model
Randomly generate weights W ∈ [0,1]N×N according to thefollowing model:
• Start with clusters C1, . . . ,Cr ofsizes k1, . . . , kr .
• Sample entries of W (Ci ,Ci) i.i.d.from probability distribution Ω1 withmean α.
• Sample remaining entries of Wi.i.d. from distribution Ω2 with meanβ << α.
30 / 42

Guaranteed recovery• Let X ∗ =
r∑i=1
vivTi
kibe the lifted solution corresponding to
the planted clusters C1, . . . ,Cr .
Theorem (Ames 2012)There exist scalars c1, c2, c3, c4 > 0 such that if
c1
√N + c2
√rkr+1 + c3kr+1 ≤ c4k ,
where k = mink1, k2, . . . , kr and kr+1 is the number ofoutliers, then
• X ∗ is the unique optimal solution of SDP relaxation, and
• C1, . . . ,Cr is the unique densest r -disjoint-cliquesubgraph
with high probability.31 / 42

Rehnquist Supreme Court• Data drawn from U.S. Supreme Court decisions (from
1994-95 to 2003-04).
• First consider by Hubert and Steinley 2005.
• Assign edge-weights corresponding to fraction ofdecisions on which Justices agreed:
St Br Gi So Oc Ke Re Sc Th
St 1 0.62 0.66 0.63 0.33 0.36 0.25 0.14 0.15Br 0.62 1 0.72 0.71 0.55 0.47 0.43 0.25 0.24Gi 0.66 0.72 1 0.78 0.47 0.49 0.43 0.28 0.26So 0.63 0.71 0.78 1 0.55 0.5 0.44 0.31 0.29Oc 0.33 0.55 0.47 0.55 1 0.67 0.71 0.54 0.54Ke 0.36 0.47 0.49 0.5 0.67 1 0.77 0.58 0.59Re 0.25 0.43 0.43 0.44 0.71 0.77 1 0.66 0.68Sc 0.14 0.25 0.28 0.31 0.54 0.58 0.66 1 0.79Th 0.15 0.24 0.26 0.29 0.54 0.59 0.68 0.79 1
32 / 42

Rehnquist Supreme Court (2)
• Solve RDC with r = 2 to get the following partition of theSupreme court:
1: “Liberal” 2: “Conservative”
Stevens (St) O’Connor (Oc)Breyer (Br) Kennedy (Ke)Ginsberg (Gi) Rehnquist (Re)Souter (So) Scalia (Sc)
Thomas (Th)
33 / 42

Rehnquist Supreme Court (3)
• Algorithm is sensitive to choice of r .• Solve with r = 3:
Cluster 1 Cluster 2 Cluster 3
Thomas (Th) O’Connor (Oc) Stevens (St)Scalia (Sc) Kennedy (Ke) Breyer (Br)
Rehnquist (Re) Ginsberg (Gi)Souter (So)
34 / 42

The NCAA Football Network
• First considered in Girvan and Newman 2001.
• Nodes are the 115 Division I football teams.
• Teams are deemed adjacent if they played at least onegame against each other in the 2000 season.
• Games are typically scheduled based on membershipwithin athletic conferences and geography.
• Should display community structure based onmembership in conferences.
35 / 42

The NCAA Football Network (2)• The node-node adjacency matrix for the football network.
36 / 42

The NCAA Football Network (3)• The adjacency matrix with rows/cols reordered according
to conferences.
37 / 42
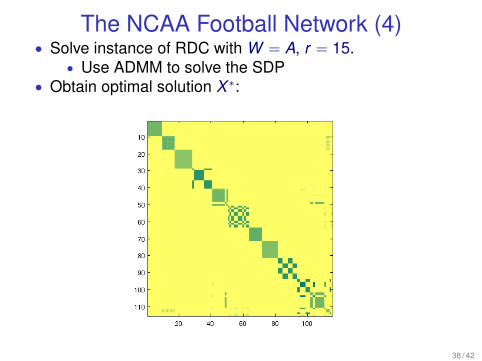
The NCAA Football Network (4)• Solve instance of RDC with W = A, r = 15.
• Use ADMM to solve the SDP• Obtain optimal solution X ∗:
38 / 42

The NCAA Football Network (4)• Solve instance of RDC with W = A, r = 15.
• Use ADMM to solve the SDP• Obtain optimal solution X ∗:
38 / 42

The NCAA Football Network (5)Atlantic Coast Big Twelve 1 MAC West Pacific Ten Sun Belt 1Clemson Colorado Ball State Arizona Arkansas StateDuke Kansas C. Michigan Arizona State Boise State*Florida State Kansas State E. Michigan California IdahoGeorgia Tech Iowa State N. Illinois Oregon NMSUMaryland Missouri Toledo Oregon State North TexasNC State Nebraska W. Michigan Stanford Utah State*North Carolina UCLAVirginia Big Twelve 2 MAC East USC Sun Belt 2Wake Forest Oklahoma State Akron Washington Central Florida*
Oklahoma BGSU WSU L-LafayetteBig East Texas Tech Buffalo L-MonroeBoston College Baylor Kent SEC West Louisiana Tech*Miami Texas A&M Marshall Alabama MTSUPittsburgh Texas Miami Ohio ArkansasRutgers Ohio Auburn Western AthleticSyracuse Conference USA LSU Fresno StTemple Alabama-Birm Mountain West Miss St HawaiiVirginia Tech Army Air Force Mississippi NevadaWest Virginia Cincinnati BYU Rice
East Carolina Colorado St SEC East SJSUBig Ten Houston New Mexico Florida SMUIllinois Louisville SDSU Georgia Texas Christian*Indiana Memphis UNLV Kentucky Texas El PasoIowa So. Miss. Utah South Carolina TulsaMichigan Tulane Wyoming TennesseeMichigan State Vanderbilt IndependentsMinnesota NavyNorthwestern Outlier Notre DameOhio State ConnecticutPenn StatePurdueWisconsin
39 / 42

Conclusions
• Have presented new convex relaxation based heuristicsfor the maximum clique and graph clustering problems.
• These relaxations are based on the relationship betweencliques and low-rank submatrices of the adjacency graph,and the nuclear norm relaxation for rank minimization.
• If data is sufficiently clusterable (i.e. highly similar withinclusters, dissimilar across clusters) then these heuristicssuccessfully recover the correct partition of the data.
40 / 42

Open problems
• Is the lower bound k = Ω(√
N) tight?
• Overlapping communities?
• Sparse graphs? Can we improve recovery guarantees?
• Sparse in the sense that α > β are both tending to 0as N →∞
• How to choose r in the clustering SDP?
• Algorithmic issues: how to efficiently solve large-scaleSDP?
41 / 42

Thank you!
• B. Ames and S. Vavasis. Nuclear norm minimization forthe planted clique and biclique problems. MathematicalProgramming, 129(1):121, 2011.
• B. Ames. Guaranteed clustering and biclustering viasemidefinite programming. To appear in MathematicalProgramming.
• B. Ames. Robust convex relaxation for the planted cliqueand densest k-subgraph problem. 2013.arxiv.org/abs/1305.4891
• Papers/slides/code: users.cms.caltech.edu/∼bpames
42 / 42