finding allelic frequencies using mapreduce/hadoop
TRANSCRIPT

Finding Allelic FrequenciesUsing MapReduce/Hadoop
Mahmoud ParsianPh.D in Computer Science
Senior Architect @ illumina1
2014 Hadoop SummitAmsterdam, Netherlands
April 3, 2014
1www.illumina.comMahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 1 / 46

Table of Contents
1 Biography
2 Overview
3 Basic Definitions
4 Source of Data for Allelic Frequency
5 Allelic Frequency Analysis
6 Allelic Frequency Using MapReduce/Hadoop
7 Running Allelic Frequency Analysis
Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 2 / 46

Biography
Outline
1 Biography
2 Overview
3 Basic Definitions
4 Source of Data for Allelic Frequency
5 Allelic Frequency Analysis
6 Allelic Frequency Using MapReduce/Hadoop
7 Running Allelic Frequency Analysis
Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 3 / 46

Biography
Who am I?
Name: Mahmoud Parsian
Education: Ph.D in Computer Science
Works: as Senior Architect @Illumina, Inc
Lead Big Data Team @IlluminaDevelop scalable regression algorithmsDevelop DNA-Seq and RNA-Seq workflowsUse Java/MapReduce/Hadoop/HBase
Author: of two books
JDBC Recipies (Apress)JDBC MetaData Recipies (Apress)
Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 4 / 46

Overview
Outline
1 Biography
2 Overview
3 Basic Definitions
4 Source of Data for Allelic Frequency
5 Allelic Frequency Analysis
6 Allelic Frequency Using MapReduce/Hadoop
7 Running Allelic Frequency Analysis
Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 5 / 46

Overview
Overview
Genetic variants in patients germline DNA is identified throughnext-gen sequencing technology.
Patient Sample −→ ... −→ VCF
Magnitude of this data is challenging to store and analyze:
several million variants per patientseveral billions for groups of patients
The group comparison will estimate allelic or genotypic frequencydifferences between groups for all variants present in any individual inthe analysis cohort.
Use Fisher’s Exact test to determine whether the difference infrequency is statistically significant.
Find allelic frequencies (use MapReduce/Hadoop)
Find top-100 p-values for two groups of variants (useMapReduce/Hadoop)
Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 6 / 46

Overview
Overview
Genetic variants in patients germline DNA is identified throughnext-gen sequencing technology.
Patient Sample −→ ... −→ VCF
Magnitude of this data is challenging to store and analyze:
several million variants per patientseveral billions for groups of patients
The group comparison will estimate allelic or genotypic frequencydifferences between groups for all variants present in any individual inthe analysis cohort.
Use Fisher’s Exact test to determine whether the difference infrequency is statistically significant.
Find allelic frequencies (use MapReduce/Hadoop)
Find top-100 p-values for two groups of variants (useMapReduce/Hadoop)
Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 6 / 46

Overview
Overview
Genetic variants in patients germline DNA is identified throughnext-gen sequencing technology.
Patient Sample −→ ... −→ VCF
Magnitude of this data is challenging to store and analyze:
several million variants per patientseveral billions for groups of patients
The group comparison will estimate allelic or genotypic frequencydifferences between groups for all variants present in any individual inthe analysis cohort.
Use Fisher’s Exact test to determine whether the difference infrequency is statistically significant.
Find allelic frequencies (use MapReduce/Hadoop)
Find top-100 p-values for two groups of variants (useMapReduce/Hadoop)
Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 6 / 46

Overview
Overview
Genetic variants in patients germline DNA is identified throughnext-gen sequencing technology.
Patient Sample −→ ... −→ VCF
Magnitude of this data is challenging to store and analyze:
several million variants per patientseveral billions for groups of patients
The group comparison will estimate allelic or genotypic frequencydifferences between groups for all variants present in any individual inthe analysis cohort.
Use Fisher’s Exact test to determine whether the difference infrequency is statistically significant.
Find allelic frequencies (use MapReduce/Hadoop)
Find top-100 p-values for two groups of variants (useMapReduce/Hadoop)
Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 6 / 46

Overview
Overview
Genetic variants in patients germline DNA is identified throughnext-gen sequencing technology.
Patient Sample −→ ... −→ VCF
Magnitude of this data is challenging to store and analyze:
several million variants per patientseveral billions for groups of patients
The group comparison will estimate allelic or genotypic frequencydifferences between groups for all variants present in any individual inthe analysis cohort.
Use Fisher’s Exact test to determine whether the difference infrequency is statistically significant.
Find allelic frequencies (use MapReduce/Hadoop)
Find top-100 p-values for two groups of variants (useMapReduce/Hadoop)
Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 6 / 46

Overview
Overview
Genetic variants in patients germline DNA is identified throughnext-gen sequencing technology.
Patient Sample −→ ... −→ VCF
Magnitude of this data is challenging to store and analyze:
several million variants per patientseveral billions for groups of patients
The group comparison will estimate allelic or genotypic frequencydifferences between groups for all variants present in any individual inthe analysis cohort.
Use Fisher’s Exact test to determine whether the difference infrequency is statistically significant.
Find allelic frequencies (use MapReduce/Hadoop)
Find top-100 p-values for two groups of variants (useMapReduce/Hadoop)
Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 6 / 46

Overview
Overview
Genetic variants in patients germline DNA is identified throughnext-gen sequencing technology.
Patient Sample −→ ... −→ VCF
Magnitude of this data is challenging to store and analyze:
several million variants per patientseveral billions for groups of patients
The group comparison will estimate allelic or genotypic frequencydifferences between groups for all variants present in any individual inthe analysis cohort.
Use Fisher’s Exact test to determine whether the difference infrequency is statistically significant.
Find allelic frequencies (use MapReduce/Hadoop)
Find top-100 p-values for two groups of variants (useMapReduce/Hadoop)
Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 6 / 46

Basic Definitions
Outline
1 Biography
2 Overview
3 Basic Definitions
4 Source of Data for Allelic Frequency
5 Allelic Frequency Analysis
6 Allelic Frequency Using MapReduce/Hadoop
7 Running Allelic Frequency Analysis
Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 7 / 46

Basic Definitions
Some Basic Definitions
Chromosome
Bioset
Bioset Record
Allele
Allelic Frequency
Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 8 / 46

Basic Definitions
Some Basic Definitions
Chromosome
Bioset
Bioset Record
Allele
Allelic Frequency
Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 8 / 46

Basic Definitions
Some Basic Definitions
Chromosome
Bioset
Bioset Record
Allele
Allelic Frequency
Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 8 / 46

Basic Definitions
Some Basic Definitions
Chromosome
Bioset
Bioset Record
Allele
Allelic Frequency
Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 8 / 46

Basic Definitions
Some Basic Definitions
Chromosome
Bioset
Bioset Record
Allele
Allelic Frequency
Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 8 / 46

Basic Definitions
Chromosome
The term chromosome comes from the Greek words for color(chroma) and body (soma)
A chromosome is an organized structure of DNA,protein, and RNA found in cells.
Human cells have 23 pairs of chromosomes labeledas {1, 2, ..., 22, X, Y}.Humans have a total of 46 chromosomes.
How are chromosomes inherited? In humans, onecopy of each chromosome is inherited from thefemale parent and the other from the male parent.
Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 9 / 46

Basic Definitions
Chromosome in Picture
Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 10 / 46

Basic Definitions
Cells to DNA
Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 11 / 46

Basic Definitions
What is a Bioset?
Individually analyzed data signatures are referred to as ”biosets”.”Biosets” encompass data in the form of experimental samplecomparisons as well as genotype signatures
A bioset most commonly referred to as a ”gene signature”. A samplerecord of a bioset will contain a chromosome, its start and stoppositions, two alleles, and other related information.
The number of entries/records for a germline bioset can have 4.3million records
A patient may have any number of biosets
Each bioset has a set of genes
Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 12 / 46

Basic Definitions
VCF to Bioset
Sample −→ FASTQ1 Data
FASTQ Data −→ DNA-Seq
DNA-Seq −→ VCF2
VCF −→ Bioset
Bioset −→ Ready for Analysis
1FASTQ format is a text-based format for storing both a biological sequence(usually nucleotide sequence) and its corresponding quality scores.
2VCF = Variant Call Format = the format of a text file used inbioinformatics for storing gene sequence variations.Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 13 / 46

Basic Definitions
VCF to Bioset
Sample −→ FASTQ1 Data
FASTQ Data −→ DNA-Seq
DNA-Seq −→ VCF2
VCF −→ Bioset
Bioset −→ Ready for Analysis
1FASTQ format is a text-based format for storing both a biological sequence(usually nucleotide sequence) and its corresponding quality scores.
2VCF = Variant Call Format = the format of a text file used inbioinformatics for storing gene sequence variations.Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 13 / 46

Basic Definitions
VCF to Bioset
Sample −→ FASTQ1 Data
FASTQ Data −→ DNA-Seq
DNA-Seq −→ VCF2
VCF −→ Bioset
Bioset −→ Ready for Analysis
1FASTQ format is a text-based format for storing both a biological sequence(usually nucleotide sequence) and its corresponding quality scores.
2VCF = Variant Call Format = the format of a text file used inbioinformatics for storing gene sequence variations.Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 13 / 46

Basic Definitions
VCF to Bioset
Sample −→ FASTQ1 Data
FASTQ Data −→ DNA-Seq
DNA-Seq −→ VCF2
VCF −→ Bioset
Bioset −→ Ready for Analysis
1FASTQ format is a text-based format for storing both a biological sequence(usually nucleotide sequence) and its corresponding quality scores.
2VCF = Variant Call Format = the format of a text file used inbioinformatics for storing gene sequence variations.Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 13 / 46

Basic Definitions
VCF to Bioset
Sample −→ FASTQ1 Data
FASTQ Data −→ DNA-Seq
DNA-Seq −→ VCF2
VCF −→ Bioset
Bioset −→ Ready for Analysis
1FASTQ format is a text-based format for storing both a biological sequence(usually nucleotide sequence) and its corresponding quality scores.
2VCF = Variant Call Format = the format of a text file used inbioinformatics for storing gene sequence variations.Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 13 / 46

Basic Definitions
VCF to Bioset
Sample −→ FASTQ1 Data
FASTQ Data −→ DNA-Seq
DNA-Seq −→ VCF2
VCF −→ Bioset
Bioset −→ Ready for Analysis
1FASTQ format is a text-based format for storing both a biological sequence(usually nucleotide sequence) and its corresponding quality scores.
2VCF = Variant Call Format = the format of a text file used inbioinformatics for storing gene sequence variations.Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 13 / 46

Basic Definitions
Sample Record of a Bioset?
A bioset can have 4.3 million records
A sample record of a bioset will contain
a chromosome (chromosomeID: 1, 2, 3, ...)Start positionStop positionTwo alleles: Allele1, Allele2Genome Referenceand other related information such as mutation class, ...
Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 14 / 46

Basic Definitions
What is an Allele?
Allele is a viable DNA coding that occupies a given locus (position)on a chromosome. There are two alleles per chromosome position andthey are called allele1 and allele2.
Allelic frequency is defined as ”the percentage of a population of aspecies that carries a particular allele on a given chromosome locus.”
Alternatively, ”allele frequency” can be defined as the frequency of anallele relative to that of other alleles of the same gene in a population.
The Fisher’s Exact Test is used to calculate the ”p-value” for AllelicFrequency.
Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 15 / 46

Basic Definitions
Two Alleles: allele1, allele2
Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 16 / 46

Basic Definitions
Two Alleles: allele1, allele2
An allele is one of two or more versions of a gene. An individualinherits two alleles for each gene, one from each parent.
Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 17 / 46

Source of Data for Allelic Frequency
Outline
1 Biography
2 Overview
3 Basic Definitions
4 Source of Data for Allelic Frequency
5 Allelic Frequency Analysis
6 Allelic Frequency Using MapReduce/Hadoop
7 Running Allelic Frequency Analysis
Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 18 / 46

Source of Data for Allelic Frequency
VCF to Bioset
Sample → FASTQ Data → DNA-Seq → VCF → Bioset
Bioset Record Elements:
1. chromosomeID
2. startPosition
3. stopPosition
4. allele1
5. allele2
6. referenceGenome
7. mutationClass
...
Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 19 / 46

Source of Data for Allelic Frequency
Size of Data for Analysis
One Bioset = 4.3 million records
For Allelic frequency: form two groups: Group-A, Group-B
Keep two sets of the same data:
one set for Group-Aone set for Group-B
Group-A = 6,000 Biosets
Group-B = 9,000 Biosets
6,000 + 9,000 = 15,000
15,000 Total Biosets to analyze
15,000 x 4.3M = 64.5 Billion records
Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 20 / 46

Allelic Frequency Analysis
Outline
1 Biography
2 Overview
3 Basic Definitions
4 Source of Data for Allelic Frequency
5 Allelic Frequency Analysis
6 Allelic Frequency Using MapReduce/Hadoop
7 Running Allelic Frequency Analysis
Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 21 / 46

Allelic Frequency Analysis
Allelic Frequency Analysis
Given
Group-A = set of biosets = {A1,A2, ...,An}Group-B = set of biosets = {B1,B2, ...,Bm}
Find
Allelic Frequecy for every chromosomeID, start, stop, allele
Find p-value for every chromosomeID, start, stop, allele
Find top-100 p-values
Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 22 / 46

Allelic Frequency Analysis
Allelic Frequency by Example
Group-A: 6 biosets
Bioset-ID Allele-1 Allele-2
1 A C2 A A3 A C4 G G5 A A6 AC T
Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 23 / 46

Allelic Frequency Analysis
Allelic Frequency by Example...
Group-B: 5 biosets
Bioset-ID Allele-1 Allele-2
7 A A8 C C9 A C10 A A11 A A
Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 24 / 46

Allelic Frequency Analysis
Allelic Frequency by Example...
Create Frequency Table for Group-A and Group-B:
Allele Group-A Group-A Group-B Group-BKnown Others Known Others
A 6 6 7 3C 2 10 3 7G 2 10 0 10AC 1 11 0 10T 1 11 0 10
Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 25 / 46

Allelic Frequency Analysis
Allelic Frequency by Example...
Create a Contigency Table for each Allele: for Allele A:
Known Others
Group-A 6 6Group-B 7 3
Now we can apply the Fisher’s Exact Test or other tests for analysis...
Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 26 / 46

Allelic Frequency Analysis
Fisher’s Exact Test Using R
# R (version 2.15.1)
> mytable = rbind( c(6, 6), c(7, 3) );
> mytable
[,1] [,2]
[1,] 6 6
[2,] 7 3
> fisher.test(mytable)
Fisher’s Exact Test for Count Data
data: mytable
p-value = 0.4149
Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 27 / 46

Allelic Frequency Analysis
Fisher’s Exact Test Definition
Note that a, b, c , d refers to the values that wegenerate as a 2× 2 contingency table shown below:
Known Others Row Totals
Group-A a b a + bGroup-B c d c + d
Column Totals a + c b + d n = a + b + c + d
p =
(a + b
a
)(c + d
c
)(
n
a + c
) =(a + b)! (c + d)! (a + c)! (b + d)!
a! b! c! d! n!
Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 28 / 46

Allelic Frequency Using MapReduce/Hadoop
Outline
1 Biography
2 Overview
3 Basic Definitions
4 Source of Data for Allelic Frequency
5 Allelic Frequency Analysis
6 Allelic Frequency Using MapReduce/Hadoop
7 Running Allelic Frequency Analysis
Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 29 / 46

Allelic Frequency Using MapReduce/Hadoop
Allelic Frequency Using MapReduce/Hadoop
MapReduce PHASE-1:
Eliminate Duplicate Bioset Records
MapReduce PHASE-2:
Allelic Frequency using Fisher’s Exact Test
MapReduce PHASE-3:
Find Top-100
Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 30 / 46

Allelic Frequency Using MapReduce/Hadoop
Allelic Frequency Using MapReduce/Hadoop
MapReduce PHASE-1:
Eliminate Duplicate Bioset Records
MapReduce PHASE-2:
Allelic Frequency using Fisher’s Exact Test
MapReduce PHASE-3:
Find Top-100
Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 30 / 46

Allelic Frequency Using MapReduce/Hadoop
Allelic Frequency Using MapReduce/Hadoop
MapReduce PHASE-1:
Eliminate Duplicate Bioset Records
MapReduce PHASE-2:
Allelic Frequency using Fisher’s Exact Test
MapReduce PHASE-3:
Find Top-100
Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 30 / 46

Allelic Frequency Using MapReduce/Hadoop
MapReduce PHASE-1: Eliminate Duplicate Records
Mapper:
// key = chrID:start:stop:group:allele1:allele2:reference
// group = {a, b}
// value = mutationClass
map(key, value) {
emit(key, value);
}
Reducer:
// key = chrID:start:stop:group:allele1:allele2:reference
// values = List<mutationClass>
reduce(key, values) {
maxMC = max(values); // max. mutationClass
outputKey = chrID:start:stop
outputValue = group:allele1:allele2:reference:maxMC
emit(outputKey, outputValue);
}
Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 31 / 46

Allelic Frequency Using MapReduce/Hadoop
MapReduce PHASE-1: Eliminate Duplicate Records
Mapper:
// key = chrID:start:stop:group:allele1:allele2:reference
// group = {a, b}
// value = mutationClass
map(key, value) {
emit(key, value);
}
Reducer:
// key = chrID:start:stop:group:allele1:allele2:reference
// values = List<mutationClass>
reduce(key, values) {
maxMC = max(values); // max. mutationClass
outputKey = chrID:start:stop
outputValue = group:allele1:allele2:reference:maxMC
emit(outputKey, outputValue);
}Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 31 / 46

Allelic Frequency Using MapReduce/Hadoop
MapReduce PHASE-2: Allelic Frequency using Fisher’sExact Test: Mapper
Mapper:
// key = chrID:start:stop
// group = {a, b}
// value = group:allele1:allele2:reference:mutationClass
map(key, value) {
emit(key, value);
}
Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 32 / 46

Allelic Frequency Using MapReduce/Hadoop
MapReduce PHASE-2: Allelic Frequency using Fisher’sExact Test: Reducer
Reducer:
// key = chrID:start:stop
// values = List<group:allele1:allele2:reference:mutationClass>
// group = {a, b}
reduce(key, values) {
setOfAlleles = all alleles in group A and group B;
freqTableA = (allele, known, others);
freqTableB = (allele, known, others);
for (String allele : setOfAlleles) {
contingecyTable = (allele, N11, N12, N21, N22);
pvalue = FishersExactTest(contingecyTable);
emit (value, entireRecored)
}
}
Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 33 / 46

Allelic Frequency Using MapReduce/Hadoop
MapReduce PHASE-3: Find Top-100
Now that we have:
p-value:chrID:start:stop:allele
How we can find top-100 p-values (close to 0.00)?
SQL solution:
SELECT *
FROM allele_frequency_table
ORDER BY pvalue LIMIT 100;
Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 34 / 46

Allelic Frequency Using MapReduce/Hadoop
MapReduce PHASE-3: Find Top-100
top100() defined as:
Let P = {p1, p2, ..., pn}Then top100(P) = {s1, s2, ..., s100}where si ∈ P and s1 ≤ s2 ≤ ... ≤ s100
NOTE: top100 for Allelic Frequency means: find smallest p-values,which are closer to 0.00
Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 35 / 46
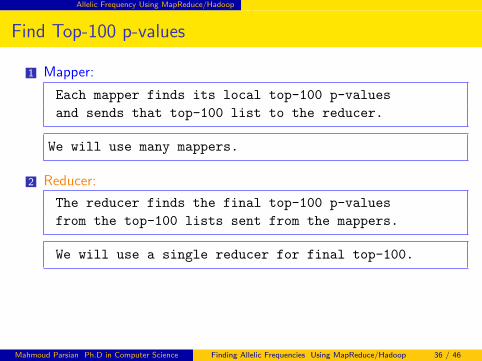
Allelic Frequency Using MapReduce/Hadoop
Find Top-100 p-values
1 Mapper:
Each mapper finds its local top-100 p-values
and sends that top-100 list to the reducer.
We will use many mappers.
2 Reducer:
The reducer finds the final top-100 p-values
from the top-100 lists sent from the mappers.
We will use a single reducer for final top-100.
Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 36 / 46

Allelic Frequency Using MapReduce/Hadoop
Top-100 p-values Creates a Monoid
Associativity:top100(x, top100(y, z)) = top100( top100(x, y), z)
Identity:top100(x, {}) = top100({}, x) = top100(x)
Therefore, we can have a combiner as well:
The combiner finds the top-100 p-values
from the top-100 lists sent from the mappers.
Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 37 / 46

Allelic Frequency Using MapReduce/Hadoop
MapReduce for Top-100 p-values: Mapper
public class Top100Mapper ... {
private SortedMap<Double, String> top100 =
new TreeMap<Double, String>();
// key is the pvalue of double type and range is 0.00 to 1.00
// value is the entire record of allelic frequency
// output (includes pvalue)
map(Double key, String entireRecord) {
top100.put(key, value); // sort by pvalue
if (top100.size() > 100) {
// remove the greatest pvalue
top100.remove(top100.lastKey());
}
}
// called once at the end of the mapper task.
cleanup() { ...}
}
Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 38 / 46

Allelic Frequency Using MapReduce/Hadoop
MapReduce for Top-100 p-values: Mapper
public class Top100Mapper ... {
private SortedMap<Double, String> top100 =
new TreeMap<Double, String>();
map(Double key, String entireRecord) {...}
// called once at the end of the mapper task.
cleanup() {
for (Map.Entry<Double, String> entry : top100.entrySet() {
Double pvalue = entry.getKey();
String entireRecord = entry.getValue();
String outputValue = pair(pvalue, entireRecord);
// NULL key will send all key-value
// pairs to a single reducer only
emit(NULL, outputValue);
}
}
}
Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 39 / 46

Allelic Frequency Using MapReduce/Hadoop
MapReduce for Top-100 p-values: Reducer
reduce(NullWritable key, Iterable<pair<Double, String>> values) {
SortedMap<Double, String> finalTop100 =
new TreeMap<Double, String>();
for (pair(Double, String) value : values) {
Double pvalue = value.pvalue;
String entireRecord = value.entireRecord;
finalTop100.put(pvalue, entireRecord);
if (finalTop100.size() > 100) {
// remove the greatest pvalue
finalTop100.remove(finalTop100.lastKey());
}
}
// now, we have the final top 100 list
emitFinalTop100();
}
Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 40 / 46

Allelic Frequency Using MapReduce/Hadoop
MapReduce for Top-100 p-values: Reducer
reduce(NullWritable key, Iterable<pair<Double, String>> values) {
...
// now, we have the final top 100 list
// emitFinalTop100();
for (Map.Entry<Double, String> entry : finalTop100.entrySet() {
Double pvalue = entry.getKey();
String entireRecord = entry.getValue();
emit(pvalue, entireRecord);
}
}
Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 41 / 46

Running Allelic Frequency Analysis
Outline
1 Biography
2 Overview
3 Basic Definitions
4 Source of Data for Allelic Frequency
5 Allelic Frequency Analysis
6 Allelic Frequency Using MapReduce/Hadoop
7 Running Allelic Frequency Analysis
Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 42 / 46

Running Allelic Frequency Analysis
Sample Run
$ cat allelic_freq_test_100_by_100.sh}
#!/bin/bash
client=AllelicFrequencyClient
groupA=bioset_ids.txt.100.a
groupB=bioset_ids.txt.100.b
$client interactive 0 $groupA $groupB
$ wc -l bioset_ids.txt.100.a bioset_ids.txt.100.b}
100 bioset_ids.txt.100.a
100 bioset_ids.txt.100.b
$ cat bioset_ids.txt.100.a
427033
427039
...
$ cat bioset_ids.txt.100.b
656714
656720
...
Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 43 / 46

Running Allelic Frequency Analysis
Sample Run
$ ./allelic_freq_test_100_by_100.sh
Wed Feb 12 15:27:10 PST 2014
Feb 12 2014 15:27:10 [INFO ] [AllelicFrequencyClient] - executionType: interactive
Feb 12 2014 15:27:10 [INFO ] [AllelicFrequencyClient] - requestID: 0
Feb 12 2014 15:27:10 [INFO ] [AllelicFrequencyClient] - GroupA: bioset_ids.txt.100.a
Feb 12 2014 15:27:10 [INFO ] [AllelicFrequencyClient] - GroupB: bioset_ids.txt.100.b
...
Feb 12 2014 15:27:12 [main] [INFO ] [JobClient] - Running job: job_201401170112_0644
Feb 12 2014 15:27:13 [main] [INFO ] [JobClient] - map 0% reduce 0%
Feb 12 2014 15:27:32 [main] [INFO ] [JobClient] - map 11% reduce 0%
...
Feb 12 2014 15:28:39 [main] [INFO ] [JobClient] - map 100% reduce 94%
Feb 12 2014 15:28:40 [main] [INFO ] [JobClient] - map 100% reduce 100%
Feb 12 2014 15:28:45 [main] [INFO ] [JobClient] - Job complete: job_201401170112_0644
...
Feb 12 2014 15:28:45 [main] [INFO ] [JobClient] - Map-Reduce Framework
Feb 12 2014 15:28:45 [main] [INFO ] [JobClient] - Map output materialized bytes=134376521
Feb 12 2014 15:28:45 [main] [INFO ] [JobClient] - Map input records=9,352,649
Feb 12 2014 15:28:45 [main] [INFO ] [JobClient] - Reduce input groups=134,894
Feb 12 2014 15:28:45 [main] [INFO ] [JobClient] - Reduce output records=53,557
Feb 12 2014 15:28:45 [main] [INFO ] [AllelicFrequencyDriver] - run(): jobSucceeded=true
Feb 12 2014 15:28:45 [main] [INFO ] [AllelicFrequencyDriver] - run(): Job Finished in 94.423 seconds
Feb 12 2014 15:28:45 [main] [INFO ] [AllelicFrequencyDriver] - submitJob(): runStatus=0
Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 44 / 46

Running Allelic Frequency Analysis
Sample Run
$ hadoop fs -cat /biomarker/output/germline/0/part* | sort -g | head
3.9437604668735787E-115:1:2483112:2483112:32872,20773539,20774078,:8:C:C:198:2:0:200:147567
3.9437604668735787E-115:12:51372604:51373968:100191,:15:1365BP:1365BP:198:2:0:200:null
7.770768062434234E-115:13:113588869:113588869:10323,:8:G:G:1:199:199:1:40972240
2.668611249251343E-113:13:113587440:113587440:10323,:8:G:G:197:3:0:200:10286004
5.206158192319811E-111:13:113587440:113587440:10323,:8:C:C:1:199:197:3:10286004
7.693839401259585E-111:1:16682451:16684181:79290,:15:1,731BP:1,731BP:2:198:198:2:null
5.580066122186588E-110:13:113588869:113588869:10323,:8:C:C:195:5:0:200:null
2.6288489416374975E-109:17:36760271:36779253:15243,15247,:15:18,983BP:18,983BP:1:199:196:4:null
1.915822701950223E-108:17:36760271:36779253:15243,15247,:15:18983BP:18983BP:194:6:0:200:null
5.665361418625481E-107:1:2483112:2483112:32872,20773539,20774078,:8:G:G:0:200:193:7:147567
Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 45 / 46

Running Allelic Frequency Analysis
References
WikipediaAllele Frequencyhttp://en.wikipedia.org/wiki/Allele_frequency
Max Kuhn and Kjell JohnsonApplied Predictive ModelingSpringer, 2013
Mahmoud Parsian Ph.D in Computer Science Finding Allelic Frequencies Using MapReduce/Hadoop 46 / 46