filtering and recommender systems content-based and collaborative some of the slides based on...
Post on 19-Dec-2015
216 views
TRANSCRIPT

Filtering and Recommender
SystemsContent-based
and Collaborative
Some of the slides based
On Mooney’s Slides

Feature selection & LSI
• Both MI and LSI are dimensionality reduction techniques
• MI is looking to reduce dimensions by looking at a subset of the original dimensions
– LSI looks instead at a linear combination of the subset of the original dimensions (Good: Can automatically capture sets of dimensions that are more predictive. Bad: the new features may not have any significance to the user)
• MI does feature selection w.r.t. a classification task (MI is being computed between a feature and a class)
– LSI does dimensionality reduction independent of the classes (just looks at data variance)
– ..where as MI needs to increase variance across classes and reduce variance within class
• Doing this is called LDA (linear discriminant analysis)
• LSI is a special case of LDA where each point defines its own class
Digression

Personalization• Recommenders are instances of personalization
software.• Personalization concerns adapting to the
individual needs, interests, and preferences of each user.
• Includes:– Recommending– Filtering– Predicting (e.g. form or calendar appt. completion)
• From a business perspective, it is viewed as part of Customer Relationship Management (CRM).

Feedback & Prediction/Recommendation
• Traditional IR has a single user—probably working in single-shot modes– Relevance feedback…
• WEB search engines have:– Working continually
• User profiling– Profile is a “model” of the user
• (and also Relevance feedback)– Many users
• Collaborative filtering– Propagate user preferences to other users…
You know this one

Recommender Systems in Use
• Systems for recommending items (e.g. books, movies, CD’s, web pages, newsgroup messages) to users based on examples of their preferences.
• Many on-line stores provide recommendations (e.g. Amazon, CDNow).
• Recommenders have been shown to substantially increase sales at on-line stores.

Feedback Detection
– Click certain pages in certain order while ignore most pages.
– Read some clicked pages longer than some other clicked pages.
– Save/print certain clicked pages.
– Follow some links in clicked pages to reach more pages.
– Buy items/Put them in wish-lists/Shopping Carts
– Explicitly ask users to rate items/pages
Non-Intrusive Intrusive

Content/Profile-basedRedMars
Juras-sicPark
LostWorld
2001
Foundation
Differ-enceEngine
Machine Learning
UserProfile
Neuro-mancer
2010
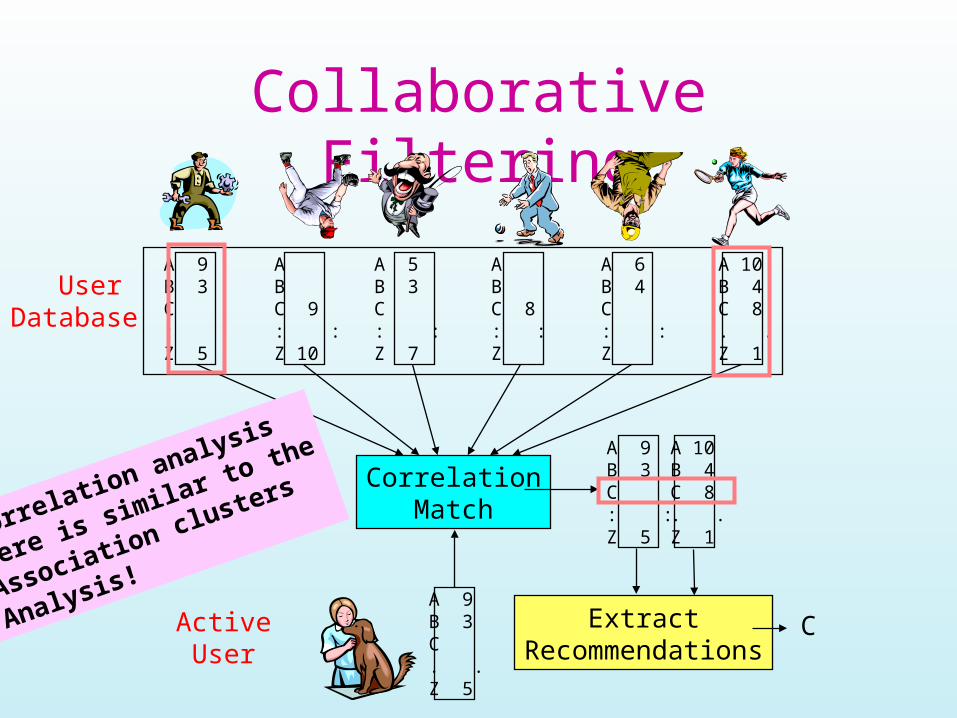
Collaborative Filtering
A 9B 3C: :Z 5
A B C 9: :Z 10
A 5B 3C: : Z 7
A B C 8: : Z
A 6B 4C: :Z
A 10B 4C 8. .Z 1
UserDatabase
ActiveUser
CorrelationMatch
A 9B 3C . .Z 5
A 9B 3C: :Z 5
A 10B 4C 8. .Z 1
ExtractRecommendations
C
Content-based vs. CollaborativeRecommendation
Collaborative Filtering
A 9B 3C: :Z 5
A B C 9: :Z 10
A 5B 3C: : Z 7
A B C 8: : Z
A 6B 4C: :Z
A 10B 4C 8. .Z 1
UserDatabase
ActiveUser
CorrelationMatch
A 9B 3C . .Z 5
A 9B 3C: :Z 5
A 10B 4C 8. .Z 1
ExtractRecommendations
C
Correlation analysis
Here is similar to the
Association clusters
Analysis!

Item-User Matrix
• The input to the collaborative filtering algorithm is an mxn matrix where rows are items and columns are users – Sort of like term-document matrix (items are terms
and documents are users)
• Can think of items as vectors in the space of users (or users as vectors in the space of items)– Can do scalar clusters etc..

Collaborative Filtering Method
• Weight all users with respect to similarity with the active user.
• Select a subset of the users (neighbors) to use as predictors.
• Normalize ratings and compute a prediction from a weighted combination of the selected neighbors’ ratings.
• Present items with highest predicted ratings as recommendations.

Similarity Weighting• Typically use Pearson correlation coefficient
between ratings for active user, a, and another user, u.
ua rr
uaua
rrc
),(covar
,
ra and ru are the ratings vectors for the m items rated by both a and u
ri,j is user i’s rating for item jm
rrrrrr
m
iuiuaia
ua
1
,, ))((),(covar
m
rrm
ixix
rx
1
2, )(
m
rr
m
iix
x
1
,

Neighbor Selection
• For a given active user, a, select correlated users to serve as source of predictions.
• Standard approach is to use the most similar n users, u, based on similarity weights, wa,u
• Alternate approach is to include all users whose similarity weight is above a given threshold.

Rating Prediction• Predict a rating, pa,i, for each item i, for active user,
a, by using the n selected neighbor users,
u {1,2,…n}.• To account for users different ratings levels, base
predictions on differences from a user’s average rating.
• Weight users’ ratings contribution by their similarity to the active user.
n
uua
n
uuiuua
aia
w
rrwrp
1,
1,,
,
||
)(
ri,j is user i’s rating for item j
ua rr
uaua
rrc
),(covar
,

Significance Weighting
• Important not to trust correlations based on very few co-rated items.
• Include significance weights, sa,u, based on number of co-rated items, m.
uauaua csw ,,,
50 if
50
50 if 1, m
mm
s ua
ua rr
uaua
rrc
),(covar
,

Problems with Collaborative Filtering• Cold Start: There needs to be enough other users already in the
system to find a match.• Sparsity: If there are many items to be recommended, even if
there are many users, the user/ratings matrix is sparse, and it is hard to find users that have rated the same items.
• First Rater: Cannot recommend an item that has not been previously rated.– New items– Esoteric items
• Popularity Bias: Cannot recommend items to someone with unique tastes. – Tends to recommend popular items.
• WHAT DO YOU MEAN YOU DON’T CARE FOR BRITNEY SPEARS YOU DUNDERHEAD? #$%$%$&^

Content-Based Recommending
• Recommendations are based on information on the content of items rather than on other users’ opinions.
• Uses machine learning algorithms to induce a profile of the users preferences from examples based on a featural description of content.
• Lots of systems

Advantages of Content-Based Approach
• No need for data on other users.– No cold-start or sparsity problems.
• Able to recommend to users with unique tastes.• Able to recommend new and unpopular items
– No first-rater problem.
• Can provide explanations of recommended items by listing content-features that caused an item to be recommended.
• Well-known technology The entire field of Classification Learning is at (y)our disposal!

Disadvantages of Content-Based Method
• Requires content that can be encoded as meaningful features.
• Users’ tastes must be represented as a learnable function of these content features.
• Unable to exploit quality judgments of other users.– Unless these are somehow included in the content
features.

Content-Boosted CF - I
Content-Based Predictor
Training Examples
Pseudo User-ratings Vector
Items with Predicted Ratings
User-ratings Vector
User-rated ItemsUnrated Items

Content-Boosted CF - II
• Compute pseudo user ratings matrix– Full matrix – approximates actual full user ratings
matrix
• Perform CF– Using Pearson corr. between pseudo user-rating
vectors
User RatingsMatrix
Pseudo UserRatings Matrix
Content-BasedPredictor

Why can’t the pseudo ratings be used to help content-based filtering?
• How about using the pseudo ratings to improve a content-based filter itself?– Learn a NBC classifier C0 using the few items for which we have
user ratings– Use C0 to predict the ratings for the rest of the items– Loop
• Learn a new classifier C1 using all the ratings (real and predicted)• Use C1 to (re)-predict the ratings for all the unknown items
– Until no change in ratings • With a small change, this actually works in finding a better
classifier! – Change: Keep the class posterior prediction (rather than just the
max class)• This is called expectation maximization
– Very useful on web where you have tons of data, but very little of it is labelled
– Reminds you of K-means, doesn’t it?


(boosted) content filtering

Co-training• Suppose each instance has two parts:
x = [x1, x2]
x1, x2 conditionally independent given f(x)
• Suppose each half can be used to classify instancef1, f2 such that f1(x1) = f2(x2) = f(x)
• Suppose f1, f2 are learnablef1 H1, f2 H2, learning algorithms A1, A2
Unlabeled Instances
[x1, x2]
Labeled Instances
<[x1, x2], f1(x1)>A1 f2
Hypothesis
~A2
Small labeled data neededYou train me—I train you…

Observations
• Can apply A1 to generate as much training data as one wants– If x1 is conditionally independent of x2 / f(x),– then the error in the labels produced by A1 – will look like random noise to A2 !!!
• Thus no limit to quality of the hypothesis A2 can make

It really works!• Learning to classify web pages as course pages
– x1 = bag of words on a page– x2 = bag of words from all anchors pointing to a page
• Naïve Bayes classifiers– 12 labeled pages– 1039 unlabeled


Focussed Crawling• Cho paper
– Looks at heuristics for managing URL queue
– Aim1: completeness
– Aim2: just topic pages
• Prioritize if word in anchor / URL
• Heuristics: – Pagerank
– #backlinks

Modified Algorithm
• Page is hot if:– Contains keyword in title, or– Contains 10 instances of keyword in body, or– Distance(page, hot-page) < 3

Results
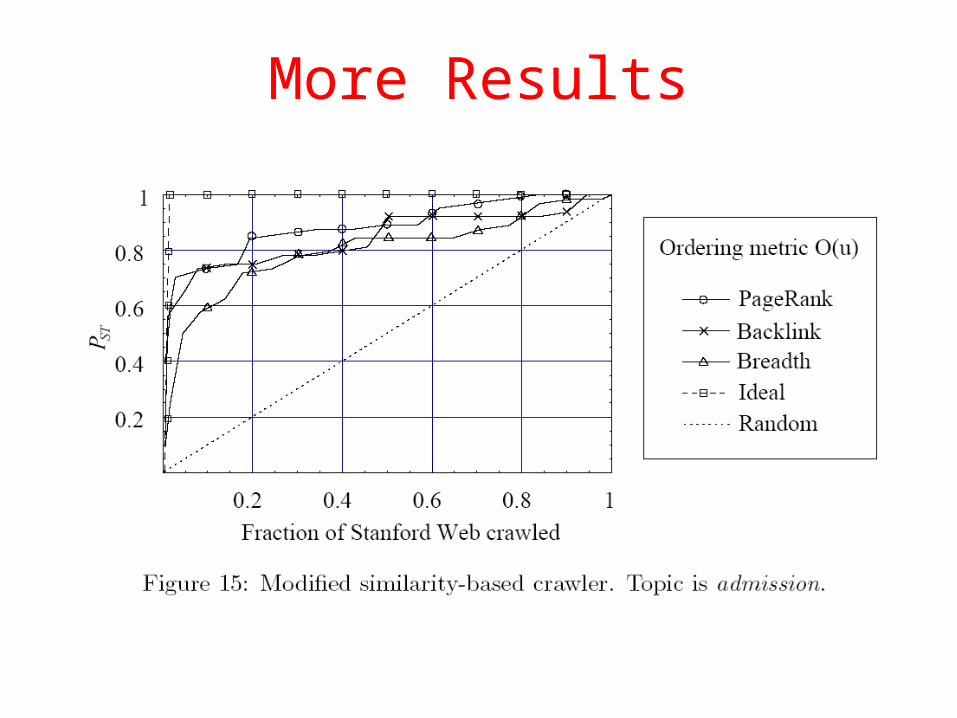
More Results