fighting against chaotically separated values with embulk
TRANSCRIPT

Fighting Against Chaotically Separated Values with Embulk
Sadayuki Furuhashi Founder & Software Architect
csv,conf,v2

A little about me…
Sadayuki FuruhashiAn open-source hacker.
github: @frsyuki
A founder of Treasure Data, Inc. located in Silicon Valley.
Fluentd - Unifid log collection infrastracture Embulk - Plugin-based ETL tool
OSS projects I founded:

It's like JSON. but fast and small.
A little about me…

What’s Embulk?
> An open-source parallel bulk data loader > loads records from “A” to “B”
> using plugins > for various kinds of “A” and “B”
> to make data loading easy. > which was very painful…
Storage, RDBMS, NoSQL, Cloud Service,
etc.
broken records,transactions (idempotency),
performance, …

The pains of bulk data loading
Example: load a 10GB CSV file to PostgreSQL > 1. Run a script → fails! > 2. Improve the script to normalize records
• Convert ”2015-01-27T19:05:00Z” → “2015-01-27 19:05:00 UTC”
• Convert “\N" → “”
• many more normalization…
> 3. Second attempt → another error! • Convert “Inf” → “Infinity”
> 4. Improve the script, fix, retry, fix, retry… > 5. Oh, some data are loaded twice!?

The pains of bulk data loading
Example: load a 10GB CSV file to PostgreSQL > 6. Ok, the script worked well today. > 7. Register it to cron to sync data every day. > 8. One day… it fails with another error
• Convert invalid UTF-8 byte sequence to U+FFFD

The pains of bulk data loading
Example: load 10GB CSV × 720 files > Most of scripts are slow.
• People have little time to optimize bulk load scripts
> One file takes 1 hour → 720 files takes 1 month (!?)
A lot of efforts for each formats & storages: > XML, JSON, Apache log format (+some custom), … > SAM, BED, BAI2, HDF5, TDE, SequenceFile, RCFile… > MongoDB, Elasticsearch, Redshift, Salesforce, …

The problems:
> Difficult to parse files correctly > How is the CSV file formatted?
> Complex error handling > How to detect and remove broken records robustly?
> Transactional load, or idempotent retrying > How to retry without duplicated loading?
> Hard to optimize performance > How to parallelize the bulk data loading?
> Many formats & storage in the world > How to save my time?

The problems at Treasure Data
What’s “Treasure Data”? > “Fast, powerful SQL access to big data from connected
applications and products, with no new infrastructure or special skills required.”
> Customers want to try Treasure Data, but > SEs write scripts to bulk load their data. Hard work :(
> Customers want to migrate their big data, but > It’s hard work :(
> Fluentd solved streaming data collection, but > bulk data loading is another problem.

Embulk is an open-source, plugin-based parallel bulk data loader that makes data loading easy and fast.
Solution:
IMPORTANT!

Amazon S3
MySQL
FTP
CSV Files
Access Logs
Salesforce.com
Elasticsearch
Cassandra
Hive
Redis
Reliable framework :-)
Parallel execution, transaction, auto guess, …and many by plugins.

Demo

$ embulk selfupdate$ embulk example demo$ vi demo/csv/sample_01.csv.gz$ embulk guess demo/seed.yml -o config.yml$ embulk run config.yml$ vi config.yml$ embulk run config.yml
out: type: postgresql host: localhost user: pg password: '' database: embulk_demo table: sample1 mode: replace
:%s/,/\t/g:%s/""/\\"/g# Created by Sada# This is a comment\N

Input Output
Embulk’s Plugin Architecture
Embulk Core
Executor Plugin
Filter Filter
Guess

Output
Embulk’s Plugin Architecture
Embulk Core
Executor Plugin
Filter Filter
GuessFileInput
Parser
Decoder

Guess
Embulk’s Plugin Architecture
Embulk Core
FileInput
Executor Plugin
Parser
Decoder
FileOutput
Formatter
Encoder
Filter Filter

Examples of Plugins (input)
File Input
Amazon S3
Google Cloud Storage
HDFS
Riak CS
SCP
FTP
…
CSV
JSON
MessagePack
Excel
Apache common logs
pcap format
XML / XPath
regexp
grok
…
File ParserInput
PostgreSQL
MySQL
Oracle
Vertica
Redis
Amazon Redshift
Amazon DynamoDB
Salesforce.com
JIRA
Mixpanel
…

Examples of Plugins (output)
File Output
Amazon S3
Google Cloud Storage
HDFS
SFTP
SCP
FTP
…
CSV
JSON
MessagePack
Excel
…
File FormatterOutput
PostgreSQL
MySQL
Oracle
Vertica
Redis
Amazon Redshift
Elasticsearch
Salesforce.com
Treasure Data
BigQuery
…

Examples of Plugins (filters)
> Filtering columns out by conditions
> Extracting values from a JSON column to columns (JSON flattening)
> Convert User-Agent strings to browser name, OS name, etc.
> Parse query string (“?k1=v1&k2=v2…”) to columns
> Applying SHA1 hash to a column
…
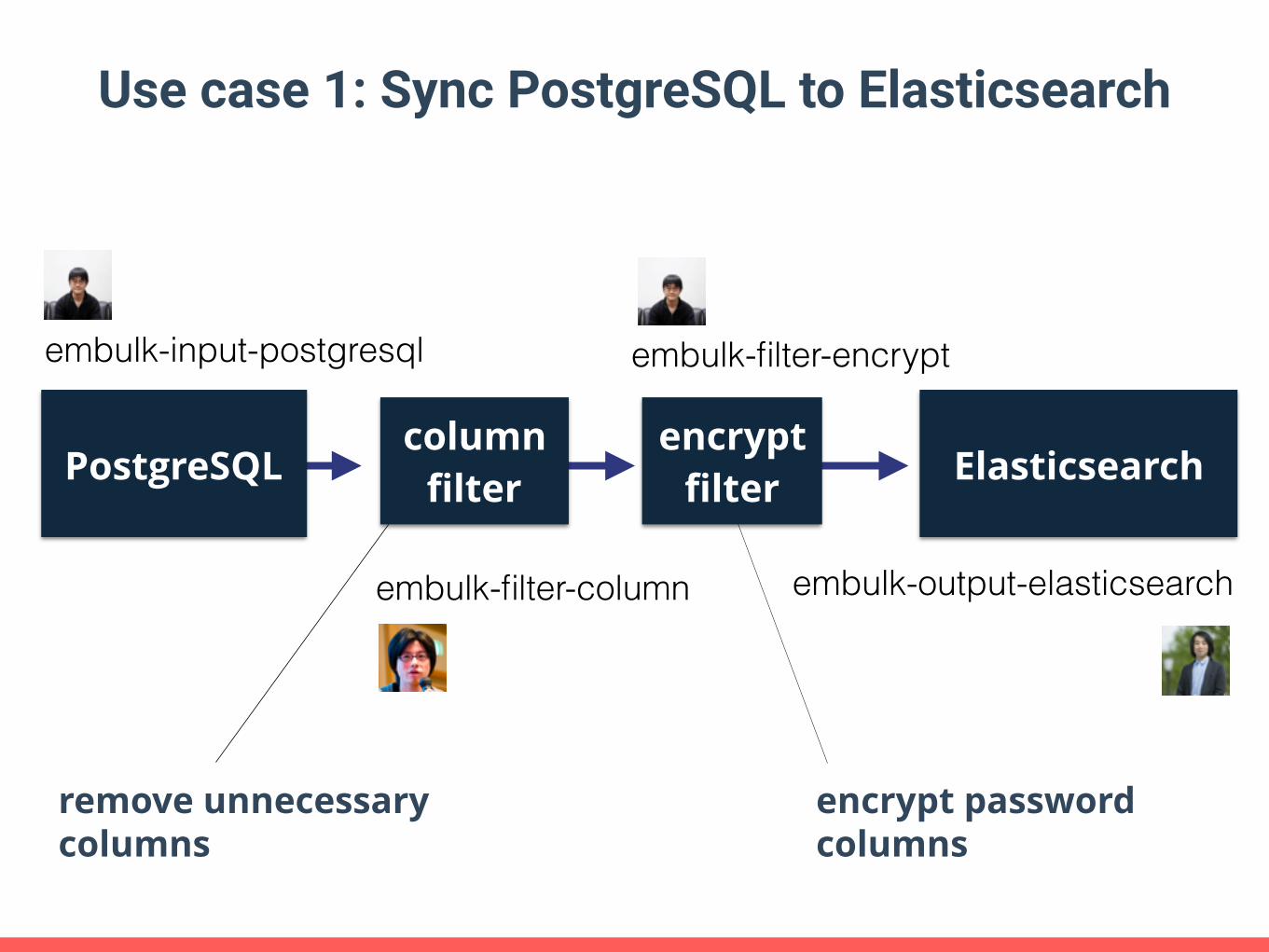
Use case 1: Sync PostgreSQL to Elasticsearch
embulk-input-postgresql
embulk-filter-column embulk-output-elasticsearch
PostgreSQLcolumn filter Elasticsearch
encrypt filter
embulk-filter-encrypt
remove unnecessary columns
encrypt password columns
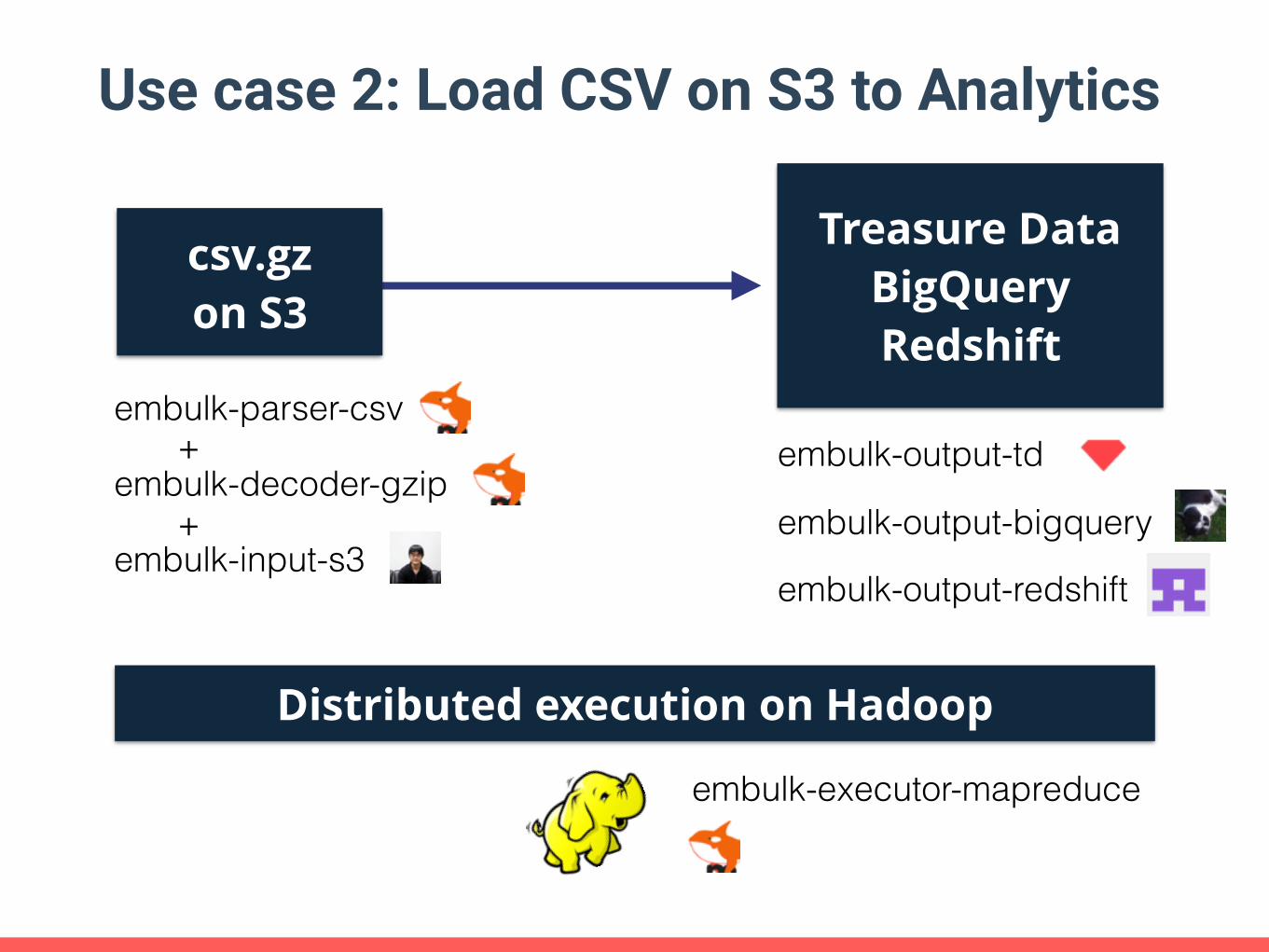
Use case 2: Load CSV on S3 to Analytics
embulk-parser-csv
embulk-decoder-gzip
embulk-input-s3
csv.gz on S3
Treasure Data BigQuery Redshift
+
+
embulk-output-td
embulk-output-bigquery
embulk-output-redshift
Distributed execution on Hadoop
embulk-executor-mapreduce

Use case 3: Embulk as a Service at Treasure Data
REST API call
MySQL

Internal Architecture

Plugin API
> A plugin is written in Java or Ruby (JRuby).
> A plugin implements “transaction” and “task”.
> transaction controls the entire bulk loading session.
> create a destination table, create a directory, commit the transaction, etc.
> transaction creates multiple tasks.
> tasks load load data.
> Embulk runs tasks in parallel.
> Embulk retries tasks if necessary.

Transaction stage & Task stage
Task
Transaction Task
Task
taskCount
{ taskIndex: 0, task: {…} }
{ taskIndex: 2, task: {…} }
runs on a single thread runs on multiple threads(or machines)

Transaction control
fileInput.transaction { parser.transaction { filters.transaction { formatter.transaction { fileOutput.transaction { executor.transaction { … } } } } } }
file input plugin
parser plugin
filter plugins
formatter plugin
file output plugin
executor plugin
Task Task

Task execution
parser.run(fileInput, pageOutput)
fileInput.open() formatter.open(fileOutput)
fileOutput.open()
parser plugin
file input plugin filter plugins
file output plugin
formatter plugin …Task Task …

Parallel execution of tasks
Task
Task
Task
Task
Threads
Task queue
run tasks in parallel
(embulk-executor-local-thread)
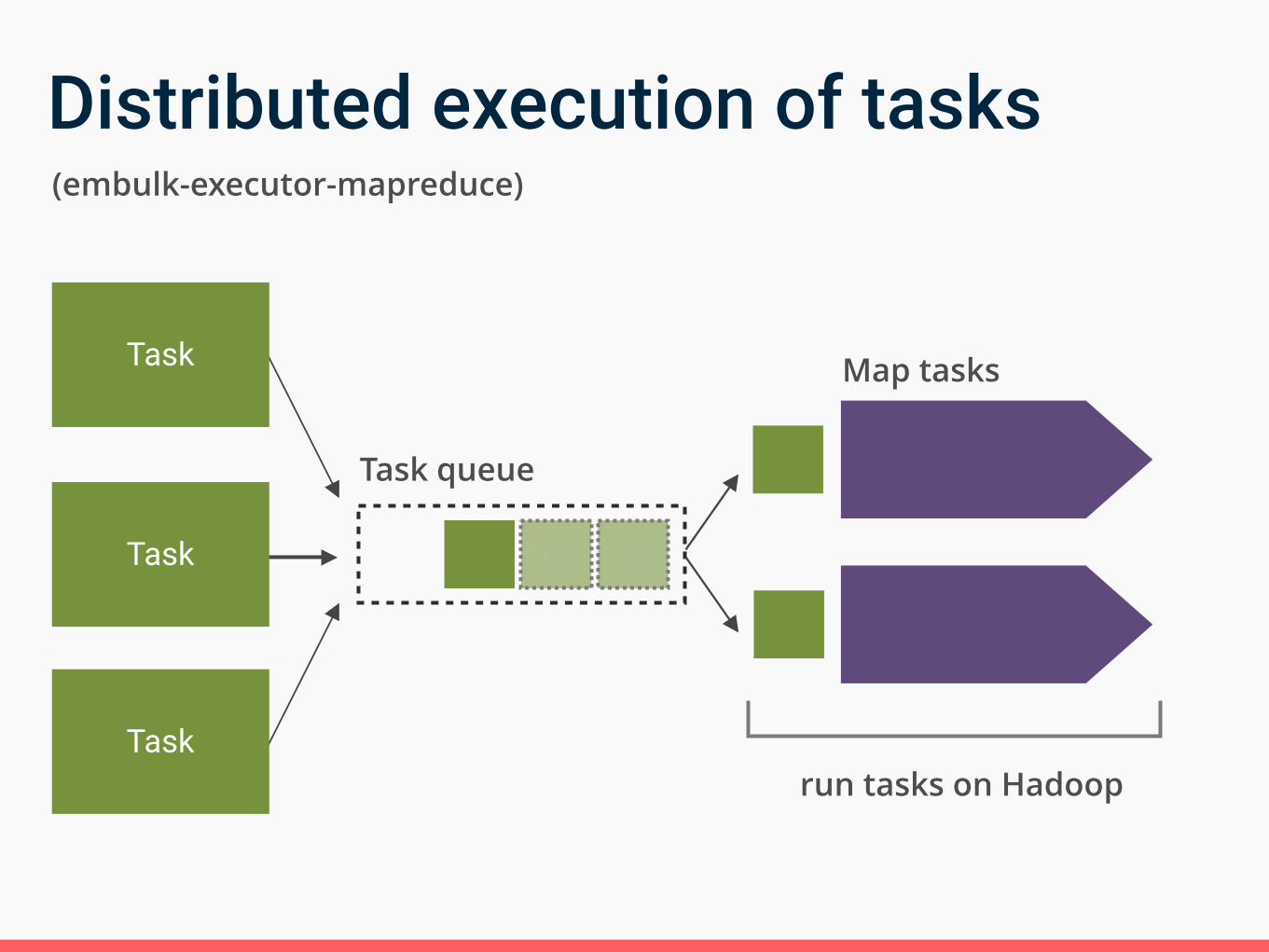
Distributed execution of tasks
Task
Task
Task
Task
Map tasks
Task queue
run tasks on Hadoop
(embulk-executor-mapreduce)

Distributed execution (w/ partitioning)
Task
Task
Task
Task
Map - Shuffle - Reduce
Task queue
run tasks on Hadoop
(embulk-executor-mapreduce)
Useful to partition data by hour or daybefore loading data to a storage.

Past & Future

What’s added since the first release?• v0.3 (Feb, 2015)
• Resuming • Filter plugin type
• v0.4 (Feb, 2015) • Plugin template generator • Incremental load (ConfigDiff) • Isolated ClassLoaders for Java plugins • Polyglot command launcher

What’s added since the first release?• v0.6 (Apr, 2015)
• Executor plugin type • Liquid template engine
• v0.7 (Aug, 2015) • EmbulkEmbed & Embulk::Runner • Plugin bundle (embulk-mkbundle) • JRuby 9000 • Gradle v2.6

What’s added since the first release?• v0.8 (Jan, 2016)
• JSON column type • Page scattaring for more parallel execution

Future plan• v0.9
• Error plugin type (#27) • Stats & metrics (#199)
• v0.10 • More Guess (#242, #235) • Multiple jobs using a single config file (#167)

Hacks(if time allows)
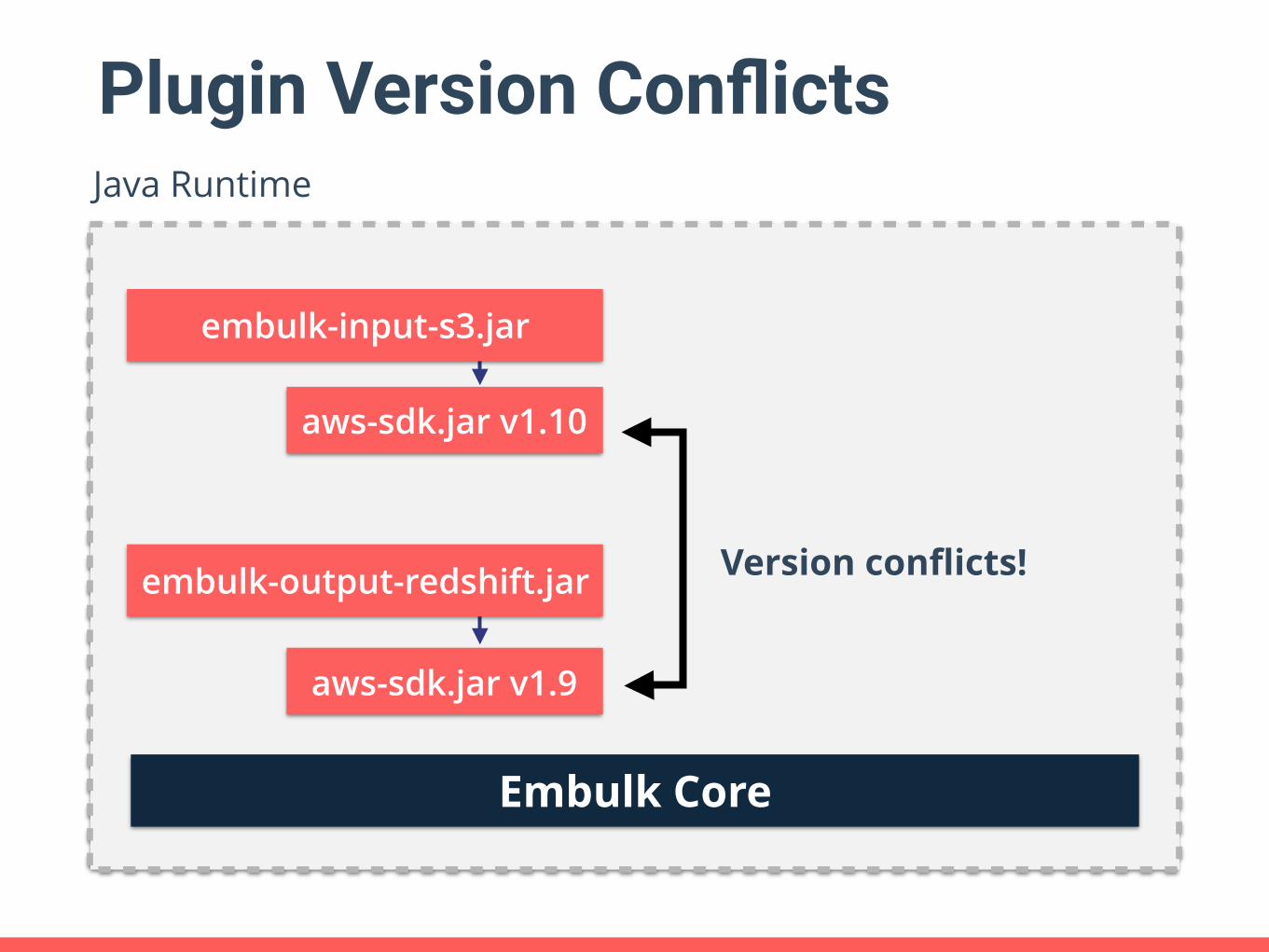
Plugin Version Conflicts
Embulk Core
Java Runtime
aws-sdk.jar v1.9
embulk-input-s3.jar
Version conflicts!
aws-sdk.jar v1.10
embulk-output-redshift.jar

Avoiding Conflicts in JVM
Embulk Core
Java Runtime
aws-sdk.jar v1.9
embulk-input-s3.jar
Isolated environments
aws-sdk.jar v1.10
embulk-output-redshift.jar
Class Loader 1
Class Loader 2

Liquid template engine• A config file can include variables.

./embulk.jar
$ ./embulk.jar guess example.yml
executable jar!

Header of embulk.jar
: <<BAT@echo offsetlocalset this=%~f0set java_args=
rem ...
java %java_args% -jar %this% %args%exit /b %ERRORLEVEL%BAT
# ...
exec java $java_args -jar "$0" "$@"exit 127
PK...

embulk.jar is a shell script
: <<BAT@echo offsetlocalset this=%~f0set java_args=
rem ...
java %java_args% -jar %this% %args%exit /b %ERRORLEVEL%BAT
# ...
exec java $java_args -jar "$0" "$@"exit 127
PK...
argument of “:” command (heredoc). “:” is a command that does nothing.
#!/bin/sh is optional. Empty first line means a shell script.
java -jar $0
shell script exits here (following data is ignored)

embulk.jar is a bat file
: <<BAT@echo offsetlocalset this=%~f0set java_args=
rem ...
java %java_args% -jar %this% %args%exit /b %ERRORLEVEL%BAT
# ...
exec java $java_args -jar "$0" "$@"exit 127
PK...
.bat exits here (following lines are ignored)
“:” means a comment-line

embulk.jar is a jar file
: <<BAT@echo offsetlocalset this=%~f0set java_args=
rem ...
java %java_args% -jar %this% %args%exit /b %ERRORLEVEL%BAT
# ...
exec java $java_args -jar "$0" "$@"exit 127
PK...
jar (zip) format ignores headers (file entries are in footer)

Type conversionEmbulk type systemInput type system Output type system
boolean
long
double
string
timestamp
boolean integer bigint double precision text varchar date timestamp timestamp with zone …
(e.g. PostgreSQL)
boolean integer long float double string array geo point geo shape … (e.g. Elasticsearch)