fast and furious decision tree induction
DESCRIPTION
Fast and Furious Decision Tree Induction. INSA Rennes. Andra BLAJ Emeline ESCOLIVET Simon MANDEMENT Gareth THIVEUX Nicolas DESFEUX Renaud PHILIPPE. Fast and Furious Decision Tree Induction. Contexte Technologies utilisées lors du projet Apprentissage automatique - PowerPoint PPT PresentationTRANSCRIPT

Fast and Furious Decision Tree Induction
INSA Rennes
1
Andra BLAJEmeline ESCOLIVETSimon MANDEMENTGareth THIVEUXNicolas DESFEUXRenaud PHILIPPE

Fast and Furious Decision Tree Induction
1. Contexte2. Technologies utilisées lors du projet
1. Apprentissage automatique2. Arbres de décision3. Map-Reduce4. Hadoop
3. Spécifications fonctionnelles1. Données présentes en entrée2. Données en sortie3. Arbres de décision dans l’application4. Parallélisation
4. Planification initiale5. Conclusion
2

1. Contexte
3

Contexte (1)
Origines du projet :• Projet lié aux activités de recherche de l’IRISA.• Equipe Texmex: exploitation de documents
multimédia.• Equipe Myriads: développement et
administration de systèmes distribués à large échelle.
4

Contexte (2)
Objectifs :• Créer des arbres aidant à la décision.• Utiliser des fichiers de données volumineux
pour trouver des règles de décision.• Généraliser le fonctionnement pour l’adapter
à tous les domaines.
5

Spécifications fonctionnelles (1)
Données en entrée
6
• 3 types de descripteurs:– discrete : données faisant partie d’une liste prédéfinie (ex: « oui », « non », « peut être »);– continuous : valeurs numériques ordonnées (ex : IMC);– text : phrases ou expressions;
6

Spécifications fonctionnelles (2)
77
Fichiers en entrée
• 2 fichiers en entrée:– .names :
• la liste des annotations possibles • une description du contenu du fichier de données• une description du type des descripteurs ou des
attributs
– .data : •les données et les annotations associées
52, Oui, 25, Grippe.45, Oui, 28, Rhume.28, Non, 20, Rhume.
Grippe, Rhume.age : continuous : ignore.boutons : discrete : cutoff = 15.imc : continuous.

2. Technologies utilisées lors du projet
8

Technologies utilisées (1)
• Discipline où un outil technologique est capable d’apprendre par lui-même.
• Sorte d’intelligence artificielle.• Plusieurs degrés de supervision.• Base de données d’exemples.• Décisions d’étiquetage précises.
Apprentissage AutomatiqueDéfinition - Fonctionnement
9

Technologies utilisées (2)
• Exemple déjà étiqueté : adapté à l’apprentissage automatique supervisé.
• Efficace avec un grand volume de données : – Processus d’apprentissage complet,– Étiquetage précis.
• Capable d’étiqueter de nouveaux exemples automatiquement.
Applications dans notre projet
10

Technologies utilisées (3)
• Outils d’aide à la décision et à l’exploration de données.
• Représentation à l’aide de nœuds et de feuilles.
• Populaire et simple d’utilisation.
Arbres de décisionsDéfinition - Fonctionnement
11

Technologies utilisées (4)
• Facile à comprendre et à utiliser.• Taille dépendante du nombre de questions, et
non de la taille des données.• Lisibilité du rendu. • Construction simple de rendu visuel (avec des
fichier XML et CSS par exemple).
Avantage pour notre projet
12

3. Spécifications fonctionnelles
13

Spécifications fonctionnelles (5)
Les arbres de décision dans l’application• Nœuds - chaque nœud correspond à une
question sur un attribut et à un ensemble d’exemples;
• Branches - chaque branche part d’un nœud et correspond à une réponse possible à la question posée en ce nœud;
• Feuilles - nœuds d’où ne part aucune branche (correspond à une classe).
14

Spécifications fonctionnelles (6)
• Etapes de la construction d’un arbre:– Apprendre une suite de questions/réponses
la plus "efficace" possible.– Isoler les classes.– Organiser les questions/réponses sous la
forme d’un arbre.
15

Spécifications fonctionnelles (3)
16
• type discrete : 1 question par valeur de l’attribut.• type continuous : pour une valeur donnée de
l’attribut, la question cherche à déterminer combien d’exemples ont une valeur supérieur ou inférieure à celle-ci.
• type text : 3 paramètres pris en compte– expert_length : nombre de mots à rechercher– expert_type : F-gram, S-gram, N-gram– expert_level : 3 niveaux de recherche
Génération des questions

Spécifications fonctionnelles (4)
17
Données en sortie
<? xml v e r s i on =" 1 . 0 " e n c o d i n g ="UTF-8" ?><Tree> <Node id =" 1 "> <Result . . . > < !-- compte-rendu des etiquettes . --> <Result number=“1" name=“grippe" percentage=“50" / > < !– Exemple de resultat --> <Question . . >+ < !-- question qui amenera a la creation de ces noeud --> <Question column=" Fumeur " value=“oui" entropy =" 1 " nbOcuurence=" 12 "> < !-- Exemple de question -->
<TrueNode id="2" / > <!– noeud où la réponse à la question est “oui” --> <Result...> <Question...> <FalseNode id="3" / > <!-- noeud où la réponse à la question est “non”-->
</Node></Tree>
• Format xml
•Visualisation graphique

Technologies utilisées (5)
• Opération exécutée en parallèle -> chaque nœud travaille indépendamment des autres, sur une partie du fichier d'entrée.
• Association à un couple ( clé , valeur ).• Opération spécifique sur chaque élément (ligne).• Traitement différent selon le type: Discrète,
Continue ou Texte.
MapReducePartie Map
18

Technologies utilisées (6)
• Nœuds esclaves font remonter l'information. • Calcul par les nœuds parents.• Groupement des couples ayant la même clé.• Le nœud origine peut, à la fin de l'opération
Reduce, donner une réponse.
MapReducePartie Reduce
19

Spécifications fonctionnelles (8)
Parallélisation
Fichier d’entrée:
1. savoir être et2. savoir faire3. sans faire savoir
Exemple de fonctionnement de MapReduce, pour compter les occurrences de mots dans un texte.
20

Technologies utilisées (7)
• Projet libre qui permet une implémentation de MapReduce.
• Un nœud maitre et des nœuds esclaves.• Fractionnement du traitement sur différentes
machines.
Hadoop
21

Technologies utilisées (8)
• Système de fichier distribué propre à Hadoop.• Répartition des données entre les Datanodes.• Assignation des tâches aux nœuds esclaves.• Retour du résultat au nœud maître.
Hadoop
22

Spécifications fonctionnelles (9)
• Spécification importante du projet → réduire le temps de construction des questions et du parcours de l’arbre.
• Solution envisagée → utilisation d’un cluster de machines via Hadoop (de manière plug-and-play).
• Parallélisation – répartition de plusieurs "job" sur plusieurs machines connectées.
23
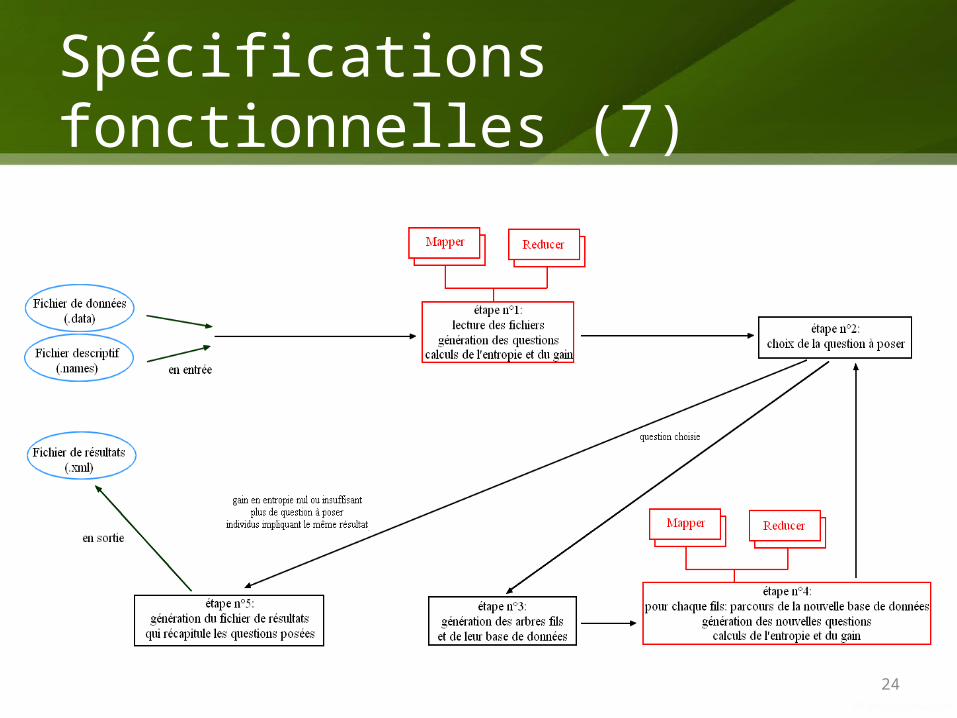
Spécifications fonctionnelles (7)
24

4. Planification initiale
25

Planification initiale (1)
26
Calendrier : - 7h par semaine - entre 25 et 28h en semaine de projet
- ajout de semaines de congés (semaine de partiels, vacances de Noël …)
Ressources : 6 personnes, ayant chacune la même charge
Détermination des tâches : 5 phases, chacune divisées entre 3 et 5 tâches, elles-mêmes découpées en sous-tâches et sous-sous-tâches
Estimation des durées : - 1re estimation basée sur le temps déjà passé sur les tâches - 2ème estimation grâce à du Planning Poker

Planification initiale (2)
27

5. Conclusion
28

Conclusion
29
Fast and Furious Decision Tree Induction :• Projet à l’origine d’équipes de l’IRISA.• Création des arbres aidant à la décision.• Généralisation le fonctionnement pour l’adapter à
tous les domaines.• Traitement des fichiers de données volumineux grâce
à une parallélisation des calculs gérée par les technologies Hadoop/MapReduce.
• Réussite et respect des délais => une bonne planification et un suivi régulier.