extracting knowledgebase from text
TRANSCRIPT

Creating Knowledge bases from text in absence of training data.
Sanghamitra Deb Accenture Technology Laboratory

Typical Business Process
Executive Summary
Business Decisions
hours of knowledge curation by experts

The Generalized approach of extracting text: Parsing
Tokenization Normalization Parsing Lemmatization
Tokenization: Separating sentences, words, remove special characters, phrase detections
Normalization: lowering words, word-sense disambiguation
Parsing: Detecting parts of speech, nouns, verbs etc.
Lemmatization: Remove plurals and different word forms to a single word (found in the dictionary).

Extract sentences that contain the specific attribute
POS tag and extract unigrams,bigramsand trigrams centered on nouns
Extract Features: words around nouns: bag of words/word vectors, position of the noun and length of sentence.
Train a Machine Learning model to predict which unigrams, bigrams or trigrams satisfy the specific relationship: for example the drug-disease treatment relationship.
Map training data to create a balanced positive and negative training set.
The Generalized approach of extracting text : ML

Extract sentences that contain the specific attribute
POS tag and extract unigrams,bigrams and trigrams centered on nouns
Extract Features: words around nouns: bag of words/word vectors, position of the noun and length of sentence.
Train a Machine Learning model to predict which unigrams, bigrams or trigrams satisfy the specific relationship: for example the drug-disease treatment relationship.
Map training data to create a balanced positive and negative training set.
The Generalized approach of extracting text : ML
How do we generate this training data?

A different Approach
Stanford
Replaces training data by encoding domain knowledge

The snorkel approach of Entity Extraction
Extract sentences that contain the specific attribute
POS tag and extract unigrams,bigramsand trigrams centered on nouns
Write Rules: Encode your domain knowledge into rules.
Validate Rules: coverage, conflicts, accuracy
Run learning: logistic regression, lstm, …
Examine a random set of candidates, create new rules
Observe the lowest accuracy(highest conflict) and edit rules
iterate

Data Dive: FDA Drug Labels

It is indicated for treating respiratory disorder caused due to allergy.
For the relief of symptoms of depression.
Evidence supporting efficacy of carbamazepine as an anticonvulsant was derived from active drug-controlled studies that enrolled patients with the following seizure types:
When oral therapy is not feasible and the strength , dosage form , and route of administration of the drug reasonably lend the preparation to the treatment of the condition
Data Dive: FDA Drug Labels

Data Dive: Clinical Trials Data
We present a case of a 10-year-old boy who had severe relapsing pancreatitis three times in two months within 3 weeks after starting treatment with methylphenidate ( ritalin ) due to attention deficit hyperactivity disorder (adhd).
The boy was generally healthy except for that he was newly diagnosed with adhd and started the use of methylphenidate ( ritalin ) for the past three weeks at a dose, of 30 mg daily.
We believe that the number of persons suffering from pancreatitis due to the use of ritalin is more than this published case.
Physicians must pay attention regarding this possible complication and it should be taken into consideration in every patient with abdominal pain who started consuming ritalin.

Final Goal: Entity and relationship Extraction
Data Dosage Drug Treats Disease
Side Effects Age Gender Ethnicity duration
10-year-old 0 0 0 0 1 0 0 0
pancreatitis-ritalin 0 0 0 1 0 0 0 0
adhd-ritalin 0 0 1 0 0 0 0 0
ritalin 0 1 0 0 0 0 0 0
30 mg 1 0 0 0 0 0 0 0
past three weeks 0 0 0 0 0 0 0 1
boy 0 0 0 0 0 1 0 0

Candidate Extraction
Using domain knowledge and language structure collect a set of high recall low precision. Typically this set should have 80% recall and 20% precision.
60% accuracy, too specific need to make it more general
30% accuracy, this looks fine
…………………………………………………………………………………………………………………………………………………………………….
…………………………………………………………………………………………………………………………………………………………………….

Automated Features:
pos-tags context dep-tree char-offsets

Rule Functions

Testing Rule Functions:
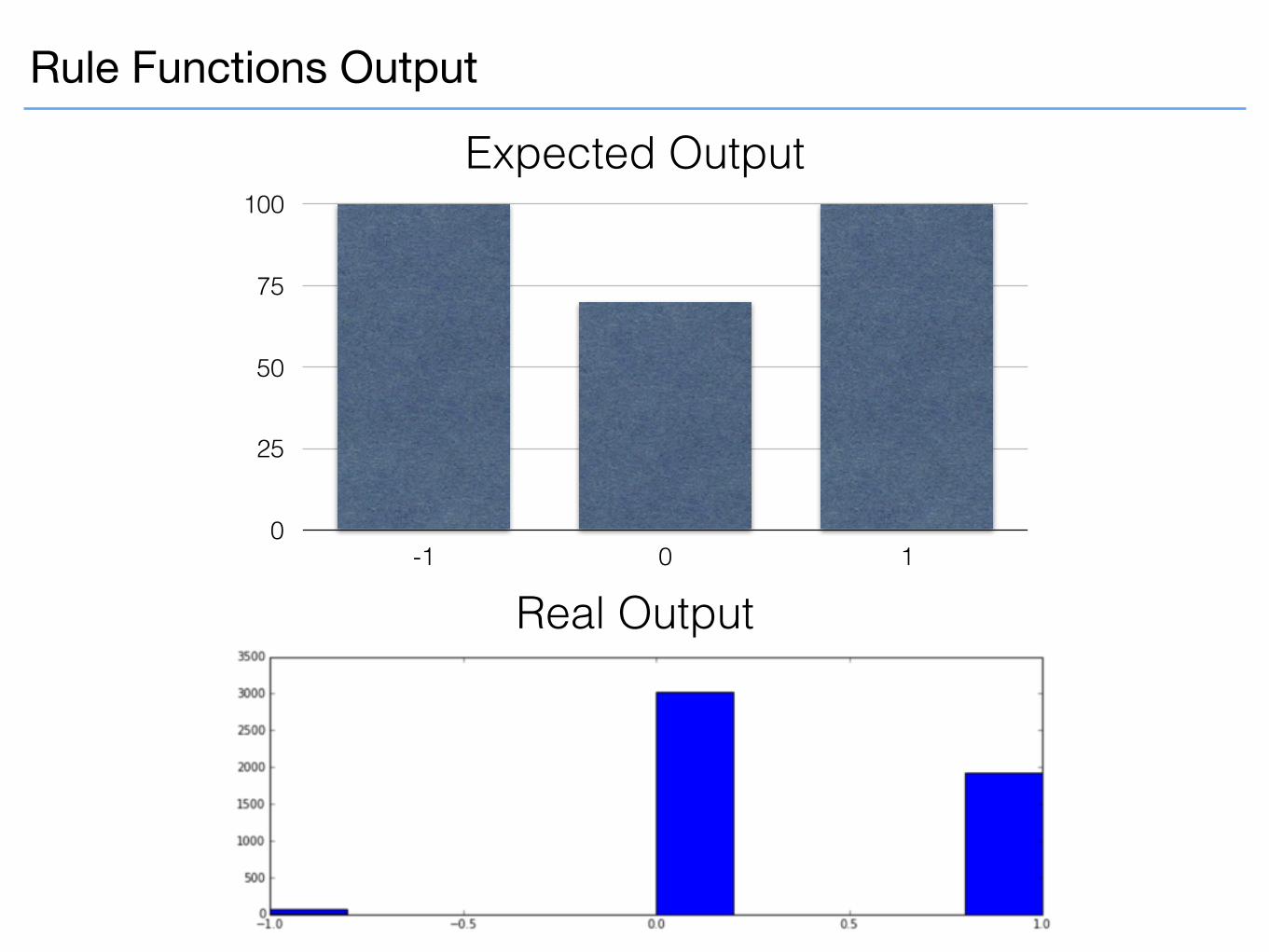
Rule Functions Output
0
25
50
75
100
-1 0 1
Expected Output
Real Output

Results and performance.
drug-name disease candidate Candidates snorkel
Lithium Carbonate
bipolar disorder 1 1
Lithium Carbonate individual 1 0
Lithium Carbonate maintenance 1 0
Lithium Carbonate manic episode 1 1
Precision and recall ~70%

Why Docker?
• Portability: develop here run there: Internal Clusters, aws, google cloud etc, Reusable by team and clients
• isolation: os and docker isolated from bugs.
• Fast• Easy virtualization : hard ware
emulation, virtualized os.• Lightweight
Python stack on docker

FROM ubuntu:latest # MAINTAINER Sanghamitra Deb <[email protected]> CMD echo Installing Accenture Tech Labs Scientific Python Enviro
RUN apt-get install python -y RUN apt-get update && apt-get upgrade -y RUN apt-get install curl -y RUN apt-get install emacs -y RUN curl -O https://bootstrap.pypa.io/get-pip.py RUN python get-pip.py RUN rm get-pip.py RUN echo "export PATH=~/.local/bin:$PATH" >> ~/.bashrc RUN apt-get install python-setuptools build-essential python-dev -y RUN apt-get install gfortran swig -y RUN apt-get install libatlas-dev liblapack-dev -y RUN apt-get install libfreetype6 libfreetype6-dev -y RUN apt-get install libxft-dev -y RUN apt-get install libxml2-dev libxslt-dev zlib1g-dev RUN apt-get install python-numpy
ADD requirements.txt /tmp/requirements.txt RUN pip install -r /tmp/requirements.txt -q
Dockerfilescipy matplotlib ipython jupyter pandas Bottleneck patsy pymc statsmodels scikit-learn BeautifulSoup seaborn gensim fuzzywuzzy xmltodict untangle nltk flask enum34
requirements.txt
docker build -t sangha/python . docker run -it -p 1108:1108 -p 1106:1106 --name pharmaExtraction0.1 -v /location/in/hadoop/ sangha/python bash docker exec -it pharmaExtraction0.1 bash docker exec -d pharmaExtraction0.1 python /root/pycodes/rest_api.py
Building the Dockerfile

Typical ML pipeline vs Snorkel
(1) Candidate Extraction.
(2) Rule Function
(3) Hyperparameter tuning

Snorkel :
Pros: • Very little training
data necessary • Do not have to
think about feature generation
• Do not need deep knowledge in Machine Learning
• Convenient UI for data annotation
• Created structured databases from unstructured text
Cons: • Code is getting
refactored very rapidly and frequently.
• Not much transparency in the internal workings.

Banks: Loan Approval Paleontology
Design of Clinical Trials
Legal Investigation
Market Research Reports
Human Trafficking
Inventory Management
Content Marketing
Product descriptions and reviews
Pharmaceutical Industry
Applicability across a variety of industries
and use cases

Where to get it?
https://github.com/HazyResearch/snorkel
http://arxiv.org/pdf/1512.06474v2.pdf