exponea - kafka and hadoop as components of architecture
TRANSCRIPT

Kafka and Hadoop as components of architecture - Martin Strycek

Kafka
Kafka is a distributed streaming platform.

Hadoop
The Apache™ Hadoop® project develops open-source software for reliable, scalable, distributed computing

How Kafka and Hadoop got into Exponea?

How Kafka and Hadoop got into Exponea?

How Kafka and Hadoop got into Exponea
● We had our in memory database super fast,
but in memory
● Our customers were scared that they will have to pay a lot
● They want to have freedom to run analyses on all data
● We had some troubles processing data
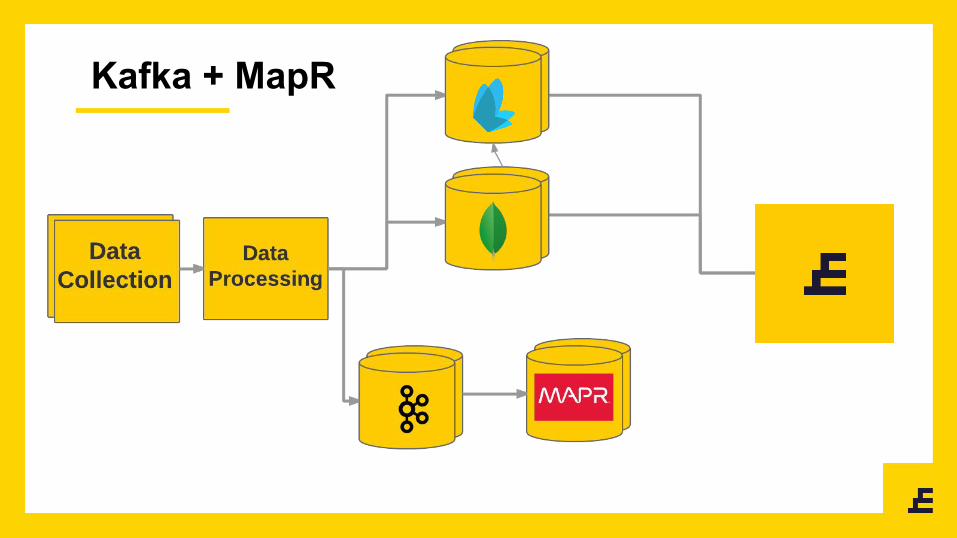
Kafka + MapR

Kafka + MapR
● We were appending data to files that contain jsons
○ HDFS does not support append
● We started using Kafka 0.8.2.1
● We had no idea how to monitor the whole stack
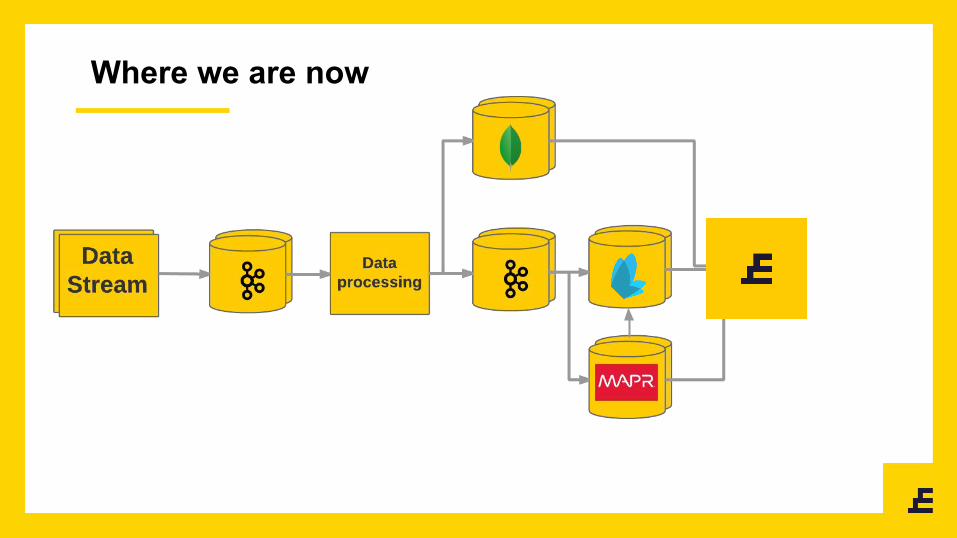
Where we are now

How Kafka and Hadoop got into Exponea
● We are using Kafka to stream data to
● We have first Sparks jobs that are part of application
○ Recommendation
○ Predictions
○ Campaigns overview
○ Loading data to

● We are using Oryx 2
○ But we need multitenancy
● We have MapR
○ But it ships with different Spark version that Oryx 2
● We are using Oryx 2
○ But it works with different version with Kafka
Recommendation
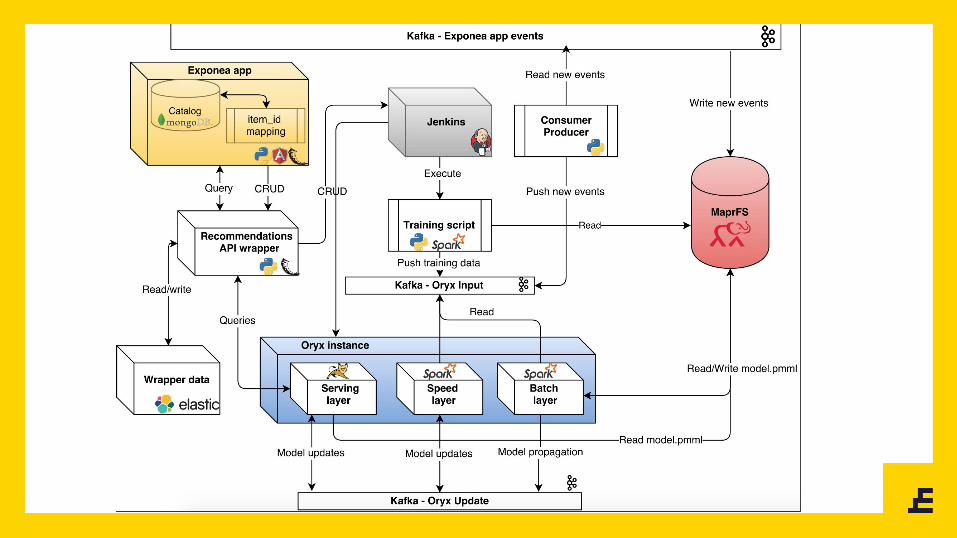

● How about we use
● How about we create better local storage for
● We need another cluster for testing
○ Bare metal? AWS? Google Cloud?
● library to be usable in
● We want to do a workshop for all of you that want to
try it out, but don’t have a place where.
What next?

● Freedom & responsibility
● Big impact
● Team
● Proficiency
Exponea Culture
} Global ambitions, best company to work for

Thanks!