exploiting scratchpad-aware scheduling on vliw architectures for high-performance real-time systems...
TRANSCRIPT

Exploiting Scratchpad-aware Scheduling on VLIW Architectures for High-Performance
Real-Time Systems
Yu Liu and Wei ZhangDepartment of Electrical and Computer EngineeringVirginia Commonwealth University
HPEC’12, Waltham, MA

Overview• A time-predictable two-level SPM based architecture
is proposed for single-core VLIW (Very Long Instruction Word) microprocessors.
• An ILP based static memory objects assignment algorithm is extended to support multi-level SPMs without harming the characteristic of time predictability of SPMs.
• We developed a SPM-aware scheduling to improve performance of the proposed VLIW architecture
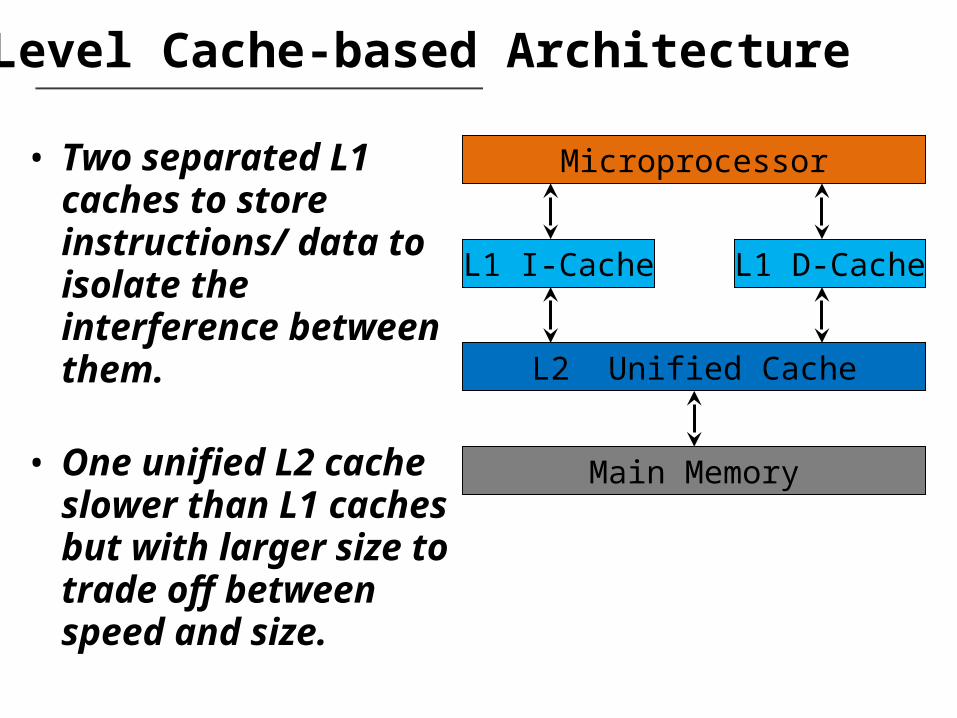
2-Level Cache-based Architecture
• Two separated L1 caches to store instructions/ data to isolate the interference between them.
• One unified L2 cache slower than L1 caches but with larger size to trade off between speed and size.
L1 I-Cache L1 D-Cache
L2 Unified Cache
Main Memory
Microprocessor

2-Level SPM-based Architecture
• Two separated L1 SPMs to store instructions/ data, and one unified L2 SPM with larger size but slower speed.
• No replacement in any higher level memory of this architecture.
L1 I-SPM L1 D-SPM
L2 Unified SPM
Main Memory
Microprocessor

ILP-based Static Allocation• The ILP-based static allocation method is utilized to
allocate memory objects to multi-level SPMs, since it can completely guarantee the characteristic of time predictability.
• The object function is to maximally save executing time, while the constraint is the sizes of SPMs.
• The ILP-based method is utilized three times for the three SPMs, and all instruction and data objects not selected to be allocated in the L1 SPMs need to be considered as candidates for the L2 SPM.

Background on Load-Sensitive Scheduling• In the cache-based architecture, generally it is hard
to statically know the latency of each load operation
• An optimistic scheduler assumes a load always hits in the cache• Too aggressive• Processor needs to be stalled when a miss occurs
• A pessimistic scheduler assumes a load always misses in the cache• Leads to bad performance
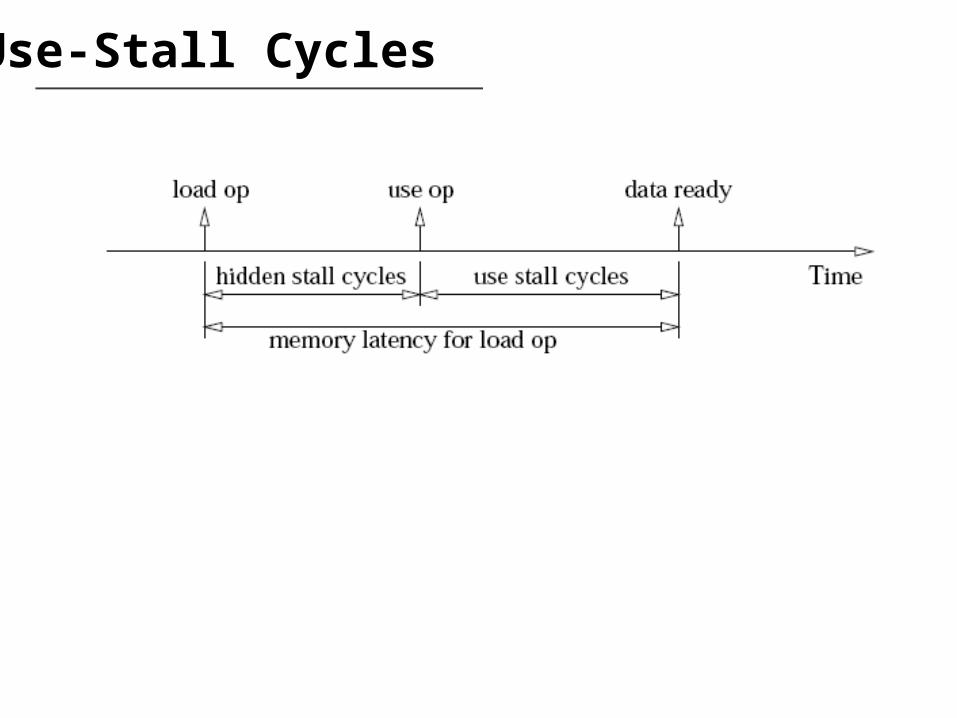
Use-Stall Cycles

Scratchpad-Aware Scheduling• Whenever possible, schedule a load op with large
memory latency earlier• Schedule its use op later• Shorten use-stall cycles while preserving time
predictability

Memory Objects• The instruction objects consist of basic blocks,
functions, and combinations of consecutive basic blocks
• The data objects consist of global scalars and non-scalar variables.

ILP for L1 Instruction SPM

Scratchpad-Aware Scheduling• The load/store latencies are known in the SPM-
based architecture
• Instruction scheduling can be enhanced by exploiting the predictable load/store latencies
• This is known as Load Sensitive Scheduling for VLIW architectures [Hardnett et al. GIT, 2001]

Evaluation Methodology
• We evaluate the performance and energy consumption of our SPM based architecture compared to the cache based architecture.
• Eight real-time benchmarks are selected for this evaluation.
• We simulate the proposed two-level SPM based architecture on a VLIW processor based on the HPL-PD architecture.

Cache and SPM Configurations

Evaluation Framework
The framework of our two-level SPM based architecture for the single-core CPUs evaluation.

Results (SPMs vs. Caches)
The WCET comparison (L1 Size: 128 Bytes, L2 Size: 256 Bytes), normalized to SPM
The energy consumption comparison (L1 Size: 128 Bytes, L2 Size: 256 Bytes), normalized to SPM

Sensitivity Study
Level Setting 1 (S1) Setting 2 (S2) Setting 3 (S3)
L1 Instruction 128 256 512
L1 Data 128 256 512
L2 Shared 256 512 1024

Sensitivity WCET Results
The WCET comparison among the SPMs with different size settings.
The WCET comparison among the caches with different size settings.

Sensitivity Energy Results The energy consumption
comparison among the SPMs with different size settings.
The energy consumption comparison among the caches with different size settings.

Why Two Levels?
L1 I-Cache L1 D-Cache
Main Memory
Microprocessor• Why do we need two levels SPMs instead of one level?
• The level 2 SPM is important to mitigate the access latency, which otherwise has to fetch from the memory.
One level SPM architecture.

Results (One-Level vs. Two-Level)
The timing performance comparison, normalized to two-level SPM based architecture.
The energy consumption comparison, normalized to two-level SPM based architecture.

Scratchpad-Aware Scheduling
The maximum improvement of computation cycles is about 3.9%, and the maximum improvement of use stall cycles is about 10%.

Thank You and Questions!

Backup Slides – SPM Access Latencies

Backup Slide – Priority Function in SSS
In our Scratchpad Sensitive Scheduling, we consider two factors related to the Load-To-Use Distance, including the memory latency for a Load Op (curLat) andthe related Load Op memory latency for a Use Op (preLat).
Priority function of the default Critical Path Scheduling: