exploiting computing power of gpu for data mining application
DESCRIPTION
Exploiting Computing Power of GPU for Data Mining Application. Wenjing Ma, Leonid Glimcher, Gagan Agrawal. Outline of contents. Background of GPU computing Parallel data mining Challenges of data mining on GPU GPU implementation k-means EM kNN Apriori Experiment results - PowerPoint PPT PresentationTRANSCRIPT

Exploiting Computing Exploiting Computing Power of GPU for Data Power of GPU for Data
Mining ApplicationMining Application
Wenjing Ma, Leonid Glimcher, GaWenjing Ma, Leonid Glimcher, Gagan Agrawalgan Agrawal

Outline of contentsOutline of contents
Background of GPU computingBackground of GPU computing Parallel data miningParallel data mining Challenges of data mining on GPUChallenges of data mining on GPU GPU implementationGPU implementation
k-meansk-means EMEM kNNkNN AprioriApriori
Experiment resultsExperiment results Results of kmeans and EMResults of kmeans and EM Features of applications that are suitable for GPFeatures of applications that are suitable for GP
U computingU computing Related and future workRelated and future work

Background of GPU computingBackground of GPU computing
Multi-core architectures are Multi-core architectures are becoming more popular in high becoming more popular in high performance computingperformance computing
GPU is inexpensive and fastGPU is inexpensive and fast CUDA is a high level language CUDA is a high level language
that supports programming on that supports programming on GPUGPU

CUDA functionsCUDA functions
Host functionHost function Called by host and executed on hCalled by host and executed on h
ostost Global functionGlobal function
Called by host and executed on dCalled by host and executed on deviceevice
Device functionDevice function Called by device and executed on Called by device and executed on
devicedevice
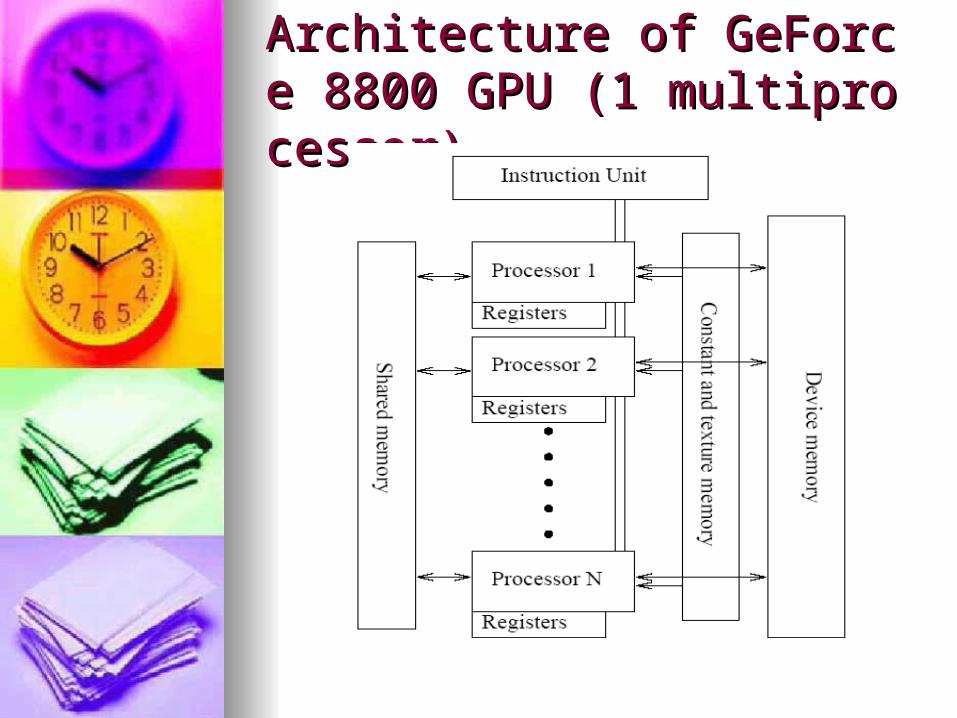
Architecture of GeForce 8800 Architecture of GeForce 8800 GPU (1 multiprocessor)GPU (1 multiprocessor)

Parallel data miningParallel data mining
Common structure of data Common structure of data mining applications (adopted mining applications (adopted from Freeride)from Freeride)
{ * Outer Sequential Loop * }While () {
{ * Reduction Loop * }Foreach (element e) {
(i,val) = process(e);Reduc(i) = Reduc(i) op val;
}}

Challenges of data mining on Challenges of data mining on GPUGPU
SIMD shared memory programming
3 steps involved in the main 3 steps involved in the main looploopData read Computing updateComputing update Writing updateWriting update

Computing updateComputing update
copy common variables from device memory to shared memory
nBlocks = blockSize/ thread number
For i=1 to nBlocks{
each thread process 1 data element}
Global reduction

GPU ImplementationGPU Implementation
k-meansk-means Data are points (say, 3 dimension)Data are points (say, 3 dimension) Start with k clustersStart with k clusters Find the nearest cluster for each pFind the nearest cluster for each p
ointointdetermine the k centroids from the
points assigned to the corresponding center
Repeat until the assignments of points don’t change
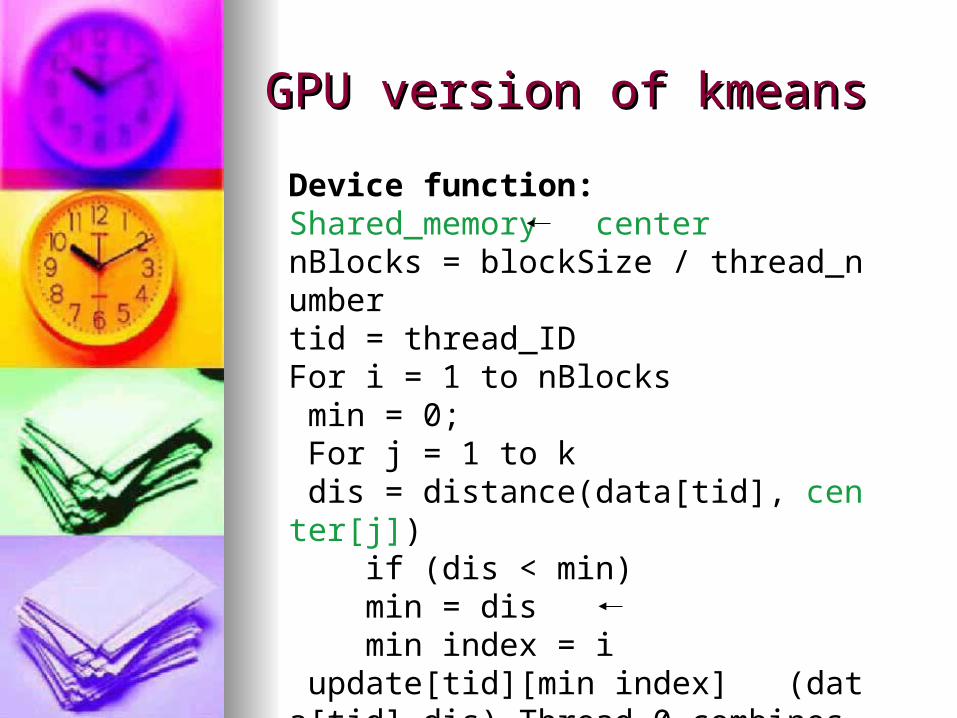
GPU version of kmeansGPU version of kmeans
Device function:Shared_memory centernBlocks = blockSize / thread_numbertid = thread_IDFor i = 1 to nBlocks min = 0; For j = 1 to k dis = distance(data[tid], center[j]) if (dis < min) min = dis min index = i update[tid][min index] (data[tid],dis) Thread 0 combines all copies of update

Other applicationsOther applications
EMEM E step and M step, different amouE step and M step, different amou
nt of computationnt of computation AprioriApriori
Tree-structured reduction objectsTree-structured reduction objects Large amount of updatesLarge amount of updates
kNNkNN

Experiment resultsExperiment results
k-means and EM has the best pk-means and EM has the best performance when using 512 threerformance when using 512 threads/block and 16 or 32 thread blads/block and 16 or 32 thread blocksocks
kNN and apriori hardly get good kNN and apriori hardly get good speedup with GPUspeedup with GPU
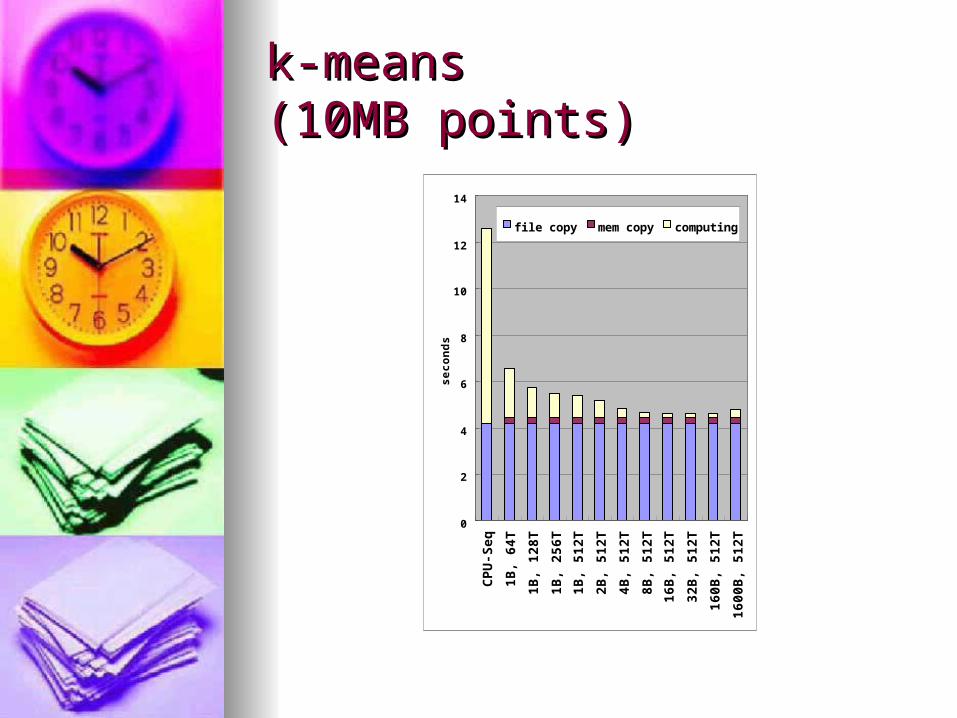
k-meansk-means(10MB points)(10MB points)
0
2
4
6
8
10
12
14
CPU-Seq
1B, 64T
1B, 128T
1B, 256T
1B, 512T
2B, 512T
4B, 512T
8B, 512T
16B, 512T
32B, 512T
160B, 512T
1600B, 512T
seconds
fi l e copy mem copy computi ng
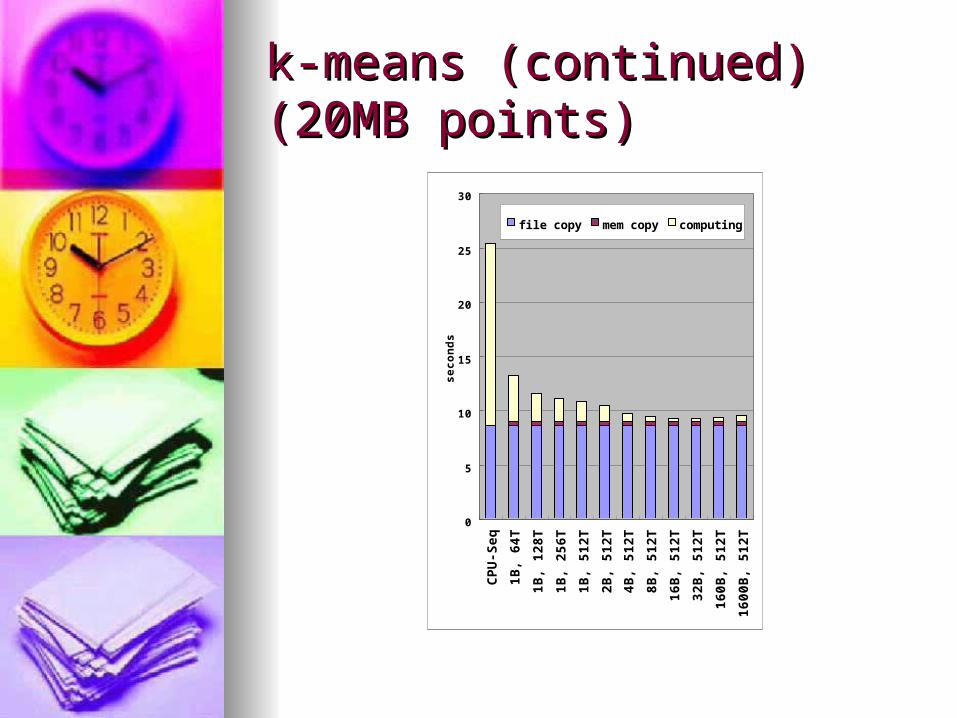
k-means (continued)k-means (continued)(20MB points)(20MB points)
0
5
10
15
20
25
30
CPU-Seq
1B, 64T
1B, 128T
1B, 256T
1B, 512T
2B, 512T
4B, 512T
8B, 512T
16B, 512T
32B, 512T
160B, 512T
1600B, 512T
seconds
fi l e copy mem copy computi ng
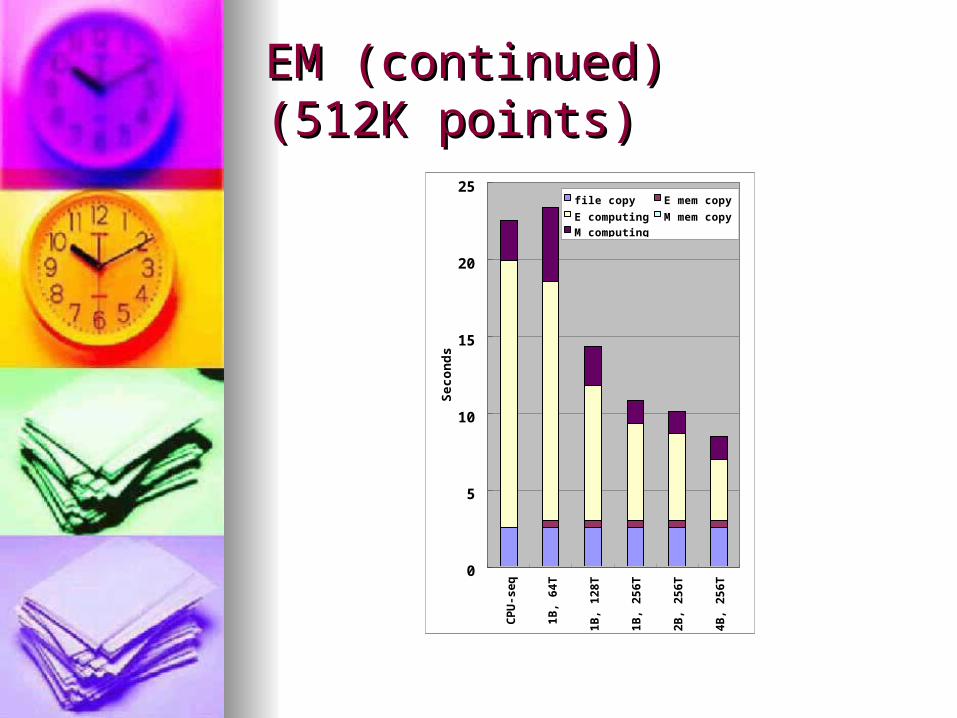
EM (continued)EM (continued)(512K points)(512K points)
0
5
10
15
20
25
CPU-
seq
1B,
64T
1B,
128T
1B,
256T
2B,
256T
4B,
256T
Seconds
fi l e copy E mem copy
E comput i ng M mem copy
M comput i ng
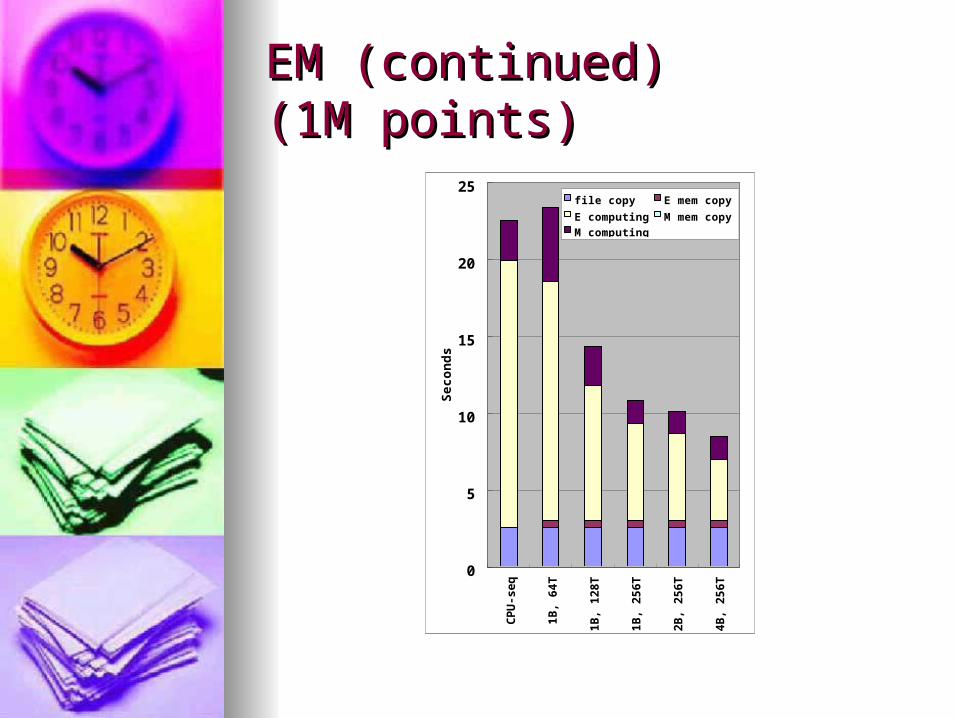
EM (continued)EM (continued)(1M points)(1M points)
0
5
10
15
20
25
CPU-
seq
1B,
64T
1B,
128T
1B,
256T
2B,
256T
4B,
256T
Seconds
fi l e copy E mem copy
E comput i ng M mem copy
M comput i ng

Features of applications that are Features of applications that are suitable for GPU computingsuitable for GPU computing
the time spent on processing the data must dominate the I/O cost
the size of the reduction object needs to be small enough to have a replica for each thread in device memory
using the shared memory to store frequently accessed data
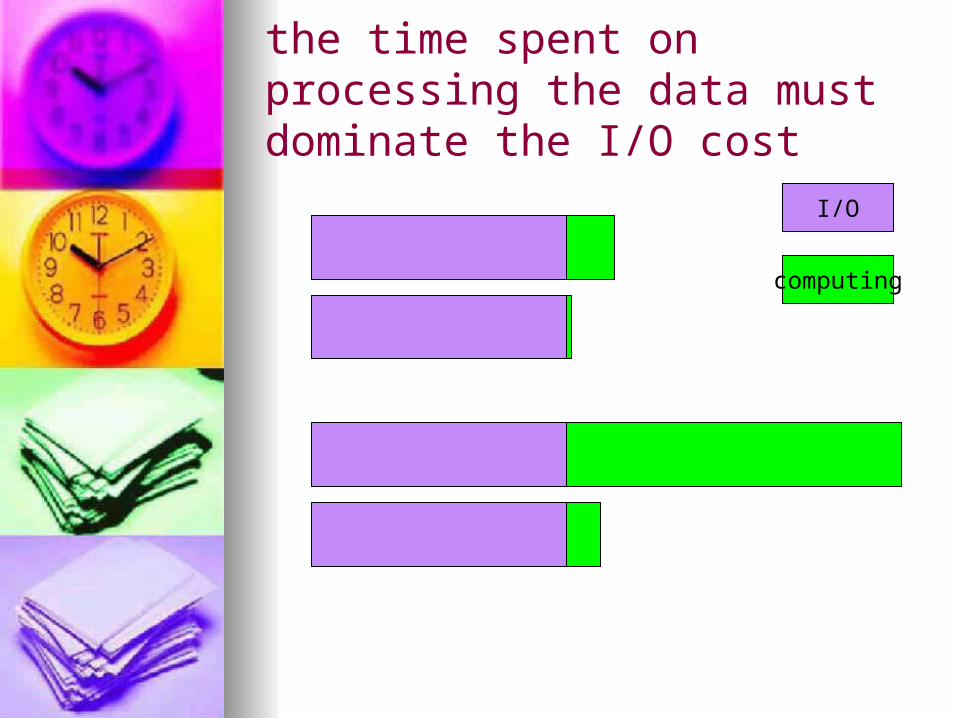
the time spent on processing the data must dominate the I/O cost
I/O
computing

the size of the reduction object needs to be small enough to have a replica for each thread in device memoryNo locking mechanism on GPUThe access to the reductionobjects
are unpredictable

using the shared memory to store frequently accessed data Accessing device memory is very Accessing device memory is very
time consumingtime consuming Shared memory serves as a high Shared memory serves as a high
speed cachespeed cache For non-read-only data elements For non-read-only data elements
on shared memory, we also need on shared memory, we also need replica for each threadreplica for each thread

Related workRelated work
FreerideFreeride Other GPU computing languageOther GPU computing language
ss The usage of GPU computation The usage of GPU computation
in scientific computingin scientific computing

Future workFuture work
Middleware for data mining on Middleware for data mining on GPUGPU
Provide some compilation Provide some compilation mechanism for data mining mechanism for data mining applications on MATLABapplications on MATLAB
Enable tuning of parameters Enable tuning of parameters that can optimize GPU that can optimize GPU computingcomputing

Thank you! Questions?Thank you! Questions?