evaluation of classifiers: choosing the right model rajashree paul irina pekerskaya
Post on 19-Dec-2015
216 views
TRANSCRIPT

Evaluation of classifiers: Evaluation of classifiers: choosing the right modelchoosing the right model
Rajashree Paul
Irina Pekerskaya

SFU, CMPT 740 R. Paul, I. Pekerskaya
2
1. Introduction1. Introduction
Different classification algorithms – which one is the best?
No free lunch theorem
Huge amount of experimental evaluations already conducted
Idea – to ask what is important to the user

SFU, CMPT 740 R. Paul, I. Pekerskaya
3
1.1. Long-term vision1.1. Long-term vision
User define quality measures that are important
Data characteristics of the given dataset are analyzed
Feature selection method is chosenClassification method is chosenThe parameters of the classification method
are optimized

SFU, CMPT 740 R. Paul, I. Pekerskaya
4
1.2. Project goals1.2. Project goals
Analyze possible user-defined criteria Analyze possible data characteristics Analyze the behavior of chosen algorithms Give some suggestions on the algorithm choice
with respect to those criteria and characteristics Survey some approaches for automatic selection
of the classification method

SFU, CMPT 740 R. Paul, I. Pekerskaya
5
Presentation ProgressPresentation Progress
IntroductionClassification AlgorithmsSpecifying Classification ProblemsCombining Algorithms and different
measures for a final mappingMeta Learning and automatic selection of
the algorithm

SFU, CMPT 740 R. Paul, I. Pekerskaya
6
2. Classification Algorithms:2. Classification Algorithms:
Decision Tree (C4.5) Neural Net Naïve Bayes k – Nearest Neighbor Linear Discriminant Analysis (LDA)

SFU, CMPT 740 R. Paul, I. Pekerskaya
7
2.1 Decision Trees (C4.5)2.1 Decision Trees (C4.5)
Starts with the root as complete dataset Chooses the best split using Information Ratio and
partitions the dataset accordingly Recursively does the same thing at each node Stops when no attribute is left or all records of the
node are of same class Applies Post pruning to avoid overfitting

SFU, CMPT 740 R. Paul, I. Pekerskaya
8
2.22.2 Neural Net Neural Net
Layered network of Neurons ( Perceptrons) connected via weighted edges
In Backpropagation Network
1. Input and the Expected Output are fed forward
2. Actual and Expected Outputs are compared (Error)
3. For each node Error is propagated back through the network to tune the weights and bias of each node

SFU, CMPT 740 R. Paul, I. Pekerskaya
9
2.3 Naïve Bayes2.3 Naïve Bayes
Assumes that the Input Attributes are independent of each other given a target class
Decision Rule of the Naïve Bayes Classifier :
where P(Oi | Cj) is the posterior probability of attribute Oi conditioned on class Cj
C cj
Cj)|P(O P(Cj)argmax i

SFU, CMPT 740 R. Paul, I. Pekerskaya
10
2.4 k – Nearest Neighbor2.4 k – Nearest Neighbor
Uses a distance function as a measure of similarity/dissimilarity between two objects
Classifies objects to the majority class of k nearest objects
Value of k may vary

SFU, CMPT 740 R. Paul, I. Pekerskaya
11
2.5 Linear Discriminant Analysis (LDA)2.5 Linear Discriminant Analysis (LDA)
Optimal for normally distributed data and classes having equal covariance structure
What it does:
For each class it generates a linear function For a problem with d features it separates the classes
by (d-1) dimensional hyperplanes

SFU, CMPT 740 R. Paul, I. Pekerskaya
12
Presentation ProgressPresentation Progress
IntroductionClassification AlgorithmsSpecifying Classification ProblemsCombining Algorithms and different
measures for a final mappingMeta Learning and automatic selection of
the algorithm

SFU, CMPT 740 R. Paul, I. Pekerskaya
13
3. Specifying Classification 3. Specifying Classification ProblemsProblems
3.1 Quality Measures
3.2 Data Characteristics

SFU, CMPT 740 R. Paul, I. Pekerskaya
14
3.1 Quality Measures3.1 Quality Measures
Accuracy Training Time Execution Time Interpretability Scalability Robustness …

SFU, CMPT 740 R. Paul, I. Pekerskaya
15
3.23.2 Data Characteristics Data Characteristics
Size of Dataset Number of Attributes Amount of Training Data Proportion of Symbolic Attributes Proportion of Missing Values Proportion of Noisy Data Linearity of Data Normality of Data

SFU, CMPT 740 R. Paul, I. Pekerskaya
16
Presentation ProgressPresentation Progress
IntroductionClassification AlgorithmsSpecifying Classification ProblemsCombining Algorithms and different
measures for a final mappingMeta Learning and automatic selection of
the algorithm

SFU, CMPT 740 R. Paul, I. Pekerskaya
17
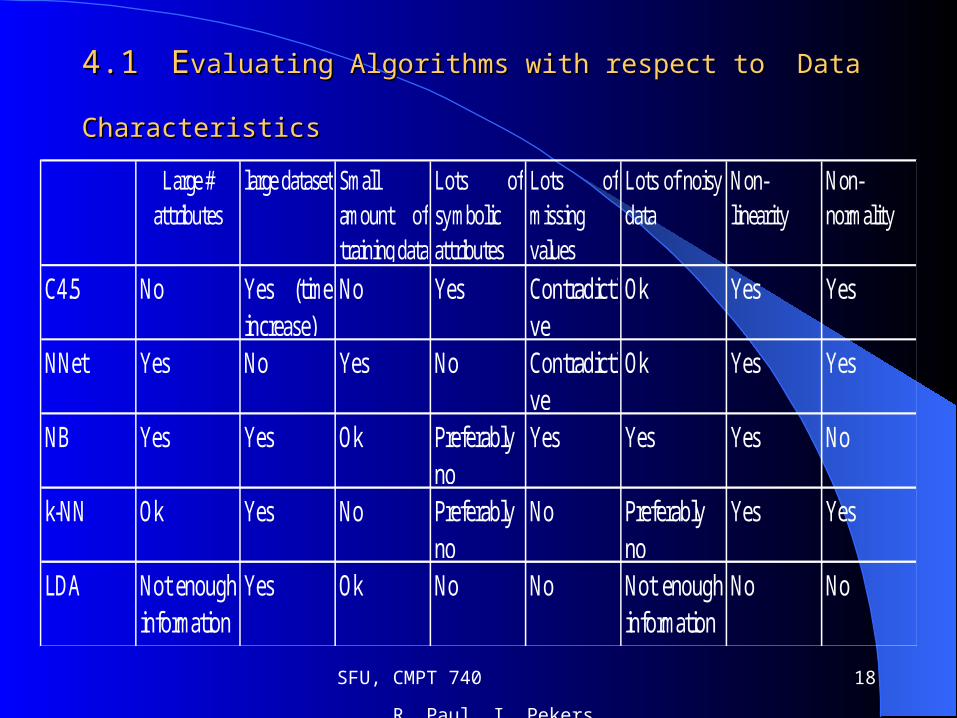
4. Combining Algorithms and 4. Combining Algorithms and Measures Measures
1st step toward our goal
Comparing the algorithms with respect
to different Data Characteristics
SFU, CMPT 740 R. Paul, I. Pekerskaya
18
4.14.1 EEvaluating Algorithms with respect to Data Characteristicsvaluating Algorithms with respect to Data Characteristics
C4.5 No Yes (time
increase)No Yes Contradicti
veOk Yes Yes
NNet Yes No Yes No Contradictive
Ok Yes Yes
NB Yes Yes Ok Preferably no
Yes Yes Yes No
k-NN Ok Yes No Preferably no
No Preferably no
Yes Yes
LDA Not enoughinformation
Yes Ok No No Not enoughinformation
No No
large dataset Small amount oftraining data
Lots ofsymbolic attributes
Large # attributes
Lots ofmissing values
Lots of noisydata
Non- linearity
Non- normality

SFU, CMPT 740 R. Paul, I. Pekerskaya
19
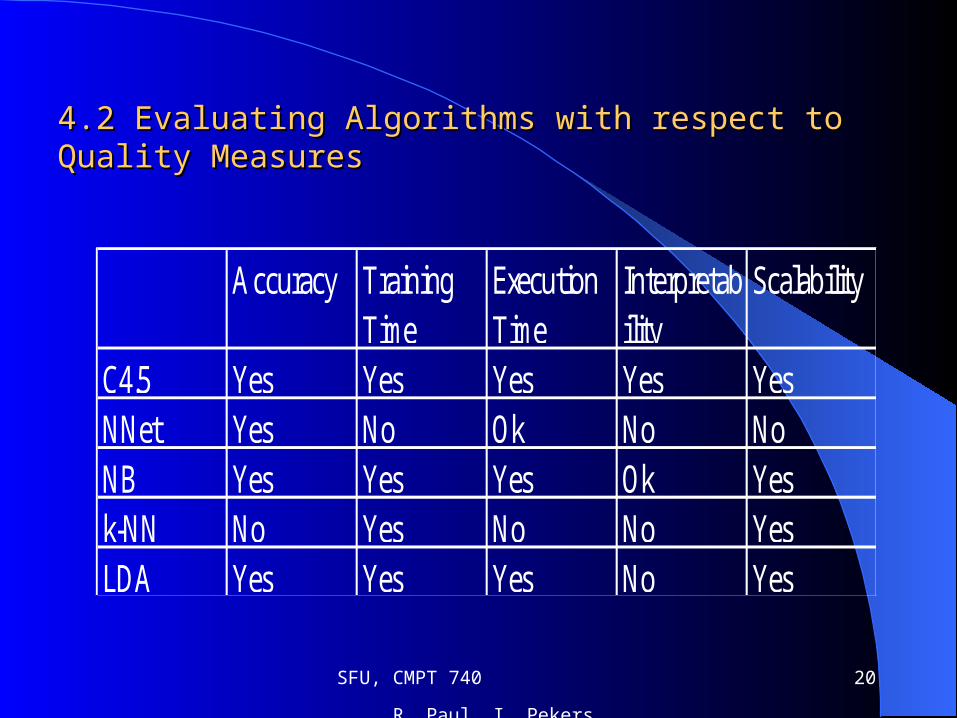
4. Combining Algorithms and 4. Combining Algorithms and Measures …(contd.)Measures …(contd.)
2nd step…
Comparing Algorithms in terms of different Quality Measures
SFU, CMPT 740 R. Paul, I. Pekerskaya
20
4.2 Evaluating Algorithms with respect to Quality Measures4.2 Evaluating Algorithms with respect to Quality Measures
Accuracy Training
TimeExecution Time
Interpretability
Scalability
C4.5 Yes Yes Yes Yes YesNNet Yes No Ok No NoNB Yes Yes Yes Ok Yesk-NN No Yes No No YesLDA Yes Yes Yes No Yes

SFU, CMPT 740 R. Paul, I. Pekerskaya
21
4. Combining Algorithms and 4. Combining Algorithms and Measures…(Contd.)Measures…(Contd.)
Finally…
Merging the information of two
tables into one table :
(Data characteristics + Quality Measures) => Algorithms

SFU, CMPT 740 R. Paul, I. Pekerskaya
22
4.3 Choice of the algorithm4.3 Choice of the algorithm
Small Large Small large symbolic numeric
Accuracy C4.5, LDA NNet, NB NNet, C4.5 C4.5, NBLDA
C4.5 NNet, LDA NB, NNet NNet, NB Nnet NNet, C4.5
Interpretability
C4.5 NB C4.5, NB,LDA
C4.5 C4.5, NB C4.5, NB C4.5, NB C4.5, NB C4.5, NB C4.5
C4.5, NB, k-NN
C4.5, k-NN
NB C4.5, NB, Nnet
C4.5, Nnet
NB, C4.5
C4.5 NB, LDA,NNet
NB, C4.5 NB, C4.5Execution time
C4.5, LDA C4.5 NB, LDA
C4.5, LDA, k-NN
Training time
C4.5 C4.5 NB, C4.5NB, k-NN NB, k-NN NB, LDA, k-NN
Lots ofmissing values
Lots ofnoisy data
Non- linearity
Non- normality
# of attributes Size of data Prevalent type ofattributes

SFU, CMPT 740 R. Paul, I. Pekerskaya
23
Presentation ProgressPresentation Progress
IntroductionClassification AlgorithmsSpecifying Classification ProblemsCombining Algorithms and different
measures for a final mappingMeta Learning and automatic selection of
the algorithm

SFU, CMPT 740 R. Paul, I. Pekerskaya
24
5. Meta-learning5. Meta-learning
Overview
We have some knowledge about the algorithms performance on some datasets
Measure similarity between given dataset and previously processed ones and choose those that are similar
Measure algorithm performance on chosen datasets Rank the algorithms

SFU, CMPT 740 R. Paul, I. Pekerskaya
25
5. Meta-learning5. Meta-learning
Measuring the similarity between datasets
Data characteristics:
Number of examples Number of attributes Proportion of symbolic attributes Proportion of missing values Proportion of attributes with outliers Entropy of classes

SFU, CMPT 740 R. Paul, I. Pekerskaya
26
5. Meta-learning5. Meta-learning
Measuring the similarity between datasets
K-Nearest Neighbor
Distance function:

SFU, CMPT 740 R. Paul, I. Pekerskaya
27
5. Meta-learning5. Meta-learning
Evaluating algorithmsAdjusted ratio of ratios(ARR) multicriteria
evaluation measure:
AccD – the amount of accuracy user can trade for a 10 times speedup or slowdown

SFU, CMPT 740 R. Paul, I. Pekerskaya
28
5. Meta-learning5. Meta-learning
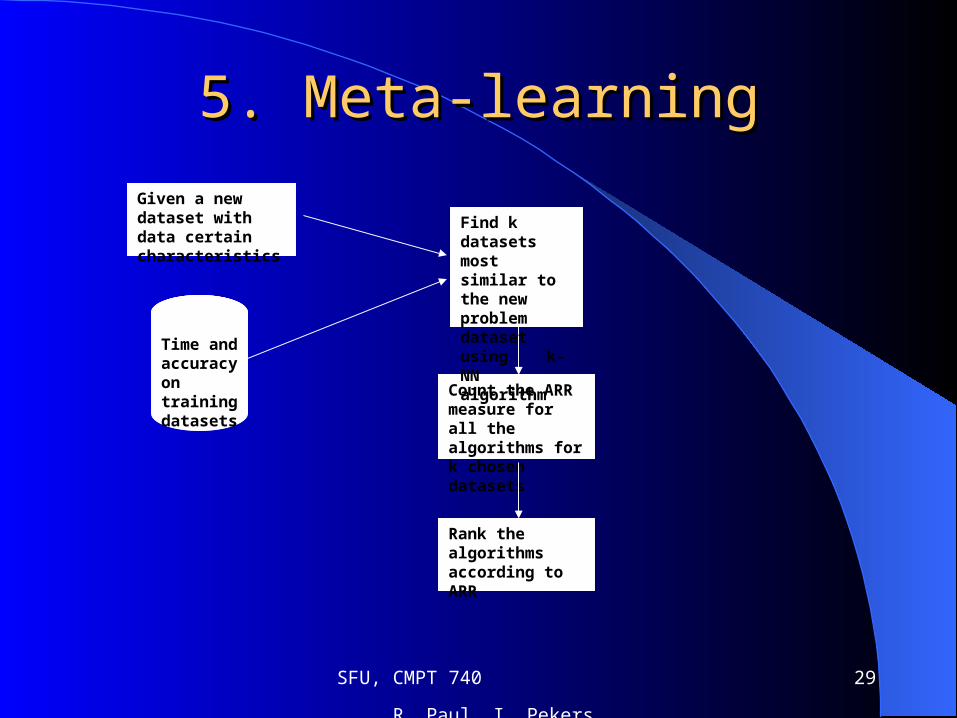
Ranking algorithms
Calculate ARR for each algorithmRank them according to this measure
SFU, CMPT 740 R. Paul, I. Pekerskaya
29
5. Meta-learning5. Meta-learning
Given a new dataset with data certain characteristics
Time and accuracy on training datasets
Count the ARR measure for all the algorithms for k chosen datasets
Rank the algorithms according to ARR
Find k datasets most similar to the new problem dataset using k-NN algorithm

SFU, CMPT 740 R. Paul, I. Pekerskaya
30
5. Meta-learning5. Meta-learning
Promising approach, as it allows quantitative measure
Needs more investigation, for example incorporating more parameters to the ARR parameter

SFU, CMPT 740 R. Paul, I. Pekerskaya
31
6. Conclusion6. Conclusion
Done: Overall mapping of five classifiers according to
some user specified parameters along with some characteristics reflecting the type of datasets.
Surveyed systems for automatic selection of the appropriate classifier or rank some different classifiers given a dataset and set of user preferences

SFU, CMPT 740 R. Paul, I. Pekerskaya
32
6. Conclusion6. ConclusionFuture research
Performing dedicated experimentsAnalysis of the choice of feature selection
method and optimization of the parametersWorking on the intelligent system for
choosing classification method

SFU, CMPT 740 R. Paul, I. Pekerskaya
33
7. References7. References 1. Brazdil, P., & Soares, C. (2000). A comparison of ranking methods for classification algorithm
selection. In R.de M´antaras & E. Plaza (Eds.), Machine Learning: Proceedings of the 11th European Conference on Machine Learning ECML2000 (pp. 63–74). Berlin: Springer.
2. Brodley, C., Utgoff ,C. (1995). Multivariate Decision Trees, Machine Learning, 19 3. Brown, D., Corruble, V, Pittard, C.L. (1993) A Comparison of Decision Tree Classifiers With
Backpropagation Neural Networks For Multimodal Classification Problems, Pattern Recognition, Vol. 26,No. 6
4. Curram, S., Mingers, J (1994) Neural Networks, Decision Tree Induction and Discriminant
Analysis : An Empirical Comparison, Operational Research Society, Vol. 45, No. 4
5. Han, J, Kamber, M. (2001) Data Mining:concepts and techniques. San Francisco:Morgan Kaufmann Publishers
6. Hilario, M., & Kalousis, A. (1999). Building algorithm profiles for prior model selection in knowledge discovery systems. In Proceedings of the IEEE SMC’99 International Conference on Systems, Man and Cybernetics. New York: IEEE Press.
7. Kalousis, A.,&Theoharis, T. (1999).NOEMON:Design, implementation and performance results of an intelligent assistant for classifier selection. Intelligent Data Analysis, 3:5, 319–337.

SFU, CMPT 740 R. Paul, I. Pekerskaya
34
7. References7. References 8. Keller, J., Paterson, I., & Berrer, H. (2000). An integrated concept for multi-criteria ranking of
data-mining algorithms. In J. Keller & C. Giraud-Carrier (Eds.), Meta-Learning: Building Automatic Advice Strategies for Model Selection and Method Combination.
9. Kiang, M. (2003). A Comparative Assessment of Classification Methods, Decision Support
Systems, 35 10. Kononenko,I, Bratko,I. (1991). Information-Based Evaluation Criterion for Classifier’s
Performance, Machine Learning ,6
11 Lim, T., Loh, W., Shoh, Y.(2000). A comparison of Prediction Accuracy, Complexity and Training Timeof Thirty-Three Old and New Classification Algorithms, Machine Learning ,6
12. Michie, D., Spiegelhalter, D., & Taylor, C. (1994). Machine Learning, Neural and Statistical Classification. Ellis Horwood.
13. Mitchell, T. (1997). Machine Learning. New York: McGraw-Hill.
14. Quinlan, J. (1993) C4.5 : programs for machine learning. San Francisco : Morgan Kaufmann Publishers

SFU, CMPT 740 R. Paul, I. Pekerskaya
35
7. References7. References 15. Salzberg, S.(1997) On Comparing Classifiers: Pitfalls to Avoid and Recommended Approach,
Data Mining and knowledge Discovery, 1 16. Shalvic, J, Mooney, R., Towell, G. (1991). Symbolic and Neural Learning Algorithms: An
Experimental Comparison, Machine Learning ,40
17. Todorovski, L., & Dˇzeroski, S. (2000). Combining multiple models with meta decision trees. In D. Zighed, J. Komorowski, & J. Zytkow (Eds.), Proceedings of the Fourth European Conference on Principles and Practice of Knowledge Discovery in Databases (PKDD00) (pp. 54–64). New York: Springer.
18. Weiss, S., Kulikowski, C. (1991). Computer Systems that learn. San Francisco:Morgan
Kaufmann Publishers 19. Witten, I., Frank, E. (2000) Data mining: practical machine learning tools and techniques with
Java implementations. San Francisco:Morgan Kaufmann Publishers
20. Brazdil, P., Soares, C.(2003) Ranking Learning Algorithms: Using IBL and Meta-Learning on Accuracy and Time Results, Machine Learning, 50, 251–277
21. Blake, C., Keogh, E., & Merz, C. (1998). Repository of machine learning databases. Available at http:/www. ics.uci.edu/~mlearn/MLRepository.html

Thank youThank you
Questions?