erin osborne nishimura onish.web.unc.edu university of north carolina at chapel hill
TRANSCRIPT

Reproducible ResearchReproducible Research
Erin Osborne Nishimuraonish.web.unc.edu
University of North Carolina at Chapel Hill

Reproducible ResearchSpecific aim
• The goal of reproducible research is to aid in the exact replication of scientific findings by an independent investigator.

Why reproducible research?
• Accuracy
• Efficiency
• Accessibility

The key components of reproducible research
• Organization– Structuring project folders in meaningful ways– Naming files
• Documentation– Taking notes along the way– Reporting what your code is doing
• Automation– Writing reproducible code– Making sure the code produces the same results each time
• Publication– Making your data, analysis, and/or code available to collaborators or
the public

1) ORGANIZATION
Best organizational practices
– Structure projects into a directory/folder.– Employ a stereotyped file structure.– Document the project as you go.– Practice effective naming.

EXAMPLE: One person’s file structure
Six months ago, your lab read a paper from the Rick Young lab stating that histone-modifying enzymes affect gene expression. Your lab noticed that some of the enzymes with the biggest changes were positively charged. At that time, you started a project to plot the charges of different enzymes and then compare the results to the Rick Young dataset from the paper. Then, you got distracted.Now, six months later, you realize you should probably re-do the analysis. You open up the folder/directory where you were performing your work only to see…
$ lsdata_from_RickYoungLab_cleanversion.txtdata_from_RickYoungLab.txtdata_fromRickYoungLab.xlsxfirst_pass_plots.pdffirstpass_main_script.shhg19_13947561833.gtfhg19_histoneacetyltransferases_only.gtfjan_22_2014_latest_main_script.shlatest_main_script.shnotes_to_myself.docxoutputplot.pdfplot_enzyme_charge.Rtemp1.txttemp2.txttest1.txttest.gtf
What are the problems with this organization?Can you re-organize your folder any better?

EXAMPLE: flat organization
Six months ago, your lab read a paper from the Rick Young lab stating that histone-modifying enzymes affect gene expression. Your lab noticed that some of the enzymes with the biggest changes were positively charged. At that time, you started a project to plot the charges of different enzymes and then compare the results to the Rick Young dataset that you obtained from the paper. Then, you got distracted.Now, six months later, you realize you should probably re-do the analysis. You open up the folder/directory where you were performing your work only to see…
$ ls00_histoneChargeProject_README.txt01_input_data_from_RickYoungLab_raw.txt01_input_data_from_RickYoungLab_raw.xlsx02_input_data_RYLab_processed.txt03_input_hg19_reference.gtf04_mainScript_14-01-22.sh04_mainScript_previous_versions/04_mainScript_14-01-20.sh04_mainScript_14-01-21.sh05_plotEnzymeCharge.R06_outputPlot_14-01-20.pdf06_outputPlot_14-01-22.pdf07_testFiles/temp1_14-01-20.txttemp2_14-01-20.txttest1_14-01-20.txttest_14-01-20.gtf

EXAMPLE: hierarchical organization$ ls
00_documentation/histoneChargeProject_README.txt
01_input/data_from_Rick_Young_lab/
inputdata_RickYoungLab_raw.txtinputdata_RickYoungLab_raw.xlsxinputdata_RYLab_processed.txt
hg19_annotations/hg19_13947561833.gtfhg19_histoneacetyltransferases_only.gtf
02_mainScript/14-01-22_mainScript.shprevious_versions/
14-01-20_mainScript.sh14-01-21_mainScript.sh
03_auxiliary_scripts/plotEnzymeCharge.R
04_ouptut/14-01-22_outputPlot.pdf14-01-22_outputPlot.logprevious_versions/
14-01-20_outputPlot.pdf14-01-20_outputPlot.log
05_testFiles/temp1_14-01-20.txttemp2_14-01-20.txttest1_14-01-20.txttest_14-01-20.gtf

Naming matters!$ ls
00_documentation/histoneChargeProject_README.txt
01_input/data_from_Rick_Young_lab/
inputdata_RickYoungLab_raw.txtinputdata_RickYoungLab_raw.xlsxinputdata_RYLab_processed.txt
hg19_annotations/hg19_13947561833.gtfhg19_histoneacetyltransferases_only.gtf
02_mainScript/14-01-22_mainScript.shprevious_versions/
14-01-20_mainScript.sh14-01-21_mainScript.sh
03_auxiliary_scripts/plotEnzymeCharge.R
04_ouptut/14-01-22_outputPlot.pdf14-01-22_outputPlot.logprevious_versions/
14-01-20_outputPlot.pdf14-01-20_outputPlot.log
05_testFiles/temp1_14-01-20.txttemp2_14-01-20.txttest1_14-01-20.txttest_14-01-20.gtf

A typical hierarchical structure
A quick guide to organizing computational biology projectsPLoS Computational Biology, 2009.

2) DOCUMENTATION
• Write a project overview in a README file• Take notes along the way
– Actual notes– Note taking .txt files or software
• Produce dynamic documentation of your project– Files that your code generates that weave together code and output
• Write scripts that generate log files– Output files that your code generates to keep a record of software
versions, commands used, input, and output.• Comments within code• Pseudocode

$ ls00_documentation/
histoneChargeProject_README.txt01_input/
data_from_Rick_Young_lab/inputdata_RickYoungLab_raw.txtinputdata_RickYoungLab_raw.xlsxinputdata_RYLab_processed.txt
hg19_annotations/hg19_13947561833.gtfhg19_histoneacetyltransferases_only.gtf
02_mainScript/14-01-22_mainScript.shprevious_versions/
14-01-20_mainScript.sh14-01-21_mainScript.sh
03_auxiliary_scripts/plotEnzymeCharge.R
04_ouptut/14-01-22_outputPlot.pdf14-01-22_outputPlot.logprevious_versions/
14-01-20_outputPlot.pdf14-01-20_outputPlot.log
05_testFiles/temp1_14-01-20.txttemp2_14-01-20.txttest1_14-01-20.txttest_14-01-20.gtf
EXAMPLE: a README file
histoneChargeProject_README.txt###########################################INFO:Author: Claude DeScientistLab: Jason Lieb LabStartDate: January 20, 2014
###########################################PROJECT: I want to understand the link between the charges associated with key histone modifying enzymes and the gene expression changes that result when these histone modifying enzymes are removed.
###########################################DIRECTORY: killdevil:/nas02/home/c/l/cdesci/
###########################################01_INPUT:
I will use data from a Rick Young Lab paper an the human genome annotations as input.
INPUT DATA: RICK YOUNG LAB:Information on the Rick Young Lab paper dataset is: Supplemental Materials 1 was downloaded on January 20, 2014 from: Devries, et al., Nature, 2013 http://nature.uk.pub/134345234/sfig1
INPUT DATA: HG ANNOTATION:…
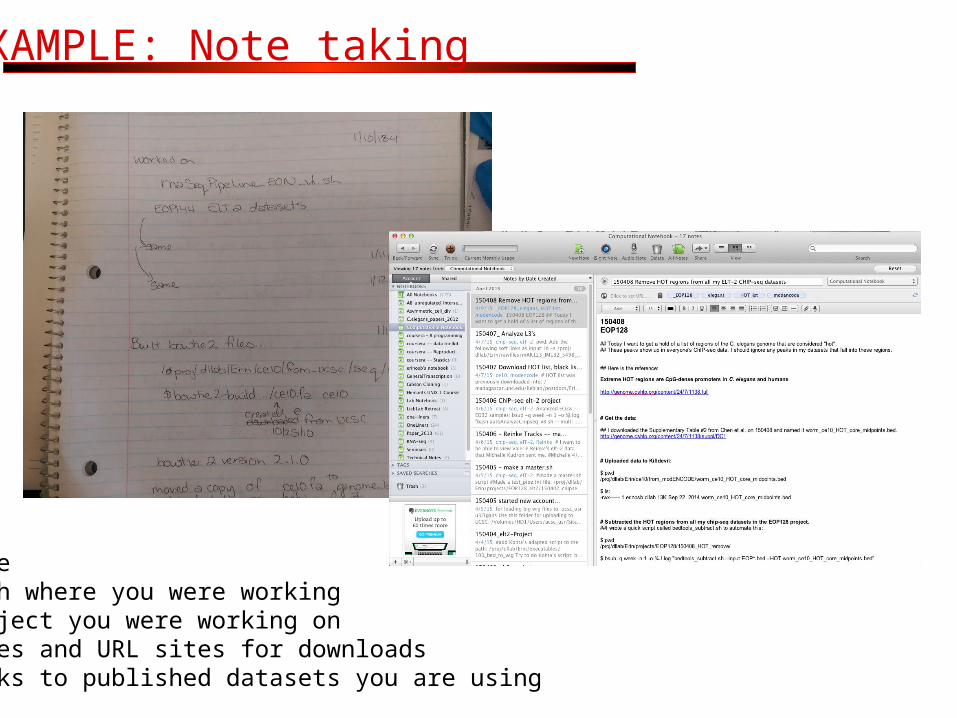
EXAMPLE: Note taking
• Date• Path where you were working• Project you were working on• Dates and URL sites for downloads• Links to published datasets you are using

3) AUTOMATION
• Try to minimize manual manipulations of data.• Set seeds on random number generators• Generate scripts that automatically generate output
and log files in structured, directories• Keep track of ALL software and package versions

EXAMPLE: An automatically generated log file
######################################################################2015-05-16_20:57 RUNNING######################################################################2015-05-16_20:57 INITIATED autoAnalyzeChipseq.sh using command:
chipSeqAutoAnalyzePipeline/chipSeqAnalyzeStep1.sh --multi ../01_input/mAR100_JM127_L007_001.fastq.gz --bar ../01_input/barcode_index_AR100.txt -p 4 --extension 150
This pipeline will run with the following modules: 1) null 4) bedtools/2.22.1 7) r/3.1.1 2) git/1.8.5.3 5) bowtie/1.1.0 8) fastqc/0.11.3 3) samtools/0.1.19 6) java/1.8.0_11
RUNNING IN SPLIT-N-ALIGN MODE
FILE TO SPLIT IS: ../01_input/mAR100_JM127_L007_001.fastq.gzBARCODE FILE IS: ../01_input/barcode_index_AR100.txt
######################################################################2015-05-16_20:57 SPLITTING######################################################################zcat ../01_input/mAR100_JM127_L007_001.fastq.gz | fastx_barcode_splitter.pl
--bcfile ../01_input/barcode_index_AR100.txt…

The key components of reproducible research
• Organization– Structuring project folders in meaningful ways– Naming files
• Documentation– Taking notes along the way– Reporting what your code is doing
• Automation– Writing reproducible code– Making sure the code produces the same results each time
• Publication– Making your data, analysis, and/or code available to collaborator or
the public

REFERENCES
• A quick guide to organizing computational biology projects. PLoS Computational Biology, 2009.
• Ten simple rules for reproducible computational research. PLoS Computational Biology, 2013.
• Why do reproducible research? ropensci.github.io
• Reproducible Research Blog

FURTHER LEARNING
• Reproducible Research. Coursera. Next class August 3 – 29, 2015.
• Reproducible Science Workshop – Tools, Resources, & Practices. Duke University. Periodically announced. Materials available for self-study.
• Tool for Reproducible Research – University of Wisconsin. Materials available for self-study.