enhancing graph database indexing by suffix tree structureenhancing graph database indexing by...
TRANSCRIPT

Enhancing Graph Database Indexing By Suffix Tree Structure
V. Bonnici, R. Di Natale, A. Ferro, R. Giugno, M. Mongiovì, G. Pigola, A. Pulvirenti
Dipartimento di Matematica e Informatica Università di Catania
D. Shasha
Courant Institute of Mathematical Science, New York University

Outline
• Biological Motivations• GraphGrep• GraphGrepSX• Experimental results (GIndex, Gcoding, GraphGrep, Ctree)

Motivations• Many applications in industry, science, and engineering share
the same problem: given a subgraph, find its occurrences in a database of graphs. – Prediction of the functionality of new natural or synthesized compounds – Make a compound Q more active– Find fragment with the same function among different species – Predict protein function, Predict protein interaction
Gene Ontologies
Pathways
Biological Networks

Graph indexing system
• Graph-to-graph matching algorithms can be used, efficiency considerations suggest the use of specific techniques to reduce the search space and the time complexity.
• In a preprocessing phase, each graph of the database is analyzed in order to extract and store its discriminatory properties, features.
• In the filtering phase, the graph database index is compared with the query index in order to discard graphs of the database not containing some features present in the query graph.

GraphGrep
Database
0 321
B CA B g1
g2
04
BC
1A 2B 3 Cg3
2 354
B CA B
1D
6 EIndex Construction
Index
Query processing
Candidate Verification
Filtering:find candidate
Load from DB
Indexing is crucial to reduce the search space and make the problem affordable!
Graphs searching is an NP-problem
Shasha D, Wang JL, Giugno R: Algorithmics and Applications of Tree and Graph Searching. Proceeding of the ACM Symposium on Principles of Database Systems (PODS) 2002, :39{52.
A. Ferro, R. Giugno, M. Mongiovì, A. Pulvirenti, D. Skripin, D. Shasha D. GraphFind: Enhancing Graph Searching by Low Support Data Mining Techniques. BMC Bioinformatics 2008, Vol. 9 (Suppl 4) :S10 doi:10.1186/1471-2105-9-S4-S10

GraphGrep: Index buildingFor each graph in DB:
• Find all paths of length from 1 to L (4,10)
• Save the paths in a Berkeley DB
• Count how many occurrences of each path in each graph
• Save the occurrences in an hash table indexed by the strings of the paths
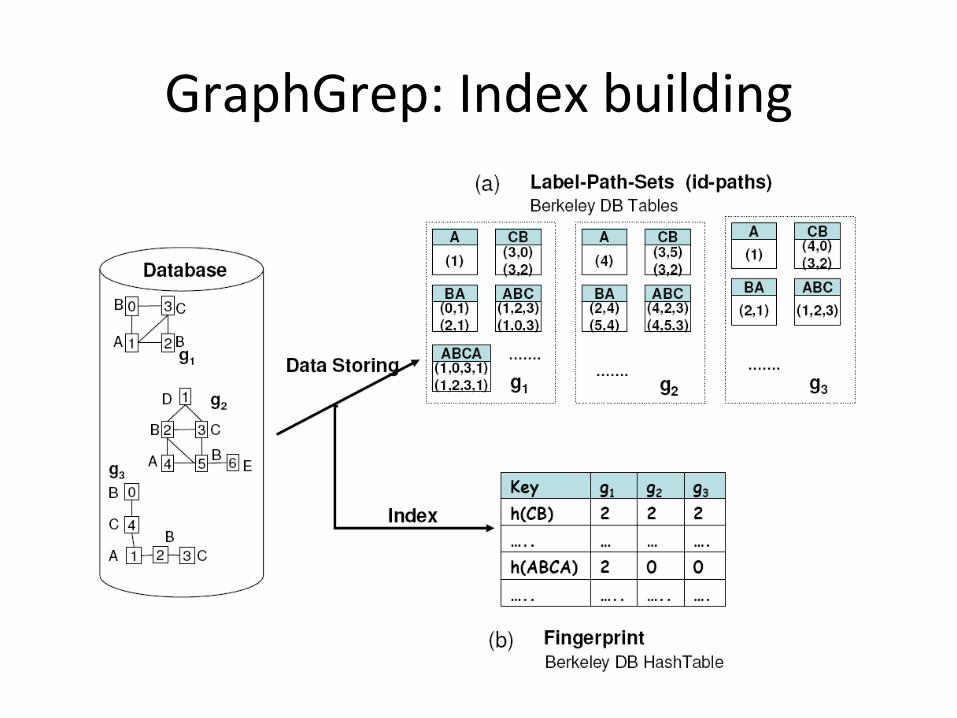
GraphGrep: Index building

Run VF
GraphGrep: Filtering and Matching

GraphGrep: Matching VF_lib(Cordella et al. IEEE PAMI 2004,
http://amalfi.dis.unina.it/graph/db/vflib-2.0/doc/vflib.html)
• Extension of Ullmann matching algorithm ( Journal of the ACM, 1976)
• The process of finding the mapping function can be suitably described by means of a TREE called State Space Representation (SSR)
• Each node is a state s of the partial matching process
• Transition from a generic state s to a successor s’ represents the addition of a pair matched nodes.
• k-look-ahead rules for checking in advance if a consistent state s has no consistent successors after k steps + Semantic rules

GraphGrepSX: IdeaRealize a compact representation of the index by making use of Suffix trees
“Algorithms on Strings, Trees, and Sequences” by Dan Gusfield

GraphGrepSX: IdeaRealize a compact representation of the index by making use of Suffix trees

GraphGrepSX: IdeaRealize a compact representation of the index by making use of Suffix trees
Suffix tree
index

GraphGrepSX: IdeaRealize a compact representation of the index by making use of Suffix trees
Suffix tree
index

GraphGrepSX: IdeaRealize a compact representation of the index by making use of Suffix trees
Suffix tree
index

GraphGrepSX: IdeaRealize a compact representation of the index by making use of Suffix trees
Suffix tree
index

GraphGrepSX
• Preprocessing phase– replaces the hash table index by a suffix tree index
• Filtering phase– Build a query index tree– The candidate set is constructed by matching the query
index tree and the database index
• This results in a more flexible graph indexing system – different ways to build the query index– an efficient technique to reduce redundant checks

GraphGrepSX: Index structure
GraphGrepSX builds the tree index as follows:

GraphGrepSX : Index structure
GraphGrepSX builds the tree index as follows:

GraphGrepSX : Index structure
GraphGrepSX builds the tree index as follows:

GraphGrepSX : Index structure
GraphGrepSX builds the tree index as follows:

GraphGrepSX : Index structure
GraphGrepSX builds the tree index as follows:
Computed by DFS visit, the backtracking allows to find paths with the same suffix

GraphGrepSX : Index structure
GraphGrepSX builds the tree index as follows:
Computed by DFS visit, the backtracking allows to find paths with the same suffix
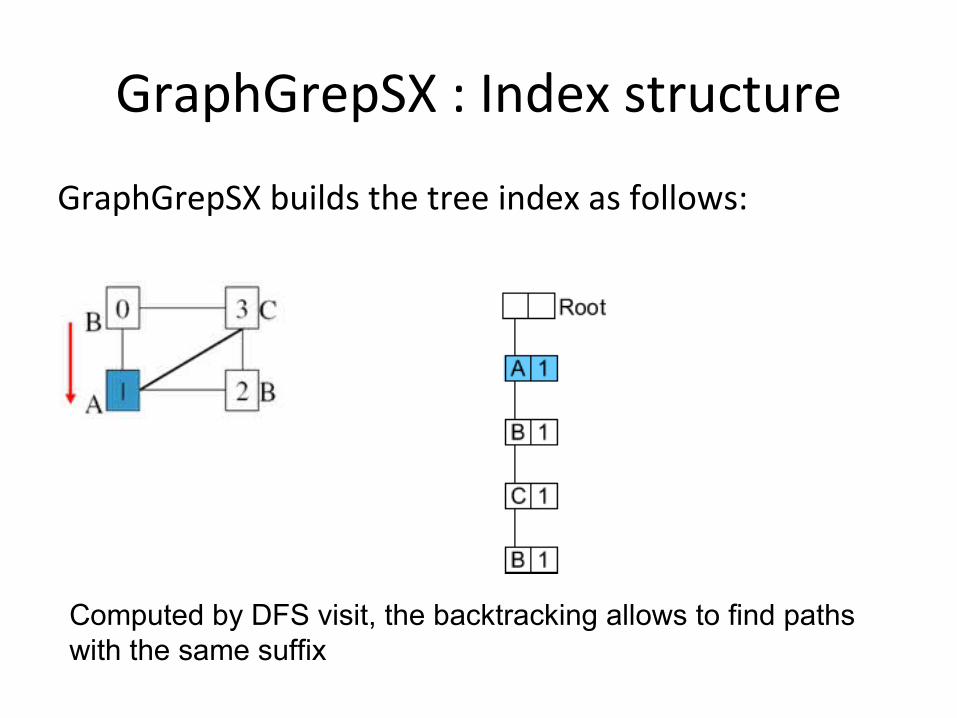
GraphGrepSX : Index structure
GraphGrepSX builds the tree index as follows:
Computed by DFS visit, the backtracking allows to find paths with the same suffix
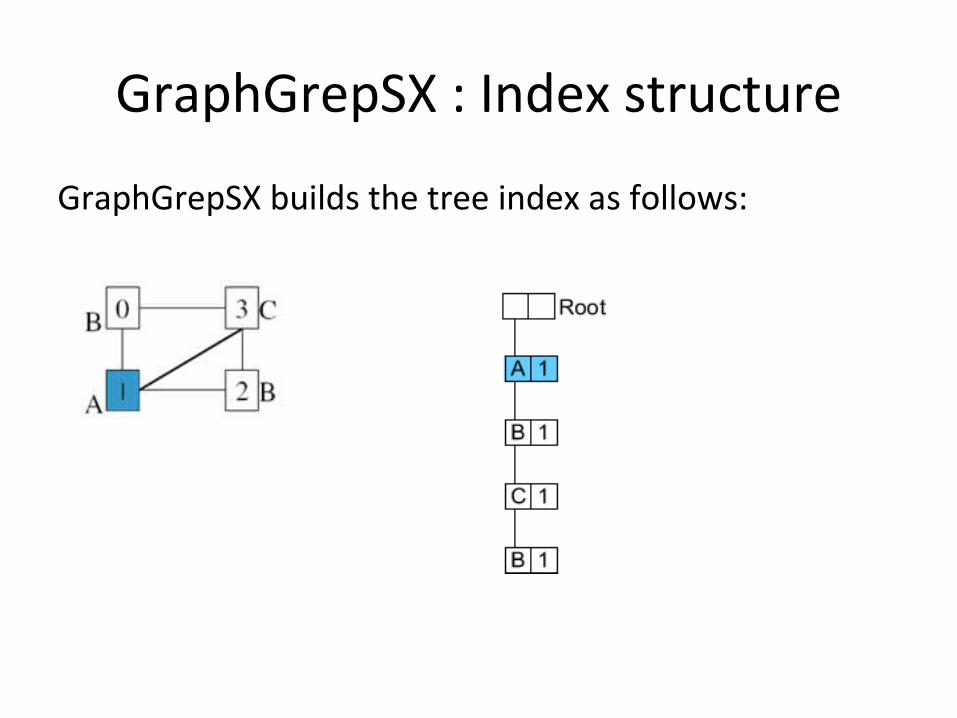
GraphGrepSX : Index structure
GraphGrepSX builds the tree index as follows:

GraphGrepSX : Index structure
GraphGrepSX builds the tree index as follows:

GraphGrepSX : Index structure
GraphGrepSX builds the tree index as follows:

GraphGrepSX : Index structure
GraphGrepSX builds the tree index as follows:

GraphGrepSX : Index structure
GraphGrepSX builds the tree index as follows:

GraphGrepSX : Index structure
GraphGrepSX builds the tree index as follows:

GraphGrepSX : Index structure
GraphGrepSX builds the tree index as follows:

GraphGrepSX : Index structure
GraphGrepSX builds the tree index as follows:

GraphGrepSX : Index structure
GraphGrepSX builds the tree index as follows:

Index construction time
Number of graphs
Build
ing
time
(sec
)
Experimental analysis on molecular dataset
http://dtp.nci.nih.gov/docs/aids/AIDS antiviral screening database

Experimental analysis on molecular dataset
Total index size
Number of graphs
Size
(Kb)
Number of graphs
Size
(Kb)
label-paths table + hashtableIndex fingerprint size
hashtable only

GraphGrepSX: Index structureA path in the index structure is defined as maximal path if:

A path in the index structure is defined as maximal path if:•its length is L
GraphGrepSX: Index structure

A path in the index structure is defined as maximal path if:•its length is L
GraphGrepSX: Index structure

A path in the index structure is defined as maximal path if:•its length is L•the path has length < L but it cannot be extended
GraphGrepSX: Index structure

A path in the index structure is defined as maximal path if:•its length is L•the path has length < L but it cannot be extended
GraphGrepSX: Index structure

A path in the index structure is defined as maximal path if:•its length is L•the path has length < L but it cannot be extended
GraphGrepSX: Index structure

GraphGrepSX: Filtering phase-Query tree index structure construction
- Discard graphs from the database which do not match the query by analyzing only the maximal paths
- In the query tree nodes representing these maximal paths are marked
Red nodes representEnd-points of Maximal Paths

GraphGrepSX: Filtering phase-candidates generation
Dataset index Query index

GraphGrepSX: Filtering phase-candidates generation
Dataset index Query index
Trees matching

GraphGrepSX: Filtering phase-candidates generation
Dataset index Query index
Trees matching

GraphGrepSX: Filtering phase-candidates generation
Trees matching

GraphGrepSX: Filtering phase-candidates generation
Trees matching
Occurrences verification

GraphGrepSX: Filtering phase-candidates generation
Trees matching
Occurrences verification
Candidates set:{g1, …}

Experimental analysisMolecular dataset of 42000 graphs
Query Time
Query dimension
Que
ry ti
me
(sec
)
filtering + matching

Experimental analysisMolecular dataset of 42000 graphs
Candidates
Query dimension
Num
ber o
f can
dida
tes

Experimental analysisMolecular dataset of 42000 graphs
Filtering time
Query dimension
Filte
ring
tim
e (s
ec)
Query dimension
Mat
chin
g tim
e (s
ec)
Matching time

Experimental analysis: CTree, GCoding, GraphGrep, GraphGrepSX
Molecular dataset of 42000 graphs
Index construction time
Tim
e (s
ec)
Number of graphs
Index size
Size
(Kb)
Number of graphs
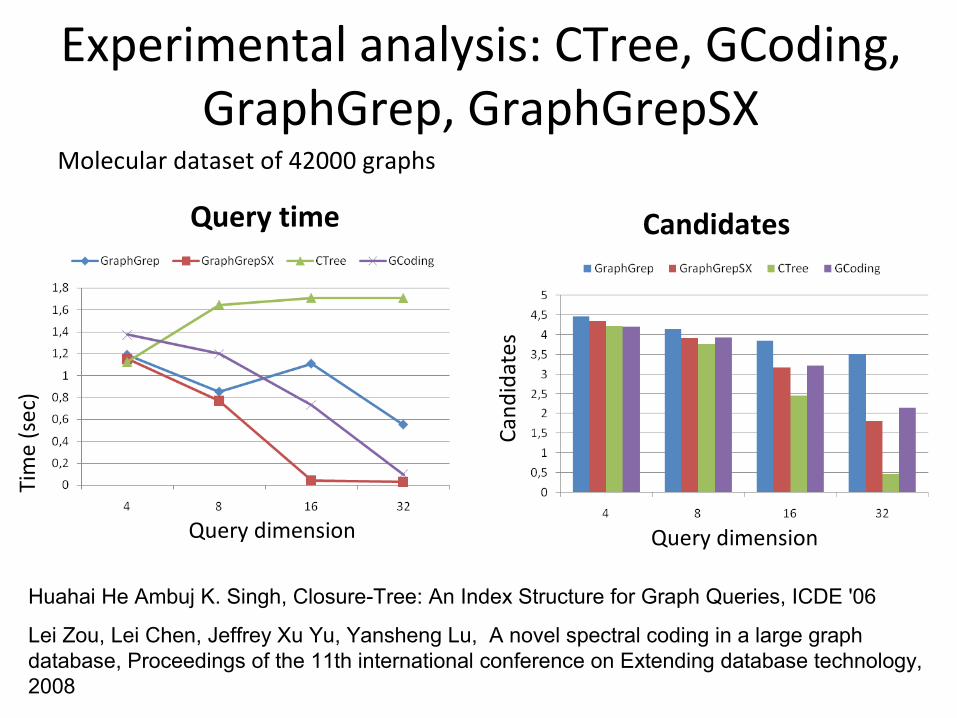
Molecular dataset of 42000 graphs
Query time
Tim
e (s
ec)
Query dimension
Candidates
Cand
idat
es
Query dimension
Huahai He Ambuj K. Singh, Closure-Tree: An Index Structure for Graph Queries, ICDE '06
Lei Zou, Lei Chen, Jeffrey Xu Yu, Yansheng Lu, A novel spectral coding in a large graph database, Proceedings of the 11th international conference on Extending database technology, 2008
Experimental analysis: CTree, GCoding, GraphGrep, GraphGrepSX

Molecular dataset of 42000 graphs
Filtering time
Tim
e (s
ec)
Query dimension
Matching time
Tim
e (s
ec)
Query dimension
Experimental analysis: CTree, GCoding, GraphGrep, GraphGrepSX

Molecular dataset of 8000 graphs
Candidates
Cand
idat
es
Query dimension
Index construction time
Tim
e (s
ec)
Experimental analysis: GraphGrep, GraphGrepSX, GIndex
Yan X, Yu PS, Han J: Graph Indexing Based on Discriminative Frequent Structure Analysis. ACM Transactions on Database Systems 2005, 30(4):960-993.

Molecular dataset of 8000 graphs
Filtering time
Tim
e (s
ec)
Query dimension
Matching time
Tim
e (s
ec)
Query dimension
Yan X, Yu PS, Han J: Graph Indexing Based on Discriminative Frequent Structure Analysis. ACM Transactions on Database Systems 2005, 30(4):960-993.
Experimental analysis: GraphGrep, GraphGrepSX, GIndex

What is it coming next?…
Collaboration networksSocial Networks
The increasing size of databases application requires efficient structure searching algorithms.
Biological Networks
Many applications in industry, science, and engineering sharethe same problem: given a subgraph, find its occurrences in a database of graphs or in large networks.

NetMatch
Graph Properties
Query Properties
Network Properties
Run the Algorithm
A. Ferro, R. Giugno, G. Pigola, A. Pulvirenti, D. Skripin, G.D. Bader, D. Shasha. NetMatch: a Cytoscape Plugin for Searching Biological Networks. Bioinformatics. vol. 23, pp. 910-912, 2007 ISSN: 1367-4803. doi:10.1093/bioinformatics/btm032.
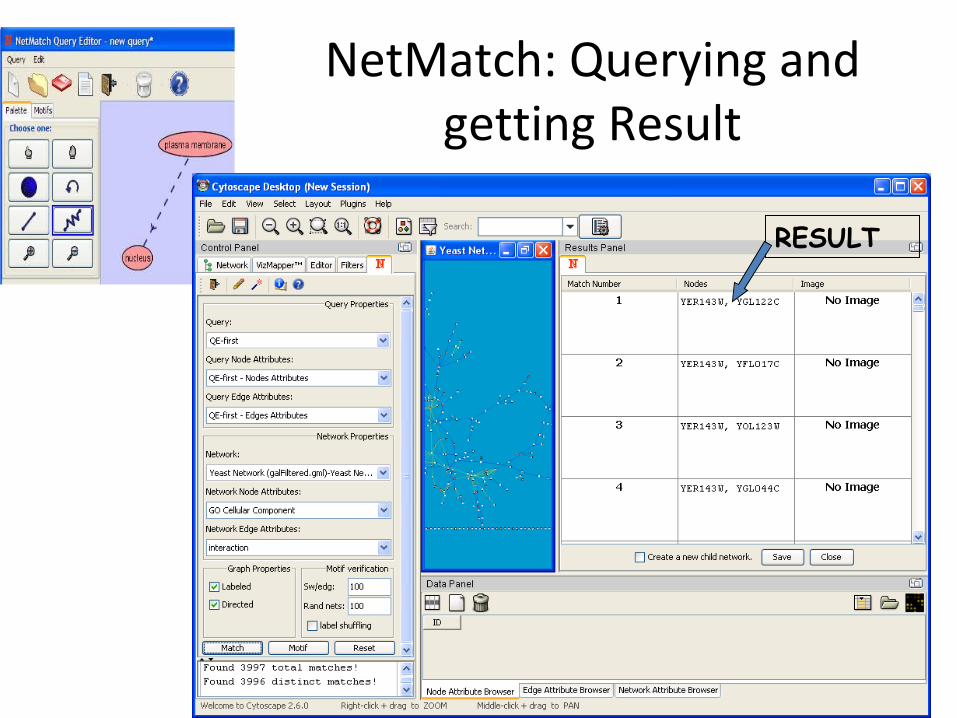
NetMatch: Querying and getting Result
RESULT

path<4
NetMatch: Analyze Results

Find Feed-Forward MotifsGraph motifs over-represented in many network types
Milo et al. Science 298, 2002
Feed-forward loop
Gene regulationNeuronsElectronic circuits

Edge Labels1=activator2=repressor3=dual
12

Find All Feed-Forward Motifs

Statistical Significance?
http://ferrolab.dmi.unict.it/
http://alpha.dmi.unict.it/~ctnyu/
Resources

Summer School 13-20 June, 2009: RNA: Structure, Function and Therapy
http://lipari.cs.unict.it/LipariSchool/SPEAKERSDr. Oliver Hobert, Howard Hughes Medical
Institute Department of Biochemistry and Molecular Biophysics, Columbia University Medical Center, New York, USA
Chris Sander, Computational Biology Center, Sander Research Lab Memorial Sloan-Kettering Cancer Center, New York, USA
Peter Stadler, Institut für Informatik, Universität Leipzig Germany
Carlo Croce, Comprehensive Cancer Center, Columbus Ohio
Debora Marks, Systems Biology Department, Harvard Medical School
Boston, MA, USA
GUEST SPEAKERSCharles R. Cantor and Graziano Pesole
TUTORIALS:
Matteo Comin: RNA-protein interaction, University of Padova, Italy
A. Pulvirenti: Algorithms for Sequence Alignment, University of Catania, Italy
R. Giancarlo: Alignment-free distances, University of Palermo, Italy
Knut Reinert: SeqAn: An efficient, generic C++ library for sequnece analysis, Institut für nformatik, Fachbereich Mathematik und Informatik, Freie Universität Berlin
Christine Heitsch: RNA structure prediction Berkeley University, School of Mathematics Georgia Institute of Technology, Atlanta, USA
Doron Betel: Non coding RNAs, Memorial Sloan-Kettering Cancer Center, New York, USA
Alessandro Laganà: Tools for miRNA genes and target prediction, University of Catania, Italy
2009