empirical design and analysis of a defect taxonomy for novice programmers · additionally novice...
TRANSCRIPT

- 1 -
Empirical Design and Analysis of a Defect
Taxonomy for Novice Programmers
Lu Zhang
This thesis is presented
For the degree of Master of Science of
The University of Western Australia
School of Computer Science & Software Engineering
2012

2
Abstract
Students in first-year computer science at many universities are required to enroll
in an introductory programming course to learn Java. Programming defects
provide useful information revealing the challenges students face in achieving
high quality code. The identification of defects also enables instructors to improve
their teaching by placing greater emphasis on those areas where students are
struggling.
In this dissertation, a range of defect types has been identified and a taxonomy -
called Novice Defect Taxonomy (NDT) – developed. This taxonomy may be used
to hierarchically classify defects in a clear and reproducible way. Its derivation
from a large number of student assignments is described. Assignments are
assessed within a defect measurement framework which combines dynamic and
static analysis. The approach measures defects in functionality, code style,
language syntax and code completeness. Based on the analyses, it is shown that
automatic assistance has a positive impact on the program quality of novice
programmers. Students rapidly accept automatic tools. Finally, this taxonomy
provides other researchers with a framework and reference baseline for
developing new defect classifications.

3
Acknowledgements
Firstly, I wish to thank my coordinating supervisor professor Rachel
Cardell-Oliver who convinced me to take the research opportunity and introduced
me to the research area. In addition, I would thank Rachel for her time giving and
extraordinary support.
I would thank my co-supervisor Terry Woodings for the useful discussion and
suggestion about the data analysis. I would thank Rachel and Terry for the
valuable advice encouragement and endless help throughout my study and fast
feedback on my writing.
I will express my thanks to CSSE computer system administrators Askley
Chew and Laurie McKeaing for their timely support.
Additional thanks goes to all my research fellows for sharing research
experience and provide help for learning research skills.
Lastly, I would express my thanks to my family for their endless support in the
last two years when I stay in Perth.

4
Publication
This dissertation contains some results from the publication:
R, Cardell–Oliver, L, Zhang, R, Barady, RH, Lim, A, Naveed, & T,
Woodings, ”Automated Feedback for Quality Assurance in Software Engineering
Education”, in Proceeding of the 2010 21st Australian Software Engineering
Conference, pp. 157-164, 2010.
The author of this dissertation is the second author of the publication above.
She takes the responsibility for the part on the results of dynamic testing.

5
Table of Contents
Abstract .............................................................................................................. 2
Acknowledgements ............................................................................................ 3
Publication ......................................................................................................... 4
Table of Contents ............................................................................................... 5
List of Figures .................................................................................................... 7
List of Tables ...................................................................................................... 8
Chapter 1 Introduction .................................................................................... 10
1.1 Motivation ............................................................................................... 10
1.2 Challenges ............................................................................................... 12
1.3 Approach and Scope ................................................................................. 13
1.4 Research Questions .................................................................................. 16
1.5 Contribution ............................................................................................. 18
1.6 Thesis Outline .......................................................................................... 19
Chapter 2 Literature Review ........................................................................... 20
2.1 Specifications of Defects .......................................................................... 20
2.1.1 What is a Software Defect?................................................................ 20
2.1.2 Defect Taxonomies ............................................................................ 22
2.1.2.1 Novice VS Experts ..................................................................... 22
2.1.2.2 Qualitative Analysis VS Quantitative Analysis of Defects ........... 24
2.1.2.3 Object Oriented Programming Languages VS Procedural
Languages .............................................................................................. 25
2.2 Measurement of Defects ........................................................................... 26
2.2.1 Automatic Assessment ....................................................................... 26
2.2.2 Code Inspection ................................................................................. 27
2.3 Categories of Defects ............................................................................... 27
2.4 Research Gaps.......................................................................................... 28
Chapter 3 Data Collection for the Defect Taxonomy ...................................... 30
3.1 Subject and Exercise Choice .................................................................... 30
3.1.1 Subject Choice .................................................................................. 30
3.1.2 Exercise Choice ................................................................................. 31

6
3.2 Data Collection Mechanism ...................................................................... 33
3.3 Defect Measurement ................................................................................. 35
3.3.1 Software Attributes for Measuring ..................................................... 35
3.3.2 Defect Counting Approaches ............................................................. 36
3.3.3 Defect Detection Framework ............................................................. 37
3.3.4 Compilation Detection ....................................................................... 39
3.3.5 Evolvability Fault Detection .............................................................. 39
3.3.6 Functional Correctness Detection....................................................... 40
3.3.7 Code Inspection ................................................................................. 48
3.4 Measurement Instruments ......................................................................... 51
3.4.1 Integrated Development Environments .............................................. 51
3.4.2 JUnit .................................................................................................. 51
3.4.3 Checkstyle ......................................................................................... 52
3.4.4 PMD .................................................................................................. 52
3.5 Comparison of Static Analysis Tools......................................................... 53
3.6 Static Analysis Tools in Practice ............................................................... 54
3.7 Measurement Risks .................................................................................. 55
Chapter 4 Novice Defect Taxonomy Specification .......................................... 57
4.1 Novice Defect Taxonomy ......................................................................... 57
4.2 Defect Specification ................................................................................. 59
4.3 Summary .................................................................................................. 75
Chapter 5 Analysis Using the Novice Defect Taxonomy ................................. 76
5.1 Comparison of NDT Defect Categories with Other Defect Taxonomies .... 77
5.2 Quantitative Analysis of Defects ............................................................... 79
5.3 Defect Patterns and the Difficulty of Exercises ......................................... 80
5.4 Using NDT to Analyze the Impact of Automatic Feedback ....................... 82
5.5 Using NDT to Improve Teaching Strategy ................................................ 87
5.6 Summary .................................................................................................. 90
Chapter 6 Conclusion....................................................................................... 91
6.1 Contribution ............................................................................................. 91
6.2 Future Work ............................................................................................. 91
6.3 Conclusion ............................................................................................... 92

7
List of Figures
Figure 1.1. Research Areas Addressed in this Study …………………………….14
Figure 3.1. Recommended Process for Completing a Programming Assignment 34
Figure 3.2. A Summary of Measurement Validation Concepts ............................ 36
Figure 3.3. An Overview of a Defect Measurement Process ............................... 38
Figure 3.4. The TextAnalyser Assignment .......................................................... 41
Figure 3.5. Test Cases for frequencyOf() ............................................................ 43
Figure 3.6. An Example of Buggy Fragment of Class TextAnalyser ................... 44
Figure 3.7. Detect Coverage of Static Analysis Tools ......................................... 53
Figure 3.8. A Solution of Class CustomersList ................................................... 54
Figure 4.1. Novice Defect Taxonomy ................................................................ 58
Figure 4.2. Levels 1 and 2 of the Novice Defect Taxonomy ............................... 59
Figure 4.3. CANNOT COMPILE Class .............................................................. 60
Figure 4.4. FUNCTIONAL DEFECT Taxonomy ................................................ 64
Figure 4.5. EVOLVABILITY DEFECT Taxonomy .............................................. 70

8
List of Tables
Table 2. 1. Comparison of Defect Taxonomies (Main Categories) ..................... 28
Table 3. 1. Student Experience and Laboratory Support for Different Cohorts .. 31
Table 3. 2. Sizes of Java Assignments ............................................................... 32
Table 3. 3. Java Language Constructs used in Assignments ............................... 32
Table 3. 4. Cohort Size and Submissions for Each Assignment ......................... 33
Table 3. 5. Metrics for Evolvability Fault Detection .......................................... 39
Table 3. 6. Test Case Failures and Relevant Defects in Program ........................ 48
Table 3. 7. Functional Property Inspection Form ............................................... 49
Table 3. 8. Functional Defect Count Checklist .................................................. 50
Table 5. 1. Top Ten Defects from the UWA Data Set ......................................... 80
Table 5. 2. FUNCTION MISSING (D2.1.1.1) Defects for Labs at Different
Complexity Levels ........................................................................................... 81
Table 5. 3. Distribution of Novice Defects ........................................................ 83
Table 5. 4. Error Information (TDC) of Lab B1 and D1on the Basis of
Sub-classes of FUNCTIONAL DEFECT ....................................................... 84
Table 5. 5. Error Information (CDC) of Lab B1 and D1 on the Basis of
Sub-classes of FUNCTIONAL DEFECT ....................................................... 84
Table 5. 6. Error Information (TDC) of Lab B1 and D1 on the Basis of Bottom
Level Classes of FUNCTIONAL DEFECT ................................................... 85
Table 5. 7. Error Information (CDC) of Lab B1 and D1 on the Basis of Bottom
Level Classes of FUNCTIONAL DEFECT ................................................... 85
Table 5. 8. Error Information (TDC) of Lab B1 and D1 on the Basis of
Sub-classes of EVOLVABILITY DEFECT .................................................... 86
Table 5. 9. Error Information (CDC) of Lab B1 and D1 on the Basis of
Sub-classes of EVOLVABILITY DEFECT .................................................... 86
Table 5. 10. Error Information (TDC) of Lab B1 and D1 on the Basis of Bottom
Level Defect Types of EVOLVABILITY DEFECT ........................................ 87
Table 5. 11. Error Information (CDC) of Lab B1 and D1 on the Basis of Bottom

9
Level Defect Types of EVOLVABILITY DEFECT ....................................... 87
Table 5. 12. Common Programming Problems, Teaching Strategies and Solutions
......................................................................................................................... 88
Table 5. 13. Top Defect Class, Novice Problems Underlying & Solution in
Teaching Strategies ....................................................................................... 89

10
Chapter 1 Introduction
Students in first-year computer science at the many universities are required to
enroll in an introductory programming course to learn Java. Programming defects
provide useful information revealing the challenges students face in achieving
high quality code. The identification of defects also enables instructors to improve
their teaching by placing greater emphasis on those areas where students are
struggling. In this dissertation, a range of defect types covering functionality
defect, code style defect, syntactic defect and code completeness defect have been
identified and a taxonomy called Novice Defect Taxonomy (NDT) has been
developed.
In this chapter, the motivation for our research is discussed in Section 1.1. Then,
the challenges are summarized in Section 1.2 followed by the approaches taken
and the scope of the study in Section 1.3. Section 1.4 outlines eight research
questions addressed in this dissertation. Section 1.5 summarizes the contributions
of this study.
1.1 Motivation
Writing error-free programs is not easy for students from the very beginning no
matter how simple the tasks are. Various aspects may affect novices‟ learning
outcomes: personal characteristics, personal learning strategies, and prior
knowledge and practices. Personal characteristics such as general intelligence and
mathematics background also seem to affect the success of learning to program
(Ala-Mutka 2004). Personal learning strategies affect novices‟ success in learning

11
programming strategies (Ala-Mutka 2004; Robins, Rountree & Rountree 2003).
Additionally novice difficulties are associated with understanding the abstract
nature of programming (Ala-Mutka 2004; Lahtinen, Ala-Mutka & Jarvinen 2005;
Robins, Rountree & Rountree 2003). Students often believe they understand
concepts in programming but they still fail to use them properly (Ala-Mutka
2004). Knowing students‟ difficulties provides an instructor with a chance to
understand their misconceptions in programming. Spohrer & Soloway (1986)
argued „the more we know about what students know, the better we can teach
them.‟ Empirical findings obtained from analyzing a large number of student
submissions enable the instructor to place greater emphasis on student problems
and thereby tailor their curriculum accordingly.
A Software Defect is an imperfection that produces a departure of system from
its required behavior (IEEE, 2010). A Defect Taxonomy is a system of hierarchical
categories for classifying the defects found in programs. The defect taxonomy is
organized by both low-level and high-level categories. Many studies have
investigated the types of defects in software and many high categories for
arranging the quantitative data have been reported (Ahmadzadeh, Elliman &
Higgins 2005; Hristova et al. 2003). However, providing high level categories
only without any lower level sub-categories failed to match the defects found in
student programs (Chillarege, Kao & Condit 1991). The defects made by students
usually involve lower level cases. The hierarchical defect taxonomy introduced in
this dissertation is used to classify defects in students‟ programming assignments
at four different levels of abstraction. The focus in our work is on identifying
defects rather than assessing their causes.
Researchers have analyzed a wide span of defect possibilities covering
functional, style, efficiency, performance, logic, syntax and completeness defect in
programs (Ahmadzadeh, Elliman & Higgins 2005; Chillarege et al. 1992;
Chillarege, Kao & Condit 1991; Coull et al. 2003; Hristova et al.2003; Jackson,
Cobb & Carver 2004; Kopec, Yarmish & Cheung 2007; Mantyla & Lassenius
2009; IEEE 2010). This study will analyse the defect types of functionality,
programming style, syntax and completeness in novices‟ programs and develop a
well-designed defect taxonomy by labeling defects detected from their code. A
well-designed defect taxonomy developed hierarchically could help instructors
indentify common defects made by novice programmers. We believe that

12
identifying defects in student programs can help students focus on their problems
and make necessary corrections. Furthermore, analysis using this taxonomy shows
instructors what areas challenged beginners most. Analysis using the taxonomy
additionally supports the improvement of teaching strategies by enabling
instructors to compare the code that a cohort of students produces when given
different teaching interventions.
1.2 Challenges
Detecting and categorizing defects in students‟ programs is a challenging problem.
Programming assignments as a kind of summative assessment are set and marked
to summarize students‟ performance at a particular time. In this study, automatic
marking and formative feedback are generated to help students to perform a
self-assessment process that thereby encourage students to master the practical
knowledge, skills and tools needed for programming. A lot of learning happens
when students undertake programming tasks. The programming assessment in this
study is formative rather than summative. Additionally, hand marking of
assignments is time consuming because the content of all submissions should be
inspected thoroughly. Automatic approaches can be used for both static and
dynamic analysis of programs. However, automatic systems are not as flexible as
human assessors and so may misclassify innovative solutions (Ala-Mutka 2004).
A compromise is to use automatic tools to assess some aspects of a program
and manual approaches to assess others (Ala-Mutka 2004). First feedback is
generated from automatic measurement tools. Subsequently, manual code
inspection supports a further code review that may capture more subtle defects in
student programs. We use the mixed automatic and manual approach for analyzing
student programs to develop our novice defect taxonomy.
Another challenge for defect measurement is how to generalize the contents of
defects and match them with existing taxonomies. Labeling errors is affected by
assessors‟ cognitive knowledge and their programming experiences. When
classifying a defect, it can be difficult to match the defects captured by program
measurement with a category of a defect taxonomy. For example, the difficulty of
placing an error into semantic or logic group has been identified as a problem by

13
Hristova et al. (2003). Our novice defect taxonomy provides a hierarchy of
categories to assist in the accurate classification of defects captured by assessing
student programs.
1.3 Approach and Scope
The purpose of our study is to develop a new defect taxonomy for classifying the
defects found in students‟ programs. The methodology we have used contains the
following steps:
1. We derive categories of defects for students‟ programs from existing defect
taxonomies and make a defect list covering the main findings (Chapter 2);
2. We first use automatic analysis tools to capture the defects in a series of
laboratory exercises completed by a student cohort. Code inspection is
then performed to refine the defect list. New defects identified from this
process are added to this defect list. Repeat step 2 until no new defects are
identified (Chapter 3);
3. We develop a hierarchical taxonomy containing all defects on the list. We
specify a definition and a detection approach for each defect (Chapter 4);
4. We evaluate the defect taxonomy by using it to capture defects in nine
exercises completed by four cohorts (1271 submissions in total). Both
defect types and distributions for each exercise have been identified. The
information provides feedback to help students produce high quality code
and can be used to improve teaching strategies (Chapter 5).

14
Figure 1.1. Research Areas Addressed in this Study
This study focuses on the areas, shown in Figure 1.1. Data acquired from
practical sessions is combined with theoretical knowledge to evaluate the quality
of student assignments. Information on defects gained from submission diagnosis
provides researchers with new reference for defect analysis. The landscape of
measurement strategy in this research is associated with objective measures using
assessment tools and techniques, and the subjective measures when instructors
perform code inspections on students‟ Java programs. We evaluate the NDT using
both qualitative and quantitative analysis of a corpus of student programs.
Defect Pattern
What are common
patterns of defects observed during diagnosis?
Evaluation
How can we evaluate NDT?
Knowledge
How to understand software defects in programs and organize them into
NDT?
Defect Type
What factors are measured to assure software quality?
Software
Defect
Measurement
Strategy How can we measure defects in
software?
Assessment Tools
What tools can be used to efficiently measure defects in software?
Humans
How humans measure defects in software?
Qualitative Analysis
What kinds of defects students are encountered?
Improvement
How can we improve teaching strategies to reduce defects in student programs?
Assessment
Techniques
What techniques are used to measure
defects in software?
Quantitative
Analysis
What are the distributions of defects in
programs?

15
Specifically within these research areas, our research targets the following topics:
Knowledge
Defect Type
Defects are grouped by the types of functionality, programming style, language
syntax and code completeness.
Defect Pattern
We discover the defect patterns made by students when they complete a series of
laboratory exercises. The data from defect analysis suggests ways to improve
teaching strategies in an introductory programming course.
Measurement Strategy
Assessment Techniques
It is necessary to recognize techniques implemented for assessing students‟ code
automatically. There are two techniques implemented for analysis: static analysis
and dynamic analysis. Assessment is performed automatically by these two
techniques to capture defects in assignments.
Assessment Tools
Several tools, such as suite of test cases and a code style checker, are provided to
students to allow them to assess their code. These tools will also be employed to
help identify defects that will then be classified using the NDT.
Code Inspection
Instructors discover defects in students‟ assignments by performing a thorough
line-by-line inspection on programs. Manual inspection helps to identify
additional defects in students‟ programs.
Evaluation
Qualitative View
A defect taxonomy is a classification scheme that represent software defect types
in a systematic structure.
Quantitative View
Counting the numbers of defects in a large number of assignments identifies the

16
most frequent defects novices encountered. Lecturers are able to improve their
courses by placing greater emphasis on the areas addressed.
Improvement
Analysis using NDT reveals the challenging areas that students face. This
information provides an evidence for the improvement of programming
assignment setting and grading.
1.4 Research Questions
This dissertation presents a new defect taxonomy for classifying defects
discovered in students‟ programming assignments. Our study aims to organize
defects in a systematic way and provide a tool for evaluating the computer
programs of individuals or a cohort. We divide the overall problems into a total of
eight research questions. Answering these research questions might help to
understand how NDT can be used to detect faults in programs. There are five
overarching research questions (Section 1.4.1, 1.4.3, 1.4.5, 1.4.6 and Section 1.4.7)
I‟d like to address. Three sub-questions (Section 1.4.2, 1.4.4 and 1.4.8) are added
to extend the breadth of thesis scope.
The data used to answer the following questions are gathered from qualitative
and quantitative analysis of nine assignments completed by four cohorts. Patterns
derived from qualitative and quantitative analysis provides insights into the way
students produce defects. The defect patterns found in this study help instructors
improve their setting and grading system of practical exercises. Evaluation using
NDT reveals novices‟ common problems in programming and enables instructors
to improve their teaching by revealing the main challenges students face in
programming.
1.4.1. What types of defects are identified from student submissions?
This research question explores what types of defects occur in student
assignments. We analyse the areas of functionality, style quality, compilation
behavior and code completeness. NDT is used as a tool to classify the defects.
1.4.2. How are these types related to existing defect taxonomies?

17
There are many defect categories in NDT derived from previous studies. They are
actually a superset of prior work. Some defect categories in NDT have been never
identified by previous studies. Another concern is that most previous studies of
defects in students‟ code are limited to only one defect area such as syntax error
analysis by Histova et al. (2003) or logic error analysis by Ahamadzadeh, Elliman
& Higgin (2005). But this study covers four areas of defects in programs.
1.4.3. What are the most common defects made by novices?
Assessing many different program aspects helps to determine what aspects
challenge students the most when they program. This study assesses students‟
assignments and captures defects covering four types: functionality defect; style
defect; language syntactic defect and code completeness defect.
1.4.4. Are these defects consistent with previous work?
Prior published work concentrates on explaining the content of defects and
exposes the distributions for each defect. Qualitative analysis in this study
emphasizes identifying the most common defect types. Counts of defects are used
to evaluate our taxonomy from a quantitative view. Additionally, these counts
show areas where students are having or not having problems.
1.4.5. What do cohort defect patterns tell us about programming exercises?
Patterns derived from empirical work demonstrate the problems students
encountered when they complete a laboratory task. For example, if many students
postponed submitting then the exercise may have been too hard. The analysis of
defect patterns in a cohort contributes to the improvement of practical exercises in
an introductory programming course.
1.4.6. How does the provision of formative feedback with programming
support tools affect the defect rates in submitted assignments?
Students are provided with tools for self-assessment of their code. The tools are
the same ones used to measure defects for our NDT. These tools generate
formative error messages to warn students about defects in their programs and
provide suggestions on how to make corrections on their programs. Because the
teaching laboratory environment changes from year to year, it is possible to use
the NDT to analyze the effect of different lab tools on student programs. We
expect that students produce programs with fewer defects when they are given

18
automatic aids in labs.
1.4.7. Which sorts of problems can be reduced?
Previous studies argue that up to half of the mistakes made can be avoided with
better programming techniques including better programming languages and more
comprehensive test tools (Endres 1975). In this study, quantitative analysis is used
to expose common defects students are prone to make.
1.4.8. What is the related strategy in programming teaching?
In the last question, we list the most common defects identified by using NDT.
For each defect identified, a possible teaching solution is available to suggest the
improvement of teaching strategies. We believe these solutions that instructors
could employ to minimize these types of defects and help to reduce the defects in
submissions.
1.5 Contribution
In this dissertation, we analyse a large number of student programs (1271
submissions) completed by four student cohorts and identify a range of defect
types covered four areas. The main contributions of this dissertation are:
Identification of new defect categories specific to novice programmers covers
the types of code completion defects, code compiled defects, functional
defects and evolvability defects;
Establishing a taxonomy called Novice Defect Taxonomy (NDT) developed
by the new defect categories identified from empirical work;
Reporting the frequency of defects in NDT that helps instructors to pay more
attention to the most common defects and helps novices to avoid making
these defects;
Describing defect measurement mechanism using both automated approaches
and manual methods to detect defects in programs;

19
1.6 Thesis Outline
In this dissertation, Chapter 2 summarizes relevant theoretical studies about
novices‟ difficulties and existing defect taxonomies. Research gaps are discussed
in Section 2.4. Chapter 3 introduces the measurement process we use and outlines
the testing techniques and related tools implemented in this study. Then, Chapter 4
defines the Novice Defect Taxonomy (NDT) and its measurement protocols.
Chapter 5 summarizes the results of experiments using NDT to analyze students‟
code and answers our research questions. Chapter 6 proposes directions of future
work and concludes this study.

20
Chapter 2 Literature Review
Section 2.1 summarizes previous theoretical studies about software defects and
existing defect taxonomies. Prior work by other researchers has focused on of the
characteristics of both novices and experts in programming, qualitative and
quantitative analysis of software defects, and the analysis of defects in different
programming languages. A summary of approaches and techniques for measuring
defects in software is presented in Section 2.2. Then, Section 2.3 compares the
coverage of existing defect taxonomies with this study. Finally, Section 2.4
identifies three open research problems addressed in this dissertation.
2.1 Specifications of Defects
The specific focus of this study is on software defects in students‟ assignments
and previous taxonomies for classifying those defects.
2.1.1 What is a Software Defect?
Defects play an important role in software because they lead a program to act in
an unintended way. Existing studies have investigated many terms error, fault,
failure, problem related to software defects. Their definitions do vary greatly from
paper to paper .We first review previous literature of the definitions of these terms.
Then we give a clear definition of a defect in a student‟s assignment before we
undertake analysis.

21
Definition: “The word anomaly may be used to refer to any abnormality,
irregularity, inconsistency or variance from expectations. It may be used to refer
to a condition or an event, to an appearance or a behavior, to a form or a function”
(IEEE 2010).
Definition: An error is “a human action that produces an incorrect result”
(ISO/IEC 2009).
Definition: “A failure is an event in which a system or system component does
not perform a required function within specified limits” (ISO/IEC 2009).
Definition: A fault is “a manifestation of an error in software” (ISO/IEC 2009).
Definition: “A software problem is a human encounter with software that causes
difficulty, doubt, or uncertainty in the use or examination of the software” (Florac
1992).
Definition: Software defects are defined as follows (Mantyla & Lassenius 2009,
pp. 2):
(1) Failures “should be counted as defects if they cause the system to fail or
produce unsatisfactory results when executed”;
(2) Faults are “incorrect code, which may or may not result in a system failure”;
and
(3) “Deviations from quality” are counted when program changes are made.
Definition: “A software defect is a manifestation of a human (software producer)
mistake” (IEEE 2010).
Many studies investigate defects in programs made by students (see Table 2-1)
but none of them provides a clear definition of software defect. It is necessary to
define a software defect in a student assignment before we perform empirical
work for analyzing defects in submissions.
Definition: A software defect, in a student programming assignment, describes an
imperfection in programming steps prevented the program from performing in
conformance with the specifications. It may refer to serious problems that prevent
the software from being executed or style problems that cause the program to
perform in an intended way.
This dissertation focuses on identifying software defects in students‟

22
assignments rather than assessing their causes. It provides a detailed investigation
of four areas: functionality, code style, language syntax and code completeness.
2.1.2 Defect Taxonomies
A defect taxonomy is used to classify defects in software. It provides a unique
category for each defect detected and provides a systematic way to “measure the
number of defects remaining in the field, the failure rate of the product, the defect
detection rate” (Musa, Iannino & Okumoto 1987).
Definition: A software defect taxonomy is a hierarchical classification scheme
used for categorizing software defects. A hierarchical taxonomy is used to classify
defects in a reproducible way.
Identification of defects in software helps students to realize their challenges in
achieving high quality code (Mantyla & Lassenius 2009). A defect taxonomy
offers program beginners a classification scheme to identify defects from students‟
submissions. Prior studies of the defect taxonomy may analyze the same area so
that their findings may be consistently “share many defect types” (Mantyle &
Lassenius 2009). However, these taxonomies may “miss defect types or use
restrictive definition” (Mantyla & Lassenius 2009). For example, the problems of
unexpected submission or code style have received little attention from prior work.
In this study, we will propose a taxonomy contains four areas: functionality, style
quality, language syntax quality and code completeness which will be discussed in
Chapter 4.
2.1.2.1 Novice VS Experts
Existing defect taxonomies target different groups from novices, advanced
students to more experienced programmers. Robins, Rountree & Rountree (2003)
described the process of a novice becoming an expert breaks in five stages:
“novice, advanced beginner, competence, proficiency and expert”.
Many previous papers summarize novices‟ characteristics in programming.
Typical curricula usually start with teaching a set of concepts of a programming

23
language. First-year students always have many misunderstandings when they
apply these concepts into practice. Novices believed they understand the concepts
but they failed to “apply relevant knowledge” (Robins, Rountree & Rountree
2003).Additionally, novices may understand the programming syntax and
semantics line by line, but they fail to combine these features into a valid program.
Robins, Rountree & Rountree (2003) argued that novices‟ deficits were in “the
surface understanding and various specific programming language constructs”.
Novices spent little time on program comprehension and planning while experts
spent a large proportion of time on that (Robins, Rountree & Rountree 2003).
Ala-Mutka (2004) also argued that beginners lacked background knowledge and
were “limited to surface knowledge „line by line‟ rather than larger program
constructions”. Kessler & Anderson (1989) argued that novices “often apply the
knowledge they learned improperly”. The ability to write good programs is not
directly linked to the ability to understand a program. Although novices can write
functionally correct code, they may still have problems in understanding code
written by others (Ahmadzadeh, Elliman & Higgins 2005).
By comparison, studies about experts in programming focus on their
knowledge structure and their programming strategies. Experts focus on the
representation of sophisticated knowledge and problem solving strategies rather
than surface knowledge. For example, the defect of submitting the wrong file
occurred frequently for novices (Coull et al. 2003). However, that would never
occur for experts. Detienne (1990) modeled the way that experts organized
knowledge and put programming skills into practice. Compared with novices,
experts mastered the programming knowledge and skills better and applied them
in programming more thoroughly.
Another information source of novices‟ debugging activities is about students‟
debugging performance in programming (Ahmadzadeh, Elliman & Higgins 2005).
Program debugging is an important activity in programming. Although various
approaches have been introduced in teaching, students mainly gain their
debugging strategies from practical sessions. Previous research additionally paid
attention to the differences of debugging behaviors between experts and novices.
Gugerty & Olson (1986) conducted two experiments to make a comparison of
experts and novices in their debugging habits. In the debugging process, experts
could fix more bugs and complete their work in a shorter time. They spent more

24
effort on program comprehension and remembered program details much better
than novices. Compared with experts, novices obtained knowledge inconsistently.
They might isolate one error and make the proper correction, but failed to correct
further errors and failed to apply debugging techniques in all situations. Novices
were always struggling with errors in program compilation because they lacked
debugging and programming experience.
This analysis emphasizes defects made by students in programming rather than
professional programmers. Since novices make different errors than experts, a
taxonomy for them needs different categories. Our defect taxonomy is required to
be more stringent on the quality of code completion and code syntax that might be
not addressed by previous studies.
2.1.2.2 Qualitative Analysis VS Quantitative Analysis of Defects
Qualitative analysis identifies defect types in students‟ programs. Coull et al.
(2003) developed a module to extract students‟ compiler error messages. All
common compiler errors are classified into four types: “files not added, incorrect
case, ; expected and } expected” (Coull et al. 2003). The last two types (;expected
and } expected) conform to compiler errors identified by Jackson, Cobb & Carver
(2004). However, the findings of these studies were limited by the data collected
from one semester-size cohort only. The results of error analysis may fluctuate
because the sample data is limited. Many efforts have been devoted to identify the
types of defect made by professionals. The IEEE classification is applicable for
classifying defects in any software or to any phase of the project, product or
system life cycle (IEEE 2010).
Helping students to identify their style defects benefits them in improving their
code quality. Mantyla & Lassenius (2009) showed that style problems account for
approximately 75% of the detected defects in software. Their study showed that
style defects were a large proportion of the total count compared with other defect
types found in programs by both novices and professional engineers.
Comprehensive information about programming defects in the Orthogonal Defect
Classification (ODC) model was reported by Chillarege et al. (1992). Their ODC
model extracted cause-effect relationships between defects and code development,
and associated defects with the development processes. The ODC model, however,
covered defect categories of high occurrence only and did not provide a low-level

25
taxonomy for each defect.
Quantitative Analysis involves counting the number of defects in any collection
of software modules. The defects are first classified then counted in quantitative
analysis. Truong, Roe & Bancroft (2004) listed four logic errors that occurred
most frequently in novice programs: “omitted break statement in a case block”;
“omitted default case in a switch statement”; “confusion between instance and
local variables” and “omitted call to super class constructor”. Jackson, Cobb &
Carver (2004) developed an error collection system to collect all syntax errors and
they explored the most frequent syntactic errors from the collection system. All
defect taxonomies count defect numbers, but our taxonomy is also evaluated from
qualitative analysis perspective so as to refine its defect categories.
2.1.2.3 Object Oriented Programming Languages VS Procedural
Languages
Many universities have changed from teaching novices a procedural programming
language in their first year to teaching an object oriented programming language
such as Java. Prior studies investigated defects in students‟ programs from a
language-based perspective. Lahtinen, Ala-Mutka & Jarvinen (2005) conducted an
international survey of students‟ programming difficulties in learning Java or C++
from students‟ and teachers‟ perceptions. They found that the practical learning
environment benefit programmers most and the experiences gained from the
practical situation enhance learning of concepts. Another interesting finding is that
compared with students, teachers may recognize beginners‟ deficiencies better
than novices themselves believed. The findings of students‟ deficiencies can be an
evidence to develop learning materials to overcome the difficulties they
encountered. Robin, Haden & Garner (2006) derived a problem list by conducting
a survey of relevant literature. The problem list was evaluated by exploring the
distribution of its problem types and this list directed the information from
diagnosing code aspects to improve the design and the delivery of exercises. In
this study, we will develop a defect classification as a resource for Java, an object
oriented language whereas most prior work focused on procedural languages.
Three studies have highlighted students‟ problems in using the procedural
languages. Pea (1986) identified persistent conceptual bugs of parallelism,
intentionality and egocentrism derived from a bug called “superbug”. Their study

26
also identified novices‟ characteristics in writing and understanding the code.
Chabert & Higginbotham (1976) investigated novice errors in assignments using
Assembly Language, and listed types and frequencies of nine errors discovered by
experiments. Kopec, Yarmish & Cheung (2007) identified students‟ errors and
located them in program components when students used the C language.
2.2 Measurement of Defects
2.2.1 Automatic Assessment
Automatic assessment has been introduced in computer science education to
assess students‟ programs. This assessment approach offers instructors an efficient
tool for grading programs and offers students timely feedback to fix defects in
their programs. In this study, the assessment of more than 1200 classes requires a
significant amount of instructors‟ time and effort. The automated assistance
therefore, would reduce the workload of instructors.
Ala-Mutka (2005) summarizes several code features that can be measured
automatically. Once students submit their source code to a central repository
several code aspects can be assessed dynamically or statically. Static evaluations
are performed by collecting information from the source code without executing it.
Dynamic assessments evaluate students‟ programs by executing them (Ala-Mutka
2005). In dynamic assessment, automated tools can actually assess users‟ testing
skills when they are asked to design their own test cases and use these test cases to
test their code (Edwards 2004). Automated tools also assess some specific features
(e.g. language specific implementation issues, memory management) (Ala-Mutka
2005). Dynamic tools execute assignments against a set of test cases to measure
programs‟ functional correctness. Prior work investigates that taking unit testing
approach has a positive effort not only to students in “two humped camels” but
also to the middle learners (Whalley &Philpott 2011). Static tools evaluate code
features (e.g. coding style, design and software metrics) without executing these
programs. Truong, Roe & Bancroft (2004) develop a measurement framework by
using static tools to compare the software metrics and the structural similarity of a
submission with a suggested model solution.
For dynamic assessment, JUnit (JUnit4, n.d.) is used to test the code

27
functionality. Static analysis is performed using Checkstyle (Checkstyle 2001) and
PMD (PMD 2002). These tools will be discussed in the next chapter.
2.2.2 Code Inspection
Automatic assessment is widespread in software engineering education. However,
automatic systems may be inflexible and so unable to award marks for the
innovative solutions (Ala-Mutka 2005). Jackson (2002) argues that automated
assessment can be combined with human components to assess code quality. Code
inspection is a systematic approach to look through the source code line by line.
Code inspections can be combined with automatic analysis as a compromise to
overcome the disadvantages of automatic approaches. This semi-automatic
approach combining code inspection with automatic assessment assesses the
assignments of large student cohorts in this study. First error messages from
automatic assessment are used to extract assignments containing defects. Then,
code inspection is used to identify defects in students‟ assignments. During code
inspections, it is possible to determine which defect category a defect belongs to.
For example, placing a defect into types of “assignment malformed” or
“assignment missing” requires a human component‟s effort because automated
tools cannot distinguish between these detected defects automatically. The
description of how to detect and classify detected defect will be presented in
Section 3.3.6. Code inspection helps to avoid uninformative or inappropriate
feedback that produces inaccurate information of subtle defects in software.
2.3 Categories of Defects
A comparison of high level defect categories of this study and of previous work is
shown in Table 2.1. In this study, novice defects fall into four categories:
completeness, language syntax, functionality and evolvability. The column on the
right, Assurance Perspective is used to specify previous software defect studies
from either the educational perspective or professional perspective.

28
Previous studies&
our NDT
Quality Assurance
Aspects
Assurance
Perspective
Completeness Syntax Functionality Evolvability Educational (E) or
Professional (P)
Ahmadzadeh, Elliman & Higgins 2005
√ √ E
Chillarege et al. 1992 √ √ P
Coull et al. 2003 √ √ E
Hristova et al.2003 √ E
IEEE 2010 √ √ P
Jackson, Cobb & Carver
2004 √ E
Kopec, Yarmish & Cheung 2007
√ √ E
Mantyla & Lassenius 2009
√ √ P
NDT in this research √ √ √ √ E
Table 2. 1. Comparison of Defect Taxonomies (Main Categories)
Several previous studies have been compared with this study by making a
comparison of quality assurance aspects between these studies, In Table 2.1, the
majority of educational studies focus more on the ranges of the code functionality
defects or syntactic problems in programs. The previous investigations of
professional programmers mainly emphasize functionality validation of the
software and the code evolvability. Only one study (Coull et al. 2003) in Table 2.1
focuses on the problem of incomplete code in programs. In Table 2.1, the ranges
of language syntax and code functionality have been widely studied whereas
defects of code style and code completeness are addressed by only a few studies.
However, in this dissertation our taxonomy (NDT) from educational perspective
covers all four areas of novice defects.
2.4 Research Gaps
This study aims to fill in the research gaps: the taxonomy with only high-level
categories; limited data sample for empirical analysis; and ambiguous
classifications for defect analysis.
There are several deficiencies in existing studies. It must be noted that several
studies specify taxonomies to fit defects identified in software made by
professional programmers. However, findings from these studies are difficult to fit
in students‟ programs (Ahmadzadeh, Elliman & Higgins 2005; Hristova et al.

29
2003). These taxonomies also fail to provide lower level categories for the defect
types they identified (Chillarege, Kao & Condit 1991). For example, the ODC
model reported by Chillarege, Kao & Condit (1991) provides only eight high level
groups without any information of their sub-groups. In this dissertation, we will
create, modify and evaluate a defect taxonomy covering high as well as low level
categories to increase scientific knowledge of novice programmers.
Only one data source may be a weakness for defect analysis. Some previous
results have suffered from limited samples collected from only one semester-size
cohort (Mantyla & Lassenius 2009). Results may fluctuate by analyzing data from
limited sample and can be improved by enlarging the size of cohorts (Coull et al.
2003). In this study, data will be collected from a series of laboratory exercises
over several semesters.
It is difficult to accurately match error types addressed from measurement
process with existing defect taxonomies. There might be more than one category
of defect taxonomy matching the defect addressed. To avoid this drawback, it is
ruled that if the defect content match many types, only one type with the higher
level is selected. In NDT, higher level is set to defect type in lower depth and in
the same depth, a defect type with lower taxonomy code has higher level.

30
Chapter 3
Data Collection for the Defect Taxonomy
A Novice Defect Taxonomy (NDT) has been developed by collecting data from a large
number of programming assignments completed by four cohorts. Section 3.1 describes
the cohort selected for measuring defects and summarizes the assignments completed by
these cohorts. Section 3.2 discusses the data collection process. The software attributes
for measuring and the measurement approaches taken are presented in Section 3.3.
Section 3.4 summarizes measurement instruments used in this study. For each
instrument, the following issues are discussed: how the tool works, whether it works as
expected, whether the tool is suitable for laboratory aid and how it contributes to this
experiment. A comparison of static tool detection range is summarized in Section 3.5
followed by a comparison of using static tools into practice in Section 3.6. Lastly,
limitations of the experiments are discussed in Section 3.7.
3.1 Subject and Exercise Choice
This dissertation uses NDT as a tool to evaluate students‟ Java assignments. Firstly,
Section 3.1 outlines some factors of subject and exercise selection addressed.
3.1.1 Subject Choice
Data is collected from students enrolled in the unit Java Programming (JP) and in the
unit Software Engineering (SE) at the University of Western Australia. Both courses
31
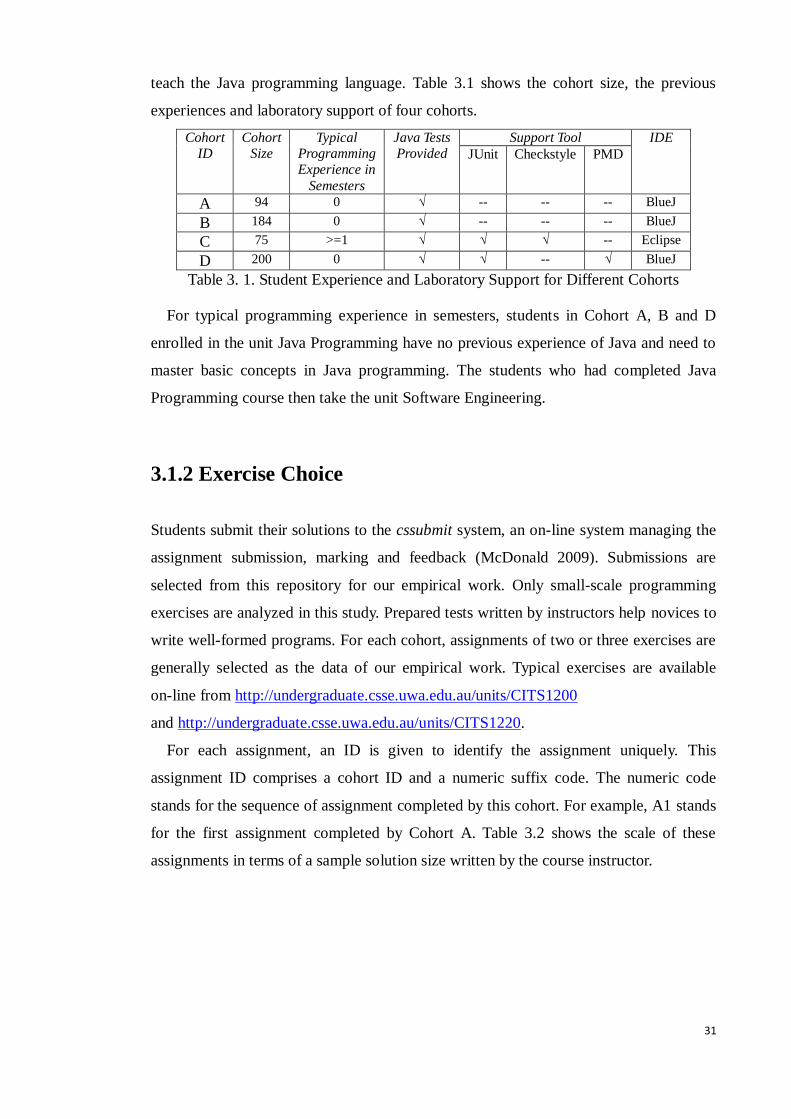
teach the Java programming language. Table 3.1 shows the cohort size, the previous
experiences and laboratory support of four cohorts.
Cohort ID
Cohort Size
Typical Programming Experience in
Semesters
Java Tests Provided
Support Tool IDE JUnit Checkstyle PMD
A 94 0 √ -- -- -- BlueJ
B 184 0 √ -- -- -- BlueJ
C 75 >=1 √ √ √ -- Eclipse
D 200 0 √ √ -- √ BlueJ
Table 3. 1. Student Experience and Laboratory Support for Different Cohorts
For typical programming experience in semesters, students in Cohort A, B and D
enrolled in the unit Java Programming have no previous experience of Java and need to
master basic concepts in Java programming. The students who had completed Java
Programming course then take the unit Software Engineering.
3.1.2 Exercise Choice
Students submit their solutions to the cssubmit system, an on-line system managing the
assignment submission, marking and feedback (McDonald 2009). Submissions are
selected from this repository for our empirical work. Only small-scale programming
exercises are analyzed in this study. Prepared tests written by instructors help novices to
write well-formed programs. For each cohort, assignments of two or three exercises are
generally selected as the data of our empirical work. Typical exercises are available
on-line from http://undergraduate.csse.uwa.edu.au/units/CITS1200
and http://undergraduate.csse.uwa.edu.au/units/CITS1220.
For each assignment, an ID is given to identify the assignment uniquely. This
assignment ID comprises a cohort ID and a numeric suffix code. The numeric code
stands for the sequence of assignment completed by this cohort. For example, A1 stands
for the first assignment completed by Cohort A. Table 3.2 shows the scale of these
assignments in terms of a sample solution size written by the course instructor.

32
Assignment
ID
Student
Cohort
Sample Solution Properties
Attributes Methods Non Commented
Lines Of Code Public Private
A1 A 7 0 10 48
B1 B
7 0 10 51
B2 2 0 8 31
B3 13 4 8 98
C1 C
4 0 9 46
C2 0 0 5 27
C3 1 0 9 29
D1 D 6 0 11 49
D2 4 0 9 66
Table 3. 2. Sizes of Java Assignments
In their assignments students practice using language constructs such as conditional
statements and for loops. Labs A1, B1, C1 and D1 require students to complete methods
involving if statements but no loops. In C2, students are required to generate six
methods for a simple calculator. In some advanced labs, the array and arraylist are
required. B2 and D2 tests students‟ abilities to manage strings and array structures. In
B3, students use two-dimension arrays. C3 evaluates students‟ performance of using the
Java library class arraylist.
Complexity
Level
Assignment
ID
Language Constructs Used
Exp. if…else for array arraylist exception
Level 1 (Low)
A1 √ √ -- -- -- -- B1 √ √ -- -- -- -- D1 √ √ -- -- -- -- C1 √ √ -- -- -- --
Level2 (Intermediate)
B2 √ √ √ √ -- -- D2 √ √ √ √ -- -- C2 √ √ √ √ -- --
Level 3 (High)
B3 √ √ √ √ -- √ C3 √ √ √ -- √ --
Table 3. 3. Java Language Constructs used in Assignments
Table 3.3 summarizes the language constructs used in assignments. The nine assessed
labs are classified into three levels of complexity. The complexity levels of assignments
are determined on the basis of constructs involved as well as the length of assignment
methods. In Table 3.3, Level 1 labs (low complexity level) use only expression and
conditional control statement. Previous studies argue that using structures such as arrays
and loops really challenge students in an introductory programming course (Robins,
Rountree & Rountree, 2003). Labs using structures such as array and loop are catered
into Level 2 labs. Category 3 labs requires students to use arraylist(C3) and exception

33
handling (B3).
Complexity
Level
Assignment
ID
Number of Subject
Number of Submission
Number of Compiled
Submissions
Level 1 (Low)
A1 94 93 85
B1 184 181 172
D1 200 196 193
C1 75 70 61 Level 2
(Intermediate) B2 184 143 132
D2 200 128 109
C2 75 71 59 Level 3 (High)
B3 184 155 133
C3 75 55 44
Table 3. 4. Cohort Size and Submissions for Each Assignment
Table 3.4 shows the number of subjects, the number of submitted assignments and the
number of submissions that compiled successfully of each lab assessed in this study.
The majority of subjects are able to upload their submissions on time and able to
complete labs of low complexity level. More than 87% submissions could be compiled
in Level 1. A high proportion (23% in B2 and 36% in D2) of students fails to submit
their written programs in Level 2 labs. Compared with Level 2, a larger proportion of
cohort B submits their programs in Level 3. At Level 3, 29 and 20 students accounting
for 15.8% and 26.7% respectively fail to submit programs. The rate of missing
submission conforms to the observation of Robins (2010) that in a typical programming
course the rate of assignment submission falls during the semester.
3.2 Data Collection Mechanism
Programming assignments develop students‟ abilities to write well-formed programs.
Completion of a laboratory assignment is a complicated process as many activities are
involved. Figure 3.1 outlines the process a student may go through to complete an
assignment.

34
Figure 3.1. Recommended Process for Completing a Programming Assignment
In Figure 3.1, students start by reading and understanding assignment requirements
published on the unit webpage. Subsequently, they make preliminary plans, complete
coding and compile their programs. If there are no syntax errors, testing programs are
available from the webpage to capture functional faults. Unit testing tools (JUnit test
suites) and style checking tools (Checkstyle and PMD) are given to Cohort C and D.
However, Cohort A and B do not have test cases and style tools but only debugging
tools (BlueJ). For Cohort C and D, students use support tools to run their programs
against the testing programs. Afterwards, error messages generated by support tools
show students detailed information on the faults in their programs. Students are
encouraged to resubmit assignments if they wish. Subsequently, students are provided
with feedback generated from instructors‟ testing of their submissions. The feedback
generated provides students with some suggestions on how to correct their defects in
programs.
The process shown in Figure 3.1 is an ideal process that students are encouraged to
undertake but they may skip when they complete a task. Actually, students of the cohort
analyzed by this study are encouraged to plan their work before they do coding and to
do self-testing before they submit their programs. Students are advised to perform the
pre-testing by themselves because both the quality of code style and the correctness of
code functionality will be scored by instructors subsequently. I think the phase “making
program plan” may be overlooked but “Code Testing with JUnit/CS or PMD” may be
Understand
Requirements
Make Program
Plan
Download Java
Convention Rule
and Test Case Files
Code
Generation
Program
Compilation
Code Testing with
JUnit
Code Testing with
CS or PMD
Completed
Assignment
Programming
Task Start
Assignment
Submit
Compilation
Passed?
All Tests Passed?
No, compilation feedback generated by compiler.
Yes
Yes
No, feedback generated by automatic tools.

35
implemented by most students because they want to get higher scores.
3.3 Defect Measurement
The dissertation aims to reveal what areas prevented students from achieving high
quality code. In this section, we first introduce defect attributes in Section 3.3.1. The
counting approaches taken for measuring attributes are discussed in Section 3.3.2.
Section 3.3.3 summarizes the defect measurement framework. Detection for each
attribute is described from Section 3.3.4 to Section 3.3.7.
3.3.1 Software Attributes for Measuring
Assessing different program aspects helps to determine what aspects challenge students
the most when they program. Before we perform a defect measurement on students‟
assignments, it is necessary to define a software attribute, quality assessment and
instrument used for defect measurement.
Definition: A software attribute is a property of a program that can be evaluated.
Several software attributes are considered in our study. Each attribute is measured and
feedback is generated as follows:
Validate language syntax and provide a feedback on program compilation errors;
Validate code completeness and generate a report on code compilation;
Validate functional correctness and provide a suggestion for repairing functional
defects;
Validate coding standards and generate a report on style violations.

36
Figure 3. 2. A Summary of Measurement Validation Concepts
Definition: Quality assessment quantifies the extent of software attributes conformed to
software requirements.
Definition: Measurement instruments are devices used to measure software attributes.
This study introduces a defect measurement framework. Both static and dynamic
analysis are used to analyze students‟ programs.
Definition: Static Analysis is an “evaluation that can be carried out by collecting
information from program code without executing it.” “Static analysis may reveal
functionality issues that have been left unnoticed by the limited test cases” (Ala-Mutka
2005).
Definition: Dynamic Analysis “is carried out against several test data sets, and each of
them is evaluated individually, starting from the initial state and completing all the
processing before the assessment of the output or the return value” (Ala-Mutka 2005).
3.3.2 Defect Counting Approaches
Data collected from the defect measurement framework is used to create a new defect
taxonomy. Basili & Perricone (1984) quantified errors in a software project from both
textual and conceptual view depending on the different purposes of the error analysis. In
Attributes
Quality Assessment
Measurement Instruments
Syntax
Functionality
Style
Compilation
Dynamic Analysis
& Code Inspection
Static Analysis
& Code Inspection
Java compiler
JUnit
Checkstyle
PMD Code Inspection
Completeness

37
the context of textual count, defects resulted from the same problem are counted
repeatedly as many times as their occurrences. The second measure counts the
conceptual effect of a defect across the source code. The conceptual approach counts the
problem only once although it occurs many times. Many textual counts may yield only
one defect from the conceptual signature measure. In this analysis, both conceptual
signature count and textual signature count are used to measure students‟ defects in
submissions. Both textual signature count and conceptual signature count are defined as
follow as:
Definition: Textual Signature Count is the sum of defects detected in all Java class
source code completed by a subject cohort. The cohort can be one cohort from cohort A,
B, C and D or it can be several cohorts from the cohort set.
Definition: Conceptual Signature Count is the number of subjects who made at least
one error in Java class source code completed by a subject cohort. The cohort can be
one cohort from cohort A, B, C and D or it can be several cohorts from the cohort set.
3.3.3 Defect Detection Framework
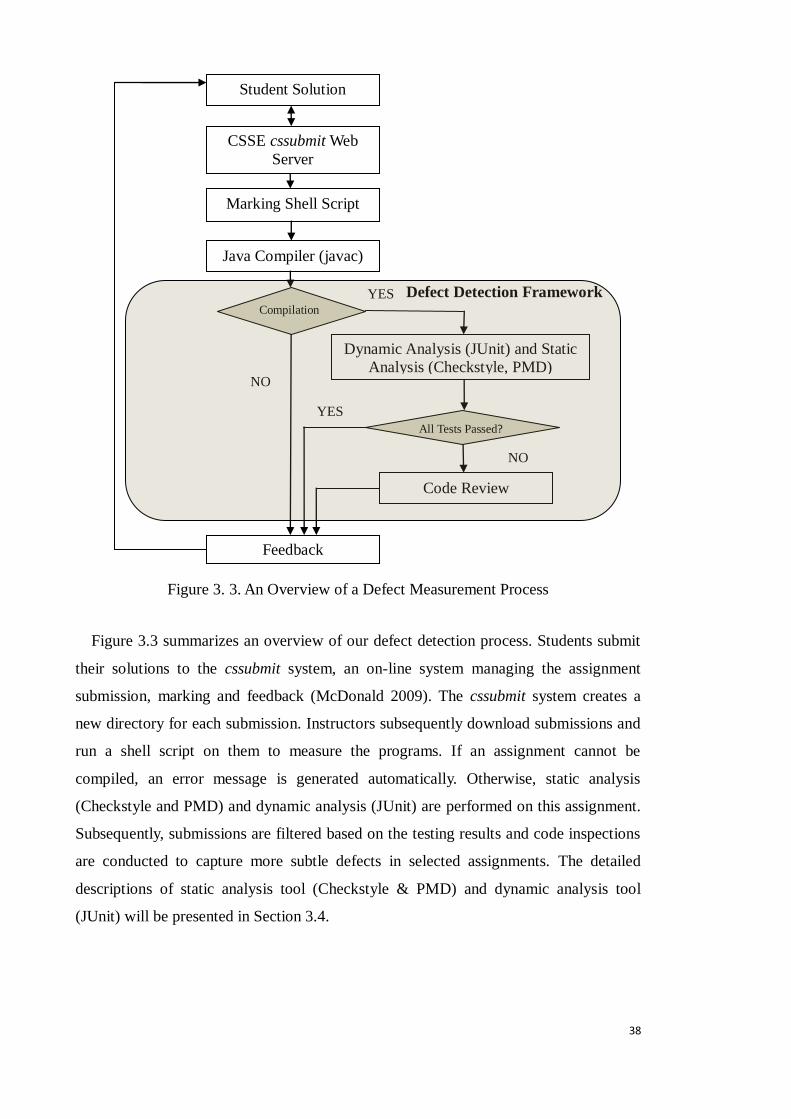
A defect measurement framework (see Figure 3.3) is proposed to analyze students‟
programs. A shell script is used to evaluate a submission automatically. The report
generated covers defects detected related to code completeness, compilation,
functionality and evolvability. The detection framework adopts both dynamic and static
assessment to evaluate students‟ programs.
Definition: Compiler Error Detection addresses incorrect compile behaviors when
compiler translates the source code into computer language (Hristova et al. 2003).
Definition: Evolvability Fault Detection addresses defects “that affect future
development efforts instead of runtime behavior” (Mantyla & Lassenius 2009).
Definition: Functional Fault Detection addresses defects by providing input and
examining output to validate the correctness of internal program structure.
38
Figure 3. 3. An Overview of a Defect Measurement Process
Figure 3.3 summarizes an overview of our defect detection process. Students submit
their solutions to the cssubmit system, an on-line system managing the assignment
submission, marking and feedback (McDonald 2009). The cssubmit system creates a
new directory for each submission. Instructors subsequently download submissions and
run a shell script on them to measure the programs. If an assignment cannot be
compiled, an error message is generated automatically. Otherwise, static analysis
(Checkstyle and PMD) and dynamic analysis (JUnit) are performed on this assignment.
Subsequently, submissions are filtered based on the testing results and code inspections
are conducted to capture more subtle defects in selected assignments. The detailed
descriptions of static analysis tool (Checkstyle & PMD) and dynamic analysis tool
(JUnit) will be presented in Section 3.4.
Feedback
All Tests Passed?
Code Review
Dynamic Analysis (JUnit) and Static
Analysis (Checkstyle, PMD)
Compilation
CSSE cssubmit Web
Server
Marking Shell Script
Student Solution
Java Compiler (javac)
YES
NO
NO
YES Defect Detection Framework

39
3.3.4 Compilation Detection
The Java compiler is distributed as a part of the Sun JDK package. The compiler reads
the source code and compiles it into a byte code file. The Java compiler stores the byte
code in a class file named classname.class. The detection checks for the correctness of
the compiler. In this study, a missing submission will be classified as NO SUBMISSION
and a file in incorrect format will be classified as UNRECOGNIZED FILE. The Java
compiler also detects syntactic errors (e.g. methods with wrong signatures) when the
submitted Java class fails to match the expected signature.
3.3.5 Evolvability Fault Detection
Evolvability detection measures whether novice code meets formal coding standards. A
high quality of style attributes improves the readability and maintainability of programs.
Static Tool Rule Set Rule
Checkstyle
Naming
Convention
ConstantName, LocalVariableName,
MemberName, MethodName, ParameterName,
StaticVariableName, TypeName
Coding
AvoidInlineConditionals, InnerAssignment,
MagicNumber, MissingSwitchDefault,
EmptyBlock, EmptyStatement
Comments JavadocMethod, JavadocType, JavadocVariable
Complexity BooleanExpressionComplexity,
CyclomaticComplexity, NPathComplexity
Size
Violation
MethodLength, ParameterNumber,
FileLength
PMD Dead Code UnusedPrivateField, UnusedLocalVariable,
UnusedPrivateMethod, UnusedFormalParameter
Table 3. 5. Metrics for Evolvability Fault Detection
PMD (PMD 2002) and Checkstyle (Checkstyle 2001) are two customizable tools.
Both of them are offered as Eclipse and BlueJ plug-ins to help developers meet coding
standards. Checkstyle provides rules to detect style faults. In this study, 26 Checkstyle
rules are selected and customized into five groups. These rules cover the detections of
naming conventions, Javadoc comments, common coding problems, size violations and

40
over-complex code. PMD is additionally used to detect “dead code”: code that is never
used in the other parts of a program. The rules selected from Checkstyle and PMD are
listed in Table 3.5. The rules picked up are a part of rule set for each tool. These rules
are selected to assess the correctness of code properties that are most relevant to the
code written by students. For example, the rule AbstractClassName from the Naming
Convention rule set hasn‟t been selected because students haven‟t developed any
abstract classes in their programs yet while the rule MethodName has been selected to
assess whether in student submissions the method names meet the naming standards.
For illustration, a feedback from detection on the code complexity
(BooleanExpressionComplexity, CyclomaticComplexity, NPathComplexity) is shown in
the following:
TextAnalyser. Java:32:36: warning: Expression can be simplified.
TextAnalyser. Java:121:5: warning: Cyclomatic Complexity is 12 (max allowed is 11).
TextAnalyser. Java:180:5: warning: Cyclomatic Complexity is 54 (max allowed is 11).
TextAnalyser. Java:180:5: warning: NPath Complexity is 67,108,865 (max allowed is 100).
TextAnalyser. Java:293:5: warning: Cyclomatic Complexity is 54 (max allowed is 11).
TextAnalyser. Java:293:5: warning: NPath Complexity is 67,108,865 (max allowed is 100).
TextAnalyser. Java:407:5: warning: Cyclomatic Complexity is 27 (max allowed is 11).
3.3.6 Functional Correctness Detection
According to Kaner (2003), the quality of software “is multi-dimensional” and “the
nature of quality depends on the nature of the product.” One important quality criterion
is functional correctness that has been used in many previous quality validations
(Ahmadzadeh, Elliman & Higgins 2005). Functional defects lead to a program‟s
unexpected behavior at execution time. Code functionality can be measured by
executing a set of test cases on a program (Ala-Mutka 2005). These test cases help users
to understand how the program works, to assure the quality of program and to expose
defects within the program (Allwood 1990). Sub-classes of FUNCTIONAL DEFECT in
NDT are derived from the dynamic analysis of student assignments.
How to Write Test Cases
Our goal is to perform dynamic testing on assignments to trigger failures that expose

41
defects. Test cases dynamically assess small testable portions of a program. Testable
portions are usually individual methods in the program. JUnit is a leading unit testing
tool used to execute functional tests on students‟ assignments. It provides users with a
platform to generate test cases and run them repeatedly. Results from dynamic testing
can verify the software‟s correctness under a given testing strategy but they cannot
verify that the software might not fail under other testing conditions (Kaner 2003).
Furthermore, there is “no simple formula for generating „good‟ test cases” to expose
more bugs (Kaner 2003). For illustration, Figure 3.4 shows instructions of one method
frequencyOf() selected from the class TextAnalyser. The lab sheet is available from
http://undergraduate.csse.uwa.edu.au/units/CITS1200 (Java Programming (CITS1200)
n.d.).
This lab contains some work that will be assessed. In order to get the mark, you must
submit the file TextAnalyser.java. Do NOT submit any other files (for example
TextAnalyser.class, lab06.zip or anything else). The specifications of the TextAnalyser are
as follows:
Instance Variables
In this exercise you decide on the instance variables you will need, rather than being given
them. Re-read lecture 13 and its summary sheet. Then try doing a text analysis by hand.
The things you need to write down and remember to do this task are the instance variables
you will need in the TextAnlyser class.
Constructor
The TextAnalyser has a single constructor that sets up the anlayser to start receiving and
analyzing text strings. corpusID is a string that captures the types of text you will be
analyzing. For example, “ShakespearsWorks” or “abrahamLincolnSpeeches” or
“SMSmessages”. Note that I am specifying the spelling of the works “TextAnlyses” and
you are not permitted to substitute “analyze” or “Analyzer”.
public TextAnalyser (String corpusID)
Now uncomment the first test in TextAnalyserTest and run it to check your constructor.
Methods Objects of the class TextAnalyser must have the following public methods; you
should use private helper methods as needed to make your code clearer, shorter and more
readable. Uncomment the results for each method as you work.
public int frequencyOf (char c)
returns the raw frequency of the character c in the text analysed since the last clearance. It
should return the same value if the user specifies the character in either upper or lower
case.
Figure 3. 4. The TextAnalyser Assignment
Test suites for student assignments generally start with a set of basic cases of normal
inputs for each method. Additionally, a good test suite hits every boundary case,
including maximum and minimum values of inputs. Extreme representatives are used to
maximize the coverage of tests. Examples of JUnit test cases for testing this method are
shown in Figure 3.5. The class TextAnalyser calculates and reports the frequencies of

42
characters in a given text. This assignment aims to test students‟ abilities in performing
calculations on elements stored in an array. Method frequencyOf() analyzes the input
text and returns the frequency for each letter in the given string. Test cases are explained
by breaking down the testing program.
The class TextAnalyserTest is a subclass of the test case by TextAnalyserTest extends
TestCase;
The setUp() method sets up a test fixture by creating objects for interaction and
storing them as instance variables in the testing class. Similarly, the method
tearDown() cleans up the test fixture after executing test cases;
Within each test case, an assert statement is used to validate the result of code
execution. Many types of assert statements are available such as the assertEquals,
assertTrue and assertFalse. Assert statements trigger failures if the expected results
from code execution is not equal to actual values;
According to the test case design principle above, test case testFrequencyNormal()
validates a program with a normal input. The case testFrequencyInitial() validates
the initial value array stored since the last clearance. For extreme cases,
testFrequencyNonAlpha() specifies letters‟ frequencies with no alpha input and
testFrequencyEquals() returns all characters occurred most frequently when more
than one letter are counted the highest occurrences.

43
import junit.framework.*; / * @version March 2010
*/ public class TextAnalyserTest extends TestCase { TextAnalyser ta; //sample strings for testing analyser functions String sample = "Freshmen enrolled in software engineering take an introductory programming course. Helping novices to learn to program is a difficult task as they are lacking programming knowledge and skills for problem solving. The study at hand aims to develop defect taxonomy for hierarchically organizing novice defects to provide a perfect view of what errors novice programmers
are making. “; int[] vals = {102,14,31,58,165,27,28,80,68,0,3,42,13,77,93,16,1,79,44,126,22,24,28,0,10,0}; String nonalpha = " *** 42 !!"; String equalAB = "ABaabbAB"; public void setUp() throws Exception{ ta=new TextAnalyser("TestCorpus"); } public void tearDown() throws Exception{
ta=null; } @Test public void testFrequencyInitial() { for (char ch = 'a'; ch <= 'z'; ch++) { assertEquals(0,ta.frequencyOf(ch)); } @Test public void testFrequencyNormal() {
ta.addTexttoCorpus(sample); for (char ch = 'a'; ch <= 'z'; ch++) { assertEquals(vals[ch-'a'], ta.frequencyOf(ch)); } for (char ch = 'A'; ch <= 'Z'; ch++) { assertEquals(vals[ch-'A'], ta.frequencyOf(ch)); } }
@Test public void testFrequencyNonAlpha(){ ta.addTexttoCorpus(nonalpha); for (char ch = 'a'; ch <= 'z'; ch++) { assertEquals(0,ta.frequencyOf(ch)); } for (char ch = 'A'; ch <= 'Z'; ch++) { assertEquals(0,ta.frequencyOf(ch));
} } @Test public void testFrequencyEquals(){ ta.addTexttoCorpus(equalAB); assertTrue(ta.frequencyOf(„a‟)==ta.frequencyOf(„b‟)); }
}
Figure 3. 5. Test Cases for frequencyOf()
How Test Cases are Used to Expose Defects
Using dynamic test cases is an effective way to evaluate software quality because “it is
possible to tell whether the program passed or failed” (Kaner 2003). Dynamic testing
targets individual methods in a class. However, it may be difficult to test the methods
individually because the interaction of variables and methods is involved in many cases.
According to Kaner (2003), “if the program has many bugs, a complex test might fail so
quickly that you don‟t get to run much of it”. For example, if a class constructor

44
contains a defect then many test cases will fail too.
The results of executing test cases on code expose the defects in student submissions.
The code shown in Figure 3.6 contains 3 defects (annotated as d1, d2 and d3). Three
defects are highlighted in the following figure. Each defect in this segment is selected
from the source code written by students. We synthetically combine these segments
together for illustration purposes. In the following sections this code will be used to
illustrate how test cases are used to expose defects.
public class TextAnalyser { // instance variables - replace the example below with your own
private String CorpusID; private String corpus;
private int numChars; // Constructor for objects of class TextAnalyser public TextAnalyser(String corpusID) { CorpusID = corpusID; corpus = ""; numChars = 0;
} public void addTexttoCorpus(String text){
corpus = corpus + text; for (int i=0;i<text.length();i++){ corpus = corpus + text.charAt(i); if (Character.isLetter(text.charAt(i))){ numChars = numChars + 1; } }
public int frequencyOf(char c){
int letterFreq = 0; for (int i=0;i<corpus.length();i++){ if ((corpus.charAt(i)== c)||(Character.toLowerCase(corpus.charAt(i))==c)){ letterFreq= letterFreq+1; } } return letterFreq; }
public double percentageOf(char c){ int freq = frequencyOf(c);
double percentage; percentage = freq*100/(corpus.length());
return percentage; }
public char mostFrequent() { return 'a';
}
Figure 3. 6. An Example of Buggy Fragment of class TextAnalyser
The assessment of student programs using NDT has been reported many times to
ensure NDT contains as many defect types as possible from empirical findings. During
the repeated assessment process, test cases have been updated accordingly. New test
cases are added to the testing programs to capture defects identified from empirical
work. This assessment will be repeated until no new defect types are found during this
process. For methods frequencyOf(), percentageOf() and mostFrequent(), eleven test
cases are designed. For illustration, we first show the global variables of the testing
d1
d2
d3

45
class TextAnalyserTest then present the eleven test cases used to test the these three
methods.
import org.junit.Test;
import junit.framework.TestCase;
public class TextAnalyserTest extends TestCase {
TextAnalyser ta;
//sample strings for testing analyser functions
String sample = "This dissertation presents a new defect taxonomy for classifying defects discovered in students‟
programming assignments. Our study aims to organize defects in a systematic way and so provides a tool for evaluating the computer programs of individuals or a cohort. We divide the overall problems into five research questions. Answering these research questions shows how NDT can be used to detect faults in programs and to evaluate students‟ performance.";
double[]vals ={29.0,2.0,12.0,11.0,38.0,9.0,7.0,7.0,22.0,9.0,8.0,11.0,12.0,12.0,6.0,12.0,8.0,13.0,22.0,11.0,01.0,21.0,6.0,9.0,12.0,10.0};
double[] percentageArray={2.6,0.0,7.8,0.0,7.8,2.6,7.8,2.6,7.8,0.0,0.0,2.6,5.2,5.2,15.7,5.2,0.0,7.8,5.2,2.6,0.0,5.2,0.0,0.0,5.2,0.0};
String nonalpha= "36+,:…..?";
String equalsAB= "aaabbbaabb";
1. testFrequencyNormal() Test if method frequencyOf() returns the raw frequencies of
characters in a given text constructed by letters, punctuation, spaces and anything else.
The frequencies of both upper and lower case characters in the input string should be
counted;
@ Test
public void testFrequencyNormal(){
ta.addTexttoCorpus(sample);
for (char ch=‟a‟; ch<=‟z‟; ch++){
assertEquals(vals[ch-„a‟], ta.frequencyOf(ch));
}
for (char ch=‟A‟; ch<=‟Z‟; ch++){
assertEquals(vals[ch-„A‟], ta.frequencyOf(ch));
}
}
2. testFrequencyInitial() Test if the initial values of array stored equal to 0;
@ Test
public void testFrequencyInitial(){
for (char ch=‟a‟; ch<=‟z‟; ch++){
assertEquals(0, ta.frequencyOf(ch));
}
}
3. testFrequencyNonAlpha() Test if the values of characters‟ frequencies equal to 0
when analyzing an input text composed by spaces, punctuations and anything else
that is not a letter;
@ Test

46
public void testFrequencyNonAlpha(){
ta.addTexttoCorpus(nonalpha);
for (char ch=‟a‟; ch<=‟z‟; ch++){
assertEquals(0, ta.frequencyOf(ch));
}
for (char ch=‟A‟; ch<=‟Z‟; ch++){
assertEquals(0, ta.frequencyOf(ch));
}
}
4. testFrequencyEquals() Test if method frequencyOf() returns all letters occurring
most frequently;
@ Test
public void testFrequencyEquals(){
ta.addTexttoCorpus(equalAB);
assertTrue(ta.frequencyOf(„c‟)== ta.frequencyOf(„b‟));
}
5. testPercentageNormal()Test if method percentageOf() returns a percentage of the
analyzed text equals the character in a normal text composed by letters, spaces,
punctuations and anything else;
@ Test
public void testPercentageNormal(){
ta.addTexttoCorpus(shortSample);
for (char ch=‟a‟; ch<=‟z‟; ch++){
assertEquals(percentageArray[ch-„a‟], ta.percentageOf(ch), 0.1);
}
}
6. testPercentageInitial() Test if the initial percentages of characters analyzed equal to
0;
@ Test
public void testPercentageInitial(){
for (char ch=‟a‟; ch<=‟z‟; ch++){
assertEquals(0, ta.percentageOf(ch));
}
for (char ch=‟A‟; ch<=‟Z‟; ch++){
assertEquals(0, ta.percentageOf(ch));
}
}
7. testPercentageNonalpha() Test if the percentage of analyzed text equals to 0 when
analyzing a text composed of spaces, punctuations and anything else that is not a
letter;
@ Test

47
public void testPercentageNonalpha(){
ta.addTexttoCorpus(nonalpha);
for (char ch=‟a‟; ch<=‟z‟; ch++){
assertEquals(0.0, ta.percentageOf(ch));
}
for (char ch=‟A‟; ch<=‟Z‟; ch++){
assertEquals(0.0, ta.percentageOf(ch));
}
}
8. testMostFrequentNormal() Test if method mostFrequent() returns a lowercase of the
characters that occurred most frequently in a given text composed by letters, spaces,
punctuations and anything else;
@ Test
public void testMostFrequentNormal(){
ta.addTexttoCorpus(shortSample);
assertEquals(„o‟, ta.mostFrequent());
}
9. testMostFrequentInitial() Test if the initial character is set to „?‟ as specified for this
assignment;
@ Test
public void testMostFrequentInitial(){
assertEquals(„?‟, ta.mostFrequent());
}
10. testMostFrequentNonAlpha() Test if the method correctly returns the characters
occurring most frequently in an input text composed of spaces, punctuations and
anything else that is not a letter;
@ Test
public void testMostFrequentNonalpha(){
ta.addTexttoCorpus(nonalpha);
assertEquals(„?‟, ta.mostFrequent());
}
11. testMostFrequentEquals() Test if method mostFrequent() returns all letters
occurringed most frequently;
@ Test
public void testMostFrequentEquals(){
ta.addTexttoCorpus(equalsSample);
assertEquals(„c‟=, ta.mostFrequent() || „b‟=ta.mostFrequent()));
}
To illustrate how test cases are used to expose defects, the testing results from
different defect sets are presented in Table 3.6. Results from the test set execution

48
expect to expose the precise defects in D.
Defect Set Test Case Result
t1 t2 t3 t4 t5 t6 t7 t8 t9 t10 t11
d1 Ⅹ √ √ √ Ⅹ Ⅹ Ⅹ √ √ √ √
d2 Ⅹ √ √ √ Ⅹ Ⅹ √ Ⅹ Ⅹ Ⅹ Ⅹ
d3 Ⅹ √ √ √ Ⅹ Ⅹ Ⅹ Ⅹ Ⅹ Ⅹ Ⅹ
d1, d2 Ⅹ √ √ √ Ⅹ Ⅹ √ √ √ √ √
d1, d3 Ⅹ √ √ √ Ⅹ Ⅹ Ⅹ Ⅹ Ⅹ Ⅹ Ⅹ
d2, d3 Ⅹ √ √ √ Ⅹ Ⅹ √ Ⅹ Ⅹ Ⅹ Ⅹ
d1, d2, d3 Ⅹ √ √ √ Ⅹ Ⅹ √ Ⅹ Ⅹ Ⅹ Ⅹ
Table 3. 6. Test Case Failures and Relevant Defects in Program
From the table, it can be seen that the surface bugs identified by the test cases provide
insufficient information to identify the underlying misconceptions for these defects.
That is, none of the test failing sets can identify the defect. The presence of one defect
(d1) in D leads to several test failures (t1, t2, …., tx) and one set of test failure (t1, t2,..,
tx) may have resulted from different sets of defect occurrence. For example, when the
test failure set (t1, t5, t6, t8, t9, t10, t11) is detected, it is likely d2 occurred. But there is
no direct evidence to determine if d1 and d3 also exist in the same code segment. This
drawback can be overcome by performing a further inspection on the code by hand.
3.3.7 Code Inspection
Code inspection complements dynamic and static assessment. In a code inspection, test
failure reports generated by prior analysis help inspectors concentrate on explicit parts
that may contain faults. Inspectors then inspect the parts line by line to reveal the
precise defects in programs.
The code inspection process used in this study conforms to conventional inspection
steps, including an inspection preparation and a data collection stage (Mantyla &
Lassenius 2009). During the preparation, an instructor‟s solution is offered to inspectors.
Meanwhile, a checklist and an inspection form are available for inspectors to locate
faults in a program. In this study, the inspection checklist focuses on faults in a software
product rather than faults in the programming process. Prior to filling in the checklist
form, an inspection form is used to direct the inspectors to specify defect contents.
Three inspection forms are available checked for code properties covering functional
property, syntactic property and style property. These forms guide inspectors to fill in
the checklist count for functional, syntactic and style defects found in a program. In this

49
section, we take the Functional Property Inspection Form and Functional Defect Count
Checklist for illustration to indicate how to address functional defects through the
inspection process. Table 3.7 shows the Functional Property Inspection Form used in
code inspection. Ten questions listed in left column of Table 3.7 help inspectors address
functional faults in an assignment. Each question is mapped to at least one defect type
in NDT. Next to the inspection question are two columns used to indicate defect types
included or excluded by an assignment. The columns, Conceptual Count and Textual
Count, are used to specify conceptual and textual counts for code functional properties.
Functional Property Inspection Form
Student ID:
Lab Exercise:
Inspection Date:
ID Inspection Question Include Exclude Conceptual
Count
Textual
Count
1 Variables are declared improperly. 2 Not all related variables are
declared.
3 Variables haven‟t been initialized
before they are used.
4 Variables are initialized
incorrectly.
5 Array index are out-of-bound. 6 The input ranges of variables
haven‟t been checked before they
are updated.
7 Expression and functions have
been checked incorrectly before
they are used.
8 Some improper conditions are in
loop.
9 Variables within loops aren‟t
update in time.
10 There are some functionality
missing or unresolved issues.
Table 3. 7. Functional Property Inspection Form
During the code inspection process, the question list in Table 3.7 was reviewed
several times to determine whether the form keeps appropriate records on all defect
information. The Functional Property Inspection Form guides completion of the
Functional Defect Count Checklist. This checklist has 9 items covering 4 areas to keep
detailed records on functional defects. In this checklist, four columns next to the Defect
Type column help to record defect counts of functional faults. Defect types shown as
bold section headings are sub-classes of defect types shown as bold and underlined
section headings. For example, FUNCTIONAL DEFECT is a main defect category. The

50
sub-classes within are PLAN, INITIALIZAITION, CHECK and COMPUTATION.
Sub-sub classes FUNCTION MISSING and LOGIC are grouped under PLAN. A defect
count is filled in based on the record of the Functional Properties Inspection Form.
Table 3.8 below shows the full details of Functional Defect Count Checklist. Different
inspectors are allowed to classify the same defect into different categories in this study.
When classifying a defect, inspectors make selections based on their programming
knowledge and previous experience. For example, an inspector may place a defect into
the type of “ASSIGNMENT MALFORMED” or the type of “LOGIC”. Some inspectors
may be sure of one category fit the defect detected, but some may feel a bit confused
because they believe more than one category fits this. Thus, although we try to
minimize this for the accuracy of the NDT, different counting may still occur.
Functional Defect Count Checklist
Student ID:
Lab Exercise:
Inspection Date: Defect Type Included Excluded Conceptual
Count
Textual
Count
FUNCTIONAL DEFECT
PLAN
FUNCTION MISSING LOGIC INITIALIZATION
ASSIGNMENT MISSING ASSIGNMENT MALFORMED
CHECK
VARIABLE EXPRESSION FUNCTION
COMPUTATION
MISSING UPDATE MALFOEMD UPDATE
Table 3. 8. Functional Defect Count Checklist
In the inspection process, an inspector concentrates on the parts based on previous
automatic feedback. For example, since there is no direct evidence to determine if d1
and d3 exist in the program tested in Table 3.6, the inspector will pay more attention on
the correctness of class constructor and method completeness to identify whether there
are any d1s or d3s. Inspectors note all the issues found during the inspection process
and fill in the checklist form. Finally, the inspector‟s records are integrated with the
automatic feedback to reveal what precise faults exist in programs.

51
3.4 Measurement Instruments
There are many tools available for static and dynamic analysis of Java code. In this
section we discuss the measurement tools selected for measuring defects in student code.
JUnit is used to dynamically assess student submissions and Checkstyle and PMD
statically assess the code style. Other tools such as Findbugs (Findbugs, n.d.) can
analyse Java programs but these tools are for professional use and have too much
learning load for students. Thus, these tools are excluded by this research. For each tool
used, we use the following criteria for evaluation:
Why select this tool or why not?
Does it work as expected?
Is it useful for the development of defect taxonomy?
How does the tool work?
3.4.1 Integrated Development Environments
BlueJ (Kolling 1999) is an interactive environment designed for teaching the Java
programming language. BlueJ supports a simple interface for students to interact with
objects in the development stage. For the students who have completed an introductory
programming course, Eclipse (Eclipse n.d.) is configured and offered in laboratories.
Plug-ins for Eclipse and BlueJ are available to support additional validation of code
style, functionality, code efficiency and program metrics in the code.
3.4.2 JUnit
XUnit are frameworks based on a design by Kent Beck, which allows testing of
different elements of functions and classes. JUnit (JUnit4, n.d.) is a testing framework
evolved from XUnit created by Erich Gamma for the Java Programming Language. It is
an open source testing framework, used to prepare and run repeatable tests. JUnit is a
leading testing tool used to launch functional tests both for teaching and in industry.
Additionally, it can be used as a plug-in for integrated development environments to run
the test cases automatically, and provides a report on the successes or failures of
executing test cases.

52
3.4.3 Checkstyle
Checkstyle (Checkstyle 2001) is a static analysis tool. It scans the abstract syntax tree of
source code and checks whether the code adheres to coding standards defined by rules.
Checkstyle can be plugged in to many IDEs including Eclipse and BlueJ. It automates
the static validation process on Java code. This tool is highly configurable and supports
the checks for various coding standards as well as rules generated by unit instructors.
Most check rules are configurable. In this study, the configurable check rules are
taken from Checkstyle 5.4 release (Checkstyle 2001). A wide range of rule sets check
for 15 standard rule sets. These rule sets are grouped to specify rules to discover 15
style aspects, namely: Annotations; Block Checks; Class Design; Coding; Duplicate
Code; Headers; Imports; Javadoc Comments; Metric; Miscellaneous; Modifiers;
Naming; Conventions; Regular Expressions (Regexp); Size Violations and Whitespace
(Checkstyle 2001). Among all checks available from SunCodeConventions, the style
validations of coding, duplicate code, Javadoc comments, naming conventions,
complexity and size violation are most relevant to this research. These rule sets are
selected and executed on student assignments to ensure students‟ code conforms to the
conventional standards of basic format, comments, method and file length, code
complexity and magic number.
3.4.4 PMD
PMD (2002) is a tool that statically analyzes source code. It is integrated with various
Java IDEs. It includes 25 built-in rule sets and supports the ability to write customizable
rules. PMD 5.0 version (2002) contains these rule sets to discover style errors: Index;
Android; Basic; Braces; Code Size; Clone; Controversial; Coupling; Design; Finalizers;
Import Statement; J2EE; Javabeans; JUnit Tests; Logging; Java; Logging; Jakarta;
Migrating; Naming; Optimizations; Strict Exceptions; Strings; Sun Security; Unused
Code; Java Server Pages and Java Server Faces (PMD 2002). Typically, PMD errors
are not functional bugs, but are associated with style problems. For example, code may
still pass functional testing when they fail the PMD detections. The problems which
PMD is looking for include potential bugs, unused code, selective code, complex
expressions and duplication. The potential bugs contain empty blocks such as try, catch
statements and the unused code fields. Complex expressions refer to unnecessary

53
statements in if, for or while loops. Code duplication detects copy-and-paste code in the
program.
PMD allows users to configure PMD rule sets flexibly. Defects in submissions are
identified by the basic and unused code rule sets, which mainly discover empty code
blocks, initialize or unnecessary conversions and unused private fields, methods and
local variables.
3.5 Comparison of Static Analysis Tools
Figure 3.7. Detect Coverage of Static Analysis Tools
Figure 3.7 shows the detection range of two static analysis tools and the overlap
between these tools. Checkstyle and PMD are configured to detect violations in coding
convention and code layout. The overlap between two analysis tools shares 7 areas
including basic style detection, naming, duplication, complexity, code size, unused code
and import. Defects in novice code mainly cover the overlap of two analysis tools the
some Checkstyle rules (e.g comments rule). The shadow in Figure 3.7 depicts the static
detection coverage of this study.
PMD
JUnit, J2EE, Sun Security
Checkstyle Annotation,,Comments, Indentation
Basic, Naming, Duplication, Complexity, Code Size, Unused Code Import
Novice

54
3.6 Static Analysis Tools in Practice
In this section, these three static tools are used to assess one code segment. Results
explicitly illustrate the different problems revealed by different tools. The exercise
CustomerList requires students to complete a class by using Java collection class
ArrayList. The domain objects, constructor and methods are presented in the following
figure (see Figure 3.8).
01 public class CustomerList { 02 private ArrayList<String> customerslist; 03 public CustomersList() {
04 customerslist = new ArrayList<String>(); 05 } 06 public String getCustomerByIndex(int pos) { 07 return customerslist.get(pos); 08 } 09 public String longestNameCustomer() { 10 if (customerslist.size() == 0) { 11 return "";
12 } 13 int x = customerslist.get(0).length(); 14 int y = 0; 15 int n = 0; 16 for (int i = 1; i < customerslist.size(); i++) { 17 y = customerslist.get(i).length(); 18 if (y > x) { 19 n = i;
20 x = y; 21 } 22 } 23 return customerslist.get(n); 24 } 25 public String listAllCustomers() { 26 String x = ""; 27 String y; 28 for (int i = 0; i < customerslist.size(); i++) {
29 y = customerslist.get(i) + "\n"; 30 x = x + y; 31 } 32 return x; 33 } 34 }
Figure 3. 8. A Solution of Class CustomersList
Each static tool captures different violations within the code segment. The violations
detected by Checkstyle are:
Line 04: Missing a Javadoc comment (Detected by Rule Set: Comments, see Table
3.5);
Line 06: Parameter pos should be final (Detected by Rule Set: Coding, see Table 3.5);
Line 25: Method „listAllCustomers‟ is not designed for extension, needs to be
abstract, final or empty (Detected by Rule Set: Coding, see Table 3.5).
When PMD is run against the code segment, the violation reports are shown in the
following:

55
Line 02: It is somewhat confusing to have a field name matching the declaring class
name (Detected by Rule Set: Naming Convention, see Table 3.5);
Line 06: Parameter „pos‟ is not assigned and could be declared final (Detected by
Rule Set: Coding, see Table 3.5):
Line 11: A method should have only one exit point, and that should be the last
statement in the method (Detected by Rule Set: Coding, see Table 3.5);
Line 30: Prefer StringBuffer over += for concatenating strings (line 30) (Detected by
Rule Set: Coding, see Table 3.5).
The second violation „parameter is not assigned and could be declared final‟ is also
detected by Checkstyle. In addition, the first violation addressed by PMD indicates that
PMD focuses on coding convention and spends more effort on coding style
improvement. The third issue warns users limit to the return statements in a method.
This finding conforms to the report generated by PMD. The findings suggest that
Checkstyle focuses on pure coding standard issues such as convention, spacing and
indentation. PMD detects non-conformance in coding convention. It additionally detects
violations prevented the programs from effectively being executed.
3.7 Measurement Risks
Measurement risks in this study are from three possibilities: bias of data source
selection; researchers‟ bias caused by personal assumptions and the same data set used
for training and testing.
Data from many sources may be not comparable because the data source is
heterogeneous. Therefore, selection bias may influence the empirical outcome. The
selection bias may refer to the data collected from different levels of programmers (e.g.
beginners, advanced programmers or professional programmers). The data may also be
from the source of the final software product or the products from different stages in
programming. To overcome this weakness, the data from two sources can improve the
empirical data in this project that one source is collected from fundamental
programming course (CITS1200 Java Programming) and the other is from advance
course (CITS1220 Software Engineering) while some studies only have one data
source.
Prior experience may affect the threshold selection for code evolvability and

56
functionality detection and extend the effect to the fault classifying from the observation
session. It is possible that the defect count varies greatly when select the different
thresholds. We cannot overcome this point and can only try to minimize it. In this study,
it should be allowed different threshold choice by different researchers judged based on
their programming knowledge and experience. When classifying a defect, inspectors
make selections based on their programming knowledge and previous experience.
Generally in machine learning, two different sets are available for developing
classification system and for verifying the system respectively. The data set for training
is different from the set for system testing. Students in Cohort A were enrolled by the
unit of Java Programming and weren‟t given to automatic tools for self-assessment.
From the assessment of cohort A, this cohort‟s submissions had many defects. We used
the defect list to develop an initial NDT. Then, other cohorts (Cohort B, C & D) were
considered to refine the defect list and update the categories of NDT. Subsequently, we
performed the measurement process repeatedly to ensure NDT contains as many as
defect categories as possible to enlarge the data sample as well as the possibility of
addressing new defect categories from empirical work.

57
Chapter 4
Novice Defect Taxonomy Specification
This chapter specifies Novice Defect Taxonomy. Defect specifications contained
defect definitions, typical examples and detection approaches are described in
Section 4.2.
4.1 Novice Defect Taxonomy
Defect categories of Novice Defect Taxonomy (NDT) are identified from previous
studies, and from empirical static and dynamic analysis. The complete Novice
Defect Taxonomy is shown in Figure 4.1. To demonstrate the abstraction level of a
defect, a taxonomy code is assigned to each defect class in NDT. The taxonomy
code consists of an alpha prefix D and a numeric code. The numeric code
indicates the position of the defect classes within the NDT tree. For example,
sub-class INCOMPLETE CODE (D1.1) belongs to defect category CANNOT
COMPILE (D1). This sub-class is the first defect class in CANNOT COMPILE.

58
Figure 4. 1. Novice Defect Taxonomy
D1.1
INCOMPLETE
CODE
D1
CANNOT
COMPILE
D1.2
SYNTAX
ERROR
D1.1.1 NO SUBMISSION
D1.1.2 UNRECOGNIZED FILE
D1.1.3 INCOMPLETE METHOD
D1.2.1 TYPE MISMATCH
D1.2.2 MISMATCHED BRACE{} OR
PARENTHESIS()
D1.2.3 OTHER SYNTAX ERRORS
D2
COMPILED
D2.1.1
PLAN
D2.1
FUNCTIONAL
DEFECT
D2.1.2
INITIALIZATION
D2.1.3
CHECK
D2.1.4
COMPUTATION
D2.1.1.1 FUNCTION
MISSING
D2.1.1.2 LOGIC
D2.1.2.1 ASSIGNMENT
MISSING
D2.1.2.2 ASSIGNMENT
MALFORMED
D2.1.3.1 VARIABLE
D2.1.3.2 EXPRESSION
D2.1.3.3 FUNCTION
D2.1.4.1 MISSING
UPDATE
D2.1.4.2 MALFORMED
UPDATE
D2.2
EVOVLABILITY
DEFECT
D2.2.1 DOCUMENTATION
D2.2.2
STRUCTURE
D2.2.1.1 NAMING
D2.2.1.2 COMMENTS
D2.2.1.3 CODING
D2.2.2.1 SIZE
VIOLATION
D2.2.2.2 COMPIEX
CODE
D2.2.2.3 UNUSED
CODE

59
Figure 4. 2. Levels 1 and 2 of the Novice Defect Taxonomy
The NDT proposed by this study is a four-level taxonomy that presents a
hierarchical model for defects in assignments. One challenge of using NDT to
classify the defects is that the defect content identified may match more than one
defect class. In this study, we set up a counting rule to solve this that will be
discussed in Section 5.1.
4.2 Defect Specification
In this section, we specify each defect categories of NDT. The defect
specifications contain the following information:
a description of a defect; example code segment(s) containing the specific
defect; and information about how the defect is detected including the methods
and tools used to detect the defect.
Each code segment is taken from the solutions written by students. The
requirement of each lab are available on-line from Java Programming Course
(CITS1200) http://undergraduate.csse.uwa.edu.au/units/CITS1200 and the
Software Engineering Course (CITS1220)
http://undergraduate.csse.uwa.edu.au/units/CITS1220.
D1. CANNOT COMPILE
In NDT, the highest-level NOVICE DEFECT is divided into two classes:
NOVICE
DEFECT
D1 CANNOT COMPILE
D 1.1
INCOMPLETE CODE
D1.2
SYNTAX ERROR
D2 COMPILED
D 2.1
FUNCTIONAL DEFECT
D 2.2
EVOLVABILITY DEFECT

60
CANNOT COMPILE defect and COMPILED defect, depending on whether a
defect leads to compile failures or not. The CANNOT COMPILED class contains
defects that prevent a program from being successfully compiled. The
COMPILERD defects are usually associated with students lacking syntax
knowledge or resulting from their unintentional behaviors. Defect class
COMPILED is further classified into two sub-classes: INCOMPLETE CODE and
SYNTAX ERROR. The taxonomy of CANNOT COMPILE is presented in Figure
4.3. Both INCOMPLETE CODE and SYNTAX ERROR have their sub-classes.
Figure 4. 3. CANNOT COMPILE Class
D1.1 INCOMPLETE CODE
Class INCOMPLETE CODE is associated with expected file missing or
unrecognized file format found in reserved directories. Class INCOMPLETE
CODE is classified into three sub-classes, NO SUBMISSION, UNRECOGNIZED
FILE and INCOMPLETE METHOD.
D1.1.1 NO SUBMISSION
Description
No submitted file found in reserved directory of CSSE cssubmit system
(McDonald, 2009) is detected and classified into the class NO SUBMISSION.
Detection
Java compiler fails to find any submissions in the reserved directory. It generates
an error message “file is not found”.
D1.1.2 UNRECOGNIZED FILE
Description
D 1
CANNOT
COMPILE
D 1.1 INCOMPLETE
CODE
D 1.2
SYNTAX ERROR
D 1.1.1 NO SUBMISSION
D 1.1.2 UNRECODNIZED FILE
D 1.1.3 INCOMPLETE METHOD
D 1.2.1 TYPE MISMATCHED
D1.2.2 MISMATCHED BRACE {} OR
PARENTHESIS ()
D 1.2.3 OTHER SYNTAX ERRORS

61
Class UNRECOGNIZED FILE includes defects such as submitted file but with
unrecognizable format or incorrect names. For example, file
BankAccountXXXX.java or BankAccount.zip is classified into UNRECOGNIZED
FILE.
Detection
Java compiler fails to find the file with the expected name or format. The compiler
generates an error message “file is not found”.
D1.1.3 INCOMPLETE METHOD
Description
Incorrect method signature including methods missing, methods with a mistyped
name or incorrect parameter types are detected and then classified into the class
INCOMPLETE METHOD.
Sample Code
Method insert() fails the compiler because it should return a double array here but
there is no expected statement return there.
01 public class ArrayUtilities { 02 public double[] insert(double k, double[] a, int p) { 03 // TODO add code for this method here
04 } 05 }
Detection
Java compiler cannot compile the submission. An error message “cannot find
symbol” is generated when the code signature are incorrect.
D1.2 SYNTAX ERROR
Language syntax defines the correct use of symbols and tokens to construct
programs. In this study, a shell script is written to automatically assess the code
syntax. In the script once a program cannot pass Java compiler, an error message
“compilation failed” is generated automatically. This may mask remaining syntax
errors that need to be confirmed by performing an inspection.
D1.2.1 TYPE MISMATCHED
Description
Class TYPE MISMATCHED is associated with defects such as an expected return
value‟s data type is incompatible with the actual return type or the expected return

62
value is missing.
Sample Code
A value with the data type double should be returned by the method sum() but the
return statement is missing. The sample code contains several defects that may
affect the understanding of this code segment. Firstly, the parameter should be the
type double [] instead of a double. Second, the loop counter should be an int
rather than a double. Third, the condition to continue in for loop is incorrect. The
condition should be less than a.length. Then, sum can be a local variable but it
hasn‟t been declared. Lastly, the method sum() requires to return a double.
01 public class ArrayUtility { 02 public double sum(double a) { 03 for (double i=0;i>a; i++){ 04 sum += a; 05 } 06 } 07 }
Detection
The Java compiler may fail when it executes the statement “for (double i=0;i>a;
i++){”. An error message afterwards is generated to warn that a compiler error has
been detected. The actual cause of syntax errors may need to be confirmed by a
code inspection. The findings from inspection are used to classify the defect
addressed into a greater depth of NDT or a bottom defect category of NDT.
D1.2.2 MISMATCHED BRACE{} OR PARENTHESIS ()
Description
Class MISMATCHED BRACE{} OR PARENTHESIS () is associated with detects
such as unbalanced placement of parentheses, braces or brackets in programs.
Sample Code
A right parenthesis is missing in the conditional expression of if statement.
01 public class BankAccount{ 02 public void applyInterest(){ 03 if(balance<0 { 04 balance=(int) 05 ( balance*rate+balance); 06 } …………………………. 07 }
08 }
Detection
Java compiler cannot compile the submission and generate a message
“compilation failed”. The actual cause of a syntax error may need to be confirmed

63
by performing a code inspection. The findings from inspection are used to classify
the defect addressed into a greater depth or a bottom defect category of NDT.
D1.2.3 OTHER SYNTAX ERRORS
Description
Class OTHER SYNTAX ERRORS includes syntax error types excluded by classes
D 1.2.1 TYPE MISMATCH and D1.2.2 MISMATCHED BRACE{} OR
PARENTHESIS().
Sample Code
Class ArrayUtility fails the compiler because a variable sum hasn‟t been defined.
This defect classified into category OTHER SYNTAX ERRORS leads to a
compilation failure.
01 public class ArrayUtility { 02 public double sum(double a[]) { 03 for (int i=0;i<a.length(); i++){ 04 sum += a[i]; 05 } return sum;
06 } 07 }
Detection
Java compiler cannot compile the submission and generate an error message
“compilation failed”. The deep reason of the defect is confirmed by performing a
code inspection.
D2. COMPILED
Class COMPILED is further divided into two sub-classes: EVOLVABILITY
DEFECT and FUNCTIONAL DEFECT. The analysis of COMPILED class and its
sub-classes uses automated approaches (both test case and code style checking)
and manual techniques (code inspection).
D2.1 FUNCTIONAL DEFECT
FUNCTIONAL DEFECT class is divided into the following four sub-classes: PLAN,
INITIALIZATION, CHECK and COMPUTATION. These sub-classes of FUNCTIONAL
DEFECT are identified from the previous studies (Basili & Selby 1987; Chillarege et
al. 1992) and discovered from code inspection. Figure 4.4 presents the
sub-classes and sub-sub-classes of the defect class FUNCTIONAL DEFECT.

64
Figure 4. 4. FUNCTIONAL DEFECT Taxonomy
D2.1.1 PLAN
Class PLAN refers to failures resulted from functionality missing or coding
strategy implemented incorrectly. This defect class is similar to the defect type
larger defects proposed by Mantyla & Lassenius (2009). Both defect PLAN in this
study as well as larger defects require a large modification or an additional code
to be added to a program. It is subdivided into two subgroups: FUNCTION
MISSING and LOGIC.
D2.1.1.1 FUNCTION MISSING
Description
Unlike the sub-class INCOMPLETE METHOD in CANNOT COMPILE class,
class FUNCTION MISSING covers code where the method signature is correct
but the method body is missing. Such code will pass Java compiler but fail JUnit
test cases. We classify this defect as FUNCTION MISSING.. However, class
INCOMPLETE CODE would fail Java compiler.
Sample Code
The sample code segment shows within topLetters() a direct String returned but
no expected body of the method given in to take the expected actions.
01 public class TextAnalyser{ 02 public String topLetters(int wordlength){
03 return “etao”; 04 } 05 }
Detection
D 2.1 FUNCTIONAL
DEFECT
D 2.1.1
PLAN
D 2.1.2
INITIALIZATION
D 2.1.3
CHECK
D 2.1.4
COMPUTATION
D 2.1.1.1 FUNCTION MISSING
D 2.1.1.2 LOGIC
D 2.1.2.1 ASSIGNMENT MISSING
D 2.1.2.2 ASSIGNMENT MALFORMED
D 2.1.2.1 VARIABLE
D 2.1.3.2 EXPRESSION
D 2.1.3.3 FUNCTION
D 2.1.4.1 MISSING UPDATE
D 2.1.4.2 MALFORMED UPDATE

65
First the code is successfully compiled by Java compiler. Then the code fails JUnit
tests. The actual cause of the functional defect may need to be confirmed by
conducting a code inspection on the submission.
D2.1.1.2 LOGIC
Description
Class LOGIC is associated with defects made in code blocks using mathematical
operators. A defect is detected when unintended outputs are observed or the
program terminates abnormally.
Sample Code
The method find() is expected to return index of an element in the parameter array.
The method returns the data accumulated by values stored in array instead of the
element index.
01 public int find(double k, double[] a){ 02 for (int i=0; i<a.length-1;i++){ 03 k+= a[i];
04 } 05 return (int)(k); 06 }
The correct code show in the following:
01 public int find(double k, double[] a){ 02 for (int i = 0; i < a.length; i++) { 03 if (a[i] == k) {
04 return i; 05 } 06 } 07 08 }
Detection
The code is successfully compiled but fails some JUnit tests. The actual cause of
functional defects should be confirmed by performing a code inspection.
D2.1.2 INITIALIZATION
Class INITIALIZATION defects occur during variable initialization in constructors
and methods. Class INITIALIZATION is subdivided into two sub-classes:
ASSIGNMENT MISSING and ASSIGNMENT MALFORMED. Both of the
sub-classes are from the study of Kopec, Yarmish & Cheung (2007).
D2.1.2.1 ASSIGNMENT MISSING
Description
Class ASSIGNMENT MISSING is associated with incorrect variable initialization
or incorrect data structures used in constructors or methods.

66
Sample Code
The sample code segment shows a constructor that is missing initializations of
instance variables maxBalance and minBalance
01 public BankAccount(String accountName, int balance) { 02 this.balance=balance; 03 this.accountName=accountName; 04 }
Detection
After the code has been successfully compiled by Java compiler, we detect the
initialization to non-default values with JUnit but need a code inspection if the
expected value is the default but is missing.
D2.1.2.2 ASSIGNMENT MALFORMED
Description
Class ASSIGNMENT MALFORMED is associated with defects such as the
incorrect assignment statements in constructors.
Sample Code
The line 04 in the following segment shows an incorrect variable assignment. The
initial value of minBalance is expected to be equal to the value of balance.
01 public class BankAccount{ 02 public BankAccount(String accountName, int balance) { 03 this.balance = balance; 04 minBalance =0; 05 ……………… 06 } 07 }
Detection
First the code is successfully compiled. Then we detect the initialization to
non-default values. The actual cause of an initialization defect is confirmed by
performing a code inspection.
D2.1.3 CHECK
Class CHECK addresses the defects made when a required validation checking is
incorrect or missing. This class in this study conforms to the findings by Mantyla
& Lassenius (2009). They provide only high-level category CHECK but we
subdivide the class CHECK into the three following sub-classes: VARIABLE,
EXPRESSION and FUNCTION.

67
D2.1.3.1 VARIABLE
Description
Class VARIABLE is associated with defects in checking that an input variable is
within a valid range.
Sample Code
The range of the interest declared in line 02 should be checked before the balance
is updated.
01 public void applyInterest (double rate) { 02 int interest; 03 interest = (int) (balance*rate); 04 if (balance < 0)
05 {balance = balance - interest;} 06 }
Detection
After the code is compiled, it fails some boundary condition tests and extreme
tests that test the boundary and extremities of a valid range. The extreme case tests
the execution of statements with an invalid input while boundary case tests an
input with a boundary value. For example, boundary case tests whether the
method withdrawn () works when the bank balance equals 0. Extreme case tests
whether this method works when the balance equals -100. A code inspection is
needed to confirm the detected defect belonged to VARIABLE, EXPRESSION or
FUNCTION.
D2.1.3.2 EXPRESSION
Description
Class EXPRESSION is associated with defects such as unguarded expressions.
Sample Code
Both the range of variables rate and balance should be checked..
01 public void applyInterest (double rate) { 02 int interest;
03 interest = (int) (balance*rate); 04 if (isOverdrawn()||rate<0) { 05 balance = balance - interest; 06 } 07 }
The correct code is shown in the following:
01 public void applyInterest (double rate) { 02 int interest; 03 interest = (int) (balance*rate); 04 if (isOverdrawn()&&rate<0) { 05 balance = balance - interest; 06 } 07 }

68
Detection
After the code is compiled, it fails some boundary and extreme tests that test the
boundary and the extremities of a valid range. A code inspection is needed to
confirm the detected defect belonged to VARIABLE, EXPRESSION or
FUNCTION.
D2.1.3.3 FUNCTION
Description
Class FUNCTION includes defects such as the incomplete subroutine call in code
or subroutine call missing.
Sample Code
The function isOverdrawn() is expected to be called in the applyInterest() method.
01 public void applyInterest (double rate) 02 {int interest; 03 interest = (int) (balance*rate); 04 if (rate<0) 05 {balance = balance - interest;}
06 }
The following segment shows a correct solution:
01 public void applyInterest (double rate) 02 {int interest; 03 interest = (int) (balance*rate);
04 if (rate<0) { 05 if (isOverdrawn()){ 06 balance = balance - interest; 07 } 08 } 09 }
Detection
After the code is compiled, it fails some boundary and extreme tests. A code
inspection is needed to confirm the detected defect belonged to VARIABLE,
EXPRESSION or FUNCTION.
D2.1.4 COMPUTATION
Class COMPUTATION is associated with defects in mathematical operations that
may involve, in addition to arithmetic operators, in one or more of the following:
constants, functions (method), and equality and relational operators. The
COMPUTATION class is divided into two sub-classes: MISSING UPDATE and
MALFORMED UPDATE. Both of the sub-classes are from the study of Kopec,
Yarmish & Cheung (2007).

69
D2.1.4.1 MISSING UPDATE
Description
Class MISSING UPDATE includes defects that a required updating of the value of
a variable is not present.
Sample Code
In the help method deposit(), the maxBalance is expected to be updated. The
update for maxBalance is missing in the following segment.
01 public void deposit(int amount){ 02 if (amount>0){ 03 balance+=amount; 04 valueDeposits+=amount;
05 } 06 }
Detection
First the code is successfully compiled by Java compiler. Then the code fails JUnit
tests relevant to specific method. The results of test cases show inspectors that the
value of maxBalance is incorrect. This code is therefore suspected of containing
defects of MISSING UPDATE or MALFORMED UPDATE. A code inspection is
needed to confirm the most appropriate defect class.
D2.1.4.2 MALFORMED UPDATE
Description
Class MALFORMED UPDATE is associated with defects that a wrong value is
updated by a variable when an assignment to a variable is presented.
Sample Code
In the following segment, in line 07 the variable maxBalance should be updated
instead of balance.
01 public class BankAccount{ 02 public void deposit (int amount) { 03 if (amount>0){ 04 balance = balance + amount;
05 sumDeposits+=amount; 06 if(balance>maxBalance) { 07 balance=maxBalance; 08 } 09 } 10 }
Detection
First the code is successfully compiled by Java compiler. Then the code fails JUnit
tests relevant to specific method. The results of test cases show inspectors the
value of variable incorrect. The code is therefore suspected of containing defects
of MISSING UPDATE or MALFORMED UPDATE that requires a code inspection

70
to confirm.
D2.2 EVOLVABILITY DEFECT
Evolvability defects affect program development and maintenance efforts instead
of runtime behaviors. The term „evolvability defect‟ is taken from the taxonomy
developed by Siy & Votta (2001). The identification of an evolvability defect is
undertaken by static analysis. The evolvability defect class and its sub-classes as
proposed by Mantyla & Lassenius (2009) are used in this study. They will be
discussed in detail in Section 5.1
There are two sub-classes DOCUMENTATION and STRUCTURE as
sub-classes of the defect class EVOLVABILITY DEFECT. Class EVOLVABILITY
DEFECT and its sub-classes are presented in Figure 4.5.
Figure 4. 5. EVOLVABILITY DEFECT Taxonomy
D2.2.1 DOCUMENTATION
Documentation is the information provided in the source code to help developers
understand the program. The DOCUMENTATION class has three sub-classes:
NAMING, COMMENTS and CODING.
D2.2.1.1 NAMING
Description
Class NAMING detects Java identifies that do not conform to the naming
conventions of Java Language Specifications and Sun Coding Conventions. The
defect identification is undertaken using Checkstyle (2001) and the rules
implemented as follows:
ConstantName checks for names of constants compounded by upper case letters and
D 2.2
EVOLVABILITY
DEFECT
D 2.2.1
DOCUMENTATION
D 2.2.2
STRUCTURE
D 2.2.1.1 NAMING
D 2.2.1.2 COMMENTS
D 2.2.1.3 CODING
D 2.2.2.1 SIZE VIOLATION
D 2.2.2.2 COMPLEX CODE
D 2.2.2.3 UNUSED CODE

71
digits;
LocalVariableName checks for local non-final variable identifiers beginning with letters,
followed by letters or digits;
MemberName checks for non-static names. The name begins with letters, followed by
letters or digits;
MethodName checks for method names beginning with letters, followed by letters or
digits;
ParameterName checks for names of parameters beginning with letters, followed by
letters and digits;
StaticVariableName checks for static non-final variable names beginning with letters,
followed by letters and digits;
TypeName ensures that class name or interface name begin with letters, constructed by
letters and digits”.
Sample Code
The declaration of variable AccountName in line 03 violates the convention. The
variable name should be in camel-case.
01 public class BankAccount { 02 public int balance; 03 public String AccountName; 04 ……………………………………… 05 }
Detection
The code is successfully compiled and run by Java compiler. It violates Naming
rule of Checkstyle (see Table 3.6).
D2.2.1.2 COMMENTS
Description
Class COMMENTS is mainly associated with defects such as the explanation of
classes, constructors, methods, interfaces and variables missing in source code.
The measurement modules for class COMMENTS are taken from Checkstyle
(Checkstyle 2001) and listed as follows:
JavadocMethod checks comments for constructor and method in code;
JavadocType checks “comments for interface and class definitions” or ignoring the
“author or version tags”;
JavadocVariable checks” that variables have Javadoc comments”.
Sample Code
A Javadoc comment is missing for chargeInterest().

72
01 public class BankAccount { 02 /**
03 *Account balance. 04 */ 05 private int balance; 06 ………………………. 07 public void chargeInterest(double rate){ 08 } 09 }
Detection
The code is successfully compiled by Java compiler. It fails the rules of Comments
rule set (see Table 3.6).
D2.2.1.3 CODING
Description
Class CODING is associated with defects such as (Checkstyle 2001):
Empty statement or block;
Inline conditionals;
“Inner assignments in sub-expressions, such as in String s= Integer.toString(i=2)”;
MissingSwitchDefault associates for the existence of the default clause in switch loops.
Sample Code
There is an empty else branch in an if-else block.
01 public char mostFrequent(){ 02 ……………………………………. 03 if(countarray[i]>=countarray[maxindex]){ 04 maxindex=i; 05 }
06 else{ 07 } 08 }………………………………… 09 }
Detection
The code is successfully compiled by Java compiler. It fails rules of Coding rule
set (see Table 3.6).
D2.2.2 STRUCTURE
Class STRUCTURE is associated with too long or too complicated structures of
the source code. SIZE VIOLATION, COMPLEX CODE and UNUSED CODE are
three sub-classes in STRUCTURE class presented in Figure 4.5.
D2.2.2.1 SIZE VIOLATION
Description
Class SIZE VIOLATION includes the defect such as a method with too many
parameters, too many lines or duplicate code. FileLength checks for long source

73
files. This detect module sets the default value of file length to the length of an
instructor‟s solution. The module MethodLength validates long methods and
constructors that may lead to code that is hard to understand. As a solution, long
methods and classes should be broken down into sub-methods. Similar to the
module FileLength, the threshold of MethodLength of different exercises sets for
the maximum method length value of different exercises. The validation modules
in class SIZE VIOLATION are also taken from Checkstyle (Checkstyle 2001) and
listed as follows:
FileLength “checks for long source files”, The file length is set to the length of solution
written by an instructor;
MethodLength “checks for long methods and constructors”. The method length is set to
the maximum method length of solution written by an instructor;
ParameterNumber “checks the number of parameter of a method or constructor”. The
default value is 3 in this study;
DuplicateCode performs “a line-by-line comparison of all code lines and reports
duplicate code if a sequence of lines differs only in indentation”. The default value sets
for 12.
Sample Code
The length of the following function frequency() is 55.
01 public class TextAnalyser{
02 int frequency[]= new int[26];
03 String alphabet ="abcdefghijklmnopqrstuvwxyz";
04 int charcount=0;
05 ……………………………………..
06 public int frequency(char c){
07 if (c== alphabet.charAt(0)){
08 charfrequency = frequency[0];}
09 if (c== alphabet.charAt(1)){
10 charfrequency = frequency[1];}
11 if (c== alphabet.charAt(2)){
12 charfrequency = frequency[2];} 13 if (c== alphabet.charAt(3)){
14 charfrequency = frequency[3];}
15 ……………………………………………………..
16 return charfrequency;
17 } 18 }
Detection
The code is successfully compiled by Java compiler. It fails rules of rule set Size
Violation (see Table 3.6).
D2.2.2.2 COMPLEX CODE
Description

74
Class COMPLEX CODE is associated with the code that can be replaced by using
helper methods. The following list gives the validation modules selected from
Checkstyle (Checkstyle 2001):
BooleanExpressionComplexity checks the maximum number of operators such as &&
and || in an expression which may lead the code difficult to understand, debug and
maintain. The default condition number of maximal allowance sets for 3 in this study;
CyclomaticComplexity measures ”the number of if, while, do, for, ?:, catch, switch, case
statements and operators && and || in the body of a constructor, method, static initializer,
or instance initializer. It is a measure of the minimum number of possible paths through
the source and therefore the number of required tests”. Generally below 8 is fine and 11+
needs to be rewritten”. The default complexity is set to 11 in this study;
NPathComplexity detects the maximum number of execution paths in function. The
default maximum limits to 200 in Checkstyle.
Sample Code
The cyclomatic complexity of TextAnalyser is 55.
01 public class TextAnalyser{ 02 public String topLetters (int wordlength){ 03 String toplet = ""; 04 char[] letters = new char[wordlength]; 05 int[] numlet = new int[wordlength]; 06 letters[0] = mostFrequent(); 07 if (letters[0] == 'a') { 08 numlet[0] = a;
09 ………………………………………………… 10 } 11 else if (letters[0] == 'z') { 12 numlet[0] = z; 13 else { numlet[0] = 0; } 14 for (int i=1;i<wordlength;i++) { 15 letters[i]=mostFrequentuptoMax(numlet[i-1]; 16 if (letters[i] == 'a') {
17 numlet[i] = a; 18 ……………………………………………. 19 } 20 else if (letters[i] == 'z') { 21 numlet[i] = z; 22 } 23 else { numlet[i] = 0; } 24 }
25 for (int i=0;i<wordlength;i++) { 26 toplet = toplet + letters[i]; } 27 return toplet; } 28 }
Detection
The code is successfully compiled by Java compiler. It fails Complex Code rule
set of Checkstyle (see Table 3.6).

75
D2.2.2.3 UNUSED CODE
Description
Class UNUSED CODE is associated with that the statement is never executed
because there is no path to it from the rest of a program. The PMD validation
modules detect unused local variables, unused private methods and fields:
UnusedPrivateField “detects when a private field is declared and assigned a value, but
not used”;
UnusedLocalVariable “detects when a local variable is declared and assigned, but not
used”;
UnusedPrivateMethod “detects when a private method is declared but is unused”;
UnusedFormalParameter detects “passing parameters to methods or constructors” and
those parameters never used.
Sample Code
The statement if() never be executed.
01 public class TextAnalyser { 02 ……………………. 03 private String (String s){ 04 final xxx=false;
05 if(xxx) { 06 07 } 08 } ……………………………… 09 }
Detection
The code is successfully compiled by Java compiler. It fails Unused rule set of
PMD (see Table 3.6).
4.3 Summary
This chapter specifies NDT on both high level categories (e.g. Code Completeness,
Syntax Error, Functional Defect and Evolvability Defect) and on low-level
categories (e.g. Function Missing and Logic). For each category, defect
specification contains a description of the defect, an example segment and
approaches to detect the defect.

76
Chapter 5
Analysis Using the Novice Defect
Taxonomy
We believe that NDT can be used as a tool to hierarchically classify defects in a
reproducible way. In this study, both qualitative analysis (defect type) and
quantitative analysis (defect count) are performed on student submissions. To
present the defect count we use both textual signature count and conceptual
signature count which are introduced in Chapter 3 (pp. 37). Textual signature
count and conceptual signature count per submission (TDC/Sub and CDC%) are
additionally used to record defect counts.
Definition: Textual Defect Count /Submission (TDC/Sub) measures the textual
signature count per submission of a given cohort;
Definition: Conceptual Defect Count /Submission (CDC %) measures the
percentage of subjects who made at least one error in a given cohort.
Additionally, a counting rule is set up for NDT users to record the count for
each defect. It is ruled that when the defect content identified match more than
one defect class, only one class with higher level priority is selected. In NDT, a
higher level priority is given to the defect class at a lower depth. For example, a
two-depth defect has a higher level than a three-depth defect in NDT. Within the
same depth, a defect class with a lower taxonomy code has a higher priority. “For
example, consider a method that requires an array data structure, but instead a
student declares separate variables to store each item. In this study, such a fault

77
would be classified in the sub-class LOGIC in the PLAN category rather than the
sub-class MALFORMED UPDATE in COMPUTATION because the LOGIC defect
class has a higher level.
This chapter evaluates Novice Defect Taxonomy (NDT) by using it to analyze a
large number of student programming assignments. The data is used to answer
eight research questions proposed in Section 1.4.
5.1 Comparison of NDT Defect Categories with
Other Defect Taxonomies
In this section we use data collected from qualitative analysis to answer research
questions: what types of defects are identified from student submissions (Section
1.4.1)? and how are these types related to existing defect taxonomies (Section
1.4.2)?
One reason for assessing a large number of student programs is to discover rare
defect types that might not have been addressed or classified by previous
taxonomies. In this section, we compare NDT categories with other defect
taxonomies and discuss their similarities and differences. From the qualitative
analysis, it is found that sub-classes of FUNCTIONAL DEFECT and
EVOLVABILITY DEFECT are matched well with existing studies. Some new NDT
categories found in this empirical work belong to the class INCOMPLETE CODE.
A taxonomy of defect INCOMPLETE CODE is created on a basis of previous
studies as well as empirical findings. Defect INCOMPLETE CODE has three
sub-classes: D1.1.1 NO SUBMISSION, D1.1.2 UNRECOGNIZED FILE and
D1.1.3 INCOMPLETE METHOD to address the problems of no submission or
incorrect submission, and incomplete functions found in programs. Defects NO
SUBMISSION and UNRECOGNIZED FILE have been also addressed by previous
studies. Both Ahmadzadeh, Elliman & Higgins (2005) and Coull et al. (2003)
presented a defect type named “submission not found” to identify the no
submission problem. Jackson, Cobb & Carver (2004) addressed the file with
unrecognizable format or incorrect names and named this defect “files with
improper names”. Sub-class INCOMPLETE METHOD has been never identified

78
by existing taxonomies.
The sub-classes of SYNTAX ERRORS are superset of previous classifications.
The defect class TYPE MISMATCHED has been also identified by Ahmadzadeh,
Elliman & Higgins (2005). The defect class MISMATCHED BRACE OR
PARENTHESIS has been identified by several previous studies, for example,
Coull et al. (2003), Hristova et al. (2003) and Jackson, Cobb & Carver (2004).
These two defect categories are the most frequent syntax errors in quantitative
analysis. All other syntax defects with lower occurrence rate are classified into
defect class OTHER SYNTAX ERRORS.
Sub-classes of FUNCTIONAL DEFECT agree with findings from previous
work. FUNCTIONAL DEFECT is classified into four sub-classes: PLAN,
INITIALIZATION, CHECK and COMPUTATION. These categories are derived
both from our analysis and from subsets of previous classifications. Some
functional categories not relevant for novice defect analysis are excluded in this
study. For example, defects relating to software interfaces are proposed by
Chillarege et al. (1992) and Mantyla & Lassenius (2009). But in this analysis, it is
observed no specific defects relevant to interface from assignment analysis, and so
there is no interface category in NDT. The discovery of defect PLAN conforms to
the plan defect proposed by Siy & Votta (2001) which refers to a large number of
statements improperly implemented. These defects may require large scale of
modification in software. Basili & Selby‟s (1987) classification contains a class
Initialization but makes no distinction between the omission and commission
cases. It is determined to be an INITIALIZATION defect due to the correct
statements not present or resource initialized incorrectly. In NDT, further
sub-classes D2.1.2.1 ASSIGNMENT MISSING and D2.1.2.2 ASSIGNMENT
MALFORMED are proposed to distinguish these two possibilities. Class CHECK
referring to improper instance assurance or improper method guard has been
detected by Chillarege et al. (1992) and Mantyla & Lassenius (2009). The type
D2.1.4 COMPUTATION indicates defects made in the fourth category
COMPUTATION.
Prior studies emphasize that “the majority of code findings are evolvability
defects” (Siy & Votta 2001): defects that affect how easy to understand, correct
and maintain the code in a long term. Our findings about evolvability classes are
similar to those in other taxonomies. Sub-classes of EVOLVABILITY DEFECT

79
(D2.2) are subset of previous findings. The main defect types DOCUMENTATION
(D2.2.1) and STRUCTURE (D2.2.2) are taken from Mantyla & Lanssenius (2009).
Sub-classes NAMING, COMMENTS and CODING are named based on
Checkstyle rule sets. Subclasses SIZE VIOLATION, COMPLEX CODE and
UNUSED CODE of defect STRUCTURE confirmed by Mantyla & Lassenius
(2009) are also named by the rule sets of Checkstyle and PMD.
5.2 Quantitative Analysis of Defects
There are discrepancies between the most frequent faults that instructors believed
student are making and the faults that students are aware of or are making
(Ala-Muta et al 2005). This section addresses the research questions: what are the
most common defects made by novices (Section 1.4.3)? Are these categories
consistent with previous work (Section 1.4.4)?
When counting defects in programs, a decision is probably needed to count the
total numbers of defects, the numbers of assignments contained defects or to
count both. As defined in Section 3.3.2, counting of defect category textually
results in multiple counts if the same fault occurred many times in one submission.
Conceptual counts are used to measure how many assignments contained the
defect. Both defect types and frequencies are tracked to create an overall list
covering the most frequent defect types.
Another concern of this research is what kinds of mistakes novices are prone to
make. Previous studies have identified the most common errors by conducting
surveys (Flowers, Carver & Jackson 2004; Jackson, Cobb & Carver 2004) or by
counting and classifying common faults identified from assessing student
assignments (Chabert & Higginbotham 1976; Kopec, Yarmish & Cheung 2007).
The textual defect counts of all assignments we analyzed are shown in Table 5.1.
That is, data are collected from 1271 submissions completed by four cohorts. The
top ten defects are ranked by Conceptual Defect Count/ Submission (CDC %)
which shows a percentage of invalid submissions. The defect classes in Table 5.1
are taken from bottom-level categories of NDT.

80
Defect Type TDC CDC %
1 D2.2.1.2 COMMENTS 1790 29.11%
2 D2.1.3.1 CHECK-VARIABLE 1022 20.27%
3 D2.2.1.1 NAMING 604 16.97%
4 D2.2.2.2 COMPLEX CODE 748 16.81%
5 D2.2.2.1 SIZE VIOLATION 590 14.30%
6 D2.2.2.3 UNUSED CODE 405 13.38%
7 D2.2.1.3 CODING 339 13.20%
8 D2.1.4.2 MALFORMED UPDATE 268 10.38%
9 D1.1.1 NO SUBMISSION 179 7.81%
10 D1.2.1 MISSING UPDATE 82 3.23%
Table 5. 1. Top Ten Defects from the UWA Data Set
The most common defect (Table 5.1) reveals students not seeing the importance
of writing proper comments in programs. In the exercises selected for the defect
analysis, a code skeleton with some global fields written by instructors is provided
to guide students. It is hoped students would read and understand the purpose of
each method and then write and comment their code. It is observed that quite few
students have completed the tags and generated meaningful comments on these
fields. Class NO SUBMISSION staying in a rate of 7.81% shows many failing
submissions often found in novice submissions. This finding is confirmed by the
observation from Robins (2010). In Table 5.1, note that the majority of top defects
belong to EVOLVABILITY DEFECT and to CODE COMPLETENESS or
FUNCTIONAL DEFECT. It is noticeable that bottom-category COMPLEX CODE,
SIZE VIOLATION and UNUSED CODE which are all types of STRUCTURE
defects. One reason is that novices may lack the knowledge and skills of program
planning (Lister & Leaney 2003). They only focus on a small part of the overall
structure and thereby design and generate their programs line by line rather than
the large structure of the whole class (Ala-Mutka 2005; Soloway & Spohrer
1989a).
5.3 Defect Patterns and the Difficulty of Exercises
In this section we derive defect patterns to answer the research question: what do
cohort defect patterns tell us about programming exercises (Section 1.4.5)?
Students enrolled by the unit of Java Programming and by the unit of Software
Engineering complete a series of laboratory exercises during a teaching semester.
Each task is designed to evaluate students‟ ability to apply the techniques they

81
have learnt. In NDT, the sub-class FUNCTION MISSING measures incomplete
methods in submissions. Students may produce functional defect FUNCTION
MISSING when they are unable to complete the function or they can‟t even start
coding the function
Complexity
Level
Cohort
(Submission
No.)
Defect Type
D2.1.1.1 FUNCTION MISSING
TDC TDC/Sub CDC CDC% TDC/CDC
Level 1 (Fast)
A1 (N=94) 0 0 0 0% 0
B1 (N=184) 2 0.011 2 1.1% 1
D1 (N=200) 4 0.02 3 1.5% 1.3
C1 (N=75) 6 0.08 3 4% 2 Level 2
(Intermediate) B2 (N=184) 9 0.049 5 2.7% 1 C2 (N=75) 6 0.08 5 6.7% 1.2 D2 (N=200) 33 0.165 20 10% 1.65
Level 3 (Hard) B3 (N=184) 30 0.163 24 13% 1.25
Table 5. 2. FUNCTION MISSING (D2.1.1.1) Defects
for Labs at Different Complexity Levels
Table 5.2 shows the defect counts of defect FUNCTION MISSING measured
from nine exercises completed by four cohorts. Assessed exercises are classified
into three levels based on their assigned complexity level (Table 3.3). Class
FUNCTION MISSING exposes students who are unable to complete lab exercises.
One reason is students cannot complete the assignment before submitting their
code is due to the time limit. Another reason may be that students are limited to
surface knowledge and are unable to apply programming concepts in practice
To obtain a fair measure of students who are struggling with this defect category,
the submission numbers (instead of the number of enrolled students) are shown.
The count of CDC% starts from zero (A1) and climbs up to roughly 10% for more
complicated exercises (D2). Lab B2 and D2 involve the same structure in
programming. Therefore, they are classified into the same level, but three more
complicated methods are added in B2. The student in Cohort D refers to the
beginners who had no typical previous Java programming experience. The trend
in defect type FUNCTION MISSING is increasing in later labs. This indicates that
almost all students are able to complete functions as required in low-level tasks
and many students are unable to complete all functions (usually last one or two
functions) when they face more complicated labs.
In Table 5.2, the high frequency of D2 in intermediate level and B3 in hard

82
level in method incompletion rate suggests that the task requirement of these two
labs may be too hard for students, as approximately 10% and 13% of students are
unable to complete B3. Given the suggestions from Lister & Leaney (2003)‟s
taxonomy, we may perform one solution that provides weak students with an
easier version of laboratory task. By performing a code inspection on these
submissions, it is noted that although both the textual and conceptual counts of
defect FUNCTION MISSING increases for more complicated exercises, there is
little difference between the average numbers of defect per assessed submission
(TDC/CDC) in assessed exercises. The data of TDC/DCD slightly fluctuated
between 1 and 2 indicate that students are able to complete the first few methods
in a code skeleton but may struggle with the last one or two functions. This
suggests instructors could simplify the last few methods or to make the methods
as optional for weak students. As suggested by Lister & Leaney (2003), using an
easier or shortened version of the exercises may better fit the needs of weak
students.
The results in Table 5.2 also suggest that providing test cases to students does
not help them in function completing: 10% students in D2 fail to complete their
tasks although they are given test cases but only 2.7% in B2 have the same
problem without any automatic aids. One reason might that although some
students received feedback generated by supporting tool they are still unable to fix
these problems by themselves. It is noted that students with incomplete code
account for only a small proportion of the whole cohort. Further analysis of defect
patterns would enhance our understanding of students in exercise completion.
5.4 Using NDT to Analyze the Impact of Automatic
Feedback
In this section, we answer the research questions: how does the provision of
formative feedback with programming support tools affect the defect rates in
submitted assignments (Section 1.4.6)? This research question addresses whether
automatic feedback reduce the defect rate of submissions. To answer this question,
we will compare defect counts of the cohort with access to automatic tools with
that of the cohort without any aids.

83
Table 5.3 presents both textual and conceptual counts addressed from all nine
exercises (1271 submissions in total). We count novices‟ defects on the
second-level defect classes: INCOMPLETE CODE, SYNTAX ERROR,
FUNCTIONAL DEFECT and EVOLVABILITY DEFECT. The largest counts
belong to defect class FUNCTIONAL DEFECT and EVOLVABILITY DEFECT,
accounting for 4450 and 1674 TDCs, respectively. INCOMPLETE CODE is the
third defect class accounting for approximately 271 submissions. These
submissions have a few syntactic defects (3.8% of total submission). In the
following, we will perform analysis of labs with and without automatic assistance
to discuss the impact of support tools on defect reduction by counting
FUNCTIONAL DEFECT and EVOLVABILITY DEFECT of these labs.
Main Group TDC TDC/Sub CDC CDC%
INCOMPLETE CODE 271 0.213 227 17.9%
SYNTAX ERROR 65 0.051 48 3.8%
FUNCTIONAL DEFECT 1674 1.317 414 32.6%
EVOLVABILITY DEFECT 4450 3.501 436 34.3%
Table 5. 3. Distribution of Novice Defects
Functional Defect Analysis
Test cases and JUnit integrated with Eclipse IDE are used by Cohort D while
cohort B is given JUnit test cases prepared by the course instructor only. Both of
these two cohorts complete four lab assignments and one project in one academic
semester. To analyze the impact of automatic aids on reducing functional defects
in assignments, the functional defect data of Labs B1 and D1 are presented in
Table 5.4 and 5.5. The defect data was collected from 384 submissions (184
submissions completed by Cohort B and 200 submissions by Cohort D). The main
defect class FUNCTION DEFECT has four sub-classes: PLAN, INITIALIZATION,
CHECK and COMPUTATION. Many submissions contained functional faults:
615 faults in 184 submissions and an average of 3.342 defects per submission
(Table 5.4). The right two columns of Table 5.4 show the outcomes of Cohort D
using instructor-provided test cases and the dynamic testing tool (JUnit) to test the
functional correctness of their programs. The total textual warnings reduce to 70
and the average falls to 0.35 defects per submission.

84
A summary of conceptual counts of functional defects is shown in Table 5.5.
Conceptual percentage of defect CHECK is 90.8% in Lab B1 and this percentage
decreases to 6% in Lab D1. The decrease in the defect rate in Table 5.5 supports
the observation that predefined test cases executed by automatic tools emphasized
on explicit side conditions evoked student awareness of defects in conditional
fields. The results from Table 5.5 show automatic tools and formative feedback
enable an easier removal of functional defects in programs.
FUNCTIONAL
DEFECT
Lab B1 (Without
Support Tool) (N=184) Lab D1 (With Support
Tool) (N=200)
TDC TDC/Sub TDC TDC/Sub
PLAN 16 0.087 5 0.025
INITIALIZATION 33 0.179 28 0.14
CHECK 467 2.538 20 0.1
COMPUTATION 99 0.538 17 0.085
Total 615 3.342 70 0.35
Table 5. 4. Error Information (TDC) of Lab B1 and D1on the
Basis of Sub-classes of FUNCTIONAL DEFECT
FUNCTIONAL
DEFECT
Lab B1 (Without
Support Tool) (N=184) Lab D1 (With
Support Tool) (N=200) CDC CDC% CDC CDC%
PLAN 8 4.3% 3 1.5%
INITIALIZATION 9 4.9% 10 5%
CHECK 157 90.8% 12 6%
COMPUTATION 33 17.9% 12 6%
Total 207 90.8% 37 7.5%
Table 5. 5. Error Information (CDC) of Lab B1 and D1 on the
Basis of Sub-classes of FUNCTIONAL DEFECT
The major change shown in Table 5.5 is the TDC data in the defect class
CHECK-VARIABLE: from 465 observed in Lab B1 to 19 in Lab D1. This finding
can be explained as students may not identify illegal parameter values unless these
are explicitly specified. However, such defects can easily be fixed once students
receive error messages from executing the given JUnit tests. There is little
difference between count of the INITIALIZATION defect of B1 and D1. This can
be explained as having a thorough understanding of field initialization challenges
students. Another concern is students may not understand the intent of an error
message and thereby unable to fix the defects without external help.
Both conceptual and textual counts of defects from the group of students with
tool support are lower than the defect count from the group without lab support
except for the INITIALIZATION defect. This finding supports that the majority of

85
students become effective users who are able to identify and remove functional
faults with the given automatic feedback.
FUNCTIONAL
DEFECT
Lab B1 (Without
Support Tool) (N=184) Lab D1 (With Support
Tool) (N=200) TDC TDC/Sub TDC TDC/Sub
FUNCTION MISSING 10 0.054 4 0.02
LOGIC 6 0.033 1 0.005
ASSIGNMENT MISSING 22 0.12 19 0.095
ASSIGNMENT
MALFORMED
11 0.060 9 0.045
CHECK-VARIABLE 465 2.527 19 0.095
CHECK-EXPRESSION 2 0.011 1 0.005
CHECK-FUNCTION 0 0 0 0
MISSING UPDATE 33 0.179 0 0
MALFORMED UPDATE 66 0.359 17 0.085
Total 615 3.342 70 0.35
Table 5. 6. Error Information (TDC) of Lab B1 and D1 on the
Basis of Bottom Level Classes of FUNCTIONAL DEFECT
FUNCTIONAL
DEFECT
Lab B1 (Without
Support Tool) (N=184) Lab D1 (With Support
Tool) (N=200) CDC CDC% CDC CDC%
FUNCTION MISSING 8 1.2% 3 1.5%
LOGIC 5 0.6% 1 0.5%
ASSIGNMENT MISSING 9 1.7% 10 5%
ASSIGNMENT
MALFORMED
6 2.3% 4 2%
CHECK-VARIABLE 157 90.8% 12 6%
CHECK-EXPRESSION 1 0.6% 1 0.5%
CHECK-FUNCTION 0 0% 0 0%
MISSING UPDATE 15 0% 0 0%
MALFORMED UPDATE 33 22% 12 6%
Total 167 90.8% 15 7.5%
Table 5. 7. Error Information (CDC) of Lab B1 and D1 on the
Basis of Bottom Level Classes of FUNCTIONAL DEFECT
Evolvability Defect Analysis
Similar to the previous functional analysis, Lab B1 and D1 are selected for
evolvability defect analysis. Cohort D is provided with static analysis tools
(Checkstyle and PMD) as well as some configured programming rules. Table 5.8
shows the textual counts of sub-classes of EVOLVABILITY DEFECT. The most
significant results belong to the sub-classes DOCUMENTATION with 275 TDCs
and 1.495 defects per submission for Lab B1. The data is reduced to 3 TDCs and
0.015 defects per submission for Lab D1. With automatic tools, students are able
to avoid making the same faults when a high occurrence observed of that error.
Table 5.9 shows the conceptual defect count (CDC). Again the results suggest that
students become effective users of static analysis tools for detecting the

86
evolvability defects and then quickly remove these faults from their assignments.
EVOLVABILITY
DEFECT
Lab B1 (Without
Support Tool) (N=184) Lab D1 (With Support
Tool) (N=200) TDC TDC/Sub TDC TDC/Sub
DOCUMENTATION 275 1.495 3 0.015
STRUCTURE 3 0.016 6 0.03
Total 278 1.511 9 0.045
Table 5. 8. Error Information (TDC) of Lab B1 and D1 on the
Basis of Sub-classes of EVOLVABILITY DEFECT
EVOLVABILITY
DEFECT
Lab B1 (Without
Support Tool) (N=184)
Lab D1 (With
Support Tool)
(N=200) CDC CDC% CDC CDC%
DOCUMENTATION 32 17.4% 2 1%
STRUCTURE 1 0.5% 2 1%
Total 33 17.9% 4 2%
Table 5. 9. Error Information (CDC) of Lab B1 and D1 on the
Basis of Sub-classes of EVOLVABILITY DEFECT
Defect counts of the bottom classes of EVOLVABILITY DEFECT’s taxonomy
for Labs B1 and D1 are presented in Table 5.10 and Table 5.11. Both conceptual
and textual defect counts of COMMENTS have been reduced. By using PMD to
validate the styles of programs, almost all students in cohort D submit defect-free
assignments. A spike of COMMENTS defects is detected in Lab B1 because
students are not given a code skeleton with code signature.
However, some defect counts do not conform to the trend as expected. It is
surprising, for example, that supporting tools do not reduce ASSIGNMENT
MALFORMED and ASSIGNMENT MISSING defects. Instead, the defect
ASSIGNMENT MALFORMED is only slightly reduced for Lab D1. It indicates
that students are unable to fix faults in constructors and in field declaration from
automatically generated feedback.
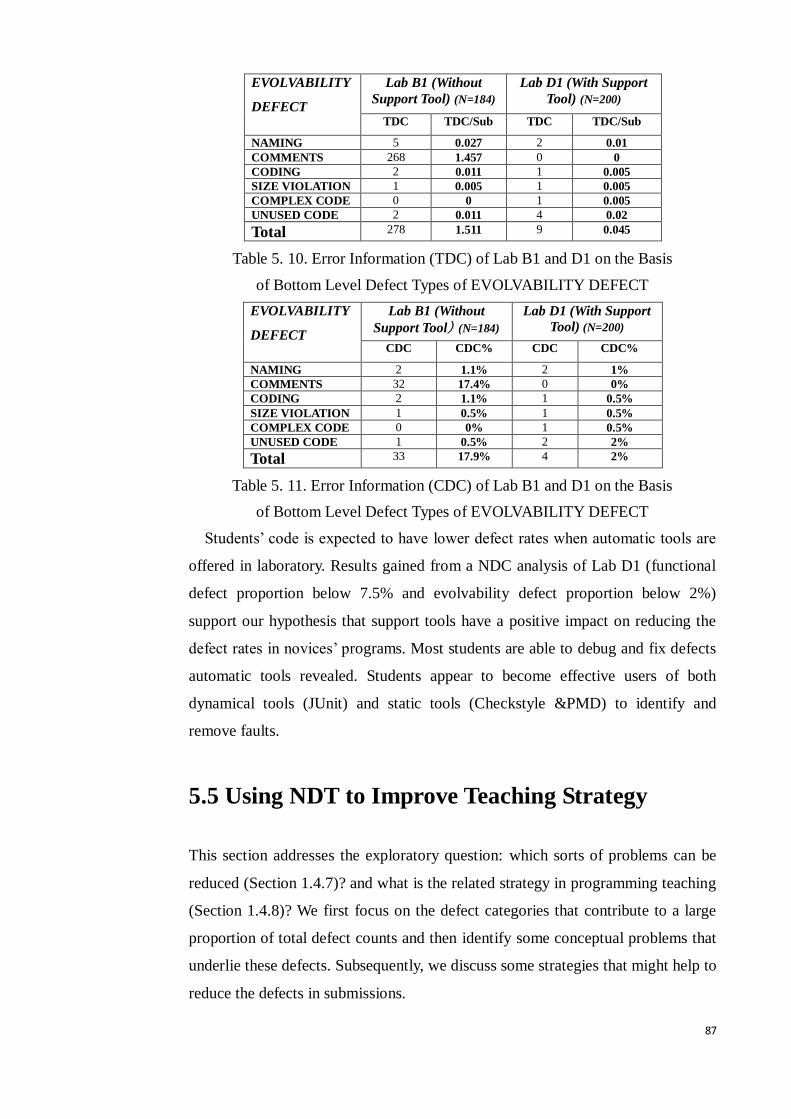
87
EVOLVABILITY
DEFECT
Lab B1 (Without
Support Tool) (N=184) Lab D1 (With Support
Tool) (N=200)
TDC TDC/Sub TDC TDC/Sub
NAMING 5 0.027 2 0.01
COMMENTS 268 1.457 0 0
CODING 2 0.011 1 0.005
SIZE VIOLATION 1 0.005 1 0.005
COMPLEX CODE 0 0 1 0.005
UNUSED CODE 2 0.011 4 0.02
Total 278 1.511 9 0.045
Table 5. 10. Error Information (TDC) of Lab B1 and D1 on the Basis
of Bottom Level Defect Types of EVOLVABILITY DEFECT
EVOLVABILITY
DEFECT
Lab B1 (Without
Support Tool) (N=184) Lab D1 (With Support
Tool) (N=200)
CDC CDC% CDC CDC%
NAMING 2 1.1% 2 1%
COMMENTS 32 17.4% 0 0%
CODING 2 1.1% 1 0.5%
SIZE VIOLATION 1 0.5% 1 0.5%
COMPLEX CODE 0 0% 1 0.5%
UNUSED CODE 1 0.5% 2 2%
Total 33 17.9% 4 2%
Table 5. 11. Error Information (CDC) of Lab B1 and D1 on the Basis
of Bottom Level Defect Types of EVOLVABILITY DEFECT
Students‟ code is expected to have lower defect rates when automatic tools are
offered in laboratory. Results gained from a NDC analysis of Lab D1 (functional
defect proportion below 7.5% and evolvability defect proportion below 2%)
support our hypothesis that support tools have a positive impact on reducing the
defect rates in novices‟ programs. Most students are able to debug and fix defects
automatic tools revealed. Students appear to become effective users of both
dynamical tools (JUnit) and static tools (Checkstyle &PMD) to identify and
remove faults.
5.5 Using NDT to Improve Teaching Strategy
This section addresses the exploratory question: which sorts of problems can be
reduced (Section 1.4.7)? and what is the related strategy in programming teaching
(Section 1.4.8)? We first focus on the defect categories that contribute to a large
proportion of total defect counts and then identify some conceptual problems that
underlie these defects. Subsequently, we discuss some strategies that might help to
reduce the defects in submissions.

88
Firstly, learning strategies and solutions derived from using NDT on analyzing
submissions are summarized in Table 5.12.
Question
What kinds of programming problems do novice encounter? 1. Do not attempt
2. Understanding programming requirement
3. Understanding language syntax
4. Understanding programming structures
5. Dividing functionality into procedures
6. Understanding class declaration and constructor
7. Using guard to validate range of input data
8. Understanding code documentation
P1
P2
P3
P4
P5
P6
P7
P8
What kinds of solutions may help novices in programming? 1. Easier Version of Exercise
2. Creative Response (Feedback)
3. Tool Assisted Instruction (Code Signature)
4. Tool Assisted Instruction (Documentation Configured File)
5. Tool Assisted Instruction (Test Cases)
S1
S2
S3
S4
S5
Table 5. 12. Common Programming Problems, Teaching Strategies and Solutions
Table 5.12 lists 8 problems students encountered. These problems are derived
from lab observation and from submission assessment. Problems P3, P4 &P5 have
also been observed by Lahtinen, Ala-Mutka & Jarvinen (2005). Teaching solutions
S1-S6 in Table 5.12 are proposed to address these problems in programming.
Table 5.13 lists the most common defects identified by using NDT. For each
defect, a possible teaching solution is available to suggest the improvement of
teaching strategies. The problem of don‟t attempt (P1) and understanding
programming requirements (P2) are seen in approximately 10% of students who
have incomplete submissions and roughly 7% who submit no programs over all
exercises analyzed. Understanding language syntax (P3) challenges a small
proportion of novices accounted for 3.8% of overall students. Previous studies
detect many syntax errors because they focus on errors made in work in progress.
However, we focus on the final assignments. The small scale of syntax defects
observed from this study can be explained as many syntax errors have been fixed
during the programming process before formal submissions. The problem of
understanding program structure (P4) results from students failing to use proper
structure to simplify their programs. From static analysis, 16.81% of submissions
violate size limitations and 14.30% have complex structures. Using guards to

89
validate range of input data (P7) and Understanding code documentation (P8)
challenges many students. In future work we plan to investigate further how in-lab
feedback helps students to overcome programming problems.
Problems Defect Class Defect Distribution Solutions
P1 D1.1.1 NO SUBMISSION 7.81% S1
P2 D1.1.2 UNRECOGNIZED FILE 4.3% S2 D1.1.3 INCOMPLETE CODE 17.9%
P3 D1.2 SYNTAX ERROR 3.8% S2
P4 D2.2.2.1 SIZE VIOLATION 14.30% S4, S2 D2.2.2.2 COMPLEX CODE 16.81%
P5 D2.1.1 PLAN 3.21% S3,S2,S6
P6 D2.1.2 INITIALIZATION 5.3% S2
P7 D2.1.3 CHECK 25.8% S5, S2 D2.1.4 COMPUTATION 9.86%
P8 D2.2.1.1 NAMING 16.97% S3, S2 D2.2.1.2 COMMENTS 29.11%
D2.2.2.3 UNUSED CODE 13.38%
Table 5. 13. Top Defect Class, Novice Problems
Underlying & Solution in Teaching Strategies
There are several teaching strategies are available to assist students in
completing laboratory assignments. It is well known that novices are struggling
with the beginning to learn program (P1) and may be unable to upload their
programs on time (D1.1.1 NO SUBMISSION). For students who are trapped in
learning to program, an easier version of an assignment is suggested to be
offered (S1). Subsequently, P2 detected by the defect (D1.1.2 UNRECOGNIZED
FILE) arises from an unawareness of assignment requirements. To solve this, a
creative response (S2) warning students of their unawareness is a possible
solution. In the exercises we assessed, students are always given a Java class
signature (S3) to help them write well-structured programs. To solve the problem
of submissions involved high complexity construct (P4), novices are given
warnings and suggestions of ways to simplify their solutions (S4). Finally,
self-assessment is a significant skill needed by programmers to debug their code.
In this study, the evaluation of functional correctness is reliable to the quality of
test cases given (S5). Test cases with good coverage help novices avoid making
logic or semantic errors. The feedback of failed JUnit tests guides students with
how to correct their problems before submitting their assignments.

90
5.6 Summary
In this chapter we evaluated the Novice Defect Taxonomy (NDT) by using it to
analyse a large dataset of student programming assignments. Then, the defect data
is used to answer five research questions introduced in Chapter 1. We have
compared our defect categories with previous taxonomies (Section 5.1), presented
a list of top defects (Section 5.2), derived defect patterns to show students‟
programming challenges (Section 5.3), evidence about the effect of in-lab
feedback on the defect rates in student assignments (Section 5.4), and proposed
some teaching strategies to address problems that students face (Section 5.5).

91
Chapter 6 Conclusion
6.1 Contribution
In this dissertation, we establish a new defect taxonomy by analyzing large sample
of students‟ assignments. This defect taxonomy reveals the main program defects
that occur in students‟ assignments and provides an evidence to improve the
current teaching curriculum. The main contributions of this dissertation are:
Establishing a descriptive taxonomy of defects for classifying the defects in
students‟ programs;
Describing a defect detection mechanism that uses automated and manual
approaches to detect defects;
Establishing a common defect list. This list contains four main defect
types, included code completion defects, code compiled defects, functional de
fects and evolvability defects;
Describing the main defect patterns that troubled students;
Presenting suggestions to improve teaching curriculum in introductory
programming course according to the defect detection methods used in this
experiment
6.2 Future Work
Future research extends to the following areas:
First, we can perform NDT on assignments completed by students in
intermediate and advanced levels. New defect types can be added to NDT. So
NDT in the future can fit for the analysis of defects made by students in different
levels rather than beginners only.
Subsequently, we provide dynamic and static tools to students in their practical

92
session. The results show that support tools have a positive impact on reducing
defect rates in novices‟ programs. In the future, we change support tools in
laboratory and observe the defect rates in programs. We hope to discover the most
effective method on ways to reduce defects in assignments.
Next, conducting a survey or an interview on students benefits the improvement
of laboratory setting and grading system. In this experiment, we only analyze
the defect types and their distributions in final submissions rather than defects
occurred in programming process. Ko & Myer (2005) conducted a
questionnaire survey on students to investigate their programming difficulties. For
example, the survey focuses on when students make defects in programming and
how long will these defects be removed. Our investigation in the next stage can
use the form of a questionnaire or an interview to investigate the causes and
removals of defects.
Finally, the analysis can be extended to defects in programs written by other
programming languages. We have identified defects in Java programs only in this
study. NDT can be used as a tool to address defects in other
languages. Through the further analysis, NDT is expected to become a taxonomy
that contained defects in many different programming languages.
6.3 Conclusion
This work presents a new defect taxonomy (NDT) developed to classify defects in
students‟ assignments. By using NDT to analyse students‟ code we get a list
of defects of the types: completeness defect, compiler defect, functional defect
and style defect. By knowing what challenged students most, instructors may
improve their teaching by placing greater emphasis on the areas where students
are struggling. From quantitative data, the defect categories observed with high
frequency show the difficulties that challenged many students. The classes of
defect indicating that no work has been done would tell instructors that the
exercises may be too complicated and thereby inform them to prefer an alternative
solution of, giving an easier version of laboratory task.
By using NDT to assess student submissions, it is noted that some defect
categories low frequencies. But it is still valuable to keep these categories in NDT
rather than remove them because the frequencies of these defects may fluctuate

93
when different exercises with different constructs are involved.
Additionally, through the experimental data we found that, the most
common defects belong to the categories of code style defects and functional
defects. Fortunately, automated testing tools and timely feedback have a
positive impact on reducing these two types.

94
Bibliography
Ahmadzadeh, M, Elliman, D & Higgins, C 2005, „An Analysis of Patterns of
Debugging Among Novice Computer Science Students‟, Proceedings of the 10th
Annual SIGCSE Conference on Innovation and Technology in Computer Science
Education, New York, USA, pp. 84-88.
Ala-Mutka, K 2004, „Problems in Learning and Teaching Programming- A
Literature Study for Developing Visualizations in the Codewitz-Minerva Project,‟
Codewitz Needs Analysis, Institute of Software Systems, Tampere University of
Technology.
Ala-Mutka, K 2005, „A Survey of Automated Assessment Approaches for
Programming Assignments,‟ Computer Science Education, vol. 15, no. 2, pp.
83-102.
Allwood, C.M. 1990, „Novices‟ Debugging When Programming in Pascal,‟
International Journal of Man Machine Studies, vol. 33, no. 6, pp. 707-724.
Basili, VR & Perricone, BT 1984, „Software Errors and Complexity: An
Empirical Investigation,‟ Communications of the ACM, vol. 27, no. 1, pp. 42-52.
Basili, VR & Selby, RW 1987, „Comparing the Effectiveness of Software
Testing Strategies‟, IEEE Transactions on Software Engineering, vol. 13, no. 12,
pp. 1278-1296.
Cardell-Oliver, R, Zhang, L, Barady, R, Lim, YH, Naveed, A & Woodings, T
2010, „Automated Feedback for Quality Assurance in Software Engineering
Education,‟ Proceeding of the 2010 21st Australian Software Engineering
Conference, pp. 157-164.
Chabert, J & Higginbotham, T 1976, „An Investigation of Novice Programmer
Errors in IBM 370 (OS) Assembly Language,‟ ACM-SE’14 Proceedings of the
14th
Annual Southeast Regional Conference, New York, NY, USA, pp. 319-323.
Checkstyle 2001, Checkstyle, plug-in for Eclipse Version 5.0.0.200906281855
-final. Available from: http://checkstyle.sourceforge.net. [26 June 2009].
Chillarege, R, Bhandari, IS, Chaar, JK, Halliday, MJ, Moebus, DS, Ray, BK &
Wong, M-Y 1992, „Orthogonal Defect Classification- A Concept for In-Process
Measurements,‟ IEEE Transactions on Software Engineering, vol. 18, no. 11, pp.

95
943-956.
Chillarege, R, Kao, W-L & Condit, RG 1991, „Defect Type and its Impact on
the Growth Curve,‟ Proceedings of the 13th International Conference of Software
Engineering, Austin, TX, USA, pp. 246-255.
Coull, N, Duncan, I, Archibald, J & Lund, G 2003, „Helping Novice
Programmers Interpret Compiler Error Message,‟ Proceedings of the 4th Annual
LTSN-ICS Conference, National University of Ireland, Galway, pp. 26-28.
Detienne, F 1990, „Expert Programming Knowledge: A Scheme-based
Approach‟, in Psychology of Programming, eds J-M HOC, TRG Green & R
Gilmore, Academic Press, People and Computer Series, pp. 205-222.
Eclipse, n.d., Eclipse Fundation Open Source Community. Available from:
http://www.eclipse.org/. [12 December 2008].
Edwards, S 2004, „Improving Student Performance by Evaluating How Well
Students Test Their Own Programs. ACM Journal of Educational Resources in
Computing, vol. 3, no. 3, pp. 1-24.
Endres, A 1975, „An Analysis of Errors and Their Causes in System Programs,‟
Proceedings of the International Conference on Reliable Software, Los Angeles,
California, USA, pp. 327-336.
Findbugs, n.d., Find Bugs in Java Program. Available from:
http://findbugs.sourceforge.net. [26 June 2010].
Florac, WA 1992, Software Quality Measurement: a Framework for Counting
Problems and Defects, CMU/SEI-92-TR-022, Software Engineering Institute,
Carnegie Mellon University, Pittsburgh, Pennsylvania.
Flowers, T, Carver, CA & Jackson, J 2004, „Empowering Students and Building
Confidence in Novice‟, The 34th ASEE/IEEE Frontiers in Education Conference,
vol. 1, pp. T3H/10- T3H/13.
Gugerty, L & Olson, G 1986, „Debugging by Skilled and Novice Programmers,‟
Proceedings of the SIGCHI Conference on Human Factors in Computing Systems,
New York, USA, pp. 171-174.
Hristova, M, Misra, A, Rutter, M & Mercuri, R 2003, „Identifying and
Correcting Java Programming Errors for Introductory Computer Science
Students,‟ ACM SIGCSE Bulletin, vol. 35, no. 1, pp. 153-156.
IEEE 2010, IEEE Standard Classification for Software Anomalies, IEEE Std.
1044-2009.

96
ISO/IEC 2009, Systems and Software Engineering- Vocabulary, ISO/IEC
24765-2009.
Jackson, D 2002, „A Semi-automated Automated Approach to on-line
Assessment‟, in Proceedings of the 5th Annual SIGCSE Conference on Innovation
and Technology in Computer Science Education, pp. 164-167.
Jackson, J, Cobb, M & Carver, C 2004, „Identifying Top Java Errors for Novice
Programmers‟, paper presented to the 35th ASEE/IEEE Frontiers in Education
Conference pp. T4C-24-T4C-27.
Java Programming (CITS1200) n.d., School of Computer Science and Software
Engineering, Available from:
<http://undergraduate.csse.uwa.edu.au/units/CITS1200>, [24 March 2009].
JUnit4, n.d., JUnit4, Resources for Test Driven Development. Available from:
http://www.junit.org. [04 March 2009]
Kaner, C 2003, „What is a Good Test Case?‟ paper presented on the STAR East
2003 Conference, Orlando, pp. 1-16.
Kessler, CM & Anderson, JR 1989, „Learning Flow of Control: Recursion and
Iterative Procedures,‟ Human Computer Interaction, vol. 2, no. 2, pp. 135-166.
Ko, AJ & Myers, BA 2005, „A Framework and Methodology for Studying the
Causes of Software Errors in Programming Systems,‟ Journal of Visual
Languages and Computing, vol. 16, pp. 41-84.
Kolling, M 1999, BlueJ-The Interactive Java Environment. Available from:
http://www.bluej.org/. [14 May 2009]
Kopec, D, Yarmish, G & Cheung, P 2007, „A Description and Study of
Intermediate Student Programmer Errors,‟ Computer Human Error, vol. 39, no. 2,
pp. 146-156.
Lahtinen, E, Ala-Mutka, K & Jarvinen, H-M 2005, „A Study of the Difficulties
of Novice Programmers,‟ ACM SIGC SE Bulletin, vol. 37, no. 3, pp. 14-18.
Lister, R & Leaney, J 2003, „First Year Programming: Let All the Flowers
Bloom‟, Proceeding of the 5th Australasian Conference on Computing Education,
vol. 20, pp. 221-230.
Mantyla, M & Lassenius, C 2009, „What Types of Defects Are Really
Discovered in Code Reviews?‟, IEEE Transactions on Software Engineering, vol.
35, no. 3, pp. 430-448.
McDonald, C 2009, Computer Science and Software Engineering Web-based

97
Software Supporting Teaching. Available from:
https://secure.csse.uwa.edu.au/chris/portfolio/web-software.html. [27 November
2009]
Musa, JD, Iannino, A & Okumoto, K 1987, Software Reliability-Measurement,
Prediction, Application, New York, McGraw-Hill.
Pea, R 1986, „Language-Independent Conceptual Bugs in Novice
Programming,‟ Journal of Educational Computing Research, vol. 2, pp. 25-36.
PMD 2002, PMD plug-in for Eclipse version 3.2.6. v200903300643. Available
from: http://pmd.sourceforge.net/eclipse. [14 July 2009].
Robins, A 2010, „Learning Edge Momentum: A New Account of Outcomes in
CS1,‟ Journal of Computer Science Education, vol. 20, no. 1, pp. 37-71.
Robins, A, Haden, P & Garner, S 2006. „Problem Distributions in a
CS1 Course‟. In Proceeding of the 8th
Australasian Computing Education
Conference, ed. D. Tolhurst, S. Mann, Hobart, Australia, pp. 165-173.
Robins, A, Rountree, J & Rountree, N 2003, „Learning and Teaching
Programming: A Review and Discussion,‟ Computer Science Education, vol. 13,
no. 2, pp. 137-172.
Siy, H & Votta, L 2001, „Does the Modern Code Inspection Have Value?‟
Proceedings of International Conference of Software Maintenance, pp. 281-289.
Soloway, E & Spohrer, J 1989a, „Novice Mistakes: Are the Folk Wisdoms
Correct?‟ in Studying the Novice Programmers, eds E Soloway & J Spohrer,
Lawrence Erlbaum Associates, pp. 401-418.
Soloway, E & Spohrer, J 1989b, Studying the Novice Programmer. Hillsdale,
New Jersey, Lawrence Erlbaum Associates.
Truong, N, Roe, P & Bancroft, P 2004, „Static Analysis of Students' Java
Programs,' Proceedings of the 6th Australian Computing Education Conference,
eds R Lister & AL Young, Dunedin, New Zealand, vol. 30, pp. 317-325.
Whalley, J. and Philpott, A. (2011), A unit testing approach to building novice
programmers skills and confidence. In Proc. Australasian Computing Education
Conference (ACE 2011),Perth, Australia, CRPIT, 114, John Hamer and Michael
de Raadt Eds., ACS. 113-118.