emc vplex with suse high availability extension … vplex with suse high availability extension best...
TRANSCRIPT

ABSTRACT This White Paper provides a best practice to install and configure SUSE SLES High Availability Extension (HAE) with EMC VPLEX. January 2016
EMC WHITE PAPER
EMC® VPLEX® WITH SUSE HIGH AVAILABILITY EXTENSION BEST PRACTICES PLANNING
2 EMC VPLEX with SUSE High Availability Extension Best Practices Planning
To learn more about how EMC products, services, and solutions can help solve your business and IT challenges, contact your local representative or authorized reseller, visit www.emc.com, or explore and compare products in the EMC Store
Copyright © 2014-2016 EMC Corporation. All Rights Reserved.
EMC believes the information in this publication is accurate as of its publication date. The information is subject to change without notice. The information in this publication is provided “as is.” EMC Corporation makes no representations or warranties of any kind with respect to the information in this publication, and specifically disclaims implied warranties of merchantability or fitness for a particular purpose.
Use, copying, and distribution of any EMC software described in this publication requires an applicable software license.
For the most up-to-date listing of EMC product names, see EMC Corporation Trademarks on EMC.com.
Part Number H12377.2

3 EMC VPLEX with SUSE High Availability Extension Best Practices Planning
Table of Contents
Executive summary.................................................................................................. 4 Introduction ....................................................................................................................... 4 Audience ............................................................................................................................ 4
VPLEX overview ....................................................................................................... 4 VPLEX family ....................................................................................................................... 5
VPLEX features ............................................................................................................... 6 Data mobility .................................................................................................................. 6 Continuous availability ................................................................................................... 6 Geographically dispersed clusters .................................................................................. 6 HA Infrastructure ............................................................................................................ 7 Migrations ...................................................................................................................... 7 Federated AccessAnywhere ............................................................................................ 7 VPLEX Witness ................................................................................................................ 8
VPLEX clustering architecture ............................................................................................. 9
Multipathing ......................................................................................................... 11 DM-Multipath ................................................................................................................... 11 EMC PowerPath ................................................................................................................ 11
SUSE HAE overview ............................................................................................... 12
Business imperative for geographically dispersed clusters ..................................... 12
SUSE HAE with VPLEX ............................................................................................ 13 Planning SUSE HAE topology configuration ....................................................................... 13 Best practices .................................................................................................................. 17
Conclusion ............................................................................................................ 19
References ............................................................................................................ 19

4 EMC VPLEX with SUSE High Availability Extension Best Practices Planning
Executive summary High availability is an important business consideration. For many business applications, highly reliable and redundant hardware provides sufficient uptime. For other business needs, the ability for a critical application to fail over to another server in the same data center is sufficient. However, neither of these server availability strategies will help in the event of truly catastrophic server loss.
For some business applications, even an event as unlikely as a fire, flood, or earthquake can pose an intolerable amount of risk to business operations. For truly essential workloads, distance can provide the only hedge against catastrophe. By failing server workloads over to servers separated by hundreds of miles, truly disastrous data loss and application downtime can be prevented.
EMC® VPLEX® with SUSE SLES HAE provides the answer.
Introduction This white paper discusses the VPLEX models and features to provide high availability data across geographically dispersed locations. It describes which technologies working together to provide fully-automated failover mechanisms designed to protect customer data and provide data mobility for planned or unplanned downtimes.
Audience This white paper is intended for technology architects, storage administrators, and system administrators who are responsible for architecting, creating, managing IT environments that utilize EMC VPLEX technologies. The white paper assumes the reader is familiar with SUSE Linux Enterprise Server (SLES).
VPLEX overview EMC VPLEX delivers data mobility and availability across arrays and sites. VPLEX is a unique virtual storage technology that enables mission-critical applications to remain up and running during any of a variety of planned and unplanned downtime scenarios. VPLEX permits painless, non-disruptive data movement, taking technologies like SUSE SLES HAE and other clusters that were built assuming a single storage instance and enabling them to function across arrays and across distance.

5 EMC VPLEX with SUSE High Availability Extension Best Practices Planning
Figure 1 provides an example of an EMC GeoSynchrony™ operating environment.
Figure 1. GeoSynchrony operating environment
This section contains the following information:
• VPLEX family • VPLEX features • VPLEX clustering architecture
VPLEX family
The following are the EMC VPLEX family offerings:
• VPLEX Local: VPLEX local allows centralized management of all arrays in the data center. Storage management is simplified allowing for improved storage utilization across all storage arrays. Data mobility and availability is enhanced using VPLEX local.
• VPLEX Metro/Metro Express: VPLEX Metro uses EMC Federated AccessAnywhere™ technology, allowing block level access to data between two sites within synchronous distances. VPLEX Metro with its active/ active configuration provides high levels of availability, mobility and resource utilization between data centers. EMC VPLEX Metro Express Edition is preconfigured for mid-sized requirements, packaging VPLEX hardware and software in combination with EMC RecoverPoint continuous data protection (CDP). VPLEX Metro Express includes all functionality and features found in standard EMC VPLEX Metro. It comprises everything needed to build a two-site VPLEX Metro configuration for up to 40 TB.

6 EMC VPLEX with SUSE High Availability Extension Best Practices Planning
Figure 2. VPLEX offerings
VPLEX features
This section describes VPLEX features used in this paper.
Data mobility
Move applications, virtual machines, and data in and between data centers without impacting users.
Figure 3. Data mobility example
Continuous availability
Deliver application and data availability within the data center and over distance with full infrastructure utilization and zero downtime.
Figure 4. Continuous availability example
Geographically dispersed clusters
Server clusters support a single cluster spanning multiple sites.
Figure 5. Geographically dispersed clusters example

7 EMC VPLEX with SUSE High Availability Extension Best Practices Planning
HA Infrastructure
HA Infrastructure reduces recover time objective (RTO).
Figure 6. HA infrastructure example
VPLEX is inherently a high availability solution that provides application and data mobility. Adding SUSE SLES High Availability Extension to the VPLEX storage solution creates a total high availability environment with storage, servers, and application protection.
Migrations
Non-disruptive data migrations enable risk-free, faster tech refreshes and load balancing.
Figure 7. Migrations example
Federated AccessAnywhere
VPLEX utilizes cache coherency technology, Federated AccessAnywhere, EMC’s break-through technology that enables a single copy of data to be shared, accessed, and relocated over distance and between sites. Data is presented consistently across VPLEX clusters and can be accessed, shared or relocated between sites.
8 EMC VPLEX with SUSE High Availability Extension Best Practices Planning
Figure 8. Federated AccessAnywhere example
VPLEX Witness
VPLEX Witness is an optional, but highly recommended, component designed for deployment in customer environments where the regular bias rule sets are insufficient to provide seamless zero or near-zero Recovery Time Objective (RTO) failover in the event of site disasters and VPLEX cluster failures.
By reconciling its own observations with the information reported periodically by the clusters, VPLEX Witness enables the cluster(s) to distinguish between inter-cluster network partition failures and cluster failures and to resume I/O automatically in these situations.
Figure 9. High-level VPLEX Witness architecture

9 EMC VPLEX with SUSE High Availability Extension Best Practices Planning
VPLEX clustering architecture
EMC VPLEX represents the next-generation architecture for data mobility and information access. The new architecture is based on EMC’s more than 20 years of expertise in designing, implementing, and perfecting enterprise-class intelligent cache and distributed data protection solutions.
As shown in the following figure, VPLEX is a solution for federating both EMC and non-EMC storage. VPLEX resides between the servers and heterogeneous storage assets and introduces a new architecture with unique characteristics:
• Scale-out clustering hardware, which lets customers to start small and grow big with predictable service levels
• Advanced data caching utilizing large-scale SDRAM cache to improve performance and reduce I/O latency and array contention
• Distributed cache coherence for automatic sharing, balancing, and failover of I/O across the cluster
• Consistent view of one or more LUNs across VPLEX clusters separated either by a few feet with a data center or across synchronous distances, enabling new models of high availability and workload relocation
Figure 10. Capability of the VPLEX system to federate heterogeneous storage
VPLEX uses a unique clustering architecture to help customers break the boundaries of the data center and allow servers at multiple data centers to have concurrent read and write access to shared block storage devices. A VPLEX cluster can scale up through the addition of more engines, and scale out by connecting multiple clusters to form a VPLEX Metro configuration.
In the initial release, a VPLEX Metro system supports up to two clusters, which can be in the same data center or at two different sites within synchronous distances (approximately up to 60 miles or 100 kilometers apart).

10 EMC VPLEX with SUSE High Availability Extension Best Practices Planning
VPLEX Metro configurations help users to transparently move and share workloads, consolidate data centers, and optimize resource utilization across data centers. In addition, VPLEX clusters provide non-disruptive data mobility, heterogeneous storage management, and improved application availability.
Figure 11. Schematic representation of supported EMC VPLEX cluster configurations
A VPLEX cluster is composed of one, two, or four engines. The engine is responsible for virtualizing the I/O stream, and connects to hosts and storage using Fibre Channel connections as the data transport. A single-engine VPLEX cluster consists of the following major components:
• Two directors, which run the GeoSynchrony software
• Dedicated 8 Gb FC front-end, back-end, and local COM and WAN ports
• One Standby Power Supply, which provides backup power to sustain the engine through transient power loss
Each cluster also consists of:
• A management server that provides a GUI and CLI interface to manage a VPLEX cluster
• An EMC standard 40U cabinet to hold all of the equipment of the cluster
Additionally, clusters containing more than one engine also have:
• A pair of Fibre Channel switches used for inter-director communication between various engines
• A pair of Universal Power Supplies that provide backup power for the Fibre Channel switches and allow the system to ride through transient power loss

11 EMC VPLEX with SUSE High Availability Extension Best Practices Planning
Multipathing EMC VPLEX supports multipathing via EMC PowerPath® or SUSE SLES native DM-Multipath on SLES.
DM-Multipath
Device Mapper multipathing (DM-MPIO) is a Linux native multipathing software which can configure multiple I/O paths between server nodes and storage arrays into a single device.
DM-Multipath can be used to provide:
• Redundancy
DM-MPIO can provide failover in an active/passive configuration. In an active/passive configuration, only half the paths are used at any time for I/O. If any element of an I/O path (the cable, switch, or controller) fails, DM-Multipath switches to an alternate path.
• Improved performance
DM-Multipath can be configured in active/active mode, where I/O is spread over the paths in a round-robin fashion. In some configurations, DM-Multipath can detect loading on the I/O paths and dynamically re-balance the load.
For more information on DM-Mulitpath usage, configurations, etc., on SUSE SLES, consult the SLES Storage Administration Guide, available at: https://www.suse.com/documentation.
EMC PowerPath
EMC PowerPath is a host-based software that provides automated data path management and load-balancing capabilities for heterogeneous server, network, and storage deployed in physical and virtual environments. It provides the following benefits:
• Automates failover/recovery
PowerPath automates data path failover and recovery to ensure applications are always available and remain operational.
• Optimizes load balancing
Adjusts I/O paths constantly to leverage all available data paths and to monitor and rebalance the dynamic environment for the best application performance.
• Standardizes path management
Simplifies and standardizes data path management across heterogeneous physical and virtual environments as well as cloud deployments.

12 EMC VPLEX with SUSE High Availability Extension Best Practices Planning
For steps on how to install and configure PowerPath, refer to one of the following EMC PowerPath documents available at https://support.emc.com:
• PowerPath for Linux 6.0 and Minor Releases Installation and Administration Guide
• PowerPath for Linux 6.1 and Minor Releases Installation and Administration Guide
• PowerPath Family Product Guide
SUSE HAE overview A failover cluster is a group of independent computers that work together to increase the availability and scalability of clustered roles (formerly called clustered applications and services). The clustered servers (called nodes) are connected by physical cables and by software. If one or more of the cluster nodes fail, other nodes begin to provide service (a process known as failover). In addition, the clustered roles are proactively monitored to verify that they are working properly. If they are not working, they are restarted or moved to another node.
SUSE Linux Enterprise High Availability Extension is an integrated suite of open source clustering technologies that enables you to implement highly available physical and virtual Linux clusters, and to eliminate single points of failure. It ensures the high availability and manageability of critical network resources including data, applications, and services. Thus, it helps you maintain business continuity, protect data integrity, and reduce unplanned downtime for your mission-critical Linux workloads. It ships with essential monitoring, messaging, and cluster resource management functionality (supporting failover, failback, and migration (load balancing) of individually managed cluster resources). The High Availability Extension is available as add-on to SUSE Linux Enterprise Server. For more information, refer to the SUSE Linux Enterprise High Availability Extension Guide, located at: https://www.suse.com/documentation/sle_ha/book_sleha/?page=/documentation/sle_ha/book_sleha/data/book_sleha.html
Business imperative for geographically dispersed clusters Not all server workloads are created equal. Some applications and solutions hold disproportionate value to your organization. These might be the line-of-business application that represents your competitive advantage or the email server that ties your far-flung organization together. The dark side of these essential IT functions is that they provide a hostage to fate; eventually something will take those services offline, severely hampering your company’s ability to operate, or even bringing business operations to a halt.
Redundant hardware on servers, redundant servers in data centers and effective IT management all play a role in keeping these applications online and available to your employees and your customers. However, none of these precautions can prepare for large-scale server disruptions. Fires, floods, and earthquakes that can destroy or

13 EMC VPLEX with SUSE High Availability Extension Best Practices Planning
impair an entire data center are relatively rare, yet they do occur and, without adequate preparation, they can cost an organization millions of dollars in lost revenue and production. For truly large disasters, distance between server sites is the only thing that can keep a disruption from turning into a catastrophe.
Geographically dispersed clusters can form an important component in disaster preparation and recovery. In contrast to cold standby servers, the servers in a multi-site cluster provide automatic failover. This reduces the total service downtime in the case of a loss of a business-critical server. Another server in the cluster takes over service from the lost server as soon as the cluster determines that it has lost communication with the server previously running the critical workload, as opposed to users and customers waiting for human administrators to notice the service failure and bring a standby server online. And, because the failover is automatic, it lowers the overall complexity of the disaster-recovery plan.
The lower complexity afforded by automatic failover in a multi-site cluster also reduces administrative overhead. Changes made to applications and the application data housed on the cluster are automatically synchronized between all of the servers in the cluster. Backup and recovery solutions do this with a periodic snapshot of the standalone server being protected; meaning that the standby server may have a longer effective time to recovery. For example, if the backup software takes a snapshot every 30 minutes, even if the standby server is brought online at the disaster recovery site within 10 minutes, if the last 25 minutes of transactions have been lost with the primary server, the recovery might as well have taken 25 minutes (at least from the user’s point of view).
SUSE HAE with VPLEX EMC VPLEX in a clustered storage configuration may present devices that are distributed across the two VPLEX sites. Coherency is provided through a WAN link between the two sites such that if one site should go down, the data is available from the other site. Further high availability for the data center is achievable through server clustering. SUSE High Availability Extension is supported in such an application.
This section discusses how to plan a SUSE High Availability Extension topology configuration and best practices.
Planning SUSE HAE topology configuration
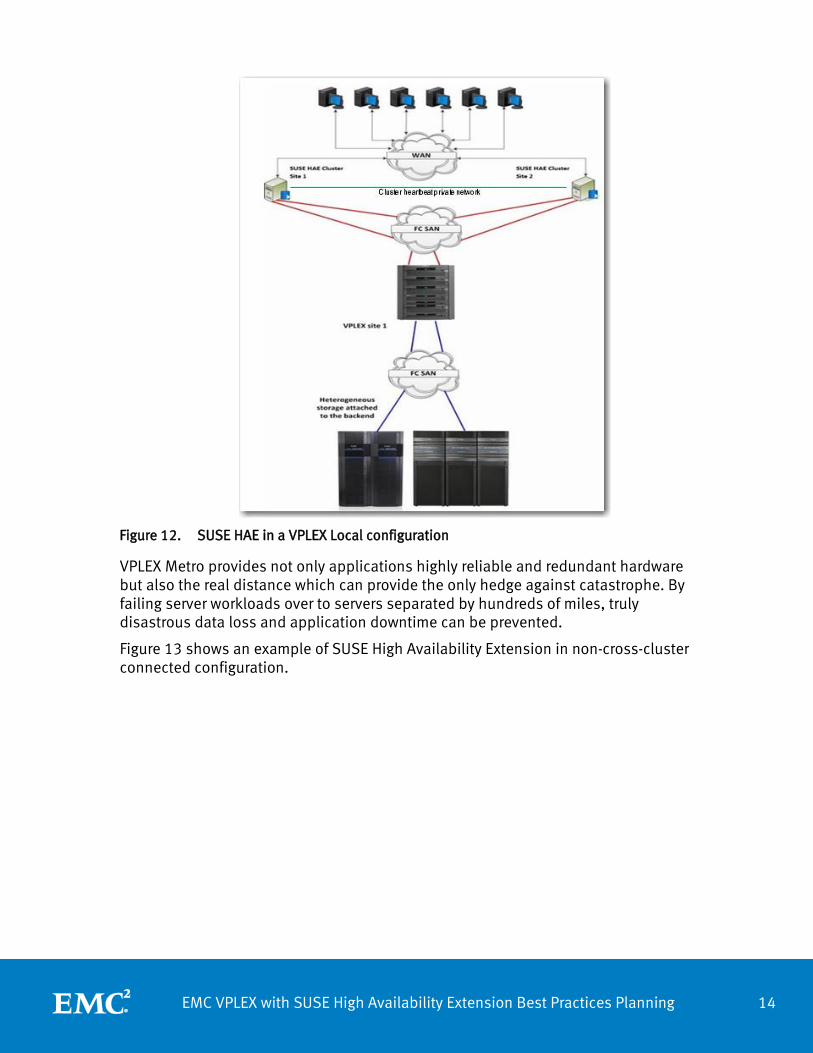
VPLEX Local HA infrastructure provides applications highly reliable and redundant hardware while delivering data mobility and availability across arrays of EMC and Non-EMC storage. VPLEX manages heterogeneous block storage from a single interface with EMC Unisphere® for VPLEX, which uses the same graphical user interface (GUI) framework as EMC VNX and EMC VMAX platforms, providing a way to simplify, normalize, and consolidate EMC management tools. Figure 12 shows an example of SUSE HAE in a VPLEX Local configuration.
14 EMC VPLEX with SUSE High Availability Extension Best Practices Planning
Figure 12. SUSE HAE in a VPLEX Local configuration
VPLEX Metro provides not only applications highly reliable and redundant hardware but also the real distance which can provide the only hedge against catastrophe. By failing server workloads over to servers separated by hundreds of miles, truly disastrous data loss and application downtime can be prevented.
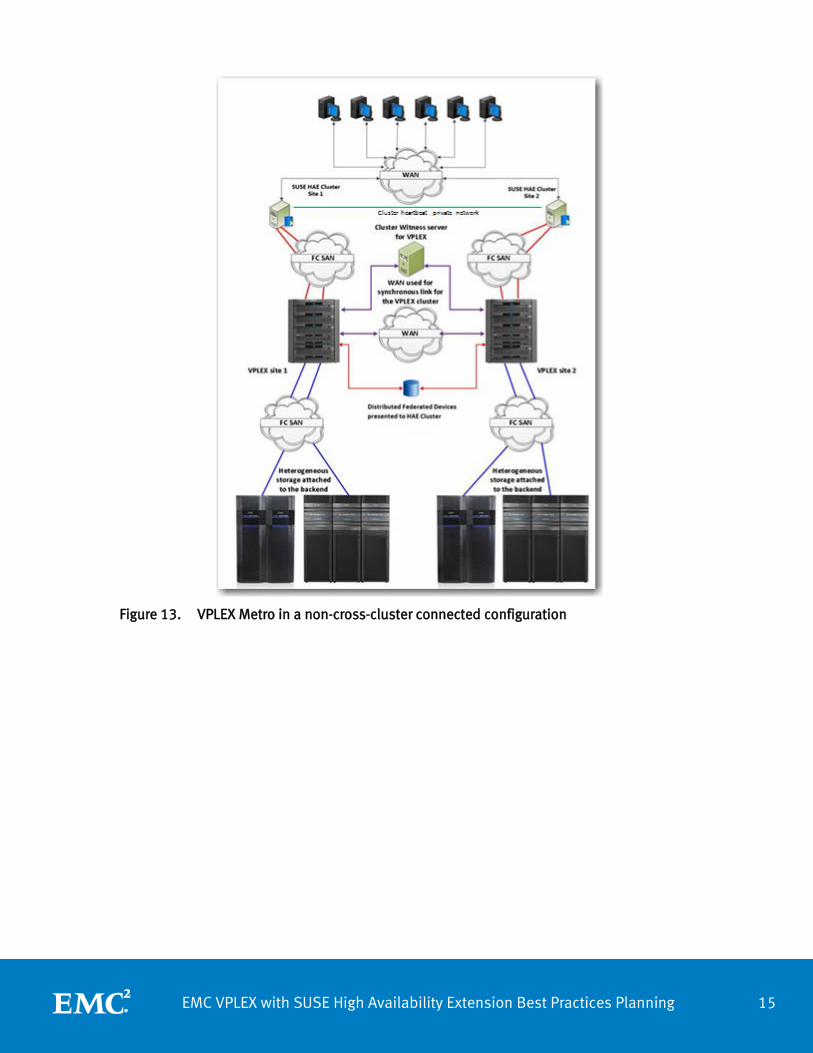
Figure 13 shows an example of SUSE High Availability Extension in non-cross-cluster connected configuration.
15 EMC VPLEX with SUSE High Availability Extension Best Practices Planning
Figure 13. VPLEX Metro in a non-cross-cluster connected configuration

16 EMC VPLEX with SUSE High Availability Extension Best Practices Planning
Figure 14 shows an example of SUSE High Availability Extension in a cross-cluster connected configuration.
Figure 14. VPLEX Metro in a cross-cluster connected configuration

17 EMC VPLEX with SUSE High Availability Extension Best Practices Planning
Best practices
Consider the following best practices.
Heartbeat installation
Server cluster heartbeat limitation per SUSE specification is less than 5.0 ms.
Refer to the SUSE High Availability Guide for details.
STONITH Fencing
SUSE High Availability Extension implements fencing with STONITH (Shoot the Other Node in the Head) mechanism. STONITH provides node level fencing. SUSE High Availability Extension includes the stonith command-line tool, an extensible interface for remotely powering down a node in the cluster. For an overview of the available options, run stonith –help or refer to the man page of stonith for more information.
You can also refer to the “Fencing and STONITH” chapter in SUSE Linux Enterprise High Availability Extension Guide, to find out more about the configuration and settings of STONITH. This guide is located at:
https://www.suse.com/documentation/sle_ha/book_sleha/?page=/documentation/sle_ha/book_sleha/data/book_sleha.html
Consistency groups
Consistency groups should be set for one site wins for all distributed devices in the VPLEX cluster attached to the SUSE HAE cluster. The winning site should be aligned to the winning nodes in the SUSE HAE cluster.
Node communication
For the communication between nodes in a HAE cluster, at least two TCP/IP communication media should be installed and configured. Cluster nodes use multicast or unicast for communication so the network equipment must support the communication means you want to use. The communication media should support a data rate of 100Mbit/s or higher. Preferably, the Ethernet channels should be bonded. For more information, see the “Installation and Basic Setup” chapter in the SUSE Linux Enterprise High Availability Extension Guide, available at:
https://www.suse.com/documentation/sle_ha/book_sleha/?page=/documentation/sle_ha/book_sleha/data/book_sleha.html
SBD Fencing
SBD refers to STONITH Block Devices, in which you can use shared storage that are visible to all nodes as STONITH devices. In conjunction with watchdog and external/sbd agent, SBD devices can reliably protect HAE cluster from split brain scenarios.

18 EMC VPLEX with SUSE High Availability Extension Best Practices Planning
You can have up to three SBD devices, where reliability increases with the number of devices. A very small portion (1 MB) is used on each device to create 255 message slots to support up to 255 nodes that can access to the same shared storage.
For more information, refer to the “Storage Protection” chapter in the SUSE Linux Enterprise High Availability Extension Guide, located at
https://www.suse.com/documentation/sle_ha/book_sleha/?page=/documentation/sle_ha/book_sleha/data/book_sleha.html
Or SBD Fencing on Linux-HA.org:
http://www.linux-ha.org/wiki/SBD_Fencing
SBD using multipathed devices
You can use PowerPath devices for SBD fencing. You may need to adjust the timeouts SBD uses, as PowerPath’s path down detection can cause delays.
After the msgwait timeout, the message is assumed to have been delivered to the node. For a PowerPath device this should be the time required for PowerPath to detect a path failure and switch to the next path, which should be 180 seconds as a worst case. The node will perform suicide if it has not updated the watchdog timer fast enough; the watchdog timeout must be shorter than the msgwait timeout. Typically, half the value of watchdog timeout is a good rule of thumb.
You would set these values by adding -4 msgwait -1 watchdogtimeout to the create command:
/usr/sbin/sbd -d /dev/emcpowera -4 180 -1 90 create
(All timeouts are in seconds.)
Note: This can incur significant delays to fail-over.
A DM-Multipath device is also supported as an SBD fencing device. Just as when PowerPath is employed, considerations for its configuration must account for path failover and detection logic and the delay it may impact upon the msgwait timeout. For more information regarding its configuration, consult the “Storage-based Fencing” chapter in SUSE Linux Enterprise High Availability Extension, available at:
https://www.suse.com/documentation/sle_ha/pdfdoc/book_sleha/book_sleha.pdf
Detailed EMC best practices and configuration information
More detailed configuration information can be found in the “Supported SUSE HAE Configurations and Best Practices” section of the EMC Host Connectivity Guide for Linux at https://support.emc.com.

19 EMC VPLEX with SUSE High Availability Extension Best Practices Planning
Conclusion
This document provided an overview of EMC VPLEX, along with a best practice of installation and configuration of SUSE High Availability Extension. By using VPLEX distributed virtual volumes, data can be transparently made available to all notes in a SUSE High Availability Extension cluster divided across two physical locations. SUSE HAE cluster can be defined either as a local cluster or a geographically extended cluster by the host cluster software. VPLEX supports either scenario.
Like a host clustering product, VPLEX is architected to react to failures in a way that will minimize the risk of data corruption. With VPLEX, the concept of a “preferred site” ensures that one site will have exclusive access to the data in the event of an inter-site failure. To minimize downtime and manual intervention, it is a best practice to configure the host cluster and VPLEX in parallel; that is, for a given resource the VPLEX preferred site and the host cluster preferred node(s) should be set to the same physical location.
References
The following in available on EMC Online support at https://support.emc.com:
• Implementation and Planning Best Practices for EMC VPLEX Technical Notes
• Long-Distance Application Mobility Enabled by EMC VPLEX GEO White Paper
• EMC VPLEX with GeoSynchrony Product Guides
• EMC Host Connectivity Guide for Linux, https://elabnavigator.emc.com
For SUSE SLES or HAE related topics, you may refer to SUSE Docs:
https://www.suse.com/documentation
• SUSE Linux Enterprise High Availability Extension Guide
• SLES Administration Guide
• SLES Storage Administration Guide
And you can also find SBD fencing on Linux-HA.org:
http://www.linux-ha.org/wiki/SBD_Fencing