embedded systems in silicon td5102 data management (1) overview henk corporaal...
Post on 20-Dec-2015
232 views
TRANSCRIPT

Embedded Systems in SiliconTD5102
Data Management (1)Overview
Henk Corporaalhttp://www.ics.ele.tue.nl/~heco/courses/EmbSystems
Technical University EindhovenDTI / NUS Singapore
2005/2006

H.C. TD5102 2
Data Management Overview
• Motivation
• Example application
• Data Management (DM) steps
• Results
Important note:-We consider here static declared data structures only-DM is also called
-DTSE (Data Transfer and Storage Exploration), or-Physical Memory Management

H.C. TD5102 3
Dynamic memory mgmtDynamic memory mgmt
Task concurrency mgmtTask concurrency mgmt
Physical memory mgmtPhysical memory mgmt
Address optimizationAddress optimization
SWSWdesigndesignflowflow
HWHWdesigndesignflowflow
SW/HW co-designSW/HW co-design
Concurrent OO specConcurrent OO spec
Remove OO overheadRemove OO overhead

H.C. TD5102 4
VLIWcpu
I$
video-in
video-out
audio-in
audio-out
PCI bridge
Serial I/O
timers I2C I/O
SDRAM
D$
for (i=0;i<n;i++) for (j=0; j<3; j++) for (k=1; k<7; k++) B[j] = A[i*4+k];
SDRAM
D$
Data storage bottleneck
B[j] = A[i*4+k];
The underlying idea
B[j] = A[i*4+k];
Data transfer bottleneck
B[j] = A[i*4+k];

H.C. TD5102 5
Platform architecture model
CPUs
HWaccel
Level-1 Level-2 Level-3 Level-4
ICache
LocalMemory
Disk
MainMemory
bus-if
on-c
hip
buss
es
LocalMemory
L2Cache
LocalMemory
bridge SCSI
DCache Disk
Disk
bus
bus
SCSI
bus
Chip

H.C. TD5102 6
Platform example: TriMedia
5 out of 27 processor
FU’s
128*32b16-portRegFile
Hardware accelerators
TriMedia TM1000
256M1-portSDRAM
16K2-portSRAM
256M1-portSDRAM
SWcache8KB
TriMedia TM1000 cache
HWcache
8/16KB
CPUCache bypassSW controlledHW controlled

H.C. TD5102 7
Data transfer and storage power
012345
6
Relative energyper operation
ADD DX,BX
MOV DB,[BX]
Cache miss(per word)
05
10152025303540
Powerdistribution in
CPUs
Storage
Interconnect
Clocks
Other
05
101520253035
Relative energy per operation
16b carry-select
16b multiplier
8x128x16 SRAM (R)
8x128x16 SRAM (W)
External IO access
16b Memory transfer
Power(memory)
Power(arith
metic)= 33

H.C. TD5102 8
ApplicationsApplicationsArchitecture
Instance
Mapping
Applications
PerformanceAnalysis
PerformanceNumbers
Data transfer anddata storagespecificrewrites in theapplication code
Positioning in the Y-chart
H.C. TD5102 9
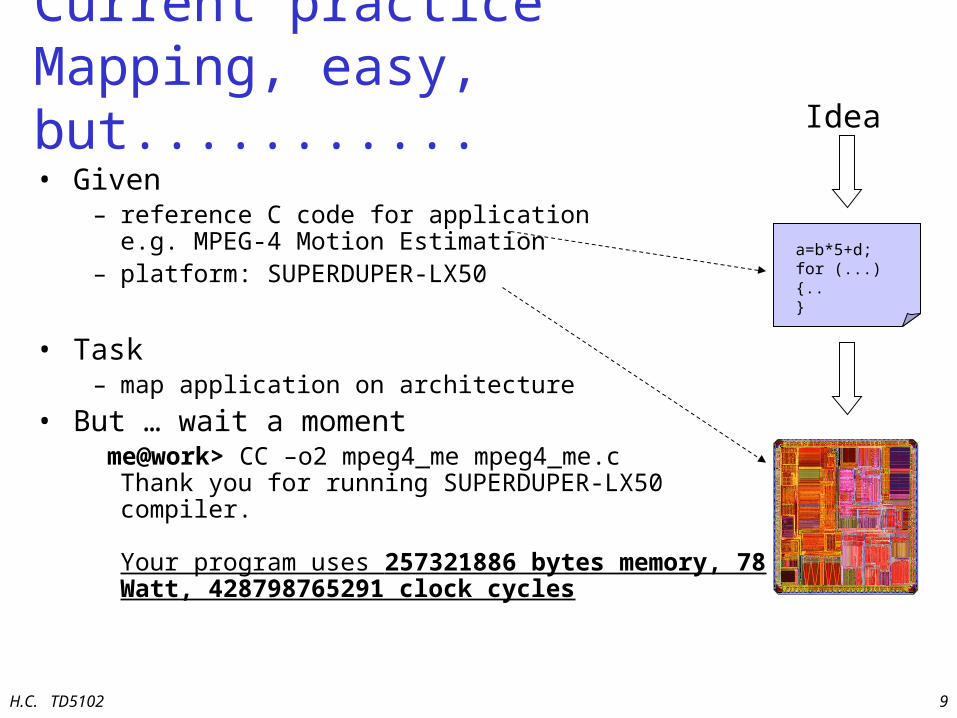
Current practiceMapping, easy, but...........• Given
– reference C code for applicatione.g. MPEG-4 Motion Estimation
– platform: SUPERDUPER-LX50
• Task– map application on architecture
• But … wait a moment me@work> CC –o2 mpeg4_me mpeg4_me.cThank you for running SUPERDUPER-LX50 compiler.
Your program uses 257321886 bytes memory, 78 Watt, 428798765291 clock cycles
a=b*5+d;for (...){..}
Idea

H.C. TD5102 10
Let’s help the compiler ...DTSE: data transfer and storage exploration
• DTSE is a methodology to explore data-transfer and data-storage in multi-media applications
– Transforms C-code of the application
– By focusing on multi-dimensional signals (arrays)
– To better exploit platform capabilities
• This overview covers the major steps to improve power, area, performance trade-off

H.C. TD5102 11
Data Management principles
Processor Data Paths
L1cache
L2cache
CacheBank
Combine
local latch 1& bank 1
local latch N& bank N
Exploit memory hierarchy
Off-chip SDRAM
Exploit limited life-time
Avoid N-port Memories within real-time constraints
Reduce redundant transfersIntroduce Locality

H.C. TD5102 12
DM stepsC-in
Preprocessing
Dataflow transformations
Loop transformations
Data reuse Memory hierarchy layer assignment
Cycle budget distribution
Memory allocation and assignment
Data layout
C-out
Address optimization

H.C. TD5102 13
The DM steps• Preprocessing
– Rewrite code in 3 layers (parts)– Selective inlining, Single Assignment form, ....
• Data flow transformations– Eliminate redundant transfers and storage
• Loop and control flow transformations– Improve regularity of accesses and data locality
• Data re-use and memory hierarchy layer assignment– Determine when to move which data between memories to meet
the cycle budget of the application with low cost– Determine in which layer to put the arrays (and copies)

H.C. TD5102 14
The DM steps
Per memory layer:• Cycle budget distribution
– determine memory access constraints for given cycle budget
• Memory allocation and assignment– which memories to use, and where to put the arrays
• Data layout– determine how to combine and put arrays into memories
• Address optimization on the final C-code

H.C. TD5102 15
Application example
• Application domain:– Computer Tomography in medical imaging
• Algorithm: – Cavity detection in CT-scans
– Detect dark regions in successive images
– Indicate cavity in brain
Bad news for owner of brain

H.C. TD5102 16
Data enters Cavity Detectorrow-wise
scandevice
Buffer
serial scan
Cavity
Detector
GaussBlur loop
= image_in

H.C. TD5102 17
Application
Reference (conceptual) C code for the algorithm
– all functions: image_in[N x M]t-1 -> image_out[N x M]t
– new value of pixel depends on its neighbors
– neighbor pixels read from background memory
– approximately 110 lines of C code (ignoring file I/O etc)
– experiments with N x M = 640 x 400 pixels
– straightforward implementation: 6 image buffers
ComputeEdges
GaussBlur x
ReverseDetectRoots
MaxValue
GaussBlur y
H.C. TD5102 18
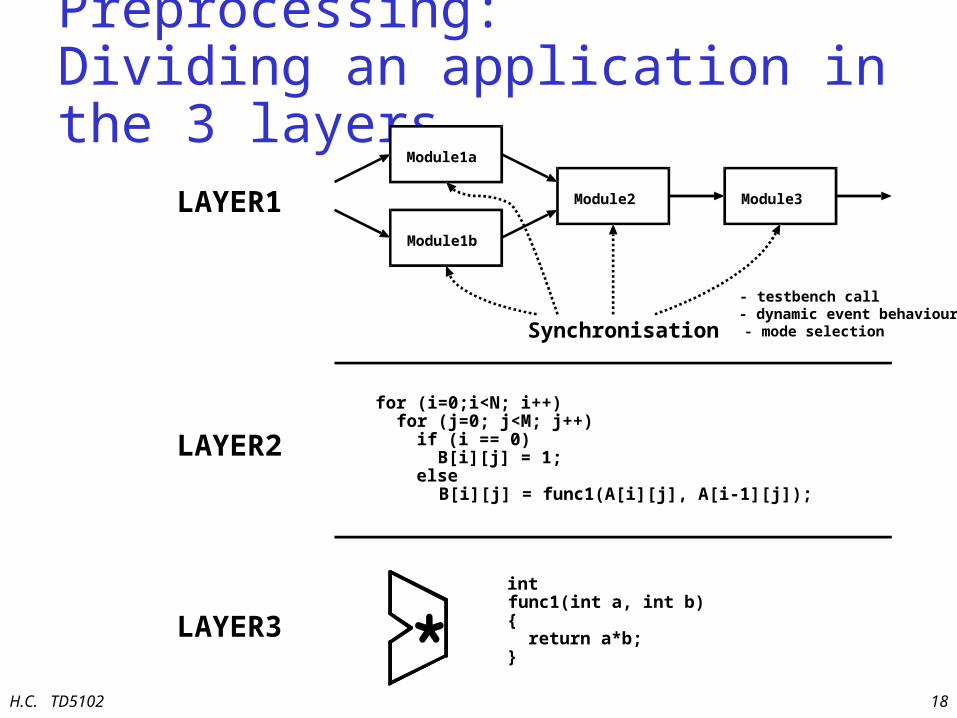
Preprocessing: Dividing an application in the 3 layers
Module1a
Module1b
Module2 Module3
Synchronisation
- testbench call- dynamic event behaviour- mode selection
for (i=0;i<N; i++) for (j=0; j<M; j++) if (i == 0) B[i][j] = 1; else B[i][j] = func1(A[i][j], A[i-1][j]);
intfunc1(int a, int b){ return a*b;}
LAYER1
LAYER2
LAYER3

H.C. TD5102 19
main(){ /* Layer 1 code */ read_image(IN_NAME, image_in); cav_detect(); write_image(image_out);}
void cav_detect() { /* Layer 2 code */ for (x=GB; x<=N-1-GB; ++x) { for (y=GB; y<=M-1-GB; ++y) { gauss_x_tmp = 0; for (k=-GB; k<=GB; ++k) { gauss_x_tmp += in_image[x+k][y] * Gauss[abs(k)]; } gauss_x_image[x][y] = foo(gauss_x_tmp); } }}
Layered code structure

H.C. TD5102 21
N
M
Data-flow trafo - cavity detection
for (x=0; x<N; ++x) for (y=0; y<M; ++y) gauss_x_image[x][y]=0;
for (x=1; x<=N-2; ++x) { for (y=1; y<=M-2; ++y) { gauss_x_tmp = 0; for (k=-1; k<=1; ++k) { gauss_x_tmp += image_in[x+k][y]*Gauss[abs(k)]; } gauss_x_image[x][y] = foo(gauss_x_tmp); } }}
M-2
N-2
#accesses: N * M + (N-2) * (M-2)

H.C. TD5102 22
Data-flow trafo - cavity detection
N
M
N-2
M-2
for (x=0; x<N; ++x) for (y=0; y<M; ++y) if ((x>=1 && x<=N-2) && (y>=1 && y<=M-2)) { gauss_x_tmp = 0; for (k=-1; k<=1; ++k) { gauss_x_tmp += image_in[x+k][y]*Gauss[abs(k)]; } gauss_x_image[x][y] = foo(gauss_x_tmp); } else { gauss_x_image[x][y] = 0; } }}
#accesses: N * Mgain is ± 50 %

H.C. TD5102 23
Data-flow transformation
• In total 5 types of data-flow transformations:
– advanced signal substitution and (copy) propagation
– algebraic transformations (associativity, etc.)
– shifting “delay lines”
– re-computation
– transformations to eliminate bottlenecks for subsequent loop transformations

H.C. TD5102 24
• Loop transformations– improve regularity of accesses
– improve temporal locality: production consumption
• Expected influence– reduce temporary storage and (anticipated) background
storage
storage size N
Loop transformations
for (j=1; j<=M; j++) for (i=1; i<=N; i++) A[i]= foo(A[i]);
for (i=1; i<=N; i++) out[i] = A[i];
for (i=1; i<=N; i++) { for (j=1; j<=M; j++) { A[i] = foo(A[i]); } out[i] = A[i];}
storage size 1

H.C. TD5102 25
Global loop transformation steps applied to cavity detection• Removal of data-flow bottleneck
– allows merging of loops– done in global data-flow trafo step
• Make all loop dimensions equal• Regularize loop traversal:
Y and X loop interchange– follow order of input stream
• Y loop folding and global mergingX loop folding and global merging– full, global scope regularity– nearly complete locality for main signals

H.C. TD5102 26
Scanner
Loop trafo - cavity detectionN x M
GaussBlur x
N x M
From double bufferto single buffer
X
YX-Y LoopInterchange

H.C. TD5102 27
• Single assignment always possible
• For all loops, to maintain regularity
Loop interchange (Y X)for (x=0;x<N;x++) for (y=0;y<M;y++) /* filtering code */
for (y=0;y<M;y++) for (x=0;x<N;x++) /* filtering code */

H.C. TD5102 28
Loop trafo - cavity detection
ComputeEdges
GaussBlur y
N x (2GB+1)
Repeated fold and loop merge
N x 3
From N x M toN x (3) buffer size
From N x M toN x (2GB+1) buffer size
2GB+13(offset
arrays)
GaussBlur x

H.C. TD5102 29
for (y=0;y<M;y++) for (x=0;x<N;x++) /* 1st filtering code */for (y=0;y<M;y++) for (x=0;x<N;x++) /* 2nd filtering code */
for (y=0;y<M;y++) for (x=0;x<N;x++) /* 1st filtering code */ for (x=0;x<N;x++) /* 2nd filtering code */
Improve regularity and locality Loop Merging
!! Impossible due to dependencies!

H.C. TD5102 30
Data dependencies between1st and 2nd loop
for (y=0;y<M;y++) for (x=0;x<N;x++) … gauss_x_image[x][y] = …
for (y=0;y<M;y++) for (x=0;x<N;x++) … for (k=-GB; k<=GB; k++) … = … gauss_x_image[x][y+k] …

H.C. TD5102 31
Enable merging withLoop Folding (bumping)
for (y=0;y<M;y++) for (x=0;x<N;x++) … gauss_x_image[x][y] = …
for (y=0+GB;y<M+GB;y++) for (x=0;x<N;x++) … y-GB … for (k=-GB; k<=GB; k++) … gauss_x_image[x][y+k-GB] …

H.C. TD5102 32
Y-loop merging on 1st and 2nd loop nest
for (y=0;y<M+GB;y++) if (y<M) for (x=0;x<N;x++) … gauss_x_image[x][y] = …
if (y>=GB) for (x=0;x<N;x++) if (x>=GB && x<=N-1-GB && (y-GB)>=GB && (y-GB)<=M-1-GB) … for (k=-GB; k<=GB; k++) … gauss_x_image[x][y-GB+k] … else

H.C. TD5102 33
Simplify conditionsin merged loop nest
for (y=0;y<M+GB;y++) for (x=0;x<N;x++) if (y<M) … gauss_x_image[x][y] = …
for (x=0;x<N;x++) if (y>=GB && x>=GB && x<=N-1-GB && (y-GB)>=GB && (y-GB)<=M-1-GB) … for (k=-GB; k<=GB; k++) … gauss_x_image[x][y-GB+k] … else if (y>=GB)

H.C. TD5102 34
Global loop merging/folding steps
1 x y Loop interchange (done)
2 Global y-loop folding/merging: 1st and 2nd nest (done)
3 Global y-loop folding/merging: 1st/2nd and 3rd nest
4 Global y-loop folding/merging: 1st/2nd/3rd and 4th nest
5 Global x-loop folding/merging: 1st and 2nd nest
6 Global x-loop folding/merging: 1st/2nd and 3rd nest
7 Global x-loop folding/merging: 1st/2nd/3rd and 4th nest

H.C. TD5102 35
End result of global loop trafo
for (y=0; y<M+GB+2; ++y) { for (x=0; x<N+2; ++x) { … if (x>=GB && x<=N-1-GB && (y-GB)>=GB && (y-GB)<=M-1-GB) { gauss_xy_compute[x][y-GB][0] = 0; for (k=-GB; k<=GB; ++k) gauss_xy_compute[x][y-GB][GB+k+1] = gauss_xy_compute[x][y-GB][GB+k] + gauss_x_image[x][y-GB+k] * Gauss[abs(k)]; gauss_xy_image[x][y-GB] = gauss_xy_compute[x][y-GB][(2*GB)+1]/tot; } else if (x<N && (y-GB)>=0 && (y-GB)<M) gauss_xy_image[x][y-GB] = 0; …

H.C. TD5102 36
#A = 100
P (original) = # access x power/access = 100
Processor Data Paths
RegFile
MMain
memory
P = 1
M’
P = 0.1
M’’
P = 0.01
100 110
Data re-use & memory hierarchy
• Introduce memory hierarchy – reduce number of reads from main memory
– heavily accessed arrays stored in smaller memories
P (after) = 100 x 0.01 + 10 x 0.1 + 1 x 1 = 3

H.C. TD5102 37
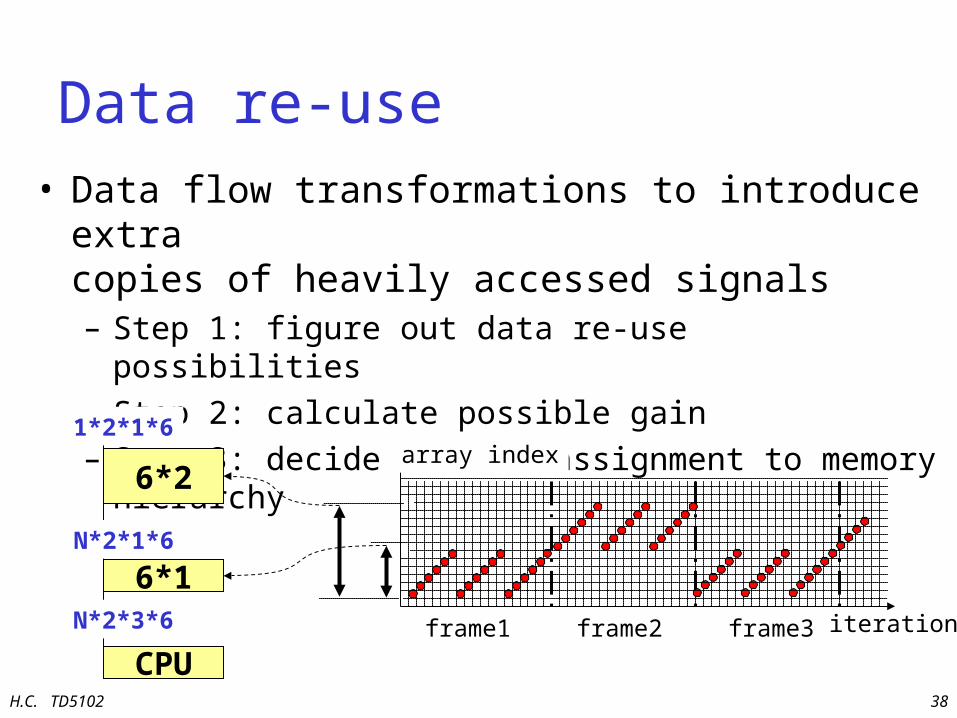
Data re-use• Data flow transformations to introduce extra
copies of heavily accessed signals– Step 1: figure out data re-use possibilities
– Step 2: calculate possible gain
– Step 3: decide on data assignment to memory hierarchy
int[2][6] A;
for (h=0; h<N; h++) for (i=0; i<2; i++) for (j=0; j<3; j++) for (k=1; k<7; k++) B[j] = A[i][k]; iterations
array index (6 * i + k)
H.C. TD5102 38
Data re-use• Data flow transformations to introduce extra
copies of heavily accessed signals– Step 1: figure out data re-use possibilities
– Step 2: calculate possible gain
– Step 3: decide on data assignment to memory hierarchy
iterationsframe1 frame2 frame3
array index6*2
6*1N*2*3*6
CPU
1*2*1*6
N*2*1*6

H.C. TD5102 39
Data re-use tree
N*M
N*1
3*1
image_in
M*3
1*3
gauss_x
M*3
3*3
gauss_xy/comp_edge
M*3
1*1
N*M*3
N*M
N*M N*M*3
N*M*3
N*M*3 N*M
N*M
image_out
0
N*M*8 N*M*8
CPU CPU CPU CPU CPU
H.C. TD5102 40
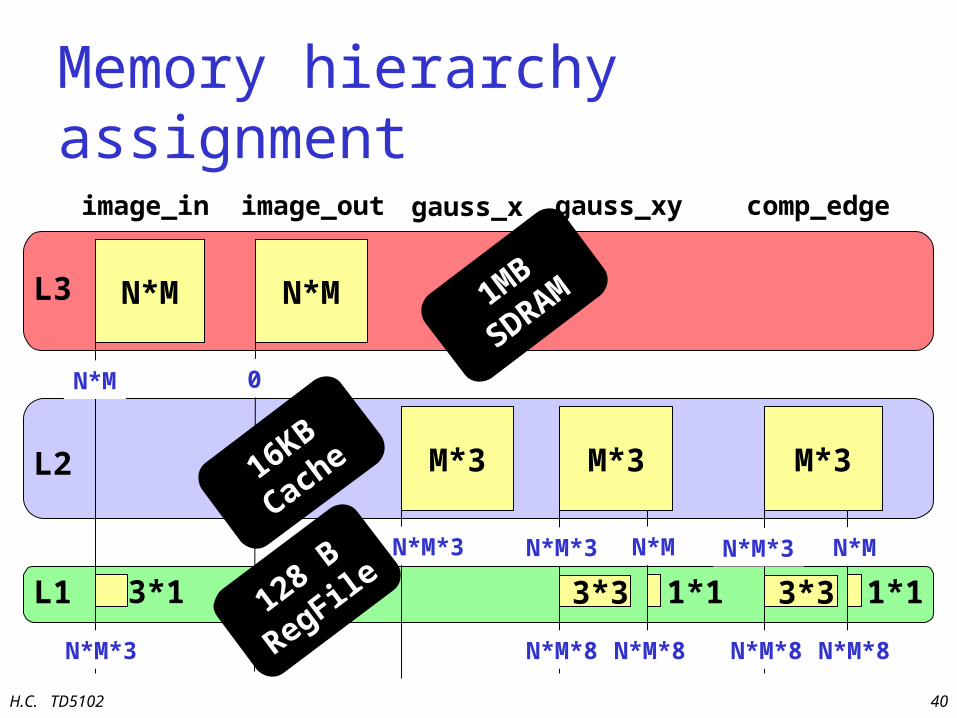
Memory hierarchy assignment
L3
L2
L1
N*M
3*1
image_in
M*3
gauss_x gauss_xy comp_edgeimage_out
3*3 1*1 3*3 1*1
N*M
N*M*3 N*M*3 N*M
N*M
0
N*M*3 N*M
N*M*3 N*M*8 N*M*8 N*M*8 N*M*8
M*3 M*3
1MB
SDRAM
16KB
Cache
128 B
RegFile

H.C. TD5102 41
Data-reuse - cavity detection code
for (y=0; y<M+3; ++y) { for (x=0; x<N+2; ++x) { if (x>=1 && x<=N-2 && y>=1 && y<=M-2) { gauss_x_tmp = 0; for (k=-1; k<=1; ++k) gauss_x_tmp += image_in[x+k][y]*Gauss[abs(k)]; gauss_x_image[x][y] = foo(gauss_x_compute); } else { if (x<N && y<M) gauss_x_lines[x][y] = 0; } /* Other merged code omitted … */ }}
Code before reuse transformation

H.C. TD5102 42
Data-reuse - cavity code
for (y=0; y<M+3; ++y) { for (x=0; x<N+2; ++x) { /* first in_pixel initialized */ if (x==0 && y>=1 && y<=M-2) for (k=0; k<1; ++k) in_pixels[(x+k)%3][y%1] = image_in[x+k][y]; /* copy rest of in_pixel's in row */ if (x>=0 && x<=N-2 && y>=1 && y<=M-2) in_pixels[(x+1)%3][y%1] = image_in[x+1][y]; if (x>=1 && x<=N-1-1 && y>=1 && y<=M-2) { gauss_x_tmp=0; for (k=-1; k<=1; ++k) gauss_x_tmp += in_pixels[(x+k)%3][y%1]*Gauss[Abs(k)]; gauss_x_lines[x][y%3]= foo(gauss_x_tmp); } else if (x<N && y<M) gauss_x_lines[x][y%3] = 0;
Code after reuse transformation detection

H.C. TD5102 43
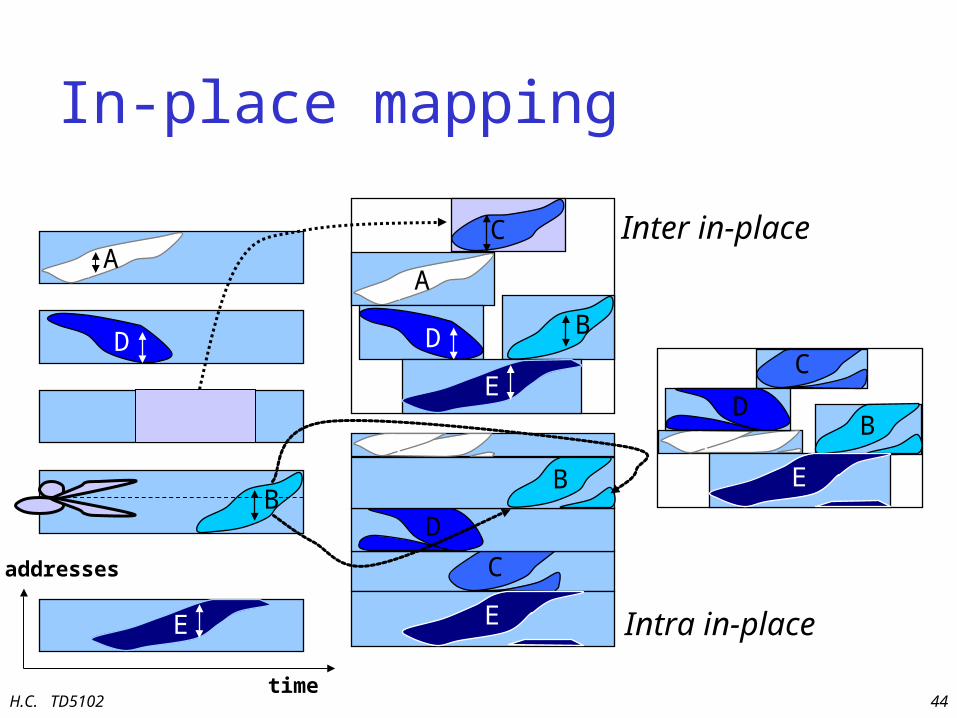
Data layout optimization• At this point multi-dimensional arrays
are to be assigned to physical memories• Data layout optimization determines exactly
where in each memory an array should be placed, to
– reduce memory size by “in-placing” arrays that do not
overlap in time (disjoint lifetimes)– to avoid cache misses due to conflicts– exploit spatial locality of the data in memory to
improve performance of e.g. page-mode memory access sequences
H.C. TD5102 44
In-place mapping
B
C
D
A
C
AD
B
E
C
A
D
E
B
time
E
addresses
A
B
C
D
E
Inter in-place
Intra in-place

H.C. TD5102 45
0x0
0x28a0B
A
In-place mapping
• Implements all the “anticipated” memory size savings obtained in previous steps
• Modifies code to introduce one array per “real” memory
• Changes indices to addresses in mem. arrays
b8 A[100][100];b6 B[20][20];for (i,j,k,l; …) B[i][j] = f(B[j][i], A[i+k][j+l]);
b8 mem1[10400];for (i,j,k,l; …) mem1[10000+i+20*j] = f(mem1[10000+j+20*i], b6(mem1[i+k+100*(j+l)]));0x2710
H.C. TD5102 46
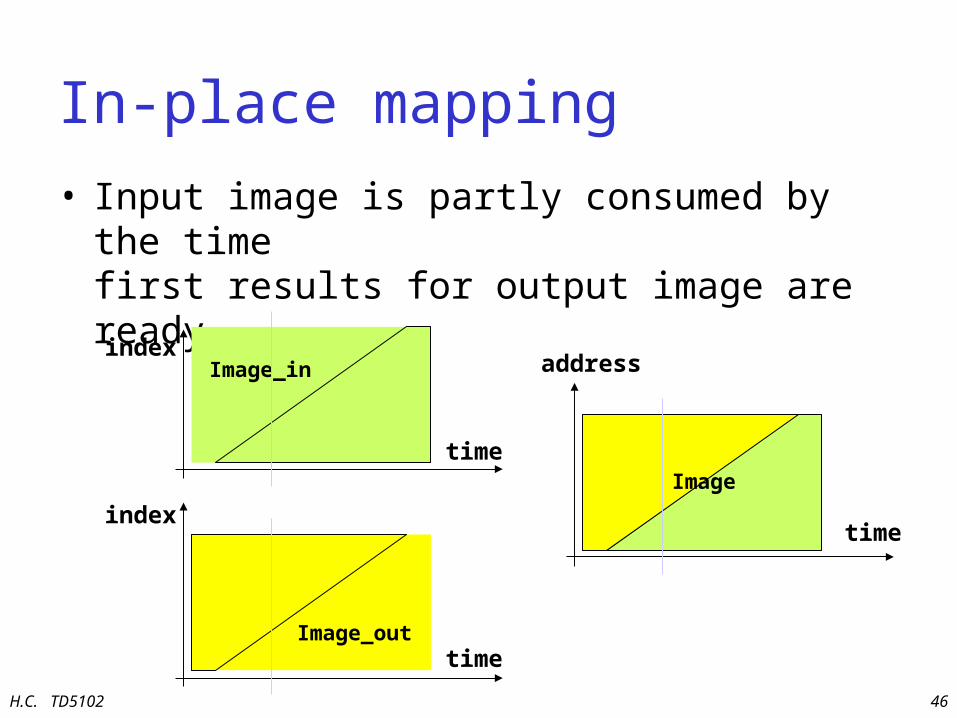
In-place mapping
• Input image is partly consumed by the time first results for output image are ready
Image_out
index
time
Image_in
time
index
time
address
Image

H.C. TD5102 47
In-place - cavity detection code
for (y=0; y<=M+3; ++y) { for (x=0; x<N+5; ++x) { image_out[x-5][y-3] = …; /* code removed */
… = image_in[x+1][y]; }}
for (y=0; y<=M+3; ++y) { for (x=0; x<N+5; ++x) { image[x-5][y-3] = …; /* code removed */
… = image [x+1][y]; }}

H.C. TD5102 48
The last step: ADOPT (Address OPTimization)
• Increased execution time introduced by DTSE– Complicated address arithmetic (modulo!)
– Additional complex control flow
• Multimedia platform not adapted to address calculations
• Additional transformations needed to– Simplify control flow
– Simplify address arithmetic: common sub-expression elimination, modulo expansion, …
– Match remaining expressions on target machine

H.C. TD5102 49
ADOPT principles
Processor specific algebraictransformations
Optimized behavioral descr.for target processor
Compile to target processor
Behavioral description
Extract address expr. codePerform addr. expr. splitting
Apply transformations:- Loop invariant code motion- Induction variable analysis- Algebraic transformations
Optimized behavioral descr.
Map to custom ACU

H.C. TD5102 50
for (i=-8; i<=8; i++) { for (j=- 4; j<=3; j++) { for (k=- 4; k<=3; k++) { Ad[ ] = A[ ]; }} dist += A[ ]-Ad[ ]; }
cse1 = (33025*i+6869616)*2; cse3 = 1040+i; cse4 = j*257+1032; cse5 = k+cse4; cse5+cse1 = cse5+cse3 3096 cse1
ADOPT principles
for (i=- 8; i<=8; i++) { for (j=- 4; j<=3; j++) { for (k=- 4; k<=3; k++) A[((208+i)*257+8+j)*257+ 16+i+k] = B[(8+j)*257+16+i+k]; } dist += A[3096] - B[((208+i)*257+4)*257+ 16+i-4]; }
Example: Full-search Motion Estimation
Algebraic transformationsat word-level

H.C. TD5102 51
DMM – results for cavity detection on ASIC
0
100
200
300
400
500
600
accesses size cycles
OriginalDF trafoLoop trafoData reuseIn-placeData layoutADOPT - moduloADOPT - rest

H.C. TD5102 52
Cavity detection on Pentium-MMX
0
5
10
15
20
25
30
35
# A
cc
es
se
s &
Ex
ec
Tim
e
Co
nve
ntio
na
l
Co
nv
+ A
do
pt
Da
ta F
low
Trf
Lo
op
Trf
D r
eu
se (
line
bu
ffe
r)
D r
eu
se (
pix
el b
uff
er)
Inp
lace
Me
m d
ata
layo
ut
Mo
du
lo r
ed
(a
do
pt)
Oth
er
Ad
op
t
Main Memory Accesses Local Memory Accesses Execution Time (sec)

H.C. TD5102 53
ApplicationsApplicationsArchitecture
Instance
Mapping
Applications
PerformanceAnalysis
PerformanceNumbers
Data transfer anddata storagespecificrewrites in theapplication code
Data transfer anddata storage
specificplatform
customization
The Y-chart revisited

H.C. TD5102 54
Fixing platform parameters
• Assume configurable on-chip memory hierarchy– Trade-off power versus cycle-budget
storagecyclebudget
power [mW]
50,000 100,000 150,000
5
10
15
20
25

H.C. TD5102 55
Conclusion• In multi-media applications exploring data
transfer and storage issues should be done at system level
• DTSE is a methodology for Data Transfer and Storage Exploration based on manual and/or tool-assisted code rewriting
– Platform independent high-level transformations– Platform dependent transformations exploit platform
characteristics (optimal use of cache, …)– Substantial reduction in power and memory size
demonstrated on MPEG-4, OFDM, H.263, ADSL, ...